
A Robust Localization System Fusion Vision-CNN Relocalization and Progressive Scan Matching for Indoor Mobile Robots

Abstract
:1. Introduction
- (1)
- Based on posenetLSTM, the laser measurement and the prior map information are used as geometric constraint relationships and they are added to the loss function of the neural network to improve the accuracy of visual relocation;
- (2)
- The use of particle filtering to sample the rotation and the translation of particles separately on the pre-calculated, multi-resolution grid map; and the use of the branch and bound method to accelerate the high-precision relocation of the robot;
- (3)
- The pose tracking stage is based on the original high-resolution map, using an extended Kalman filter (EKF) to fuse the IMU, the wheel odometer information for initial pose estimation, and correlated particle sampling to obtain the particle with the highest score. The system also introduces a nonlinear optimization method to optimize the pose, which further improves the tracking accuracy and real-time performance of the system;
- (4)
- Simulations and physical experiments were carried out in Gazebo and real environments, respectively, which verified that the system could: realize relocation quickly and accurately and track trajectory in real time with high accuracy.
2. Related Works
2.1. Laser-Based Localization Method
2.2. Vision-Based Localization Method
2.3. Localization Method Combining Vision and Laser
3. System Overview and Methodology
3.1. System Overview
3.2. Design of Convolutional Neural Network
3.3. Map Preprocessing
3.4. Correlation Particle Sampling Method
3.5. Scan Matching Optimization
4. Simulation
4.1. Simulation Settings
4.2. Initialization of the Robot Global Positioning
4.2.1. Visual Localization Accuracy Analysis
4.2.2. System Relocalization Analysis
4.3. Dynamic Pose Tracking of Robot
5. Experiments
5.1. Experimental Platform and Measuring Equipment
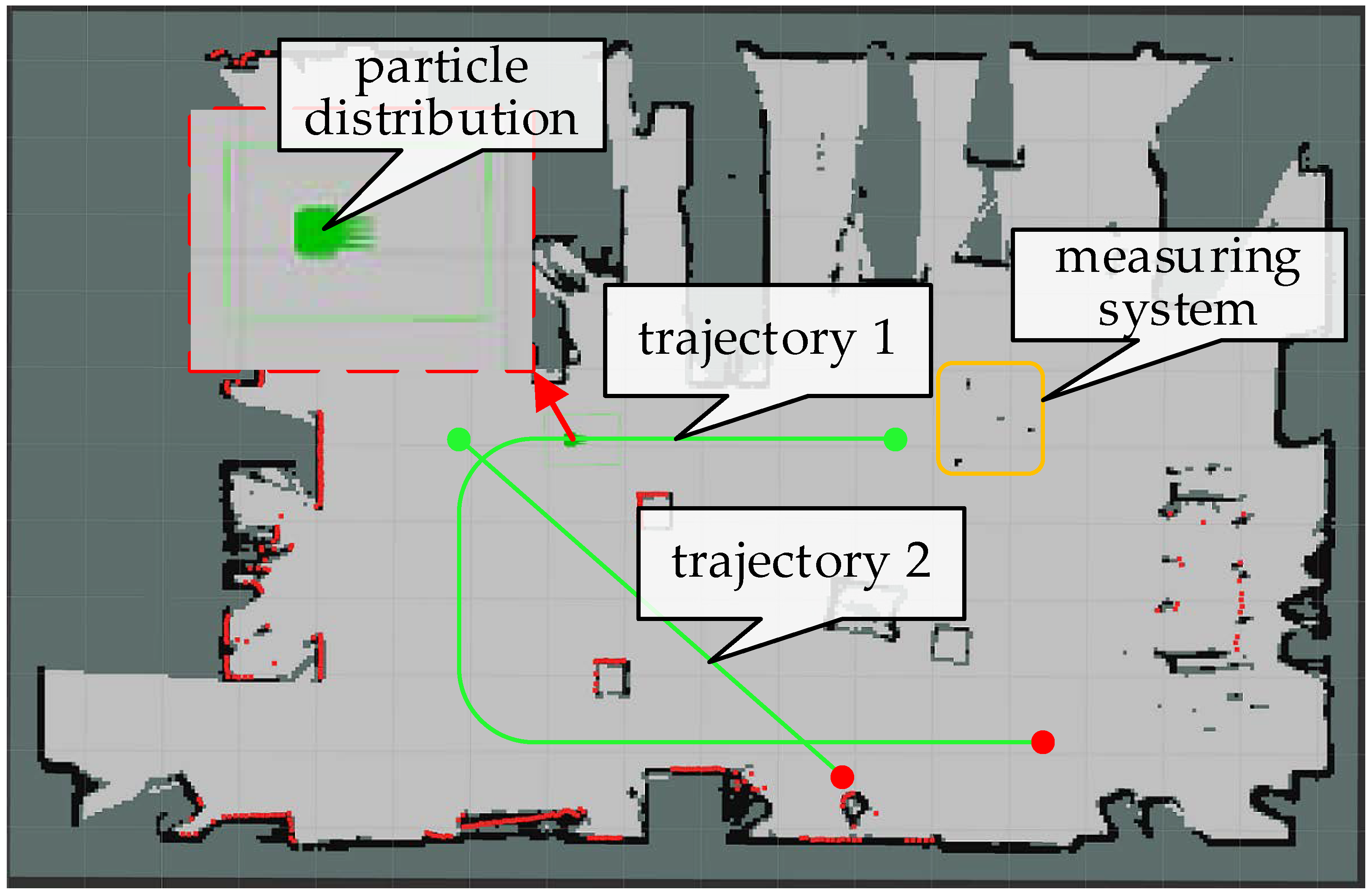
5.2. Relocalization Experiment
5.2.1. Test of Visual Relocalization Accuracy
5.2.2. Test of Relocalization Integrating Visual and Laser Information
5.3. Dynamic Pose Tracking
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, M.; Wang, H.; Yang, Y.; Zhang, Y.; Ma, L.; Wang, N. RFID 3-D Indoor Localization for Tag and Tag-Free Target Based on Interference. IEEE Trans. Instrum. Meas. 2019, 68, 3718–3732. [Google Scholar] [CrossRef]
- Zhang, Y.; Tan, X.; Zhao, C. UWB/INS Integrated Pedestrian Positioning for Robust Indoor Environments. IEEE Sens. J. 2020, 20, 14401–14409. [Google Scholar] [CrossRef]
- Zhou, M.; Lin, Y.; Zhao, N.; Jiang, Q.; Yang, X.; Tian, Z. Indoor WLAN Intelligent Target Intrusion Sensing Using Ray-Aided Generative Adversarial Network. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 61–73. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Laser-visual-inertial odometry and mapping with high robustness and low drift. J. F. Robot. 2018, 35, 1242–1264. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Chen, S.; Yuan, C.; Zhang, J.; Zhang, J. Robust High Accuracy Visual-Inertial-Laser SLAM System. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 6636–6641. [Google Scholar] [CrossRef]
