
Driving Fatigue Detection Based on the Combination of Multi-Branch 3D-CNN and Attention Mechanism


Abstract
:Featured Application
Abstract
1. Introduction
- In this study, 3D convolution and attention mechanism modules are used to extract features in both temporal and spatial dimensions and to recalibrate the fatigue features to improve the accuracy and robustness of the model.
- In this study, we conducted multiple sets of experiments on 3D-SE-Net to evaluate the detection effect of the model, including: comparative experiments with and without attention mechanism, comparative experiments for three-branch and double-branch networks, comparison experiments for different hyperparameters, comparison experiments for with and without frame aggregation strategy and comparison experiments for the proposed model with the state-of-the-art model on the same dataset.
- In this study, a dataset was collected in a real driving environment with a rich set of driving scenarios including day and night, with and without glasses and male and female, which can be used for subsequent in-depth studies on fatigue driving detection. In addition, an auxiliary software is proposed to record the changes of drivers’ facial features in real time while protecting their facial privacy.
2. Related Works
2.1. Detection Based on Driver‘s Physiological Characteristics
2.2. Detection Based on Vehicle Behavior Characteristics
2.3. Detection Based on Driver’s Facial Features
3. Materials and Methods
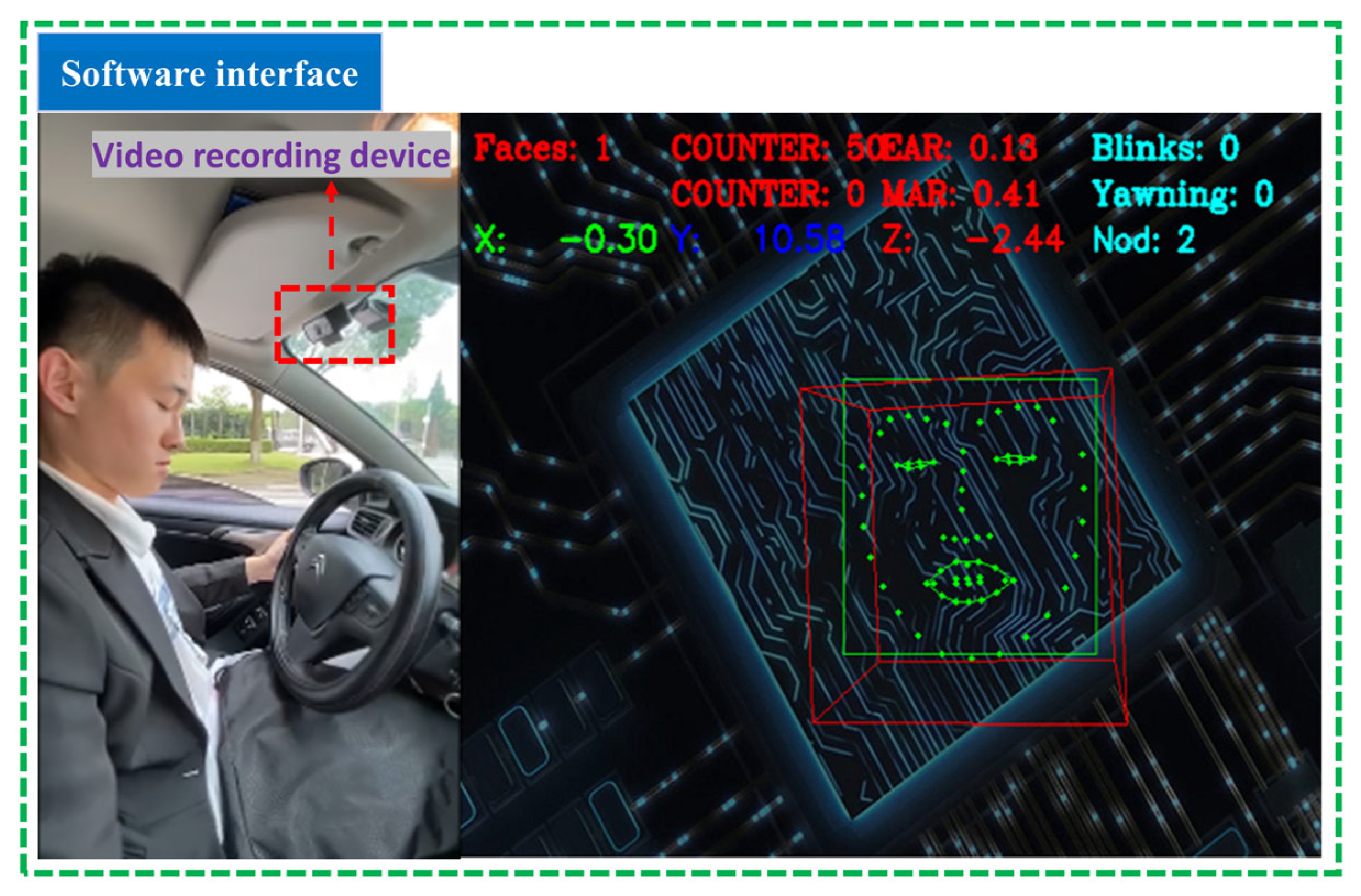
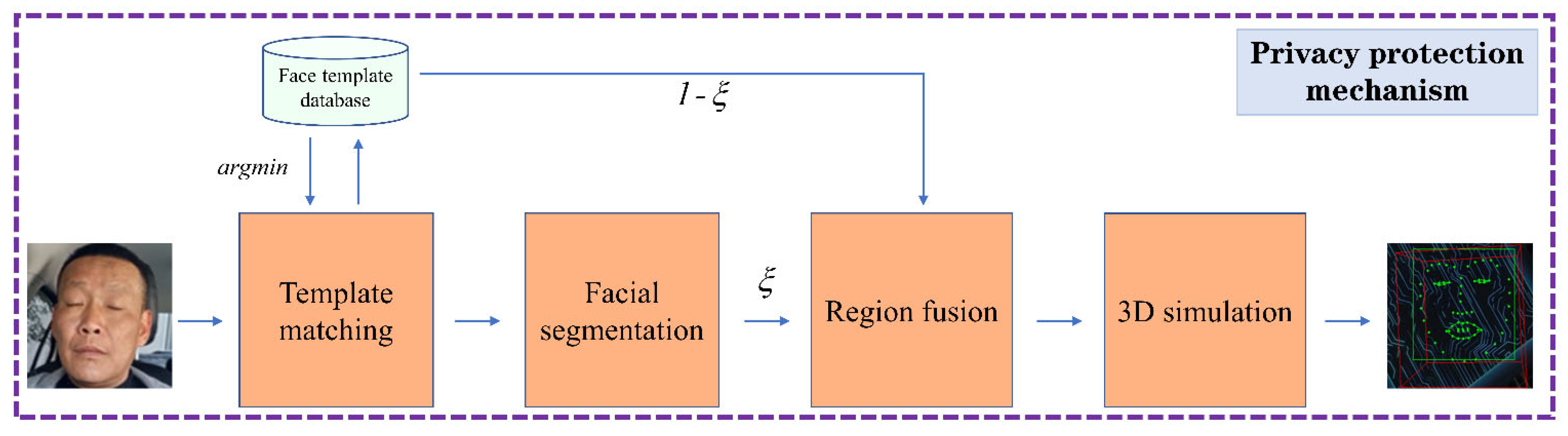
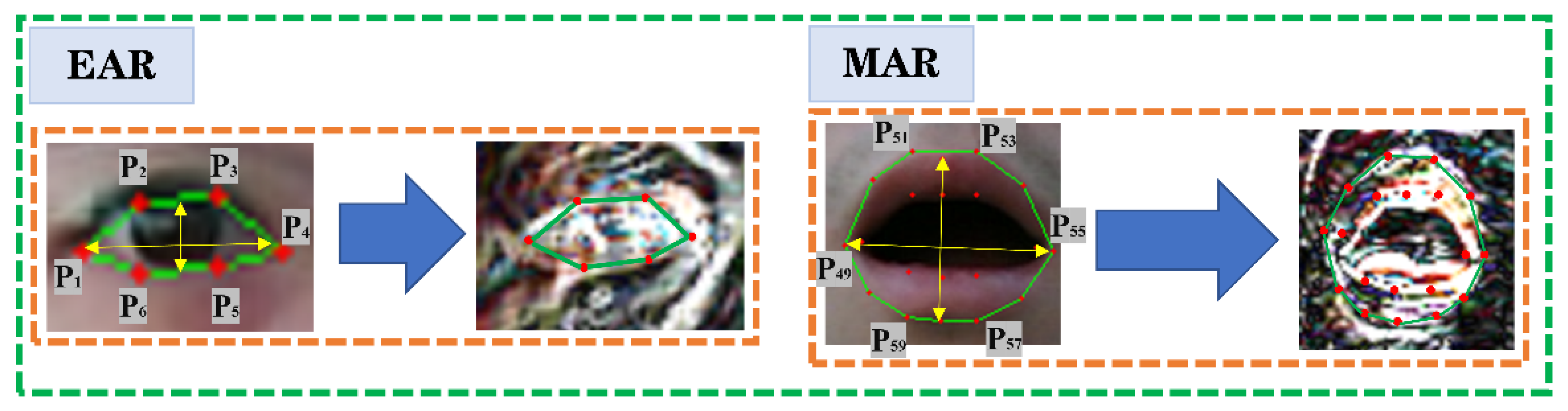
3.1. Face Tracking and Privacy Protection Processing
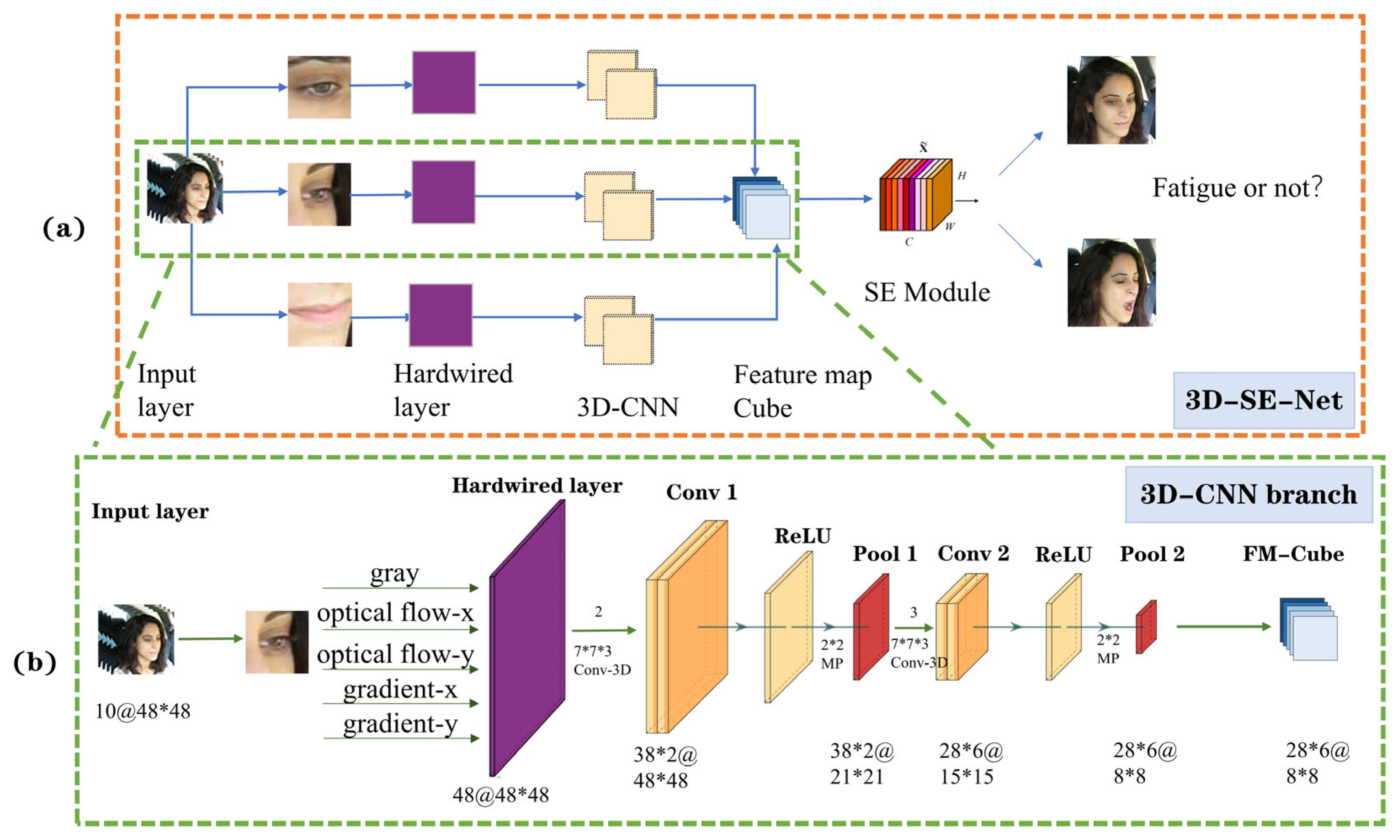
3.2. 3D-CNN Module
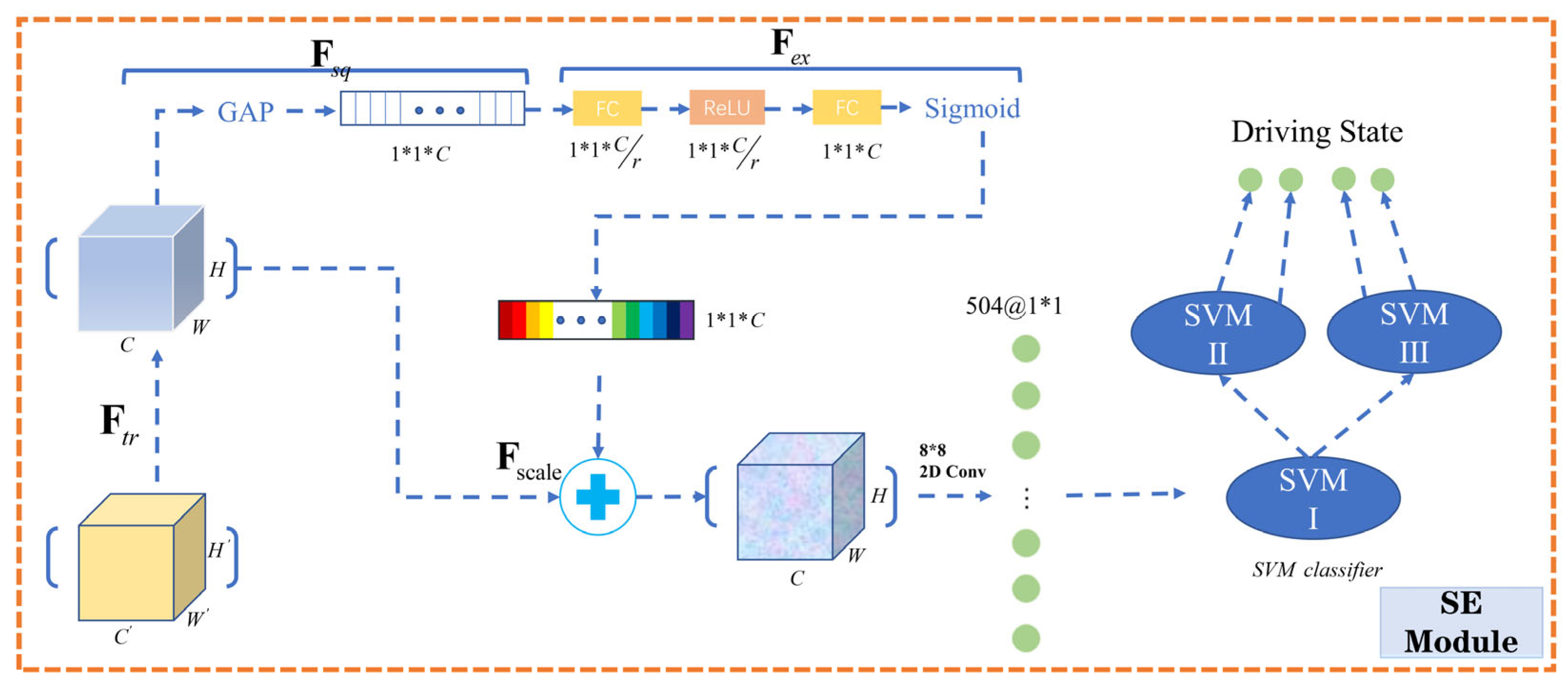
3.3. Squeeze-and-Excitation Module
3.3.1. Transformation and Squeeze Operation
3.3.2. Excitation and Scale Operation
3.3.3. Driver Behavior Analysis
4. Experiments and Result Analysis
4.1. Implementation Details
4.2. Dataset
4.3. Performance of 3D-SE-Net versus Other Network
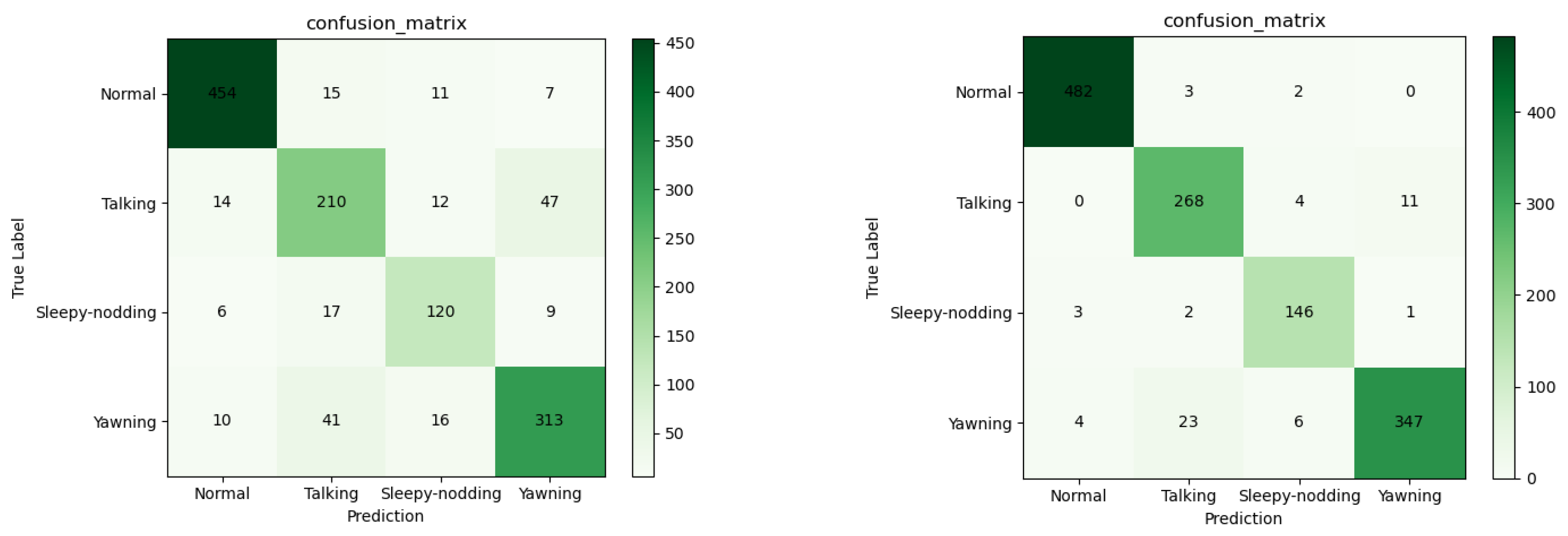
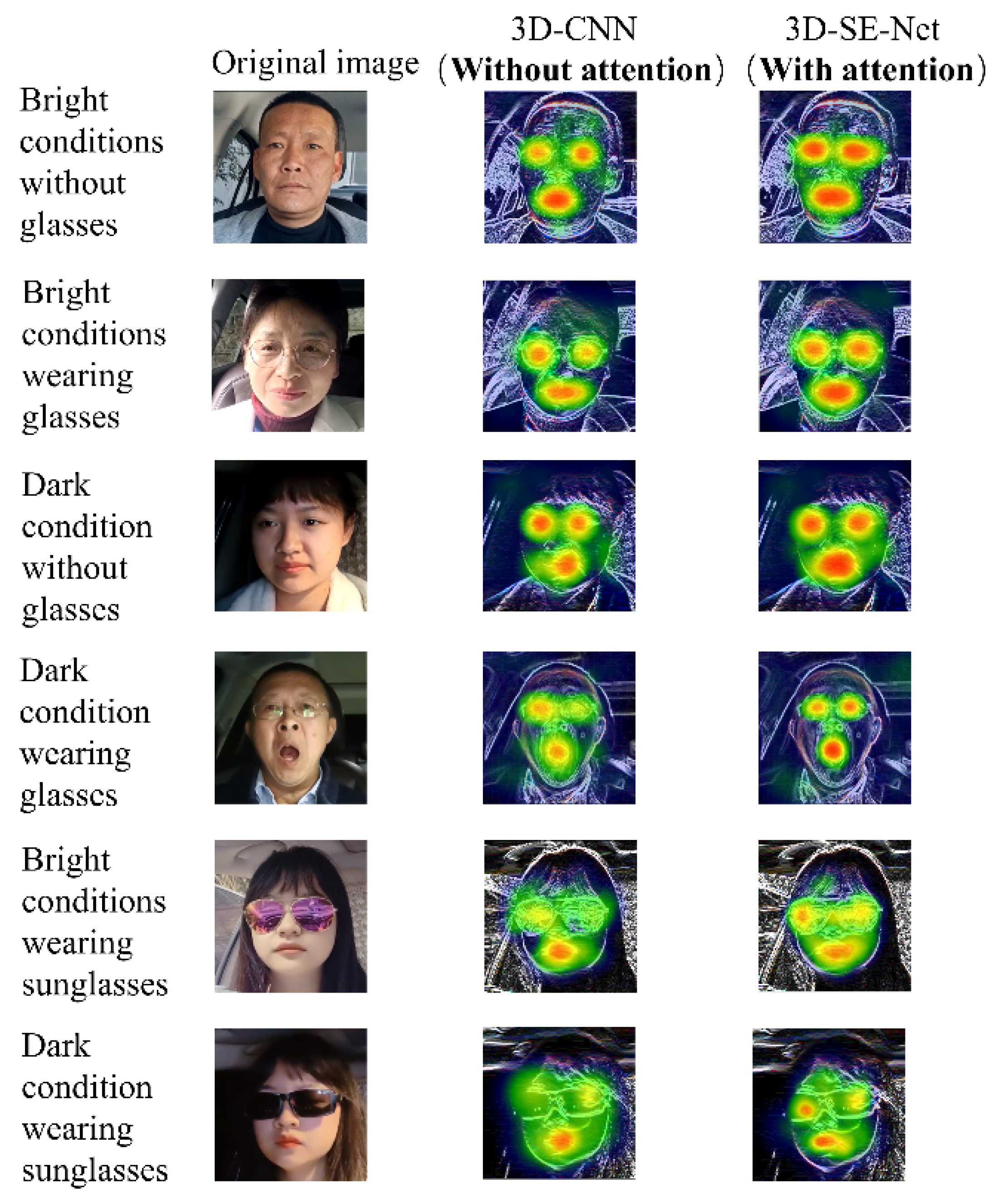
4.4. Evaluation of the Impact of the Attention Mechanism on the Model
