
Affection Enhanced Relational Graph Attention Network for Sarcasm Detection


Abstract
:1. Introduction
- We exploit the RGAT network to better learn the syntactic information by incorporating dependency relation information, which contributes to information interaction of structural relevant word pairs with long distances.
- A combination model of affective and relational graphs is explored to extract the incongruity in sarcasm detection.
- Experimental results on a number of benchmark datasets demonstrate that our proposed method achieves the state-of-the-art performances in sarcasm detection.
2. Related Works
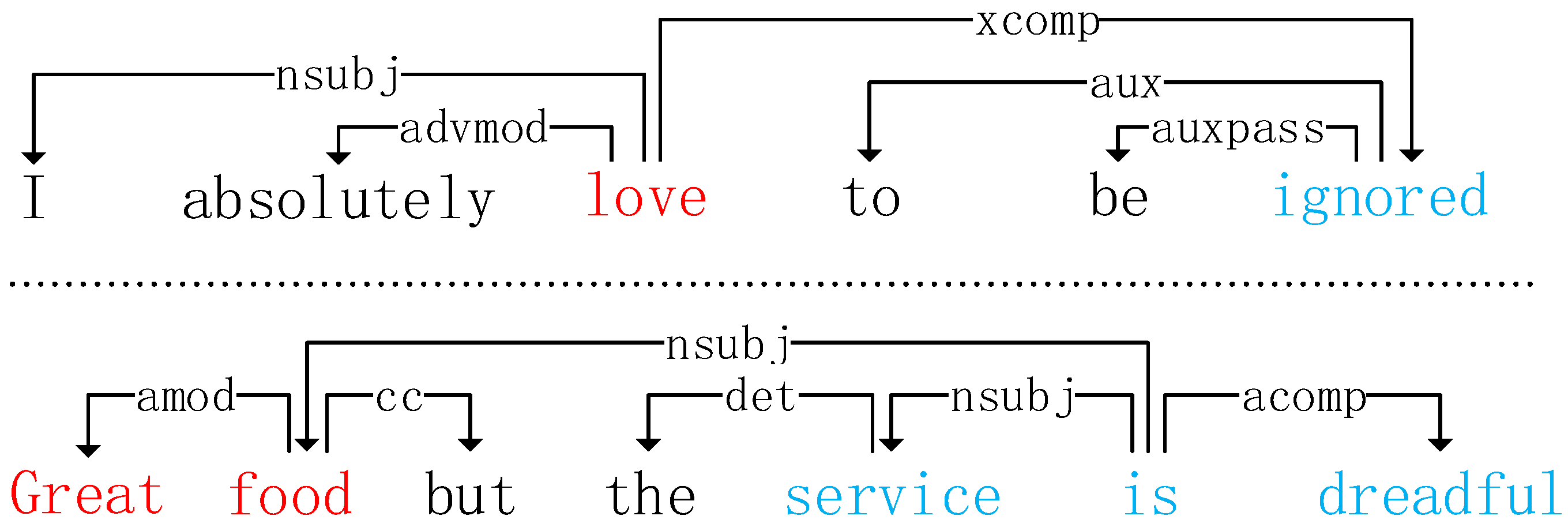
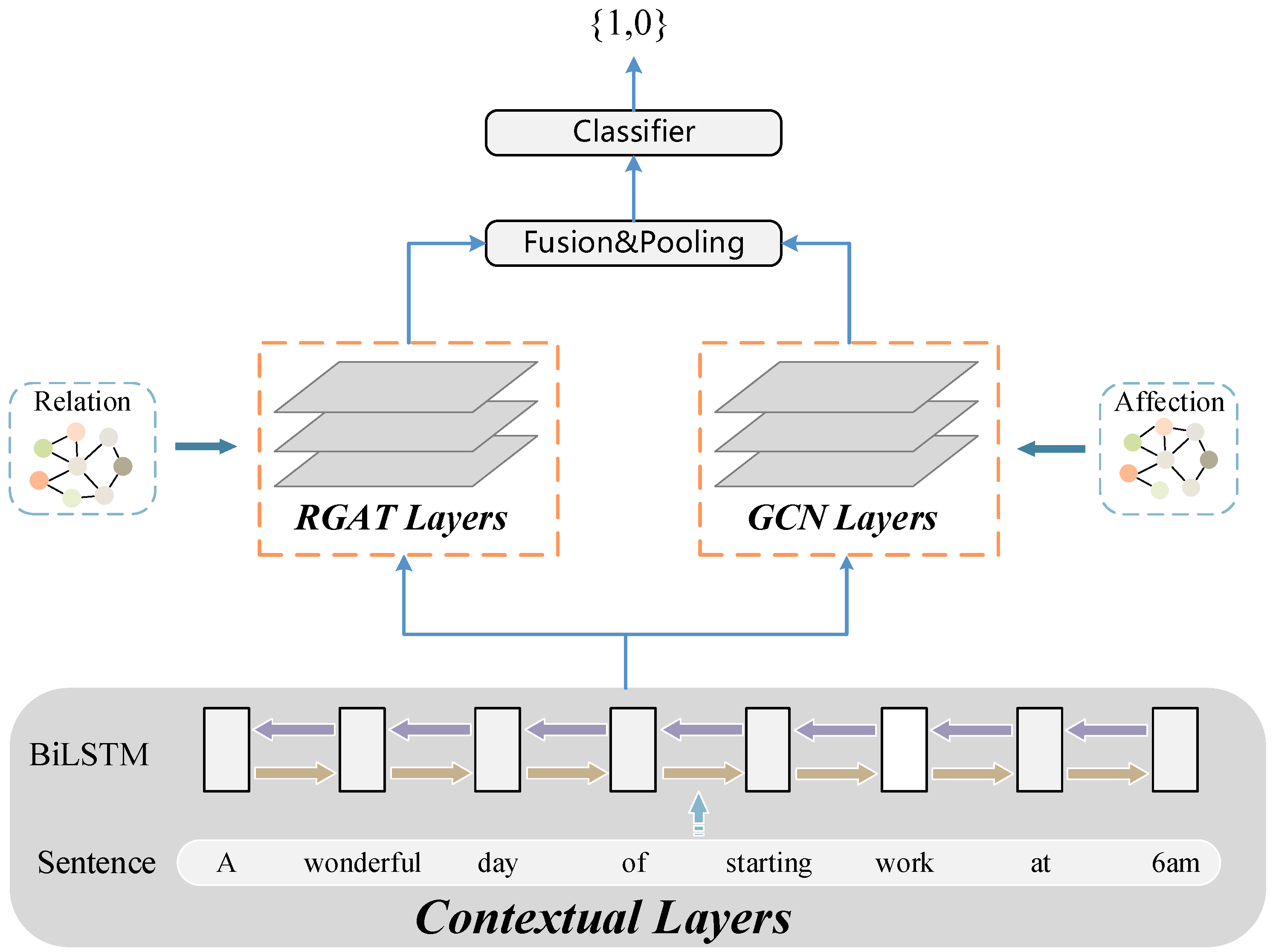
3. Methodology
3.1. Contextual Encoder
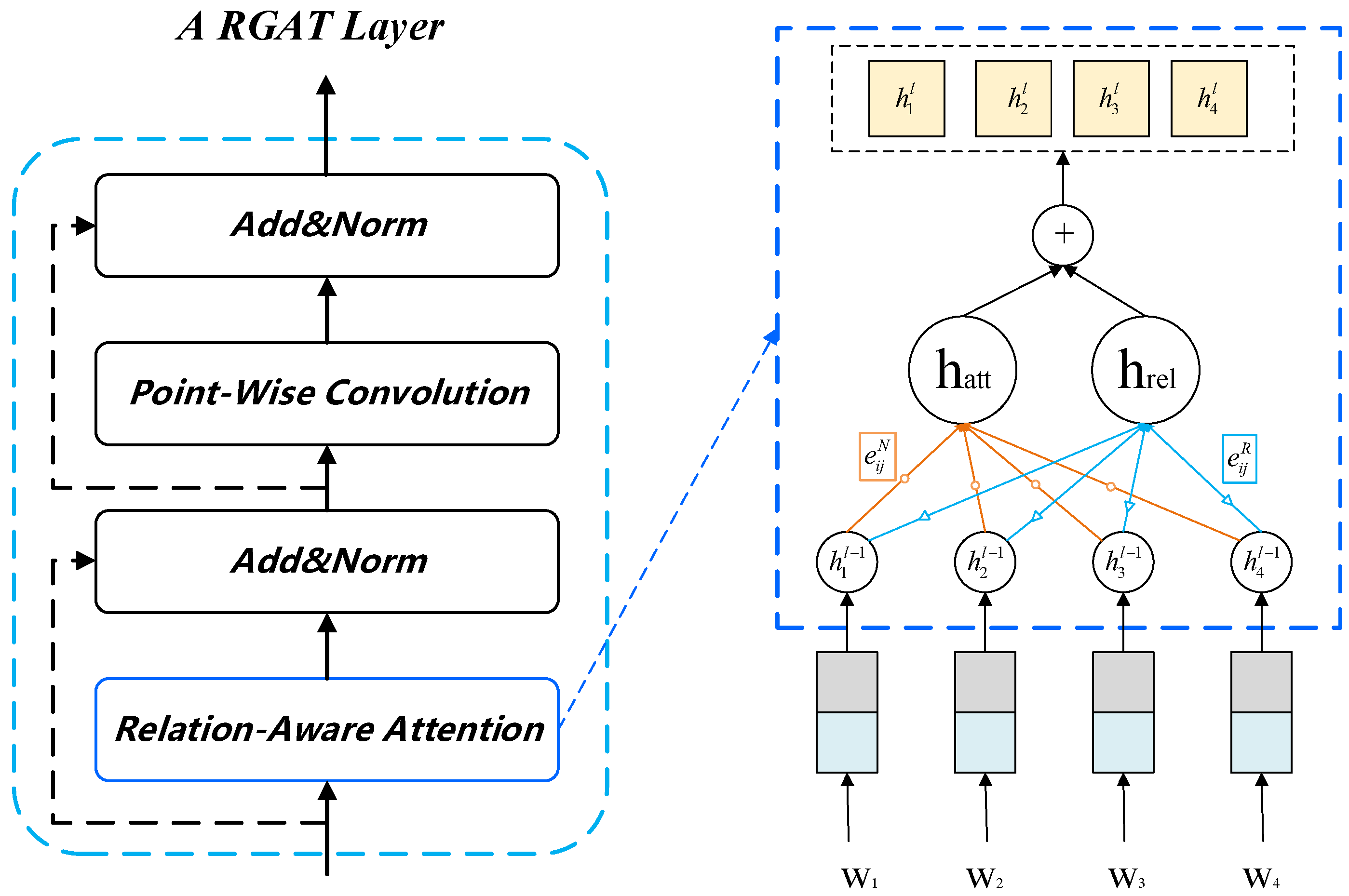
3.2. Relational Graph Attention Network
3.3. Affective Graph Convolutional Network
3.4. Classification Model
4. Experiments
4.1. Datasets
- IAC(Internet Argument Corpus): The dataset is from a forum used for political debating and voting, which is characterized by long sentences with satire style. We use two versions of the dataset from [32], which are denoted as IAC-V1 (https://nlds.soe.ucsc.edu/sarcasm1, in 1 January 2022) and IAV-V2 (https://nlds.soe.ucsc.edu/sarcasm2, in 1 January 2022), respectively.
