1. Introduction
As already stated in the companion paper [
1], the rapid development of e-commerce online payment has become more and more popular, and therefore it also represents a challenge, not only to secure the transactions but also to avoid false positives in fraud detection algorithms. According to a report by The Alan Turing Institute [
2], the number of transactions wrongly rejected due to suspected fraud can pose an equivalent threat to actual fraud in the industry of the financial services. Another study stated that transactions that were wrongly declined due to suspected fraud account for USD 118 billion in retail losses [
3]. As a consequence, the banks are now forced to devote an increasing amount of resources to discriminate among legitimate transaction and fraud to cope with the difficult dilemma of avoiding impostors’ actions while not limiting e-commerce’s inexorable growth. However, this is not an easy task, since scammers try their best to ensure that the profiles of the transactions differ as little as possible from the real ones, trying to model extremely assimilated behavioral profiles [
4]. To cope with this emerging new reality, financial institutions hire skilled expert fraud software engineers, who develop full packages of new and sophisticated strategies to pursue this purpose.
Fraud detection primitive strategies, such as expert systems, were very much related to checklists of risk factors, e.g., repeated declined transactions, multiple failed attempts to enter a credit card number, or living beyond means. However, the emergence of machine learning (ML) techniques has allowed the creation of new schemes capable of providing more adequate and precise alternatives to respond to the potential (or actual) security threats based on historical transactional records. From a mathematical perspective, credit fraud detection (CFD) could be seen and analyzed as a novelty detection problem [
2]. In this direction, a possible approach could be to find lower dimensional embeddings to model the original dataset, where anomalies are expected to be detached from normal data [
5].
Autoencoders have recently emerged as a resourceful deep learning family of methods for dimensionality reduction and feature extraction. According to the literature, these techniques have shown to offer improvements in accuracy, computational efficiency, and the subsequent user satisfaction in their applications [
6]. Even so, one of the big challenges, and a potential barrier, for autoencoders is the lack of visibility of the underlying model in the encoding and decoding sides. Therefore, these data-driven models are frequently considered as black boxes, meaning that although inputs and outputs are known, and regardless of the good results provided in many problems, the model itself exhibits relevant limitations to show the role played by each of the features in the final outcome. That is why the authorities and regulatory bodies have shown, to date, significant reluctance to accept a generalized use of these modern techniques [
7]. Although this reality becomes a clear limitation, the wide consensus among researchers and financial institutions suggests that ML still has great potential, even though a number of challenges still require special attention [
8]. As an example, in the case of the United States and in order to avoid any discrimination, the features such as race, sex, or marital status, or any related one, should be very carefully applied or even not used according to existing regulations [
9]. Moreover, an algorithm to lend money could be found in violation of this prohibition even if the algorithm does not directly use any of the prohibited categories, but instead it uses data that can be highly correlated with the protected categories. Lack of transparency is becoming a real challenge in fact in the European Union, as the General Data Protection Regulation adopted in 2018 gives its citizens the right to receive an explanation of decisions based on automated processing [
8]. The justification for this type of regulation lies in the potential bias that the hidden stages of the model could be applying, thus leaving the individual, the regulatory body, and the risk assessment entity devoid of tools to identify any undesirable situations that finally might be reproducing [
6,
10]. Even more, the data used to train the ML models may not be representative for the problem [
8], sometimes driving eventually to inaccurate models, with limited generalization capabilities. Having said that, and returning to regulatory restrictions, the entities understand the need for a regulation that ensures that the use of technology cannot inadvertently cause discriminatory treatment of people, but they also agree on the need for a clearer guidance from the authorities that offer a reasonable path towards the necessary and effective application of AI in this field [
11]. Considering that regulatory bodies and administrative authorities will not allow financial institutions to adopt AI models without addressing the necessary description of the decision process being followed [
7], a suitable way to overcome the regulatory issues and the mistrust with respect to the algorithms being used is to provide the regulators, authorities, and financial entities with supplemental environments and tools that contribute in an effectual way to the real interpretability. Therefore, we can state that decision models should be easy to understand, meaningful, and traceable. This last one means that each initial variable or feature needs to be linked to final decision score through a visible value, process, or function [
7,
9,
12].
