
Research on Short-Term Traffic Flow Combination Prediction Based on CEEMDAN and Machine Learning

Abstract
:1. Introduction
2. Current Research Status
2.1. Predictive Model Based on Mathematical Statistical Analysis
2.2. Prediction Model Based on Intelligence Theory
2.3. Prediction Model Based on a Combination Forecasting
3. Methods and Principles
3.1. Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN)
3.2. IMF Classification Based on Permutation Entropy
4. Combined Model Construction and Case Analysis Based on CEEMDAN and Machine Learning
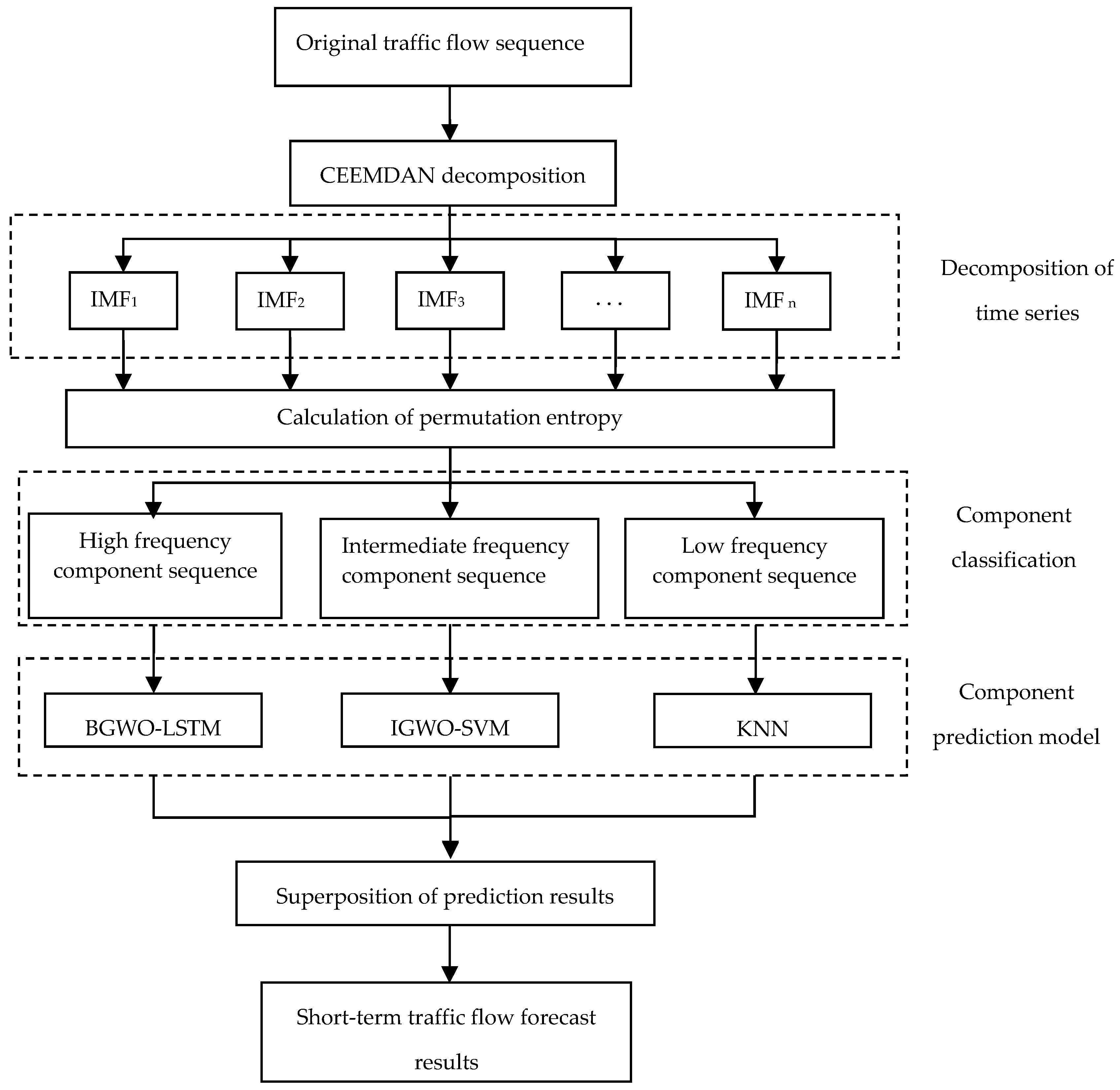
4.1. Short-Term Traffic Flow Combination Model Based on CEEMDAN
4.1.1. Construction of BGWO-LSTM Models
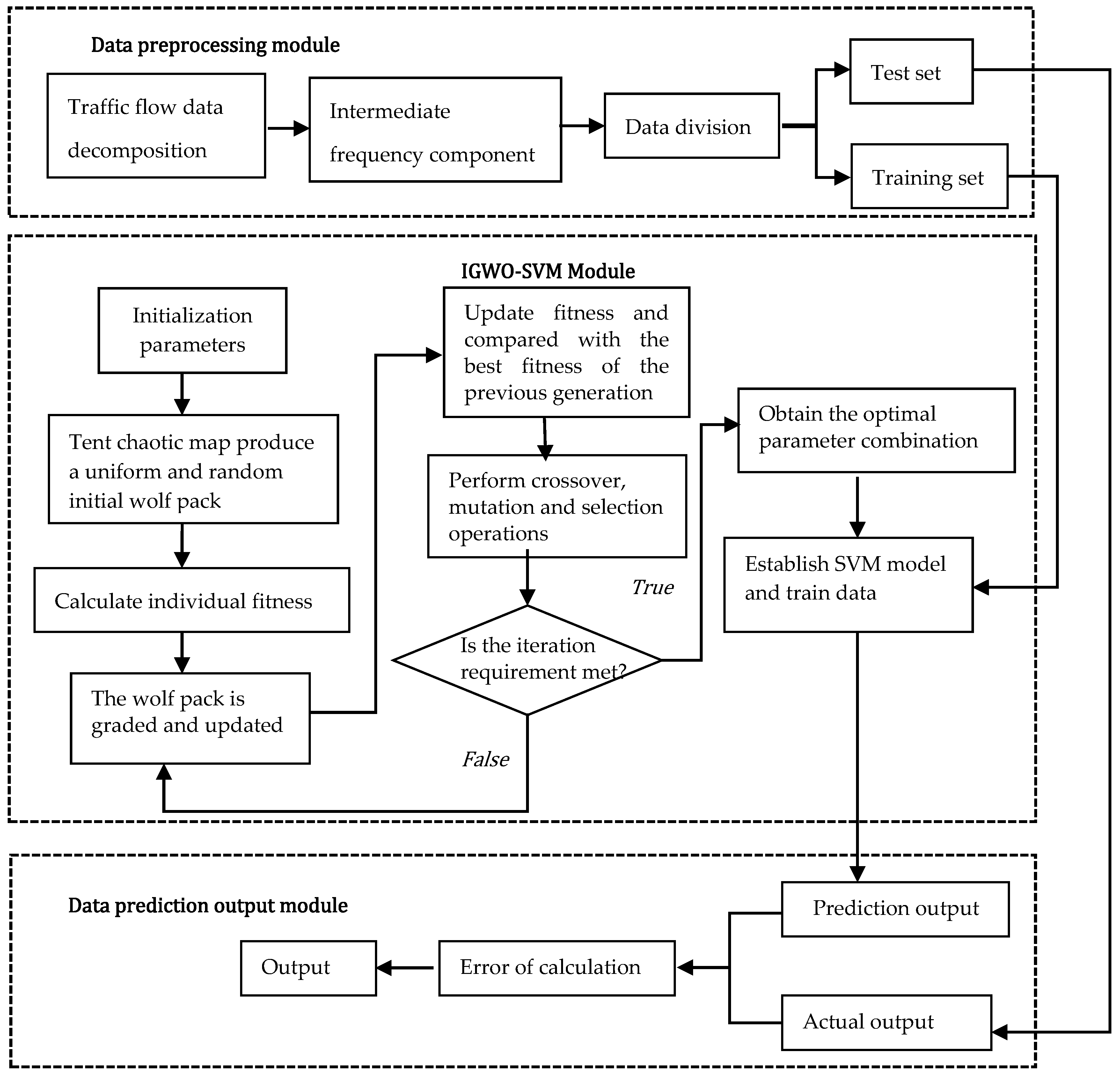
4.1.2. Construction of the IGWO-SVM Model
4.1.3. Construction of KNN Models
4.1.4. A Combined Model Based on CEEMDAN and Machine Learning
4.2. Case Studies
4.2.1. Data Sources
4.2.2. Data Preprocessing
4.2.3. Outcome Evaluation Indicators
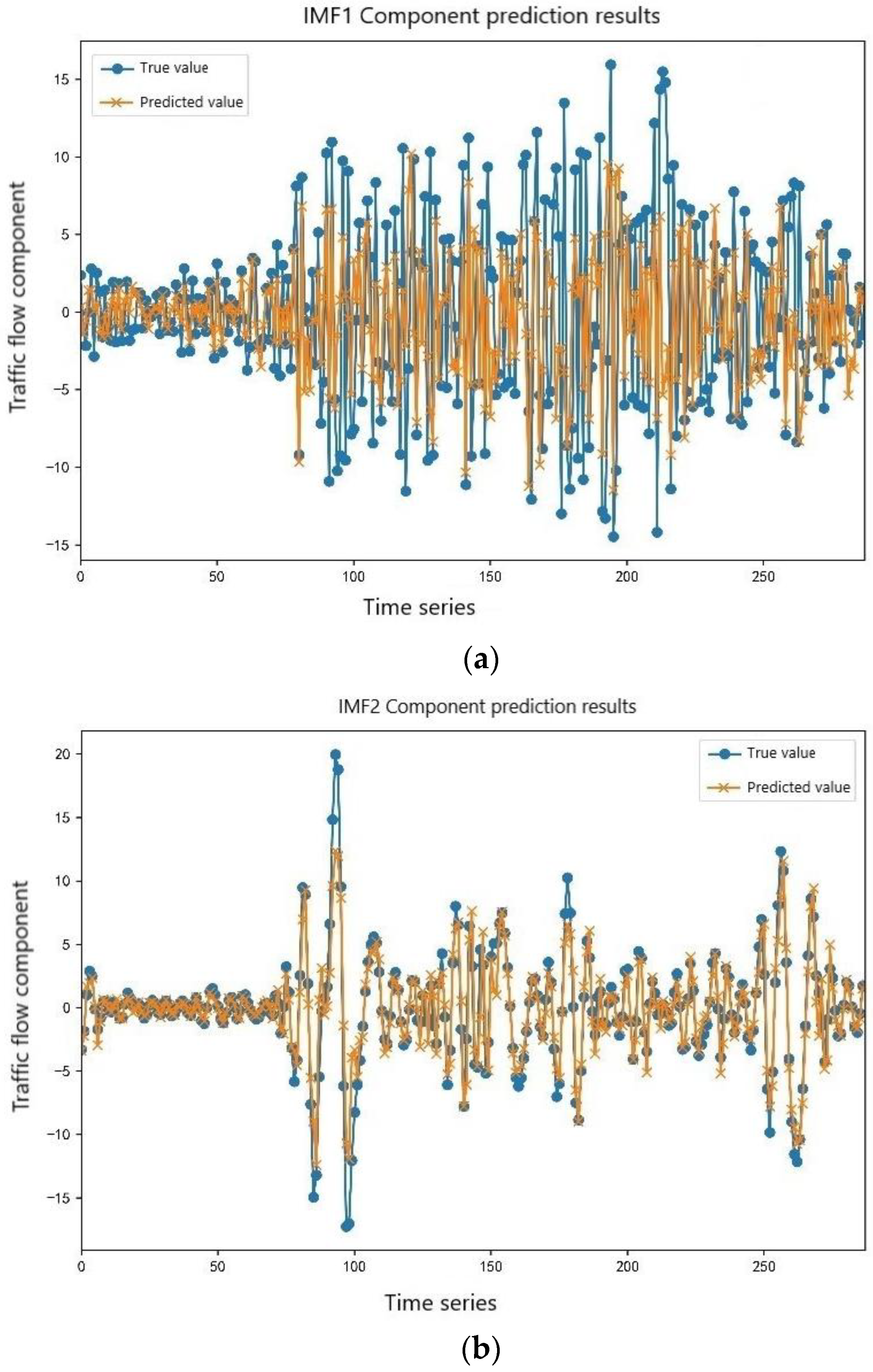
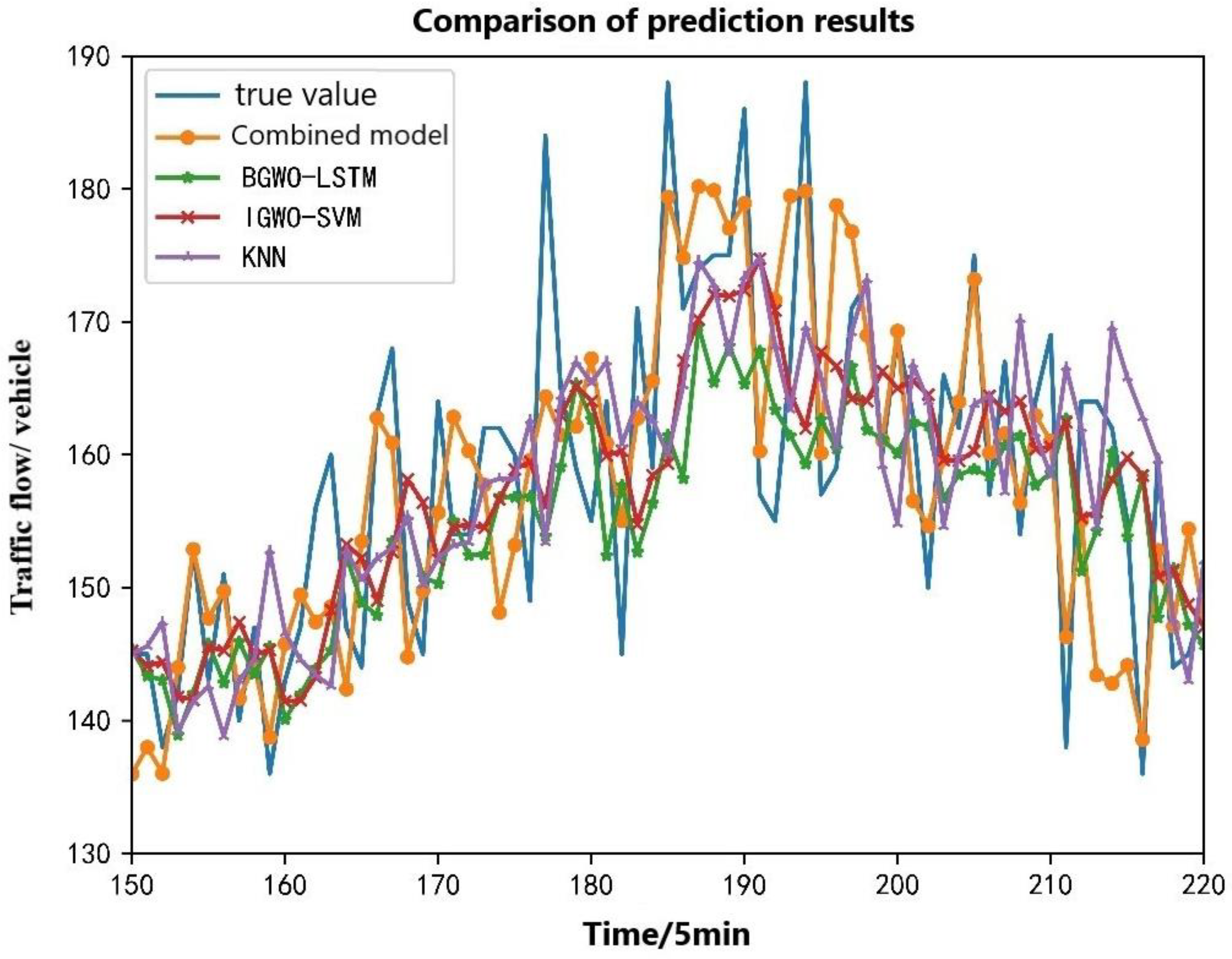
4.2.4. Comparative Analysis of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chan, K.Y.; Khadem, S.; Dillon, T.S. Optimization of neural network configurations for short-term traffic flow forecasting using orthogonal design. In Proceedings of the World Congress on Computational Intelligence, Brisbane, Australia, 10–15 June 2012. [Google Scholar]