- Tweets: We use two datasets collected by [3,33]. We get all the tweets through Twitter API with the provided tweet IDs (http://api.twitter.com/, in 1 January 2022)
- Reddit: We use two subsets (i.e., movies and technology) of the Reddit dataset (http://nlp.cs.princeton.edu/SARC, in 1 January 2022) provided by [34] for sarcasm detection.
4.2. Baselines
- NBOW Tay et al. [6] use a simple neural bag-of-words baseline that sums all the word embeddings and passes the summed vector into a simple logistic regression layer.
- CNN is a vanilla Convolutional Neural Network with max-pooling.
- GRNN Zhang et al. [35] extracts local syntactic and semantic information with a Bidirectional Gated Recurrent Unit.
- CNN-LSTM-DNN Ghosh and Veale [11] combines CNN, LSTM, and Deep Neural Network via stacking for prediction.
- ATT-LSTM Yang et al. [36] adopt a LSTM model with a neural attention mechanism applied to all the LSTM hidden outputs.
- SIARN [6] is an attention-based neural model that looks in-between instead of across.
- MIRAN [6] is a Multi-dimensional Intra-Attention Recurrent Network based on the intuition of compositional learning by leveraging intra-sentence relationships.
- SAWS Pan et al. [7] proposes a novel model based on self-attention mechanism of weighted snippets.
- ADGCN Lou et al. [10] proposed a GCN-based model to draw long-range incongruity patterns and inconsistent expressions over the context for sarcasm detection by means of interactively modeling the affective and dependency information.
4.3. Settings
4.4. Results
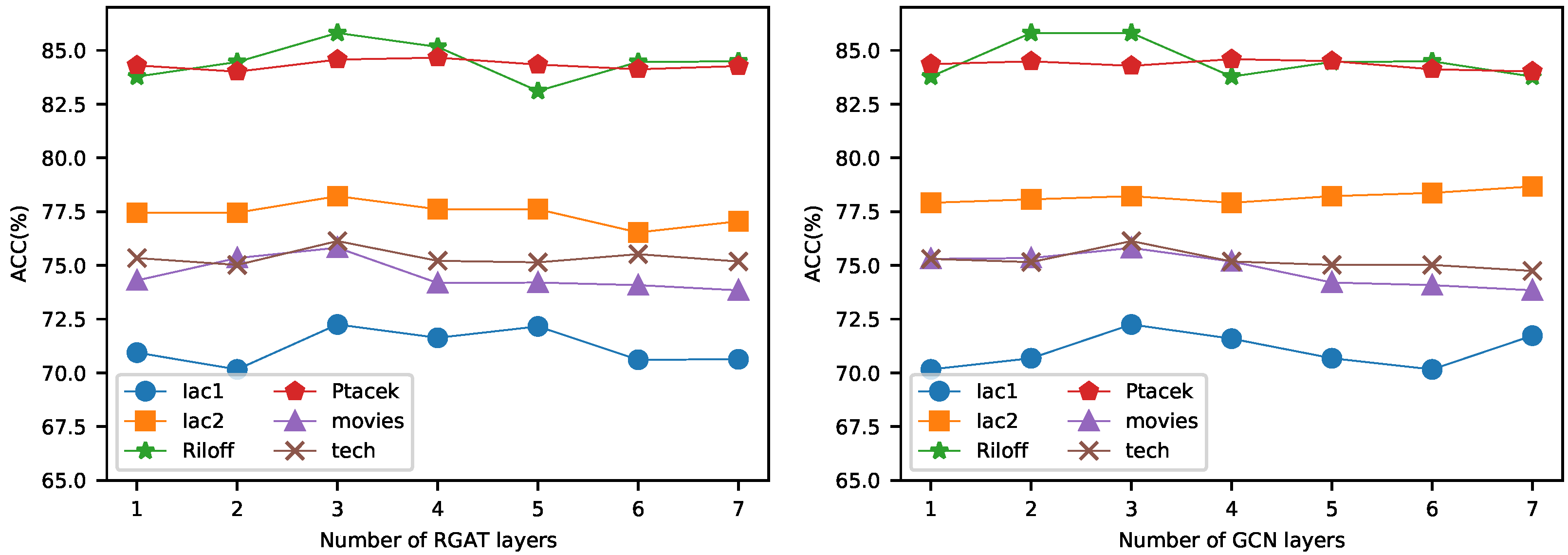
4.5. Impact of Stacked Number of RGAT and GCN
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gibbs, R.W. On the psycholinguistics of sarcasm. J. Exp. Psychol. Gen. 1986, 115, 3–15. [Google Scholar] [CrossRef]
- Bamman, D.; Smith, N.A. Contextualized Sarcasm Detection on Twitter. In Proceedings of the International AAAI Conference on Web and Social Media (ICWSM), Oxford, UK, 26–29 May 2015. [Google Scholar]
- Riloff, E.; Qadir, A.; Surve, P.; Silva, L.D.; Gilbert, N.; Huang, R. Sarcasm as Contrast between a Positive Sentiment and Negative Situation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP), Seattle, WA, USA, 26 August 2013. [Google Scholar]
- González-Ibáñez, R.I.; Muresan, S.; Wacholder, N. Identifying Sarcasm on Twitter: A Closer Look. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL), Portland, OR, USA, 23 June 2011. [Google Scholar]
- Lunando, E.; Purwarianti, A. Indonesian social media sentiment analysis with sarcasm detection. In Proceedings of the 2013 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Depok, Indonesia, 23–25 October 2013; pp. 195–198. [Google Scholar]
