
A Method to Improve the Accuracy of Pavement Crack Identification by Combining a Semantic Segmentation and Edge Detection Model


Abstract
:1. Introduction
2. Proposed Method
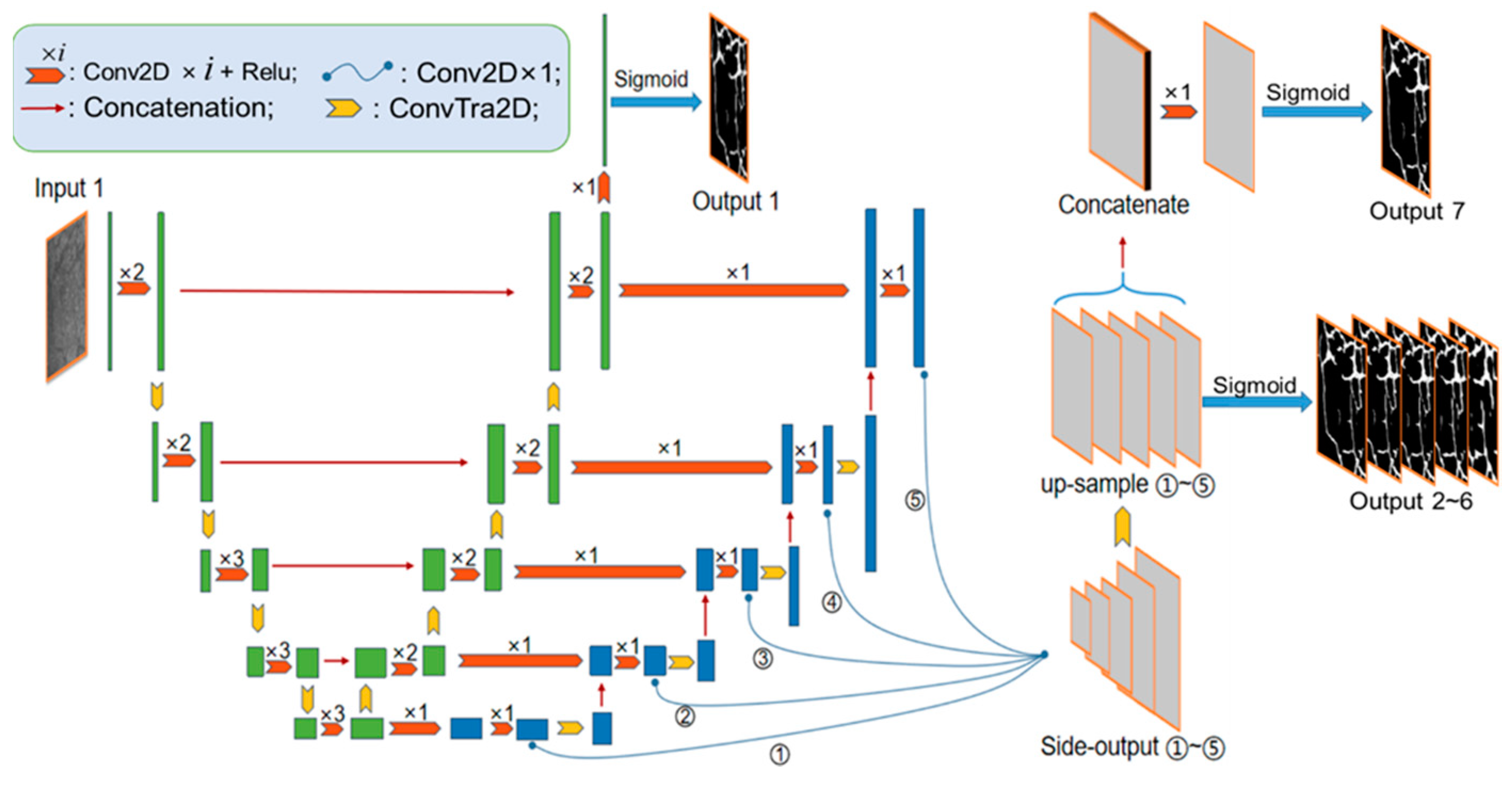
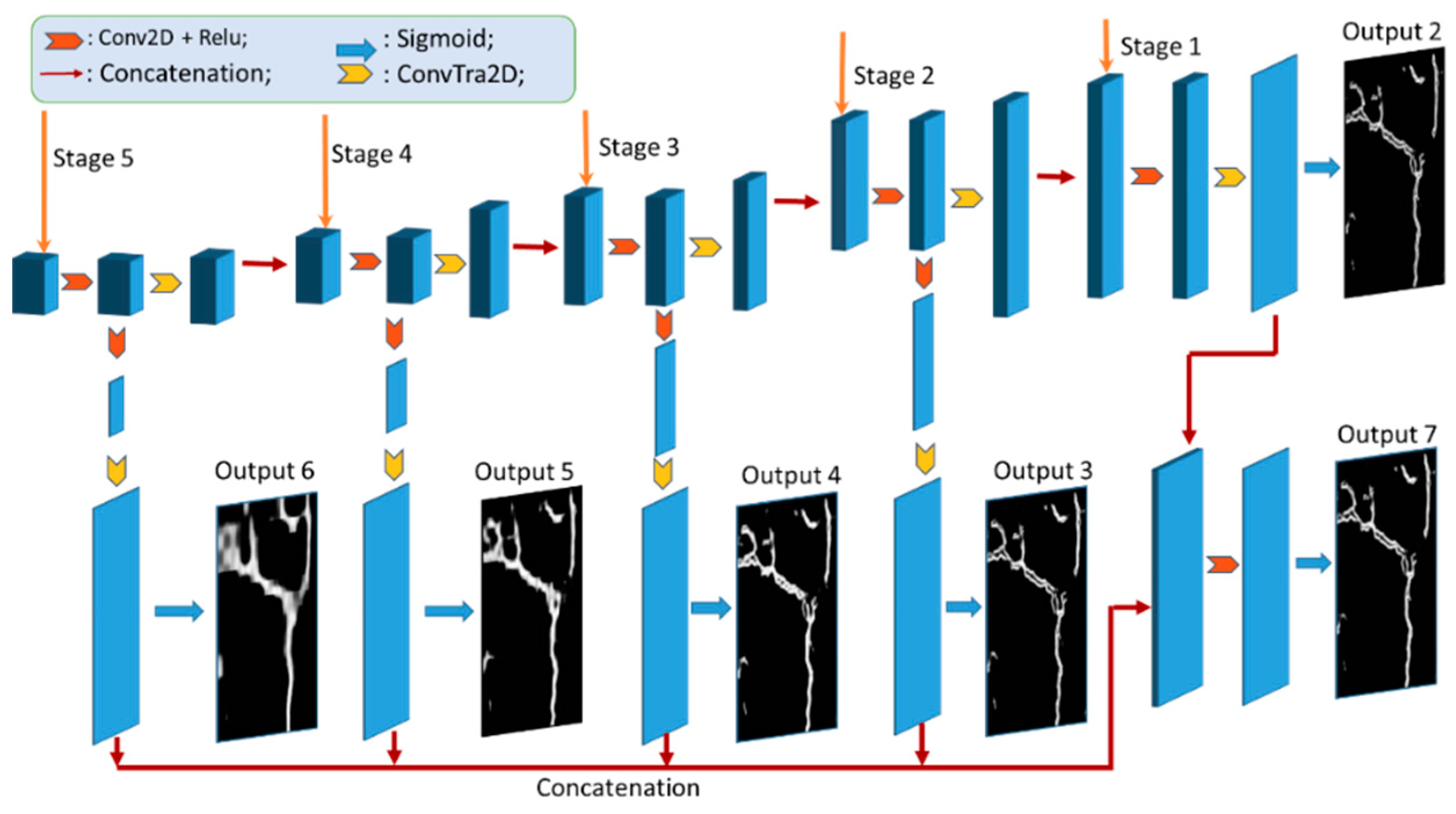
2.1. Model Architecture
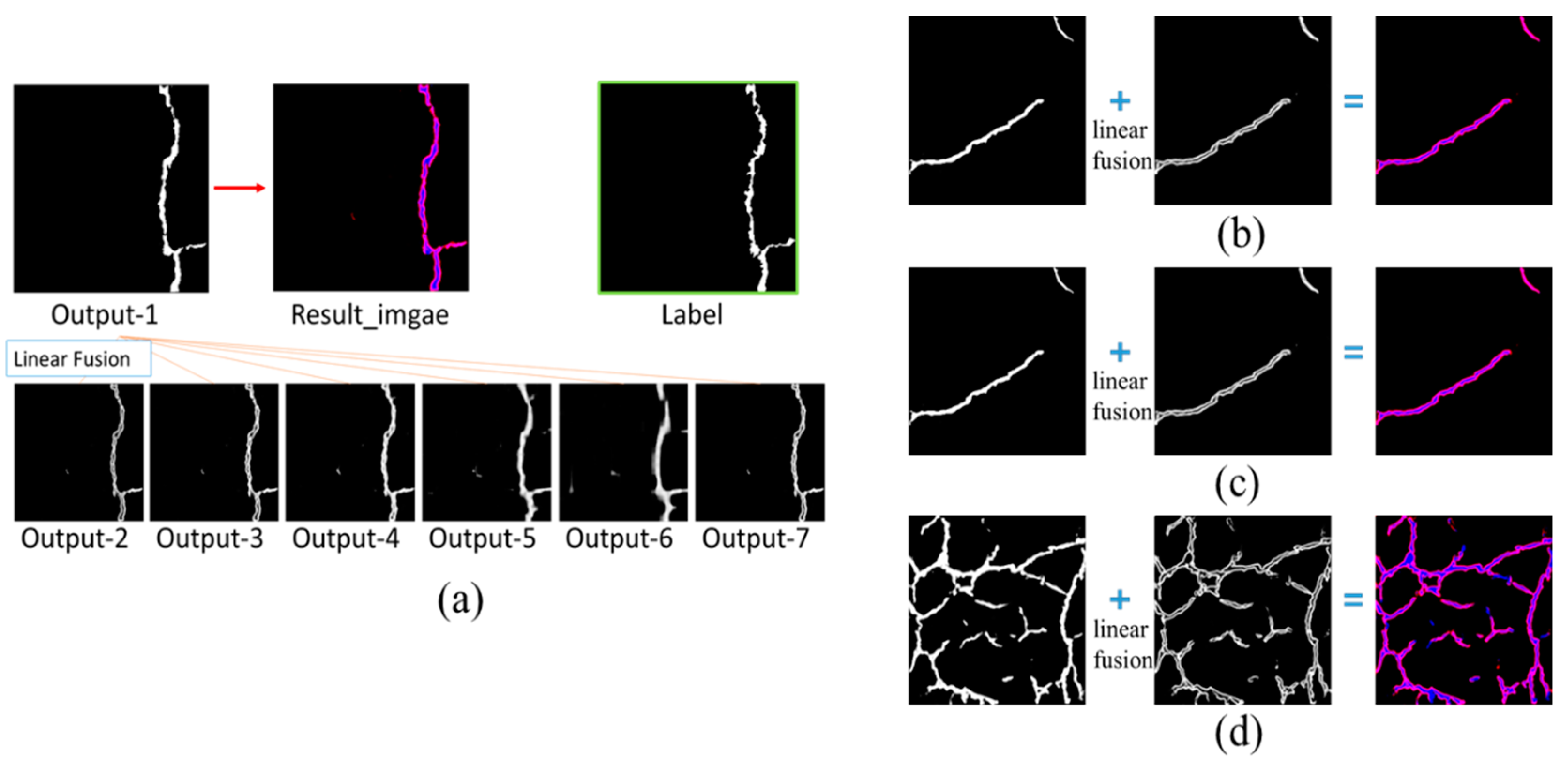
2.2. Loss Function
2.3. Metrics
3. Experiment
3.1. Image Collection
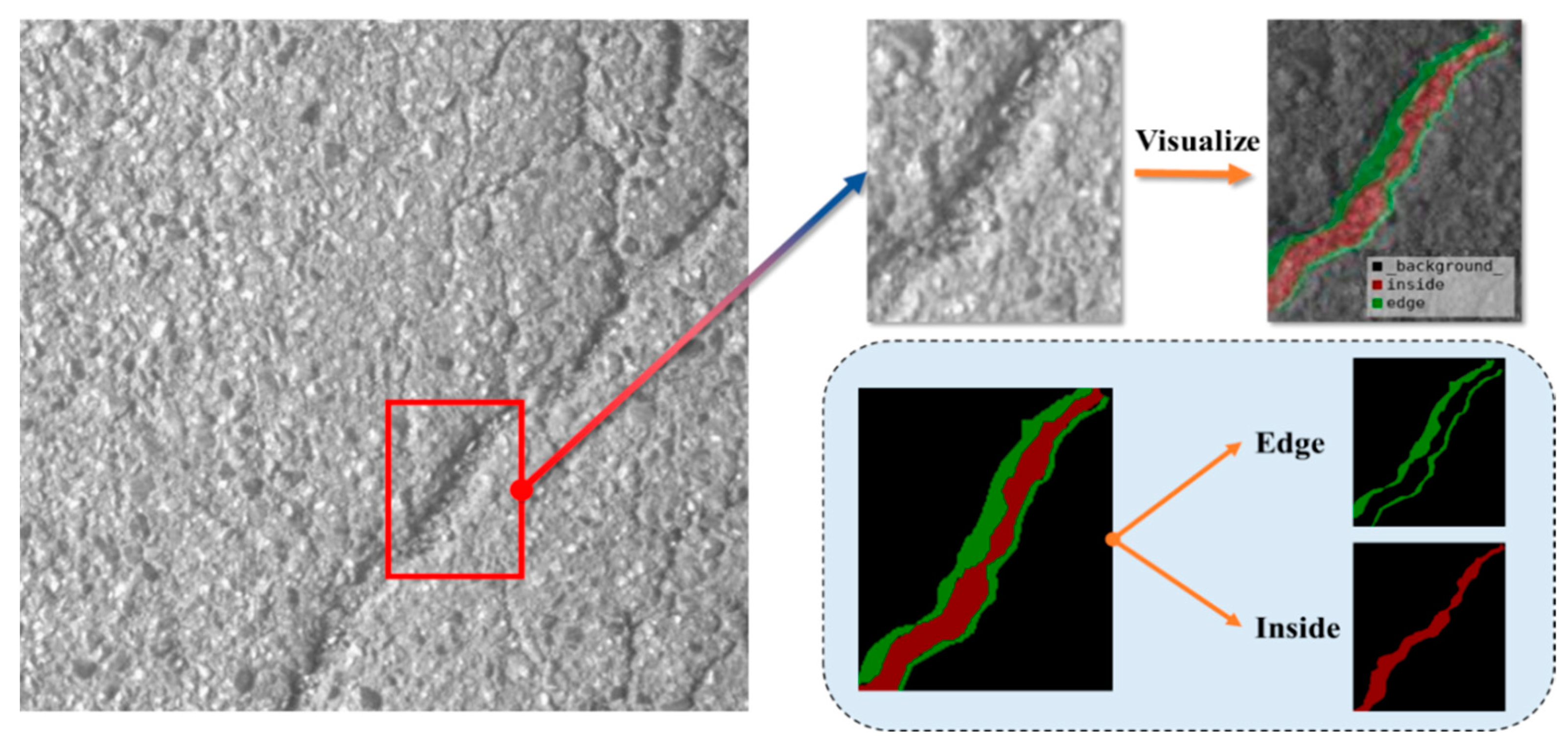
3.2. Image Dataset
3.3. Training Details
3.4. Training Process
4. Training Result and Comparison
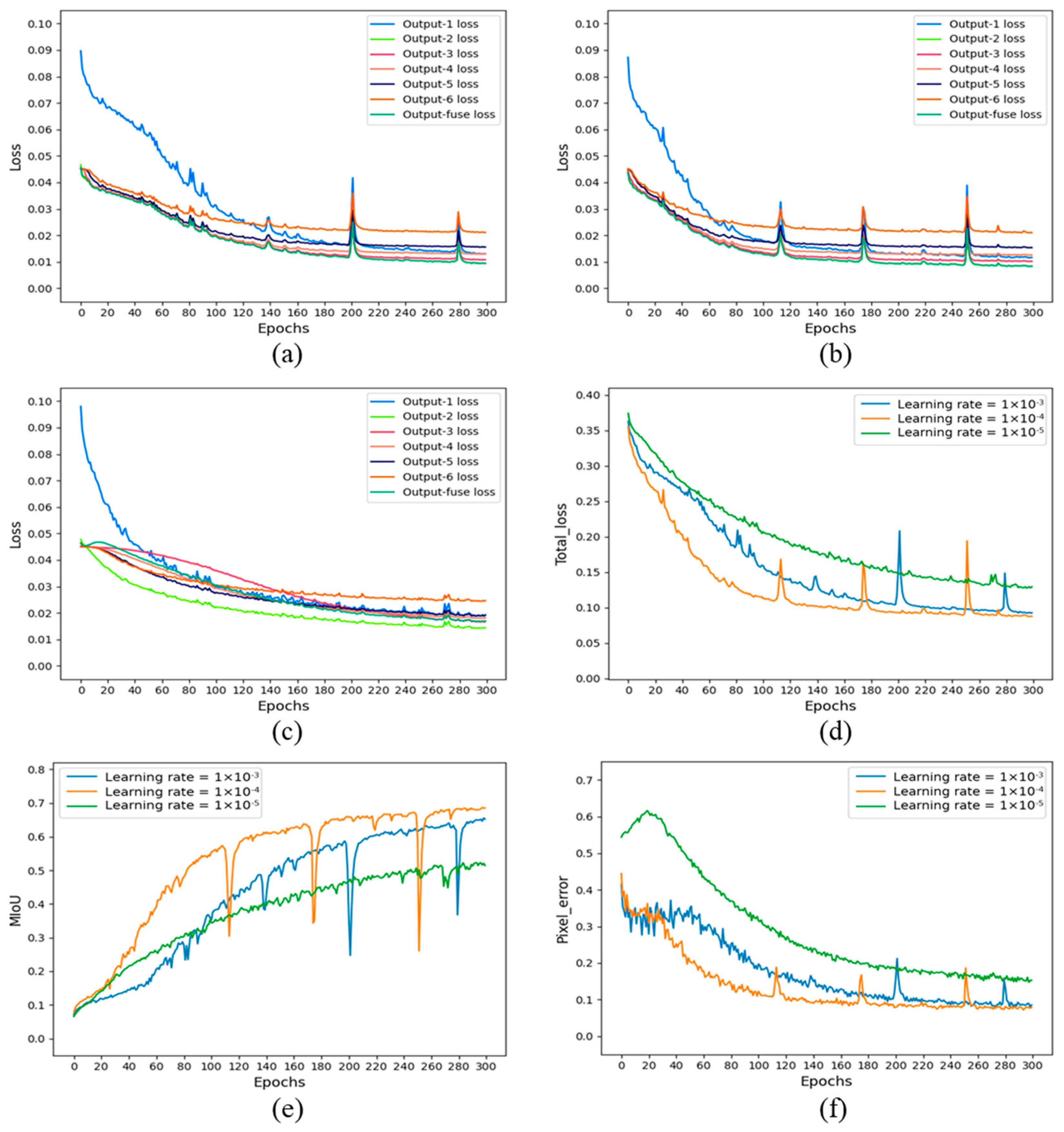
4.1. Training Result
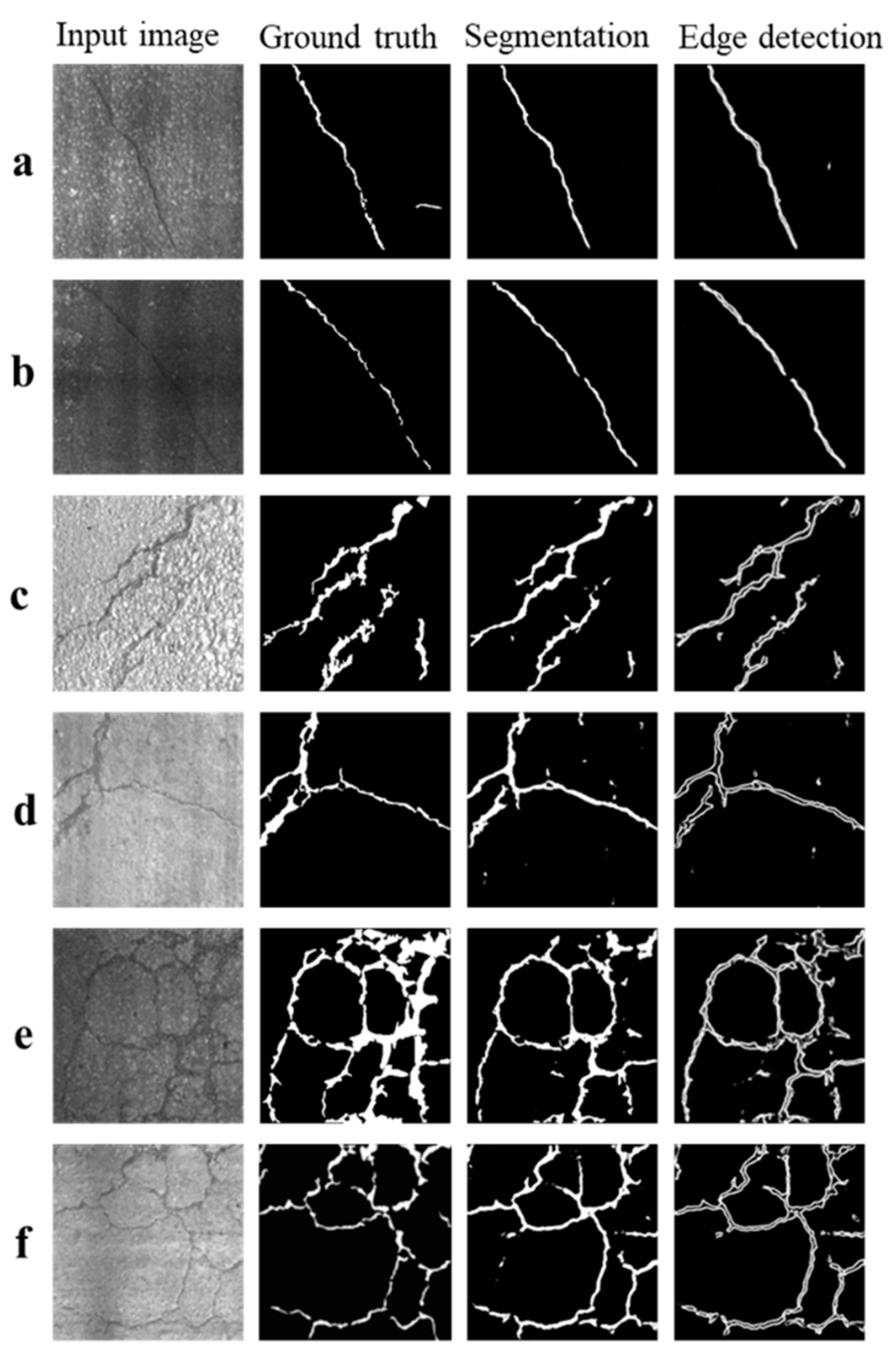
4.2. Evaluated Model
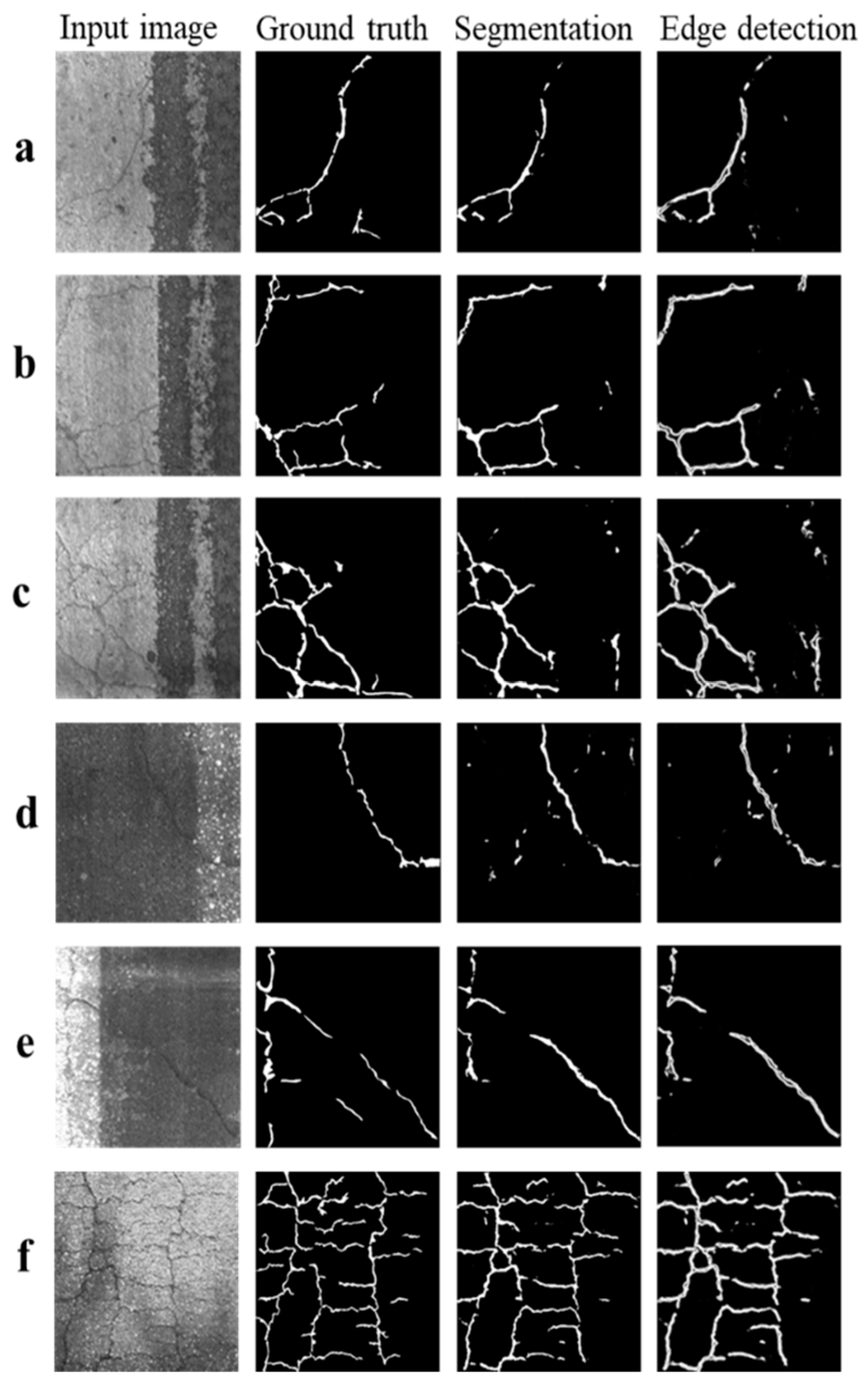
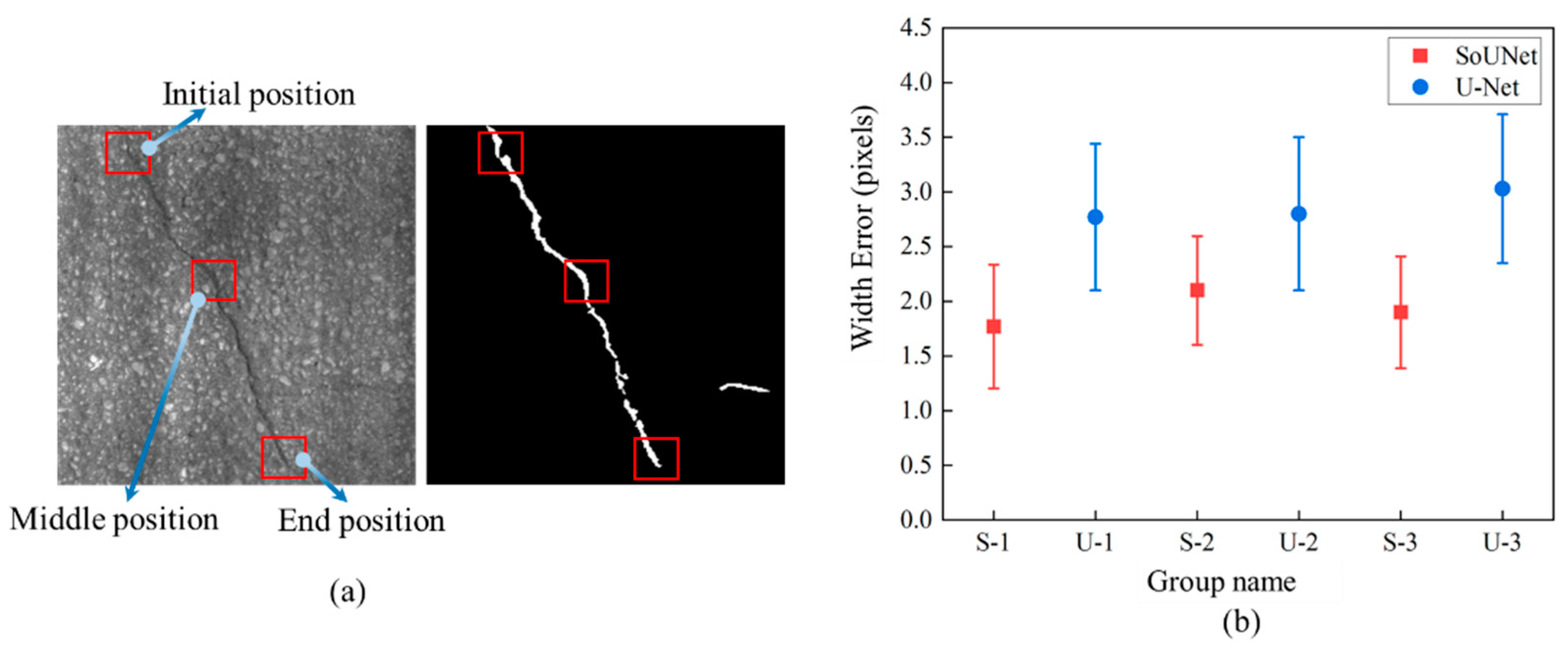
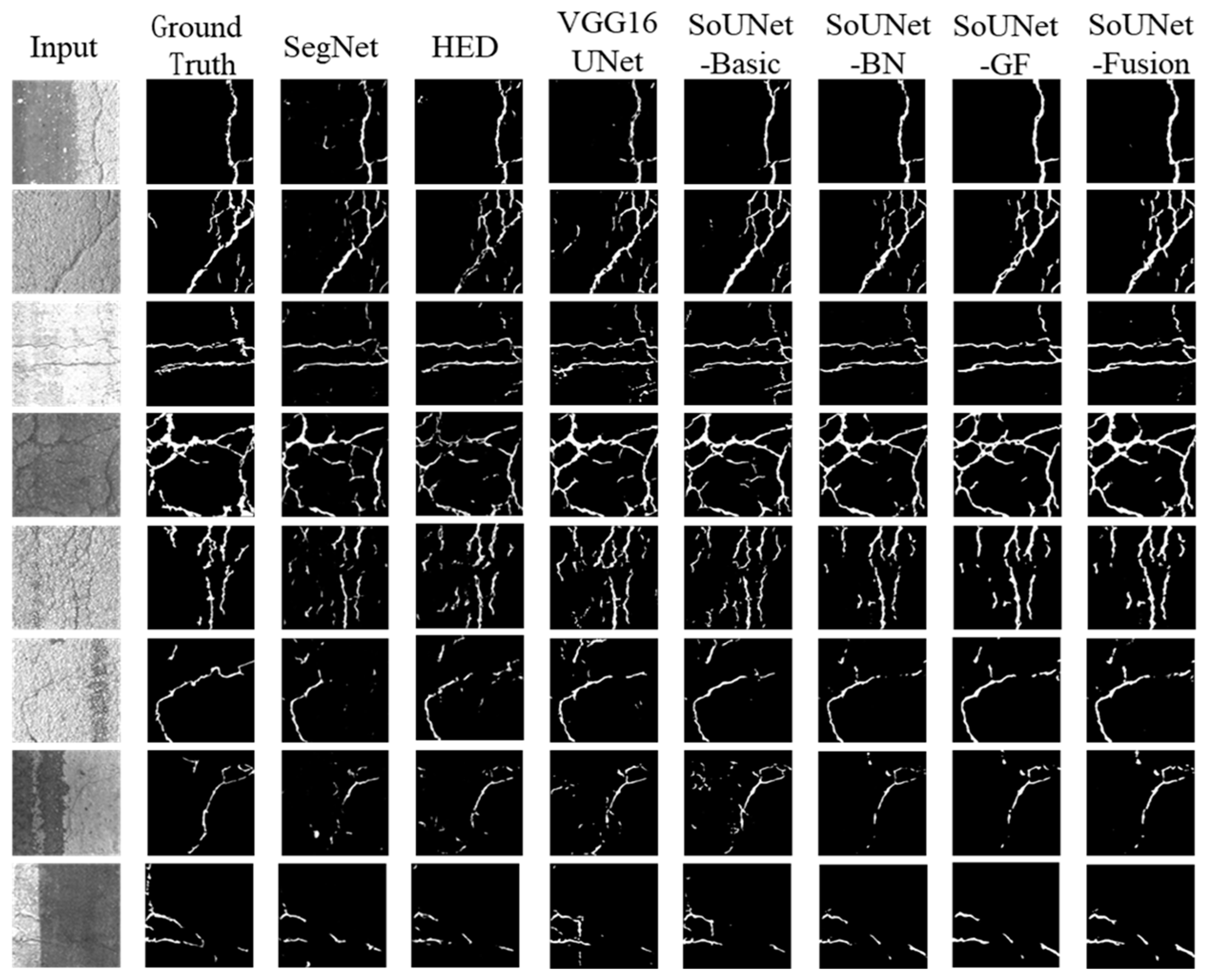
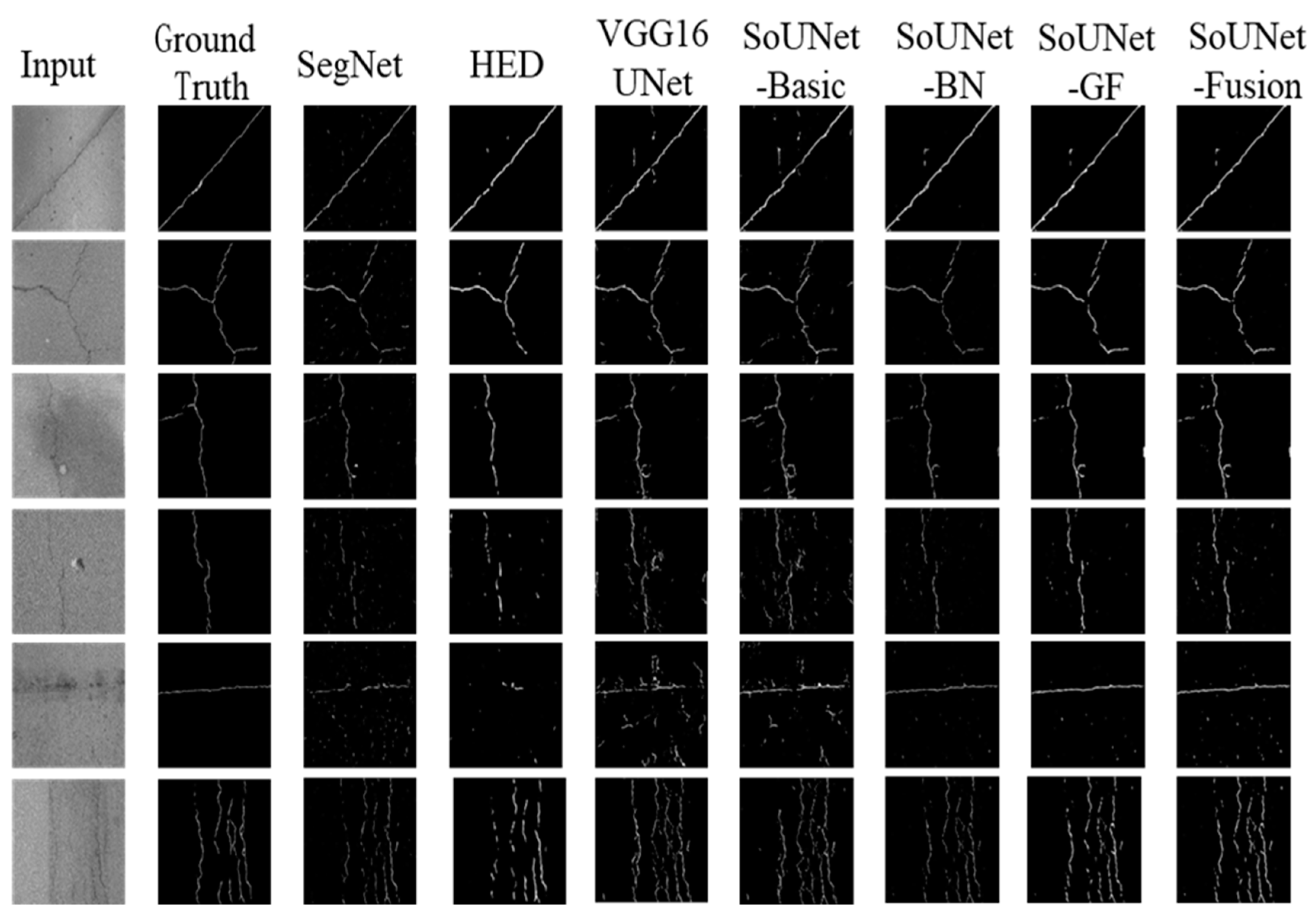
4.3. Comparative Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MIoU | Mean intersection over union |
| MPA | Mean pixel accuracy |
| ODS-F | Optimal dataset scale F-score |
| OIS-F | Optimal image scale F-score |
| CNN | Convolutional neural network |
| HED | Holistically nested edge detection network |
| SegNet | A deep convolutional encoder-decoder architecture for image segmentation |
| U-Net | U-shaped Convolutional networks for image segmentation |
| BN | Batch normalization |
| GF | Guided filter operation |
References
- Ayenu-Prah, A.; Attoh-Okine, N. Evaluating Pavement Cracks with Bidimensional Empirical Mode Decomposition. EURASIP J. Adv. Signal Process. 2008, 2008, 861701. [Google Scholar] [CrossRef] [Green Version]
