1. Introduction
Convolution neural networks (CNNs) have made significant progress on various computer vision tasks, e.g., image classification [
1,
2,
3,
4], object detection [
5,
6,
7], and segmentation [
8,
9]. However, the large scale and tremendous parameters of CNNs may result in overfitting and reduce generalization, which brings great challenges to network training. A series of training strategies have been proposed to solve these problems, including data augmentation [
10,
11,
12], batch normalization [
13], and knowledge distillation [
14]. Those approaches aim to improve the performance and generalization of CNNs by changing the input, feature space, or output.
In particular, some methods improve the generalization by strengthening the learning of the feature. As a representative regularization method, Dropout [
15] randomly discards parts of the internal features in the network to improve the influence of the remaining features. SpatialDropout [
16] randomly discards all the channels rather than individual activations for the CNN. DropBlock [
17] randomly drops some contiguous regions of a feature map. Besides, self-distillation distills the knowledge itself to improve the utilization of internal features. Be your own teacher (BYOT) [
18] improves the efficiency of network training by squeezing the knowledge in the deeper portion of the networks into the shallow ones. As a state-of-the-art self-distillation method, classwise self-knowledge distillation [
19] improves the generalization of the same kind of images from the perspective of intra-class distillation. In this paper, we focused on developing a new training strategy for CNNs to strengthen the network’s learning of the local features. Different from the above methods, which enhance the local feature learning by discarding parts of the feature or using a distillation technique, our method divides the complete feature into two complementary parts and reuses this divided feature to make the network capture different local information, which is able to achieve better generalization with negligible extra computation cost.
Our motivation stems from a phenomenon in the training process of CNNs: information loss inevitably occurs after going through the pooling layer, which may lead to the CNN’s inadequate learning of the local features. We performed several visualization experiments [
20] to explore the difference between the global features and the local features. The result empirically suggested that different parts of the feature contain different semantics, and the local features contain different semantics compared with the global features. However, the network will inevitably lose the local information during feedforward propagation. Making the network contain more local feature knowledge is a benefit to the training, but how to make the local features of images sufficiently mined by the network is a great challenge.
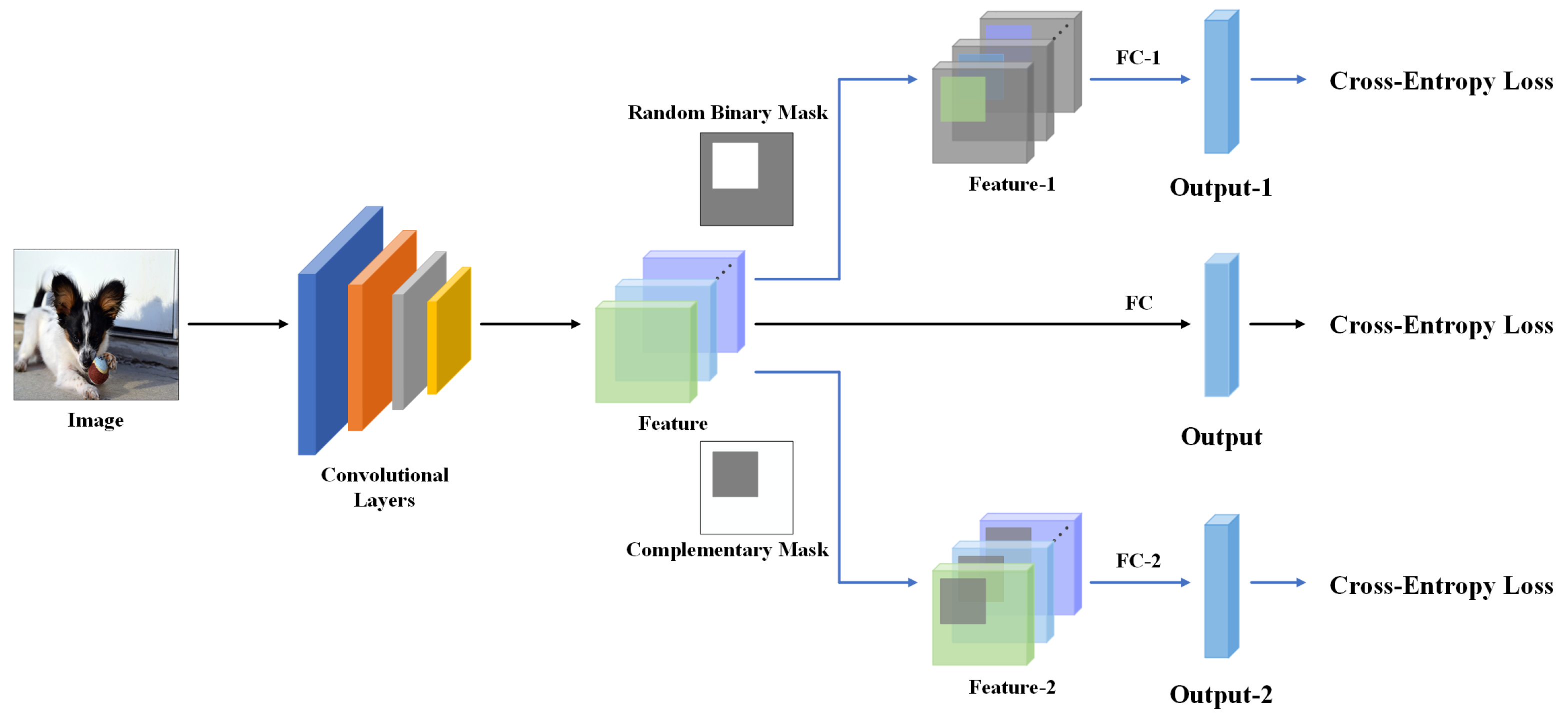
