1. Introduction
Chinese spelling errors are common in daily life, due to the similarity between characters. In Chinese, there are many characters similar in phonology and visual shape, but different in semantics. These spelling errors are typically caused by careless human writing, automatic speech recognition, or optical character recognition systems. Besides, misspellings are intentionally used by perpetrators to avoid automatic detection in current social platforms, such as spam broadcasting, malicious advertising, etc. Therefore, detecting and correcting such misuse of the Chinese language are important tasks in real-world applications. An effective method for CSC is not only useful in natural language tasks such as speech recognition, word recognition, and grammatical error correction but also has potential value in anti-spam problems such as fraud detection, advertisement detection, etc.
Unlike English, Chinese spelling error correction is a challenging task due to the characteristics of Chinese characters. Chinese texts consist of many pictographic characters without word delimiters. The semantic meaning of each character changes dramatically when the context changes. Besides, the pronunciation of a character depends on the context. In this sense, a CSC model is required to both understand the semantics and integrate the surrounding information (i.e., pronunciation, character structure).
Traditional methods have been employed for CSC. For example, previous works [
1,
2,
3] employed the traditional machine learning [
4,
5] and other deep learning models [
6]. Also, sequence-to-sequence models [
7] have been proposed for spelling error correction by transforming an input sentence into a new sentence with spelling errors corrected. Recently, several methods have been introduced to exploit external information of character similarity, which rely on a human-defined confusion set [
7,
8]. The confusion set is a dictionary containing similar character pairs. In ACL 2019, confusion set-guided Pointer Networks [
7] used a pointer network to copy similar characters from the confusion set. In ACL 2020 [
8] a spelling check convolutional graph network was presented by constructing similarity graphs using the confusion set. These methods attempt to model the relationship between characters based on the confusion set. However, the similarity information extracted from the confusion set is limited. The confusion set only provides information about whether two characters are similar, but does not present phonological and visual features of Chinese characters. Furthermore, a human-defined confusion set only covers a small subset of Chinese characters due to the human annotation, which can hardly correct the misspellings of unknown characters.
Addressing the problems of human annotation and unknown characters, we propose Feature Enhanced BERT (FE-BERT) to integrate phonological and visual similarity for CSC without using a confusion set. Specifically, we construct a glyph graph over Chinese characters for capturing the shape similarity between characters, by leveraging the intrinsic component structure of Chinese characters. Instead of similar character pairs set by human annotation to capture the shape similarity, our glyph graph requires no human annotation. Furthermore, the glyph graph utilizes the decomposition structure of Chinese characters, which can cover more characters compared to the confusion set. The glyph graph is pre-trained to generate a vector representation for each character as its shape feature. Combining the shape and pronunciation features with BERT [
9], FE-BERT can adequately leverage the similarity knowledge and generate the right corrections accordingly. Considering spelling errors which are visually and phonologically irrelevant, we adopt a siamese structure to combine a vanilla BERT and a FE-BERT, namely FES-BERT. As depicted in
Table 1, FES-BERT can completely correct the spelling errors led by both the pronunciation similarity and the shape similarity.
Experimental results on benchmark datasets and our error type balanced CSC dataset show that our model outperforms BERT and previous state-of-the-art models [
7,
8,
9,
11,
12]. In summary, our contributions are as follows:
We construct a novel glyph graph to model visual similarity between Chinese characters by leveraging the intrinsic component structure of Chinese characters. This method can cover almost all Chinese characters without the need for a confusion set or human annotation.
For fair and comprehensive performance evaluation, we build a new CSC dataset in which the amount of samples in different error types is the same. Half of the errors in the test set are included by the confusion set used by [
8] while the others are outside the confusion set. Besides, to evaluate performance on new errors, half of the errors in the test set are not included in the training set.
We incorporate phonological and visual features for CSC and reach a balance between Chinese characters’ external features and semantic features via the proposed FES-BERT. Experimental results show that our model achieves better performance compared to previous SOTA models.
3. Approach
In this section, we describe the CSC task and introduce the Feature-enhanced Siamese BERT (FES-BERT) which is able to jointly learn contextualized representations of characters’ shape, pronunciation, and semantic features.
3.1. Problem Formulation
Chinese Spelling Check can be formalized as a generation problem by modeling the probability . Given a text sequence of l characters containing misspelled characters, the goal of our task is to transform the input sentence into a correct text sequence in which the wrong characters are recognized and corrected.
