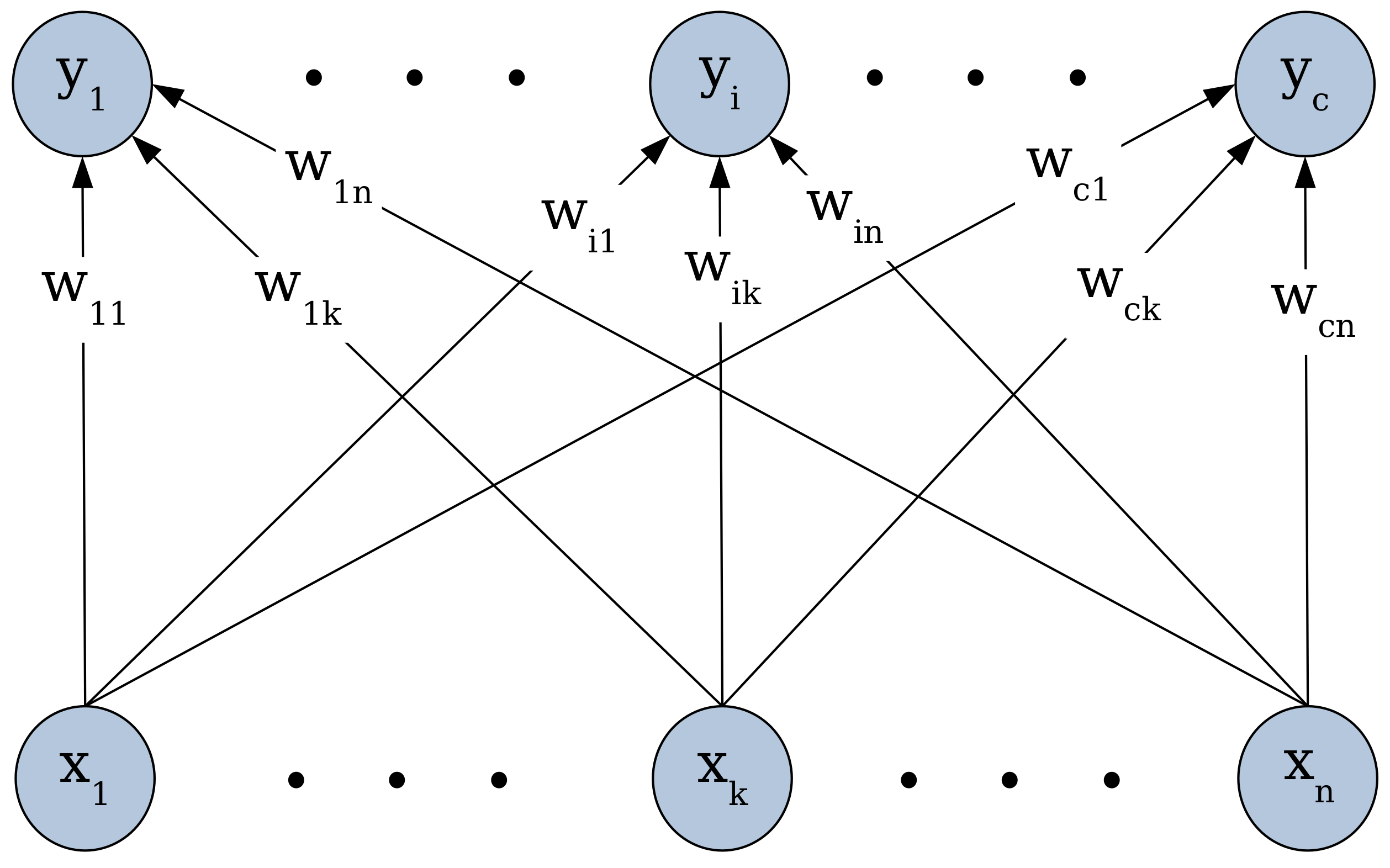
2.2. Competitive Neural Networks
A competitive neural network (
Figure 1) is comprised of only two layers: an input layer of
p neurons aimed at receiving the input data in the form of
p-dimensional object vectors, and an output or competitive layer composed of
c neurons representing each cluster prototype.
