
Multi-Scale Upsampling GAN Based Hole-Filling Framework for High-Quality 3D Cultural Heritage Artifacts

 and
and
Abstract
:1. Introduction
- A multi-scale upsampling GAN (MU-GAN) is built to generate a dense point cloud to fill the hole regions.
- To make the learned latent feature more robust, multi-scale point clouds are used to complete the incomplete models, which can restore the CHarts with more fine-grained details.
- There are no limitations on the size of the input point cloud, indicating that the proposed framework is more suitable for the CHarts with a huge point number to preserve details.
2. Method
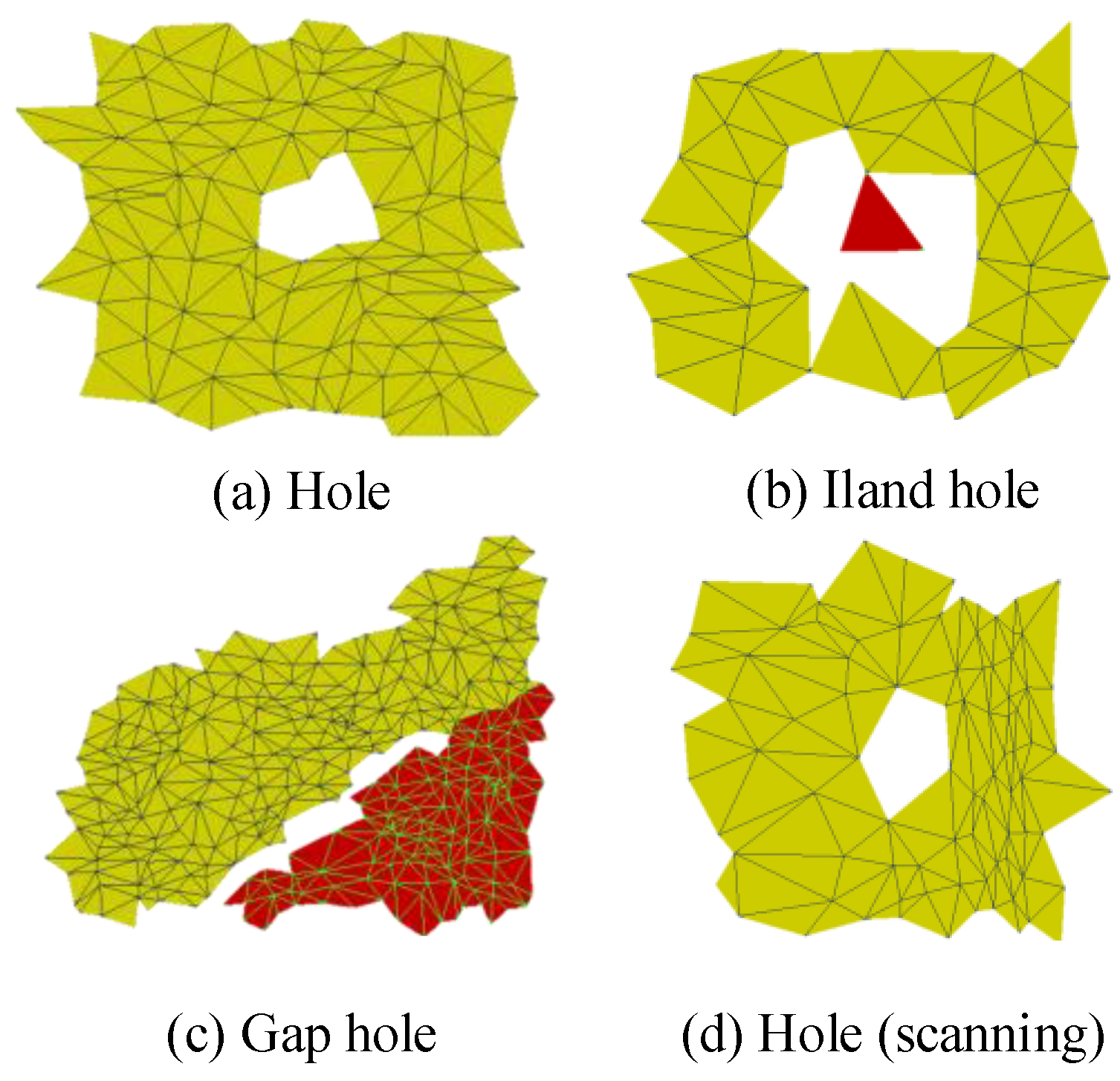
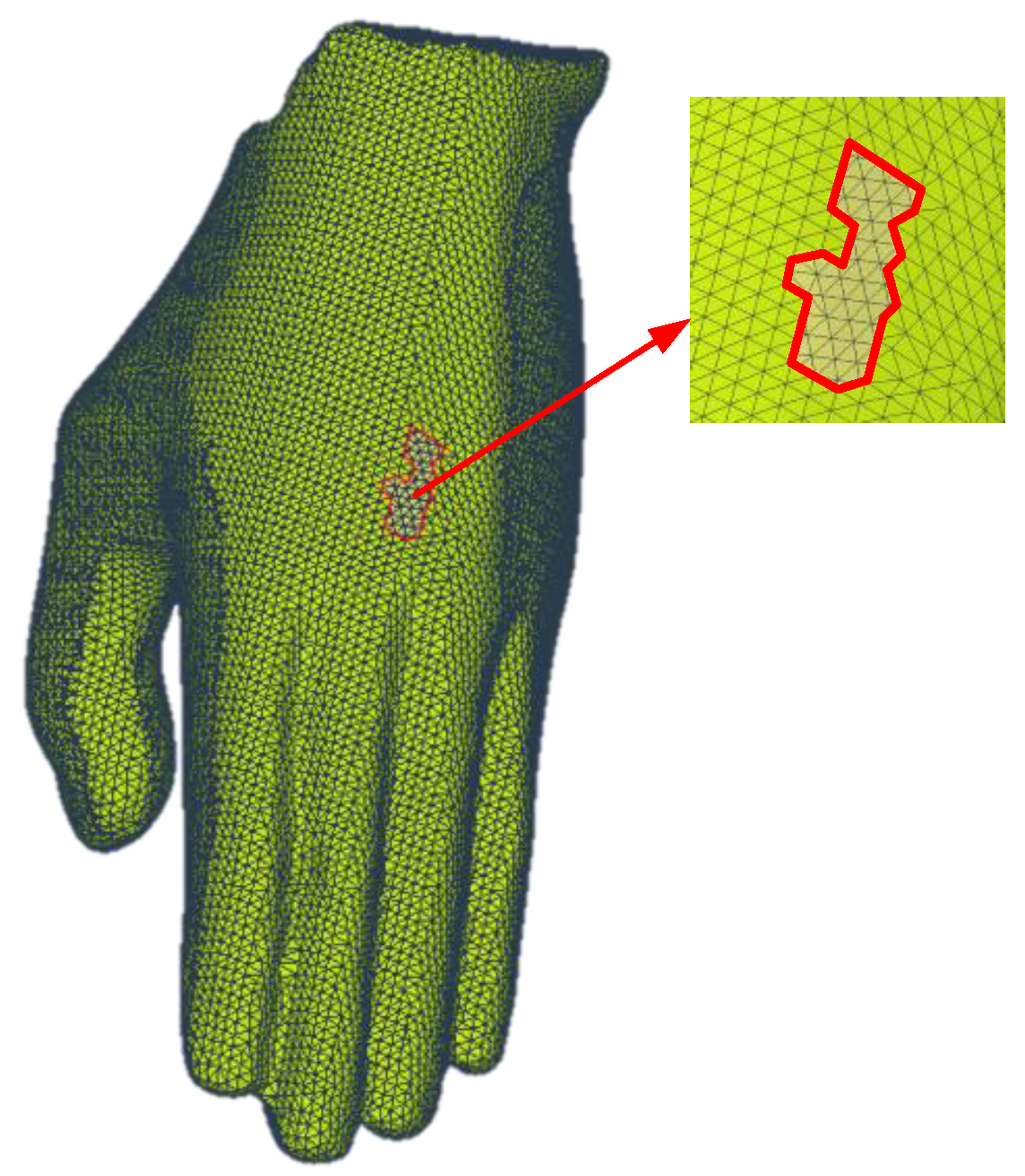
2.1. Hole Detection Method
| Algorithm 1: Hole detection method for 3D Charts |
| Initialize. The 3D mesh model of the 3D CHart is composed of a set of triangles, and the triangle contains vertices and edges. |
| Step 1: Traversing the 3d Mesh to get the number of adjacent triangles on each side to form a matrix , where E represents the side, N represents the number of triangles adjacent to the side, and B is a Boolean value, which identifies whether the current side has been traversed. |
| Step 2: Find the edge whose N value is 1 in , which is defined as the hole points set . |
| Step 3: Utilizing depth-first-search (DFS) to traverse M along . |
