
Cerebrovascular Segmentation Model Based on Spatial Attention-Guided 3D Inception U-Net with Multi-Directional MIPs


Abstract
:1. Introduction
- (1)
- Based on a careful understanding of the network structure of 3D U-Net and the application of MIP to medical images, this paper proposes an improved network using MIP images in three directions to extract richer information. The effectiveness of the improved model is verified by experiments;
- (2)
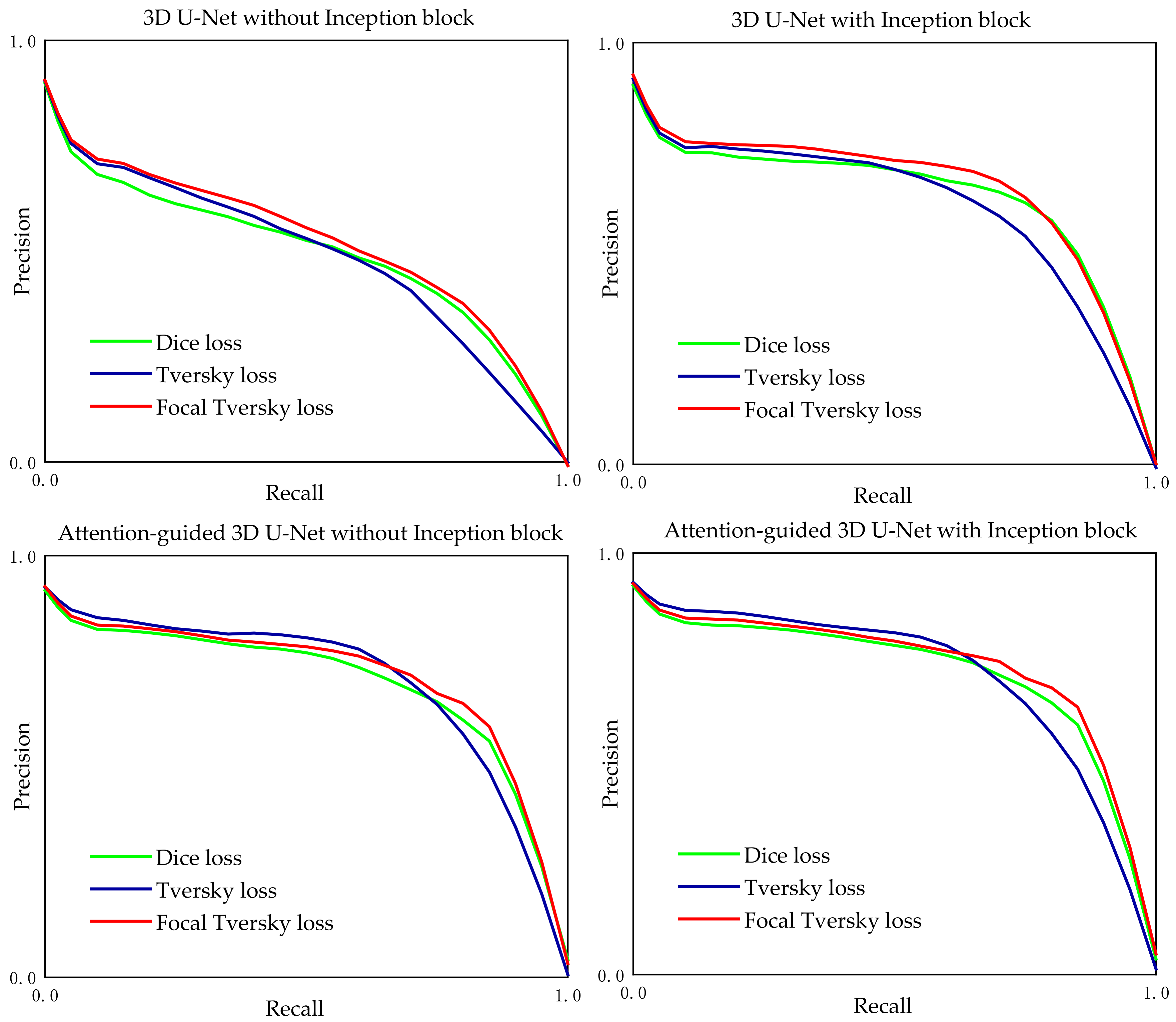
- The effect of the loss functions on the segmentation result is studied on the MRA dataset;
- (3)
- This paper replaces the original convolutional block with the Inception block [28]. In the Inception block, we employ two 3 × 3 filters to obtain an equivalent receptive field of a 5 × 5 convolutional filter, which significantly reduces the amount of computation that has to be done by the network in the subsequent layers.