Traditional algorithms for training competitive neural networks, whose state of the art can be represented by the unsupervised learning vector quantization algorithm (LVQ3) [
17], are based on the principle of the winner takes all (WTA) [
17,
18]. Meaning that, for each input vector
x presented to the network during its training process, only one output neuron, called the winner, is adjusted by assigning
x to the cluster it represents. It is the neuron whose weight vector minimizes the distance to
x. The performance of such algorithms is limited to situations where the
c clusters are compact and well separated.
For overlapping or not well separated clusters, many generalizations of WTA algorithms are proposed in the literature, including different variants of the fuzzy learning vector quantization algorithm (FLVQ) [
19,
20,
21], which can be considered as the state of the art of these generalizations. FLVQ, whose operating principle is recalled in the next subsection, is mainly inspired by the well-known fuzzy c-means algorithm, FCM [
22].
2.3. The Fuzzy Learning Vector Quantization (FLVQ)
FLVQ is a fuzzy variant of LVQ3 for which all neurons are winners but to different degrees. It is an optimization procedure that tries to better exploit the structural information carried by each training example [
20] by minimizing the following objective function
where
U is a matrix of membership degrees, with
denoting the membership degree of the
kth object to the
ith class;
V is the matrix of prototypes, with
representing the
ith class prototype;
is a weighting exponent that controls the fuzziness degree of candidate partitions during the learning process; and
n is the total number of training examples.
can be interpreted as a fuzzy measure of the global error incurred in representing the
n training vectors by the
c prototypes. It can be minimized using an alternating optimization procedure that consists in repeatedly recalculating
U and
V matrices using the expressions:
and
Hence, starting from a randomly chosen matrix of initial prototypes
, if we iteratively recalculate the components of
U and
V according to (
5) and (
6), the process will converge to a point
where the
c prototypes are stabilized, which means a point from which the difference
becomes insignificant. To evaluate this difference, we use the expression:
Depending on the way
m varies throughout iterations, two versions of FLVQ have been developed: FLVQ↓ and FLVQ↑. In FLVQ↓,
m decreases according to the relation
and in FLVQ↑, it increases according to
where
t is the index of iterations and
the maximal number of iterations.
2.4. Training Process of the Proposed Architecture
The first step in the training algorithm of the proposed neural architecture is an unsupervised learning procedure that uses the FLVQ algorithm for representing each class by one or more prototypes that the procedure tries to learn from the training data in unsupervised mode, i.e., without using the known labels. The second step uses a supervised learning procedure for assessing the quality of the learned prototypes in terms of classification results. For this, the c classes are reconstructed using the nearest prototype rule, and the obtained results compared to the original classes. If one or more constructed classes differ from the original ones, the corresponding prototypes are rejected and both steps are repeated for these classes using additional competitive layers until no difference persists between the constructed and the original classes, or a maximal number of layers is reached. For this, all misclassified objects are grouped with those, if any, that present small membership degrees to all classes in order to form the training data set for an additional layer of competitive neurons.
