
Express Construction for GANs from Latent Representation to Data Distribution

 ,
,
Abstract
:Featured Application
Abstract
1. Introduction
- We have proposed a novel training methodology for GANs to tackle the mode collapse problem, named Express Construction. The generating procedure in the proposed method will be decomposed into two steps: generating the latent representation using random noises, and generating the final results close to the data distribution from the latent representation rather than random noises. To the best of our knowledge, we are the first to search for more transportation maps in this way.
- Theoretical statements are provided to prove our assumptions under the views on the training dynamics. Besides, the transportation cost will be discussed, which indicates Express Construction is lightweight and effective.
- We conduct extensive experiments and evaluate our contributions using different datasets from small to large scale. The results show Express Construction is less prone to mode collapse and is able to generate realistic samples.
2. Related Works
3. Problem Statement
4. Materials and Methods
4.1. Datasets
4.2. Method
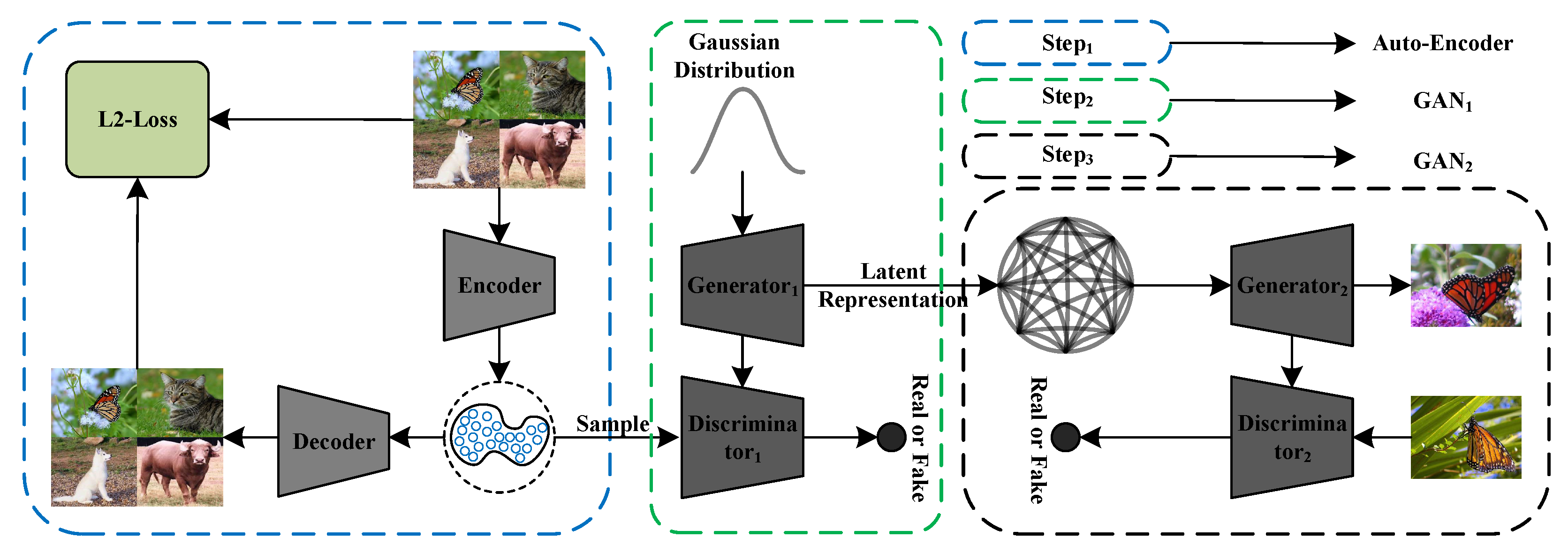
4.2.1. Framework
4.2.2. Data Embedding with Auto-Encoder
4.2.3. Constructing the Transportation Map from Random Noise to Latent Representation
4.2.4. Constructing the Transportation Map from Data Latent Representation to Distribution
5. Results
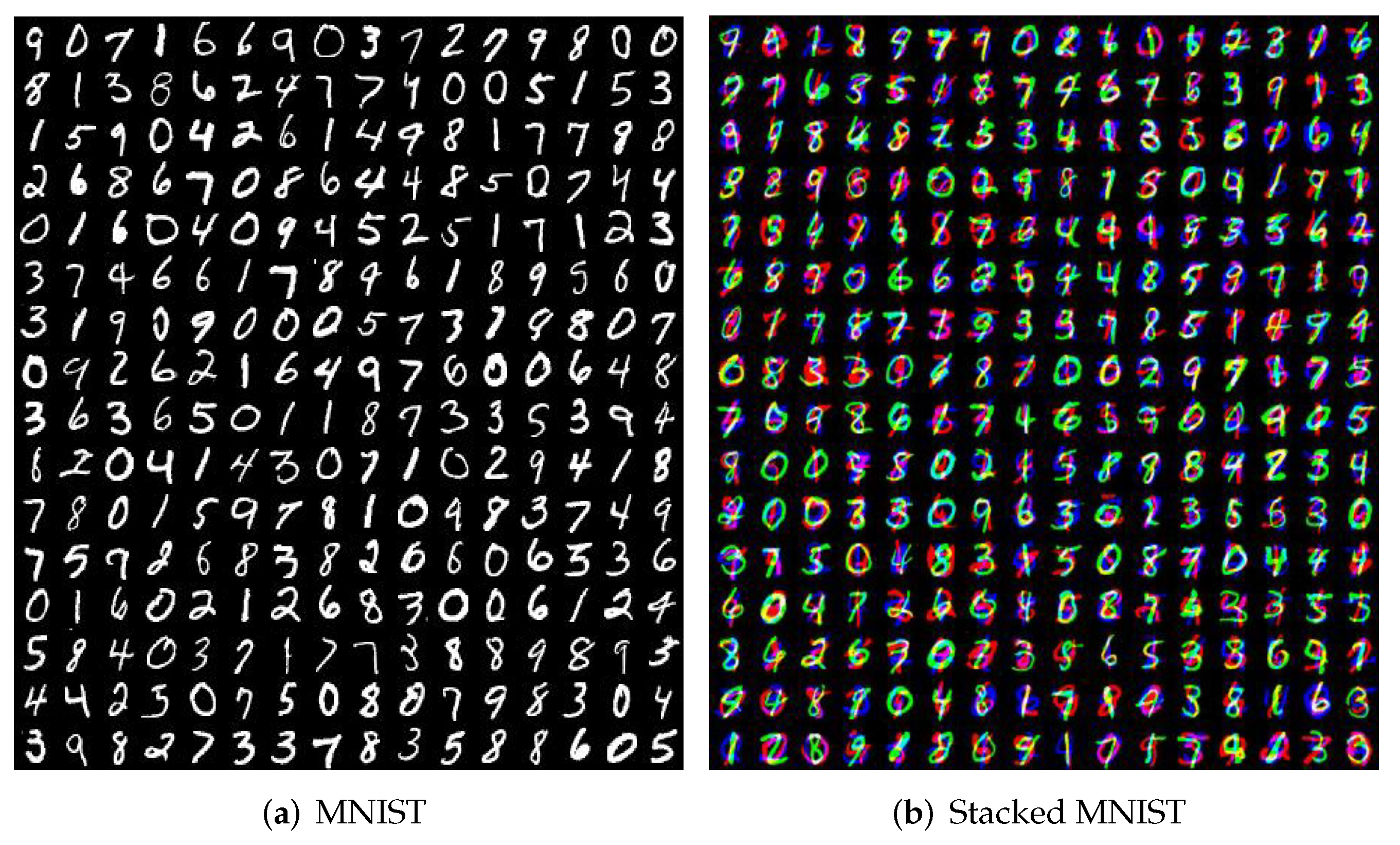
5.1. MNIST and Stacked MNIST Datasets
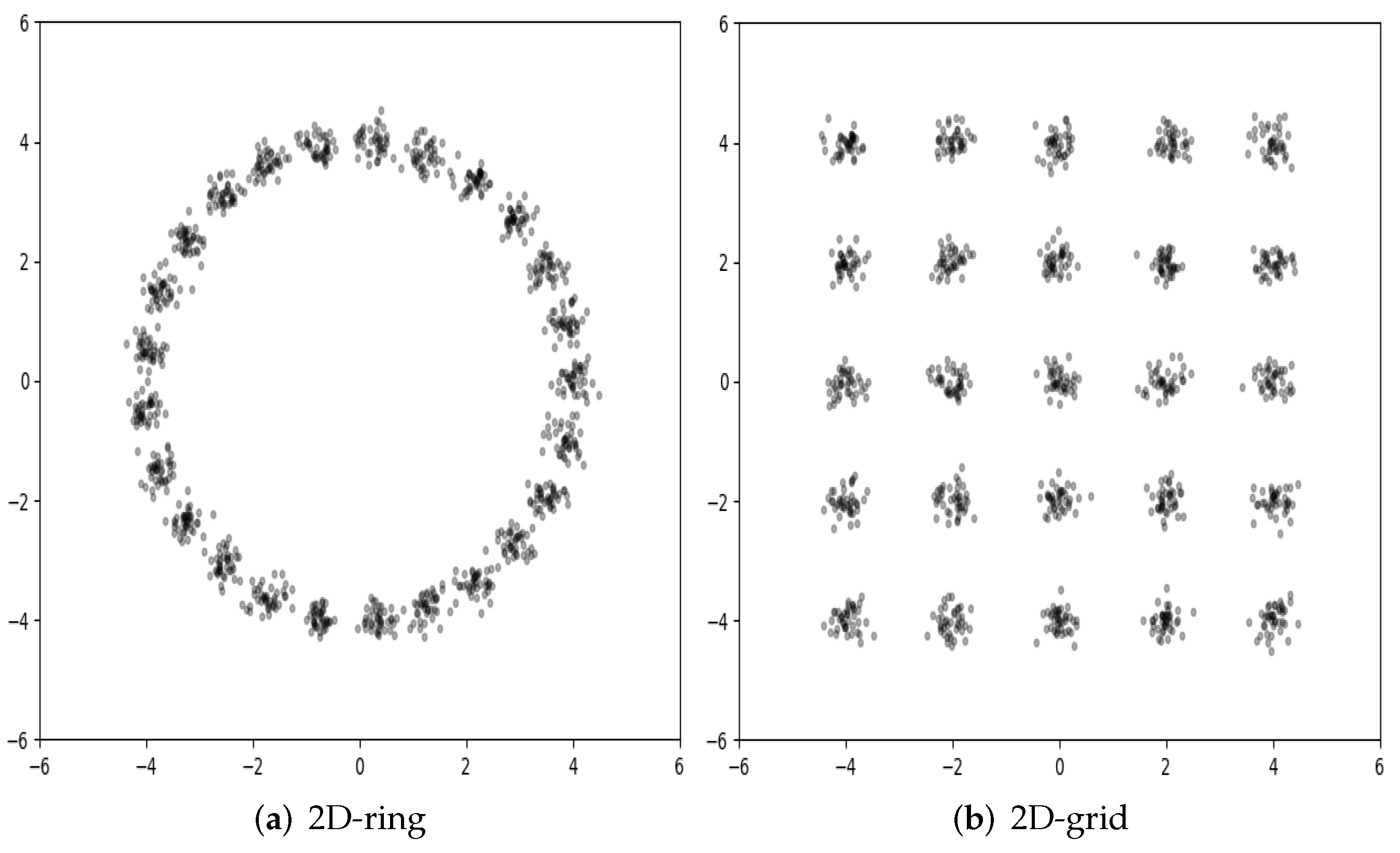
5.2. Toy Datasets
5.3. CIFAR-10 Dataset
5.4. CelebA
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Aaron van den Oord, N.K.; Kavukcuoglu, K. Pixel Recurrent Neural Networks. In Proceedings of the International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1747–1756. [Google Scholar]