- Doll, B.; Ozer, H.; Rivera-Perez, J.J.; Al-Qadi, I.L.; Lambros, J. Investigation of viscoelastic fracture fields in asphalt mixtures using digital image correlation. Int. J. Fract. 2017, 205, 37–56. [Google Scholar] [CrossRef]
- Tan, Y.Q.; Zhang, L.; Guo, M.; Shan, L. Investigation of the deformation properties of asphalt mixtures with DIC technique. Constr. Build. Mater. 2012, 37, 581–590. [Google Scholar]
- Grabowski, D.; Szczodrak, M.; Czyzewski, A. Economical methods for measuring road surface roughness. Metrol. Measurem. Syst. 2018, 25, 533–549. [Google Scholar]
- Jahanshahi, M.R.; Jazizadeh, F.; Masri, S.F.; Becerik-Gerber, B. Unsupervised Approach for Autonomous Pavement-Defect Detection and Quantification Using an Inexpensive Depth Sensor. J. Comput. Civ. Eng. 2013, 27, 743–754. [Google Scholar] [CrossRef]
- Cui, X.; Zhou, X.; Lou, J.; Zhang, J.; Ran, M. Measurement method of asphalt pavement mean texture depth based on multi-line laser and binocular vision. Int. J. Pavement Eng. 2017, 18, 459–471. [Google Scholar] [CrossRef]
- Ni, Z.; Shen, Z.; Guo, C.; Xiong, G.; Nyberg, T.; Shang, X.; Li, S.; Wang, Y. The Application of the Depth Camera in the Social Manufacturing: A review. In Proceedings of the 2016 IEEE International Conference on Service Operations and Logistics, and Informatics, Beijing, China, 10–12 July 2016; IEEE: New York, NY, USA, 2016; pp. 66–70. [Google Scholar]
