
Non-Maximum Suppression Performs Later in Multi-Object Tracking


Abstract
:1. Introduction
- In order to avoid good detection boxes being filtered out and reducing the impact of detection tasks on tracking, a method of performing NMS later in tracking is proposed. NMS does not play a role in the detection stage, but plays a role later, serving the tracking and prediction stage, effectively improving the performance of MOT.
- Experimental results show that the method proposed in this paper can effectively solve the occlusion problem.
- The effectiveness of the method proposed in this paper is verified through a large number of experiments, and good results have been achieved on the MOT17 and MOT20 datasets, and the state-of-the-art FP and ML metrics have been achieved.
2. Related Work
2.1. One Stage MOT
2.2. Two-Stage MOT
2.3. MOT with Person ReID
3. Materials and Methods
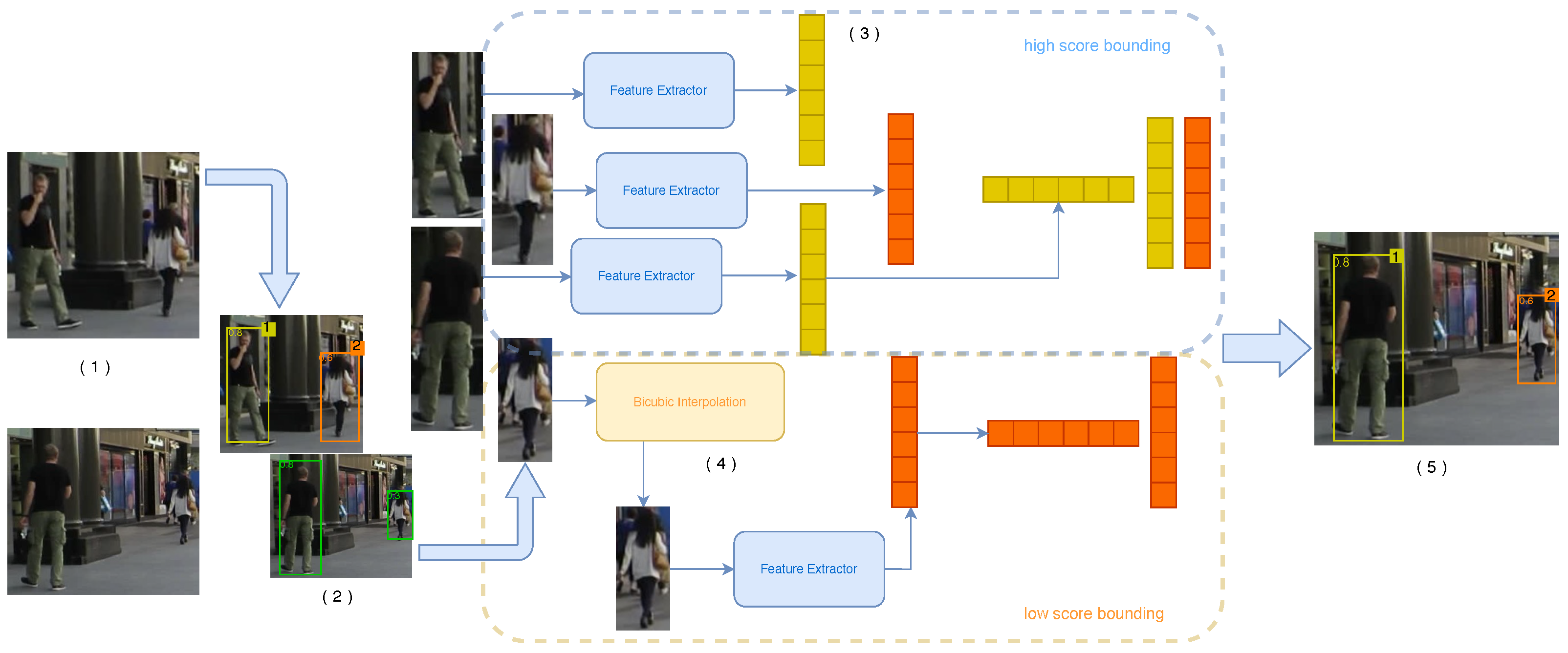
3.1. Performing NMS Later
3.1.1. NMS Performs in Tracking
3.1.2. ID Match
3.2. Bicubic Interpolation
3.3. Unsupervised Pre-Training for ReID
4. Results
4.1. Datesets and Settings
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Comparison with State-of-the-Art
4.2.1. Comparison on MOT17
4.2.2. Comparison on MOT20
4.3. Ablation Study
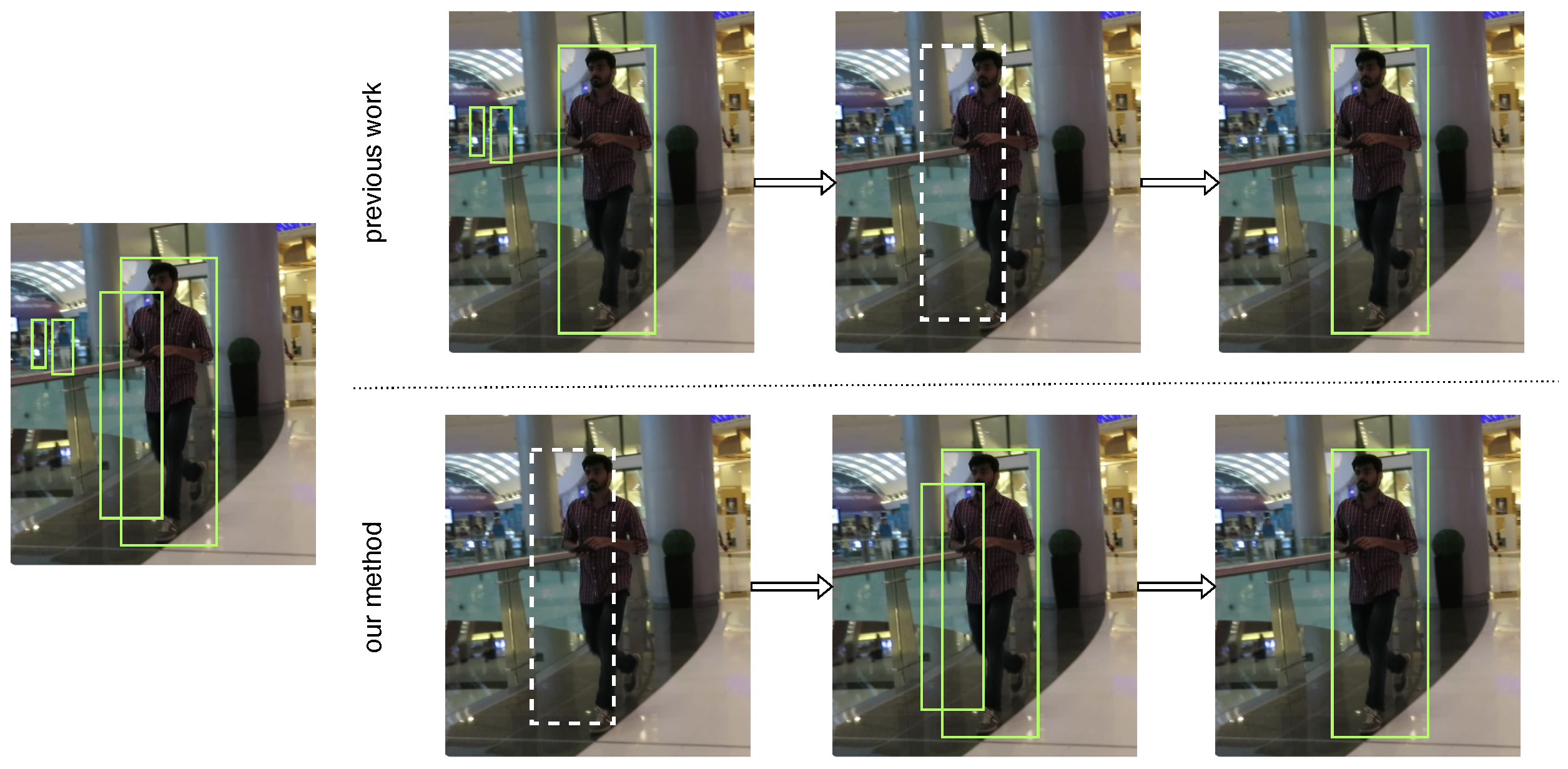
4.4. Occlusion Problem
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MOT | Multiple Object Tracking |
| NMS | Non-Maximum Suppression |
| IOU | Intersection over Union |
| ReID | Re-Identification |
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards real-time multi-object tracking. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin, Germany, 2020. Part XI 16. pp. 107–122. [Google Scholar]
- Liang, C.; Zhang, Z.; Lu, Y.; Zhou, X.; Li, B.; Ye, X.; Zou, J. Rethinking the competition between detection and reid in multi-object tracking. arXiv 2020, arXiv:2010.12138. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Wang, Q.; Zheng, Y.; Pan, P.; Xu, Y. Multiple Object Tracking with Correlation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3876–3886. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin, Germany, 2020; pp. 474–490. [Google Scholar]
- Zhou, T.; Li, J.; Wang, S.; Tao, R.; Shen, J. Matnet: Motion-attentive transition network for zero-shot video object segmentation. IEEE Trans. Image Process. 2020, 29, 8326–8338. [Google Scholar] [CrossRef] [PubMed]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. ByteTrack: Multi-Object Tracking by Associating Every Detection Box. arXiv 2021, arXiv:2110.06864. [Google Scholar]