- Van den Oord, A.; Kalchbrenner, N.; Espeholt, L.; Vinyals, O.; Graves, A. Conditional Image Generation with PixelCNN Decoders. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Kingma, D.; Max, W. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Tolstikhin Ilya, B.O.; Sylvain, G. Wasserstein Auto-Encoders. In Proceedings of the International Conference on Learning Representations(ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Guo, Y.; An, D.; Qi, X.; Luo, Z.; Yau, S.T.; Gu, X. Mode Collapse and Regularity of Optimal Transportation Maps. arXiv 2019, arXiv:1902.02934. [Google Scholar]
- An, D.; Guo, Y.; Lei, N.; Luo, Z.; Yau, S.T.; Gu, X. AE-OT: A New Generative Model Based on Extended Semi-discrete Optimal Transport. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Nagarajan, V.; Kolter, J.Z. Gradient Descent GAN Optimization Is Locally Stable. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Long Beach, CA, USA, 2017; Volume 30. [Google Scholar]
- Tenenbaum, J.B.; Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Liou, C.Y.; Huang, J.C.; Yang, W.C. Modeling word perception using the Elman network. Neurocomputing 2008, 71, 3150–3157. [Google Scholar] [CrossRef]
- Hoang, Q.; Nguyen, T.D.; Le, T.; Phung, D. MGAN: Training Generative Adversarial Nets with Multiple Generators. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Han, C.; Rundo, L.; Murao, K.; Noguchi, T.; Shimahara, Y.; Milacski, Z.Á.; Koshino, S.; Sala, E.; Nakayama, H.; Satoh, S.I. MADGAN: Unsupervised medical anomaly detection GAN using multiple adjacent brain MRI slice reconstruction. BMC Bioinform. 2021, 22, 31. [Google Scholar] [CrossRef] [PubMed]