3.2. Model Overview
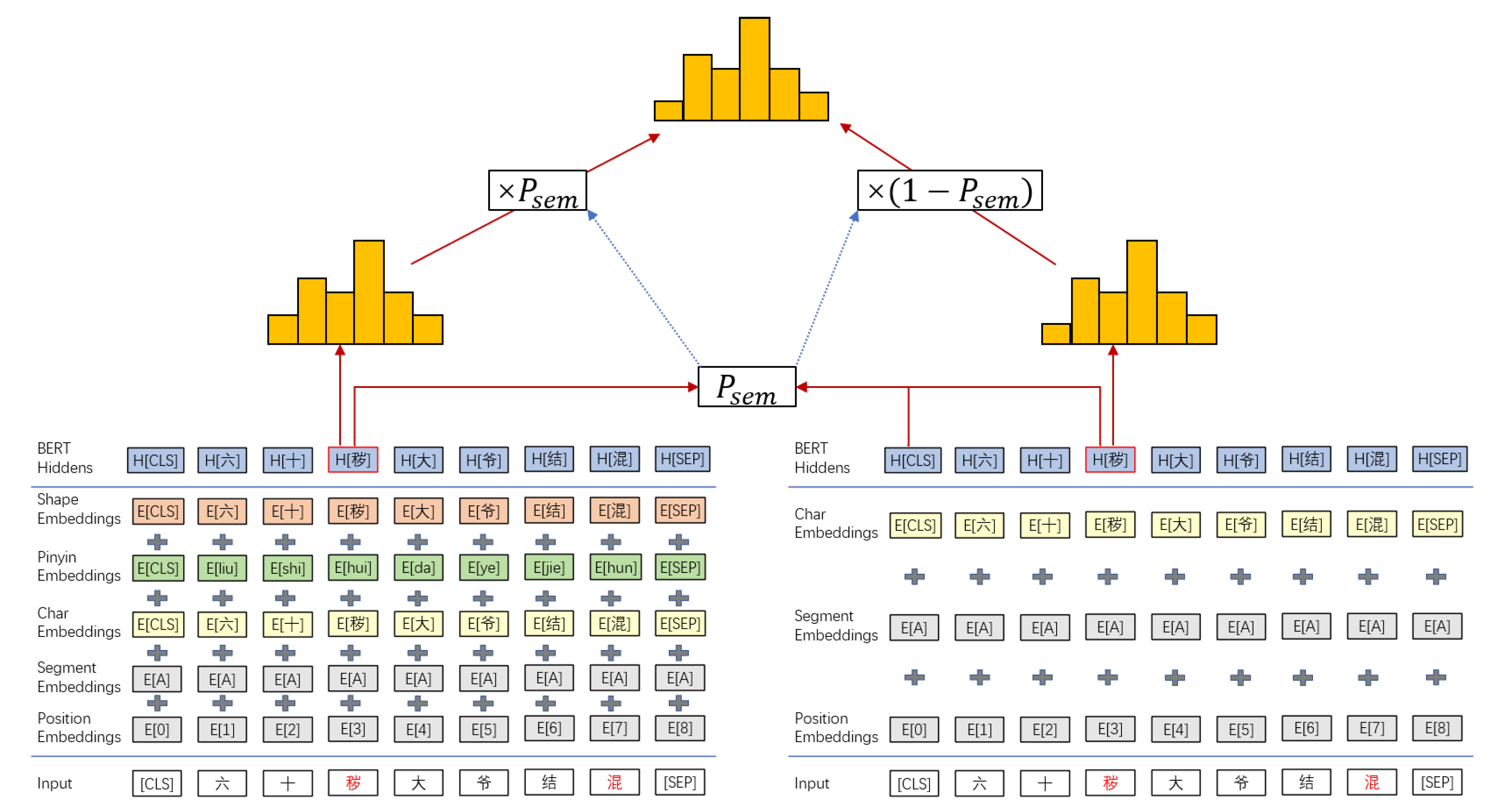
The framework of the proposed method is depicted in
Figure 1. It consists of two components, i.e., a Feature-enhanced BERT (FE-BERT) for visual and phonological errors and a vanilla BERT for visually and phonologically irrelevant typos. The prediction results of the BERT and the FE-BERT are summed up through a dynamic soft pointer to reach a balance between semantic constraints and external feature constraints. The details are shown in Algorithm 1.
More specifically, shape embeddings for visual features and pronunciation embeddings for phonologically features of each character are provided for the Feature-enhanced BERT as clues for selecting the best candidate. Shape embeddings of all Chinese characters are retrieved from a Chinese character glyph graph. In the glyph graph, Characters with the same components in the structure are connected and the edges are given different weights in terms of the number of character strokes and node neighbors. The pronunciation embeddings are initialized according to Chinese Pinyin, which serves as a romanization system providing phonetic-based information for Chinese characters.
In the following subsections, we describe (1) the Feature-enhanced BERT(FE-BERT) for errors similar in pronunciation or shape. (2) the combination of BERT and FE-BERT.
| Algorithm 1 The Feature-enhanced Siamese BERT |
Input: Chinese characters Output: The corrected characters - 1:
