
Multi-Aspect Oriented Sentiment Classification: Prior Knowledge Topic Modelling and Ensemble Learning Classifier Approach


Abstract
:1. Introduction
2. Related Work
2.1. Multi-Aspect Topic Modelling for Aspect Extraction (Prior Knowledge Models)
2.2. Sentiment Lexicon Classification
2.3. Ensemble Learning Method
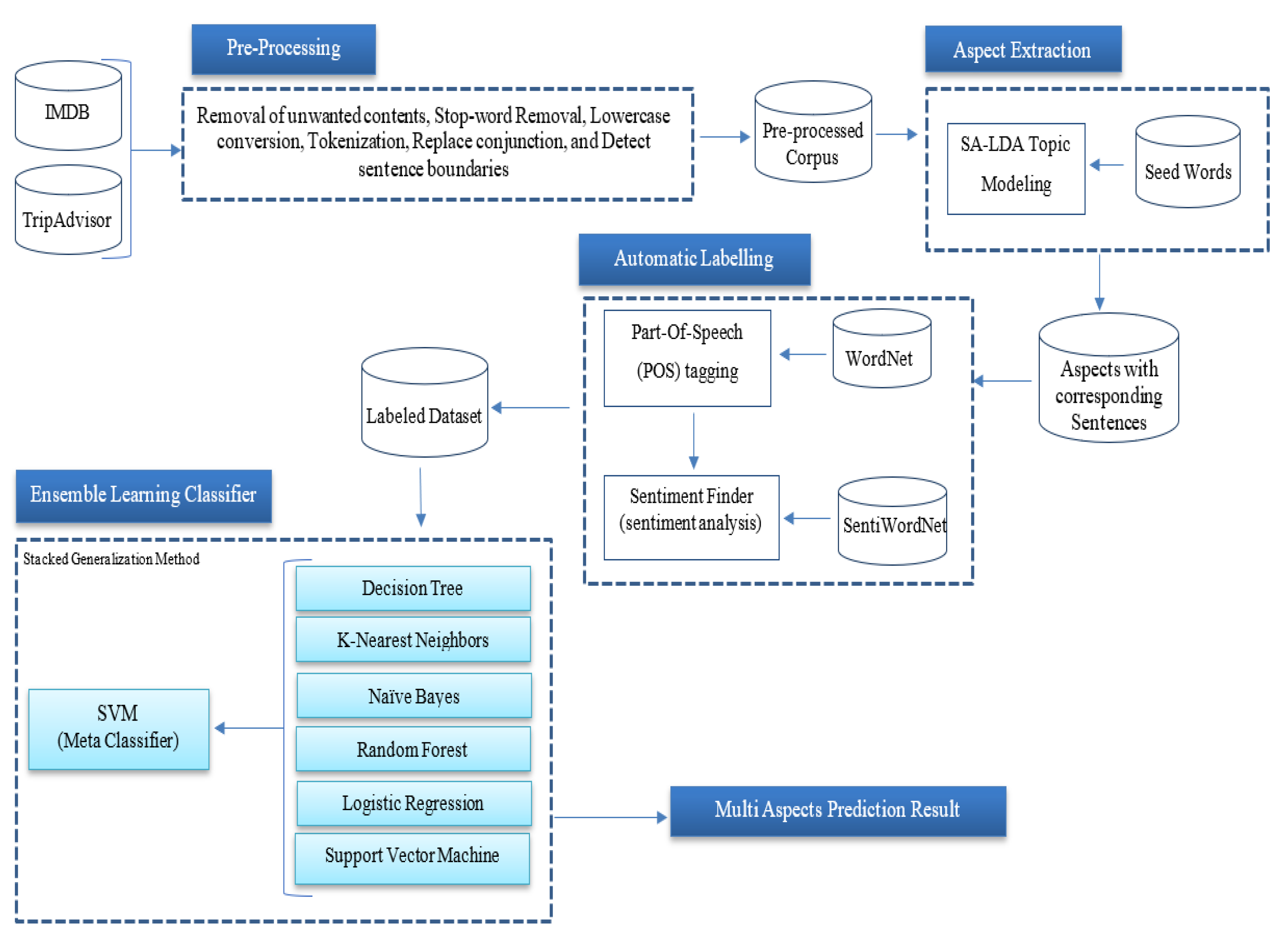
3. Materials and Methods
3.1. Dataset and Pre-Processing
| Algorithm 1: Algorithm for data collection and pre-processing |
| Input: Online reviews () Output: Cleaned reviews () For each Review in , where = 1, 2, 3, 4… Apply: 1. ). 2. ). 3. ). 4. ). 5. ). 6. ). 7. = . |
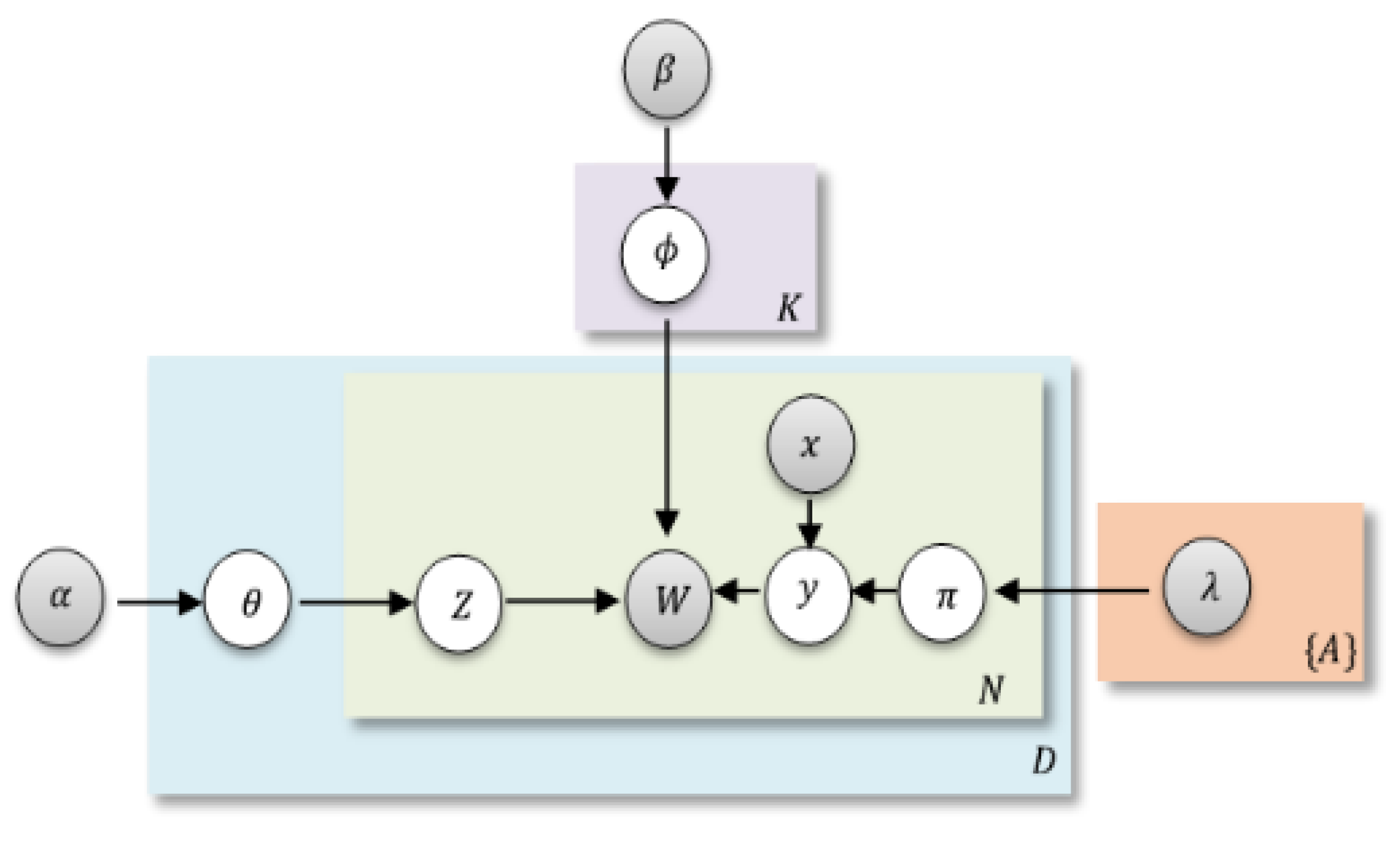
3.2. Aspect Extraction
| Algorithm 2: Algorithm for the generative hypothesis |
|
3.3. Automatic Labelling System
| Algorithm 3: Algorithm of the automatic labelling |
| Input: Sentences, SentiWordNet, WordNet, NegationWords Output: Labelled Dataset for each sentence : taggedSentence = POS(S) for each WordCandidate (verb, adverb, and adjective) in taggedSentence LookupSentiWordNet (WordCandidate) if WordCandidate not in SentiWordNet LookupWordNet (WordCandidate) else if WordCandidate > 0 polarity (WordCandidate) ← positive else if WordCandidate < 0 polarity (WordCandidate) ← negative else if polarity (WordCandidate) ← neutral else (there is NegationWords near WordCandidate) polarity (WordCandidate) ← opposite (polarity (WordCandidate)) PolarityScore += LookupSentiWordNet (WordCandidate) TotalWordCandidateCount++ AveragePolarity = PolarityScore/ TotalWordCandidateCount if AveragePolarity > 0 return 1 else return 0 |