- Metz, L.; Poole, B.; Pfau, D.; Sohl-Dickstein, J. Unrolled Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Liu, H.; Guo, Y.; Lei, N.; Shu, Z.; Yau, S.T.; Samaras, D.; Gu, X. Latent Space Optimal Transport for Generative Models. arXiv 2018, arXiv:1809.05964. [Google Scholar]
- An, D.; Guo, Y.; Zhang, M.; Qi, X.; Lei, N.; Gu, X. AE-OT-GAN: Training GANs from Data Specific Latent Distribution. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 548–564. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards Principled Methods for Training Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Khetan, A.; Fanti, G.; Oh, S. PacGAN: The power of two samples in generative adversarial networks. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Montreal, QC, Canada, 2018; Volume 31. [Google Scholar]
- Krizhevsky, A.; Hinton, G.E. Learning Multiple Layers of Features from Tiny Images; Technical Report; Citeseer: Princeton, NJ, USA, 2009. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Tero, K.; Timo, A.; Samuli, L.; Jaakko, L. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially Learned Inference. arXiv 2016, arXiv:1606.00704. [Google Scholar]
- Dieng, A.B.; Ruiz, F.J.; Blei, D.M.; Titsias, M.K. Prescribed Generative Adversarial Networks. arXiv 2019, arXiv:1910.04302. [Google Scholar]
- Xiao, C.; Zhong, P.; Zheng, C. BourGAN: Generative Networks with Metric Embeddings. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Montreal, QC, Canada, 2018; Volume 31. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Long Beach, CA, USA, 2017; Volume 30. [Google Scholar]
- Salimans, T.; Zhang, H.; Radford, A.; Metaxas, D. Improving GANs Using Optimal Transport. arXiv 2018, arXiv:1803.05573. [Google Scholar]
- Martin Arjovsky, S.C.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Vancouver, BC, Canada, 2019; Volume 32. [Google Scholar]