- Kim, E.Y. MRF model based real-time traffic flow prediction with support vector regression. Electron. Lett. 2017, 53, 243–245. [Google Scholar] [CrossRef]
- Fu, Y.Q. Short-Term Traffic Flow Analysis and Prediction; Nanjing University of Information Science and Technology: Nanjing, China, 2016. [Google Scholar]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Theory. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Okutani, I.; Stephanedes, Y.J. Dynamic prediction of traffic volume through Kalman filtering theory. Transp. Res. Part B Methodol. 1984, 18, 1–11. [Google Scholar] [CrossRef]
- Leixiao, S.H.E.N.; Yuhang, L.U.; Jianhua, G.U.O. Adaptability of Kalman Filter for Short-time Traffic Flow Forecasting on National and Provincial Highways. J. Transp. Inf. Saf. 2021, 39, 117–127. [Google Scholar]
- Vincent, A.M.; Arthur, V.H. A combination projection-causal approach for short range forecasts. Int. J. Prod. Res. 1997, 15, 153–162. [Google Scholar]
- Kumar, S.V.; Vanajakshi, L. Short-term traffic flow prediction using seasonal ARIMA model with limited input data. Eur. Transp. Res. Rev. 2015, 7, 21–25. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Zhai, D.; Shi, C. Review of Short-term Traffic Flow Forecasting Models. Urban Rapid Rail Transit 2019, 32, 50–54. [Google Scholar]
- Hu, W.B.; Yan, L.P. A Short-term Traffic Flow Forecasting Method Based on the Hybrid PSO-SVR. Neural Process. Lett. 2016, 43, 155–172. [Google Scholar] [CrossRef]
- Wang, Y.T.; Ja, J.J. Analysis and Forecasting for Traffic Flow Data. Sens. Mater. 2019, 31, 2143–2154. [Google Scholar] [CrossRef]
- Mao, Y.-X.; Li, X.-Y. Random Forest in Short-term Traffic Flow Forecasting. Comput. Digit. Eng. 2020, 48, 1585–1589. [Google Scholar]
- Di, J. Investigation on the Traffic Flow Based on Wireless Sensor Network Technologies Combined with FA-BPNN Models. J. Internet Technol. 2019, 20, 589–597. [Google Scholar]
- Zhao, J.Y.; Jia, L. The forecasting model of urban traffic flow based on parallel RBF neural network. In Proceedings of the International Symposium on Intelligence Computation and Applications, Wuhan, China, 27–28 October 2005; pp. 515–520. [Google Scholar]
- Wen, H.; Zhang, D.; Siyuan, L.U. Application of GA-LSTM model in highway traffic flow prediction. J. Harbin Inst. Technol. 2019, 51, 81–95. [Google Scholar]