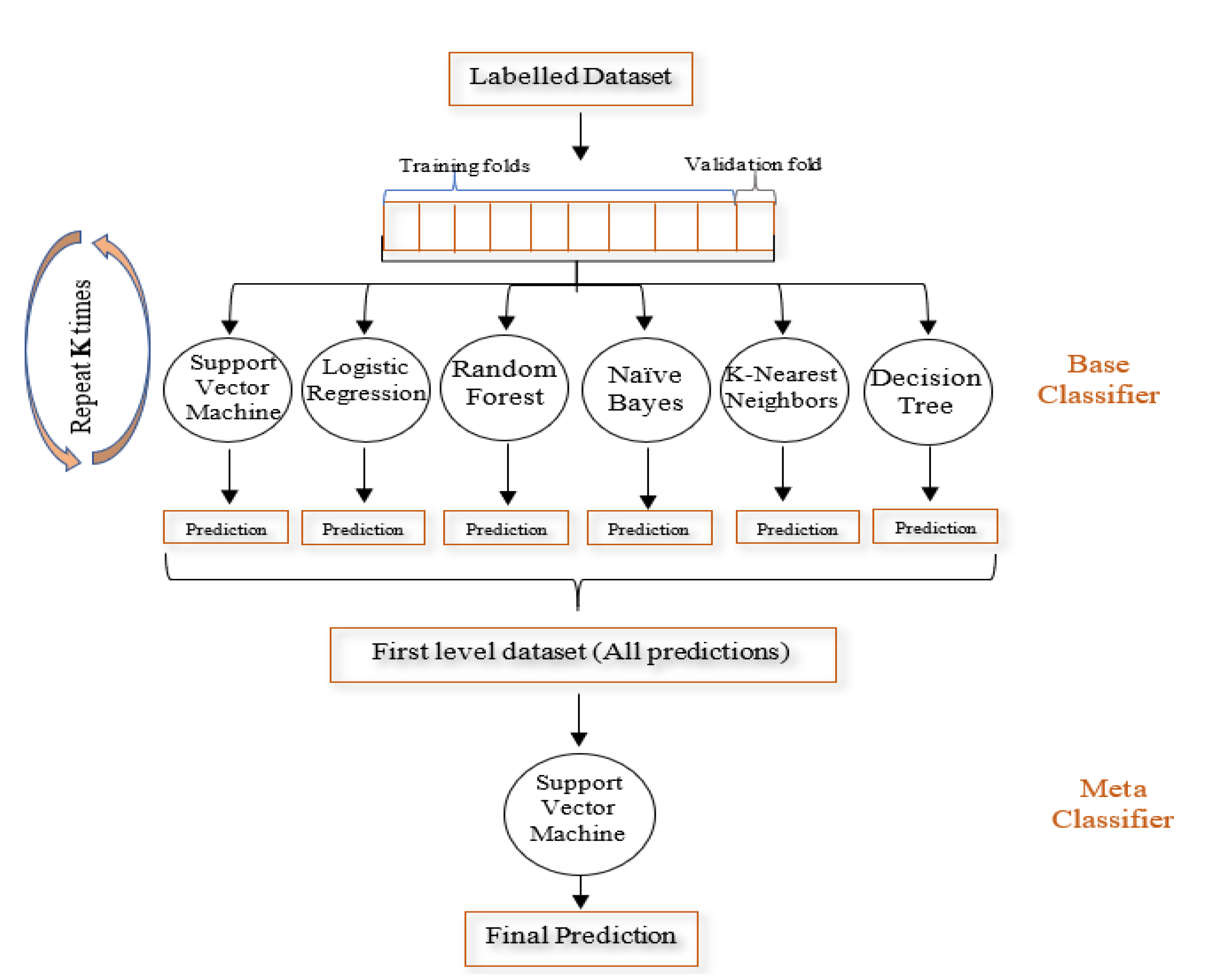
3.4. Predicting Polarity of Largescale Social Data Using Supervised Learning (The Ensemble Learning Classifier Method)
| Algorithm 4: Stacked Generalization with k-fold cross-validation |
| Input: Dataset D, Base classifiers t, base classifier prediction p, meta classifier m Output: Ensemble Classifier Prediction P Apply k-fold CV, } //Split the dataset into 10 subsets for k ← 1 to n do for each t ← 1 to T //base classifiers train the classifier from . end for for do //generate first level dataset get a dataset }. end for //meta classifier return //final prediction |
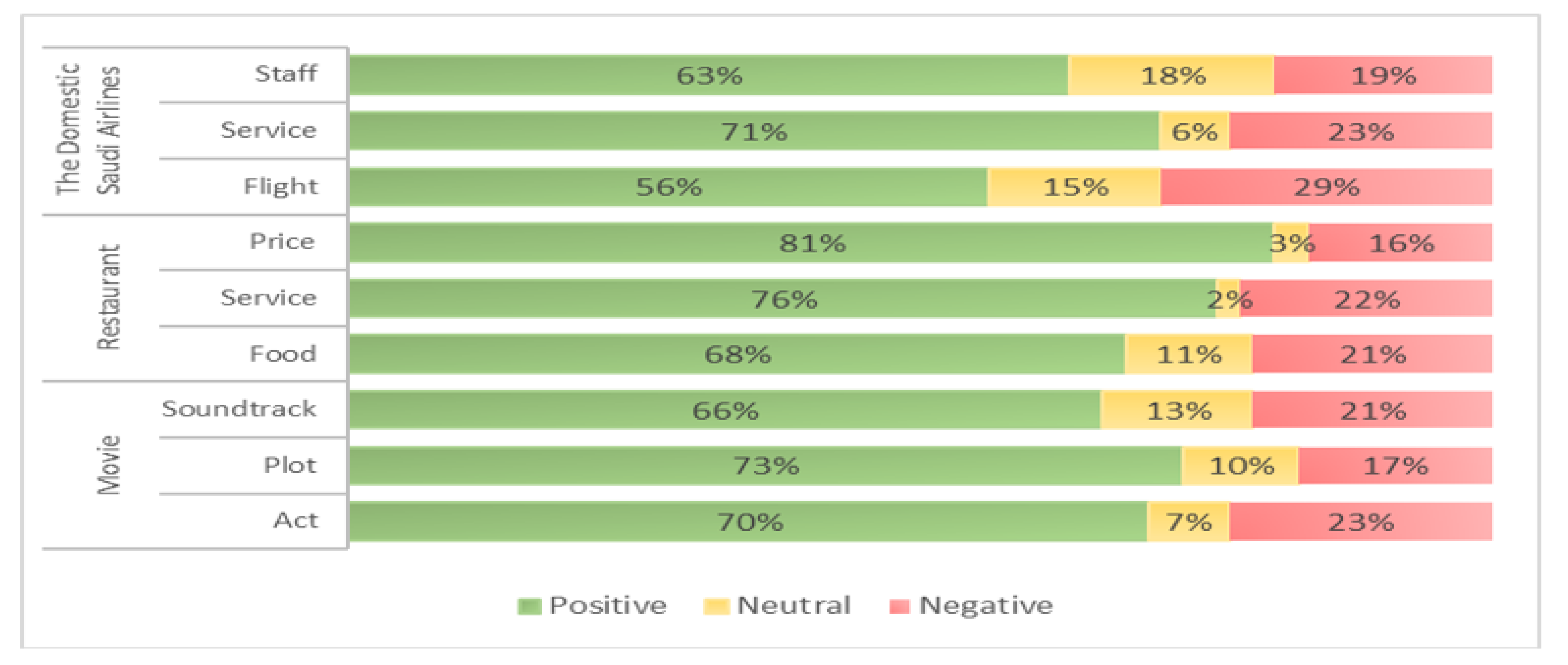
4. Evaluation Criteria and Experimental Results
4.1. Aspect Extraction (SA-LDA Model)
4.2. Automatic Labelling (SentiWordNet)
4.3. Ensemble Classifier (Stacking Generalization)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, M.; Liu, J.; Cao, B.; Wen, Y.; Zhang, X. A Prior Knowledge Based Approach to Improving Accuracy of Web Services Clustering. In Proceedings of the 2018 IEEE International Conference on Services Computing (SCC), San Francisco, CA, USA, 2–7 July 2018. [Google Scholar]