Based on the above observations, we propose a parameter-free training method: Feature Mining, which aims to make the network efficiently learn the local features. This strategy requires two steps: Feature Segmentation and Feature Reusing. During Feature Segmentation, we divide the feature into two complementary parts by two binary masks. Feature Reusing denotes that these two parts of the feature will respectively pass through a global average pooling layer and a fully connected layer to generate two independent outputs, and the three cross-entropies will be added to form the final loss function. In this way, different local features can jointly participate in the network training with the global features, so that the network is able to learn more abundant feature expressions. Feature Mining can also be extended to any layer of the CNN. Specifically, adding Feature Mining in the last two layers of the network not only further improves the performance of the network, but also strengthens the shallow layers’ learning ability. Due to its inherent simplicity, Feature Mining has a plug-and-play nature. Besides, we do not need to set any hyperparameters for Feature Mining, which can reduce the operating cost and maintain the stability of our method for performance improvement.
We demonstrate the effectiveness of our simple, yet effective training method with different network structures, such as ResNet [
4], DenseNet [
21], Wide ResNet [
22], and PyramidNet [
23], for image classification tasks on various datasets including CIFAR100 [
24], TinyImageNet, and ImageNet [
2]. A great accuracy boost was obtained by Feature Mining, higher than the Dropout [
15,
16,
17] and self-distillation methods [
18,
19]. In addition, our training method has strong compatibility and can be superimposed on the mainstream data augmentation [
12] and self-distillation methods. Besides, we verified the wide applicability of Feature Mining in fine-grained classification [
25], object detection [
26], and practical scenarios [
27,
28].
In summary, we made the following principle contributions in this paper:
We propose a novel training strategy, Feature Mining, which aims to make the network learn the local features more efficiently. Our method enjoys a plug-and-play nature and is parameter-free;
The proposed training approach can obviously improve the network’s performance with little extra training cost and can be superimposed on the mainstream training methods;
Experiments for four kinds of CNN architectures on three kinds of datasets were conducted to prove the generalization of this technique. The performance in different scenarios demonstrated the wide applicability of our method.
2. Related Works
Methods for reducing information loss in CNNs: The pooling layer decreases the size of the activation maps to reduce the computational requirements of the CNN, which would inevitably incur information loss. Many strategies try to alleviate this problem by reforming the structure of the pooling layer. Random shifting [
29] embeds random shifting in the downsampling layers during the training process to generate more robust features in the network. S3Pool [
30] replaces the regular downsampling by a more general stochastic version and can be seen as performing implicit data augmentation by introducing distortions in the feature maps. Inspired by the human visual system, detail-preserving pooling [
31] magnifies spatial changes and preserves important structural detail to make the CNN focus on local spatial changes. Based on softmax normalization, SoftPool [
32] preserves the descriptive activation features, while remaining computationally and memory efficient. Note that although our approach also attempts to reduce information loss and strengthen local feature learning as the above methods, we did not change the structure of the pooling layer, but reused the segmented features for efficient learning.
