1. Introduction
Image is an important source of information for human perception and machine recognition [
1,
2,
3]. In order for machines to have visual perception, not only does the equipment need to be capable of predictive maintenance [
4], but it also needs to capture high-quality images. Image quality plays a decisive role in the sufficiency and accuracy of the acquired information. However, the image is inevitably distorted in the process of acquisition, compression, processing, transmission, and display. How to measure the quality of the image and evaluate whether the image meets a specific requirement becomes a problem. To solve this problem, it is necessary to establish an effective image quality assessment (IQA) system. At present, IQA methods can be divided into subjective evaluation methods and objective evaluation methods. The former relies on the subjective perception of experimenters to evaluate the quality of the object. The latter simulates the perception mechanism of the human visual system based on the quantitative indicators given by the model. According to the classification of images, IQA can be divided into facial image quality [
5,
6], synthetic image quality, and so on. Below, we introduce the perspective of model improvement.
Objective image quality assessments are quite meaningful. They can provide feedback and optimization for denoising algorithms, provide early evaluation and preprocessing of image data for computer vision tasks, and even indirectly reflect the quality of the shooting equipment. According to whether a reference image is needed, the objective image quality assessment is divided into full-reference image quality assessment (FR-IQA), reduced reference image quality assessment (RR-IQA) and no-reference image quality assessment (NR-IQA). The FR-IQA [
7,
8,
9,
10] method requires a distortion-free reference image and compares the information or feature similarity of two images to obtain the evaluation result of the distorted image. The RR-IQA [
11,
12,
13] method is based on part of the characteristic information of the reference image. The NR-IQA method directly evaluates the quality of distorted images. Despite some NR-IQA methods not needing reference images in the testing phase, they still need reference images in the training phase [
14,
15]. According to the type of distortion, the method is divided into specific types of distortion and general image quality assessment. Classical methods are based on natural scene statistics (NSS) [
10,
16,
17,
18,
19], transform domain [
9,
20], gradient features [
17] and unsupervised learning [
21,
22], etc.
Since 2014, most of the NR-IQA methods have adopted CNN-based models, and researchers have constantly changed and deepened the model structure. CNN is a simulation of the biological visual system. With research on the physiology and anatomy of the biological optic nerve, an increasing number of scholars have begun to use mathematical models to reveal the processing mechanism of visual information. Inspired by the biological vision, we simulated the mechanism of the biological optic nerve and receptive field, and proposed a two-stage training method that does not require reference images. This was tested on the LIVE [
23] data set and TID2013 [
24] data set. The innovations of this article are as follows:
- (1)
Using multi-scale contour features as the one-stage regression target to solve the problem of too few data sets.
- (2)
Designing the different learning labels of different layers of the model to simulate the evaluation of human eyes on images at different distances.
- (3)
Designing a central attention peripheral inhibition module to simulate the mechanism of the receptive field of retinal ganglion cells.
The following sections of the paper are organized as follows.
Section 2 introduces the current status of the CNN-based NR-IQA.
Section 3 details the framework of the model proposed in this paper.
Section 4 presents the test results of the model.
Section 5 concludes the paper.
2. Related Work
The current NR-IQA methods based on convolutional neural network (CNN) are divided into image-based and patch-based according to the input image [
25]. In the early years, in order to increase training data, most of the methods were based on patch-based methods.
In 2014, Kang et al. [
26] used CNN for the NR-IQA for the first time. The author first normalized the image, and then divided it into 32 · 32 non-overlapping image patches, used the CNN network to estimate the quality score of each image patch, and the final image quality score was the average score of all image patches. The CNN network used in this method has one convolutional layer with max and min pooling, two fully connected layers and an output node. Although this method has better results than traditional manual feature extraction methods, it has the following shortcomings when the distortion types are complex and diverse: (1) It is unreasonable to use the average of the quality scores of all image patches as a quality score for the entire image. (2) It is unreasonable to use the global subjective score as the image local quality score for training.