- Tay, Y.; Luu, A.T.; Hui, S.C.; Su, J. Reasoning with Sarcasm by Reading In-Between. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL 2018), Melbourne, Australia, 15–20 July 2018; Gurevych, I., Miyao, Y., Eds.; Association for Computational Linguistics: Melbourne, Australia, 2018; Volume 1: Long Papers, pp. 1010–1020. [Google Scholar] [CrossRef]
- Pan, H.; Lin, Z.; Fu, P.; Wang, W. Modeling the Incongruity Between Sentence Snippets for Sarcasm Detection. In Proceedings of the ECAI 2020—24th European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020; Giacomo, G.D., Catalá, A., Dilkina, B., Milano, M., Barro, S., Bugarín, A., Lang, J., Eds.; IOS Press: Santiago de Compostela, Spain, 2020; Volume 325, pp. 2132–2139. [Google Scholar] [CrossRef]
- Babanejad, N.; Davoudi, H.; An, A.; Papagelis, M. Affective and Contextual Embedding for Sarcasm Detection. In Proceedings of the 28th International Conference on Computational Linguistics (COLING 2020), Barcelona, Spain, 8–13 December 2020; pp. 225–243. [Google Scholar] [CrossRef]
- Liang, B.; Lou, C.; Li, X.; Gui, L.; Yang, M.; Xu, R. Multi-Modal Sarcasm Detection with Interactive In-Modal and Cross-Modal Graphs. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20 October 2021; pp. 4707–4715. [Google Scholar] [CrossRef]
- Lou, C.; Liang, B.; Gui, L.; He, Y.; Dang, Y.; Xu, R. Affective Dependency Graph for Sarcasm Detection. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Montréal, QC, Canada, 11–15 July 2021; pp. 1844–1849. [Google Scholar] [CrossRef]
- Ghosh, A.; Veale, T. Fracking Sarcasm using Neural Network. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, WASSA@NAACL-HLT 2016, San Diego, CA, USA, 16 June 2016; Balahur, A., der Goot, E.V., Vossen, P., Montoyo, A., Eds.; The Association for Computer Linguistics: Berlin, Germany, 2016; pp. 161–169. [Google Scholar] [CrossRef]
- Busbridge, D.; Sherburn, D.; Cavallo, P.; Hammerla, N.Y. Relational Graph Attention Networks. arXiv 2019, arXiv:1904.05811. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Maynard, D.; Greenwood, M.A. Who cares about Sarcastic Tweets? Investigating the Impact of Sarcasm on Sentiment Analysis. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC 2014), Reykjavik, Iceland, 26–31 May 2014; pp. 4238–4243. [Google Scholar]
- Davidov, D.; Tsur, O.; Rappoport, A. Semi-supervised recognition of sarcastic sentences in Twitter and Amazon. In Proceedings of the CoNLLco 2010, Uppsala, Sweden, 15–16 July 2010. [Google Scholar]
- Joshi, A.; Sharma, V.; Bhattacharyya, P. Harnessing Context Incongruity for Sarcasm Detection. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL), Beijing, China, 26–31 July 2015. [Google Scholar]
