1. Introduction
People with speech impediments and hearing impairments, whether congenital or acquired, often encounter difficulty in speaking [
1]. Therefore, it is necessary to practice vocalizations, so that they can speak correctly [
2]. In this way, they can acquire conversational speaking abilities that are common to otherwise healthy people. Communication also requires listening. For this, many people are required to acquire lipreading skills to interpret the movements of other people’s mouths and determine the contents of conversations [
3]. In particular, Japanese, as a 50-syllable language, is composed of a combination of consonants and vowels to form a single sound, so research on inferring consonants from vowel sequences and inferring words has been active in the field of natural language [
4]. This is rooted in the fact that the lipreader actually understands the language by looking at the shape of the mouth and the order in which it moves. Therefore, in Japanese, vowel identification is important in lipreading, in learning in developmental training, and in machine lipreading.
In Japanese speech practice, it is fundamental to learn the pronunciation of vowels [
5] that are phonetically formed by mouth shapes. To practice vowels, an instructor presents the shape of the mouth for pronunciation, and the trainee imitates the shape [
3].
In recent years, as smartphones and cameras have become mainstream, machine learning lipreading techniques have been actively researched using algorithmic methods to identify specific words with high accuracy [
6,
7]. This makes it possible for healthy, speech-impaired, or hearing-impaired people to imitate what the other person is saying on a display, such as a smartphone, simply by silently changing the shape of their mouth [
7]. However, this technique only accounts for the listening part of a conversation and is a tool that can be used by people who can vocalize well.
Even today, there are few tools for learning correct pronunciation, and vocal practice with a trainer is the norm. Many proposed training methods that use information processing are multimodal and use multiple processing devices, images, sounds, and vocal fold sensors, which impose a heavy burden during training [
8]. Therefore, the authors believe that the three-dimensional (3D) shapes of the mouth can play a leading role in machine-learning-assisted pronunciation training. Hence, we have been studying the identification of vowels using 3D point clouds [
9]. TOF cameras that use infrared sensors emit infrared light of a specific wavelength and measure the distance to an object according to its time of flight [
10]. Since only specific wavelengths are detected, it is possible to acquire a 3D point cloud robust to the lighting environment of the shooting environment [
11]. The use of a 3D point cloud is also expected to be a recognition method as previously reported, as it is robust to the effects of facial orientation if the area to be identified can be captured [
12]. As a conventional vowel recognition method based on two-dimensional (2D) images, a method has been proposed to recognize the shape of lips as a feature of frontal 2D images of faces [
13]. However, the identification rate of the method using the polyline lip region is 59.8%, whereas that of the method using the spline curve lip region is 61.6%. Using only 2D images has the problem of misrecognizing mouth shapes similar to “a” and “e”, resulting in a low identification rate. In the method proposed by the authors, a 3D point cloud was acquired using a time-of-flight (ToF) camera for vowel identification, and it was confirmed that a high identification rate was obtained by adding depth information to the frontal image. The 3D point cloud comprises the shape information of the lips, obtained via 3D images of the lips; such information is not available in 2D images. Therefore, a different method is required for identification, instead of the feature points used from color information. However, their original method lacked versatility because it was necessary to save each trainee’s mouth shape as model data.
In this study, we aimed to capture and identify mouth features as vowels, excluding features related to each person’s vocalization, by learning the shape of the mouth through deep learning using a 3D point cloud.
2. Materials and Methods
The five Japanese vowels are phonetically distinct and rely on well-known and easy-to-practice changes in mouth shape [
14]. Hence, simple resonant vocalization can be used to create the basic phonemes. The characteristics of speech resonance can be extracted from recorded speech signals by manipulating the amplitude spectrum. Peak resonance frequency measurement is the norm [
15]. The formant frequencies are called the first formant (F1), second formant (F2), and third formant (F3) in descending order, and it has been reported previously that Japanese vowels can be distinguished mainly by F1 and F2 [
16]. As the formant frequency of Japanese vowels is determined by the shape of the mouth, a three-dimensional (3D) interpretation of mouth shape should be capable of discriminating vowels. In the proposed method, the mouth shapes of the five vowels pronounced by a healthy Japanese subject were acquired as 3D point clouds. Next, using a model that can learn 3D point clouds, we divided the 3D point clouds acquired by learning into five classes. Finally, the unknown mouth shapes of the vowels were identified and evaluated.