Construct the glyph graph G according to structure information of Chinese characters. - 2:
Pre-train the glyph graph G to generate the shape embedding: - 3:
Randomly initialize the pronunciation embedding: - 4:
Token embeddings - 5:
Segment embeddings - 6:
Position embeddings - 7:
- 8:
- 9:
- 10:
- 11:
|
3.3. Glyph Graph
3.3.1. Shape Embeddings for Visual Features
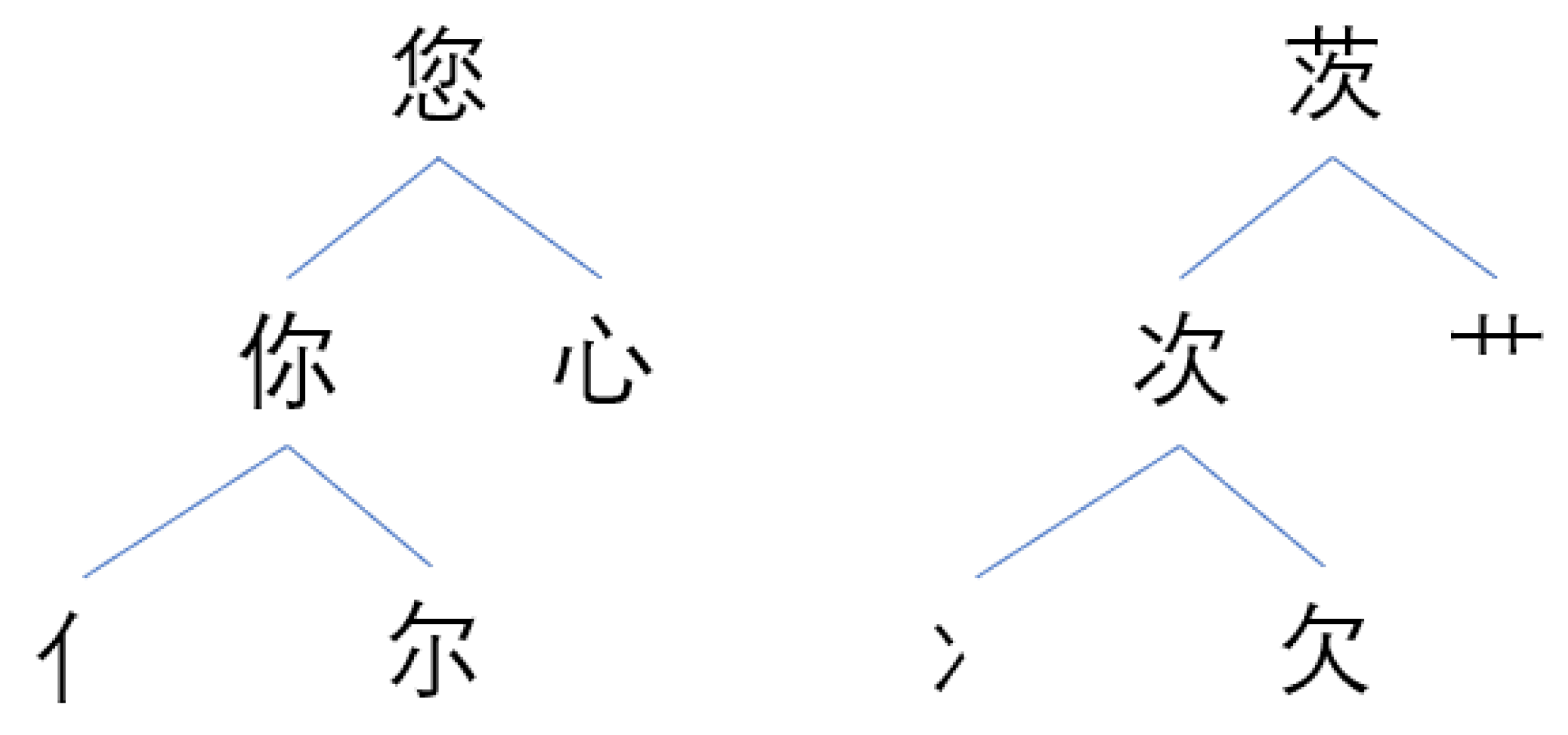
We retrieve shape embeddings for Chinese characters from a glyph graph. As illustrated in
Figure 2, Chinese characters can be repeatedly disassembled until the structure can not be subdivided. For example, character “您” can be divided into “你” and “心”, while “你” can be split into “亻” and “尔”. The same is true for character “茨”. Although the shapes of Chinese characters are different from others, they share common basic components which are also Chinese characters.
The structure information of characters are labeled by the Kanji Database Project (
http://kanji-database.sourceforge.net/, accessed on 12 September 2021). The shape information of Chinese characters is represented by unicode standard—Ideographic Description Sequence (IDS). For example, character “您” is represented as “U+60A8 您你心”, while character “你” is represented as “U+4F60 你亻尔”. As illustrated in
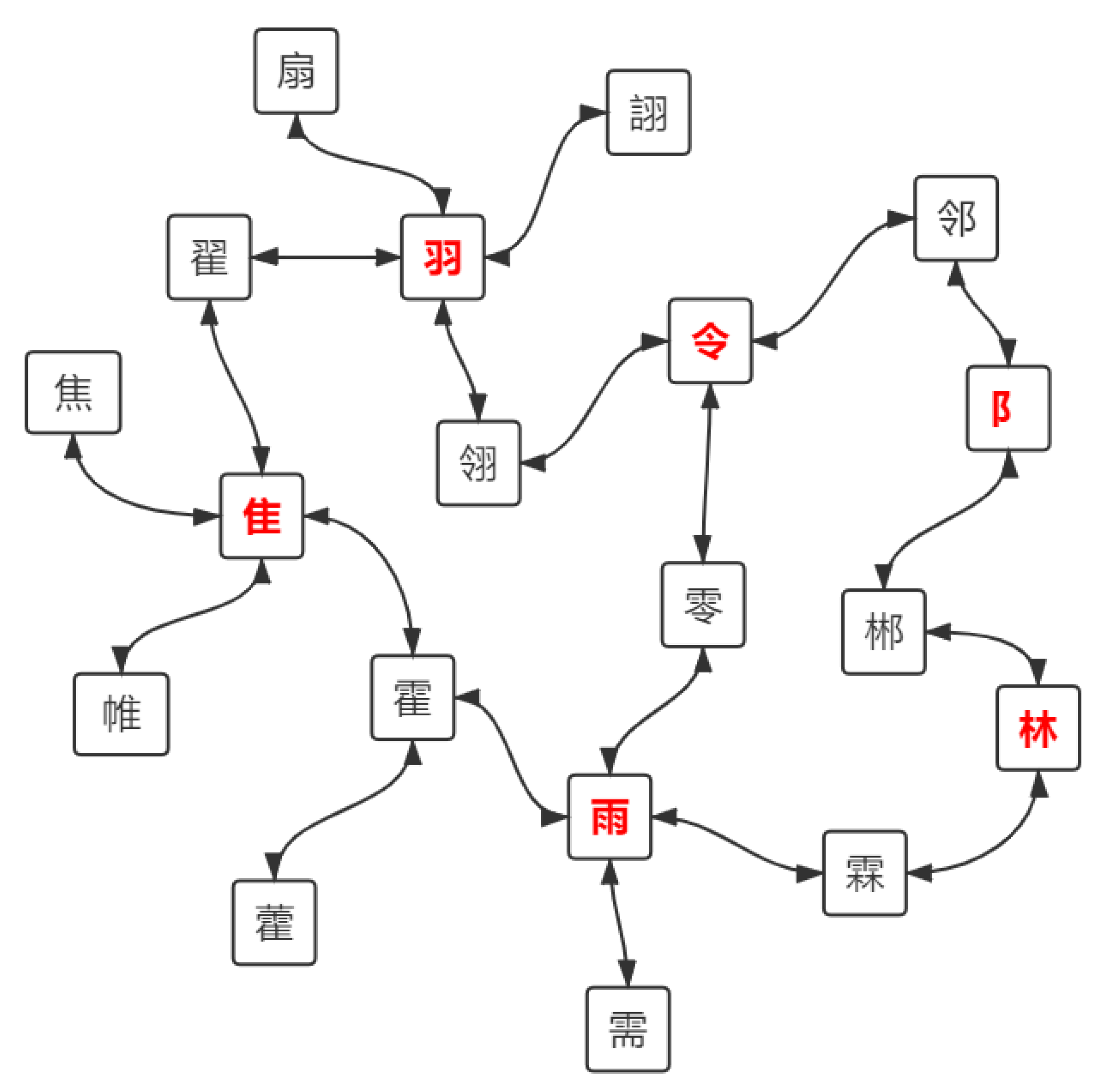
Figure 3, we build the glyph graph according to IDS labels of Chinese characters by connecting characters and their sub-components.