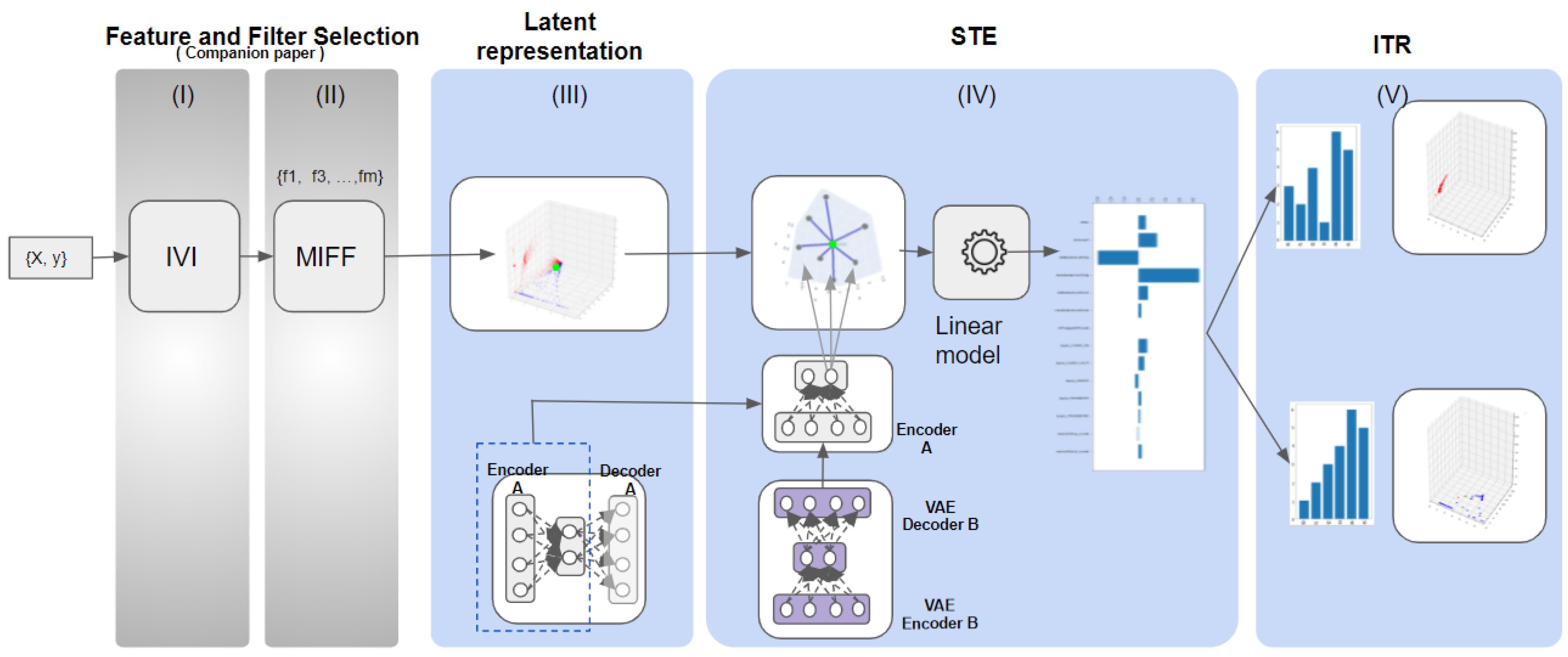
To accomplish this challenging goal, state-of-the-art methods in novelty detection such as autoencoders can be extremely useful, as well as a new set of strategies to offer interpretability on what was traditionally considered a black-box model. Under this perspective, the contribution of this work is a novel methodology to address the mentioned complexity. The methodology proposed in this work has a triple objective: First, to reduce the dimensionality by selecting the informative features; second, to efficiently compress and encode data to isolate fraud transactions from non-fraudulent ones; third, to propose, and eventually evaluate, novel techniques to offer a comprehensive explanatory model in CFD. To achieve this, we propose an explanation at the level of a single instance artificially generating a set of data around said instance (through random sampling and using controlled perturbations), and finally, applying a linear learning model to the distance between the instance and the sampling data. This last step represents the main difference with respect to previous applications in terms of the ability to tie input features to the outputs, thus providing the desirable interpretability. To approach the dimensionality reduction, we use the positive results included in the companion paper [
1] where we applied a novel feature selection technique, the informative variable identifier (IVI) [
13], which can distinguish among informative, redundant, and noisy variables or features.
This work is organized as follows. A short review of the vast literature in the field of CFD and ML-based systems is presented in
Section 2. In
Section 3, a summary of new nonlinear ML algorithms used in this work is described, as well as explanatory strategies to convey an effective interpretation, as single transaction-level explanation (STE) and individual transaction rankings (ITR) are introduced and formally described. In
Section 4, the different datasets are defined, and we present the qualitative and quantitative benchmarking over different datasets while maintaining the interpretability. Finally, in
Section 5, discussion and observations are given, and conclusions are summarized.
2. Related Work
CFD is the process or the set of techniques followed in order to classify a transaction as fraudulent or not, in contrast to legitimate operations. This process could be understood from a methodological perspective as under the novelty detection category of data-driven problems. Nowadays, a large number of the transactions take place digitally, by means of credit cards and other electronic payment systems, increasingly challenging the fraud control systems of financial institutions worldwide. Although the fraud accounts only for 0.1% of the total transactions, the large and growing volume of the electronic market has forced the industry to devote tremendous efforts aimed to secure this new and almost indispensable way of working [
14].
Among many novelty detection methods, the design of low-dimensional embeddings is becoming a relevant strategy in ML. This method suggests that once the original domain data, including anomalies and normal samples, are introduced in the model, examples are squeezed into a lower dimensional space, where these distinctive classes are expected to be separated. The projection of all samples in the new space, also known as the latent space, is referred to in the literature as a manifold or as an embedding, and it can represent a useful and illustrative plot of the dataset. In a second step, those low-dimensional embeddings are transferred back to the original space through a process called reconstruction. The training process which minimizes error or distance among samples from the original space and reconstructed space will perform the rest. If the training process concludes successfully, it is expected to yield a picture of the true intrinsic nature of the data in the latent space, without unnecessary features or noise. In other words, if the high-dimensional dataset is compressed into a limited number of new features, and it is subsequently reconstructed into the original space back again with a minimum error, then we can reckon that the features of the low-dimensional space keep all the relevant features of the initial samples. Principal component analysis (PCA) could be understood as a low complexity and linear-type example of this set of techniques, where the new features are ranked by variance [