- Rahkonen, J.; Jokela, H. Infrared Radiometry for Measuring Plant Leaf Temperature during Thermal Weed Control Treatment. Biosyst. Eng. 2003, 86, 257–266. [Google Scholar] [CrossRef]
- Tsai, Y.-C.J.; Li, F. Critical Assessment of Detecting Asphalt Pavement Cracks under Different Lighting and Low Intensity Contrast Conditions Using Emerging 3D Laser Technology. J. Transp. Eng. 2012, 138, 649–656. [Google Scholar] [CrossRef]
- Janowski, A.; Nagrodzka-Godycka, K.; Szulwic, J.; Ziółkowski, P. Modes of Failure Analysis in Reinforced Concrete Beam Using Laser Scanning and Synchro-Photogrammetry How to apply optical technologies in the diagnosis of reinforced concrete elements? In Proceedings of the International Conference on Advances in Civil, Structural and Environmental Engineering—ACSEE-2014, Zurich, Switzerland, 21–22 September 2014. [Google Scholar]
- Lu, C.; Yu, J.; Leung, C.K.Y. An improved image processing method for assessing multiple cracking development in Strain Hardening Cementitious Composites (SHCC). Cem. Concr. Compos. 2016, 74, 191–200. [Google Scholar] [CrossRef]
- Peng, C.; Yang, M.; Zheng, Q.; Zhang, J.; Wang, D.; Yan, R.; Wang, J.; Li, B. A triple-thresholds pavement crack detection method leveraging random structured forest. Constr. Build. Mater. 2020, 263, 120080. [Google Scholar] [CrossRef]