Table 2 shows some statistics of the glyph graph.
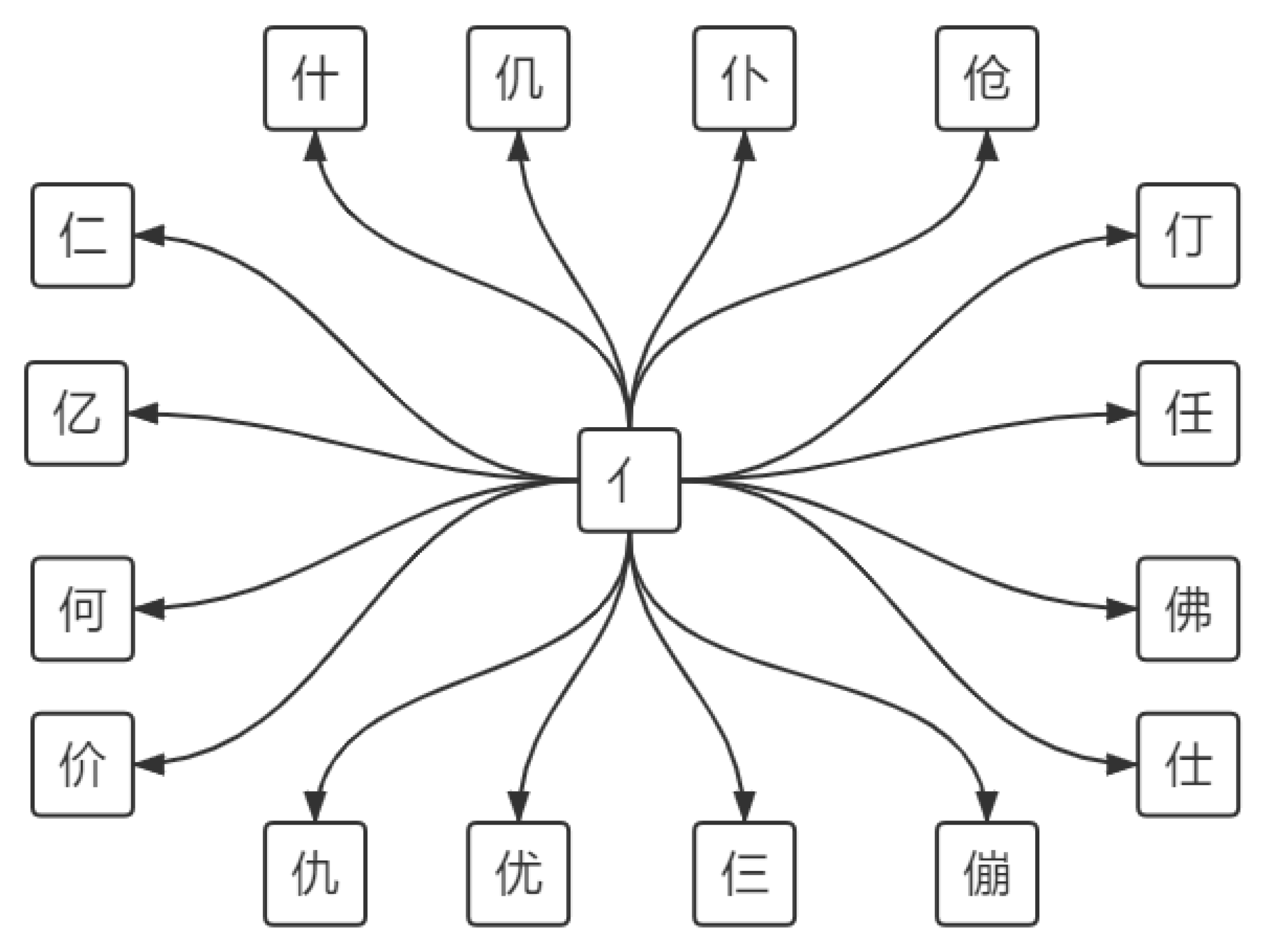
Considering that different character pairs have different similarity degrees and need to be distinguished, we make the glyph graph directed and weighted in terms of the number of strokes and the neighbors of graph nodes.
Figure 4 shows an extreme situation that a frequently-used radical “亻” connects to 1758 characters. This indicates why the number of neighbors should be considered when setting up the edge weights. These characters sharing the same radical “亻” are similar, but their similarities should be different from each other. If every node is connected equally without weights, the characters connected by “亻” will be similar to each other with the same degree, which is not true. Besides, the number of character strokes is also important. Connected characters with closer stroke numbers may look more similar than others, such as character pair “仁” and “仨” are more similar compared to pair “亻” and “仁”.