5]. In the same direction and with the advent of deep learning, a new group of techniques is being opened. On the one hand, specialized embedding approaches for natural language processing have emerged [
15,
16,
17,
18,
19,
20,
21], and on the other hand, autoencoders are becoming among the most promising approaches for feature extraction and dimensionality reduction [
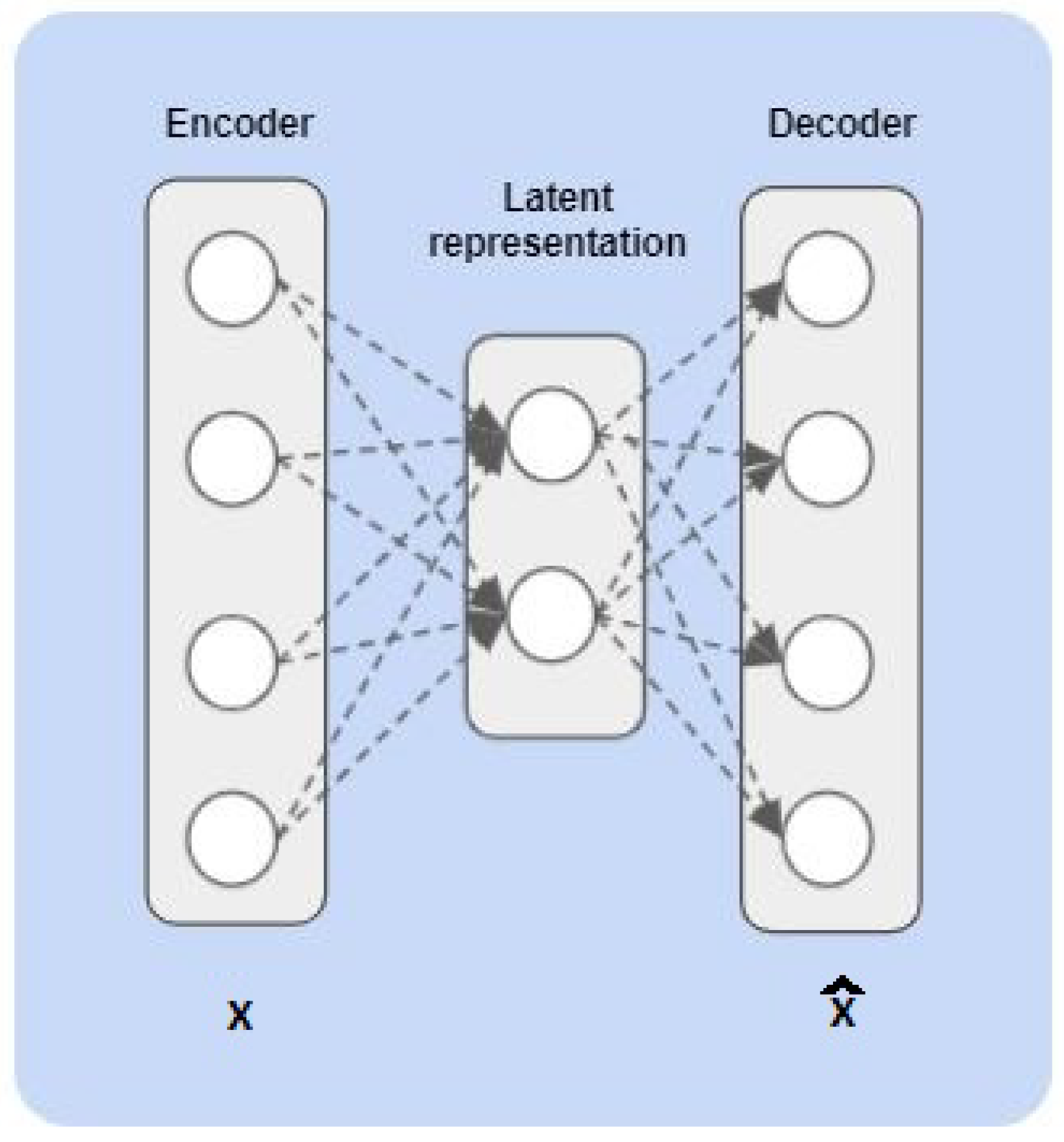
22]. An autoencoder [
23,
24] is a multiple layer neural network that compresses the high-dimensional data into a low-dimensional latent representation (encoder), combined with a later expansion to the original space (decoder). As a result, autoencoders are able to discover a lower-level representation of a higher dimensional data space [
25]. Considering that the autoencoder training processes tend to minimize the distance among original input space and the regenerated space through the two-stage encode–decode methodology, it could be understood that the existing low-dimensional (or latent) space summarizes the essence of the actual data, as the decoder is capable of expanding those low-dimensional data to the original dimension. In other words, we could make a case saying that the hidden layers of the encoder are able to extract the features that better represent the actual data with the current dimensional constraint. This procedure, although considered a black-box method, shows good performance in the CFD field according to literature [
26,
27].
As we introduced in
Section 1, financial services and, more specifically, CFD are highly regulated areas, with almost no room for black boxes, for models which are difficult to understand, or for architectures without adequate transparency in their use of the data. All this leads to the need for interpretability as a crucial element when it comes to breaking the barriers of lack of transparency in traditional ML developments. A good number of papers have delved into this issue, pointing out how the increase in complexity works against transparency [
11], how regulations of the United States and Europe tighten their vigilance on the correct use of the features [
8], and how the absence of these criteria can lead to unacceptable bias for the application of ML techniques [
11]. An important challenge in ML is interpretability, which refers to the interpretation of the reasons behind the model decision in a way that humans can understand, that is, human beings would be able to have full understanding about the model logic [
7]. However, in the field of financial services, there is no shortage of entities that point out the difficulty of making use of the powerful ML tools for fraud detection and simultaneously complying with the increasingly restrictive regulatory requirements. This does not mean that regulation is seen as an unjustified barrier to ML deployment, although some entities do emphasize the need for a certain guidance on how to take it into consideration in the context of the CFD architectures [
11]. To cope with it, and according to existing literature, financial institutions rely on using simple interpretable models, such as decision trees [
28] or linear models [
12]. These kinds of models are easy to understand, and their predictions are straightforwardly explained. In the case of decision trees, for instance, interpretation can be followed through the branches, and in the case of linear models, interpretations depend on the weights for each feature in the model. In other direction, new strategies are currently focused on local surrogate models and specifically on local interpretable model-agnostic explanations (LIME) [
29]. In this last method, the authors, instead of training a global surrogate model, use local surrogates to approximate predictions of the underlying black-box model. This is performed by modifying a single instance by tweaking the feature values and observing the impact on the output. This procedure is reproduced at a local level, and it effectively generates a valid surrogate model for a tight environment of the local instances. By doing so, LIME generates an interpretable, agnostic, and locally meaningful alternative to the original black-box data model. Finally, other studies have elaborated on the binomial interpretability vs. accuracy. In [
30], the authors elaborate on the trade-off among the cost of interpretability vs. the predictive capabilities, concluding that currently, in financial services, interpretability is even more important than accuracy, as it is mandatory to comply with regulations.