2.1. Acquisition of 3D Point Cloud of Mouth Shape during Vowel Pronunciation
First, landmarks of a person’s face were detected from a video acquired using a color camera, and the lip region was then determined based on visual landmarks.
Figure 1 shows an example of lip-region detection. Dlib’s FaceLandmark Detector was used for landmark detection in
Figure 1. Dlib’s FaceLandmark is capable of acquiring 68 points for facial contours, eyebrows, eyes, and other parts of the face. The detection accuracy and speed are high as it corresponds to the orientation and size of the face using a machine learning model. The 68 points to be acquired include the contours of the face, nose, eyes, and mouth. Even if the position of the lips cannot be accurately captured due to a mustache, etc., the position of the lips can be estimated and detected from other feature points. In this case, 20 points of Dlib’s FaceLandmark adjacent to the lip contours were used. From these 20 points, we could obtain the boundary (contour) of the lips by connecting the adjacent points to the outside and inside of the lips, respectively. Next, a 3D sensor was used to acquire a 3D point cloud. By mapping the coordinates of the 3D sensor and the color camera to both in advance, the color image and the coordinates on the 3D point cloud were matched. This made it possible to use the coordinates of the lip area acquired from the color camera as coordinates in the 3D point cloud.
Figure 2 shows an example of the lip region extracted from a 3D point cloud.
Figure 2 shows an example of a lip point cloud cut from a face point cloud based on the lip contour obtained in
Figure 1. The 3D sensor used in this study uses the ToF method [
10] rather than a stereo camera method [
17] because the mouth shape was photographed at a short distance and the lips had little color change. With stereo imaging, it may not be possible to detect feature points. The ToF method is a 3D sensor that measures the distance using the time it takes for the ultrashort pulses to be reflected by the measuring object and return to the light-receiving device without using feature points. As lip color varies considerably from person to person, the color information is not stored because it may affect identification processes.
2.2. Identification and Learning of Lip Area via 3D Point Cloud
The properties of 3D point clouds include permutation and transformation invariance of points. Therefore, it is possible to design a model with a high degree of freedom for identification by maintaining these properties and performing deep learning. Permutation invariance means that even if the order of input values changes, the output value can be handled by a fixed function, such as sum, average, or maximum value selection. In deep learning networks, maximum pooling is the hierarchy of the network that corresponds to the property of permutation invariance. In transformation invariance, the shape of the point cloud appears to be different depending on the viewpoint from which it is taken, but the relationship between the points in the point cloud remains the same, regardless of the viewpoint. Thus, it minimizes the effect during training. The effort required in the learning process can be minimized.
The classification of the proposed method uses a model for 3D point clouds called PointNet [
18].
Figure 3 shows the training model used in the proposed method. The ‘n’ in
Figure 3 indicates the number of point clouds. In the learning model, the input transform first performed an affine transformation on the input point cloud (input points) to approximate the movement invariance. Thereafter, features were extracted from the affine-transformed point cloud with a multilayer perceptron composed by PyTyorch’s nn. Linear, feature transform was used to apply affine transformation to the extracted features. The multilayer perceptron was used again to extract feature data. Max pooling was then used to extract feature data that were sequentially invariant. Global features were used for segmentation as well as classification, but since this paper only performed classification, it was necessary to perform a final transformation. The features were transformed into the number of classes k using a multilayer perceptron and classified accordingly. Final class identification was performed using SoftMax. The bold square indicates the feature array size of the processed point cloud or array. At this time, the multilayer perceptron shared the weights among the points and maintained them, and the number of points was arbitrary since max pooling was applied to extract the strongest features from the point cloud.