| Step 4: Adding boundary vertices to the hole points set , and the Boolean value is set to TRUE. |
| Step 5: Repeating Step 4, until a closed loop which is the identified hole is formed. |
| Step 6: Repeating Step 2–Step 4 until the matrix M does not have hole edges. |
| Output: The hole regions of the 3D mesh model. |
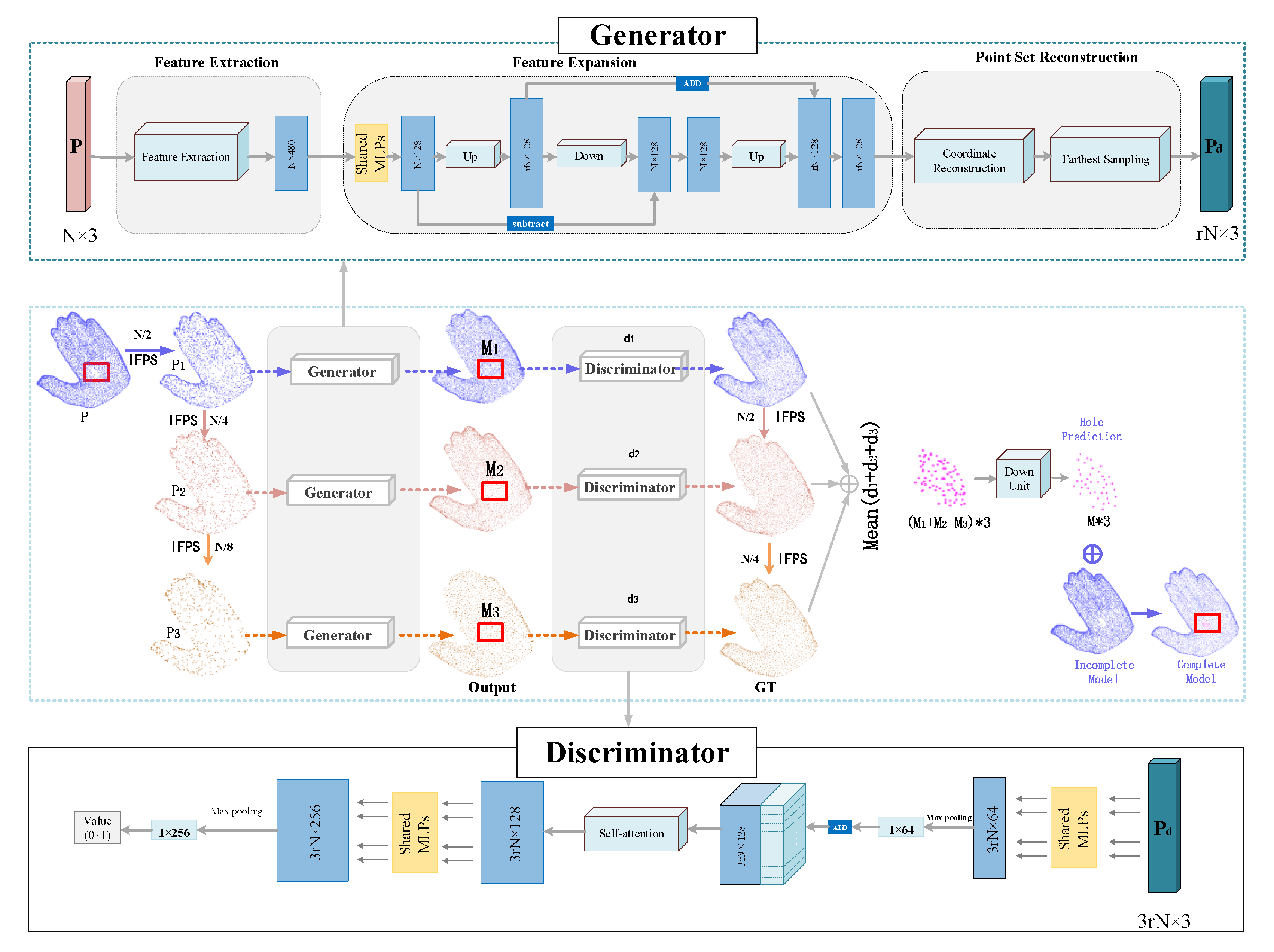
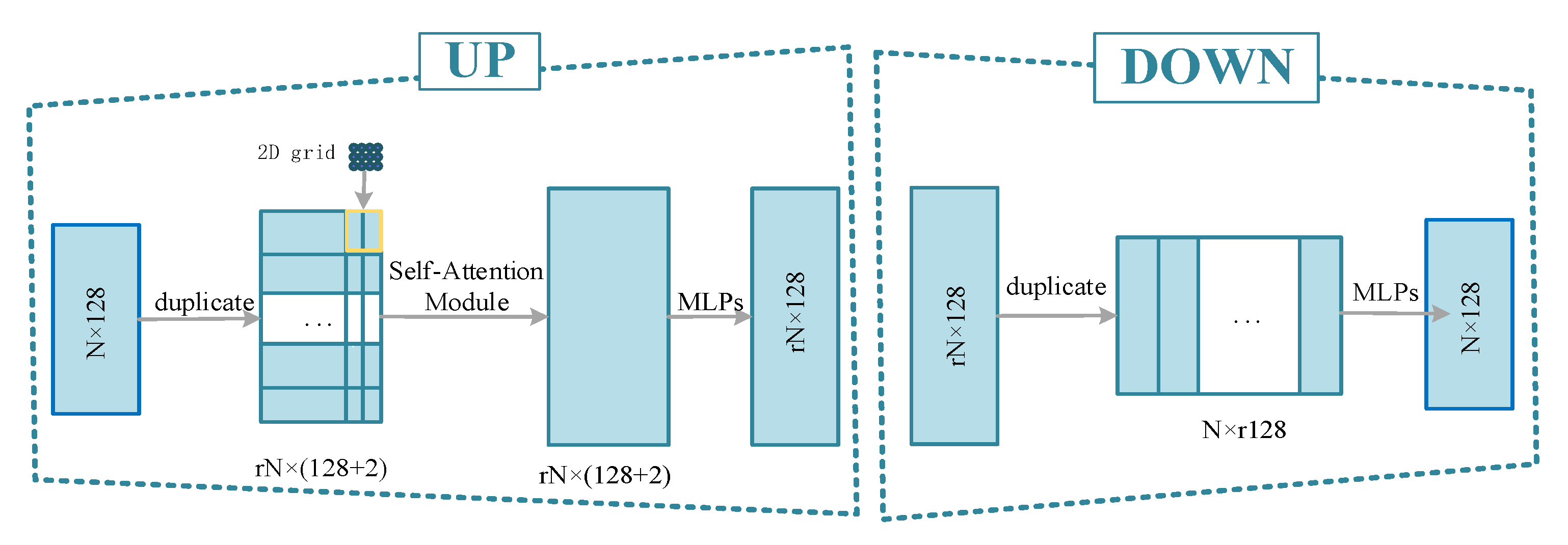
2.2. MU-GAN Architecture
2.3. MU-GAN-Based Hole FILLING framework
| Algorithm 2: MU-GAN Based Hole Filling Framework |
| Initialize: Point cloud data of 3D CHart model. |
| Step 1: Construct the mesh model and locate the hole regions based on Algorithm 1. |
| Step 2: Convert the mesh model into point cloud data and extract the point cloud P containing the hole area. |
| Step 3: Generating the downsampled point cloud , and . , and are the downsampled point cloud from , and , separately. |
| Step 4: Input , and into the trained MU-GAN to obtain dense point cloud . |
| Step 5: Extracting the point cloud corresponding to the hole area in as a patch, is denoted as . |
| Step 6: Merging with incomplete original point cloud to generate the complete point cloud. |
| Output: 3D CHart model with no hole regions. |
3. Experiments and Results
3.1. Dataset and Implementation Detail
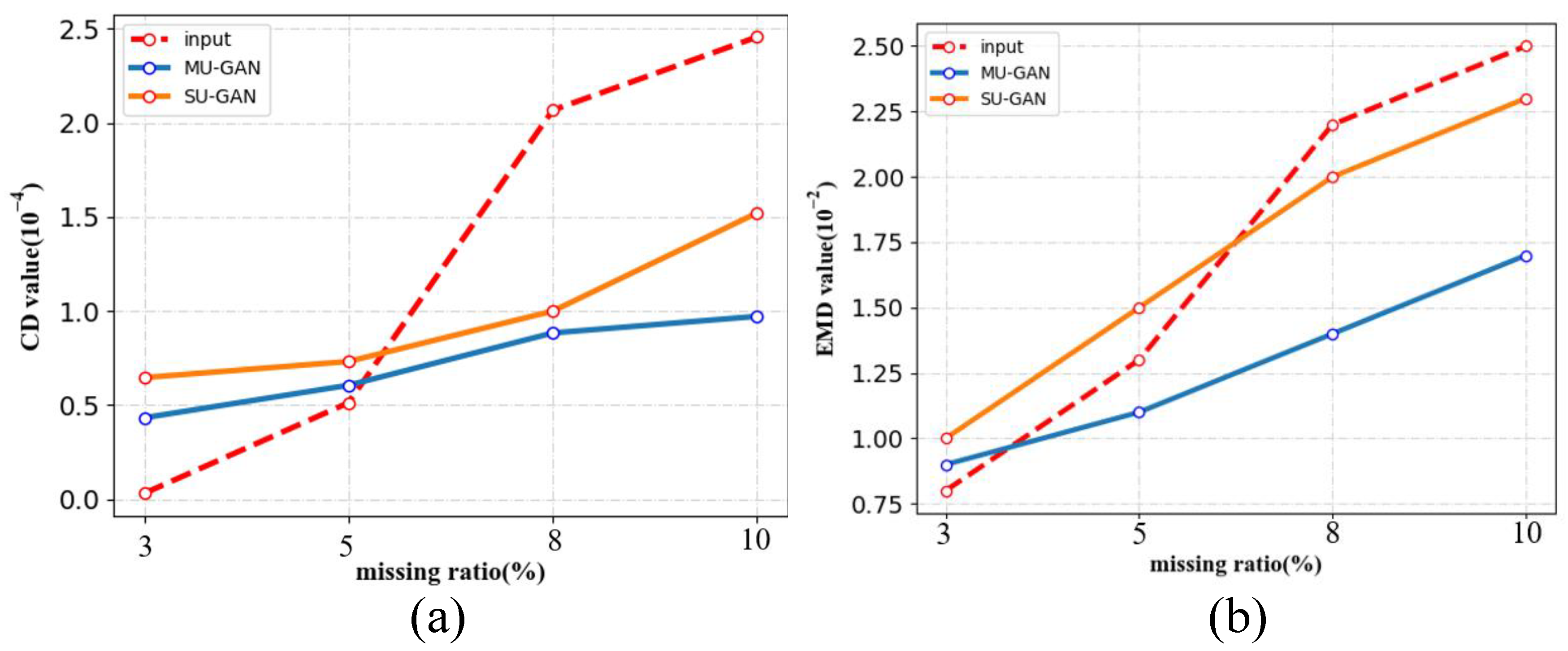
3.2. Evaluation Metrics
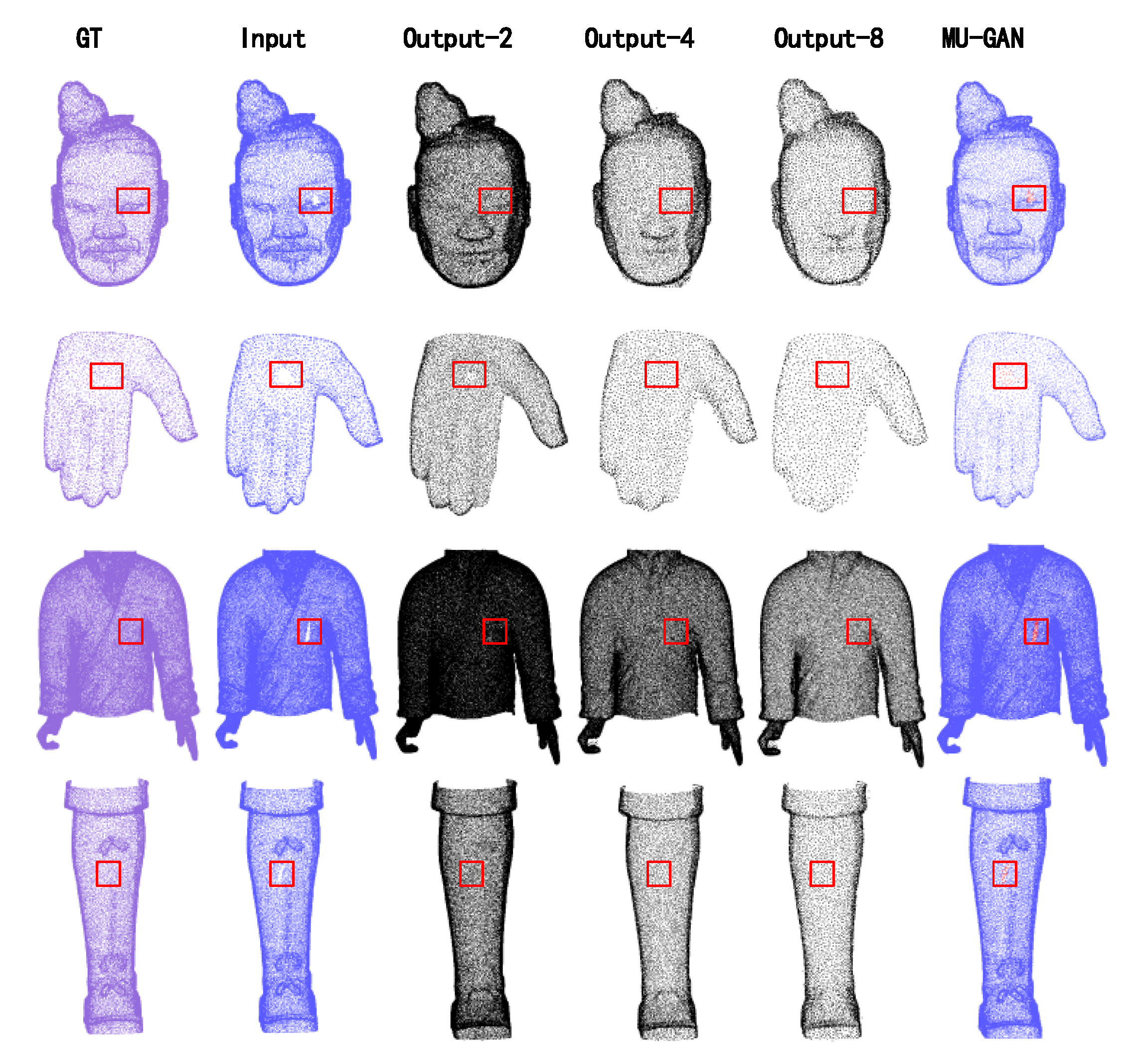
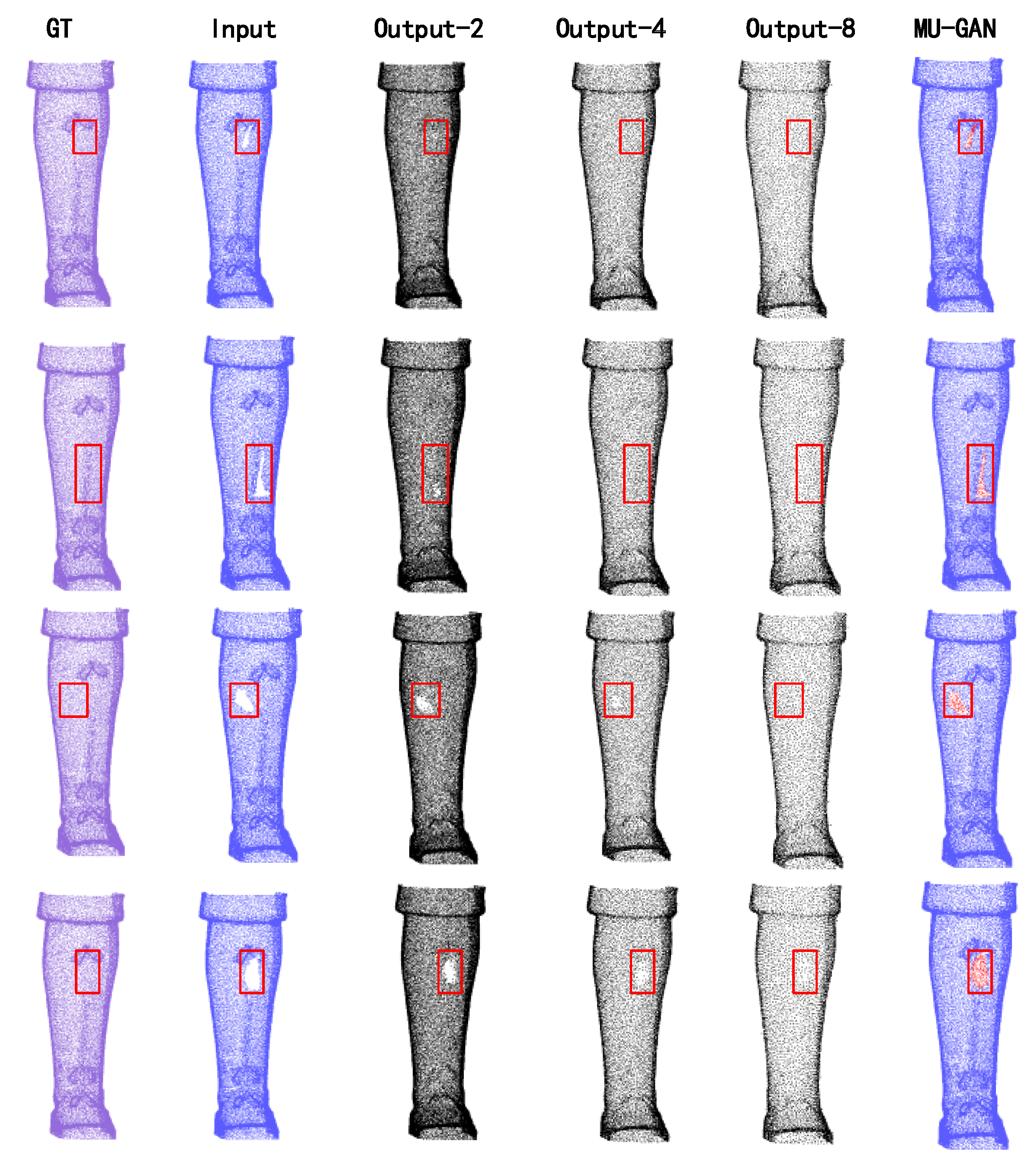
