
Fusion Segmentation Network Guided by Adaptive Sampling Radius and Channel Attention Mechanism Module for MLS Point Clouds

Abstract
:1. Introduction
- A module for adaptively varying the sampling radius is proposed to enhance the high-dimensional features of the sampled points and improve the semantic segmentation accuracy of inhomogeneous sparse MLS point clouds, which can solve the problem that road point clouds data was sparse and inhomogeneous in deep learning network.
- To train and test the proposed model, we constructed a new MLS road point clouds dataset for training, testing, and evaluating the deep learning network.
- Based on the addition of the new sampling module, the attention mechanism module is added to build a new deep learning network, and ablation experiments are conducted to verify the effectiveness of the new sampling module with the mechanism.
2. Related Work
2.1. Non-Deep Learning Methods
2.2. The Way of Deep Learning
3. Methods
3.1. Sampling Module with Adaptive Radius
3.2. Channel Attention Module
4. Results and Discussion
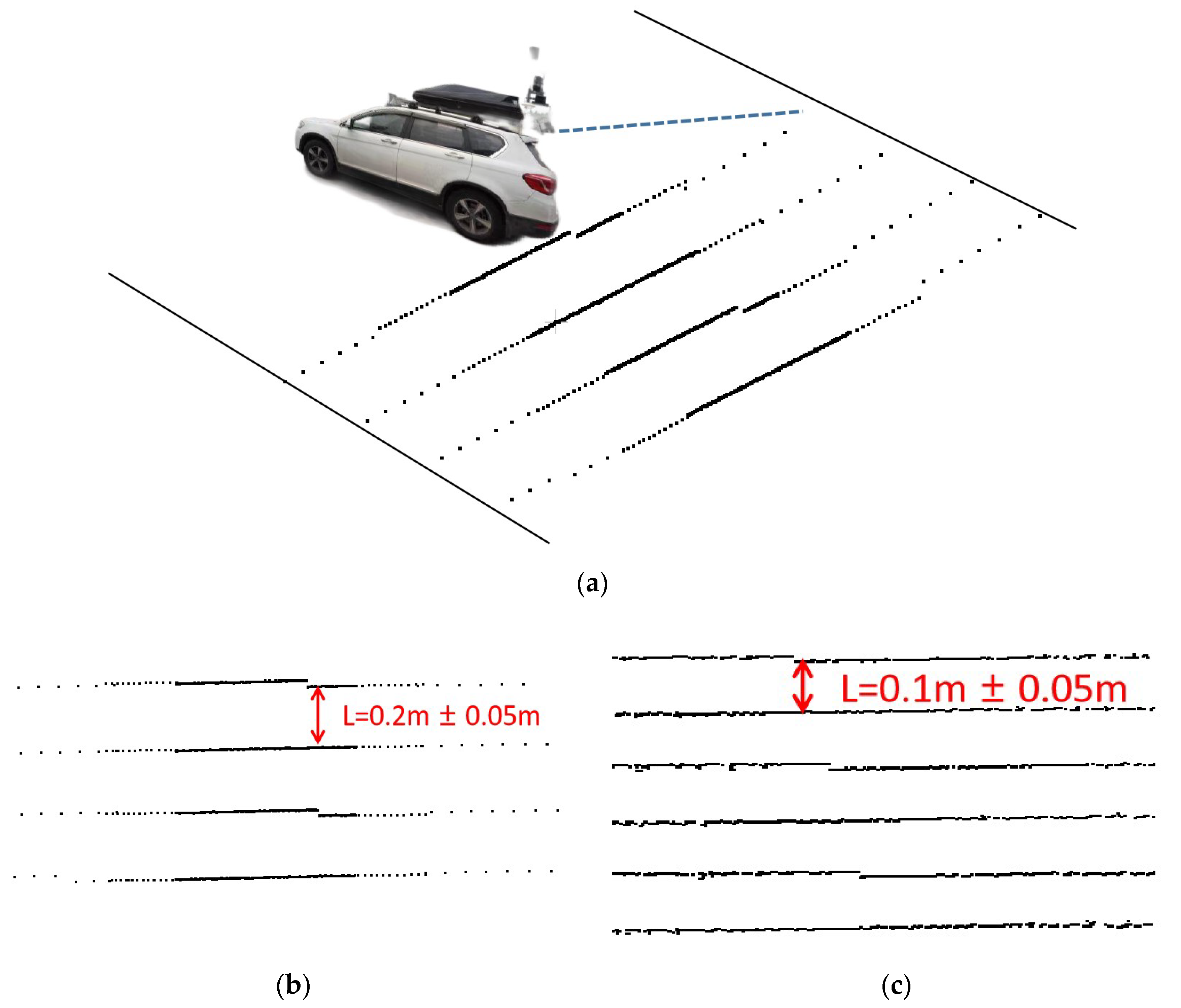
4.1. Dataset Description and Assessment
4.1.1. Quantitative Analysis
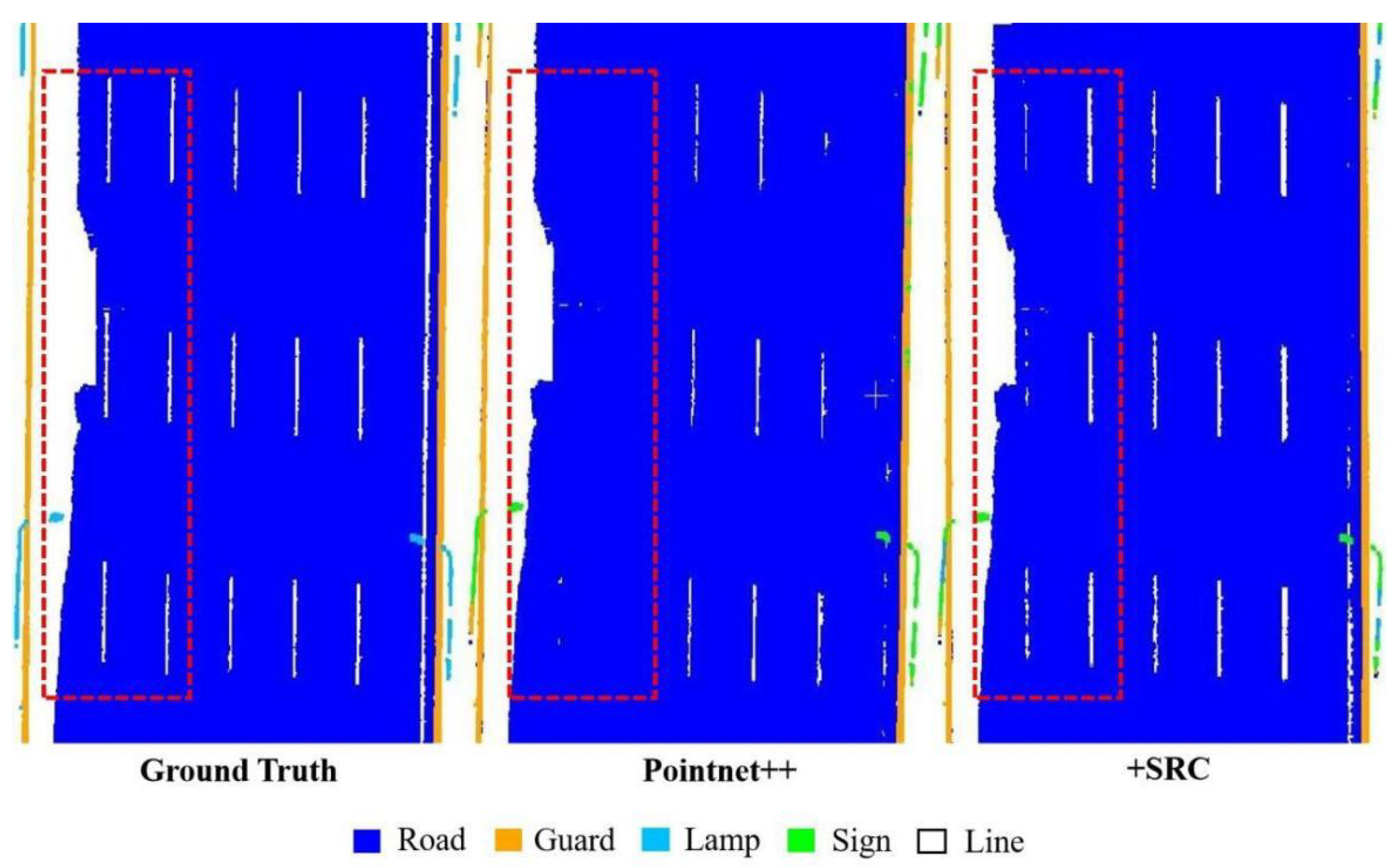
4.1.2. Qualitative Analysis
4.2. Experiment and Analysis
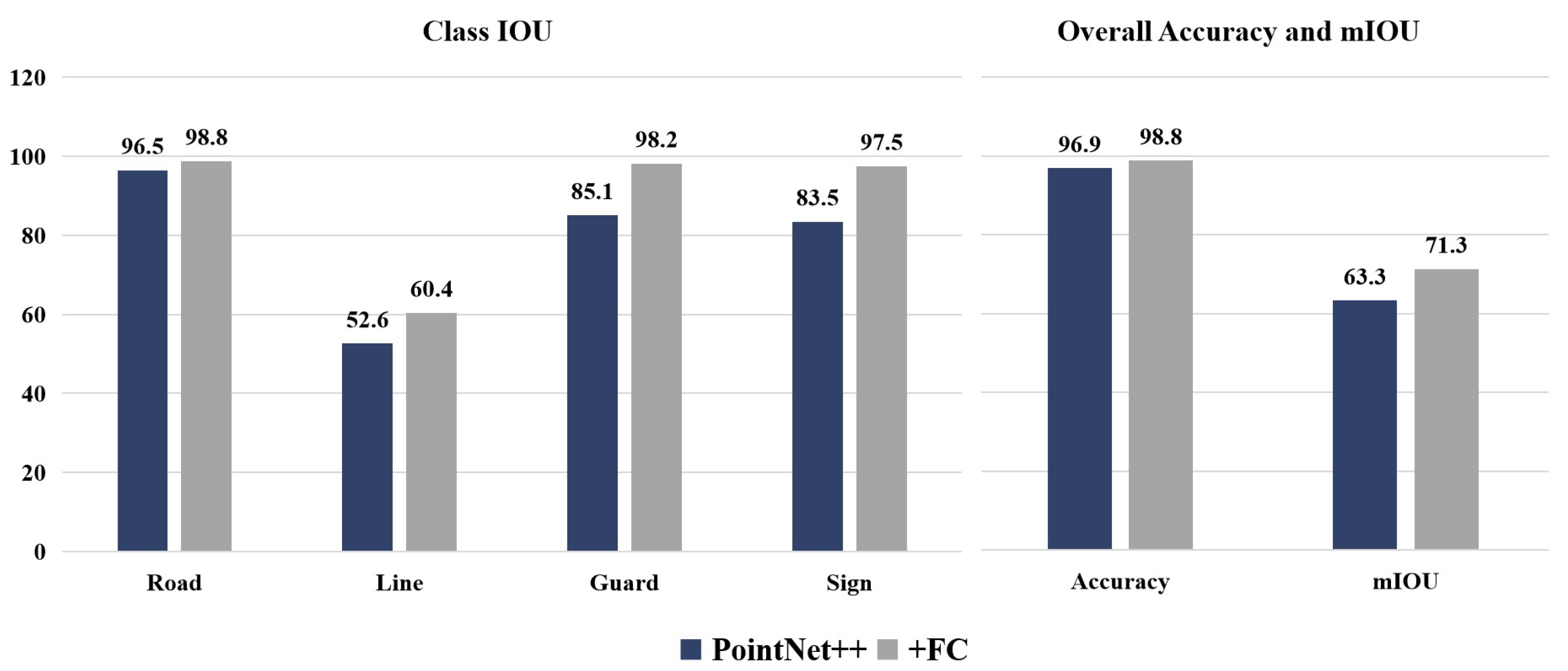
4.2.1. SRC Module Enhancements
4.2.2. Enhancement of Channel Attention Mechanism
4.2.3. Ablation Experiment
4.2.4. Comparison Experiments
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, M.; Zhou, Y.Q.; Zhao, J.H.; Zhou, T.F.; Yan, B.N.; Huang, X.F. Urban Geospatial Information Acquisition Mobile Mapping System based on close-range photogrammetry and IGS site calibration. Geo-Spat. Inf. Sci. 2021, 24, 558–579. [Google Scholar] [CrossRef]
- Gu, J.X.; Yang, B.S.; Dong, Z.; Yang, C.H. Intelligent holographic mapping for digital twin cities. Mapp. Bull. 2020, 6, 134–140. [Google Scholar]