4. Discussion
Table 6 and
Table 7 show that the accuracy rate of k-fold cross-validation exceeded 70% in both the mixed-gender and male-only experiments. As shown in
Table 8 and
Table 9, the accuracy of the test data identification results was 82.67% for the mixed-gender experiment and 85.20% for the male-only experiment. From the training results using 2D images (the conventional method:
Table 10 and
Table 11) and those from 3D point clouds (the proposed method:
Table 6 and
Table 7), it can be seen that in the mixed results, accuracy, recall, and F-measure decreased by 2.945%, 3.835%, and 3.458%, respectively, while precision increased by 0.404% in accuracy compared to the conventional method. The male-only results show that the accuracy, precision, recall, and F-measure decreased by 2.538%, 0.487%, 2.795%, and 2.689%, respectively. The total parameters of the Xception model used in the experiment was 22,960,173, while the total number of parameters of the proposed method was 1,645,385. The total parameters of the proposed method was 92.834% less than that of the conventional method. The proposed method uses only the coordinates of the point cloud and does not use pixel information, while the conventional method uses image coordinates and pixel information. Therefore, the input information was reduced, contributing to a reduction in the number of parameters. In addition, by generating a training model for vowel identification using a 3D point cloud, it is possible to maintain the order independence that provides degrees of freedom in the input array of point clouds. A point cloud of only the lip region can extract lip shape features with a few parameters and achieve 3.835% accuracy, as compared to conventional methods. In machine learning methods, models with a huge number of parameters have been proposed to improve accuracy, and research has also been conducted to reduce the number of parameters and decrease the computational cost [
22]. Xception, which was used as a conventional method in this study, is also known as a method that reduces the number of parameters while maintaining a highly accurate model [
22]. In the proposed method, by changing the input data from 2D images to 3D point clouds in the same way, it was confirmed that the number of parameters can be reduced, and identification can be performed with a high degree of accuracy.
