1. Introduction
Mobile robots are increasingly used in outdoor applications, such as search and rescue missions, planetary ground surveys, and national defense security [
1] where robots usually have to face complex environments with an uneven terrain [
2,
3,
4]. In such an environment, the planned trajectory usually includes path segments with rapidly changing height and multiple sharp turns. When the mobile robot passes through this section of the path, it will consume more energy [
5], which should be avoided. Therefore, this paper focuses on trajectory generation and optimization to quickly find a short and smooth trajectory in uneven environments.
In an uneven environment, it is obvious that ordinary 2D grid maps cannot reasonably model the environment, so it is essential to build a map model that can better describe the uneven environment. Generally, 3D modeling and 2.5D elevation maps are used in this circumstance. In [
6,
7,
8], 3D radar for 3D modeling was used which simulates the complex uneven outdoor environment including stairs, slopes, etc. This method can accurately and comprehensively grasp the specific information of the surrounding environment [
9], but it occupies a large amount of computer running memory and has poor timeliness, especially when the size of the environment increases. Therefore, scholars have tried to find simpler and more applicable modeling methods. In [
10,
11,
12], the authors tried to reduce the cost of 3D radar modeling, using RGB-D (Red Green Blue-Depth) sensors to store the height information and coordinates of the environment in the same grid to obtain a discrete 3D grid map, namely a 2.5D elevation map. This paper proposes a 2D-H grid map based on a 2.5D elevation map, which maps the height information of the environment to a 2D plane. Compared with the 2.5D elevation map, the 2D-H method further reduces the number of calculations and saves memory space, which not only meets the needs of timeliness but is also practical enough.
The goal of trajectory planning is to find a trajectory for a robot from a starting point to an ending point without colliding with obstacles and meeting other constraints, such as the trajectory length and smoothness. In recent years, trajectory planning has attracted much attention in the field of robotics. Traditional methods, such as simulated annealing (SA) [
13] and the artificial potential field method (APF) [
14], are widely used because of their ease of understanding and implementation. However, [
15] these methods may easily fall into a local optimal solution and cannot reach the end point when a complex environment is encountered.
When dealing with trajectory planning in a complex dynamic environment, intelligent bionic algorithms often play an important role [
16], including genetic algorithms (GA) [
17], neural networks [
18], particle swarm optimization (PSO) [
19], and the ant colony algorithm (ACO) [
20]. The GA algorithm has strong uncertainty in the planned trajectory due to its large number of parameters and the randomness of the initial population [
21]. In the PSO algorithm, [
22] the initial particles are randomly selected, which leads to a variety of different planning results. [
23]. Neural network algorithms spend a lot of time on pre-training and adjusting parameters. Not only is the number of calculations significant, but also the interpretability is not ideal. In an uneven environment with obstacles, the uncertainty of the environment, such as the distribution of obstacles and the complexity of the environment, brings difficulties to the trajectory planning of mobile robots. Therefore, the required path planning algorithm needs a strong search ability and good stability.
ACO is a probabilistic technique to solve computational problems which is robust and easy to combine with other methods [
24,
25]. In recent years, the ant colony algorithm has been widely used in transportation, logistics distribution, network analysis, and other fields [
26]. Nevertheless, the traditional ant colony algorithm has the defects of a low search efficiency and a slow convergence speed, and it is also easy to fall into local extremes.
Researchers have put forward various improved methods to optimize the search ability of the ant colony algorithm. Li et al. [
27] proposed an improved ant colony algorithm with multiple heuristics (MH-ACO), which is better reflected in the global search ability and convergence. However, the parameter setting is complex, which brings randomness to the experiment. Akka et al. [
28] used a stimulating probability to help the ants choose the next grid and employed new heuristic information based on the principle of unlimited step length to expand the field of view and improve the visibility accuracy. The improved algorithm speeds up the convergence speed and expands the search space, but the safety of the trajectory cannot be guaranteed. In addition, Ning et al. [
29] designed a new pheromone smoothing mechanism to enhance the search performance of the algorithm. When the search process of the ant colony algorithm is close to stagnation, the pheromone matrix is reinitialized to increase the diversity of the connections at the expense of a large time cost.