Let
denote the graph where
denote all Chinese characters,
denotes the weight of edge
pointing to character
from character
. Let
denote the number of strokes of character
,
denote the number of neighbors of character
. The edge weight
is defined in Formula (
1). The 0.5 in the denominator is to avoid dividing by zero.
3.3.2. Shape Embeddings
Node2vec [
19] algorithm is adopted to retrieve shape representations for characters in the glyph graph. Node2vec is an extension of the Word2vec [
20] algorithm, which can generate vector representations of nodes on a graph. It follows the intuition that random walks through a graph can be treated like sentences in a corpus. A random walk is treated as a sentence and each node in the walk is treated as a word. By applying Word2vec algorithms such as skip-gram or continuous bag of words model on these “sentences”, the algorithm generates shape embeddings for all nodes in the glyph graph. Visualization results of shape embeddings will be shown in
Section 4.6.
It should be emphasized that the purpose of the glyph graph is not to directly learn the similarity between characters, but to learn the structure information of characters. Therefore models using these shape embeddings can learn structure relation from error pairs similar in shape and make corrections under the guidance of visual features.
3.4. Pronunciation Embeddings Phonological Features
Pinyin is an official romanization system for Standard Chinese, which provides phonetic-based information for Chinese characters. The word “Pinyin” literally means “spelled sounds”. In the Pinyin system, each character has one syllable, which consists of three components: an initial (consonant), a final (vowel), and a tone [
21]. There are thousands of Chinese characters sharing hundreds (402) of Pinyin codes with different tones. Following [
22], we ignore the tones here because the pronunciation of characters can already be regarded as similar if the initial (consonant) and final (vowel) of Pinyin are the same. Pinyin itself is already a mature representation of phonological features of Chinese characters. Different from shape embeddings retrieved by graph-based algorithm, the pronunciation embeddings are initialized randomly according to the Pinyin codes of characters and updated during the training phase. Case analysis results show that pronunciation embeddings can deliver phonological information and help the model to make correct predictions in phonological constraints.
3.5. Feature-Enhanced BERT
We use a Feature-enhanced BERT (FE-BERT) to deal with spelling errors with similar pronunciations or shape. Compared to original BERT, FE-BERT requires two more embeddings as input: shape embeddings for visual features and pronunciation embeddings for phonetic features. Let denote the Pinyin embeddings, denote the glyph embeddings. “M” is the number of Pinyin codes for Chinese characters’ pronunciation, “N” is the number of Chinese characters.
The input sentence is converted to a sequence of embeddings that are constructed by summing up token, segment, position, shape, and pronunciation embeddings. For characters in the text sequence
, BERT is used to retrieve the corresponding output representations
. A visualization of this construction is shown in
Figure 1.
3.6. Feature-Enhanced Siamese BERT
On one hand, the existence of external features can be the guidance to correct visually and phonologically related errors. On the other hand, the external features may be useless or even harmful when it comes to visually and phonologically irrelevant spelling errors. To reach a balance between semantic constraints and external feature constraints, and to fully leverage the reasoning capacity of the pre-trained BERT, we combine the prediction results of an original BERT and the FE-BERT through a dynamic pointer .
For character
in the input sequence, there is a purely semantic vector representation
from BERT and another vector representation
mixed with external features from FE-BERT. The dynamic pointer
to combine
and
is dependent on
,
and
, where
is the representation for token “[CLS]” from BERT. The final probability for each candidate is defined as
where
and
are trainable parameters. The predicted character
at position
i is the character with the max probability
. Finally, the learning objective is to maximize the log likelihood of target characters:
4. Experiments
4.1. Datasets
SIGHAN Datasets. The training datasets are composed of three benchmark datasets [
10,
23,
24] for CSC, which has 10 k training samples in total. The SIGHAN datasets are collected from the Chinese essay section of Test for foreigners. The corresponding test datasets from SIGHAN 2013, SIGHAN 2014, SIGHAN 2015 are used to evaluate the performance of the proposed method. The characters are converted to simplified Chinese from traditional Chinese using OpenCC (
https://github.com/BYVoid/OpenCC, accessed on 11 December 2021). Following [
7,
8], we include additional 271 K samples as the supplementary training materials, which are generated by an automatic method [
7]. Statistics of the SIGHAN datasets are listed in
Table 2.
Error Type Balanced Dataset. SIGHAN are real-world datasets generated by the modification of international students’ compositions, they reflect the real situation in practice. However, they might not be fully capable to evaluate CSC models accurately and comprehensively because: (1) The scale of SIGHAN datasets is too small. There are only 1k sentences in the SIGHAN15 test dataset. (2) The errors in SIGHAN datasets are mainly spelling errors in similar pronunciations. Errors in similar shapes and errors which are visually and phonologically irrelevant are not included. (3) Most spelling errors in current benchmark datasets are leaked to CSC models through widely-used auto-generated datasets in training process. The ability to handle unseen new errors of CSC models is never evaluated. To handle these issues, we construct a relatively large-scale Error Type Balanced Dataset.
We repartition the auto-generated 271K samples dataset and modify the spelling errors to build an error-type balanced dataset. There are four kinds of errors defined by character’s similarity: similar only in shape, similar only in pronunciation, similar in both shape and pronunciation, and not similar in shape nor pronunciation. Besides, it is also necessary to evaluate errors that are not included in the confusion set. If character
is misspelled as
in training materials, the error pair
is defined as “seen” by CSC models in training phase. In the test dataset, there are spelling errors not seen by CSC models in the training materials. This is to evaluate the performance on new errors. Statistics of the Error Type Balanced Dataset are listed in
Table 3.
4.2. Baselines
We compare our method with several strong baselines.
PN [
7]: This method copies candidate characters from a confusion set by Pointer Network [
25].