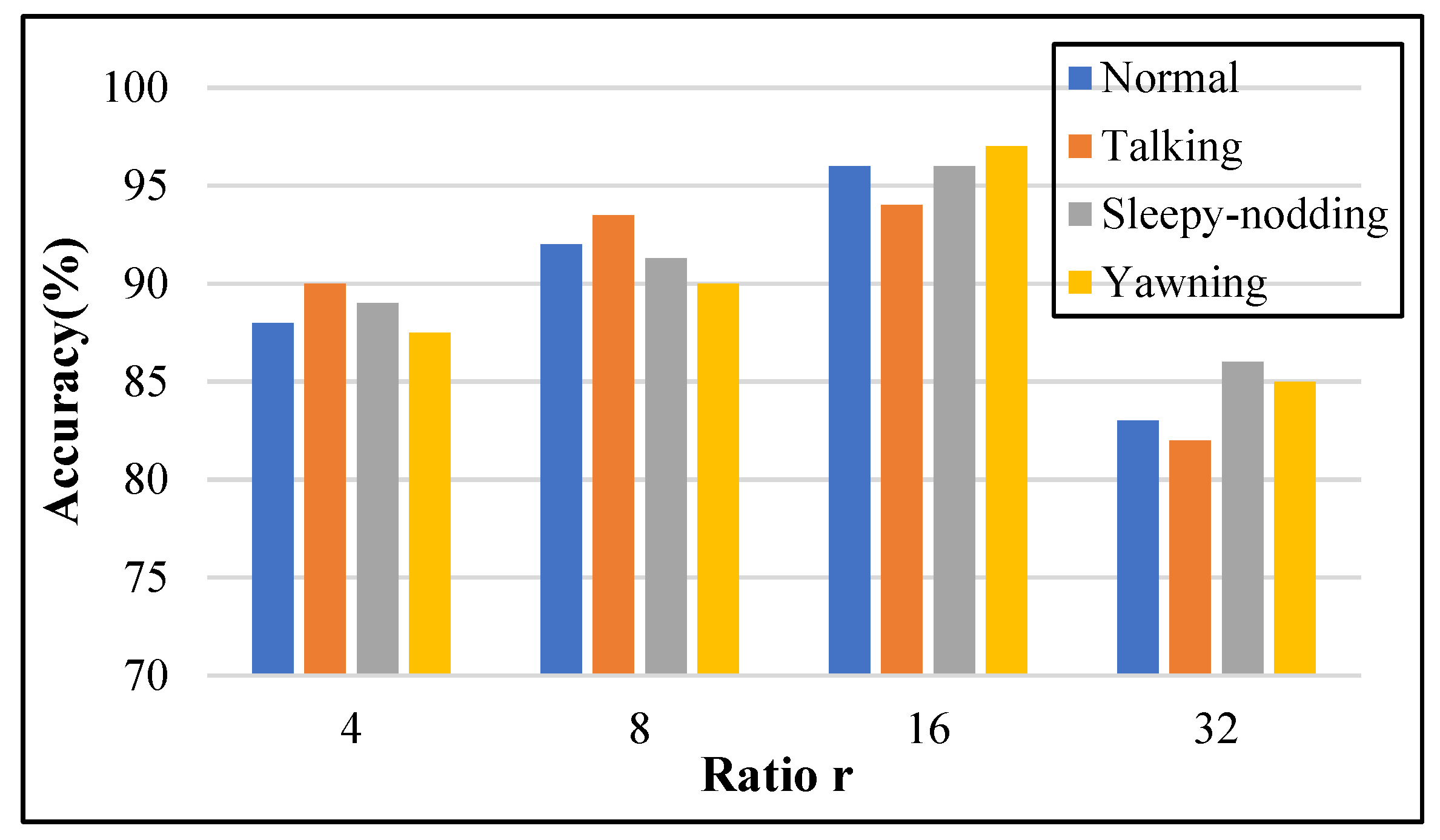
4.5. Evaluation of the Impact of Different Hyperparameter r Values on the Model Accuracy
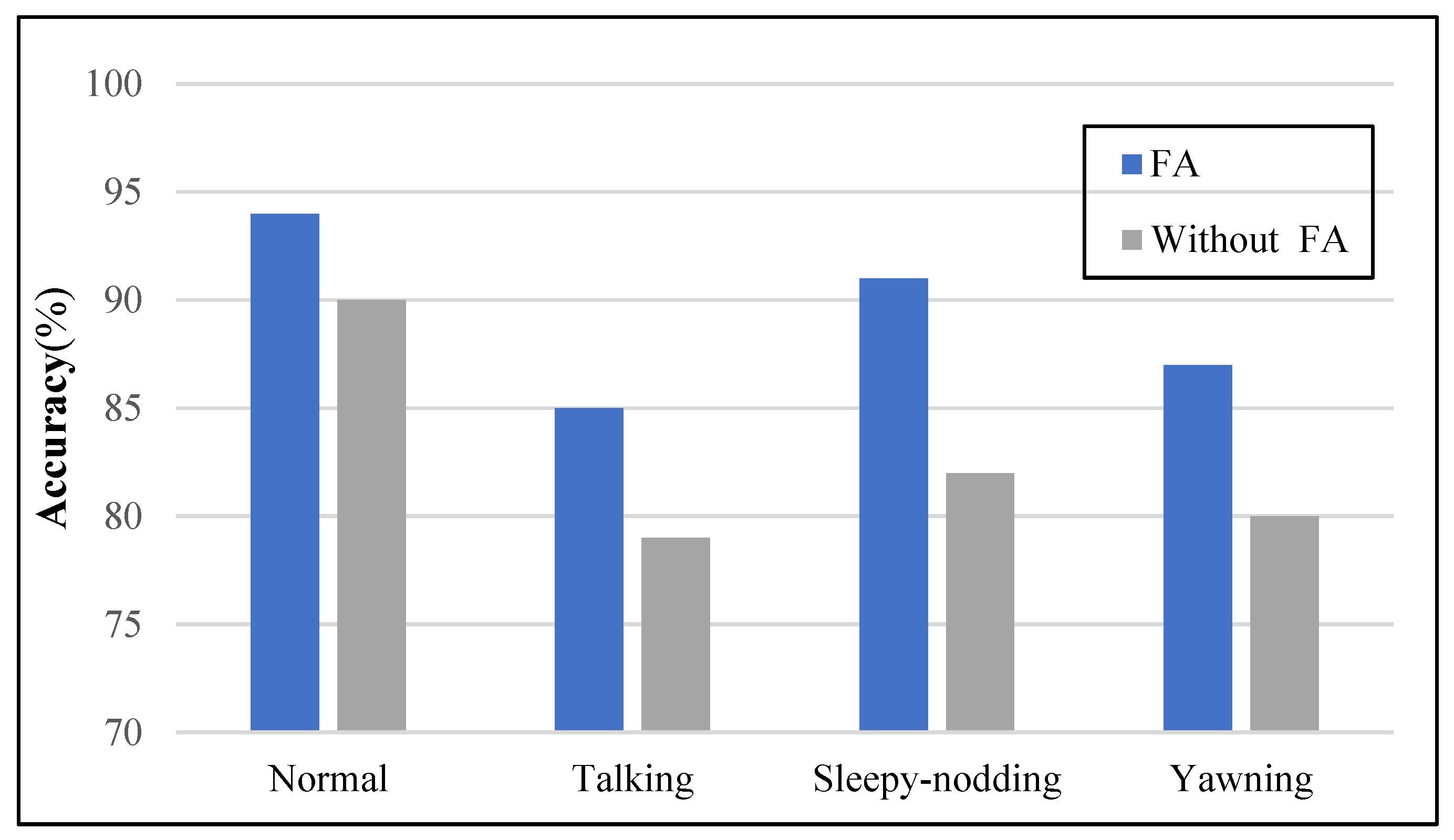
4.6. Evaluating the Impact of Frame Aggregation Strategy on Model Accuracy
4.7. Comparison of the Proposed Method and State-of-the-Art Methods
5. Discussion
- (1)
- From the perspective of data format: The flaw of the 3D network lies in the problem of memory occupation, which makes it impossible to use the entire 3D image layer as input and must be cropped and cut into a series of 3D patches as input. The cropped blocks will limit the maximum receptive field that the network can achieve, resulting in the loss of certain global information. If the target to be segmented is