Furthermore, the improved ant colony algorithm is combined with some two-stage trajectory planning methods. Chen et al. [
30] proposed a fast two-stage ant colony algorithm based on the odor diffusion principle, including two stages of preprocessing and trajectory planning, which accelerated the convergence speed but did not consider the trajectory optimization. Yang et al. [
31] proposed a multi-factor improved ant colony algorithm (MF-ACO) to solve the problem related to the fact that the trajectory planning algorithm of mobile robots cannot cope with the complex actual environment. The maximum and minimum ant strategy was adopted to avoid local optima. Then the dynamic tangent point adjustment method was used to smooth the path to further improve the quality of the trajectory, but the smoothness needed to be further improved.
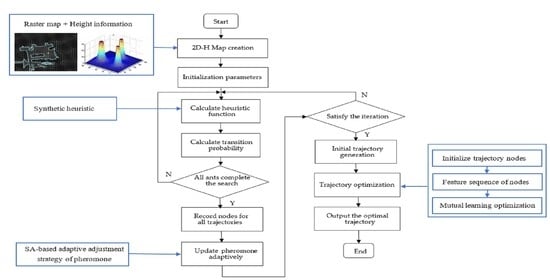
Although the above-mentioned improved algorithm attempts to improve the search performance of ACO and speed up the convergence speed, it does not consider the height information in the environment, which is different from ordinary raster maps, and the convergence performance of ACO can be further improved. For trajectory planning and optimization in complex and uneven environments, this paper proposes a trajectory generation and optimization method based on mutual learning and adaptive ant colony optimization (MuL-ACO), which can make robots safely and quickly plan a short and smooth trajectory in uneven environments. In this method, the global trajectory planning of mobile robots is divided into two consecutive parts: the initial trajectory generation and trajectory optimization. Firstly, the improved adaptive ant colony algorithm further accelerates the convergence of ACO to quickly generate the initial trajectory. The initial planned trajectory may contain redundant points and inflection points, which results in high memory consumption and poor trajectory quality. Then, a trajectory optimization algorithm based on mutual learning is proposed to further optimize the length and smoothness of the initial trajectory.
The main contributions of this paper are as follows.
The 2D-H raster map is proposed to simulate the uneven outdoor environment. The height information in the three-dimensional environment is stored in the 2D plane;
A hybrid scheme using mutual learning and adaptive ant colony optimization is proposed in this paper. The global robot trajectory planning problem is divided into two consecutive parts: the trajectory generation part and the trajectory optimization part;
An improved adaptive ant colony algorithm is proposed to generate the initial trajectory. Considering the height information of the map, a comprehensive heuristic function including length, height, and smoothness is designed. Then, a new pheromone adaptive update strategy is proposed through an improved simulated annealing function to speed up the convergence of the algorithm.
A new trajectory optimization algorithm based on mutual learning is proposed to optimize the generated initial trajectory. Firstly, feature ablation experiments are carried out for each turning point to obtain the safety feature sequence of each turning point. Then, each point learns from other points to gradually eliminate the points that do not affect the trajectory safety to optimize the trajectory length and smoothness. Finally, the shortest sequence of key points affecting trajectory safety is obtained. Therefore, the algorithm optimizes the final trajectory in terms of smoothness, length, and stability.
This research is structured as follows:
Section 2 describes the environment and problems.
Section 3 illustrates the improved adaptive ant colony algorithm.
Section 4 describes the framework and the process of the proposed trajectory optimization algorithm based on mutual learning in detail.
Section 5 presents the steps and flowcharts of a hybrid scheme using mutual learning and adaptive ant colony optimization.
Section 6 discusses the results of the simulation experiment. Finally,
Section 7 concludes the paper.