In order to solve the problem 1, Bosse et al. [
27] proposed a method including a weight estimation module. During the training stage, a sub-network is used to train the weights of image patches. The method proposed by [
27] used a deeper and more complex neural network structure than the method of Kang et al. [
26] Therefore, the network learned more image features, and its performance was improved. However, as the network deepens, the problem of too few training data sets becomes more serious. As in the previous method, with the aim of increasing the training data, the network input was the 32 · 32 image patch, and the quality score of the image patch was still the quality score of the entire image.
For the purpose of solving problem 2, many researchers have proposed a method of first generating the local quality score of the distorted image as the one-stage regression target. In 2017, Kim proposed a two-stage method (BIECON) [
14]. The first step is to use the FR-IQA method to obtain the local quality score and use the local quality score as the target label of the CNN model to predict the quality score of image patches. In the second step, the subjective quality score of the distorted image was used as the target label, and all model parameters were optimized at the same time. In spite of the fact that the BIECON method solved the unreasonable problem of using the subjective score of the entire image as the quality score label of the image patch, the local quality score of the distorted image generated by the FR-IQA method has an error in itself, and this method must use the reference image.
The root cause of the patch-based method is that there are too few data sets. Therefore, many researchers have proposed methods of pre-training CNN networks using data sets in other fields. For example, DeepBIQ [
28] proposed by Simone Bianco et al. In addition to the pre-training method, Liu et al. proposed the RankIQA [
29] method based on the idea of ranking learning. Although it is difficult to directly estimate the quality score of a distorted image, it is relatively easy to compare the relative quality of different degrees of distortion. In 2019, the author of the BIECON method proposed the DIQA [