Dropout methods: The Dropout methods aim to improve the generalization of neural networks. Dropout [
15] injects noise into the feature space by randomly zeroing the activation function to avoid overfitting. SpatialDropout [
16] randomly discards all the channels rather than individual activations to improve the generalization of the CNN. DropBlock [
17] randomly drops some contiguous regions of a feature map for better network performance. Besides, References [
33,
34,
35,
36] also proposed variants of Dropout. These Dropout methods enhance local feature learning by discarding other parts of the feature, but Feature Mining divides the feature into different parts and reuses all of them.
Data augmentation methods: Data augmentation is an effective strategy for network training. Random cropping and horizontal flipping [
1] are the most commonly used data augmentation techniques. By randomly removing contiguous sections of the input images, Cutout [
10] improves the robustness of the network. Random erasing [
11] randomly selects a rectangle region in an image and erases its pixels with random values. Input Mixup [
12] creates virtual training examples by linearly interpolating two input data and the corresponding one-hot labels. Inspired by Cutout and Mixup, CutMix [
37] cuts patches and pastes them among the training images. Feature Mining is complementary to the above data augmentation methods such as Mixup because it operates on the feature level without changing the data processing.
Self-distillation methods: Knowledge distillation [
14] is proposed for model compression. Unlike traditional knowledge distillation methods that require teacher and student models, self-distillation distills knowledge itself. Data distortion [
38] transfers knowledge between different augmented versions of the same training data. Be your own teacher [
18] improves the efficiency of network training by squeezing the knowledge in the deeper portion of the networks into the shallow ones. Classwise self-knowledge distillation [
19] improves the generalization of the same kind of images from the perspective of intra-class distillation. Both self-distillation and Feature Mining could improve the utilization of the internal features. Experiments showed that our method outperformed existing self-distillation methods and can be superimposed on self-distillation.
4. Results and Discussion
In this section, we investigate the effectiveness of Feature Mining for multiple computer vision tasks. We first conducted extensive experiments on image classification (
Section 4.1) and fine-grained image classification (
Section 4.2). Next, we studied the effect of Feature Mining on object detection (
Section 4.3). Besides, we evaluated the performance of our method in practical scenarios (
Section 4.4). We also show the ablation study of Feature Mining in
Section 4.5. All experiments were performed with Pytorch [
39] on Tesla M40 GPUs. The highest validation accuracy over the full training course was chosen as the result. If not specified, all results reported were averaged over four runs. Note that all the accuracy results are pixel based.
4.1. Image Classification
4.1.1. CIFAR Classification
The CIFAR100 dataset [
24] consists of 60,000 32 × 32 color images of 100 classes, each with 600 images including 500 training images and 100 test images. For ResNet [
4] and Wide ResNet [
22], the mini-batch size was set to 128, and the models were trained for 300 epochs with an initial learning rate of 0.1 decayed by a factor of 0.1 at Epochs 150 and 225. We changed the batch size to 64 when training with DenseNet [
21]. As mentioned in [
23], we changed the initial learning rate to 0.5 and decreased it by a factor of 0.1 at Epochs 150 and 225 when training PyramidNet [
23].
Comparison with the Dropout methods: We adopt ResNet-56, ResNet-110, ResNet-164, DenseNet-100-12, Wide ResNet-28-10, and PyramidNet-110-270 as the baselines to evaluate Feature Mining’s generalization for different layers and structures of networks. We tested Feature Mining with the last layer and the last two layers. Dropblock [
17] was applied to the output of the first two groups. Dropout [
15] and SpatialDropout [
16] were applied to the output of the penultimate group.
Table 1 shows that Feature Mining outperformed other baselines consistently. In particular, Feature Mining improved the top-1 accuracy of the cross-entropy loss from 74.98% to 78.31% (independent-samples
t test,
p-value = 0.000177 < 0.001) of ResNet-164 under the CIFAR100 dataset.
Our method, only used in the last layer, was better than the performance of the three Dropout methods, and we considered the reason to be that Dropout and its variants strengthen the part of the neurons’ learning by discarding other parts of the neurons, which may cause information loss during the training phase. Feature Mining can make the network simultaneously learn the different regions of the feature without information loss, so that the network can achieve better performance. We can also find that the network performance of Feature Mining used in the last two layers was much better than that only used in the last layer, which indicates that the local feature in the front layer is also beneficial to the network training.