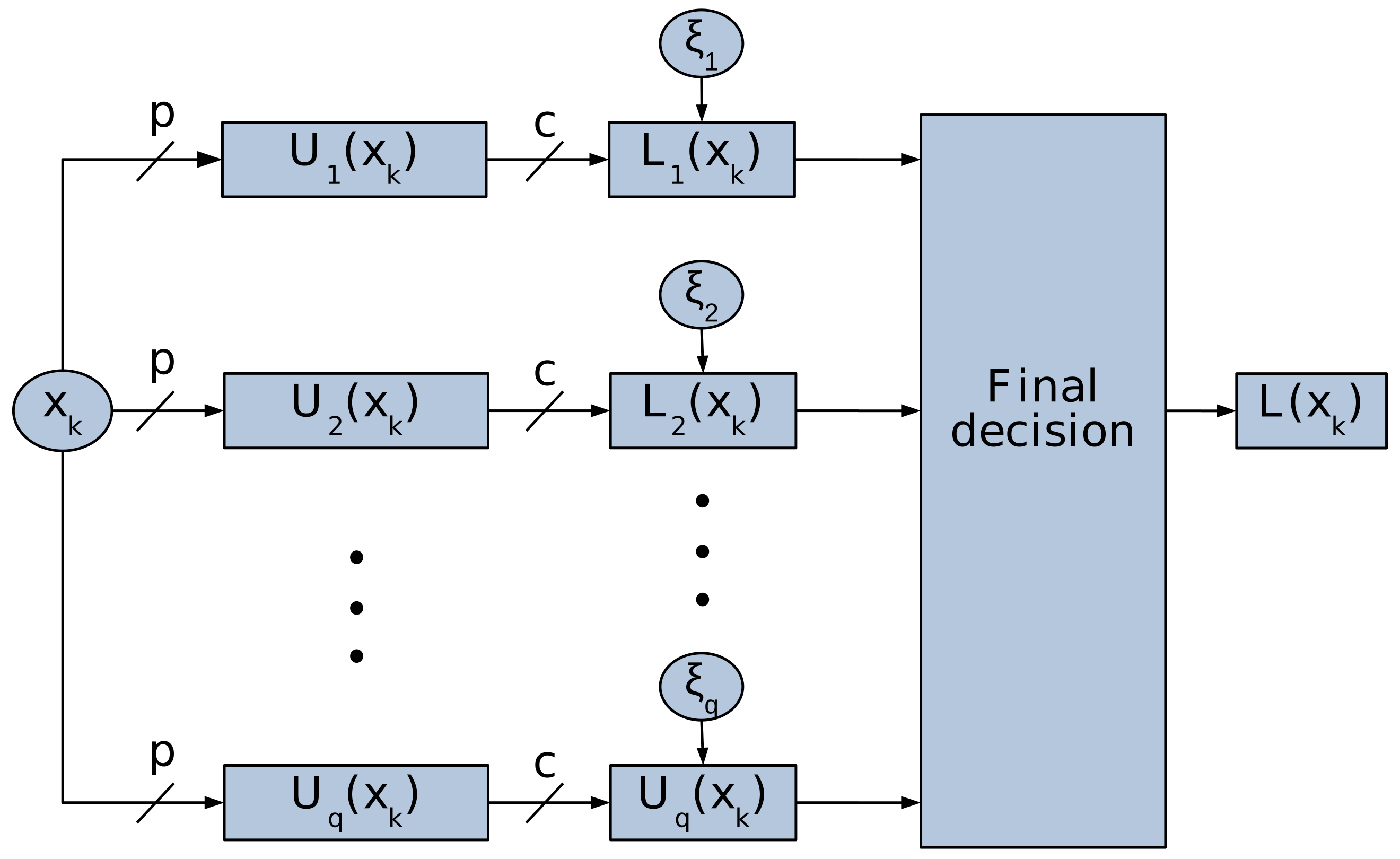
As shown in (
Figure 2), the resulting architecture is a multi-competitive-layer neural network (MCLNN). Each of these layers contains
neurons representing the
detected prototypes, and
possible additional neurons representing the training examples that could not be correctly classified by this layer. These remaining examples are called “strong elements” and can be seen as noisy elements for the current layer.
Thus, the ultimate goal of MCLNN is to represent each class by a set of one or more prototypes. The total number of the resulting prototypes for all layers of the network is
, with
. During the learning process of these prototypes, whenever an object is presented to the input of a layer
r, all neurons of this layer are considered as winners to different degrees, and the membership degrees of the input object to the corresponding classes are computed using the expression:
where
is the membership degree of the object
to the cluster
, which is represented by the
ith neuron of the
rth layer;
is the number of neurons in the
rth layer;
is the
kth object vector of the training data set used to train the
rth layer;
is the
jth feature of the object vector
;
is a weighting exponent that controls the fuzziness degree of candidate partitions during the learning process; and
is the activation function of the
neuron of the
rth layer, defined by the expression:
where
is the
jth synaptic weight of neuron
, which is also the
jth feature of prototype
that represents cluster
;
p is the number of features of the object vectors;
i is the index used to locate a neuron in a competitive layer; and
r is the layer’s index.