It is clear, according to the literature [
31,
32], that dimensionality reduction is more than needed in order to be able to classify and identify anomalies in a daily growing dataset environment. It is quite frequent in the artificial intelligence business to think that the larger the number of features, the more possibilities we must articulate, as a feasible model that fits the latent reality. This often means a continuous exponential increase in features, and consequently, the quality of the data required to process ML algorithms gradually decreases. This effect has long been known as the curse of dimensionality [
33,
34]. In fact, higher dimensions lead to the existence of redundant information, noisy samples, and irrelevant information, which may cause overfitting of the model and may increase the error rate of the learning algorithms. To handle these problems, direct and previous dimensionality reduction can be applied. The classical approach to the previous issues is the use of feature selection (FS) techniques. FS is used to clean up and pre-evaluate the possible contribution of the features in terms of valid information by removing noisy, redundant, and irrelevant data [
32]. FS methods can improve accuracy, efficiency, effectiveness, and even interpretability to the learning process. For this reason, a large number of automatic FS methods have been developed in the past. In FS, a subset of features is selected from the original set, based on the evaluation of the actual intrinsic information of each feature, namely, the redundancy and the relevance [
31]. During this process, features are classified into the following four groups according to their eventual effective information: (1) noisy and irrelevant; (2) redundant and weakly relevant; (3) weakly relevant and non-redundant; (4) strongly relevant. Popular approaches to carry this out are filter methods, wrapper methods, and embedded methods. Filter methods analyze the usefulness of each single feature through the use of relevance techniques, mainly from hypothesis tests or estimates of mutual information [
35]. Wrapper methods solve ML problems to assess the relevance of each feature in the input space [
36]. Finally, embedded methods, such as recursive feature elimination (RFE) [
37], aim to increase their efficiency by combining the FS procedure with training a subsequent learning machine. Many of these embedded methods impose a regularization on the solution. A special mention is required for a recently proposed novel feature selection method, called IVI [
1,
13]. This technique is capable of isolating informative, redundant, and noisy features automatically. One of its main characteristics is being able to transform the distribution of the input variable space into a coefficient feature space by using existing linear classifiers or efficient weight generators. At this point, it is necessary to mention that a large number of feature selection methods have been published in the literature, with uneven results in their application in different disciplines. It is not the object of this article to carry out a detailed analysis of each and every one of these techniques, but for the reader’s convenience and with the intention of offering a summary of the different typologies of published methods, hereafter in
Table 1 a schematic summary is presented for the different types of techniques as published in various reviews [
32,
38], including a new category for the informative variable identifier (IVI) that we included in this paper [
13].
5. Discussion and Conclusions
In this article, we elaborated on the possibility of applying, today, ubiquitous ML techniques to CFDs and providing interpretability to those decisions made in ML models. We have extended here the analysis to nonlinear models with respect to the companion work [
1]. One of the main drawbacks of these technologies is that, even though extremely effective and powerful in all disciplines where they were applied, they are mostly presented to users as black boxes where it is virtually impossible to decode the way the features are treated internally. This last statement is intrinsically incompatible with regulation issued by administrative bodies, as whatever tool used should be compliant with non-discriminatory rules and transparency. In an attempt to deal with such a difficult dichotomy, in the companion paper [
1], we evaluated different techniques to identify in an effective way the informative features and their relationships and to minimize potential biases. In this work, we proposed to evaluate and present a methodology to obtain interpretability in nonlinear models, and, in particular, we worked with autoencoders. To achieve this, through STE we are able to effectively identify the main features in the decision process, thus providing interpretability, and hence leaving aside black boxes through the use of state-of-the-art technology in ML techniques. We claim that it is possible to build robust explanatory models to simultaneously meet the regulatory constraint while using the power of the ML techniques. To achieve this, we first developed the synthetic dataset to define and fine-tune the models, and successful models were later applied to two real datasets to verify their generalization and consistency.
The main conclusions when analyzing the three datasets are summarized next.
We have verified the results obtained in the companion paper [
1], that is, using the IVI algorithm with MIFF filter in a new real dataset, we can systematically capture all the real features with informative values.