FASpell [
11]: FASPell is a new paradigm for CSC which consists of a denoising autoencoder (DAE) and a decoder. Candidate characters are retrieved by a pre-trained masked language model and a specialized decoder utilizing the salient feature of Chinese character similarity is used to select the best candidate.
BERT-Embed [
9]: The word embeddings are used as the softmax layer on the top of BERT for the CSC task. This method served as a baseline in [
9].
BERT-Linear [
9]: The original BERT without shape or phonological features. A pre-trained linear layer is used to make predictions over hidden states of the last layer of BERT.
Spell-GCN [
8]: Phonological and visual similarity knowledge is integrated into language models for CSC via a specialized graph convolutional network (SpellGCN).
Soft-Masked BERT [
12]: This model consists of a network for error detection and a network for error correction based on BERT, with the former being connected to the latter with a “soft-masking” technique.
4.3. Hyper-Parameters
Our implementation is based on the repository of pytorch-transformers (
https://github.com/huggingface/pytorch-transformers, accessed on 12 November 2021). The BERT model pre-trained by huggingface (
https://huggingface.co/, accessed on 12 November 2021) is used in our experiments. We fine-tune the models using AdamW [
26] optimizer with Stochastic Weight Averaging (SWA) [
27] for 3 epochs with a batch size of 32 and a learning rate of 5 × 10
.
When training shape embeddings using Node2vec algorithm on the glyph graph, the return parameter p and the in-out parameter q are 1 and 8, respectively; the length and number of walk per source are 3 and 300; the context size for optimization is 2. We force the Node2vec algorithm to concentrate on neighbors which are characters with the same components by setting the context size and walk length small and the in-out parameter q large.
4.4. Main Results
Table 4 shows experimental results of the above methods on three SIGHAN datasets. The FES-BERT equipped with shape and phonic features achieves better performance against vanilla BERT and SpellGCN on most metrics of SIGHAN datasets. In terms of sentence-level F1 score metric in the correction subtask, i.e., C-F score in the last column, the improvements against previous best results (Spell-GCN) are 3.3%, 1.5%, and 0.2% points respectively. In terms of character-level F1 score metric in the correction subtask, the improvements against SpellGCN are 2.0%, 0.1%, and −0.1%, respectively. This demonstrates the effectiveness of our proposed method on benchmark datasets.
Table 5 exhibits model performance on different kinds of spelling errors, which are respectively about pronunciation, shape, and others. There are four situations for a CSC model to correct a spelling error according to whether the error pairs are in the confusion set and whether the error pairs have been seen in training materials. For errors in both train and test datasets, SpellGCN and FES-BERT reach close scores on the sentence level F1 metrics while the latter has a small advantage. For new errors that only exist in the test dataset, the FES-BERT achieves a large advantage on the sentence level F1 metrics. This demonstrates that FES-BERT has a better generalization performance than SpellGCN and BERT. For errors that are new but included in the confusion set, SpellGCN achieves an obvious advantage over vanilla BERT. This indicates that it is helpful to collect error characters into a confusion set.
4.5. Ablation Studies
In this section, we analyze the effect of shape embeddings and pronunciation embeddings on SIGHAN15. We trained FES-BERT with only pronunciation embeddings or shape embeddings as an external feature. The experimental results on SIGHAN15 can be seen in
Table 6.
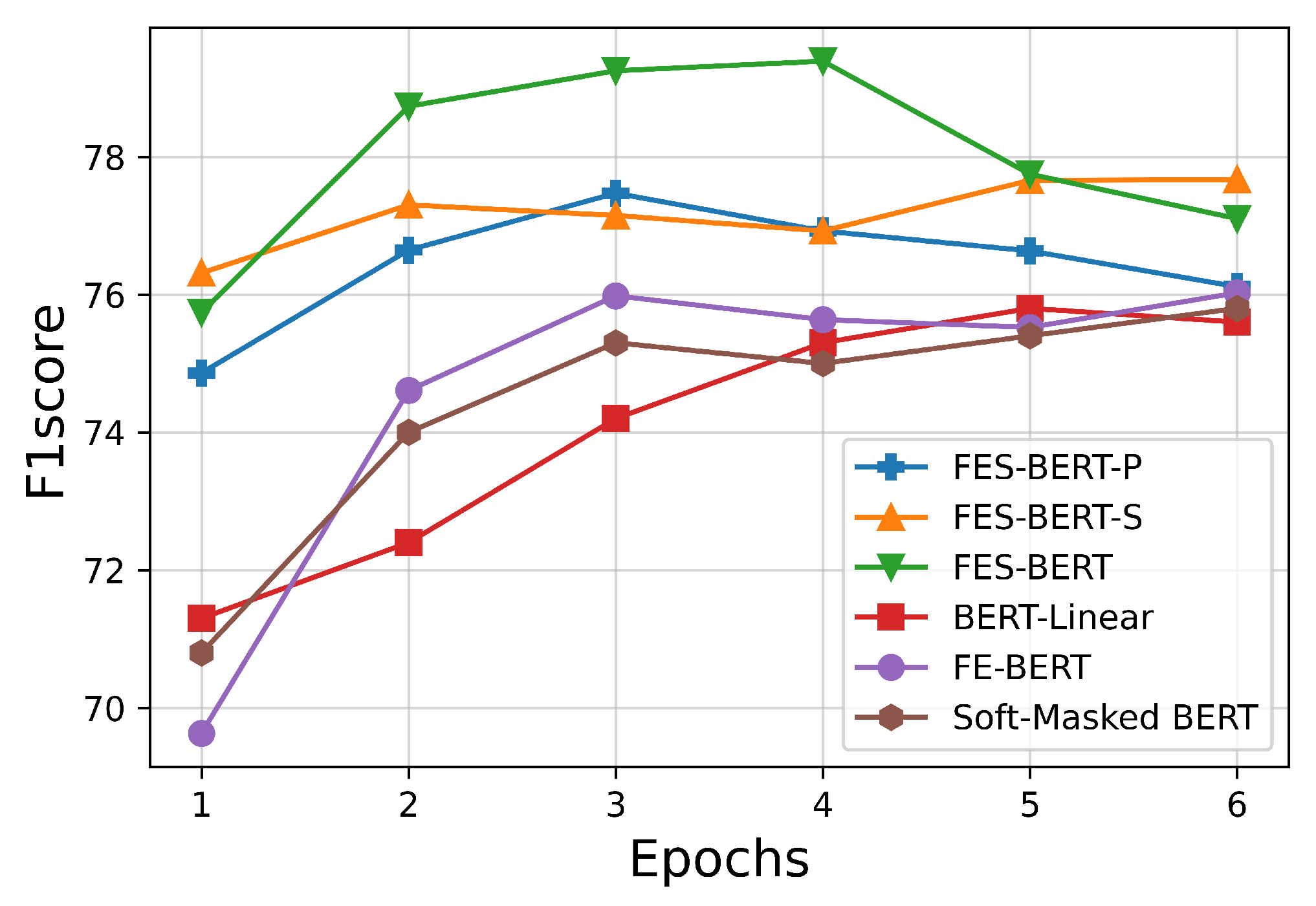
Figure 5 shows the test curves of FES-BERT-S, FES-BERT-P, FES-BERT, BERT-Linear, FE-BERT, and Soft-Masked BERT.