- Mishra, A.; Kanojia, D.; Nagar, S.; Dey, K.; Bhattacharyya, P. Harnessing Cognitive Features for Sarcasm Detection. arXiv 2016, arXiv:abs/1701.05574. [Google Scholar]
- Reyes, A.; Rosso, P. Making objective decisions from subjective data: Detecting irony in customer reviews. Decis. Support Syst. 2012, 53, 754–760. [Google Scholar] [CrossRef]
- Pawar, N.; Bhingarkar, S. Machine Learning based Sarcasm Detection on Twitter Data. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 957–961. [Google Scholar]
- Farías, D.I.H. Irony and Sarcasm Detection on Twitter: The Role of Affective Content. Proces. Leng. Natural 2019, 62, 107–110. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar] [CrossRef] [Green Version]
- Das, D.; Clark, A.J. Sarcasm Detection on Flickr Using a CNN. In Proceedings of the 2018 International Conference on Computing and Big Data, Tibet, China, 20–22 April 2018. [Google Scholar]
- Porwal, S.; Ostwal, G.; Phadtare, A.; Pandey, M.; Marathe, M. Sarcasm Detection Using Recurrent Neural Network. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; pp. 746–748. [Google Scholar]
- Hiai, S.; Shimada, K. Sarcasm Detection Using RNN with Relation Vector. Int. J. Data Warehous. Min. 2019, 15, 66–78. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Kumar, A.; Narapareddy, V.T.; Veerubhotla, A.S.; Malapati, A.; Neti, L.B.M. Sarcasm Detection Using Multi-Head Attention Based Bidirectional LSTM. IEEE Access 2020, 8, 6388–6397. [Google Scholar] [CrossRef]
- Duan, S.; Zhao, H. Attention Is All You Need for Chinese Word Segmentation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, 16–20 November 2020; pp. 3862–3872. [Google Scholar] [CrossRef]
- He, S.; Guo, F.; Qin, S. Sarcasm Detection Using Graph Convolutional Networks with Bidirectional LSTM. In Proceedings of the 2020 3rd International Conference on Big Data Technologies, Qingdao, China, 18–20 September 2020. [Google Scholar]
- Huang, B.; Carley, K.M. Syntax-Aware Aspect Level Sentiment Classification with Graph Attention Networks. arXiv 2019, arXiv:abs/1909.02606. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:abs/1810.04805. [Google Scholar]
- Cambria, E.; Li, Y.; Xing, F.Z.; Poria, S.; Kwok, K. SenticNet 6: Ensemble Application of Symbolic and Subsymbolic AI for Sentiment Analysis. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, 19–23 October 2020; pp. 105–114. [Google Scholar] [CrossRef]
- Lukin, S.M.; Walker, M.A. Really? Well. Apparently Bootstrapping Improves the Performance of Sarcasm and Nastiness Classifiers for Online Dialogue. arXiv 2017, arXiv:abs/1708.08572. [Google Scholar]