- Mardasi, A.G.; Wu, N.; Wu, C. Experimental study on the crack detection with optimized spatial wavelet analysis and windowing. Mech. Syst. Signal Process. 2018, 104, 619–630. [Google Scholar] [CrossRef]
- Lakshmi, K. Detection and quantification of damage in bridges using a hybrid algorithm with spatial filters under environmental and operational variability. Structures 2021, 32, 617–631. [Google Scholar] [CrossRef]
- Liebold, F.; Maas, H.-G. Advanced spatio-temporal filtering techniques for photogrammetric image sequence analysis in civil engineering material testing. ISPRS J. Photogramm. Remote Sens. 2016, 111, 13–21. [Google Scholar] [CrossRef]
- Li, Q.; Zou, Q.; Zhang, D.; Mao, Q. FoSA: F* Seed-growing Approach for crack-line detection from pavement images. Image Vis. Comput. 2011, 29, 861–872. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 640–651. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef] [Green Version]
- Nhat-Duc, H.; Nguyen, Q.; Tran, V. Automatic recognition of asphalt pavement cracks using metaheuristic optimized edge detection algorithms and convolution neural network. Autom. Constr. 2018, 94, 203–213. [Google Scholar] [CrossRef]
- Hamed, M.; Peng, J.; Yaw, A.; William, B. Pavement Image Datasets: A New Benchmark Dataset to Classify and Densify Pavement Distresses. Transp. Res. Rec. J. Transp. Res. Board 2020, 2674, 328–339. [Google Scholar] [CrossRef] [Green Version]
- Ji, A.; Xue, X.; Wang, Y.; Luo, X.; Xue, W. An integrated approach to automatic pixel-level crack detection and quantification of asphalt pavement. Autom. Constr. 2020, 114, 103176. [Google Scholar] [CrossRef]