Compared to vanilla BERT, the FES-BERT with additional features converges rapidly in less than four epochs. In terms of sentence-level F1 score metric in the correction subtask at epoch 3, the improvements of FES-BERT-S, FES-BERT-P, and FE-BERT against the original BERT (BERT-Linear) are 2.9%, 3.3%, and 1.8%, respectively. In terms of character-level F1 score metric in the detection subtask, the improvements of FES-BERT-S, FES-BERT-P, and FE-BERT against the original BERT are 3.9%, 4.7%, and 1.8%, respectively. All three models achieve better performance on all metrics than to the original BERT. This indicates that both pronunciation and shape features are necessary to correct Chinese spelling errors. Models with the siamese structure achieve higher scores than FE-BERT, which means the siamese structure is also important for correcting spelling errors.
4.6. Case Study
We show several spelling error cases either similar in shape or similar in pronunciation in
Table 7. There are more than one semantically appropriate candidate characters for these cases, which means information of pronunciation and shape is necessary to make further judgments.
For sentences with error characters in similar shapes, such as “他们计划舂(chong)天去爬山。”, the corresponding correct sentence is “他们计划春(chun)天去爬山。(They plan to climb mountains in spring.)”. The Chinese character “ 春(chun)” is misspelled as “ 舂(chong)” in a similar shapes. There are several semantically appropriate candidate characters such as “秋(qiu)”, “春(chun)” and “明(ming)”. It is reasonable in semantics for BERT to correct the sentence to “他们计划明(ming)天去爬山。(They plan to climb mountains tomorrow.)” or “他们计划秋(qiu)天去爬山。(They plan to climb and mountains in autumn.)”. However, both 明(ming) and 秋(qiu) are not consistent with the shape constraints of 舂(chong). The errors are easy to detect but difficult to correct for vanilla BERT with only semantic information. However, the FES-BERT can find the best candidates “春(chun)” according to the shape constraints from shape embeddings of character “舂(chong)”. The same is true for character pair “愁(chou)” and “秋(qiu)”. SpellGCN also makes correct predictions in the case of “舂” and “春“ which are in the character pairs of the confusion set. However, SpellGCN fails to correct “轻哽(geng)卡车” to “轻便(bian)卡车” because character pair “哽(geng)” and “便(bian)” are not in the confusion set, which means “哽(geng)” and “便(bian)” are considered similar by Spell-GCN.
For sentences with error characters in similar pronunciations, FES-BERT can also make correct predictions according to phonic features. For example, in sentence “围这(zhe)他的摄影师将近二百三十人。”, “这(zhe)” is an error character with similar pronunciations but different shapes compared to “着(zhe)”. FES-BERT corrects “围这(zhe)” to “围着(zhe)”, while BERT and SpellGCN corrects “围这(zhe)” to “围攻(gong)” and “围堵(du)” according to semantic constraints. For spelling errors “埔(bu)办” and “琥(hu)区”, both FES-BERT and SpellGCN predict correct answers “补(bu)办” and “虎(hu)区” according to character pronunciation while the original BERT makes error predictions “举(ju)办” and “误(wu)区”, which are misled by the semantic context.
The Soft-Masked BERT corrects both “舂(chong)天” and “愁(chou)天” into “秋(qiu)天”. The reason may be that the soft masks avoids the influence of original error characters. Besides, it is worth mentioning that most spelling errors can be corrected by BERT according to semantic information without other features. If the error pair in input sentence has appeared in the training materials, BERT can make correct predictions easily.