- Ekinci, E.; İlhan Omurca, S. Concept-LDA: Incorporating Babelfy into LDA for Aspect Extraction. J. Inf. Sci. 2020, 46, 406–418. [Google Scholar] [CrossRef]
- Chen, Z.; Mukherjee, A.; Liu, B.; Hsu, M.; Castellanos, M.; Ghosh, R. Exploiting Domain Knowledge in Aspect Extraction. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1655–1667. [Google Scholar]
- Fang, L.; Huang, M. Fine Granular Aspect Analysis Using Latent Structural Models. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju, Korea, 8–14 July 2012; Volume 2, pp. 333–337. [Google Scholar]
- Chen, Z.; Mukherjee, A.; Liu, B.; Hsu, M.; Castellanos, M.; Ghosh, R. Leveraging Multi-Domain Prior Knowledge in Topic Models. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2071–2077. [Google Scholar]
- Chen, Z.; Mukherjee, A.; Liu, B.; Hsu, M.; Castellanos, M.; Ghosh, R. Discovering Coherent Topics Using General Knowledge. In Proceedings of the 22nd ACM International Conference on Conference on Information & Knowledge Management—CIKM ’13, San Francisco, CA, USA, 27 October–1 November 2013; pp. 209–218. [Google Scholar]
- Chen, Z.; Mukherjee, A.; Liu, B. Aspect Extraction with Automated Prior Knowledge Learning. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 347–358. [Google Scholar]
- Chen, Z.; Liu, B. Topic Modeling Using Topics from Many Domains, Lifelong Learning and Big Data. In Proceedings of the the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Volume 32, pp. II-703–II-711. [Google Scholar]