- Chu, P.; Wang, J.; You, Q.; Ling, H.; Liu, Z. Spatial-temporal graph transformer for multiple object tracking. arXiv 2021, arXiv:2104.00194. [Google Scholar]
- Zhou, T.; Li, J.; Li, X.; Shao, L. Target-aware object discovery and association for unsupervised video multi-object segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6985–6994. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. Real-time multiple people tracking with deeply learned candidate selection and person re-identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef] [Green Version]
- Fu, D.; Chen, D.; Bao, J.; Yang, H.; Yuan, L.; Zhang, L.; Li, H.; Chen, D. Unsupervised Pre-training for Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14750–14759. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled Samples Generated by GAN Improve the Person Re-Identification Baseline in Vitro. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1116–1124. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 79–88. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 28 October 2019; pp. 3702–3712. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. Mot20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar]
- Kasturi, R.; Goldgof, D.; Soundararajan, P.; Manohar, V.; Garofolo, J.; Bowers, R.; Boonstra, M.; Korzhova, V.; Zhang, J. Framework for performance evaluation of face, text, and vehicle detection and tracking in video: Data, metrics, and protocol. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 319–336. [Google Scholar] [CrossRef] [PubMed]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; Springer: Berlin, Germany, 2016; pp. 17–35. [Google Scholar]
- Li, Y.; Huang, C.; Nevatia, R. Learning to associate: Hybridboosted multi-target tracker for crowded scene. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2953–2960. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A benchmark for detecting human in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zeng, F.; Dong, B.; Wang, T.; Chen, C.; Zhang, X.; Wei, Y. MOTR: End-to-End Multiple-Object Tracking with TRansformer. arXiv 2021, arXiv:2105.03247. [Google Scholar]