- Tim, S.; Ian, G.; Wojciech, Z.; Vicki, C.; Alec, R.; Chen, X. Improved Techniques for Training GANs. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Barcelona, Spain, 2016. [Google Scholar]
- Dowson, D.; Landau, B. The frechet distance between multvariate normal distributions. J. Multivar. Anal. 1982, 12, 450–455. [Google Scholar] [CrossRef] [Green Version]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems(NIPS); MIT Press: Long Beach, CA, USA, 2017; Volume 30. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. In Proceedings of the International Conference on Machine Learning (ICLR), Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Wei, X.; Gong, B.; Liu, Z.; Lu, W.; Wang, L. Improving the Improved Training of Wasserstein GANs: A Consistency Term and Its Dual Effect. In Proceedings of the International Conference on Machine Learning (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Liu, K.; Tang, W.; Zhou, F.; Qiu, G. Spectral Regularization for Combating Mode Collapse in GANs. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6382–6390. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kumar, A.; Sattigeri, P.; Fletcher, P.T. Improved Semi-supervised Learning with GANs using Manifold Invariances. arXiv 2017, arXiv:1705.08850. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2D-Ring | 2D-Grid | |||||
|---|---|---|---|---|---|---|
| Modes | h-Quality | Reverse | Modes | h-Quality | Reverse | |
| Max 25 | Samples | KL | Max 25 | Samples | KL | |
| GAN [1] | 19.7 ± 0.5 | 95.3 ± 0.2 | 0.45 ± 0.09 | 17.3 ± 0.8 | 94.8 ± 0.7 | 0.70 ± 0.07 |
| CTGAN [33] | 23.8 ± 0.3 | 98.3 ± 0.1 | 0.04 ± 0.03 | 23.5 ± 0.4 | 98.0 ± 0.2 | 0.05 ± 0.04 |
| PacGAN [18] | 24.7 ± 0.1 | 96.5 ± 0.3 | 0.05 ± 0.02 | 24.6 ± 0.4 | 94.2 ± 0.4 | 0.06 ± 0.02 |
| PresGAN [23] | 24.7 ± 0.2 | 97.2 ± 0.3 | 0.04 ± 0.04 | 24.7 ± 0.4 | 94.5 ± 0.2 | 0.05 ± 0.03 |