Comparison with self-distillation methods: We also compared our method with self-distillation techniques such as be your own teacher (BYOT) [
18] and classwise knowledge distillation (CS-KD) [
19]. BYOT improved the performance of the network by making the shallow network learn the knowledge of the last layer. Therefore, we took the output of the last layer in ResNet-110 as the teachers of all the front layers and provided the final results after ensembling for a fair comparison. Besides, CS-KD improved the generalization of the same kind of images from the perspective of intra-class distillation. Note that we only chose ResNet-110 as the baseline model due to the limitation of computing resources, but it can be seen from the results in
Table 1 that the improvement of our method in a deeper network (ResNet-110) was more obvious than that in a shallow network (ResNet-164). Therefore, the performance of our method on ResNet-110 was able to prove its advantage because of its generalization.
As shown in
Table 2, Feature Mining showed better top-1 accuracy on ResNet-110 compared with BYOT and CS-KD. Note that BYOT added extra overhead in the training, while the time of our method was negligible. Besides, we combined Feature Mining with these two methods and improved the top-1 accuracy of ResNet-110 from 76.68% to 77.34% (independent-samples
t test,
p-value = 0.046 < 0.05) of BYOT and from 75.92% to 77.68% (independent-samples
t test,
p-value = 0.000322 < 0.001) of CS-KD. This shows that Feature Mining does not conflict with these methods; even in the case of improving the performance of the front layer (BYOT) or reducing the gap within the class (CS-KD), the performance can still be improved by strengthening the learning of the local features.
Comparison with the data augmentation method: We investigated orthogonal usage with other types of regularization methods such as Mixup [
12]. Mixup utilizes convex combinations of input pairs and corresponding label pairs for training. We combined our method with Mixup regularization by combining the input and label processed by Mixup with ResNet-110, which uses Feature Mining on the last two layers.
Table 3 shows the effectiveness of our method combined with Mixup regularization. Interestingly, this simple idea significantly improved the performance of the classification task. In particular, our method improved the top-1 accuracy of Mixup regularization from 79.22% to 81.04% (independent-samples
t test,
p-value = 0.001 < 0.01) on ResNet-164, which proves our method is also compatible with the data augmentation method.
4.1.2. Tiny ImageNet Classification
The Tiny ImageNet dataset is a subset of the ImageNet [
2] dataset with 200 classes. Each class has 500 training images, 50 validation images, and 50 test images. All images have a 64 × 64 resolution. The test set label is not publicly available, so we used the validation set as a test set for all the experiments on Tiny ImageNet following the common practice. The results are summarized in
Table 4. Feature Mining achieved the best performance 65.22% on Tiny ImageNet compared with the Dropout methods, BYOT and CS-KD, +2.80% (independent-samples
t test,
p-value = 0.000062 < 0.001) higher than the baseline. This proves that our method is also generalized for datasets with different data sizes. These results also show that Feature Mining has wide applicability and performs better than other regularization or self-distillation methods on different datasets.
4.1.3. ImageNet Classification
ImageNet-1K [
2] contains 1.2M training images and 50K validation images labeled with 1K categories. To verify the scalability of our method, we evaluated our method on the ImageNet dataset with ResNet-50, which is the commonly used model for ImageNet with high performance and acceptable computing overhead. The model was trained from scratch for 300 epochs with a batch size of 256, and the learning rate was decayed by a factor of 0.1 at Epochs 75, 150, and 225. As reported in
Table 5, our method improved by 0.94% (independent-samples
t test,
p-value = 0.001 < 0.01) the top-1 accuracy compared with the baseline. This shows that our training strategy is also effective for image recognition in large-scale datasets.
4.2. Fine-Grained Image Classification
Fine-grained image classification aims to recognize similar subcategories of objects under the same basic level category. The difference of fine-grained recognition compared with general category recognition is that fine-grained subcategories often share the same parts and usually can only be distinguished by the subtle differences in the texture and color properties of these parts. CUB-200-2011 [
25] is a widely used fine-grained dataset that consists of images of 200 bird species. There are about 30 images for training for each class. We used ResNet-50 to test the performance of our method on CUB-200-2011 to verify the generalization of different types of computer vision tasks. For a fair comparison, the model was trained from scratch for 300 epochs with a batch size of 32, and the learning rate was decayed by a factor of 0.1 at Epochs 150 and 225.