The first layer is trained using the original training data set X, and each subsequent one with the set of remaining strong elements . Thus, at the end of the training process of each layer r, all objects of its training data set are labeled. For this, each object in is assigned to the cluster represented by the winning prototype, which is the output neuron that maximizes while exceeding a certain threshold . The latter is introduced in this work to ensure a minimum of similarity between each processed object, and the representative prototype of the class it is assigned to, using the maximum membership degree rule. Consequently, two possible cases can be distinguished according to the label of : (1) is well classified, if its true label is equal to , or (2) is misclassified, if .
In the first case, the rth layer is used to recognize , and we say that accepts its representation by the winning neuron of the rth layer. In the second case, the classification result is ignored because cannot be represented by the winning neuron. In this case, is considered as a strong element that leads to the addition of a new neuron to MCLNN that may better represent it. For this, the p synaptic weights of the newly added neuron are initialized using the p components of .
In the instance where the membership degree of to the class represented by the winning prototype in the current layer does not reach its acceptance threshold , we consider that cannot be classified at the level of this layer and we assign it to a new training data set that will be used for training the next additional layer, .
This mechanism can be summarized by the following mathematical expression:
where
is the label of the object
generated by the
layer. If
,
and all similar objects cannot be processed by this layer;
is the maximum membership degree of