- Guo, M.; Sun, M.X.; Pan, D.; Huang, M.; Yan, B.N.; Zhou, Y.Q.; Nie, P.J.; Zhou, T.F.; Zhao, Y.S. High-precision detection method for large and complex steel structures based on global registration algorithm and automatic point cloud generation. Measurement 2021, 172, 8. [Google Scholar] [CrossRef]
- Zhao, J.H.; Wang, Y.R.; Cao, Y.E.; Guo, M.; Huang, X.F.; Zhang, R.J.; Dou, X.T.; Niu, X.Y.; Cui, Y.Y.; Wang, J. The Fusion Strategy of 2D and 3D Information Based on Deep Learning: A Review. Remote Sens. 2021, 13, 4029. [Google Scholar] [CrossRef]
- Guo, M.; Sun, M.X.; Zhou, T.F.; Yan, B.N.; Zhou, Y.Q.; Pan, D. Novel Trajectory Optimization Algorithm of Vehicle-borne LiDAR Mobile Measurement System. Sens. Mater. 2020, 32, 3935–3953. [Google Scholar] [CrossRef]
- Guo, M.; Yan, B.N.; Zhou, T.F.; Pan, D.; Wang, G.L. Accurate Calibration of a Self-Developed Vehicle-Borne LiDAR Scanning System. J. Sens. 2021, 2021, 18. [Google Scholar] [CrossRef]
- Guo, M.; Yan, B.N.; Zhou, T.F.; Chen, C.Y.; Zhang, C.; Liu, Y. Application of lidar technology in the deformation analysis of Yingxian wooden towers. J. Build. Sci. Eng. 2020, 37, 109–117. [Google Scholar]
- Guo, M.; Zhao, J.W.; Pan, D.; Sun, M.X.; Zhou, Y.Q.; Yan, B.N. Normal cloud model theory-based comprehensive fuzzy assessment of wooden pagoda safety. J. Cult. Herit. 2022, 55, 1–10. [Google Scholar] [CrossRef]
- Balado, J.; Martinez-Sanchez, J.; Arias, P.; Novo, A. Road Environment Semantic Segmentation with Deep Learning from MLS Point Cloud Data. Sensors 2019, 19, 3466. [Google Scholar] [CrossRef] [Green Version]