| BourGAN [24] | 24.8 ± 0.2 | 97.9 ± 0.1 | 0.02 ± 0.01 | 24.9 ± 0.1 | 95.9 ± 0.2 | 0.02 ± 0.02 |
| SRGAN [34] | 24.8 ± 0.2 | 97.5 ± 0.2 | 0.02 ± 0.01 | 24.7 ± 0.3 | 98.4 ± 0.3 | 0.03±0.04 |
| AE-OT [7] | 24.9 ± 0.1 | 99.8 ± 0.2 | 0.01 ± 0.01 | 24.9 ± 0.1 | 99.5 ± 0.5 | 0.01 ± 0.01 |
| AE-OT-GAN [15] | 24.8 ± 0.2 | 99.9 ± 0.1 | 0.01 ± 0.01 | 24.8 ± 0.2 | 99.7 ± 0.3 | 0.01 ± 0.01 |
| Ours1 | 22.5 ± 0.5 | 97.6 ± 0.5 | 0.08 ± 0.04 | 22.1 ± 0.7 | 97.0 ± 0.6 | 0.10 ± 0.06 |
| Ours2 | 24.8 ± 0.2 | 99.9 ± 0.1 | 0.01 ± 0.01 | 24.8 ± 0.2 | 99.7 ± 0.3 | 0.01 ± 0.01 |
| GANs | BEGAN | GAN | WGAN | WGAN-GP | CTGAN | WCGAN | SNGAN |
|---|---|---|---|---|---|---|---|
| IS | 5.62 | 7.01 | 7.22 | 7.78 | 8.09 | 8.20 | 8.22 |
| FID | 84.0 | 31.8 | 30.3 | 29.5 | 22.4 | 20.4 | 21.7 |
| IS + Express Construction | 6.58 | 7.60 | 7.83 | 8.11 | 8.38 | 8.36 | 8.37 |
| FID + Express Construction | 55.1 | 29.7 | 28.2 | 27.3 | 19.9 | 20.2 | 20.0 |
| GAN-Based | Improved GANs [29] | Improved Semi [36] | CTGAN [33] | Express Construction |
| 18.63 ± 2.32 | 16.78 ± 1.80 | 9.98 ± 0.21 | 9.64 ± 0.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Deng, J.; Yang, M.; Cheng, X.; Xie, T.; Deng, P.; Wang, X.; Liu, M. Express Construction for GANs from Latent Representation to Data Distribution. Appl. Sci. 2022, 12, 3910. https://doi.org/10.3390/app12083910
Liu M, Deng J, Yang M, Cheng X, Xie T, Deng P, Wang X, Liu M. Express Construction for GANs from Latent Representation to Data Distribution. Applied Sciences. 2022; 12(8):3910. https://doi.org/10.3390/app12083910
Chicago/Turabian StyleLiu, Minghui, Jiali Deng, Meiyi Yang, Xuan Cheng, Tianshu Xie, Pan Deng, Xiaomin Wang, and Ming Liu. 2022. "Express Construction for GANs from Latent Representation to Data Distribution" Applied Sciences 12, no. 8: 3910. https://doi.org/10.3390/app12083910