- Wang, T.; Cai, Y.; Leung, H.; Lau, R.Y.K.; Li, Q.; Min, H. Product Aspect Extraction Supervised with Online Domain Knowledge. Knowl.-Based Syst. 2014, 71, 86–100. [Google Scholar] [CrossRef]
- Rana, T.A.; Cheah, Y.-N.; Letchmunan, S. Topic Modeling in Sentiment Analysis: A Systematic Review. J. ICT Res. Appl. 2016, 10, 76–93. [Google Scholar] [CrossRef]
- Majumder, N.; Bhardwaj, R.; Poria, S.; Zadeh, A.; Gelbukh, A.; Hussain, A.; Morency, L.-P. Improving Aspect-Level Sentiment Analysis with Aspect Extraction. Neural Comput. Appl. 2020, 2021, 1–14. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment Analysis Algorithms and Applications: A Survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Khatoon, S.; Romman, L.A. Domain Independent Automatic Labeling System for Large-Scale Social Data Using Lexicon and Web-Based Augmentation. ITC 2020, 49, 36–54. [Google Scholar] [CrossRef] [Green Version]
- Keshavarz, H.; Abadeh, M.S. ALGA: Adaptive Lexicon Learning Using Genetic Algorithm for Sentiment Analysis of Microblogs. Knowl.-Based Syst. 2017, 122, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Li, Y.; Wang, J.; Sherratt, R.S. Sentiment Analysis for E-Commerce Product Reviews in Chinese Based on Sentiment Lexicon and Deep Learning. IEEE Access 2020, 8, 23522–23530. [Google Scholar] [CrossRef]