itself much larger than the cropped blocks, it is difficult for the network to learn the overall structural information of the target. For this problem, we adopt the scheme of hardwired layer to introduce the information of five channels of grayscale, optical flow and gradient into the network, which encodes the prior knowledge of feature information and increases the richness of input information to reduce the impact of this information loss.
- (2)
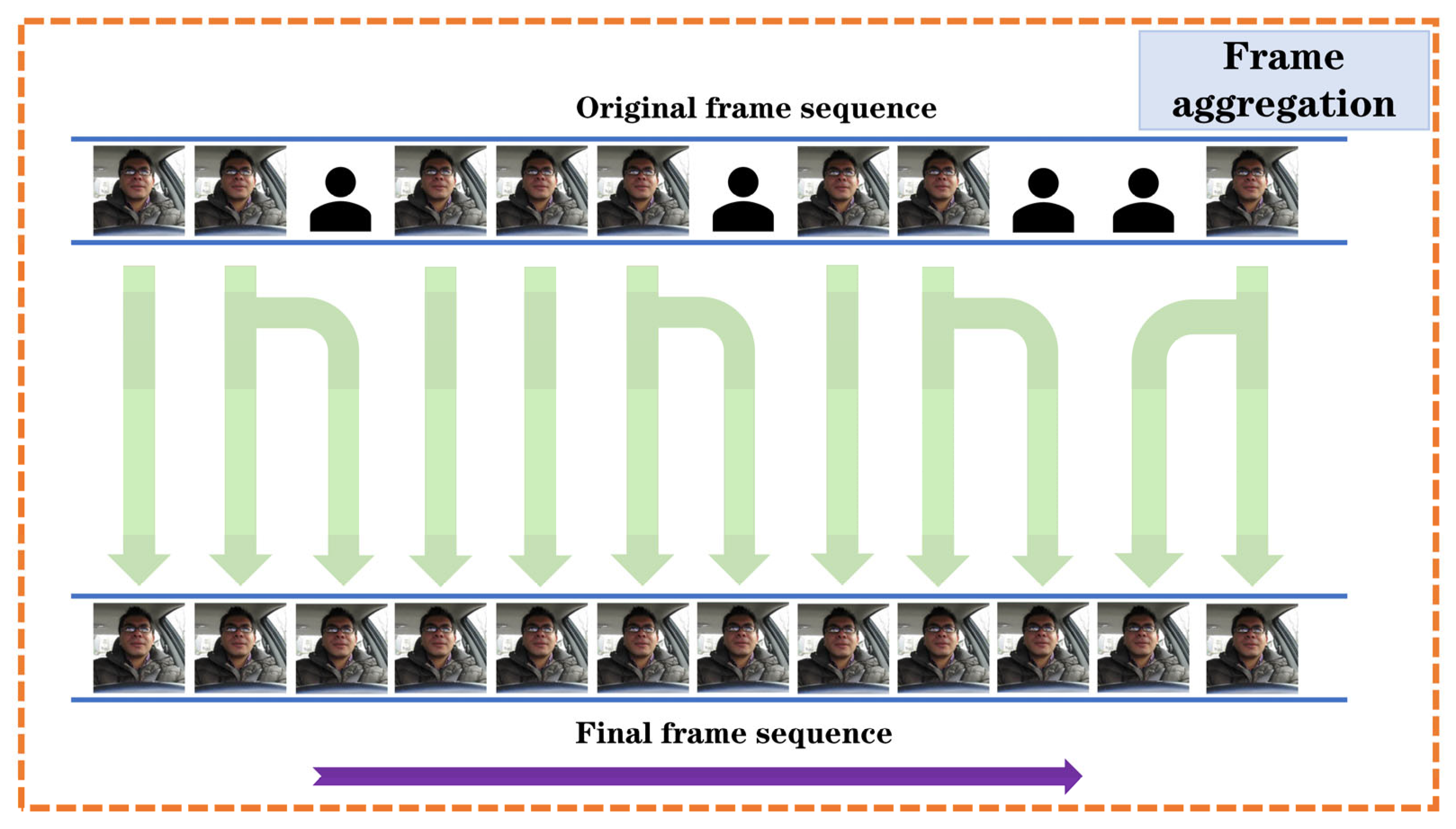
- From the perspective of model training: Generally speaking, the number of parameters of 3D convolution is larger, so the 3D convolution we commonly use are not like 2D convolution. The 3D convolution is not down sampled at a high multiplicity, but at a lower multiplicity. However, due to the matching problem between the amount of data and the amount of model parameters, the 3D convolutional neural network may require more data to train, otherwise it may lead to overfitting. In response to this problem, our approach is to expand the dataset as much as possible. As shown in Figure 7, we have collected a large number of fatigue detection datasets and in addition we have collected and produced our own datasets under real vehicle conditions and trained on a large amount of data to improve the generalization performance of the model. If there are enough training samples and the computing power is strong enough, the model can quickly fit to the optimal encoding function.