As shown in
Table 6, we improved the accuracy of ResNet-50 from 66.73% to 76.26% (independent-samples
t test,
p-value =
< 0.001), +9.53% with Feature Mining, which significantly surpassed previous self-distillation methods. It also shows that fully utilizing feature information has a high gain effect even on fine-grained image classification, which requires more subtle differences.
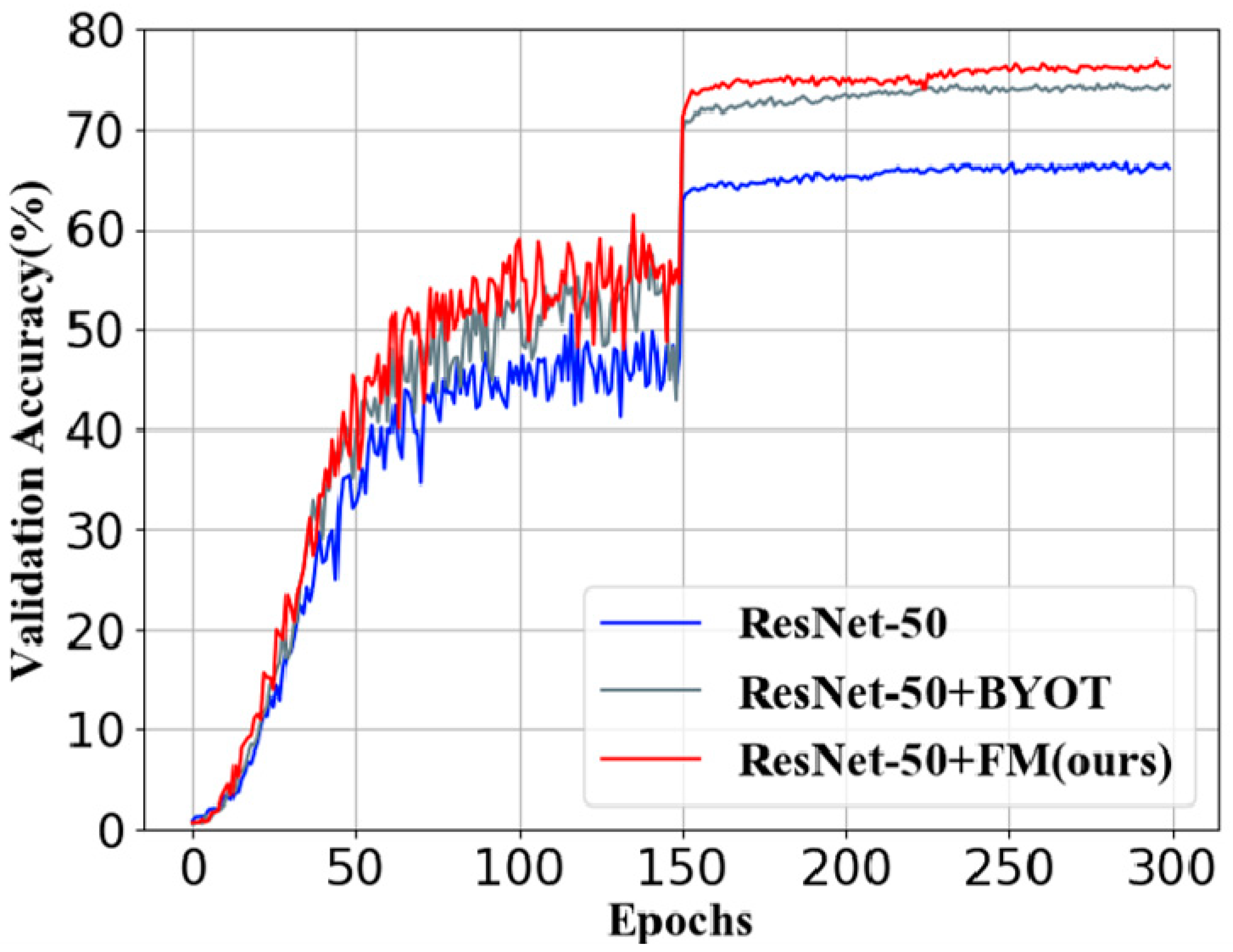
Figure 3 shows the validation accuracy comparison among the baseline, BYOT, and Feature Mining on CUB-200-2011 with ResNet-50. The accuracy of BYOT and our method was much higher than the baseline, and the accuracy of Feature Mining was higher than that of BYOT.
