
Generative Adversarial Networks for Zero-Shot Remote Sensing Scene Classification

Abstract
:1. Introduction
- 1.
- We trained a generator that can generate class image features close to the real image through class semantic information. We propose well-designed modules to constrain the generator, including classification loss module, class-prototype loss module, and semantic regression module. To the best of our knowledge, we are the first to employ generative adversarial networks for zero-shot remote sensing scene classification (RSSC);
- 2.
- We explored the effect of different semantic embeddings for zero-shot RSSC. Specifically, we investigated various natural language processing models, i.e., Word2vec, Fasttest, Glove, and Bert, to extract semantic embeddings for each class either from the class name or from the class sentence descriptions. Our conclusion may help future work in understanding and choosing semantic embeddings for zero-shot RSSC;
- 3.
2. Methods
2.1. Problem Definition
2.2. Overall Framework
2.3. Class Semantic Feature Representation Module
2.4. Feature Generation Module
2.5. Training and Testing
3. Results
3.1. Dataset
3.2. Evaluation Protocols
3.3. Implementation Details
3.4. Ablations on Different Word Vectors
3.5. Comparison with State-of-the-Art
3.6. Ablation Studies
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chi, M.; Plaza, A.; Benediktsson, J.A.; Sun, Z.; Shen, J.; Zhu, Y. Big data for remote sensing: Challenges and opportunities. Proc. IEEE 2016, 104, 2207–2219. [Google Scholar] [CrossRef]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Qi, K.; Yang, C.; Hu, C.; Shen, Y.; Shen, S.; Wu, H. Rotation invariance regularization for remote sensing image scene classification with convolutional neural networks. Remote Sens. 2021, 13, 569. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv 2015, arXiv:1508.00092. [Google Scholar]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Larochelle, H.; Erhan, D.; Bengio, Y. Zero-Data Learning of New Tasks; AAAI: Menlo Park, CA, USA, 2008; Volume 1, p. 3. [Google Scholar]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Attribute-based classification for zero-shot visual object categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 453–465. [Google Scholar] [CrossRef]