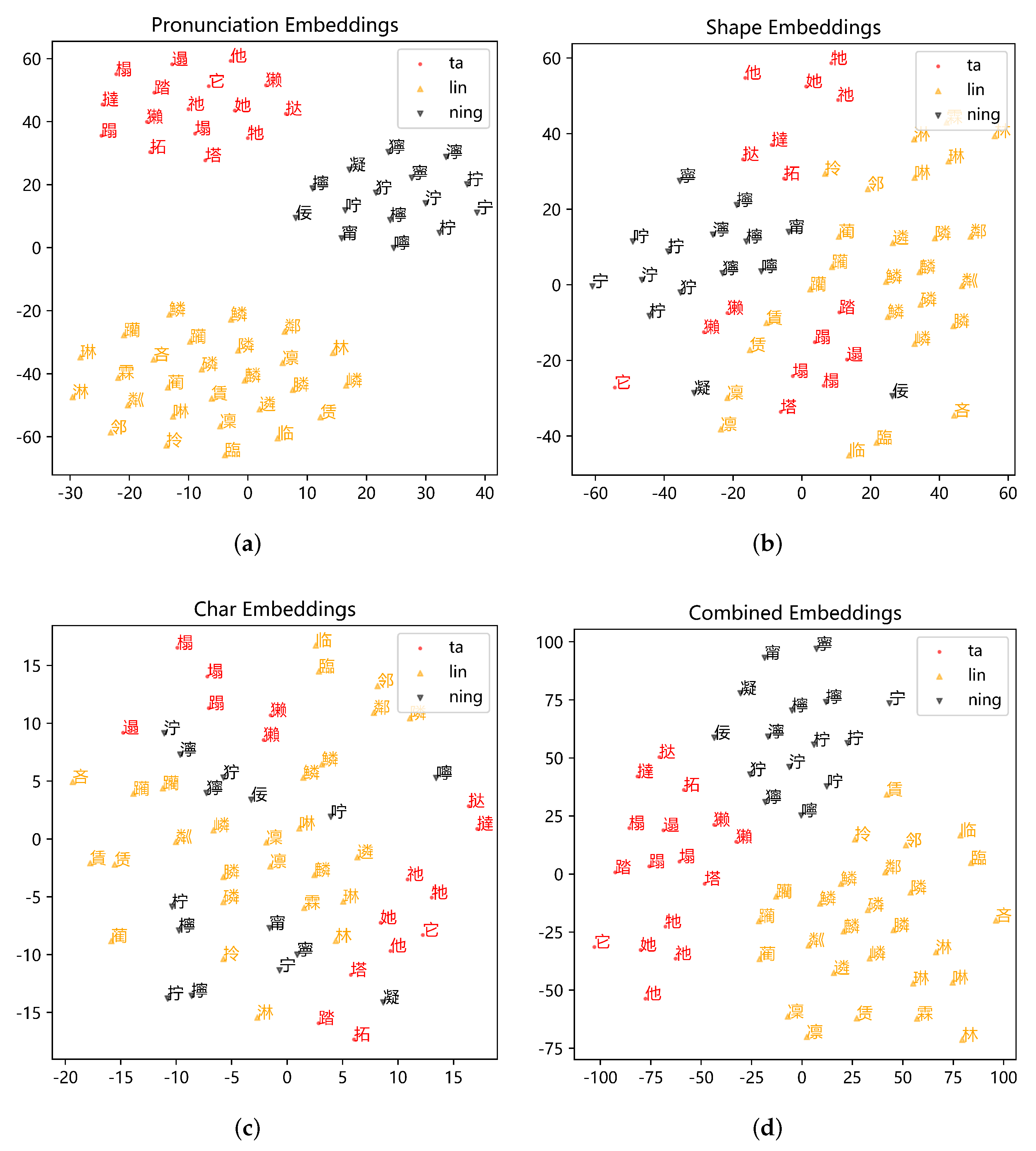
4.7. Visualization of Embeddings
Figure 6 shows visualization results of embedddings by t-SNE [
29]. Characters with Pinyin “lin”, “ning”, or “ta” are presented in the figure.
Figure 6a shows visualization results of pronunciation embeddings. Characters with different pronunciations are separated easily. The reason is that characters with similar pronunciations in the graph share the same Pinyin codes (without tone), so their phonological features are represented by the same pronunciation embedding.
Figure 6b shows visualization results of shape embeddings, in which the similar characters in terms of shape are placed together. For example, characters “宁柠拧泞咛” with common components “宁” are located closer to each other than other characters. This indicates the shape embeddings retrieved from the glyph graph do contain structure information of Chinese characters and can be used to measure the similarity of characters in shape.
Figure 6c shows visualization results of BERT token embeddings. Characters in
Figure 6c do not gather together either by shape or sound. Embeddings of original BERT failed to capture similarity information in terms of shape or pronunciation.
Figure 6d shows visualization results of embeddings which are the sum of shape, pronunciation, and BERT char embeddings. In
Figure 6d, characters with similar shapes and similar pronunciations exhibit cluster patterns in an obvious trend. The characters with similar shapes such as “遴磷麟鳞膦” or “他她地” are placed closely from each other. Characters with similar pronunciations exhibit the same phenomenon, are also closely. Characters with both similar shapes and similar pronunciations are placed closer than those with only one similar feature. For example, “遢榻拓” are characters with the same pronunciation, so these three characters are closer than other words. Meanwhile, “遢榻” looks more similar than “塌拓”, so “遢榻” are closer than “塌拓” in
Figure 6d. Due to this property, the feature-enhanced model may tend to recognize the similarity between characters and is able to search for answers with shape or pronunciation constraints.
5. Conclusions
We incorporate shape and pronunciation features of Chinese characters into BERT language models, and a good balance between semantic constraints and Chinese characters’ external feature constraints is reached via a siamese model structure. A novel and efficient graph-based method is introduced for retrieving shape features of Chinese characters. The proposed method achieves better experimental results compared to previous SOTA models SpellGCN and Soft-Masked BERT. Case studies compared to the original BERT, SpellGCN, and Soft-Masked BERT show that our model is able to search candidate characters more accurately with the constraints of shape and pronunciation. For more effective development and evaluation of CSC methods, we built an error type balanced dataset by repartitioning the auto-generated 271K CSC dataset and modifying the types of spelling errors.
As for future work, we plan to develop an end-to-end CSC system based on the glyph graph and explore models with more powerful reasoning capabilities through external features of characters, instead of simply “remembering” spelling errors that appeared in the training materials.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}