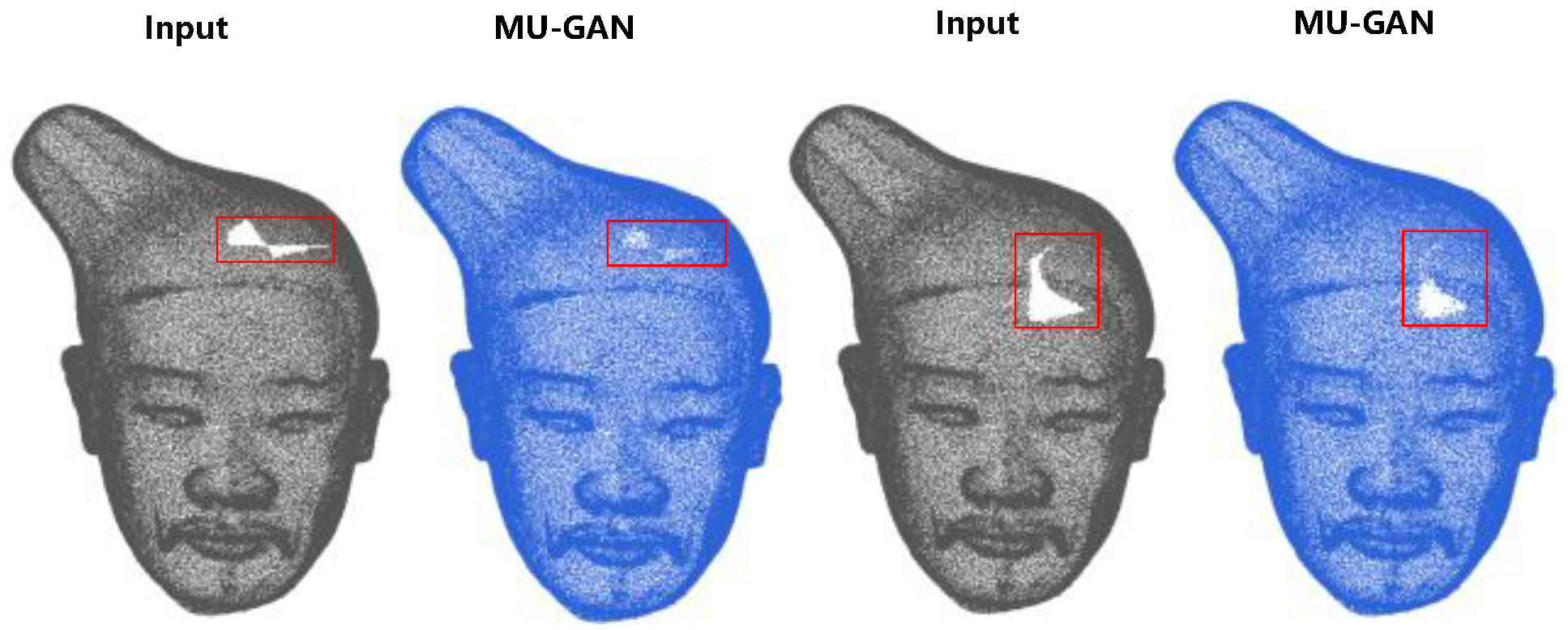
3.3. Experimental Results on MU-GAN
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fortes, M.A.; González, P.; Palomares, A.; Pasadas, M. Filling holes with shape preserving conditions. Math. Comput. Simul. 2015, 118, 198–212. [Google Scholar] [CrossRef]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing, Cagliari, Italy, 26–28 June 2006. [Google Scholar]
- Quinsat, Y. Filling holes in digitized point cloud using a morphing-based approach to preserve volume characteristics. Int. J. Adv. Manuf. Technol. 2015, 81, 411–421. [Google Scholar] [CrossRef]
- Wang, X.; Liu, X.; Lu, L.; Li, B.; Cao, J.; Yin, B.; Shi, X. Automatic hole-filling of CAD models with feature-preserving. Comput. Graph. 2012, 36, 101–110. [Google Scholar] [CrossRef]
- Zhao, W.; Gao, S.; Lin, H. A robust hole-filling algorithm for triangular mesh. Vis. Comput. 2007, 23, 987–997. [Google Scholar] [CrossRef]
- Attene, M. A lightweight approach to repairing digitized polygon meshes. Vis. Comput. 2010, 26, 1393–1406. [Google Scholar] [CrossRef]
- Sagawa, R.; Ikeuchi, K. Hole filling of a 3D model by flipping signs of a signed distance field in adaptive resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 686–699. [Google Scholar] [CrossRef] [PubMed]
- Sahay, P.; Rajagopalan, A. Geometric inpainting of 3D structures. In Proceedings of the Computer Vision and Patten Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–7. [Google Scholar]