- Guo, M.; Zhou, Y.Q.; Chen, C.; Zhou, Z.; Guo, K. Design of time synchronization device for mobile lidar measurement system with BeiDou navigation timing. Infrared Laser Eng. 2020, 49, 33–42. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classifification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, P.; Li, W.; Liu, S.; Zhang, Y.; Gao, Z.; Ogunbona, P. Large-scale Continuous Gesture Recognition Using Convolutional Neural Networks. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Yang, B.S.; Han, X.; Dong, Z. Point cloud deep learning benchmark data set. J. Remote Sens. 2021, 25, 231–240. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Wu, W.; Qi, Z.; Li, F. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9613–9622. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation. arXiv 2018, arXiv:1807.00652v2. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. arXiv 2018, arXiv:1801.07791v5. [Google Scholar]
- Bhanu, B.; Lee, S.; Ho, C.C.; Henderson, T. Range data processing: Representation of surfaces by edges. In Proceedings of the Eighth International Conference on Pattern Recognition, Paris, France, 27–31 October 1986. [Google Scholar]
- Jiang, X.Y.; Bunke, H.; Meier, U. Fast range image segmentation using high leve segmentation primitives. In Proceedings of the 3rd IEEE Workshop on Applications of Compute Vision, Sarasota, FL, USA, 2–4 December 1996. [Google Scholar]
- Besl, P.J.; Jain, R.C. Segmentation through variable order surface fitting. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 167–192. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Chen, B. Architectural modeling from sparsely scanned range data. Int. J. Comput. Vis. 2008, 78, 223–236. [Google Scholar] [CrossRef]
- Filin, S.; Pfeifer, N. Segmentation of airborne data using a slope adaptive filter. ISPRS J. Photogramm. Remote Sens. 2006, 60, 71–80. [Google Scholar] [CrossRef]
- Zhu, Z.J.; Li, X.; Xu, J.H.; Yuan, J.H.; Tao, J. Unstructured Road Segmentation Based on Road Boundary Enhancement Point-Cylinder Network Using LiDAR Sensor. Remote Sens. 2021, 13, 495. [Google Scholar] [CrossRef]