- Debeunne, C.; Vivet, D. A review of visual-lidar fusion based simultaneous localization and mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef] [Green Version]
- Thrun, S.; Fox, D.; Burgard, W.; Dellaert, F. Robust Monte Carlo localization for mobile robots. Artif. Intell. 2001, 128, 99–141. [Google Scholar] [CrossRef] [Green Version]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; Communications of the ACM: New York, NY, USA, 2005; Volume 1. [Google Scholar]
- Wang, Y.; Zhang, W.; Li, F.; Shi, Y.; Chen, Z.; Nie, F.; Zhu, C.; Huang, Q. An improved Adaptive Monte Carlo Localization Algorithm Fused with Ultra Wideband Sensor. In Proceedings of the 2019 IEEE International Conference on Advanced Robotics and Its Social Impacts (ARSO), Beijing Institute of Technology (BIT), Beijing, China, 31 October–2 November 2019. [Google Scholar]
- Yuan, R.; Zhang, F.; Fu, Y.; Wang, S. A robust iterative pose tracking method assisted by modified visual odometer. Sens. Rev. 2021, 41, 1–15. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, W.; Li, F.; Huang, Q. Robust localization system fusing vision and lidar under severe occlusion. IEEE Access 2020, 8, 62495–62504. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2938–2946. [Google Scholar] [CrossRef] [Green Version]
- Walch, F.; Hazirbas, C.; Leal-Taixe, L.; Sattler, T.; Hilsenbeck, S.; Cremers, D. Image-Based Localization Using LSTMs for Structured Feature Correlation. In Proceedings of the IEEE ICCV, Venice, Italy, 22–29 October 2017; pp. 627–637. [Google Scholar] [CrossRef] [Green Version]
- Hanten, R.; Buck, S.; Otte, S.; Zell, A. Vector-AMCL: Vector based adaptive monte carlo localization for indoor maps. Adv. Intell. Syst. Comput. 2017, 531, 403–416. [Google Scholar] [CrossRef]
- Li, T.; Sun, S.; Sattar, T.P. Adapting sample size in particle filters through KLD-resampling. Electron. Lett. 2013, 49, 740–742. [Google Scholar] [CrossRef] [Green Version]
- Olson, E.B. Real-time correlative scan matching. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 4387–4393. [Google Scholar] [CrossRef] [Green Version]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–20 May 2016; pp. 1271–1278. [Google Scholar] [CrossRef]
- Yuan, R.; Zhang, F.; Qu, J.; Li, G.; Fu, Y. An enhanced pose tracking method using progressive scan matching. Ind. Rob. 2019, 46, 235–246. [Google Scholar] [CrossRef]
- Peng, G.; Zheng, W.; Lu, Z.; Liao, J.; Hu, L.; Zhang, G.; He, D. An improved AMCL algorithm based on laser scanning match in a complex and unstructured environment. Complexity 2018, 2018, 1–11. [Google Scholar] [CrossRef]
- Tipaldi, G.D.; Spinello, L.; Burgard, W. Geometrical FLIRT phrases for large scale place recognition in 2D range data. In Proceedings of the 2013 IEEE international conference on robotics and automation, Karlsruhe, Germany, 6–10 May 2013; pp. 2693–2698. [Google Scholar] [CrossRef]