- Chen, C.; Cheng, K. A Sharpness-Dependent Filter for Recovering Sharp Features in Repaired 3D Mesh Models. IEEE Trans. Vis. Comput. Graph. 2008, 14, 200–212. [Google Scholar] [CrossRef] [PubMed]
- Cignoni, P.; Callieri, M.; Corsini, M.; Dellepiane, M.; Ganovelli, F.; Ranzuglia, G. Meshlab: An open-source mesh processing tool. In Proceedings of the Eurographics Italian Chapter Conference, Salerno, Italy, 2–4 July 2008. [Google Scholar]
- Elshishiny, H.E.E.D.; Bernardini, F.; Rushmeier, H.E. System and Method for Hole Filling in 3D Models. U.S. Patent 7,272,264, 18 September 2007.
- Harary, G.; Tal, A.; Grinspun, E. Context-based coherent surface completion. ACM Trans. Graph. 2014, 33, 1–12. [Google Scholar] [CrossRef]
- Pauly, M.; Mitra, N.J.; Wallner, J.; Pottmann, H.; Guibas, L.J. Discovering structural regularity in 3D geometry. In Proceedings of the SIGGRAPH’08: International Conference on Computer Graphics and Interactive Techniques, Dallas, TX, USA, 11–15 August 2008; pp. 1–11. [Google Scholar]
- Fu, Z.; Hu, W.; Guo, Z. Point cloud inpainting on graphs from non-local self-similarity. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2137–2141. [Google Scholar]
- Fortes, M.A.; González, P.; Palomares, A.; Pasadas, M. Filling holes with geometric and volumetric constraints. Comput. Math. Appl. 2017, 74, 671–683. [Google Scholar] [CrossRef]