4. Mutual Learning-Based Trajectory Optimization Algorithm
To reduce the redundant nodes of the initial trajectory generated by the adaptive ant colony algorithm to further optimize the length and smoothness of the trajectory, a trajectory optimization algorithm based on mutual learning is proposed. Firstly, feature ablation experiments were carried out for each turning point to obtain the safety feature sequence of each turning point. Then, each point learns from other points to gradually eliminate the points that do not affect the trajectory safety to optimize the trajectory length and smoothness. Finally, the shortest sequence of key points affecting trajectory safety is obtained. The proposed algorithm achieved a smooth trajectory and minimized the length of the trajectory. At the same time, the wear of the robot’s steering to follow the planned trajectory was reduced.
For instance, as shown in
Figure 5, the feasible initial trajectory
:
is usually not the best trajectory. After the trajectory optimization algorithm based on mutual learning is optimized once, the trajectory
can reach the end point without passing through the
point. When the optimization is completed, the final trajectory
can even reach the end point directly through the
point. Consequently,
is optimized to
:
, which optimizes the length and smoothness of the initial trajectory. The algorithm is described as follows.
The initial trajectory
, including the starting point
S and the ending point
E, can be represented by a set of all turning points
,
, and the coordinates of the point set are represented by Equation (12).
To learn the collision characteristic of each turning point, it is assumed that there are
n initial individuals
represented by the characteristic matrix (13). Then each individual subjected to a characteristic ablation experiment, and the characteristic zero point is set by Equation (14).
A reward and punishment step are added to determine whether the
i-th individual
reaches the target directly from the starting point without collision. The cost function is
calculated by Equation (15),
is the length of the initial trajectory, and
is the trajectory length of the current individual.
The current individual
learns from each other in turn with other individuals
, and learns the collision characteristics of each other’s nodes to obtain the best individual. Suppose
is the current individual, the mutual learning process is shown in
Figure 6.
In the first stage of initialization, each turning point is subjected to an ablation experiment to obtain the feature and feature sequence of the point, which can be obtained by Equation (14). In the second stage of mutual learning, individuals start from
and learn from each other in turn. The learning method is to compare the value of the cost function, and individuals with high values learn from individuals with low values. In the third stage of the individual update after mutual learning, if the current individual penalty value
does not increase, the old individual
is updated to the new individual
according to the cost function, otherwise, it is not updated. The individual is updated by Equation (18).
The ultimate goal of the mutual learning trajectory optimization algorithm is to generate an optimized path with fewer turns
and a shorter length
.
Algorithm 1. The pseudo code for MLTO.
| Algorithm 1. Mutual learning-based Trajectory Optimization Algorithm |
| 1: input turning point set |
| 2: initialize point set as feature individual by (13)(14) |
| 3: calculate the reward and punishment function by (15)(16)(17) |
| 4: for = 1 to n do |
| 5: for = 1 to n do |
| 6: if is not more than then |
| 7: learns feature zero through , and calculate
|
| 8: will be updated to by (18) |
| 9: else |
| 10: learns feature zero through , and calculate
|
| 11: will be updated to by (18) |
| 12: end if |
| 13: end for |
| 14: end for |
| 15: if
is equal to the initial trajectory then |
| 16: the optimal trajectory is initial trajectory , number of turns is |
| 17: else |
| 18: calculate the length of the optimal trajectory and the number of turns by (19)(20) |
| 19: end if |
| 20: output the number of turns: |
| 21: output the shortest trajectory: |
6. Experiment
In this section, four sets of simulation experiments were conducted to evaluate the performance of the MuL-ACO scheme. In the first set of experiments, the algorithm proposed in this paper was compared with other intelligent algorithms, which are the well-known GA and the novel sparrow search algorithm (SSA) [
33]. In the second set of experiments, the algorithm proposed in this paper was compared with the traditional ACO and other improved ACO, which are MH-ACO and MF-ACO. Two groups of experiments were carried out on maps with different sizes and different numbers of obstacles. The third set of experiments was set with different starting points and ending points on a map, and compared with the proposed algorithm with ACO, MH-ACO, and MF-ACO. To further verify the effectiveness of the improved algorithm, the fourth set of experiments was simulated in a dynamic environment. Furthermore, the height threshold of uneven environments was set to (−1 m, 1 m) to constrain the robot’s trajectory search. The initial trajectory is given on each map to show the process of trajectory generation and optimization.