- Park, S.; Roh, K.S. Coarse-to-Fine Localization for a Mobile Robot Based on Place Learning With a 2-D Range Scan. IEEE Trans. Robot. 2016, 32, 528–544. [Google Scholar] [CrossRef]
- Gálvez-López, D.; Tardós, J.D. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Andoni, A.; Indyk, P.; Laarhoven, T.; Razenshteyn, I.; Schmidt, L. Practical and optimal LSH for angular distance. Adv. Neural Inf. Process. Syst. 2015, 28, 1225–1233. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef] [Green Version]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded Up Robust Features. In Proceedings of the European conference on computer vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Kendall, A.; Cipolla, R. Modelling uncertainty in deep learning for camera relocalization. In Proceedings of the IEEE ICRA, Stockholm, Sweden, 16–21 May 2016; pp. 4762–4769. [Google Scholar] [CrossRef] [Green Version]
- Valada, A.; Radwan, N.; Burgard, W. Deep Auxiliary Learning for Visual Localization and Odometry. In Proceedings of the 2018 IEEE international conference on robotics and automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6939–6946. [Google Scholar] [CrossRef] [Green Version]
- Radwan, N.; Valada, A.; Burgard, W. VLocNet++: Deep Multitask Learning for Semantic Visual Localization and Odometry. IEEE Robot. Autom. Lett. 2018, 3, 4407–4414. [Google Scholar] [CrossRef] [Green Version]
- Tian, M.; Nie, Q.; Shen, H. 3D Scene Geometry-Aware Constraint for Camera Localization with Deep Learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 4211–4217. [Google Scholar] [CrossRef]
- Kendall, A.; Cipolla, R. Geometric loss functions for camera pose regression with deep learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6555–6564. [Google Scholar] [CrossRef] [Green Version]
- Zuo, X.; Geneva, P.; Lee, W.; Liu, Y.; Huang, G. LIC-Fusion: LiDAR-Inertial-Camera Odometry. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 5848–5854. [Google Scholar] [CrossRef] [Green Version]
- Shao, W.; Vijayarangan, S.; Li, C.; Kantor, G. Stereo Visual Inertial LiDAR Simultaneous Localization and Mapping. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 370–377. [Google Scholar] [CrossRef] [Green Version]
- System, I.; Monte, W.; Localization, C.; Wolf, J.; Burgard, W.; Burkhardt, H. Robust Vision-Based Localization by Combining. IEEE Trans. Robot. 2005, 21, 208–216. [Google Scholar]
- Park, S.; Park, S.K. Vision-based global localization for mobile robots using an object and spatial layout-based hybrid map. In Proceedings of the 2009 International Conference on Advanced Robotics, Munich, Germany, 22–26 June 2009; pp. 2111–2116. [Google Scholar]
- Xu, S.; Chou, W.; Dong, H. A robust indoor localization system integrating visual localization aided by CNN-based image retrieval with Monte Carlo localization. Sensors 2019, 19, 249. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Agarwal, S.; Mierle, K.; Ceres Solver, O. Available online: http://ceres-solver.org (accessed on 3 February 2022).