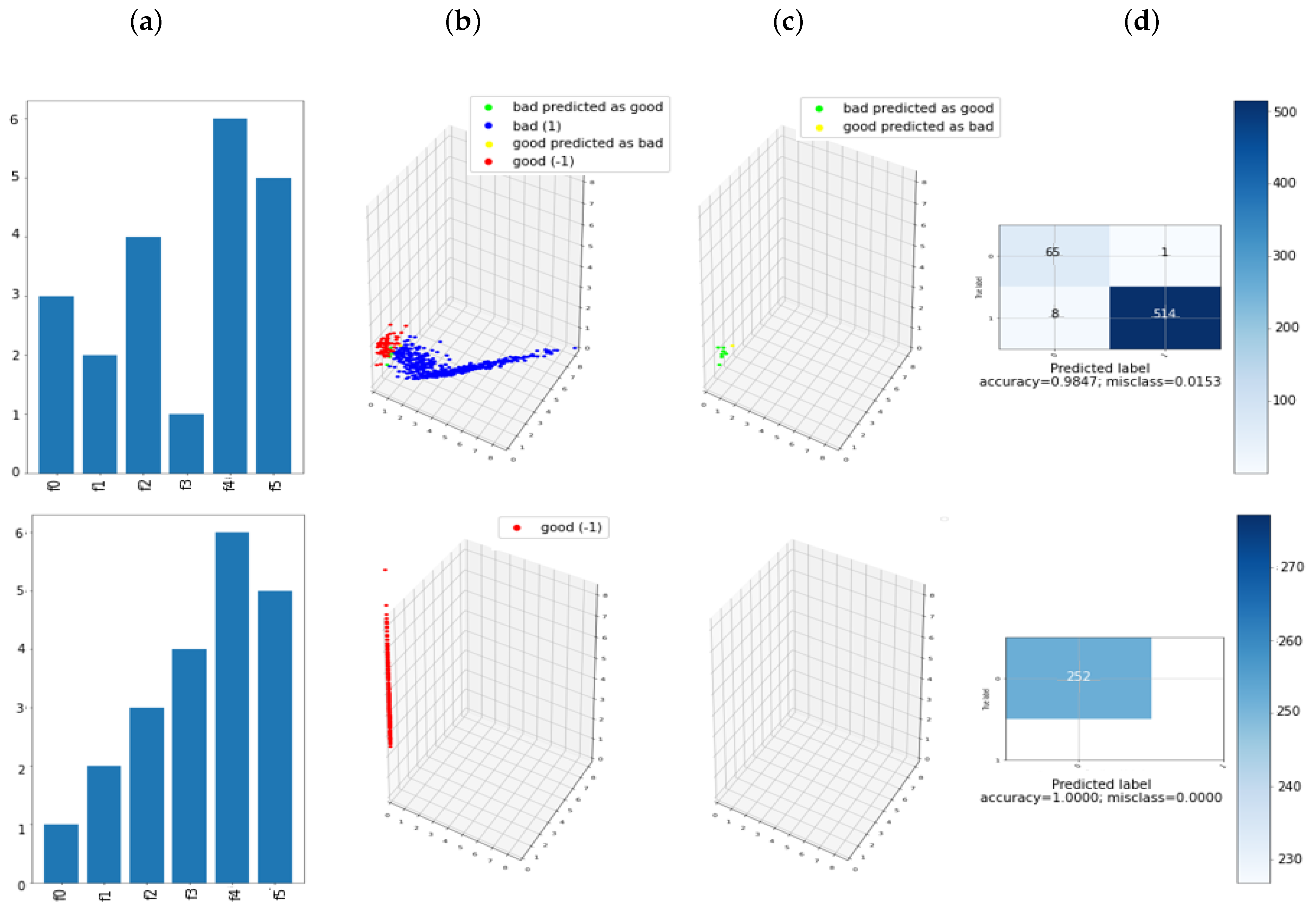
The better results obtained with the proposed approach (accuracy increase of 5%) suggested that the use of the presented method can improve the performance, meanwhile the reduction in terms of features simultaneously can enhance the computer efficiency.
The use of STE has proven to be a suitable method to interpret the relationship between the contribution of each feature and the output of the classifier in black box methods.
The use of ITR methods is proposed as a novel technique to classify transactions that are similar in terms of the participation of the variables in the classifier result.
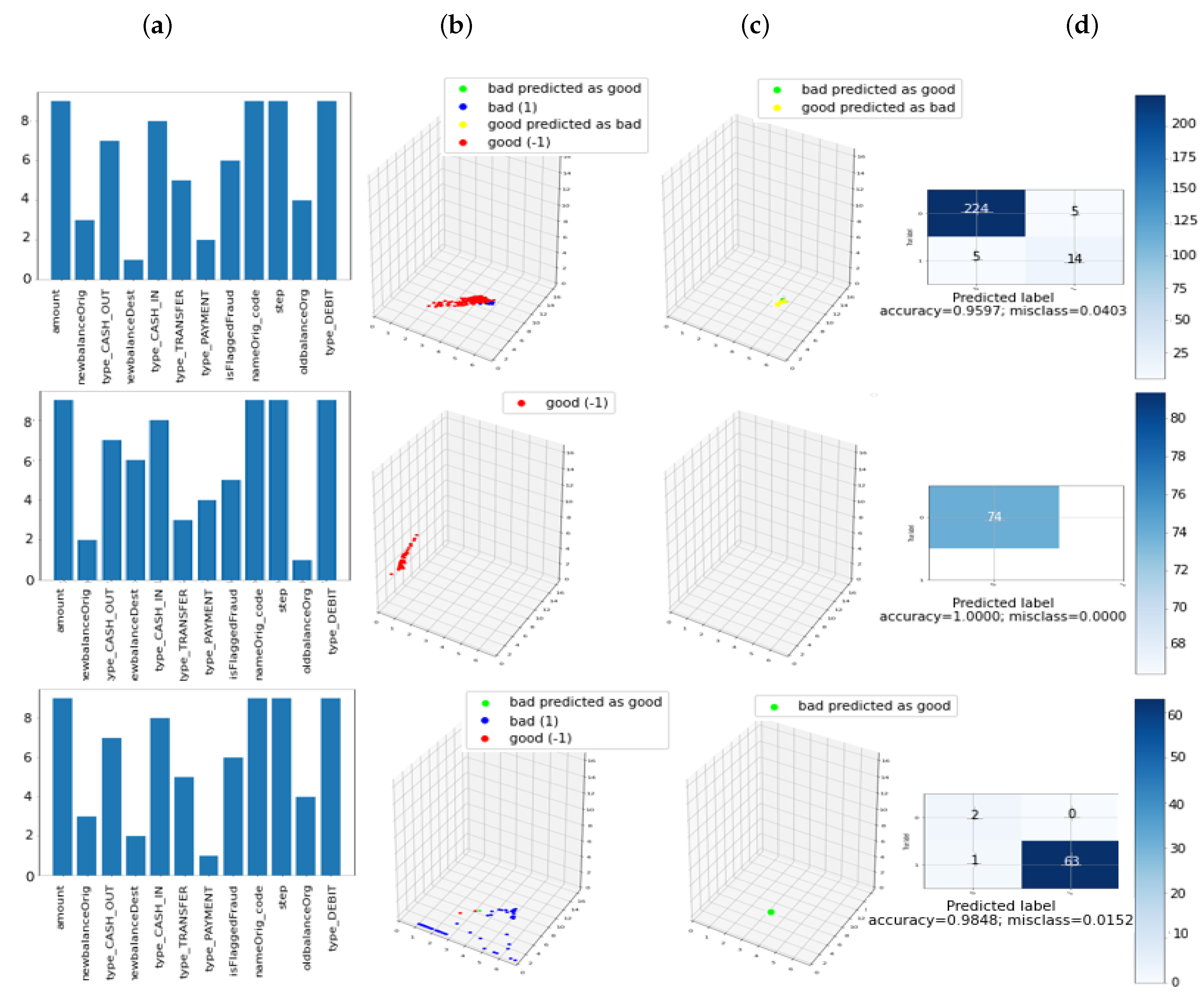
The results of applying these findings over the German Credit Dataset [
47,
48] were confirmed consistent with previous results in our synthetic dataset, as well as with other public published studies. It is also interesting to note that features picked by the model were consistent with those ones from published works sourcing the very same datasets [
49,
50]. Key features found in our case were livingbeyond means, lack or absence of transaction trail, unexpected overdrafts or declines in cash balances, and carloans. It is interesting to note that in the new dataset one of the features marked as relevant was isFlaggedFraud, which is a flag decided by a fraud analyst expert and it has high accuracy rate by itself.
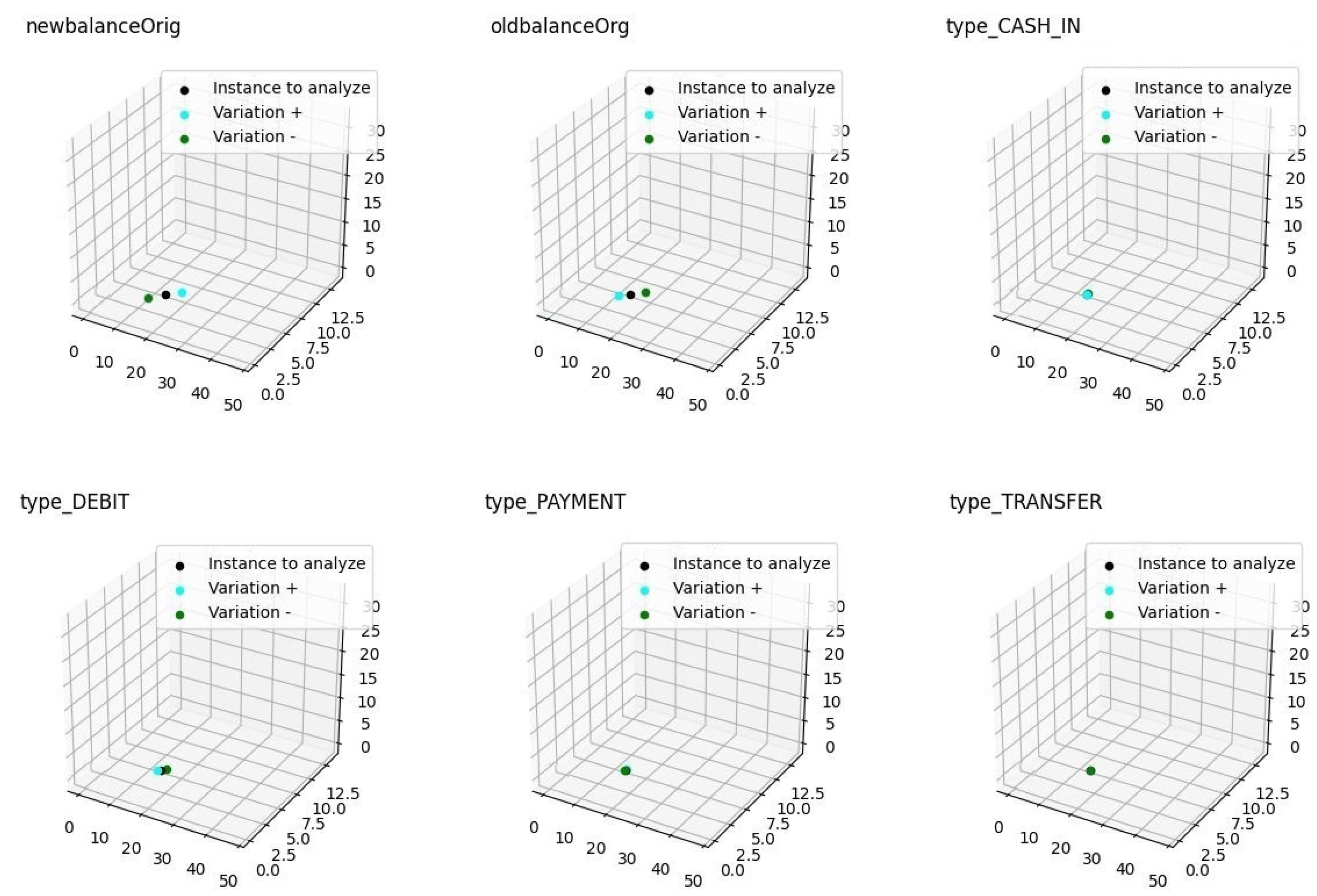
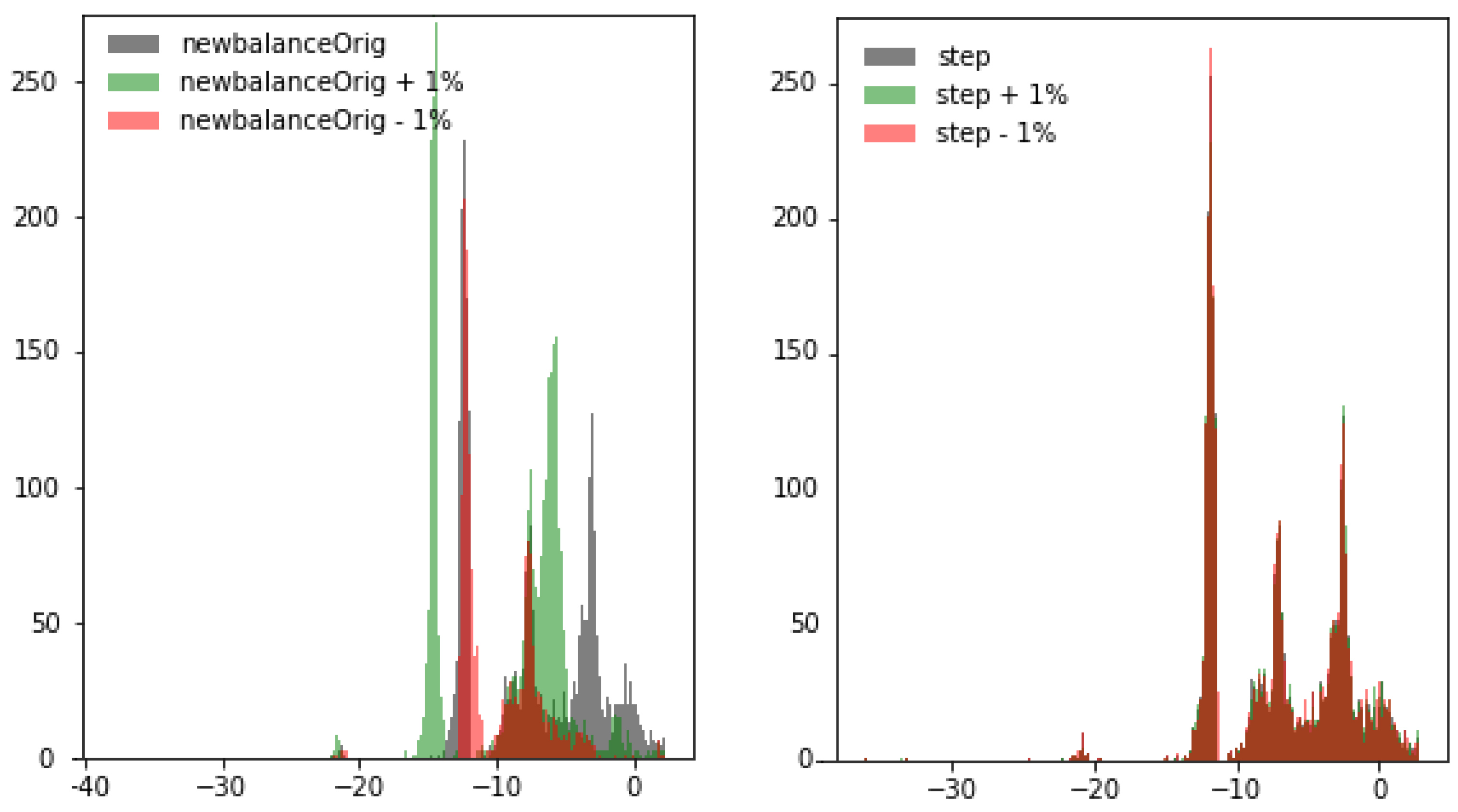
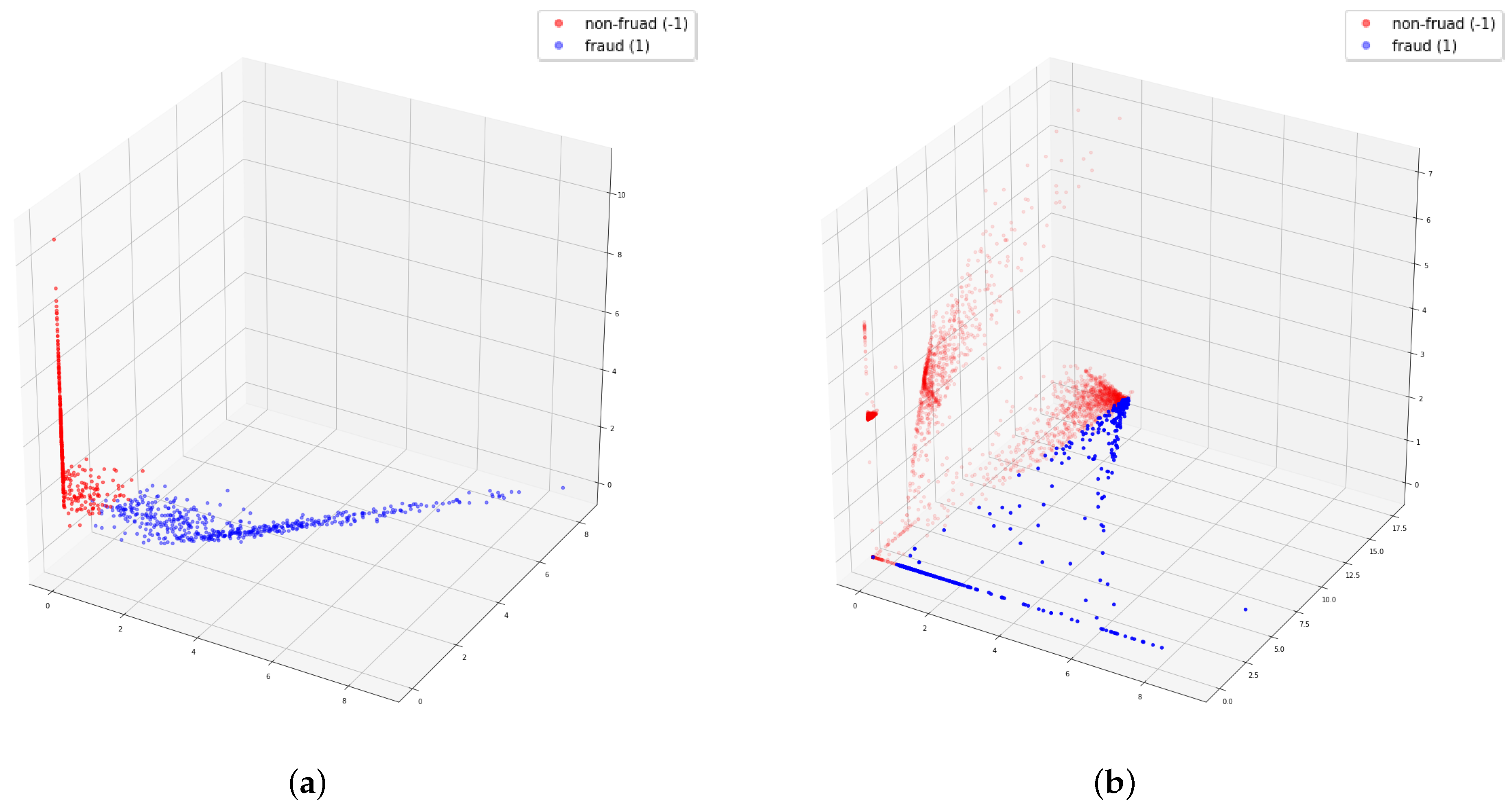
It was clear from the experiments that in the latent space the ML algorithms improve the classification task by better mapping the different types of transactions. The use of latent spaces could still be considered as a black-box model. With the aim of mitigating explanations for black-box, we have introduced two new