- Zhang, Z.C.; Li, M. Multistep speed prediction on traffic networks: A deep learning approach considering spatio-temporal dependencies. Transp. Res. Part C Emerg. Technol. 2019, 105, 297–322. [Google Scholar] [CrossRef]
- Bates, J.M.; Granger, C.W. The Combination of Forecasts. J. Oper. Res. Soc. 1960, 20, 451–468. [Google Scholar] [CrossRef]
- Wang, J.; Deng, W.; Zaho, J.-B. Short-Term Freeway Traffic Flow Prediction Based on Multiple Methods with Bayesian Network. J. Transp. Syst. Eng. Inf. Technol. 2011, 11, 147–153. [Google Scholar]
- Li, W.; Ban, X.J. Real-time movement-based traffic volume prediction at signalized intersections. J. Transp. Eng. Part A Syst. 2020, 146, 04020081. [Google Scholar] [CrossRef]
- Xia, D.; Zhang, M. A distributed WND-LSTM model on map reduce for short-term traffic flow prediction. Neural Comput. Appl. 2020, 33, 2393–2410. [Google Scholar] [CrossRef]
- Zhou, J.; Chang, H. A multiscale and high-precision LSTM-GASVR short-term traffic flow prediction model. Complexity 2020, 2020, 1434080. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the IEEE International Conference on Speech and Signal Processing (ICASSP), Prague, Czech, 22–27 May 2011; pp. 4140–4147. [Google Scholar]