- Meinhardt, T.; Kirillov, A.; Leal-Taixe, L.; Feichtenhofer, C. Trackformer: Multi-object tracking with transformers. arXiv 2021, arXiv:2101.02702. [Google Scholar]
- Brasó, G.; Leal-Taixé, L. Learning a neural solver for multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6247–6257. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Mode | MOTA↑ | IDF1↑ | MT↑ | ML↓ | FP↓ | FN↓ | IDs↓ |
|---|---|---|---|---|---|---|---|---|
| MOTR [32] | one-stage | 67.4 | 67.0 | 34.6 | 24.5 | 32,355 | 149,400 | 1992 |
| CorrTracker [8] | one-stage | 76.5 | 73.6 | 47.6 | 12.7 | 29,808 | 99,510 | 3369 |
| FairMOT [7] | one-stage | 73.7 | 72.3 | 43.2 | 17.3 | 27,507 | 117,477 | 3303 |
| CSTrack++ [6] | one-stage | 70.6 | 71.8 | 38.2 | 17.8 | - | - | 1071 |
| TrackFormer [33] | one-stage | 62.5 | 60.7 | - | - | 32,828 | 174,921 | 3917 |
| TransMOT [13] | two-stage | 76.7 | 75.1 | 51.0 | 16.4 | 36,231 | 125,665 | 1042 |
| MPNTrack [34] | two-stage | 58.8 | 61.7 | 28.8 | 33.5 | 17,413 | 213,594 | 1185 |
| Our method | two-stage | 78.3 | 76.1 | 50.8 | 11.8 | 33,754 | 93,797 | 1435 |
| Method | Mode | MOTA↑ | IDF1↑ | MT↑ | ML↓ | FP↓ | FN↓ | IDs↓ |
|---|---|---|---|---|---|---|---|---|
| CorrTracker [8] | one-stage | 65.2 | 69.1 | 66.4 | 8.9 | 79,429 | 95,855 | 5183 |
| FairMOT [7] | one-stage | 61.8 | 67.3 | 68.8 | 7.6 | 103,440 | 88,901 | 5243 |
| TransMOT [13] | two-stage | 77.5 | 75.2 | 70.7 | 9.1 | 34,201 | 80,788 | 1615 |
| Our method | two-stage | 75.7 | 71.4 | 68.3 | 9.7 | 42,134 | 90,833 | 2026 |
| Method | MOTA↑ | IDF1↑ | FP↓ | FN↓ | IDs↓ |
|---|---|---|---|---|---|
| Baseline + IOU | 66.3% | 70.4% | 56,794 | 102,512 | 2072 |
| Baseline + NMS + IOU | 75.1% | 71.2% | 40,654 | 96,341 | 2043 |
| Baseline + NMS + UR | 75.4% | 71.2% | 42,372 | 98,784 | 2032 |
| Baseline + NMS + UR + BI | 75.7% | 71.4% | 42,134 | 90,833 | 2026 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, H.; Wu, T.; Zhang, Q.; Zhou, H. Non-Maximum Suppression Performs Later in Multi-Object Tracking. Appl. Sci. 2022, 12, 3334. https://doi.org/10.3390/app12073334
Liang H, Wu T, Zhang Q, Zhou H. Non-Maximum Suppression Performs Later in Multi-Object Tracking. Applied Sciences. 2022; 12(7):3334. https://doi.org/10.3390/app12073334
Chicago/Turabian StyleLiang, Hong, Ting Wu, Qian Zhang, and Hui Zhou. 2022. "Non-Maximum Suppression Performs Later in Multi-Object Tracking" Applied Sciences 12, no. 7: 3334. https://doi.org/10.3390/app12073334