- Luo, N.; Jiang, Y.Y.; Wang, Q. Supervoxel-Based Region Growing Segmentation for Point Cloud Data. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 20. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, L.; Sheng, Y.; Shen, M. Pole-like Objects Segmentation and Multiscale Classifification-Based Fusion from Mobile Point Clouds in Road Scenes. Remote Sens. 2021, 13, 4382. [Google Scholar] [CrossRef]
- Sha, Z.C.; Chen, Y.P.; Lin, Y.B.; Wang, C.; Marcato, J.; Li, J. A Supervoxel Approach to Road Boundary Enhancement From 3-D LiDAR Point Clouds. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5. [Google Scholar] [CrossRef]
- Rastiveis, H.; Shams, A.; Sarasua, W.A.; Li, J. Automated extraction of lane markings from mobile LiDAR point clouds based on fuzzy inference. ISPRS J. Photogramm. Remote Sens. 2020, 160, 149–166. [Google Scholar] [CrossRef]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph attention convolution for point cloud semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10296–10305. [Google Scholar]
- Yang, J.C.; Zhang, Q.; Ni, B.B.; Li, L.G.; Liu, J.X.; Tian, Q. Modeling Point Clouds with Self-Attention and Gumbel Subset Sampling. arXiv 2019, arXiv:1904.03375. [Google Scholar]
- Ma, L.F.; Li, Y.; Li, J.; Yu, Y.T.; Marcato, J.; Goncalves, W.N.; Chapman, M.A. Capsule-Based Networks for Road Marking Extraction and Classification from Mobile LiDAR Point Clouds. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1981–1995. [Google Scholar] [CrossRef]
- Chen, S.Y.; Zhang, Z.X.; Zhong, R.F.; Zhang, L.Q.; Ma, H.; Liu, L.R. A Dense Feature Pyramid Network-Based Deep Learning Model for Road Marking Instance Segmentation Using MLS Point Clouds. IEEE Trans. Geosci. Remote Sens. 2021, 59, 784–800. [Google Scholar] [CrossRef]