- (3)
- From the perspective of problem context: Most of the deep learning-based driving fatigue detection methods process driver facial signals and the process of fatigue is usually a time-series problem. 2D networks only calculate features from the spatial dimension and the information of temporal features is often ignored, which can be improved by introducing the time-series module (LTSM, RNN) [37,38] to solve this problem, but this makes the complexity of the model higher and is not conducive to later real-world applications. 3D networks are able to capture inter-frame motion information, which is a good alternative solution for fatigue feature capture.
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- National Bureau of Statistics of China. China Statistical Yearbook. Available online: http://www.stats.gov.cn/english/ (accessed on 2 February 2022).
- Rau, P.S. Drowsy driver detection and warning system for commercial vehicle drivers: Field operational test design, data analyses, and progress. In Proceedings of the 19th International Conference on Enhanced Safety of Vehicles, Washington, DC, USA, 6–9 June 2005; pp. 6–9. [Google Scholar]
- Khushaba, R.N.; Al-Jumaily, A.; Al-Ani, A. Novel feature extraction method based on fuzzy entropy and wavelet packet transform for myoelectric control. In Proceedings of the 2007 International Symposium on Communications and Information Technologies, Sydney, NSW, Australia, 17–19 October 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 352–357. [Google Scholar]
- Chen, L.; Zhao, Y.; Zhang, J.; Zou, J. Automatic detection of alertness/drowsiness from physiological signals using wavelet-based nonlinear features and machine learning. Expert Syst. Appl. 2015, 42, 7344–7355. [Google Scholar] [CrossRef]
- Fu, R.; Wang, H. Detection of driving fatigue by using noncontact EMG and ECG signals measurement system. Int. J. Neural Syst. 2014, 24, 1450006. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Li, S.E.; Li, R.; Cheng, B.; Shi, J. Online detection of driver fatigue using steering wheel angles for real driving conditions. Sensors 2017, 17, 495. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, W.; Zhang, X.; Peeta, S.; He, X.; Li, Y.; Zhu, S. A self-adaptive dynamic recognition model for fatigue driving based on multi-source information and two levels of fusion. Sensors 2015, 15, 24191–24213. [Google Scholar] [CrossRef] [PubMed]
- Song, F.; Tan, X.; Liu, X.; Chen, S. Eyes closeness detection from still images with multi-scale histograms of principal oriented gradients. Pattern Recognit. 2014, 47, 2825–2838. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, Z.; Zhang, G.; Qi, Y.; Wang, X. Eye state recognition based on deep integrated neural network and transfer learning. Multimed. Tools Appl. 2018, 77, 19415–19438. [Google Scholar] [CrossRef]
- Dua, M.; Shakshi; Singla, R.; Raj, S.; Jangra, A. Deep CNN models-based ensemble approach to driver drowsiness detection. Neural Comput. Appl. 2021, 33, 3155–3168. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-r.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Processing Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; He, Z.; Wang, L. Truck Driver Fatigue Detection Based on Video Sequences in Open-Pit Mines. Mathematics 2021, 9, 2908. [Google Scholar] [CrossRef]
- Ansari, S.; Naghdy, F.; Du, H.; Pahnwar, Y.N. Driver mental fatigue detection based on head posture using new modified reLU-BiLSTM deep neural network. IEEE Trans. Intell. Transp. Syst. 2021, 1–13. [Google Scholar] [CrossRef]
- Ye, M.; Zhang, W.; Cao, P.; Liu, K. Driver Fatigue Detection Based on Residual Channel Attention Network and Head Pose Estimation. Appl. Sci. 2021, 11, 9195. [Google Scholar] [CrossRef]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. Epnp: An accurate o(n) solution to the pnp problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Wijffels, J.; King, B. dlib: Allow Access to the ‘Dlib’ C++ Library. 2017. Available online: http://dlib.net/ (accessed on 11 November 2021).