- Park, S.; Bang, S.; Kim, H.; Kim, H. Patch-Based Crack Detection in Black Box Images Using Convolutional Neural Networks. J. Comput. Civ. Eng. 2019, 33, 04019017. [Google Scholar] [CrossRef]
- Flah, M.; Suleiman, A.R.; Nehdi, M.L. Classification and quantification of cracks in concrete structures using deep learning image-based techniques. Cem. Concr. Compos. 2020, 114, 103781. [Google Scholar] [CrossRef]
- Pratt, L.; Govender, D.; Klein, R. Defect detection and quantification in electroluminescence images of solar PV modules using U-net semantic segmentation. Renew. Energy 2021, 178, 1211–1222. [Google Scholar] [CrossRef]
- Lin, D.; Li, Y.; Prasad, S.; Nwe, T.L.; Dong, S.; Oo, Z.M. CAM-guided Multi-Path Decoding U-Net with Triplet Feature Regularization for Defect Detection and Segmentation. Knowl. Based Syst. 2021, 228, 107272. [Google Scholar] [CrossRef]
- Rong-qiang, L.; Ming-hui, L.; Jia-chen, S.; Yi-bin, L. Fabric Defect Detection Method Based on Improved U-Net. J. Phys. Conf. Ser. 2021, 1948, 012160. [Google Scholar] [CrossRef]
- Zhong, Q.; Zhang, J.; Xu, Y.; Li, M.; Shen, B.; Tao, W.; Li, Q. Filamentous target segmentation of weft micro-CT image based on U-Net. Micron 2021, 146, 102923. [Google Scholar] [CrossRef]