- Li, H.T.; Todd, Z.; Bielski, N.; Carroll, F. 3D lidar point-cloud projection operator and transfer machine learning for effective road surface features detection and segmentation. Visual Comput. 2022, 38, 1759–1774. [Google Scholar] [CrossRef]
- Ma, L.F.; Li, Y.; Li, J.; Tan, W.K.; Yu, Y.T.; Chapman, M.A. Multi-Scale Point-Wise Convolutional Neural Networks for 3D Object Segmentation from LiDAR Point Clouds in Large-Scale Environments. IEEE Trans. Intell. Transp. Syst. 2021, 22, 821–836. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Types | Class IOU | Overall | |||||
|---|---|---|---|---|---|---|---|
| Road | Line | Lamp | Guard | Sign | Accuracy | mIOU | |
| Syncretic | 0.991 | 0.662 | 0.385 | 0.999 | 0.983 | 0.991 | 0.726 |
| Method | Object Types | Overall | |||||
|---|---|---|---|---|---|---|---|
| Road | Line | Lamp | Guard | Sign | Accuracy | mIOU | |
| PointNet | 0.961 | 0.406 | - | 0.303 | 0.188 | 0.963 | 0.421 |
| PointNet++ | 0.965 | 0.526 | - | 0.851 | 0.835 | 0.969 | 0.517 |
| GACNet | 0.965 | 0.584 | - | 0.806 | 0.714 | 0.972 | 0.642 |
| Syncretic | 0.991 | 0.662 | 0.385 | 0.999 | 0.983 | 0.991 | 0.726 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, P.; Guo, M.; Wang, H.; Fu, Z.; Li, D.; Ren, X. Fusion Segmentation Network Guided by Adaptive Sampling Radius and Channel Attention Mechanism Module for MLS Point Clouds. Appl. Sci. 2023, 13, 281. https://doi.org/10.3390/app13010281
Cheng P, Guo M, Wang H, Fu Z, Li D, Ren X. Fusion Segmentation Network Guided by Adaptive Sampling Radius and Channel Attention Mechanism Module for MLS Point Clouds. Applied Sciences. 2023; 13(1):281. https://doi.org/10.3390/app13010281
Chicago/Turabian StyleCheng, Peng, Ming Guo, Haibo Wang, Zexin Fu, Dengke Li, and Xian Ren. 2023. "Fusion Segmentation Network Guided by Adaptive Sampling Radius and Channel Attention Mechanism Module for MLS Point Clouds" Applied Sciences 13, no. 1: 281. https://doi.org/10.3390/app13010281