- Zhang, Z.; Saligrama, V. Zero-shot learning via semantic similarity embedding. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 4166–4174. [Google Scholar]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A deep visual-semantic embedding model. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Stateline, NV, USA, 5–10 December 2013; Volume 26. [Google Scholar]
- Li, Y.; Wang, D.; Hu, H.; Lin, Y.; Zhuang, Y. Zero-shot recognition using dual visual-semantic mapping paths. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3279–3287. [Google Scholar]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Int. Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Xian, Y.; Lorenz, T.; Schiele, B.; Akata, Z. Feature generating networks for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5542–5551. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montréal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Felix, R.; Reid, I.; Carneiro, G. Multi-modal cycle-consistent generalized zero-shot learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 21–37. [Google Scholar]
- Li, J.; Jing, M.; Lu, K.; Ding, Z.; Zhu, L.; Huang, Z. Leveraging the invariant side of generative zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7402–7411. [Google Scholar]
- Yu, Y.; Ji, Z.; Han, J.; Zhang, Z. Episode-based prototype generating network for zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14035–14044. [Google Scholar]
- Li, A.; Lu, Z.; Wang, L.; Xiang, T.; Wen, J.R. Zero-shot scene classification for high spatial resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4157–4167. [Google Scholar] [CrossRef]
- Quan, J.; Wu, C.; Wang, H.; Wang, Z. Structural alignment based zero-shot classification for remote sensing scenes. In Proceedings of the 2018 IEEE International Conference on Electronics and Communication Engineering (ICECE), Xi’an, China, 10–12 December 2018; pp. 17–21. [Google Scholar]
- Wang, C.; Peng, G.; De Baets, B. A Distance-Constrained Semantic Autoencoder for Zero-Shot Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12545–12556. [Google Scholar] [CrossRef]