- Liapakis, A. A Sentiment Lexicon-Based Analysis for Food and Beverage Industry Reviews. The Greek Language Paradigm. SSRN J. 2020, 9, 21–42. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, Z.; Wang, Y.; Liao, T. Sentiment Analysis of Chinese Micro-Blog Text Based on Extended Sentiment Dictionary. Future Gener. Comput. Syst. 2018, 81, 395–403. [Google Scholar] [CrossRef]
- Bandhakavi, A.; Wiratunga, N.; Padmanabhan, D.; Massie, S. Lexicon Based Feature Extraction for Emotion Text Classification. Pattern Recognit. Lett. 2017, 93, 133–142. [Google Scholar] [CrossRef]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2014; ISBN 978-1-118-91456-4. [Google Scholar]
- Onan, A.; Korukoğlu, S.; Bulut, H. A Multiobjective Weighted Voting Ensemble Classifier Based on Differential Evolution Algorithm for Text Sentiment Classification. Expert Syst. Appl. 2016, 62, 1–16. [Google Scholar] [CrossRef]
- Oussous, A.; Lahcen, A.A.; Belfkih, S. Improving Sentiment Analysis of Moroccan Tweets Using Ensemble Learning. In Big Data, Cloud and Applications; Tabii, Y., Lazaar, M., Al Achhab, M., Enneya, N., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 872, pp. 91–104. ISBN 978-3-319-96291-7. [Google Scholar]
- Nehe, M.P.B.; Nawathe, A. Aspect Based Sentiment Classification Using Machine Learning for Online Reviews. 2020. Available online: https://easychair.org/publications/preprint_download/xnVW (accessed on 13 March 2022).