- Ptácek, T.; Habernal, I.; Hong, J. Sarcasm Detection on Czech and English Twitter. In Proceedings of the COLING 2014, 25th International Conference on Computational Linguistics, Technical Papers, Dublin, Ireland, 23–29 August 2014; Hajic, J., Tsujii, J., Eds.; ACL: Baltimore, MD, USA, 2014; pp. 213–223. [Google Scholar]
- Khodak, M.; Saunshi, N.; Vodrahalli, K. A Large Self-Annotated Corpus for Sarcasm. arXiv 2018, arXiv:1704.05579. [Google Scholar]
- Zhang, M.; Zhang, Y.; Fu, G. Tweet Sarcasm Detection Using Deep Neural Network. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics, Technical Papers, Osaka, Japan, 11–16 December 2016; Calzolari, N., Matsumoto, Y., Prasad, R., Eds.; ACL: Osaka, Japan, 2016; pp. 2449–2460. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.J.; Hovy, E.H. Hierarchical Attention Networks for Document Classification. In Proceedings of the NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Knight, K., Nenkova, A., Rambow, O., Eds.; The Association for Computational Linguistics: Osaka, Japan, 2016; pp. 1480–1489. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; pp. 8024–8035. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; Moschitti, A., Pang, B., Daelemans, W., Eds.; ACL: Baltimore, MD, USA, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Test | ||
|---|---|---|---|---|
| Sarcasm | None | Sarcasm | None | |
| IAC-V1 | 862 | 859 | 97 | 94 |
| IAC-V2 | 2947 | 2921 | 313 | 339 |
| Tweets-1 (Riloff) | 282 | 1051 | 35 | 113 |
| Tweets-2 (Ptáček) | 23,456 | 24,387 | 2569 | 2634 |
| Reddit-1 (movies) | 5521 | 5607 | 1389 | 1393 |
| Reddit-2 (technology) | 6419 | 6393 | 1596 | 1607 |
| Model | IAC-V1 | IAC-V2 | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | Acc. (%) | Precision (%) | Recall (%) | F1 (%) | Acc. (%) | |
| NBOW | 57.17 | 57.03 | 57.00 | 57.51 | 66.01 | 66.03 | 66.02 | 66.09 |
| CNN | 58.21 | 58.00 | 57.95 | 58.55 | 68.45 | 68.18 | 68.21 | 68.56 |
| GRNN | 56.21 | 56.21 | 55.96 | 55.96 | 62.26 | 61.87 | 61.21 | 61.37 |
| CNN-LSTM-DNN | 55.50 | 54.60 | 53.31 | 55.96 | 64.31 | 64.33 | 64.31 | 64.38 |
| ATT-LSTM | 58.98 | 57.93 | 57.23 | 59.07 | 70.04 | 69.62 | 69.63 | 69.96 |
| SIARN | 63.94 | 63.45 | 60.52 | 62.69 | 72.17 | 71.81 | 71.85 | 72.10 |
| MIARN | 63.88 | 63.71 | 63.18 | 63.21 | 72.92 | 72.93 | 72.75 | 72.75 |
| SAWS | 66.22 | 65.65 | 65.60 | 66.13 | 73.25 | 73.40 | 73.43 | 73.55 |
| ADGCN | 68.08 | 68.08 | 68.06 | 68.06 | 76.96 | 76.98 | 76.97 | 76.99 |
| ARGAT (proposal) | 72.26 | 72.26 | 72.25 | 72.25 | 78.41 | 78.19 | 78.21 | 78.22 |