- Sumbul, G.; Cinbis, R.G.; Aksoy, S. Fine-grained object recognition and zero-shot learning in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2017, 56, 770–779. [Google Scholar] [CrossRef] [Green Version]
- Verma, V.K.; Arora, G.; Mishra, A.; Rai, P. Generalized zero-shot learning via synthesized examples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4281–4289. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Shigeto, Y.; Suzuki, I.; Hara, K.; Shimbo, M.; Matsumoto, Y. Ridge regression, hubness, and zero-shot learning. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Porto, Portugal, 7–11 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 135–151. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kodirov, E.; Xiang, T.; Gong, S. Semantic autoencoder for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3174–3183. [Google Scholar]
- Wan, Z.; Chen, D.; Li, Y.; Yan, X.; Zhang, J.; Yu, Y.; Liao, J. Transductive zero-shot learning with visual structure constraint. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Wu, H.; Yan, Y.; Chen, S.; Huang, X.; Wu, Q.; Ng, M.K. Joint visual and semantic optimization for zero-shot learning. Knowl.-Based Syst. 2021, 215, 106773. [Google Scholar] [CrossRef]
- Xing, Y.; Huang, S.; Huangfu, L.; Chen, F.; Ge, Y. Robust bidirectional generative network for generalized zero-shot learning. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Settles, B. Active Learning Literature Survey; University of Wisconsin-Madison: Madison, WI, USA, 2009. [Google Scholar]
- Fu, M.; Yuan, T.; Wan, F.; Xu, S.; Ye, Q. Agreement-Discrepancy-Selection: Active Learning with Progressive Distribution Alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 2–9 February 2021; Volume 35, pp. 7466–7473. [Google Scholar]
- Wang, S.; Li, Y.; Ma, K.; Ma, R.; Guan, H.; Zheng, Y. Dual adversarial network for deep active learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 680–696. [Google Scholar]
- Ahmad, M.; Khan, A.; Khan, A.M.; Mazzara, M.; Distefano, S.; Sohaib, A.; Nibouche, O. Spatial prior fuzziness pool-based interactive classification of hyperspectral images. Remote Sens. 2019, 11, 1136. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