- Ji, G.-Y. Dissolved Oxygen Prediction of Xi-jiang River with the LSTM Deep Network by Artificial Bee Colony Algorithm Based on CEEMDAN. Chin. J. Eng. Math. 2021, 38, 315–329. [Google Scholar]
- Brandt, C.; Pompe, B. Permutation Entropy: A natural complexity measure for time series. Phys. Rev. Lett. Am. Physiol. Soc. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Song, G.; Zhang, Y.; Bao, F.; Qin, C. Stock prediction model based on particle swarm optimization LSTM. J. Beijing Univ. Aeronaut. Astronaut. 2019, 45, 2533–2542. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Traffic Flow/Vehicle | Time | Traffic Flow/Vehicle |
|---|---|---|---|
| 7 October 2019 00:00:00 | 43 | 7 October 2019 01:05:00 | 38 |
| 7 October 2019 00:05:00 | 47 | 7 October 2019 01:10:00 | 41 |
| 7 October 2019 00:10:00 | 42 | 7 October 2019 01:15:00 | 38 |
| 7 October 2019 00:15:00 | 40 | 7 October 2019 01:20:00 | 36 |
| 7 October 2019 00:20:00 | 43 | 7 October 2019 01:25:00 | 38 |
| 7 October 2019 00:25:00 | 45 | 7 October 2019 01:30:00 | 42 |
| 7 October 2019 00:30:00 | 38 | 7 October 2019 01:35:00 | 39 |
| 7 October 2019 00:35:00 | 40 | 7 October 2019 01:40:00 | 36 |
| 7 October 2019 00:45:00 | 36 | 7 October 2019 01:45:00 | 36 |
| 7 October 2019 00:50:00 | 36 | 7 October 2019 01:50:00 | 36 |
| 7 October 2019 00:55:00 | 43 | 7 October 2019 01:55:00 | 40 |
