
FedQAS: Privacy-Aware Machine Reading Comprehension with Federated Learning


Abstract
:1. Introduction
2. Related Work
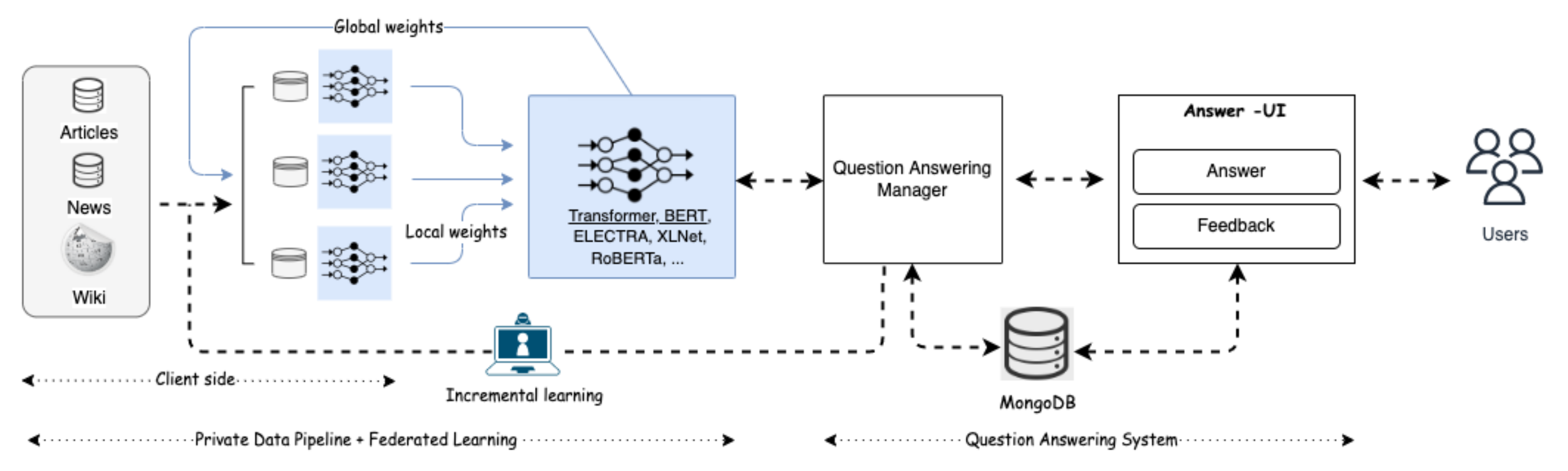
3. Proposed Approach
3.1. Data Processing (Client Side)
3.2. Private Data Pipeline Module
3.3. Federated Machine Learning Module
| Algorithm 1: Incremental FedAVG algorithm. k: Number of clients, r: Number of rounds, : Local model weights and M: Global model weights. |
| Input: |
| Output: |
 |
| Algorithm 2: Local client update, k: Number of clients, : Client k local dataset, e: Number of local epochs, and is the learning rate. |
Output: |
 |
3.4. Transformer Model
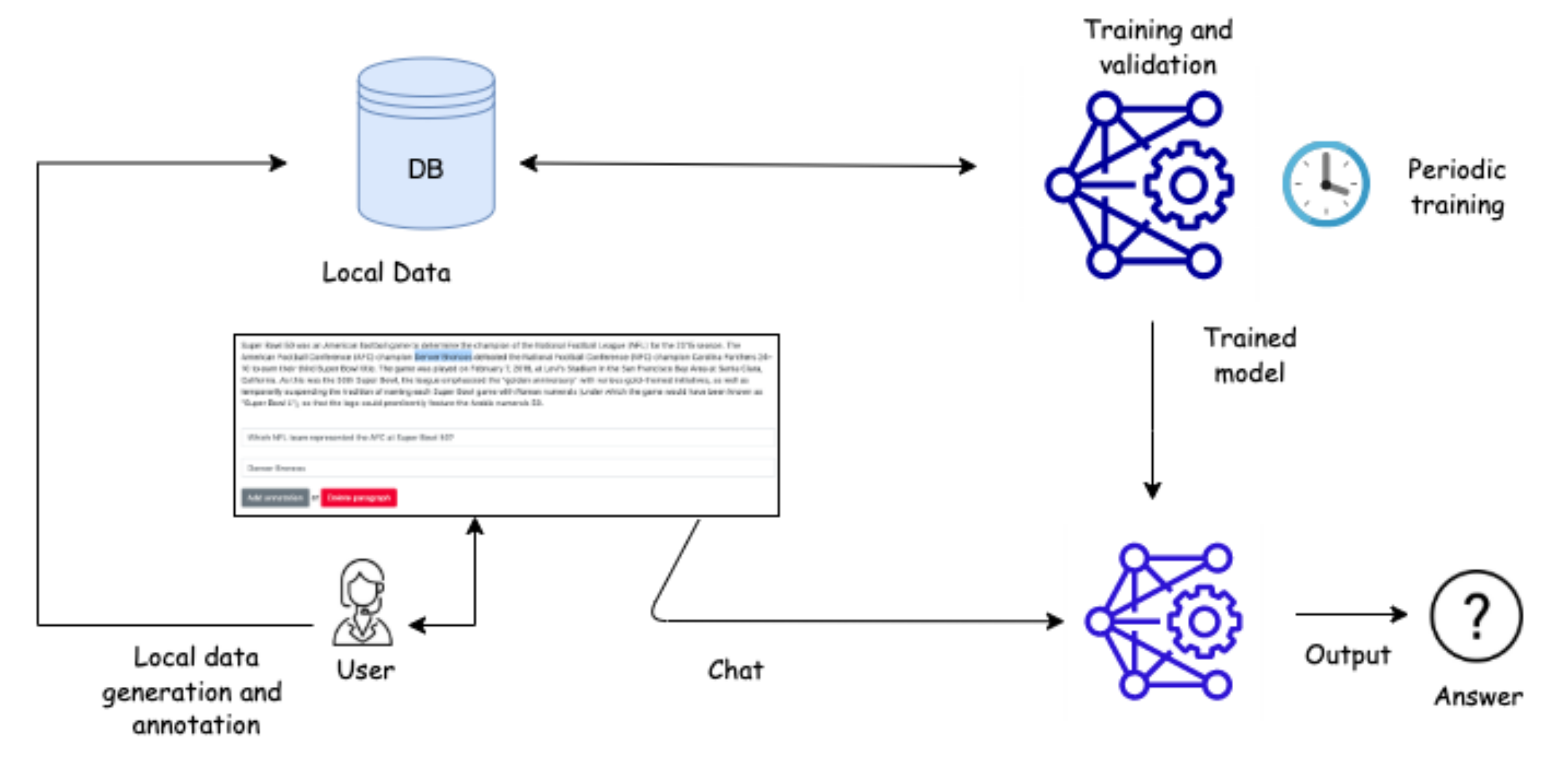
3.5. Incremental Learning Module
4. Experiment and Results
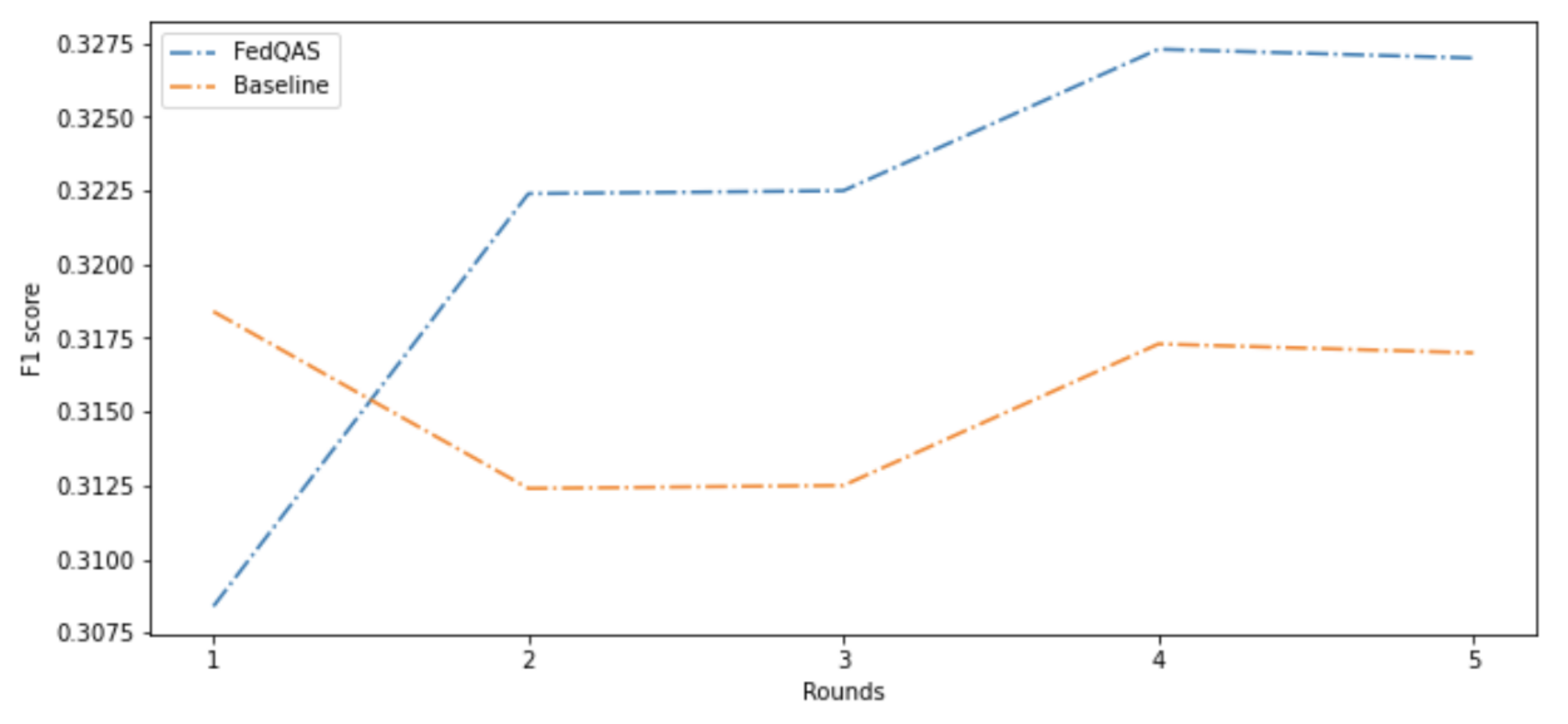
4.1. Framework Evaluation
4.2. Implementation and Demo Environment
- Privacy-preserving: sharing only model parameters with a central server (cloud) and keeping data private on the client side,
- Incremental learning: improving the global models by attaching more clients and adding new data points,
- Robust: robust enough to deal with natural language tasks (e.g., question answering, chatbot, etc.) and large models in a geographically distributed manner,
- Multilingual: language agnostic, can be trained on any language,
- Standalone: multiple platforms (i.e., guarantee for low disk and memory footprint). It can be run production-grade on a standard laptop having two cores and 2GB of RAM,
- Accuracy and F1 score: achieve competitive performance compared with centralized training and the used baseline model (see experiment and evaluation section).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Ekmefjord, M.; Ait-Mlouk, A.; Alawadi, S.; Åkesson, M.; Stoyanova, D.; Spjuth, O.; Toor, S.; Hellander, A. Scalable federated machine learning with FEDn. arXiv 2021, arXiv:2103.00148. [Google Scholar]
- Lehnert, W. The Process of Question Answering. Ph.D. Thesis, Yale University, New Haven, CT, USA, 1977. [Google Scholar]