to all clusters;
is the label of cluster
represented by neuron
i of layer
r; and
is the minimum threshold of membership degree for
to accept to be represented exclusively by a neuron of the current layer. Any result of classification generated by other layers is then ignored.
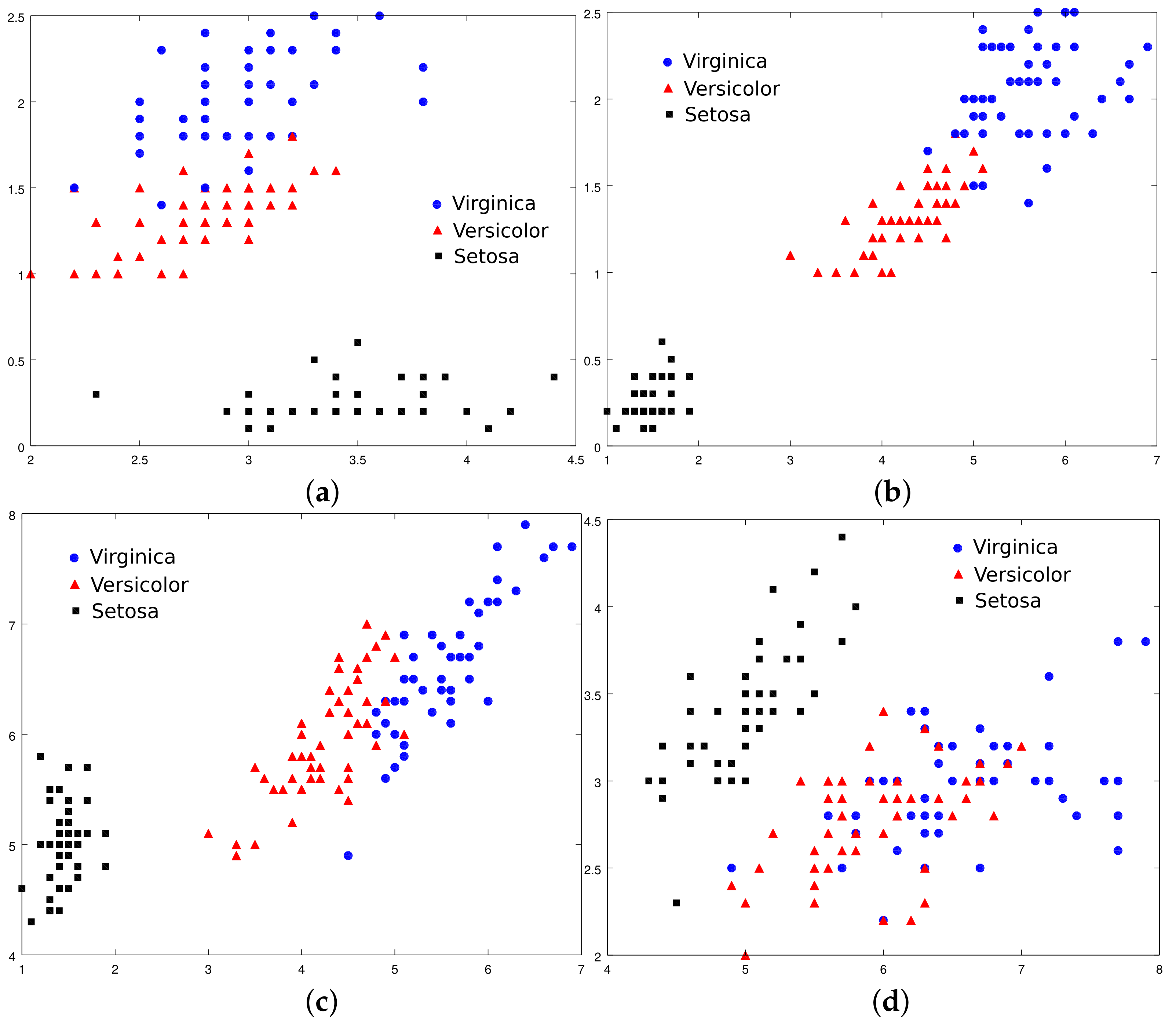
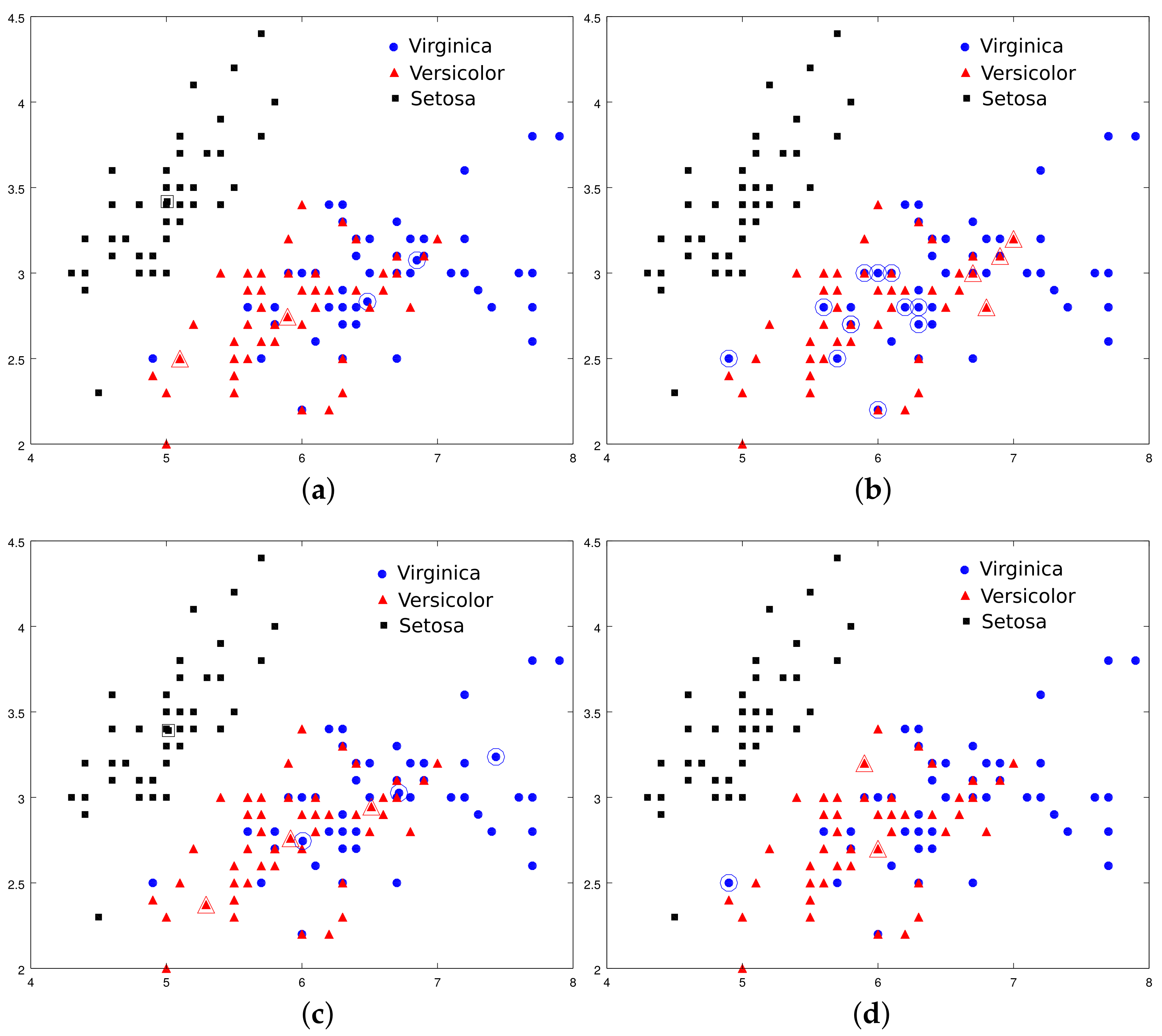
The number of layers used to form the MCLNN depends on the learning outcomes of the first layers. Indeed, if the first layers allow the correct classification of all training examples, there will be no need for additional layers and the training process of MCLNN is terminated. In the presence of misclassified objects, however, the validation step will group all these objects with those, if any, that present small membership degrees to all classes, in order to form the training data set for the next additional layer. This process is iterated until all objects are well classified or a maximum number of layers is reached. Our simulation results show that, for all the studied data examples, all objects could be well classified before reaching the fixed maximum of 20 layers (
Table 1).
A more formal description of this hybrid learning algorithm is given by the following pseudo-code:
Given a set of n training examples ;
Step 1: Construct a neural network of one competitive layer with c neurons (So far, , and );
Step 2: Initialize by a value in ;
Step 3: Initialize the step with a value in ;
Step 4: Apply FLVQ to train the layer r using the data set ; This step ends with the convergence of FLVQ;
Step 5: Adjust by ;
Step 6: For each object of the data set presented to the input of the current layer r:
Evaluate the activation function of each neuron
i (
) of the layer
r using the Equation (
11);
Evaluate the membership degrees of the object