To build the environment map of the mobile robot, 2D-H grid maps with different sizes, obstacles, and terrains were modeled by the MATLAB simulation platform, where the blue areas are low terrain areas, and the green areas are high terrain areas. Obstacles were randomly placed on the map and start and end points were set. All experiments were performed on the same PC to obtain an unbiased comparison of CPU time. Parameters of MuL-ACO were set as the following: .
6.1. Simulation Experiment A
In this experiment, six maps of 20 × 20 m were selected for simulation, which differed in the number of obstacles and the shapes of obstacles.
Figure 8 shows the optimal trajectories planned by GA, SSA, and MuL-ACO. To obtain more specific performance indicators, including length, number of iterations, smoothness, height difference, and running time, the experiment was performed 30 times to obtain the average value.
Table 2 summarizes the qualitative comparison of the performance of MuL-ACO, GA, and SSA.
In
Figure 8a–f, the trajectory planning based on MuL-ACO tended to bypass steep or concave areas and generated a comprehensive optimal target trajectory with good safety, fewer turns, and a shorter length. The main reason is that MuL-ACO introduces the height factor in environments into the heuristic function, and the trajectory optimization algorithm based on mutual learning further optimizes the trajectories. In contrast, the GA and SSA algorithms do not actively bypass steep or concave areas when generating trajectories, so mobile robots will incur certain losses when following trajectories and the quality of trajectories is average. In the case of a small difference in trajectory length, as shown in
Figure 8a,b,e, MuL-ACO can find a flatter and safer trajectory through the trajectory optimization algorithm based on mutual learning. In
Figure 8c,d,f, the trajectories generated by MuL-ACO were shorter, smoother, and safer than GA and SSA.
As shown in
Table 2, compared with GA and SSA, the hybrid scheme of MuL-ACO proposed in this paper had a large improvement in the convergence performance, which was about 70% to 85%. The reason is that the SA-based pheromone adaptive adjustment strategy accelerated the convergence of the algorithm. In terms of the height difference of the trajectory, the trajectory planned by MuL-ACO tended to avoid passing through steep uneven areas, so the total height difference of the trajectory was lower than GA and SSA. Compared with the other two algorithms, the final trajectory generated by the mutual learning-based trajectory optimization algorithm was better in terms of length and smoothness. In addition, it can be seen from
Table 2 that MuL-ACO had a shorter running time when planning the trajectory.
6.2. Simulation Experiment B
In this experiment, six maps of 30 × 30 m were selected for simulation, which differed in the number of obstacles and the shapes of obstacles. Start and end positions were given randomly, as shown in
Table 3. MuL-ACO was compared with ACO, MH-ACO, and MF-ACO in larger and more complex uneven environments.
Figure 9 shows the best trajectory planned by each method. It is obvious that the trajectory planned by the method proposed in this paper had fewer turns, good smoothness, and short length, while bypassing steep or concave terrain. In simple scenes, as shown in
Figure 9c,d,e, the trajectory planned by MuL-ACO was smoother and bypassed steep or concave areas as much as possible. In more complex scenes (Map 1 and Map 6), the difference in the quality of the trajectories was more obvious. As shown in
Figure 9a, the trajectories planned by ACO and MH-ACO extended along the edge of the obstacle resulting in multiple turns. Although the MF-ACO algorithm avoided local traps when planning trajectories, its trajectory height and smoothness were worse than MuL-ACO. Especially in Vortex map 6, as shown in
Figure 9f, the traditional ACO failed to generate a trajectory from the starting point to the end point, and MH-ACO often fell into a local trap and could not escape. Although MF-ACO could work normally, the quality of the trajectory was not ideal. MuL-ACO had a good performance due to the improved heuristic function and adaptive pheromone adjustment strategy. Moreover, the trajectory optimization algorithm based on mutual learning is suitable for different maps. Therefore, the scheme proposed in this paper is not affected by changeable environments and can plan the trajectory with a good comprehensive quality.