15] method. This method is still a two-stage method, but no longer uses the subjective quality score as the regression target, instead, using the objective error map as the intermediate CNN learning target.
In addition to the aforementioned method of predicting image quality scores, Hossein et al. proposed the NIMA [
30] method. This method no longer trains the network to predict the quality score of the image but predicts the distribution of human quality scores of the image.
In short, due to the lack of IQA data sets, which seriously affects the structural design of the CNN network, this paper proposes a two-stage method to solve this problem.
3. Approach
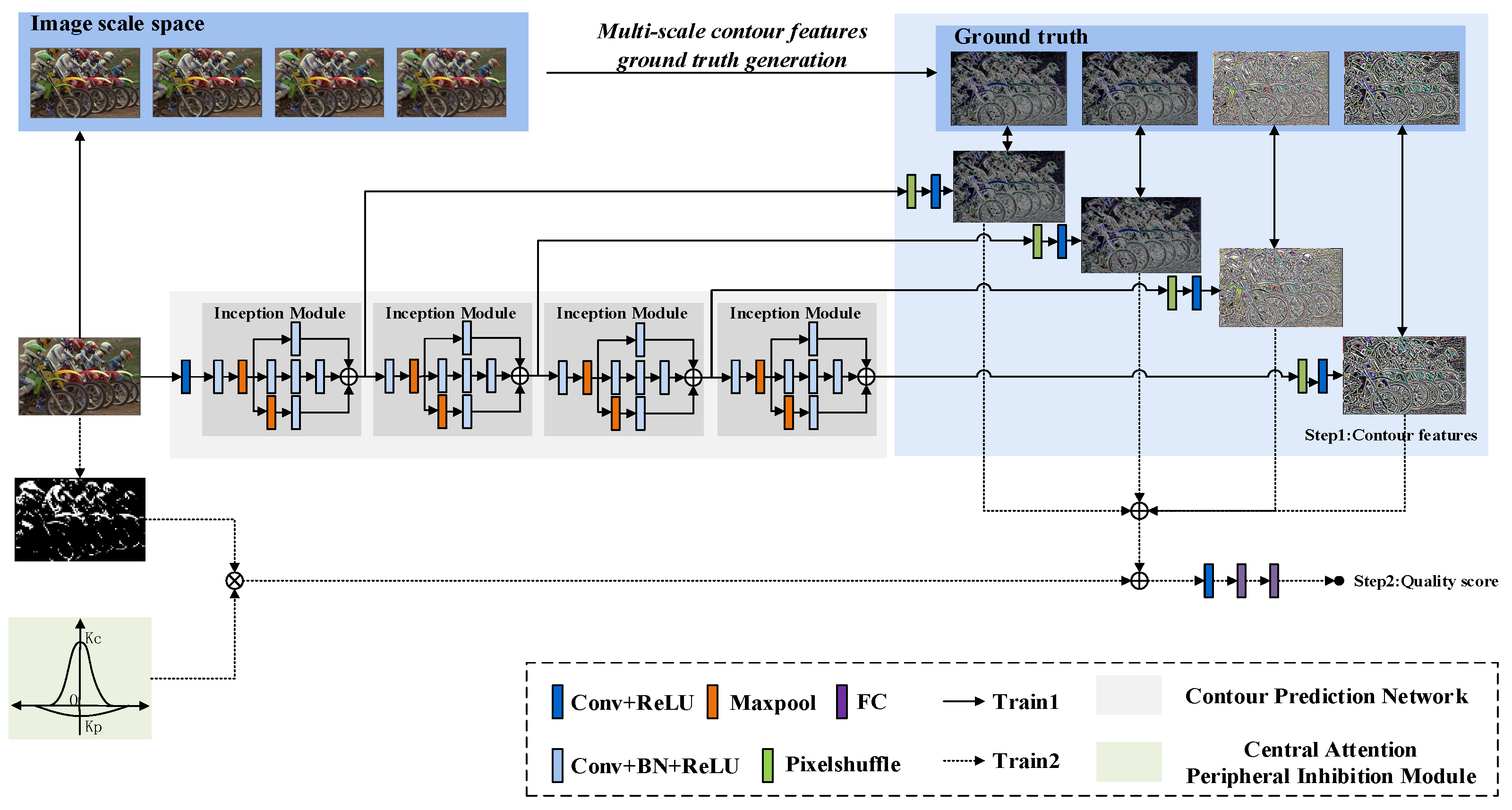
The overall framework of the MSIQA is shown in
Figure 1. In the first stage of training, the multi-scale contour prediction network is trained to predict the contour features of diverse scale pictures in scale-spaces. In the second stage of training, the MSIQA model combines the central attention peripheral inhibition module to learn to predict the quality score of the image.
3.1. Model Architecture
The MSIQA model consists of two main modules: (1) a multi-scale contour prediction network to simulate the response of human eyes on an image’s contours at different distances, and (2) a central attention peripheral inhibition module to simulate the mechanism of the receptive field of retinal ganglion cells. We use four inception [
31,
32,
33] modules with the same structure to build the contour prediction network. Each layer has a batch normalization (BN) [
34] and a rectified linear unit (ReLU) [
35]. After the inception module, the PixelShuffle [
36] method is used to upscale the input feature to the same size as the input image. In the second stage of training, the outputs of different inception modules are first fused and combined with the central attention peripheral inhibition module, then fed into the convolutional layer and two fully connected layers.