- Gai, S.; Da, F.; Liu, C. Multiple-gamma-value based phase error compensation method for phase measuring profilometry. Appl. Opt. 2018, 57, 10290–10299. [Google Scholar] [CrossRef] [PubMed]
- Hoang, V.-D.; Le, M.-H.; Hernández, D.C.; Jo, K.-H. Localization estimation based on Extended Kalman filter using multiple sensors. In Proceedings of the IECON 2013—39th Annual Conference of the IEEE Industrial Electronics Society, Vienna, Austria, 10–13 November 2013; pp. 5498–5503. [Google Scholar]
- Li, Y.; Geng, G.; Wei, X. Hole-filling algorithm based on poisson equation. Comput. Eng. 2017, 43, 209–215. [Google Scholar]
- Ngo, T.M.; Lee, W.S. Feature-First Hole Filling Strategy for 3D Meshes. In Proceedings of the Computer Vision, Imaging and Computer Graphics, Theory and Applications, Barcelona, Spain, 21–24 February 2013. [Google Scholar]
- Gai, S.; Da, F.; Dai, X. A novel dual-camera calibration method for 3D optical measurement. Opt. Lasers Eng. 2018, 104, 126–134. [Google Scholar] [CrossRef]
- Vokhmintcev, A.; Timchenko, M.; Alina, K. Real-time visual loop-closure detection using fused iterative close point algorithm and extended Kalman filter. In Proceedings of the 2017 International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Saint Petersburg, Russia, 16–19 May 2017; pp. 1–6. [Google Scholar]