- Hirschman, L.; Light, M.; Breck, E.; Burger, J.D. Deep Read: A Reading Comprehension System. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics, ACL ’99, College Park, MD, USA, 20–26 June 1999; Association for Computational Linguistics: Stroudsburg, PA, USA, 1999; pp. 325–332. [Google Scholar] [CrossRef] [Green Version]
- Riloff, E.; Thelen, M. A Rule-Based Question Answering System for Reading Comprehension Tests. In Proceedings of the 2000 ANLP/NAACL Workshop on Reading Comprehension Tests as Evaluation for Computer-Based Language Understanding Sytems—Volume 6, ANLP/NAACL-ReadingComp ’00, Seattle, WA, USA, 4 May 2000; Association for Computational Linguistics: Stroudsburg, PA, USA, 2000; pp. 13–19. [Google Scholar] [CrossRef] [Green Version]
- Charniak, E.; Altun, Y.; de Salvo Braz, R.; Garrett, B.; Kosmala, M.; Moscovich, T.; Pang, L.; Pyo, C.; Sun, Y.; Wy, W.; et al. Reading Comprehension Programs in a Statistical-Language-Processing Class. In Proceedings of the ANLP-NAACL 2000 Workshop: Reading Comprehension Tests as Evaluation for Computer-Based Language Understanding Systems, Seattle, WA, USA, 4 May 2000; Association for Computational Linguistics: Stroudsburg, PA, USA, 2000. [Google Scholar]
- Wang, Z.; Hamza, W.; Florian, R. Bilateral Multi-Perspective Matching for Natural Language Sentences. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, Melbourne, Australia, 19–25 August 2017; pp. 4144–4150. [Google Scholar] [CrossRef] [Green Version]
- Richardson, M.; Burges, C.J.; Renshaw, E. MCTest: A Challenge Dataset for the Open-Domain Machine Comprehension of Text. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 193–203. [Google Scholar]
- Wang, W.; Yan, M.; Wu, C. Multi-Granularity Hierarchical Attention Fusion Networks for Reading Comprehension and Question Answering. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 1: Long Papers, pp. 1705–1714. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Wu, Y.; Zhao, H.; Li, Z.; Zhang, S.; Zhou, X.; Zhou, X. Semantics-aware BERT for Language Understanding. arXiv 2020, arXiv:1909.02209. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, Y.; Zhou, J.; Duan, S.; Zhao, H.; Wang, R. SG-Net: Syntax-Guided Machine Reading Comprehension. arXiv 2019, arXiv:1908.05147. [Google Scholar] [CrossRef]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional Attention Flow for Machine Comprehension. arXiv 2018, arXiv:1611.01603. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar] [CrossRef]
- Zhuang, L.; Wayne, L.; Ya, S.; Jun, Z. A Robustly Optimized BERT Pre-training Approach with Post-training. In Proceedings of the 20th Chinese National Conference on Computational Linguistics, Hohhot, China, 13–15 August 2021; Chinese Information Processing Society of China: Beijing, China, 2021; pp. 1218–1227. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2020, arXiv:1906.08237. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 1 (Long Papers), pp. 2227–2237. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Yamada, I.; Asai, A.; Shindo, H.; Takeda, H.; Matsumoto, Y. LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention. arXiv 2020, arXiv:2010.01057. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2020, arXiv:1909.11942. [Google Scholar]
- Zhang, Z.; Yang, J.; Zhao, H. Retrospective Reader for Machine Reading Comprehension. arXiv 2020, arXiv:2001.09694. [Google Scholar]
- Hermann, K.M.; Kočiský, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching Machines to Read and Comprehend. arXiv 2015, arXiv:1506.03340. [Google Scholar]
- Hill, F.; Bordes, A.; Chopra, S.; Weston, J. The Goldilocks Principle: Reading Children’s Books with Explicit Memory Representations. arXiv 2016, arXiv:1511.02301. [Google Scholar]
- Bajaj, P.; Campos, D.; Craswell, N.; Deng, L.; Gao, J.; Liu, X.; Majumder, R.; McNamara, A.; Mitra, B.; Nguyen, T.; et al. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. arXiv 2018, arXiv:1611.09268. [Google Scholar]
- Trischler, A.; Wang, T.; Yuan, X.; Harris, J.; Sordoni, A.; Bachman, P.; Suleman, K. NewsQA: A Machine Comprehension Dataset. In Proceedings of the 2nd Workshop on Representation Learning for NLP, Vancouver, BC, Canada, 3 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 191–200. [Google Scholar] [CrossRef]