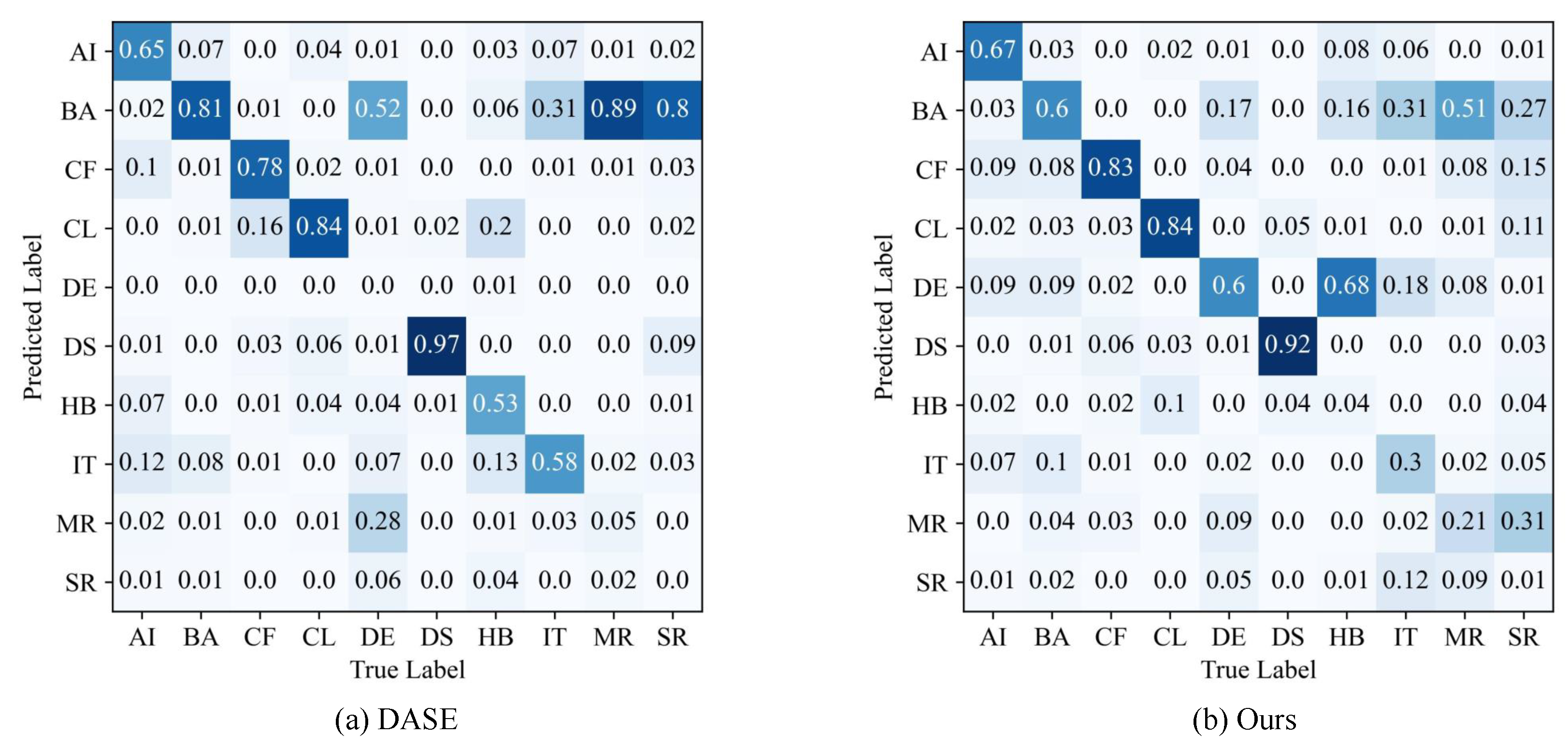{kind=link}
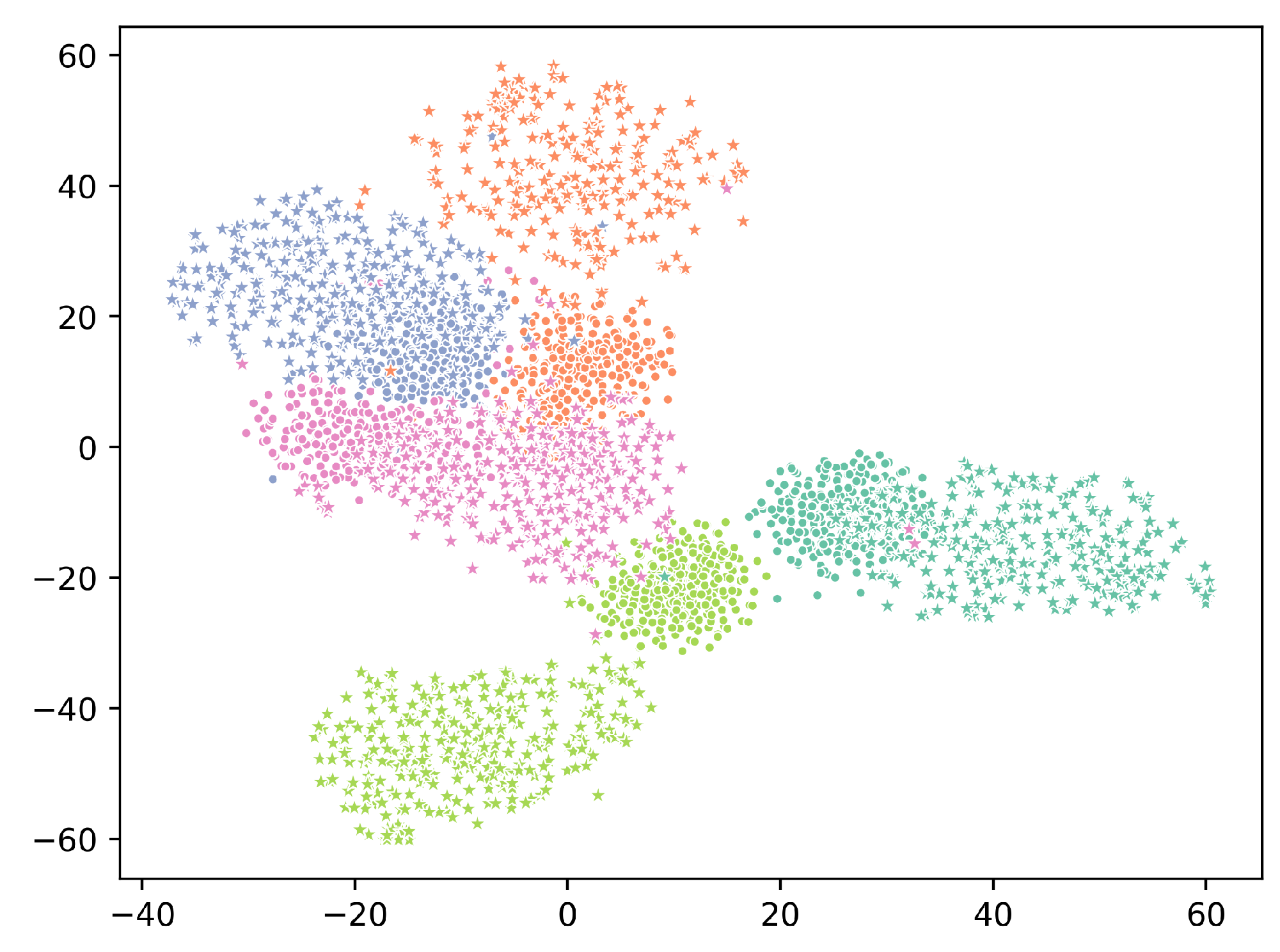{kind=link}
| Word2vec | Glove | Fasttext | Bert | UC Merced Land Use Dataset | |||
|---|---|---|---|---|---|---|---|
| acc | u | s | H | ||||
| ✓ | 0.6266 | 0.4869 | 0.7348 | 0.5857 | |||
| ✓ | 0.5602 | 0.4303 | 0.7389 | 0.5439 | |||
| ✓ | 0.5358 | 0.4007 | 0.6875 | 0.5063 | |||
| ✓ | 0.4536 | 0.3507 | 0.7138 | 0.4704 | |||
| Method | 16/5 | 13/8 | 10/11 | 7/14 |
|---|---|---|---|---|
| SSE [10] | 35.59 ± 5.90 | 23.42 ± 3.81 | 17.07 ± 3.56 | 10.82 ± 2.10 |
| DMaP [12] | 48.92 ± 8.71 | 30.91 ± 4.77 | 22.99 ± 4.81 | 17.30 ± 3.04 |
| SAE [36] | 49.50 ± 8.42 | 32.71 ± 6.49 | 24.04 ± 4.36 | 18.63 ± 2.76 |
| ZSL-LP [19] | 49.01 ± 8.85 | 31.26 ± 5.09 | 23.28 ± 4.13 | 17.55 ± 2.90 |
| ZSC-SA [20] | 50.42 ± 8.84 | 34.12 ± 6.10 | 24.68 ± 4.22 | 18.38 ± 2.74 |
| VSC [37] | 55.91 ± 11.77 | 36.26 ± 7.31 | 25.97 ± 5.79 | 19.53 ± 3.05 |
| VSOP [38] | 46.48 ± 7.83 | 29.81 ± 4.56 | 21.97 ± 4.11 | 16.14 ± 2.59 |
| f-CLSWGAN [14] | 56.97 ± 11.06 | 36.47 ± 6.28 | 27.89 ± 4.99 | 19.34 ± 3.96 |
| CYCLEWGAN [16] | 58.36 ± 10.04 | 36.81 ± 5.53 | 28.37 ± 4.53 | 21.15 ± 3.51 |
| RBGN [39] | 57.93 ± 11.56 | 36.95 ± 5.99 | 27.74 ± 5.16 | 20.67 ± 3.95 |
| DSAE [21] | 58.63 ± 11.23 | 37.50 ± 7.79 | 25.59 ± 5.24 | 20.18 ± 3.07 |
| CSPWGAN (our) | 62.66 ± 10.79 | 46.19 ± 5.52 | 35.17 ± 4.93 | 26.17 ± 3.87 |
| Method | 25/5 | 20/10 | 15/15 | 10/20 |
|---|---|---|---|---|
| SSE [10] | 46.11 ± 7.21 | 30.28 ± 4.90 | 19.94 ± 2.43 | 12.73 ± 1.27 |
| DMaP [12] | 43.40 ± 7.29 | 28.29 ± 4.78 | 19.38 ± 2.62 | 11.56 ± 1.29 |
| SAE [36] | 47.34 ± 8.42 | 32.12 ± 4.45 | 23.73 ± 3.28 | 13.77 ± 1.17 |
| ZSL-LP [19] | 46.77 ± 7.65 | 30.82 ± 4.90 | 21.78 ± 3.37 | 12.97 ± 1.06 |
| ZSC-SA [20] | 50.87 ± 8.74 | 33.46 ± 5.99 | 24.41 ± 3.83 | 15.89 ± 2.03 |
| VSC [37] | 52.61 ± 8.37 | 35.85 ± 5.52 | 26.11 ± 3.76 | 17.50 ± 2.19 |
| VSOP [38] | 48.56 ± 7.90 | 32.95 ± 5.52 | 24.84 ± 3.04 | 14.03 ± 2.47 |
| f-CLSWGAN [14] | 50.68 ± 11.25 | 33.89 ± 5.72 | 24.95 ± 2.96 | 17.26 ± 3.06 |
| CYCLEWGAN [16] | 52.37 ± 10.47 | 35.94 ± 5.46 | 25.28 ± 2.66 | 17.89 ± 2.86 |