4.3. Object Detection
In this subsection, we show that Feature Mining can also be applied for training the object detector on the Pascal VOC dataset [
26]. The RetinaNet [
40] framework was chosen as the baseline model, which is composed of a backbone network and two task-specific subnetworks. The ResNet-50 backbone was initialized with the ImageNet-pretrained model and then fine-tuned on Pascal VOC 2007 and 2012 trainval data. The models were evaluated on the VOC 2007 test data using the mAP metric. We followed the fine-tuning strategy of the original method.
As shown in
Table 7, the ResNet-50 pre-trained with Feature Mining achieved a better accuracy (71.11%), +0.97% (independent-samples
t test,
p-value = 0.013 < 0.05) higher than the baseline performance. The result suggests that the model trained with Feature Mining is also an effective training approach for object detection.
4.4. Practical Scenarios
A. Label noise problem: In practical scenarios, the dataset is full of error labels because of the expensive and time-consuming labeling process, which could seriously affect the performance of the model. This phenomenon is known as the label noise problem. We set up experiments with noisy datasets to see how well Feature Mining performed for different types and amounts of label noise.
Following [
27,
41], we corrupted these datasets manually on CIFAR-100. Two types of noisy labels were considered: (1) symmetry flipping: each label was set to an incorrect value uniformly with a certain probability; (2) pair flipping: labelers may only make mistakes within very similar classes. We use
to denote the noise rate.
Table 8 compares the results with and without Feature Mining using ResNet-110. Our method made huge improvements on different types and amounts of noise compared with the baseline (which only uses cross-entropy to classify). One possible implication of the improvement is that our method can make the convolutional layers’ training more sufficient, and the robust network has stronger anti-noise ability. Together, these results provide strong proofs that Feature Mining helps raise the internal noise tolerance of the network.
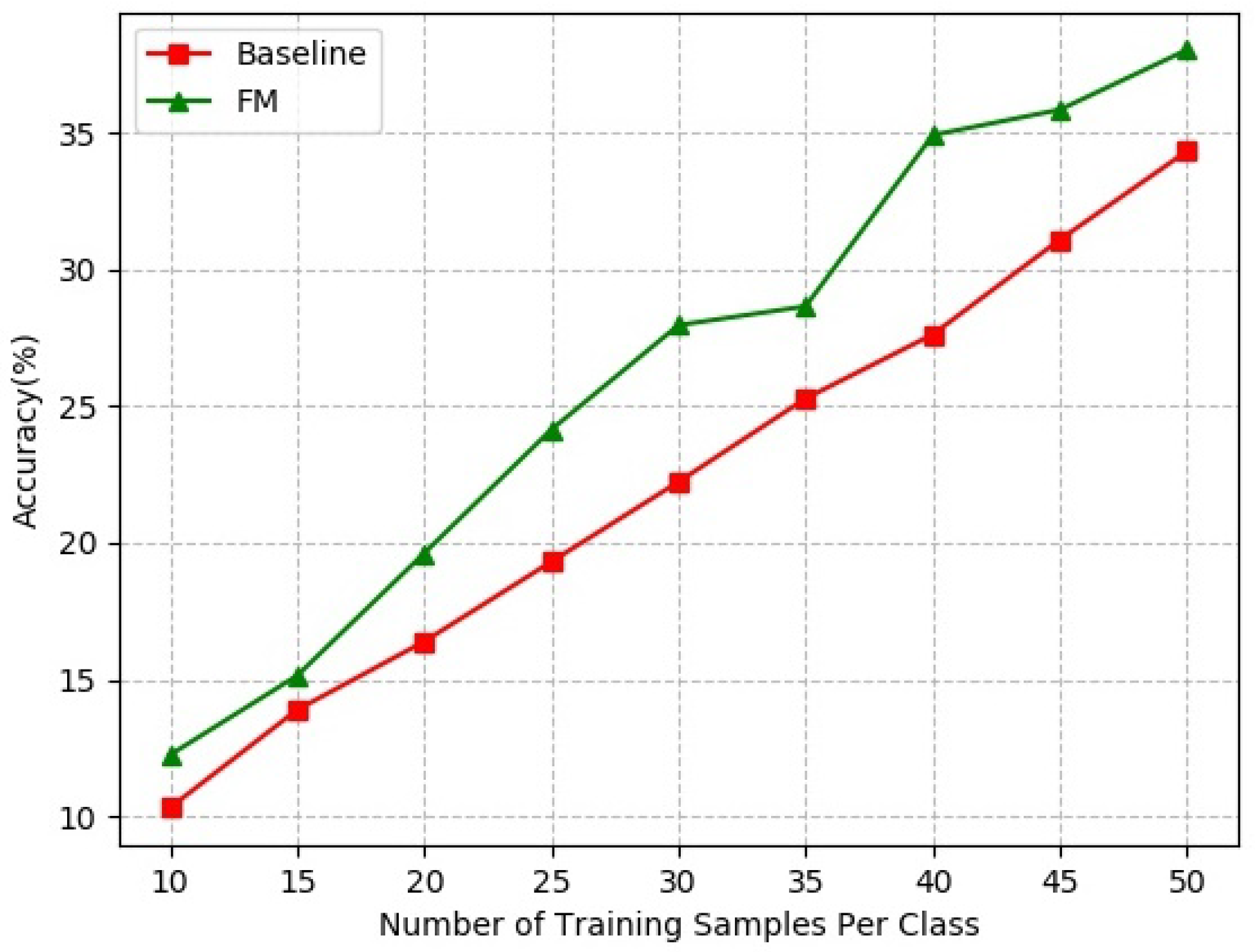
B. Small sample size problem: In some real industrial scenarios, the size of the dataset may be small, which would bring difficulty to the network training. Besides, Reference [
42] mentioned that reducing the size of the training dataset can measure the generalization performance of the models. Therefore, we evaluated the effectiveness of Feature Mining on the small sample size problem along with varying the size of the training data. Due to the limitation of the computing resources, we chose ResNet-56 as the baseline model.
We constructed a series of sub-datasets of CIFAR-100 via randomly choosing samples for each class.
Figure 4 compares the results obtained from ResNet-56 trained with and without our strategy. Feature Mining was used on the last two layers of the network. From the graph, we can see that our method yielded much higher accuracies compared to the vanilla setting on all of the sub-datasets, in accordance with the expectations. The performance of Feature Mining proves that our method can effectively improve the generalization of CNNs.
4.5. Ablation Study