- Shoukry, A.; Rafea, A. Machine Learning and Semantic Orientation Ensemble Methods for Egyptian Telecom Tweets Sentiment Analysis. JWE 2020, 19, 195–214. [Google Scholar] [CrossRef]
- Sultana, N.; Islam, M.M. Meta Classifier-Based Ensemble Learning for Sentiment Classification. In Proceedings of International Joint Conference on Computational Intelligence; Uddin, M.S., Bansal, J.C., Eds.; Algorithms for Intelligent Systems; Springer: Singapore, 2020; pp. 73–84. ISBN 9789811375637. [Google Scholar]
- Basiri, M.E.; Abdar, M.; Cifci, M.A.; Nemati, S.; Acharya, U.R. A Novel Method for Sentiment Classification of Drug Reviews Using Fusion of Deep and Machine Learning Techniques. Knowl.-Based Syst. 2020, 198, 105949. [Google Scholar] [CrossRef]
- Khalid, M.; Ashraf, I.; Mehmood, A.; Ullah, S.; Ahmad, M.; Choi, G.S. GBSVM: Sentiment Classification from Unstructured Reviews Using Ensemble Classifier. Appl. Sci. 2020, 10, 2788. [Google Scholar] [CrossRef] [Green Version]
- Tharwat, A. Classification Assessment Methods. ACI 2021, 17, 168–192. [Google Scholar] [CrossRef]
- Raju, K.D.; Jayasingh, B.B. Machine Learning for Sentiment Analysis for Twitter Restaurant. JES 2018, 9, 21–27. [Google Scholar]
- Waikul, V.; Ravgan, O.; Pavate, A. Restaurant Review Analysis and Classification Using SVM. IOSR JEN 2019, 1, 49–52. [Google Scholar]
- Sharieff, H.; Sindhu, T.; SaiRamesh, L. Comparison of Machine Learning Techniques for Sentimental Analysis on Restaurant Reviews. IJAEM 2020, 2, 740–743. [Google Scholar]
- Bandana, R. Sentiment Analysis of Movie Reviews Using Heterogeneous Features. In Proceedings of the 2nd International Conference on Electronics, Materials Engineering & Nano-Technology (IEMENTech), Kolkata, India, 4–5 May 2018; pp. 1–4. [Google Scholar]
- Ghosh, M.; Sanyal, G. An Ensemble Approach to Stabilize the Features for Multi-Domain Sentiment Analysis Using Supervised Machine Learning. J. Big Data 2018, 5, 44. [Google Scholar] [CrossRef]
- Untawale, T.M.; Choudhari, G. Implementation of Sentiment Classification of Movie Reviews by Supervised Machine Learning Approaches. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; pp. 1197–1200. [Google Scholar]
- Chang, J.-R.; Liang, H.-Y.; Chen, L.-S.; Chang, C.-W. Novel Feature Selection Approaches for Improving the Performance of Sentiment Classification. J. Ambient. Intell. Humaniz. Comput. 2020, 2021, 1–14. [Google Scholar] [CrossRef]
- Jagdale, R.S.; Shirsat, V.S.; Deshmukh, S.N. Sentiment Analysis on Product Reviews Using Machine Learning Techniques. In Cognitive Informatics and Soft Computing; Advances in Intelligent Systems and Computing Book Series; Springer: Berlin/Heidelberg, Germany, 2019; Volume 768, pp. 639–647. [Google Scholar]
- Shaheen, M. Sentiment Analysis on Mobile Phone Reviews Using Supervised Learning Techniques. IJMECS 2019, 11, 32–43. [Google Scholar] [CrossRef]
- Choudhari, P.; Veenadhari, S. Sentiment Classification of Online Mobile Reviews Using Combination of Word2vec and Bag-of-Centroids. In Machine Learning and Information Processing; Swain, D., Pattnaik, P.K., Gupta, P.K., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 1101, pp. 69–80. ISBN 9789811518836. [Google Scholar]
- Xu, F.; Pan, Z.; Xia, R. E-Commerce Product Review Sentiment Classification Based on a Naïve Bayes Continuous Learning Framework. Inf. Process. Manag. 2020, 57, 102–221. [Google Scholar] [CrossRef]
- Al-Azani, S.; El-Alfy, E.-S.M. Using Word Embedding and Ensemble Learning for Highly Imbalanced Data Sentiment Analysis in Short Arabic Text. Procedia Comput. Sci. 2017, 109, 359–366. [Google Scholar] [CrossRef]