mechanisms. First, STE summarizes the contribution of each feature for an individual transaction based on small-scale fluctuations, and second, the ITR method is able to build an individual feature ranking for each transaction. These rankings represent a closer estimation of those features that are more important than the others in the decision process for an individual transaction. The rationale of the ITR-based approach is a single-instance-level explanation for each transaction, which allows us to detect similar transaction profiles for the transaction with equivalent ITR. With these profiles, we can detect possible transaction biases caused by giving too much importance to not-allowed features, and then producing discrimination based on various categories including, for instance, race, sex, or marital status. We also may disclose the strong relation between STE and ITR. In the experiment where we verify how small variation in a feature in input space has different response in the latent space, we discovered that the feature newbalanceOrig has a high impact on this small variation, and this was confirmed when we generated the different profiles with ITR.
In addition to what is expressed in these conclusions regarding the potentiality in terms of the explicability shown, the evaluation of the Kendall correlation of ITR throughout the different datasets showed interesting results that encourage the deepening of the proposed analysis. In this sense, the differences in the means and distributions of the Kendall correlation, for the different datasets, can be interpreted in several directions. On the one hand is the existence of modalities in the distributions, which correspond to the existence of a number of different models needed to approximate the underlying reality that may be related to the number of different sets of transactions that take place. This set of transactions should not necessarily coincide with the classes under study, but with different realities, or varieties, which should be studied individually and separately for a better understanding of the sample base for greater interpretability. On the other hand, the presence of a single modality would indicate that of a linear, unique, and representative model, capable of evaluating with at least the same precision as the highly complex model evaluated. Thirdly, the existence of a non-modal distribution, whether uniform, Gaussian, or of any other type, could suggest various interpretations that in all cases could suggest facing new methods of analysis, either due to the existence of infinite linear models, equivalents, or a limited number of nonlinear models. In this direction, it is necessary to point out that although it is possible for each and every one of the transactions to obtain an ITR model, which provides interpretability to the proposed classification, it will be offered solely and exclusively for that transaction, not being possible to generalize to other cases. This local approximation and STE approach, could be understood as an advantage when it comes to interpretability, although its unique single explanation could also make regulators and authorities reluctant to validate extensively. That is why it is proposed, as the next step of this work, to advance in the knowledge of these distributions and the data models that give rise to them in order to also be able to propose interpretable and generalizable nonlinear models that ensure consistency, if not for the total of samples of the set, at least for a large group of them that are part of subsets that share the same ITR.