- Lee, D.T.; Schachter, B.J. Two algorithms for constructing a Delaunay triangulation. Int. J. Comput. Inf. Sci. 1980, 9, 219–242. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving deep neural networks for LVCSR using rectified linear units and dropout. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 8609–8613. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Soukupova, T.; Cech, J. Eye blink detection using facial landmarks. In Proceedings of the 21st Computer Vision Winter Workshop, Rimske Toplice, Slovenia, 3–5 February 2016. [Google Scholar]
- Li, X.; Xia, J.; Cao, L.; Zhang, G.; Feng, X. Driver fatigue detection based on convolutional neural network and face alignment for edge computing device. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2021, 235, 2699–2711. [Google Scholar] [CrossRef]
- Huang, Z.; Siniscalchi, S.M.; Lee, C.H. A unified approach to transfer learning of deep neural networks with applications to speaker adaptation in automatic speech recognition. Neurocomputing 2016, 218, 448–459. [Google Scholar] [CrossRef]
- Li, X.; Pfister, T.; Huang, X.; Zhao, G.; Pietikäinen, M. A spontaneous micro-expression database: Inducement, collection and baseline. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–6. [Google Scholar]
- Pan, G.; Sun, L.; Wu, Z.; Lao, S. Eyeblink-based anti-spoofing in face recognition from a generic webcamera. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Weng, C.-H.; Lai, Y.-H.; Lai, S.-H. Driver Drowsiness Detection via a Hierarchical Temporal Deep Belief Network. In Proceedings of the Asian Conference on Computer Vision Workshop on Driver Drowsiness Detection from Video, Taipei, Taiwan, 20–24 November 2016. [Google Scholar]
- Abtahi, S.; Omidyeganeh, M.; Shirmohammadi, S.; Hariri, B. YawDD: A yawning detection dataset. In Proceedings of the 5th ACM Multimedia Systems Conference, Singapore, 19 March 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 24–28. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Zhang, W.; Murphey, Y.L.; Wang, T.; Xu, Q. Driver yawning detection based on deep convolutional neural learning and robust nose tracking. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–16 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–8. [Google Scholar]
- Deng, W.; Wu, R. Real-time driver-drowsiness detection system using facial features. IEEE Access 2019, 7, 118727–118738. [Google Scholar] [CrossRef]
- Ji, Y.; Wang, S.; Zhao, Y.; Wei, J.; Lu, Y. Fatigue state detection based on multi-index fusion and state recognition network. IEEE Access 2019, 7, 64136–64147. [Google Scholar] [CrossRef]
- Chen, J.; Yang, L.; Zhang, Y.; Alber, M.; Chen, D.Z. Combining fully convolutional and recurrent neural networks for 3d biomedical image segmentation. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; p. 29. [Google Scholar]
- Bai, W.; Suzuki, H.; Qin, C.; Tarroni, G.; Oktay, O.; Matthews, P.M.; Rueckert, D. Recurrent neural networks for aortic image sequence segmentation with sparse annotations. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 586–594. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training Object | Test Data | Method | Accuracy (%) |
|---|---|---|---|---|
| ZJU | Eyes | 975 | ResNet-50 | 95.64 |
| MobileNetV3 | 95.73 | |||
| EfficientNet | 96.22 | |||
| 3D-SE-Net(T) | 98.35 | |||
| 3D-SE-Net(D) | 97.72 | |||
| Mouth | 634 | ResNet-50 | 95.65 | |
| MobileNetV3 | 96.17 | |||
| EfficientNet | 96.41 | |||
| 3D-SE-Net(T) | 97.17 | |||
| 3D-SE-Net(D) | 96.84 | |||
| NTHU-DDD | Eyes | 1135 | ResNet-50 | 97.31 |
| MobileNetV3 | 97.47 | |||
| EfficientNet | 97.72 | |||
| 3D-SE-Net(T) | 99.02 | |||
| 3D-SE-Net(D) | 98.53 | |||
| Mouth | 990 | ResNet-50 | 97.09 | |
| MobileNetV3 | 97.43 | |||
| EfficientNet | 98. 27 | |||
| 3D-SE-Net(T) | 98.84 | |||
| 3D-SE-Net(D) | 98.31 | |||
| YawDD | Eyes | 2014 | ResNet-50 | 97.13 |
| MobileNetV3 | 97.26 | |||
| EfficientNet | 97.48 | |||
| 3D-SE-Net(T) | 98.67 | |||
| 3D-SE-Net(D) | 98.04 | |||
| Mouth | 1065 | ResNet-50 | 97.32 | |
| MobileNetV3 | 97.47 | |||
| EfficientNet | 97.72 | |||
| 3D-SE-Net(T) | 98.55 | |||
| 3D-SE-Net(D) | 97.81 | |||
| FDF | Eyes | 5461 | ResNet-50 | 98.45 |
| MobileNetV3 | 98.61 | |||
| EfficientNet | 98.57 | |||
| 3D-SE-Net(T) | 99.12 | |||
| 3D-SE-Net(D) | 98.74 | |||
| Mouth | 2136 | ResNet-50 | 98.32 | |
| MobileNetV3 | 98.57 | |||
| EfficientNet | 98.62 | |||
| 3D-SE-Net(T) | 99.38 | |||
| 3D-SE-Net(D) | 98.55 |
| Model | 3D-CNN (Without Attention) | 3D-SE-Net (With Attention) | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| Normal | 0.94 | 0.93 | 0.95 | 0.99 | 0.99 | 0.99 |
| Talking | 0.74 | 0.74 | 0.74 | 0.91 | 0.94 | 0.92 |
| Sleepy-nodding | 0.75 | 0.79 | 0.77 | 0.92 | 0.96 | 0.94 |
| Yawning | 0.83 | 0.82 | 0.82 | 0.97 | 0.91 | 0.94 |
| Average | 0.82 | 0.82 | 0.82 | 0.95 | 0.95 | 0.95 |
| Research | Dataset | Method | Accuracy (%) |
|---|---|---|---|
| Zhang et al. [34] | YawDD | Kalman + TLD + CNN | 92 |
| Deng et al. [35] | YawDD | MC-KCF + blinking + yawning | 96.3 |
| Ji et al. [36] | YawDD | MSR-Net | 98.45 |
| Ye et al. [16] | YawDD | RCAN(CBAM) | 98.43 |
| Wang et al. [14] | NTHU | Resnet + DHLSTM | 99.3% |
| Ansari et al. [15] | Homemade | reLU-BiLSTM | 99.2% |
| Ours | YawDD | 3D-SE-Net(D) | 97.34 |
| YawDD | 3D-SE-Net(T) | 99.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, W.; Wu, X.; Li, C.; Zhang, W.; Li, F. Driving Fatigue Detection Based on the Combination of Multi-Branch 3D-CNN and Attention Mechanism. Appl. Sci. 2022, 12, 4689. https://doi.org/10.3390/app12094689
Xiang W, Wu X, Li C, Zhang W, Li F. Driving Fatigue Detection Based on the Combination of Multi-Branch 3D-CNN and Attention Mechanism. Applied Sciences. 2022; 12(9):4689. https://doi.org/10.3390/app12094689
Chicago/Turabian StyleXiang, Wenbin, Xuncheng Wu, Chuanchang Li, Weiwei Zhang, and Feiyang Li. 2022. "Driving Fatigue Detection Based on the Combination of Multi-Branch 3D-CNN and Attention Mechanism" Applied Sciences 12, no. 9: 4689. https://doi.org/10.3390/app12094689