- Dunn, M.; Sagun, L.; Higgins, M.; Guney, V.U.; Cirik, V.; Cho, K. SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine. arXiv 2017, arXiv:1704.05179. [Google Scholar]
- Joshi, M.; Choi, E.; Weld, D.S.; Zettlemoyer, L. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv 2017, arXiv:1705.03551. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 2383–2392. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. arXiv 2018, arXiv:1806.03822. [Google Scholar]
- Reddy, S.; Chen, D.; Manning, C.D. CoQA: A Conversational Question Answering Challenge. Trans. Assoc. Comput. Linguist. 2019, 7, 249–266. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 2: Short Papers, pp. 784–789. [Google Scholar] [CrossRef] [Green Version]
- Sweeney, L. K-Anonymity: A Model for Protecting Privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-Diversity: Privacy beyond k-Anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 1–52. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 106–115. [Google Scholar] [CrossRef] [Green Version]
- Rocher L., H. J.; de Montjoye YA. Estimating the success of re-identifications in incomplete datasets using generative models. Nat. Commun. 2019, 10, 3069. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2017, arXiv:1602.05629. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Toor, S.; Lindberg, M.; Falman, I.; Vallin, A.; Mohill, O.; Freyhult, P.; Nilsson, L.; Agback, M.; Viklund, L.; Zazzik, H.; et al. SNIC Science Cloud (SSC): A National-Scale Cloud Infrastructure for Swedish Academia. In Proceedings of the 2017 IEEE 13th International Conference on e-Science (e-Science), Auckland, New Zealand, 24–27 October 2017; pp. 219–227. [Google Scholar] [CrossRef]
- Pokorny, J. NoSQL Databases: A Step to Database Scalability in Web Environment; iiWAS ’11; Association for Computing Machinery: New York, NY, USA, 2011; pp. 278–283. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Answer Type | Domain-Specific |