A hidden-Markov-model-based method has been proposed for identifying Japanese vowels [
23]. In this conventional method [
23], as in the proposed method, only the lip region is extracted for recognition; the average vowel identification rate from the lip region alone was 75.4%. Another method, the dynamic-contour-model-based vowel recognition method, extracts the lip shape and uses this information to recognize vowels [
24]; the average discrimination rate of this method was 72.3%. The identification rate of the proposed method using the male-only dataset was 4.48% higher than that of the HMM-based approach and 8.96% higher than that of the DCM-based approach.
In recent years, multimodal methods have been reported for Japanese speech recognition [
25]. This method uses speech information, color images, and depth images for training, and the best recognition rate (79.1%) was achieved using all three.
Table 6 and
Table 7 show that the proposed method discriminated 71.3% of the test data with k-fold cross-validation accuracy for the mixed-gender dataset and 78.8% for the male-only dataset, indicating that the proposed method is more accurate than the conventional method in terms of the discrimination rate of the test data. From this result, it can be claimed that the accuracy of the proposed method and that of the conventional method are comparable. However, unlike the conventional method, the proposed method is a discrimination method using only 3D depth point clouds. The noise in the depth image of the conventional method may have affected the accuracy of the conventional method.
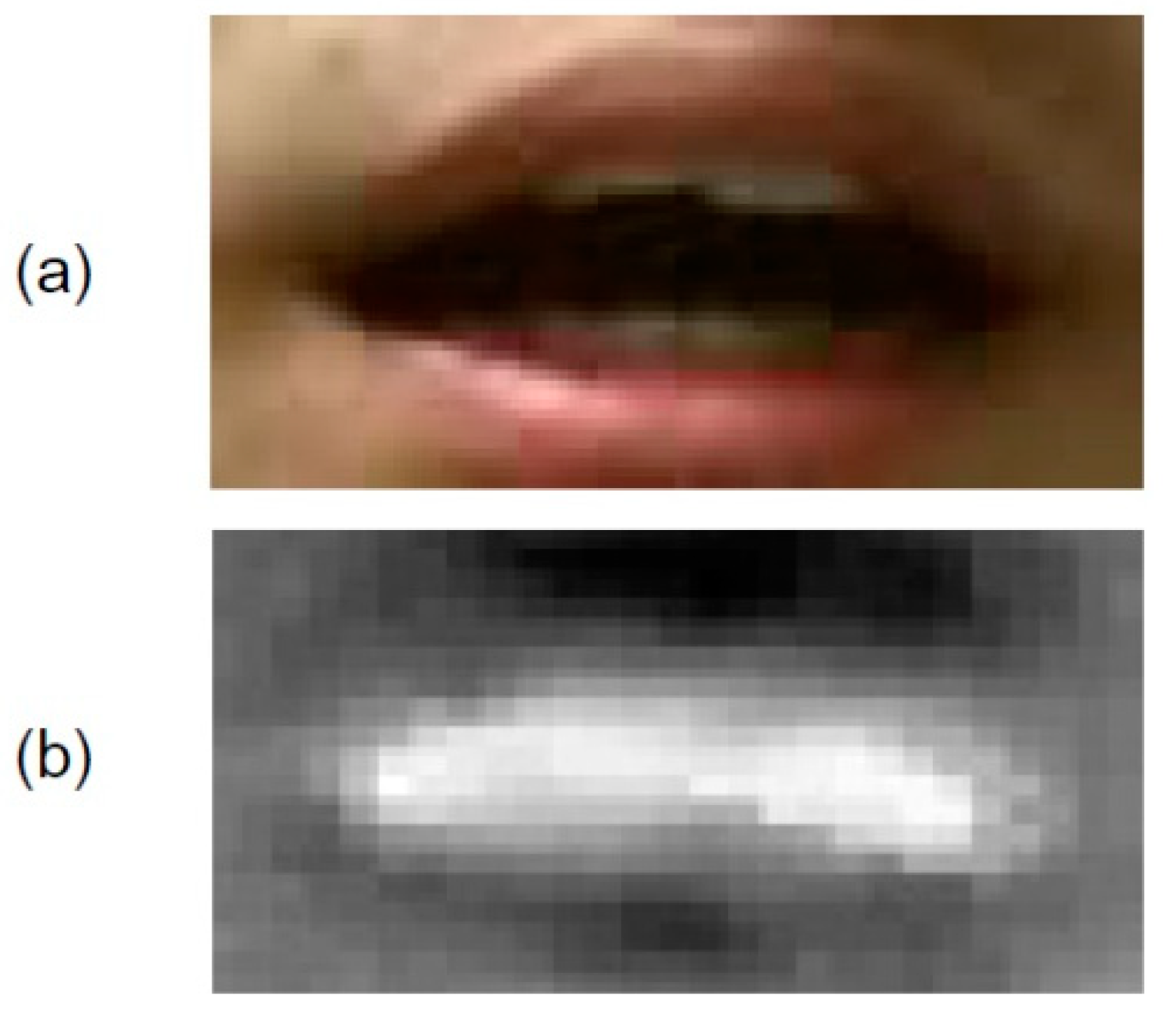
Figure 7 shows the depth image used for training in the conventional method.
Figure 7 shows that depth data other than those of the lip region are included. It is thought that the depth noise outside the lip region affects the discrimination rate. In our proposed method, we removed the learning noise other than that for the lips by learning with a 3D point cloud of only the lip region, as shown in
Figure 2. Furthermore, by treating the 3D data as a point cloud, we achieved a more robust recognition of lip movements.