- Khan, J.; Alam, A.; Hussain, J.; Lee, Y.-K. EnSWF: Effective Features Extraction and Selection in Conjunction with Ensemble Learning Methods for Document Sentiment Classification. Appl. Intell. 2019, 49, 3123–3145. [Google Scholar] [CrossRef]
- Khai Tran; Thi Phan Deep Learning Application to Ensemble Learning—The Simple, but Effective, Approach to Sentiment Classifying. Appl. Sci. 2019, 9, 2760. [CrossRef] [Green Version]
- İzmir Katip Çelebi Üniversitesi; Onan, A. Ensemble of Classifiers and Term Weighting Schemes for Sentiment Analysis in Turkish. SRC 2021, 1, 1–12. [Google Scholar] [CrossRef]
- Ruta, D.; Gabrys, B. Classifier Selection for Majority Voting. Inf. Fusion 2005, 6, 63–81. [Google Scholar] [CrossRef]
- Novaković, J.D.; Veljović, A.; Ilić, S.S.; Papić, Ž.; Milica, T. Evaluation of Classification Models in Machine Learning. Theory Appl. Math. Comput. Sci. 2017, 7, 39–46. [Google Scholar]
- Bhoir, P.; Kolte, S. Sentiment Analysis of Movie Reviews Using Lexicon Approach. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 10–12 December 2015; pp. 1–6. [Google Scholar]
- Rajeswari, A.M.; Mahalakshmi, M.; Nithyashree, R.; Nalini, G. Sentiment Analysis for Predicting Customer Reviews Using a Hybrid Approach. In Proceedings of the 2020 Advanced Computing and Communication Technologies for High Performance Applications (ACCTHPA), Cochin, India, 2–4 July 2020; pp. 200–205. [Google Scholar]
- Guha, S.; Joshi, A.; Varma, V. SIEL: Aspect Based Sentiment Analysis in Reviews. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 759–766. [Google Scholar]
- Fikri, M.; Sarno, R. A Comparative Study of Sentiment Analysis Using SVM and SentiWordNet. IJEECS 2019, 13, 902–909. [Google Scholar] [CrossRef]
- Yuan, P. Sentiment Classification and Opinion Mining on Airline Reviews. 2016. Available online: https://www.semanticscholar.org/paper/Sentiment-Classification-and-Opinion-Mining-on-Yuan/daf1d9de4066eed1d193847cae578389da16c5e8 (accessed on 13 March 2022).
- Mehta, P.; Chandra, S. Enhancement of SentiWordNet Using Contextual Valence Shifters. IJDATS 2019, 11, 337. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | No. of Reviews | Source of Datasets |
|---|---|---|
| Movie Reviews | 2000 | IMDB |
| Restaurant Reviews | 2000 | TripAdvisor |
| Domestic Saudi Airlines Reviews | 2000 | TripAdvisor |
| Total | 6000 reviews | |
| Domain | Aspect | Seed Words |
|---|---|---|
| Movie | ACT | performance, actor, play, character, role, scene |
| PLOT | story, script, sequence, scenario | |
| SOUNDTRACK | sound, audio, music, playlist, effect | |
| Restaurant | FOOD | taste, dish, dinner, appetizer, menu |
| SERVICE | internet, parking, delivery, location, seating, staff | |
| PRICE | payment, price, discount, cost, pay offer | |
| Domestic Saudi Airlines | FLIGHT | meal, internet, entertainment, seat, cleanliness, drink |
| SERVICE | lounge, ticket, baggage, upgrade, punctuality | |
| STAFF | crew, captain, pilot, service, steward |
| Domain | Aspect | LDA Model | SA-LDA Model |
|---|---|---|---|
| Movie | Act | (actor, show, play, character, art, life, movie, appear, sound, only) | (performance, act, actor, character, play, actress, part, scene, role, do) |
| Plot | (story, play, series, know, role, line, set, sound, voice, say) | (story, series, play, script, sequence, role, scenario, line, do, text) | |
| Soundtrack | (music, song, sound, great, play, musical, product, show, story, movie) | (music, sound, audio, song, show, effect, playlist, soundtrack, play, movie) | |
| Restaurant | Food | (food, restaurant, menu, good, chicken, dishes, street, visit, dinner, service) | (restaurant, menu, food, taste, appetizer, dinner, dishes, view, cook, flavor) |