|---|---|---|
| MCTest [8] | Multiple choice | Children’s stories |
| CNN/Daily Mail [21] | Spans | News |
| Children’s book [22] | Spans | Children’s stories |
| MS MARCO [23] | Free-form text | Web Search |
| NewsQA [24] | Spans | News |
| SearchQA [25] | Spans | Jeopardy |
| TriviaQA [26] | Spans | Trivia |
| SQuAD [27] | Spans | Wikipedia |
| SQuAD 2.0 [28] | Spans, Unanswerable | Wikipedia |
| CoQA [29] | Free-form text, | News, Reddit |
| Wikipedia |
| Rounds | Total Number of Clients | Update Size | Total Number of Parameters |
|---|---|---|---|
| 5 | 5 | 400 MB | 109,483,776 |
| Hyper-Parameter | Range | Value |
|---|---|---|
| Epochs | [1–3] | 1 |
| Batch size | [8–128] | 8 |
| Learning rate | [0.001–0.004] | |
| Optim. method | Adam, SGD, RMSProp | Adam |
| [1–1000] | 384 |
| Model | F1 Score | Accuracy (EM) |
|---|---|---|
| Baseline | 0.31 | 0.75 |
| FedQAS | 0.33 | 0.81 |
| Title: Project Apollo |
|---|
| Passage: The Apollo program, also known as Project Apollo, was the third United States human spaceflight program carried out by the National Aeronautics and Space Administration (NASA), which accomplished landing the first humans on the Moon from 1969 to 1972. First conceived during Dwight D. Eisenhower’s administration as a three-man spacecraft to follow the one-man Project Mercury which put the first Americans in space, Apollo was later dedicated to President John F. Kennedy’s national goal of landing a man on the Moon and returning him safely to the Earth by the end of the 1960s, which he proposed in a 25 May 1961, address to Congress. Project Mercury was followed by the two-man Project Gemini. The first manned flight of Apollo was in 1968. Apollo ran from 1961 to 1972, and was supported by the two man Gemini program which ran concurrently with it from 1962 to 1966… |
| Question 1: How long did Project Apollo run? |
| Gold answer (human): 1961 to 1972 |
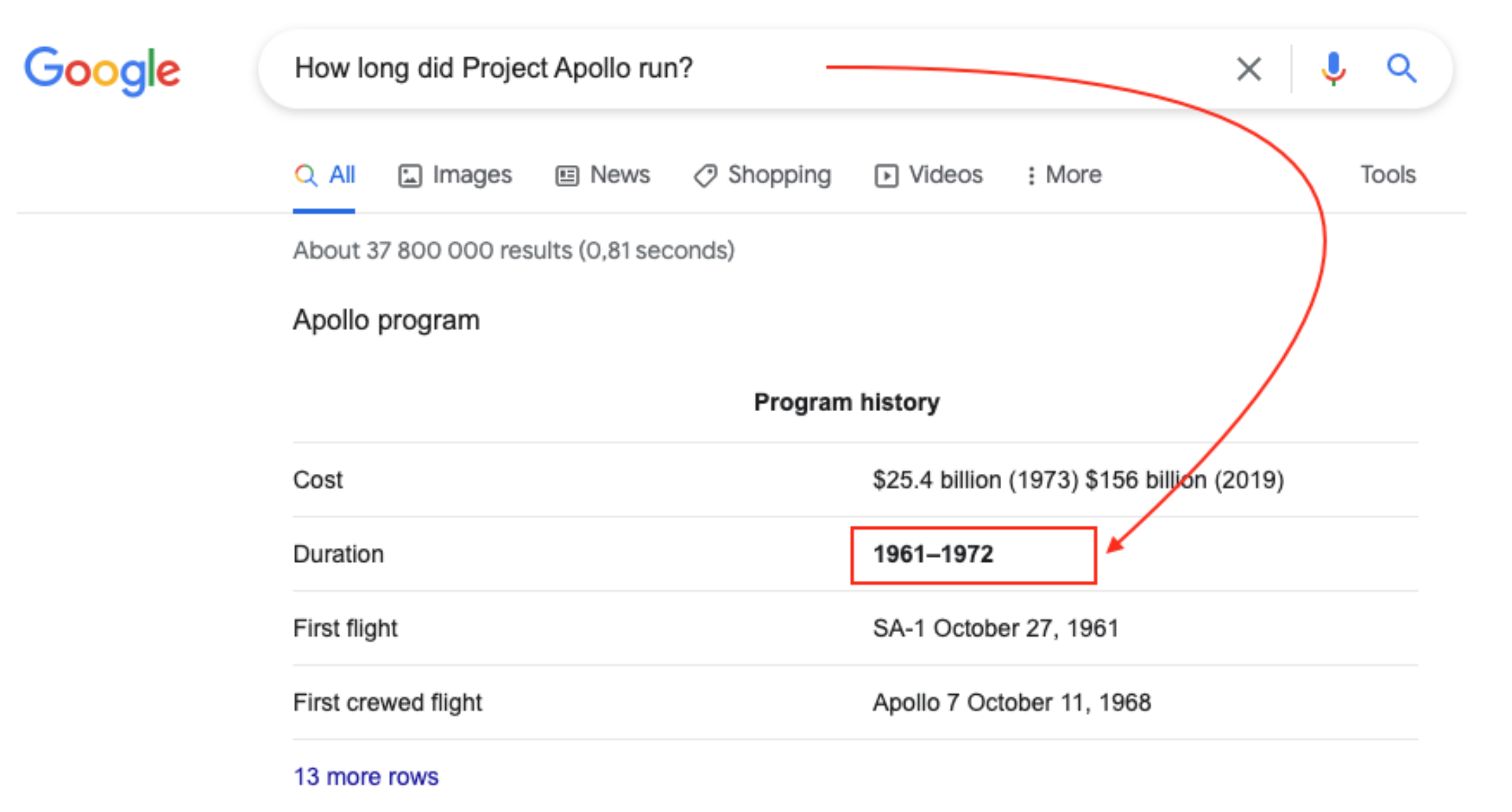
| Google search engine answer: see Figure 1 |
| Baseline model answer: 1961 to 1972 |
| FedQAS answer: 1961 to 1972 |