- Deriche, R. Using Canny’s criteria to derive a recursively implemented optimal edge detector. Int. J. Comput. Vis. 1987, 1, 167–187. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J.Y.; Liu, J.X.; Zhang, Y.; Chen, Z.P.; Li, C.G.; He, K.; Yan, R.B. Research on Crack Detection Algorithm of the Concrete Bridge Based on Image Processing. Procedia Comput. Sci. 2019, 154, 610–616. [Google Scholar] [CrossRef]
- Qiang, S.; Guoying, L.; Jingqi, M.; Hongmei, Z. An Edge-Detection Method Based on Adaptive Canny Algorithm and Iterative Segmentation Threshold. In Proceedings of the 2016 2nd International Conference on Control Science and Systems Engineering, Singapore, 27–29 July 2016; pp. 64–67. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. Int. J. Comput. Vis. 2017, 125, 3–18. [Google Scholar] [CrossRef]
- Wei, K.; Jie, C.; Jianbin, J.; Guoying, Z.; Qixiang, Y. SRN: Side-Output Residual Network for Object Reflection Symmetry Detection and Beyond. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1881–1895. [Google Scholar]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Konrad, H.; Lichao, M.; Celia, B.; Andreas, D.; Xiang, Z. HED-UNet: Combined Segmentation and Edge Detection for Monitoring the Antarctic Coastline. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4300514. [Google Scholar] [CrossRef]
- Sergey, L.; Christian, S. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Cai, Z.; Zhao, X.; Chen, C.; Liang, X.; Zou, T.; Wang, P. Pavement crack detection and recognition using the architecture of segNet. J. Ind. Inf. Integr. 2020, 18, 100144. [Google Scholar] [CrossRef]