We can conclude that our methodology provides a detailed evaluation at the transaction level, adding interpretability to each transaction and making visible the most relevant features in decision process. This individualized, unbiased, and traceable perspective provides the necessary transparency, not only to comply with regulations, but also to be able to justify each classified transaction to clients and authorities.
As a general summary, we can affirm that the objective and contribution of this work was twofold. On the one hand, we intended to evaluate (and where appropriate, to improve) the detection capabilities of CFD techniques through the application of advanced AI techniques, which can be applied directly and in real time (online). Secondly, a novel analysis has been proposed, which is valid for any classification method providing interpretability retrospectively (offline). The authors consider that this last part constitutes the most important contribution of this work, since it is not only applicable to the latest generation CFD technique presented here, but, on the contrary, it can be used by regulators, clients, and authorities of supervision, as well as the entities themselves, separately and retrospectively (offline) to guarantee the non-discriminatory treatment and the audit of any pre-existing model without the need to delve into the details of CFD architecture.
The results and conclusions presented here also open up new potential lines of work for the future. In particular, (i) the possibility of extending the work carried out here to CFD risk assessments in real time (online); (ii) the possibility of deepening into ITR-clustering to better profile CFD; and, finally, (iii) to be able to extend AI techniques for fraud detection to their full potential, after having validated the blind evaluation techniques of black-box methods.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}