As shown in
Table 4, 30 experiments were performed on six different maps to obtain the specific average performance metric of the algorithms.
Figure 10 shows the performance comparison of MuL-ACO and the other three algorithms on 6 maps, which more clearly highlights the advantages of the proposed scheme in terms of length, number of iterations, number of turns, and the height difference of trajectory. From the specific data and the line graph, it can be seen that the method proposed in this paper was significantly better than the other algorithms in the number of iterations and the number of turns, reducing them by about 66.7%~87.5% and 80%~94.7%. Moreover, compared with other algorithms, the trajectory length was reduced by about 6%~23.3%. Furthermore, the MuL-ACO scheme did not choose a steep route to reduce the wear of the mobile robot in uneven terrain. The height difference of the trajectory was reduced by 15.9%~68.2%. As shown in
Table 4, in Maps 1, 2, 3, and 6, although the running time of MuL-ACO was not the shortest, the gap between the running time of MuL-ACO and the shortest running time was no more than 0.3 s. In some complex maps (Map4 and Map5), the running time of MuL-ACO was even about 0.1 s~0.8 s less than other algorithms, which provides the possibility for trajectory planning in dynamic environments.
6.3. Simulation Experiment C
In this group of experiments, the Complex2 map of simulation experiment B was selected. Moreover, different starting points and ending points were randomly set to diversify the experimental results.
Figure 11 shows the optimal trajectories planned by ACO, MH-ACO, MF-ACO, and MuL-ACO.
Table 5 summarizes the qualitative comparison of the performance of algorithms.
In
Figure 11a,d, compared with other algorithms, MuL-ACO found a flatter and smoother trajectory for the robot. Although MH-ACO and MF-ACO also tended to find flat trajectories, the planned trajectories were not smooth enough. In
Figure 11b,c, the trajectories planned by different algorithms were concentrated in the same area with height. Moreover, the cost of bypassing this height area was high. The hybrid scheme proposed in this paper did not completely bypass the height area but planned a shorter and smoother trajectory with a small height difference.
As shown in
Table 5, the MuL-ACO hybrid scheme proposed in this paper had great advantages in smoothing performance. In terms of the height difference of the trajectories, the trajectories planned by MuL-ACO tended to bypass uneven areas, and the total height difference of the trajectories was lower than that of ACO, MH-ACO, and MF-ACO. Further, compared to other algorithms, MuL-ACO had the least number of iterations and the shortest running time. The hybrid scheme proposed in this paper runs stably and plans trajectories with a high comprehensive quality.
6.4. Simulation Experiment D
In this section, the feasibility of the proposed scheme in dynamical environments, which consisted of 2 dynamic obstacles represented by red blocks and other static obstacles represented by black blocks, was tested. The starting point of the mobile robot was (3.5, 2.5), and the end point was set to (28.5, 28.5). The dynamic obstacles moved vertically down and right at a rate of 2 m per time step and moved a total of 6 steps.
Figure 12 shows the process of MuL-ACO generating the optimal trajectory. In the initial trajectory generation stage, the planned trajectory avoided steep regions and dynamic obstacles in the environment and contained several redundant trajectory nodes. In particular, it can be seen that the planned trajectory actively bypassed the vertical downward moving obstacles and adjusted the trajectory to reach the end point. In the trajectory optimization stage, the length and smoothness of the initial trajectory were minimized by a mutual learning-based trajectory optimization algorithm. The specific length and smoothness of the initial trajectory and the optimized trajectory are given in
Table 6. Clearly, the proposed scheme can stably plan desired trajectories in dynamic environments.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}