- Wen, Z.; Wang, H.; Yuan, H.; Liu, M.; Guo, X. A method of pulmonary embolism segmentation from CTPA images based on U-net. In Proceedings of the 2019 IEEE 2nd International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 16–18 August 2019; pp. 31–35. [Google Scholar] [CrossRef]
- Li, D.; Duan, Z.; Hu, X.; Zhang, D. Pixel-Level Recognition of Pavement Distresses Based on U-Net. Adv. Mater. Sci. Eng. 2021, 2021, 5586615. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Wada, K. LabelMe. Github. 2019. Available online: https://github.com/wkentaro (accessed on 15 March 2021).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chambon, S.; Moliard, J. Automatic Road Pavement Assessment with Image Processing: Review and Comparison. Int. J. Geophys. 2011, 2011, 989354. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantity | Crack Pixels (%) | Non-Crack Pixels (%) | |
|---|---|---|---|
| Training data | 420 | 6.79 | 93.21 |
| Validation data | 120 | 4.14 | 95.86 |
| Test data | 60 | 6.52 | 93.48 |
| Pavement | Environment | ||||||
|---|---|---|---|---|---|---|---|
| Types | Concrete | Asphalt | Normal Brightness | Low Brightness | High Brightness | Shadow | Water Stain |
| Percentage (%) | 21.6 | 78.4 | 81.8 | 13.0 | 5.2 | 9.2 | 20.7 |
| Methods | Metrics | |||
|---|---|---|---|---|
| MIoU | MPA | ODS-F | OIS-F | |
| SoUNet-Output-1 | 67.17 | 72.31 | — | — |
| SoUNet-Fusion-12 | 69.64 | 78.25 | 31.52 | 32.99 |
| SoUNet-Fusion-13 | 69.32 | 80.33 | 33.14 | 34.11 |