| Model | Tweets (Riloff) | Tweets (Ptacek) | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | Acc. (%) | Precision (%) | Recall (%) | F1 (%) | Acc. (%) | |
| NBOW | 71.28 | 62.37 | 64.13 | 79.23 | 80.02 | 79.06 | 79.43 | 80.39 |
| CNN | 71.04 | 67.13 | 68.55 | 79.48 | 82.13 | 79.67 | 80.39 | 81.65 |
| GRNN | 66.32 | 64.74 | 65.40 | 76.41 | 82.06 | 81.02 | 82.43 | 82.20 |
| CNN-LSTM-DNN | 69.76 | 66.62 | 67.81 | 78.72 | 79.65 | 79.12 | 79.20 | 79.94 |
| ATT-LSTM | 69.76 | 66.62 | 67.81 | 78.72 | 81.62 | 81.45 | 81.56 | 81.56 |
| SIARN | 73.82 | 73.26 | 73.24 | 82.31 | 82.62 | 82.51 | 82.59 | 82.59 |
| MIARN | 73.34 | 68.34 | 70.10 | 80.77 | 82.34 | 82.72 | 82.78 | 82.78 |
| SAWS | 74.69 | 74.08 | 74.34 | 81.72 | 83.25 | 83.40 | 83.43 | 83.55 |
| ADGCN | 74.81 | 76.22 | 75.45 | 81.75 | 83.85 | 83.85 | 83.85 | 83.86 |
| ARGAT (proposal) | 83.19 | 76.24 | 79.78 | 85.81 | 84.28 | 84.28 | 84.28 | 84.28 |
| Model | Reddit (/r/Movies) | Reddit (/r/Technology) | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | Acc. (%) | Precision (%) | Recall (%) | F1 (%) | Acc. (%) | |
| NBOW | 67.33 | 66.56 | 66.82 | 67.52 | 65.45 | 65.62 | 65.52 | 66.55 |
| CNN | 65.97 | 65.97 | 65.97 | 66.24 | 65.88 | 62.90 | 62.85 | 66.80 |
| GRNN | 66.16 | 66.16 | 66.16 | 66.42 | 66.56 | 66.73 | 66.66 | 67.65 |
| CNN-LSTM-DNN | 68.27 | 67.87 | 67.95 | 68.50 | 66.14 | 66.73 | 65.74 | 66.00 |
| ATT-LSTM | 68.11 | 67.87 | 67.94 | 68.37 | 68.20 | 68.78 | 67.44 | 67.22 |
| SIARN | 69.59 | 69.48 | 69.52 | 69.84 | 69.35 | 70.05 | 69.22 | 69.57 |
| MIARN | 69.68 | 69.37 | 69.54 | 69.90 | 68.97 | 69.30 | 69.09 | 69.91 |
| SAWS | 71.79 | 71.77 | 71.76 | 71.77 | 72.50 | 72.45 | 72.45 | 72.48 |
| ADGCN | 74.48 | 74.58 | 74.47 | 74.48 | 75.59 | 75.59 | 75.58 | 75.59 |
| ARGAT (proposal) | 75.82 | 75.82 | 75.81 | 75.82 | 76.13 | 76.13 | 76.13 | 76.13 |
| Model | IAC-V1 | IAC-V2 | Tweets-1 | Tweets-2 | Reddit-1 | Reddit-2 |
|---|---|---|---|---|---|---|
| ARGAT | 72.25 | 78.22 | 85.81 | 84.28 | 75.82 | 76.13 |
| w/o | 71.11 | 77.45 | 82.43 | 84.09 | 74.04 | 74.93 |
| w/o | 70.06 | 76.99 | 81.76 | 83.87 | 73.15 | 73.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Lin, F.; Chen, W.; Liu, B. Affection Enhanced Relational Graph Attention Network for Sarcasm Detection. Appl. Sci. 2022, 12, 3639. https://doi.org/10.3390/app12073639
Li G, Lin F, Chen W, Liu B. Affection Enhanced Relational Graph Attention Network for Sarcasm Detection. Applied Sciences. 2022; 12(7):3639. https://doi.org/10.3390/app12073639
Chicago/Turabian StyleLi, Guowei, Fuqiang Lin, Wangqun Chen, and Bo Liu. 2022. "Affection Enhanced Relational Graph Attention Network for Sarcasm Detection" Applied Sciences 12, no. 7: 3639. https://doi.org/10.3390/app12073639