3.2. Multi-Scale Contour Features
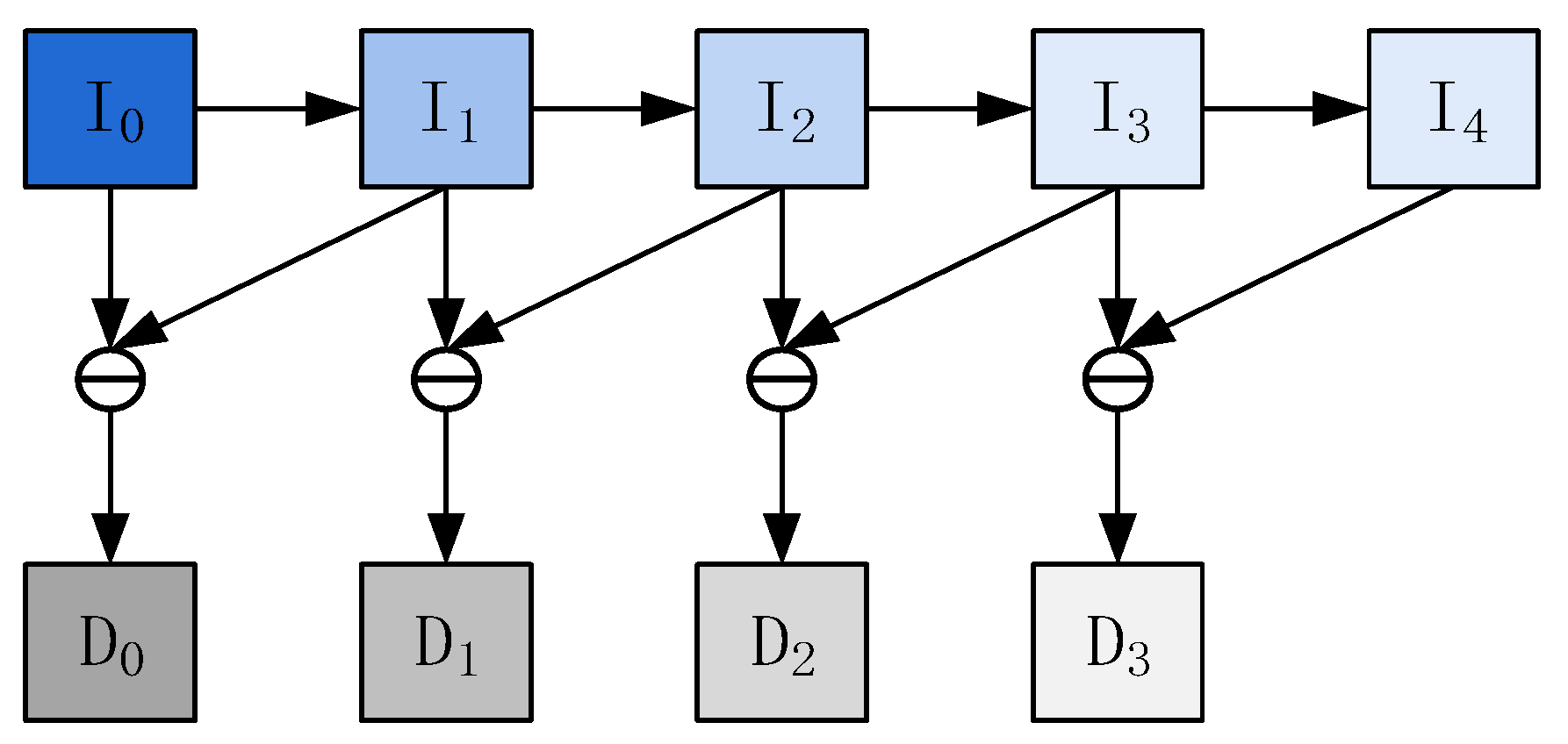
We believe that the sharpness of the edge contour of the image is an important feature that affects the image quality. At the same time, the same distortion type of the distorted images have different degrees of distortion, and the contour features of all images in the image scale space can simulate images with different degrees of distortion. Multi-scale features are used to simulate the contour response of the retina to images at different distances, so we train the model in the first stage to predict the contour features of images at different scales.
The scale-space of an image is the convolution of the image and the Gaussian function of the variable scale. The two-dimensional Gaussian function is:
The scale-space of an image
is:
where
The image subtraction of adjacent scales obtains the multi-scale contour features. Therefore, the contour feature ground truth is defined as:
Figure 2 shows the generation of the multi-scale contour features ground truth. The images shown in
Figure 3a–e are an image scale space of
Figure 3a. The images shown in
Figure 3f–i are contour features of different scales of the image in
Figure 3a.
Figure 4 is the same as
Figure 3.
In the first stage of training, the contour prediction network learns to predict contour features, and the loss function is defined by the mean square error between the predicted value and the ground-truth:
where
is the contour feature of the image
predicted by the model,
is the parameters of the contour prediction network, and
is the exponent number. In our experiment, we choose
.