| 7 October 2019 01:00:00 | 38 | 7 October 2019 02:00:00 | 38 |
| Component Sequence | IMF1 | IMF2 | IMF3 | IMF4 | IMF5 | IMF6 | IMF7 | IMF8 |
|---|---|---|---|---|---|---|---|---|
| PE | 0.9950 | 0.8677 | 0.6898 | 0.5162 | 0.4203 | 0.4017 | 0.3931 | 0.0374 |
| Model | A Combined Model Based on CEEMDAN and Machine Learning | BGWO-LSTM Model | IGWO-SVM Model | KNN Model | |
|---|---|---|---|---|---|
| Evaluation Indicators | |||||
| EMSE | 32.53 | 73.79 | 77.55 | 90.22 | |
| EMAE | 4.14 | 6.47 | 6.58 | 6.84 | |
| ERMSE | 5.70 | 8.59 | 8.81 | 9.50 | |
| R2 | 0.98 | 0.96 | 0.96 | 0.95 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Fu, S.; He, Z. Research on Short-Term Traffic Flow Combination Prediction Based on CEEMDAN and Machine Learning. Appl. Sci. 2023, 13, 308. https://doi.org/10.3390/app13010308
Wu X, Fu S, He Z. Research on Short-Term Traffic Flow Combination Prediction Based on CEEMDAN and Machine Learning. Applied Sciences. 2023; 13(1):308. https://doi.org/10.3390/app13010308
Chicago/Turabian StyleWu, Xinye, Shude Fu, and Zujie He. 2023. "Research on Short-Term Traffic Flow Combination Prediction Based on CEEMDAN and Machine Learning" Applied Sciences 13, no. 1: 308. https://doi.org/10.3390/app13010308