- Gai, S.; Da, F.; Zeng, L.; Huang, Y. Research on a hole filling algorithm of a point cloud based on structure from motion. J. Opt. Soc. Am. A 2019, 36, A39–A46. [Google Scholar] [CrossRef] [PubMed]
- Dai, A.; Ruizhongtai Qi, C.; Nießner, M. Shape completion using 3d-encoder-predictor cnns and shape synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5868–5877. [Google Scholar]
- Nguyen, D.T.; Hua, B.-S.; Tran, K.; Pham, Q.-H.; Yeung, S.-K. A field model for repairing 3d shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5676–5684. [Google Scholar]
- Stutz, D.; Geiger, A. Learning 3d shape completion under weak supervision. Int. J. Comput. Vis. 2020, 128, 1162–1181. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Han, X.; Li, Z.; Huang, H.; Kalogerakis, E.; Yu, Y. High-resolution shape completion using deep neural networks for global structure and local geometry inference. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 85–93. [Google Scholar]
- Sharma, A.; Grau, O.; Fritz, M. Vconv-dae: Deep volumetric shape learning without object labels. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; pp. 236–250. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Huang, Q.; Wang, W.; Neumann, U. Recurrent slice networks for 3d segmentation of point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2626–2635. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning Representations and Generative Models for 3D Point Clouds. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 206–215. [Google Scholar]