A. Influence of different choices of Feature Mining on network performance: We explored different design choices for Feature Mining, and these choices were classified into two groups.
As shown in
Table 9, the first group discusses the number of layers using Feature Mining. ResNet-56 contains three layers, and we tested the Feature Mining on the last layers, the last two layers, and all three layers. All three models outperformed the baseline model from 74.55% to 75.35%, while the model with the last two layers using Feature Mining performed better than others. This shows that the penultimate layer’s local feature is beneficial to the network training. While the feature of the first layer does not contain mature semantics, adding learning of the feature in the first layer is not beneficial for the network training.
The second group focuses on the Feature Segmentation approach. The Feature Segmentation determines the additional feature pattern of the network learning, which plays a crucial role in the performance of our method. Dropout-FM denotes that the binary mask is set by random points as the Dropout. SpatialDropout-FM denotes that the feature is divided by channels as the SpatialDropout. The performance of these segmentation approaches could not compete with Feature Mining, which proves the segmentation feature based on the block region can ensure a larger difference between the two parts and make the network learn more feature information. Non-complementary FM denotes that we randomly chose two parts of the feature instead of the complementary ones; its performance was still not as good as the complementary way, which again verifies that the difference between the two parts of the feature is important.
B. Analysis of time and memory overhead:Table 10 provides some complexity statistics of Feature Mining, which shows that the computation cost introduced by Feature Mining is negligible, especially when our method is only used in the last layer. Besides, this additional cost is introduced only in the training phase, and the inference cost is not increased.
5. Conclusions
In this paper, we proposed a novel training strategy named Feature Mining that aims to strengthen a CNN’s learning of the local features. Feature Mining divides the complete feature into two complementary parts and reuses the divided feature to make the network capture different local information for efficient training. Our method has a plug-and-play nature and can be applied to any CNN model. Extensive experiments proved that Feature Mining brought stable improvement to different classification datasets on various models and could be applied to various tasks, including fine-grained image classification, object detection, label noise, and the small data regime. On CIFAR-100 classification, applying Feature Mining to ResNet-164 brought +3.33% top-1 accuracy improvement. On CUB-200-2011, fine-grained image classification, applying Feature Mining to ResNet-50, significantly improved the performance of the baseline by +9.53%. Besides, Feature Mining is complementary to data augmentation and self-distillation methods. For future work, we plan to find better segmentation strategies for Feature Mining by using reinforcement learning.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}