| Question 2: What program was created to carry out these projects and missions? |
| Gold answer (human): Apollo program |
| Baseline model answer: National Aeronautics and Space Administration |
| FedQAS answer: Apollo program |
| Question 3: What year did the first manned Apollo flight occur? |
| Gold answer (human): 1968 |
| Baseline model answer: 1968 |
| FedQAS answer: 1968 |
| Question 4: What President is credited with the original notion of putting Americans in space? |
| Gold answer (human): John F. Kennedy |
| Baseline model answer: John F. Kennedy |
| FedQAS answer: John F. Kennedy |
| Question 5: Who did the U.S. collaborate with on an Earth orbit mission in 1975? |
| Gold answer (human): Soviet Union |
| Baseline model answer: Soviet Union |
| FedQAS answer: Soviet Union |
| Question 6: How long did Project Apollo run? |
| Gold answer (human): 1962 to 1966 |
| Baseline model answer: 1961 to 1972, and was supported by the two man Gemini program which ran 1966 |
| FedQAS answer: 1962 to 1966 |
| Question 7: What program helped develop space travel techniques that Project Apollo used? |
| Gold answer (human): Gemini |
| Baseline model answer: Gemini |
| FedQAS answer: Gemini |
| Question 8: What space station supported three manned missions in 1973–1974? |
| Gold answer (human): Skylab |
| Baseline model answer: Skylab |
| FedQAS answer: Skylab |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ait-Mlouk, A.; Alawadi, S.A.; Toor, S.; Hellander, A. FedQAS: Privacy-Aware Machine Reading Comprehension with Federated Learning. Appl. Sci. 2022, 12, 3130. https://doi.org/10.3390/app12063130
Ait-Mlouk A, Alawadi SA, Toor S, Hellander A. FedQAS: Privacy-Aware Machine Reading Comprehension with Federated Learning. Applied Sciences. 2022; 12(6):3130. https://doi.org/10.3390/app12063130
Chicago/Turabian StyleAit-Mlouk, Addi, Sadi A. Alawadi, Salman Toor, and Andreas Hellander. 2022. "FedQAS: Privacy-Aware Machine Reading Comprehension with Federated Learning" Applied Sciences 12, no. 6: 3130. https://doi.org/10.3390/app12063130