- Yuan, W.; Khot, T.; Held, D.; Mertz, C.; Hebert, M. Pcn: Point completion network. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 728–737. [Google Scholar]
- Chen, X.; Chen, B.; Mitra, N.J. Unpaired point cloud completion on real scans using adversarial training. arXiv 2019, arXiv:1904.00069. [Google Scholar]
- Sarmad, M.; Lee, H.J.; Kim, Y.M. Rl-gan-net: A reinforcement learning agent controlled gan network for real-time point cloud shape completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 5898–5907. [Google Scholar]
- Yu, L.; Li, X.; Fu, C.-W.; Cohen-Or, D.; Heng, P.-A. Pu-net: Point cloud upsampling network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2790–2799. [Google Scholar]
- Yifan, W.; Wu, S.; Huang, H.; Cohen-Or, D.; Sorkine-Hornung, O. Patch-based progressive 3d point set upsampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 5958–5967. [Google Scholar]
- Li, R.; Li, X.; Fu, C.-W.; Cohen-Or, D.; Heng, P.-A. Pu-gan: A point cloud upsampling adversarial network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–17 June 2019; pp. 7203–7212. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ma, C.; Guo, Y.; Lei, Y.; An, W. Binary volumetric convolutional neural networks for 3-D object recognition. IEEE Trans. Instrum. Meas. 2018, 68, 38–48. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RL-GAN | PU-Net | Traditional | Our-SU | Our-Mu | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| CD | EMD | CD | EMD | CD | EMD | CD | EMD | CD | EMD | |
| head | 1.720 | 0.0915 | 1.710 | 0.0851 | 0.453 | 0.0883 | 0.788 | 0.0774 | 0.409 | 0.0728 |
| body | 1.160 | 0.0753 | 0.665 | 0.0734 | 0.385 | 0.0685 | 0.528 | 0.0707 | 0.294 | 0.0676 |
| arm | 1.940 | 0.0714 | 0.922 | 0.0742 | 0.218 | 0.0693 | 0.237 | 0.0688 | 0.208 | 0.0674 |
| leg | 1.050 | 0.0692 | 1.024 | 0.0628 | 0.918 | 0.0696 | 0.563 | 0.0603 | 0.458 | 0.0599 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Y.; Chu, T.; Jiao, Y.; Zhou, M.; Geng, G.; Li, K.; Cao, X. Multi-Scale Upsampling GAN Based Hole-Filling Framework for High-Quality 3D Cultural Heritage Artifacts. Appl. Sci. 2022, 12, 4581. https://doi.org/10.3390/app12094581
Ren Y, Chu T, Jiao Y, Zhou M, Geng G, Li K, Cao X. Multi-Scale Upsampling GAN Based Hole-Filling Framework for High-Quality 3D Cultural Heritage Artifacts. Applied Sciences. 2022; 12(9):4581. https://doi.org/10.3390/app12094581
Chicago/Turabian StyleRen, Yong, Tong Chu, Yifei Jiao, Mingquan Zhou, Guohua Geng, Kang Li, and Xin Cao. 2022. "Multi-Scale Upsampling GAN Based Hole-Filling Framework for High-Quality 3D Cultural Heritage Artifacts" Applied Sciences 12, no. 9: 4581. https://doi.org/10.3390/app12094581