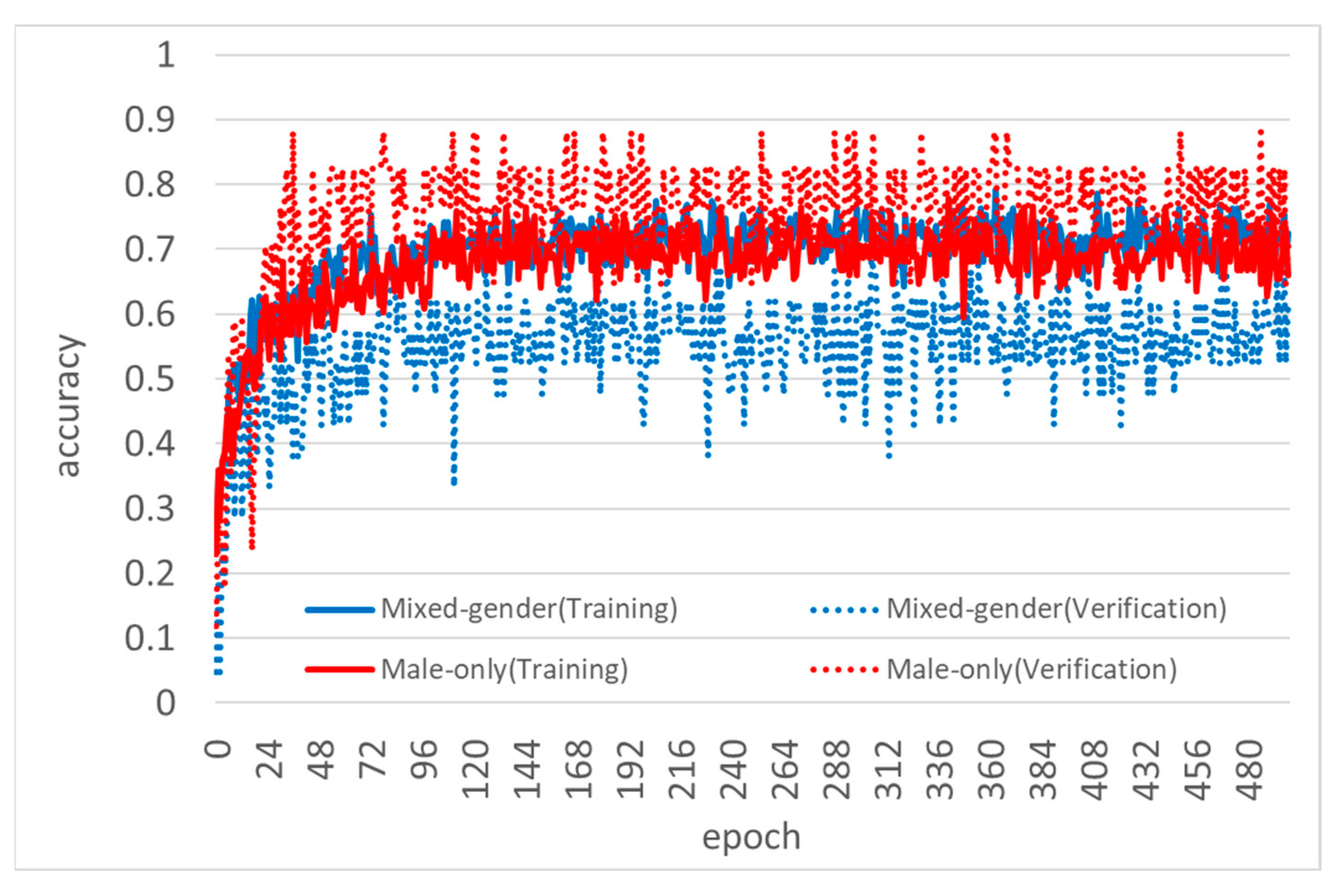
Table 6 and
Table 7 indicate that the results of the male-only experiment were better than those of the mixed-gender experiment for all parameters. From the training process shown in
Figure 5, the accuracy rate during validation was higher than that during training when using the male-only dataset. In other words, the model trained on a training dataset with a large number of data correctly answered a larger number of validation data. Conversely, in the case of the mixed-gender dataset, the accuracy rate during validation decreased more than that during training. This can be explained by the fact that there were many data that did not fit the trained model. In other words, the mixed-gender model was over-trained for the training dataset and could not make correct judgments on the data at the time of validation. For the male-only dataset, the model parameters obtained from the training data were appropriate, and the accuracy rate increased during validation. The reason for the change in the learning state depending on the dataset is thought to be related to the differences in the skeletal structure of men and women. In fact, in the field of phonetics, a difference in formant frequency between males and females has been reported [
14]. In other words, it is thought that the shape of the mouth, the factor that causes changes in formant frequency, also differs significantly between men and women. Hence, this factor was thought to cause overfitting during the study.
In the future, the proposed method is expected to be implemented in smartphones equipped with stereo cameras and TOF cameras, which have been increasing steadily in recent years and are capable of facial recognition [
26]. Combined with natural language processing, which identifies vowels in real time and estimates words based on vowel sequences, the proposed method could contribute to the development of systems in which subtitles and letters can be typed without speech. In addition, since the number of parameters was significantly reduced and the training time was also shortened by using the proposed method, it can be assumed that the machine specs used for identification can be implemented even in small mobile devices such as smartphones.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}