2. Materials and Methods
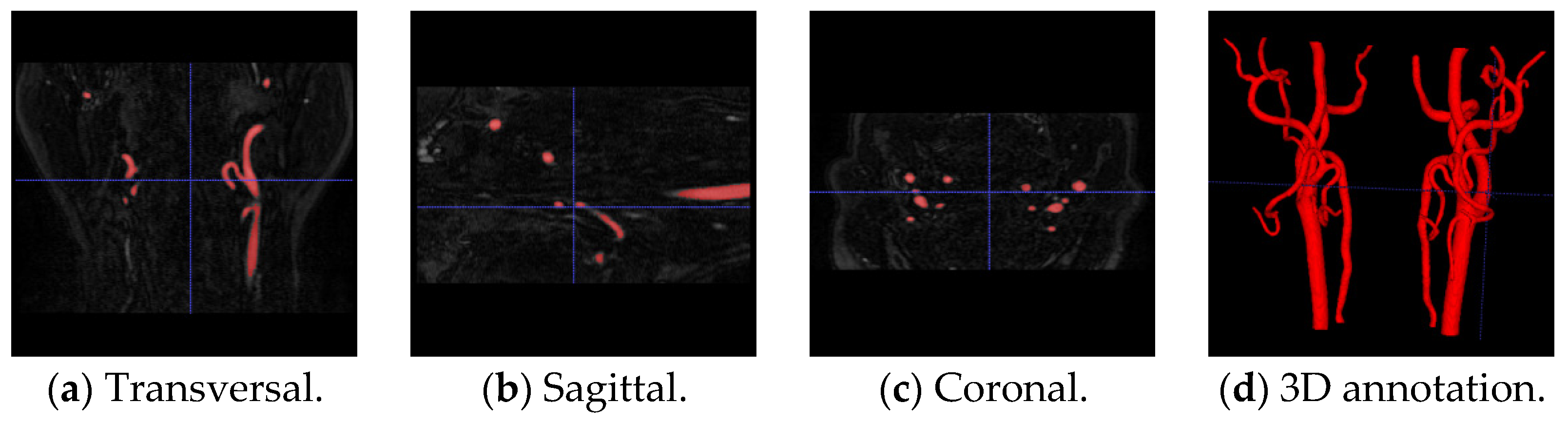
2.1. Dataset