| RBGN [39] | 51.99 ± 11.32 | 36.27 ± 5.65 | 24.83 ± 3.07 | 16.83 ± 3.14 |
| DSAE [21] | 53.49 ± 8.58 | 35.32 ± 5.17 | 25.92 ± 3.92 | 17.65 ± 2.52 |
| CSPWGAN (our) | 55.86 ± 10.60 | 37.93 ± 5.26 | 26.97 ± 2.53 | 19.43 ± 3.02 |
| Method | 35/10 | 30/15 | 25/20 | 20/25 |
|---|---|---|---|---|
| SSE [10] | 33.36 ± 3.58 | 23.30 ± 2.48 | 16.88 ± 2.29 | 12.94 ± 1.46 |
| DMaP [12] | 49.53 ± 6.31 | 38.07 ± 4.83 | 28.15 ± 3.86 | 23.95 ± 2.60 |
| SAE [36] | 44.81 ± 4.73 | 35.07 ± 3.91 | 24.65 ± 3.71 | 20.77 ± 2.02 |
| ZSL-LP [19] | 47.00 ± 6.64 | 36.45 ± 4.58 | 26.71 ± 3.43 | 22.90 ± 2.47 |
| ZSC-SA [20] | 48.40 ± 6.36 | 37.55 ± 4.54 | 28.27 ± 3.47 | 23.69 ± 2.38 |
| VSC [37] | 50.68 ± 6.60 | 40.92 ± 4.59 | 30.62 ± 3.10 | 25.51 ± 2.04 |
| VSOP [38] | 45.32 ± 5.71 | 36.09 ± 4.63 | 25.44 ± 3.13 | 22.18 ± 2.00 |
| f-CLSWGAN [14] | 45.35 ± 6.37 | 38.97 ± 4.93 | 30.06 ± 2.96 | 24.31 ± 2.57 |
| CYCLEWGAN [16] | 46.87 ± 5.99 | 39.85 ± 4.71 | 31.17 ± 2.66 | 25.06 ± 2.74 |
| RBGN [39] | 44.68 ± 6.14 | 40.31 ± 4.89 | 31.91 ± 3.07 | 24.89 ± 2.44 |
| DSAE [21] | 51.52 ± 6.91 | 41.94 ± 4.61 | 31.85 ± 3.32 | 25.20 ± 2.17 |
| CSPWGAN (our) | 50.66 ± 5.86 | 41.61 ± 4.48 | 32.09 ± 2.96 | 26.65 ± 2.33 |
| Method | UCM21 | AID30 | NWPU45 |
|---|---|---|---|
| CSPWGAN- | 59.84 ± 9.64 | 53.05 ± 10.07 | 47.82 ± 6.24 |
| CSPWGAN- | 60.43 ± 10.32 | 53.79 ± 10.34 | 48.79 ± 5.67 |
| CSPWGAN- | 59.67 ± 9.85 | 52.89 ± 9.59 | 47.07 ± 5.96 |
| CSPWGAN | 62.66 ± 10.79 | 55.86 ± 10.60 | 50.66 ± 5.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhang, D.; Wang, Y.; Lin, D.; Zhang, J. Generative Adversarial Networks for Zero-Shot Remote Sensing Scene Classification. Appl. Sci. 2022, 12, 3760. https://doi.org/10.3390/app12083760
Li Z, Zhang D, Wang Y, Lin D, Zhang J. Generative Adversarial Networks for Zero-Shot Remote Sensing Scene Classification. Applied Sciences. 2022; 12(8):3760. https://doi.org/10.3390/app12083760
Chicago/Turabian StyleLi, Zihao, Daobing Zhang, Yang Wang, Daoyu Lin, and Jinghua Zhang. 2022. "Generative Adversarial Networks for Zero-Shot Remote Sensing Scene Classification" Applied Sciences 12, no. 8: 3760. https://doi.org/10.3390/app12083760