to all clusters represented by the neurons of the layer
r, using the Equation (
10);
Find the maximum membership degree for ;
If :
- -
Evaluate the label
using the Equation (
Section 2.4);
- -
if :
- ∗
Add a new neuron to the layer r;
- ∗
Increase the size of the layer r ();
- ∗
Write the features of in the weights of the new neuron ();
else
- -
Create the set of examples if it does not exist;
- -
Add the object to the dataset ;
Increment r ();
Allocate neurons to form a new layer r;
Use the data set as training data set for the layer r;
Go to step 4;
Using the big O notation, the computational complexity of each layer L of the proposed architecture at each iteration is given by the expression O(.p.), where denotes the number of classes in the training data set of layer L, which is also the number of neurons in layer L, and is the number of elements of this data set. For the N layers of the whole network, and the total number of iterations required for convergence, t, this amounts, in the worst case, to O(t..p.n.N). Remarking that and , we can conclude that this is the same order as O(t..p.n), which is the computational complexity of the state of the art method, FLVQ.
During the exploitation phase, the label assigned to each input object
is generated by the first layer whose result is taken into account by an object
x; i.e.,:
where
q is the number of competitive layers forming MCLNN;
is the final label of the object
x generated by the proposed neural architecture.
The following pseudo-code provides a more formal description of the exploitation process:
For each object x presented to MCLNN for recognition;
If :
- -
the final label is ;
else:
- -
Increment r ();
- -
Evaluate
;
- -
If layer r is the last layer:
- ∗
;
- -
else:
- ∗
go to step 3;









{kind=link}
{kind=link}
{kind=link}
{kind=link}