3.3. Quality Score Prediction
In the second step of training, the central attention peripheral inhibition module combines the brightness information of the image to weigh the multi-scale contour features learned in the first stage. The central attention peripheral inhibition module adopts a double Gaussian difference model, which is composed of two parts: the center position of the image has strong attention and the edge position is weakened, which simulates the different attention and different residence times of humans in different areas of the image. The distribution is:
where
is the central attention enhancement coefficient,
is the peripheral inhibition coefficient.
Because the optic nerve has different sensitivity to images of different brightness, it is necessary to add brightness information of the image while considering the attention of different areas of the image. We normalized the overall image brightness and increased the quality score weight of image blocks with strong brightness.
The MSIQA model learns to predict image quality score. The loss function is defined as:
where
is the image quality score of the image
predicted by the model,
is the parameters of the CNN network,
is the ground truth subjective score of the input image
.
3.4. Training
Because there are fully connected layers in the MSIQA model, the input size of the network must be unified. We have tested the effect of different sizes on the performance of the model, and the results are given in
Section 4.
In the first stage of training, 80% of the images in the data set are randomly selected for training. First, the image is cropped into image patches of uniform size, and then the four-scale space images of each image patch are fed to the network for training. In the second stage of training, 80% of the images are randomly selected for training, and the image patches are directly fed to the network for training.
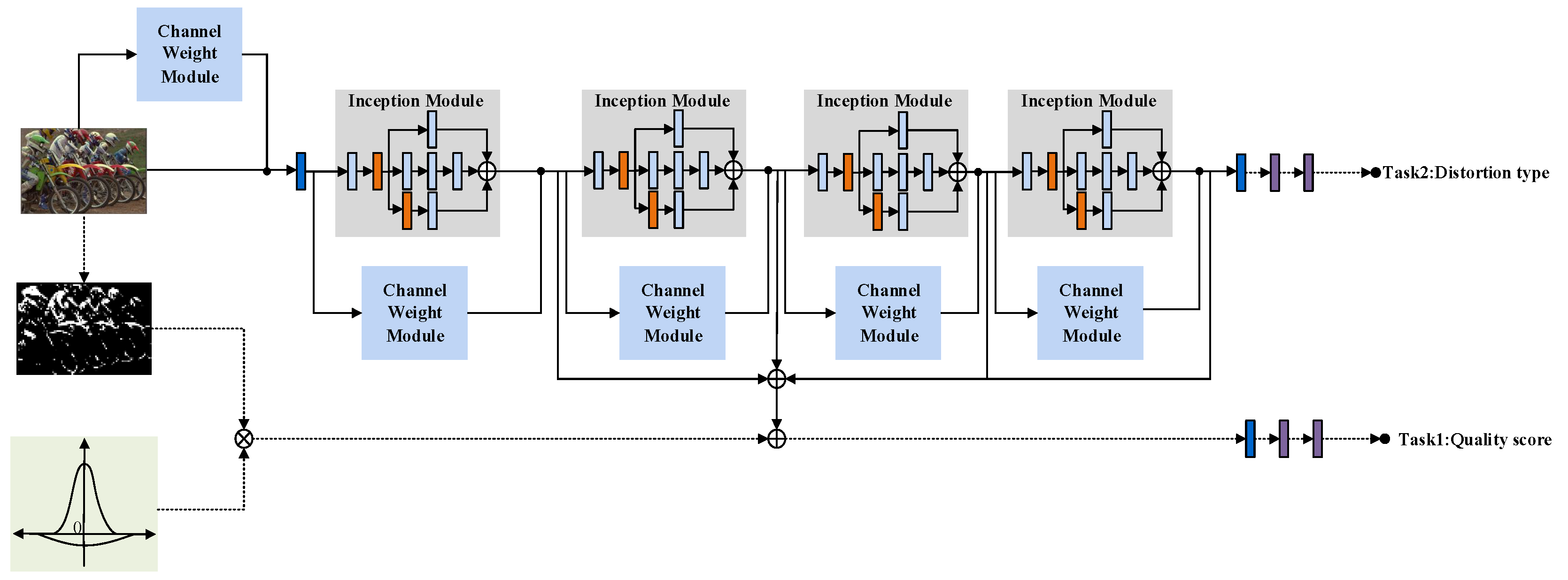
3.5. Multi-Task Model
Humans have various intuitive perceptions of different types of distortions. The types of distortions affect humans’ evaluation of image quality to a certain extent. Therefore, from the point of view of IQA, the detection of the distortion type is also of certain significance. At the same time, additional feature information of the distortion type is added to more strongly constrain the model and reduce the risk of overfitting.