- Meeussen, W. robot_pose_ekf. Available online: http://wiki.ros.org/robot_pose_ekf (accessed on 3 February 2022).


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pose | posenetLSTM | The System | Improvement | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | S.D. | RMSE | MAE | S.D. | RMSE | MAE | S.D. | |
| pose_x(m) | 0.5938 | 0.4642 | 0.5939 | 0.4291 | 0.3191 | 0.4291 | 27.74% | 31.26% | 27.75% |
| pose_y(m) | 0.5595 | 0.4094 | 0.5586 | 0.3187 | 0.2345 | 0.3148 | 43.04 | 42.72% | 43.64% |
| pose_yaw(rad) | 0.1840 | 0.1180 | 0.1831 | 0.09518 | 0.06790 | 0.09197 | 48.27% | 42.45% | 49.77% |
| Pose | AMCL | The System | Improvement | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | S.D. | RMSE | MAE | S.D. | RMSE | MAE | S.D. | ||
| case 1 | pose_x(m) | 0.0400 | 0.0319 | 0.0350 | 0.0361 | 0.0295 | 0.0321 | 9.75% | 7.52% | 8.28% |
| pose_y(m) | 0.0327 | 0.0266 | 0.0272 | 0.0278 | 0.0220 | 0.0238 | 14.98% | 17.29% | 12.5% | |
| pose_yaw(rad) | 0.0186 | 0.0119 | 0.0186 | 0.0170 | 0.0108 | 0.0170 | 8.6% | 9.24% | 8.6% | |
| case 2 | pose_x(m) | 0.0415 | 0.0322 | 0.0411 | 0.0355 | 0.0289 | 0.0310 | 14.5% | 10.2% | 24.5% |
| pose_y(m) | 0.0381 | 0.0301 | 0.0329 | 0.0269 | 0.0218 | 0.0225 | 29.4% | 27.6% | 31.6% | |
| pose_yaw(rad) | 0.0195 | 0.0128 | 0.0193 | 0.0157 | 0.0097 | 0.0156 | 19.5% | 24.2% | 19.2% | |
| Case 1 | AMCL | The System | Time–Cost Reduction |
|---|---|---|---|
| Mean Time–Cost (ms) | Mean Time–Cost (ms) | ||
| case 1 | 10.442 | 7.258 | 30.49% |
| case 2 | 10.883 | 7.286 | 33.05% |
| Pose | posenetLSTM | The System | Improvement | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | S.D. | RMSE | MAE | S.D. | RMSE | MAE | S.D. | |
| pose_x(m) | 0.2738 | 0.1769 | 0.2686 | 0.1870 | 0.1370 | 0.1867 | 31.70% | 22.56% | 30.49% |
| pose_y(m) | 0.2758 | 0.2070 | 0.2751 | 0.2089 | 0.1359 | 0.2078 | 24.26% | 34.34% | 24.46% |
| pose_yaw(rad) | 0.0799 | 0.0545 | 0.0798 | 0.0584 | 0.0424 | 0.0571 | 26.91% | 22.20% | 28.45% |
| Trajectory | Pose | AMCL | The System | Improvement | |||
|---|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | ||
| 1 | pose_x(m) | 0.0310 | 0.0293 | 0.0304 | 0.0290 | 1.94% | 7.52% |
| pose_y(m) | 0.0192 | 0.0175 | 0.0185 | 0.0157 | 3.65% | 10.28% | |
| 2 | pose_x(m) | 0.0240 | 0.0225 | 0.0214 | 0.0204 | 10.8% | 9.33% |
| pose_y(m) | 0.0237 | 0.0230 | 0.0207 | 0.0192 | 12.65% | 16.52% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhao, C.; Wei, Y. A Robust Localization System Fusion Vision-CNN Relocalization and Progressive Scan Matching for Indoor Mobile Robots. Appl. Sci. 2022, 12, 3007. https://doi.org/10.3390/app12063007
Liu Y, Zhao C, Wei Y. A Robust Localization System Fusion Vision-CNN Relocalization and Progressive Scan Matching for Indoor Mobile Robots. Applied Sciences. 2022; 12(6):3007. https://doi.org/10.3390/app12063007
Chicago/Turabian StyleLiu, Yanjie, Changsen Zhao, and Yanlong Wei. 2022. "A Robust Localization System Fusion Vision-CNN Relocalization and Progressive Scan Matching for Indoor Mobile Robots" Applied Sciences 12, no. 6: 3007. https://doi.org/10.3390/app12063007