| SoUNet-Fusion-14 | 68.29 | 81.54 | 32.08 | 33.15 |
| SoUNet-Fusion-15 | 65.92 | 81.89 | 29.46 | 30.63 |
| SoUNet-Fusion-16 | 60.39 | 81.51 | 25.66 | 26.73 |
| SoUNet-Fusion-17 | 69.42 | 80.14 | 33.08 | 34.08 |
| Datasets | Our Test Datasets | FISSURES Datasets | ||
|---|---|---|---|---|
| Metrics | MIoU | MPA | MioU | MPA |
| SegNet | 63.77 | 69.92 | 56.34 | 60.65 |
| HED | 64.56 | 70.70 | 58.30 | 65.86 |
| VGG16-U-Net | 66.99 | 74.57 | 59.12 | 67.66 |
| SoUNet-Basic | 67.46 | 75.59 | 59.15 | 68.45 |
| SoUNet-BN | 68.46 | 74.65 | 60.07 | 65.56 |
| SoUNet-GF | 68.41 | 77.28 | 61.04 | 67.81 |
| SoUNet-Fusion | 69.32 | 80.33 | 61.05 | 68.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Xia, H.; Zhou, B.; Yan, F.; Guo, R. A Method to Improve the Accuracy of Pavement Crack Identification by Combining a Semantic Segmentation and Edge Detection Model. Appl. Sci. 2022, 12, 4714. https://doi.org/10.3390/app12094714
Li P, Xia H, Zhou B, Yan F, Guo R. A Method to Improve the Accuracy of Pavement Crack Identification by Combining a Semantic Segmentation and Edge Detection Model. Applied Sciences. 2022; 12(9):4714. https://doi.org/10.3390/app12094714
Chicago/Turabian StyleLi, Peigen, Haiting Xia, Bin Zhou, Feng Yan, and Rongxin Guo. 2022. "A Method to Improve the Accuracy of Pavement Crack Identification by Combining a Semantic Segmentation and Edge Detection Model" Applied Sciences 12, no. 9: 4714. https://doi.org/10.3390/app12094714