The multi-task learning model adopts the hard parameter sharing method and adopts the basic structure of the MSIQA model proposed in 3.1. Task one is IQA, and task two is a classification of image distortion types. The overall framework of the model is shown in
Figure 5.
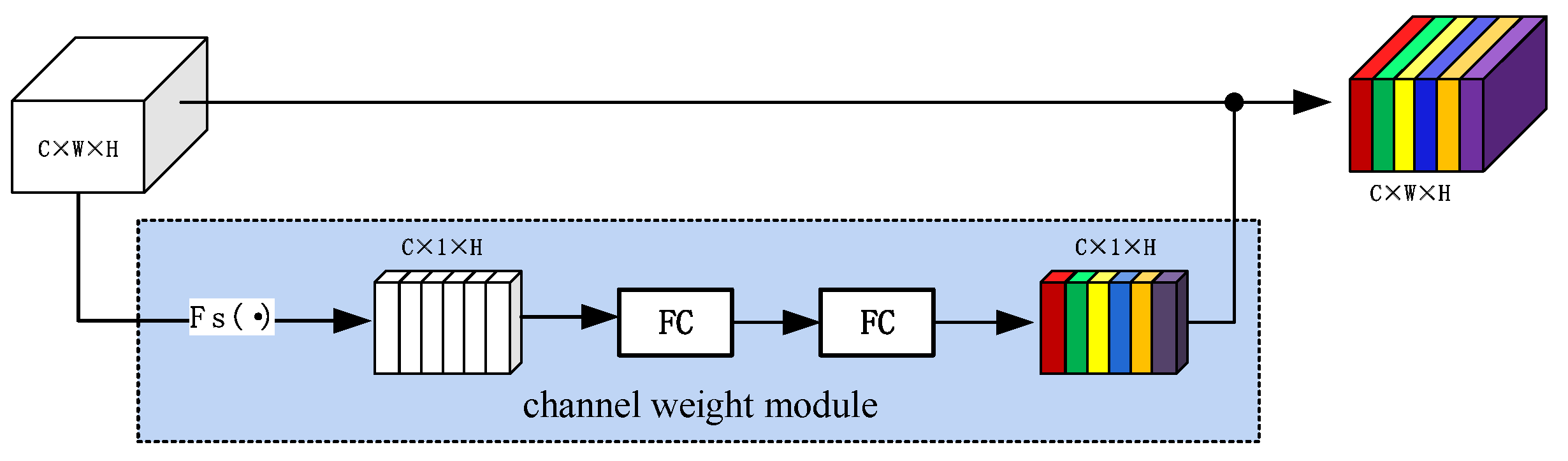
The image convolution operation can only obtain the relationship between local channels, and the network should learn important feature information from different feature channels. Referring to the idea proposed by Hu et al. [
37], a feature channel weight module is added to the model, and the framework is shown in
Figure 6.
First compress the input from size
to
:
where
x is the input and
W is the width of the input. After size compression, through two convolutional layers, the input channel weight is finally obtained, and then dot-multiply with input.
The loss weight of the two tasks adopts a dynamic weighting method. The loss function is defined as:
where
is the weight of loss defined as:
where
is the loss of task
in step
,
is a constant.
5. Conclusions
In this paper, we propose a biological vision-based multi-scale fusion NR-IQA model named MSIQA, which simulated the mechanism of the biological optic nerve and receptive field and adopts a two-stage training method. The MSIQA model fully combines the image contour feature, brightness and receptive field attention mechanism, and does not require reference images in the training and testing stages. As a result, the SRCC of the MSIQA model test on the LIVE database reached 0.983. On this basis, we propose a multi-task model that can classify distortion types at the same time. In the future, we will compress the model and increase the detection speed.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}