| Service | (staff, manager, ask, service, food, said, friendly, restaurant, told, eat) | (service, staff, order, internet, view, location, delivery, parking, menu, seating) | |
| Price | (price, card, feel, money, charged, payment, cheap, night, really, like) | (price, cost, payment, offer, card, discount, pay, bill, charge, worth) | |
| Domestic Saudi Airlines | Flight | (ticket, check, flight, bad, lounge, schedule, time, only, food, hour) | (flight, seat, meal, internet, food, entertainment, movie, clean, drink, ticket) |
| Service | (staff, desk, check, airport, out, arrival, hour, ready, late, wait) | (ticket, service, lounge, flight, baggage, schedule, staff, upgrade, offer, punctuality) | |
| Staff | (staff, friendly, service, direct, talk, helpful, front, desk, time, late) | (staff, service, facility, schedule, time, crew, ticket, pilot, flight, plane) |
| Domain | Accuracy (SentiWordNet) | Accuracy of Related Work |
|---|---|---|
| Movie | 65% | 53.33% [45], 79% [46] |
| Restaurant | 69.4% | 53% [47], 56% [48] |
| The Domestic Saudi Airlines | 63.2% | 65.2% [49], 46.41% [50] |
| Domain | Accuracy of the Proposed Model SA-LDA (LDA with Seed Words) | Accuracy of the Baseline Model (LDA without Seed Words) |
|---|---|---|
| Movie | 83.3% | 54% |
| Restaurant | 86.7% | 41% |
| The Domestic Saudi Airlines | 80% | 32% |
| Domain | Base Classifiers | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|---|
| Restaurant | SVM | 80.2 | 80.9 | 79.1 | 80 |
| LR | 80.3 | 80.9 | 79 | 80 | |
| RF | 76 | 74.5 | 79 | 76.7 | |
| DT | 68.8 | 71.2 | 63.4 | 67.1 | |
| NB | 80.4 | 81 | 78.9 | 80.1 | |
| KNN | 68.9 | 65.9 | 78.5 | 71.6 | |
| Movie | SVM | 81.2 | 81 | 80.7 | 80.3 |
| LR | 80 | 71 | 73.5 | 72 | |
| RF | 73 | 73 | 72.6 | 72.7 | |
| DT | 72.2 | 69 | 75 | 71.8 | |
| NB | 71.5 | 80.5 | 64 | 71.3 | |
| KNN | 71 | 74 | 68.4 | 71 | |
| The Domestic Saudi Airlines | SVM | 73.6 | 73 | 73 | 73.5 |
| LR | 72 | 71 | 72.3 | 73 | |
| RF | 62 | 56 | 75 | 57.5 | |
| DT | 63.5 | 70.1 | 57 | 63 | |
| NB | 72 | 81 | 65 | 72 | |
| KNN | 73.2 | 76 | 70 | 73.4 |
| Domain | Ensemble Method | Acc. (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|
| Restaurant | Bagging | 80.3 | 80.1 | 79 | 80.1 |
| AdaBoost | 79.5 | 81 | 76.4 | 78.8 | |
| Majority Voting | 77.5 | 76.4 | 79.4 | 77.9 | |
| Stacked Generalization (Proposed) | 83.2 | 83 | 82.4 | 83.1 | |
| Movie | Bagging | 80 | 80.7 | 79.6 | 79.4 |
| AdaBoost | 77.8 | 79 | 77.7 | 77.7 | |
| Majority Voting | 77.6 | 78 | 77.6 | 77.2 | |
| Stacked Generalization (Proposed) | 84 | 83.5 | 83 | 84 | |
| The Domestic Saudi Airlines | Bagging | 74.1 | 74 | 74.3 | 74 |
| AdaBoost | 77.5 | 77.3 | 76.2 | 76.3 | |
| Majority Voting | 75 | 74 | 75.3 | 75.7 | |
| Stacked Generalization (Proposed) | 84.4 | 83.1 | 82 | 84.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlGhamdi, N.; Khatoon, S.; Alshamari, M. Multi-Aspect Oriented Sentiment Classification: Prior Knowledge Topic Modelling and Ensemble Learning Classifier Approach. Appl. Sci. 2022, 12, 4066. https://doi.org/10.3390/app12084066
AlGhamdi N, Khatoon S, Alshamari M. Multi-Aspect Oriented Sentiment Classification: Prior Knowledge Topic Modelling and Ensemble Learning Classifier Approach. Applied Sciences. 2022; 12(8):4066. https://doi.org/10.3390/app12084066
Chicago/Turabian StyleAlGhamdi, Najwa, Shaheen Khatoon, and Majed Alshamari. 2022. "Multi-Aspect Oriented Sentiment Classification: Prior Knowledge Topic Modelling and Ensemble Learning Classifier Approach" Applied Sciences 12, no. 8: 4066. https://doi.org/10.3390/app12084066