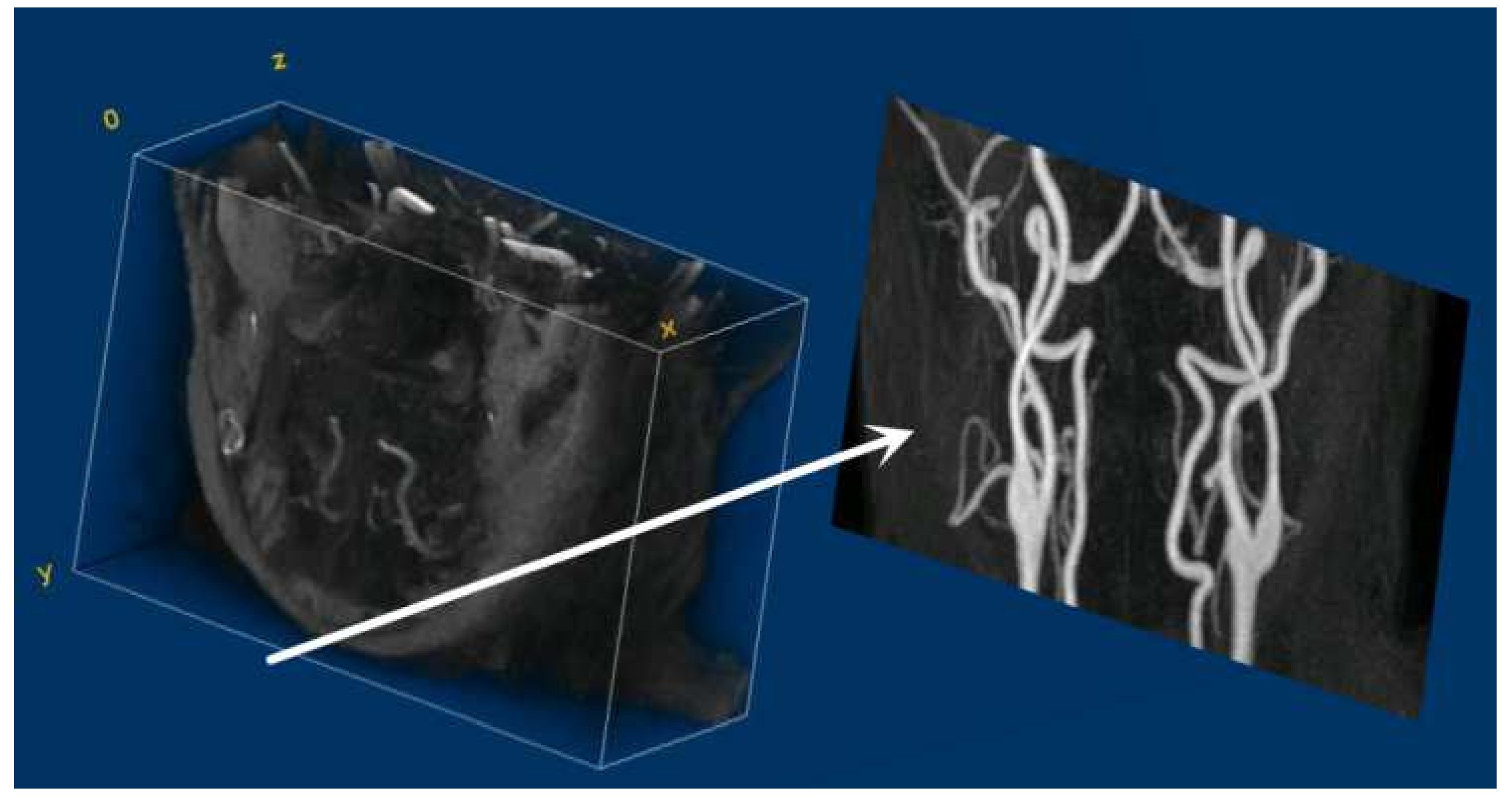
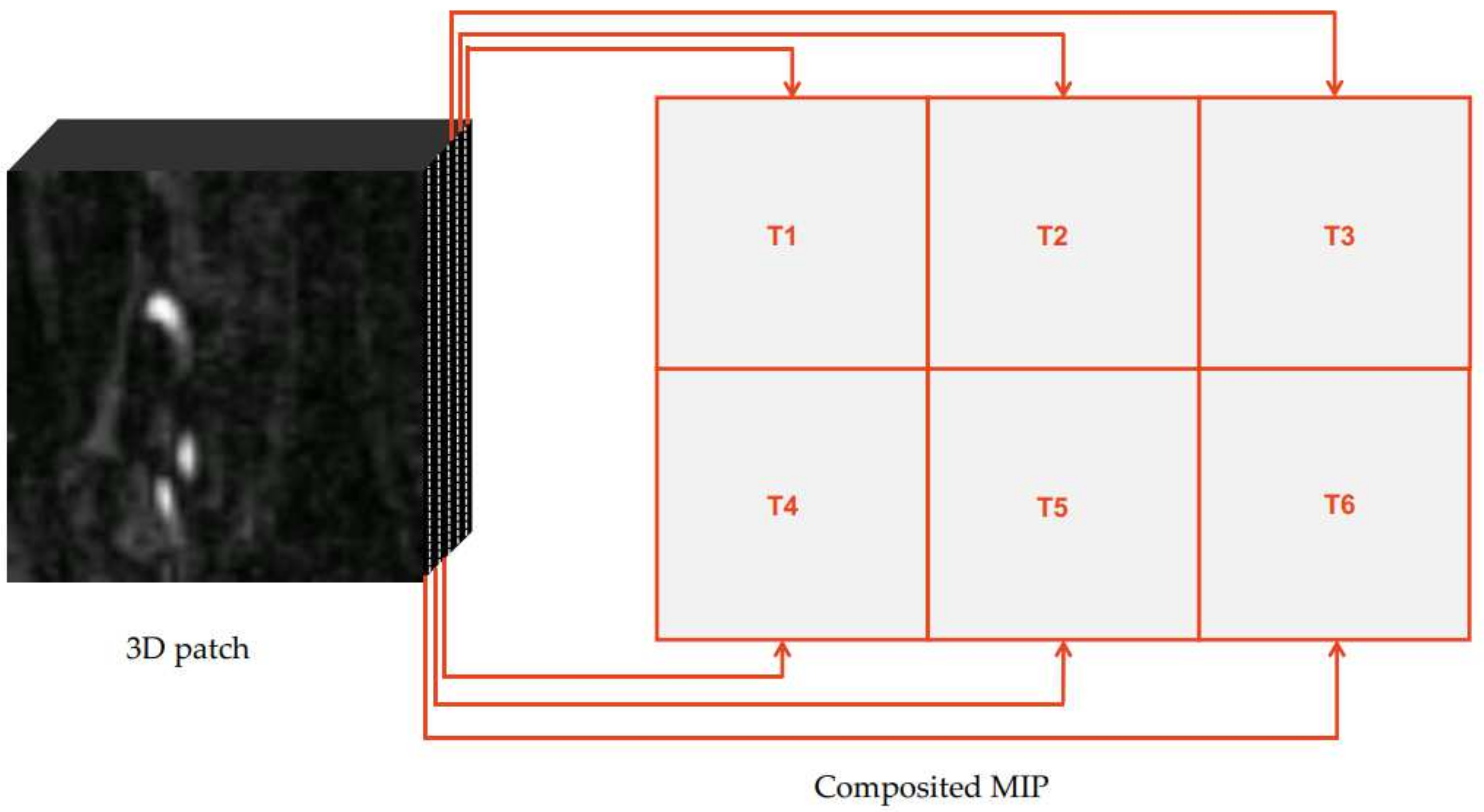
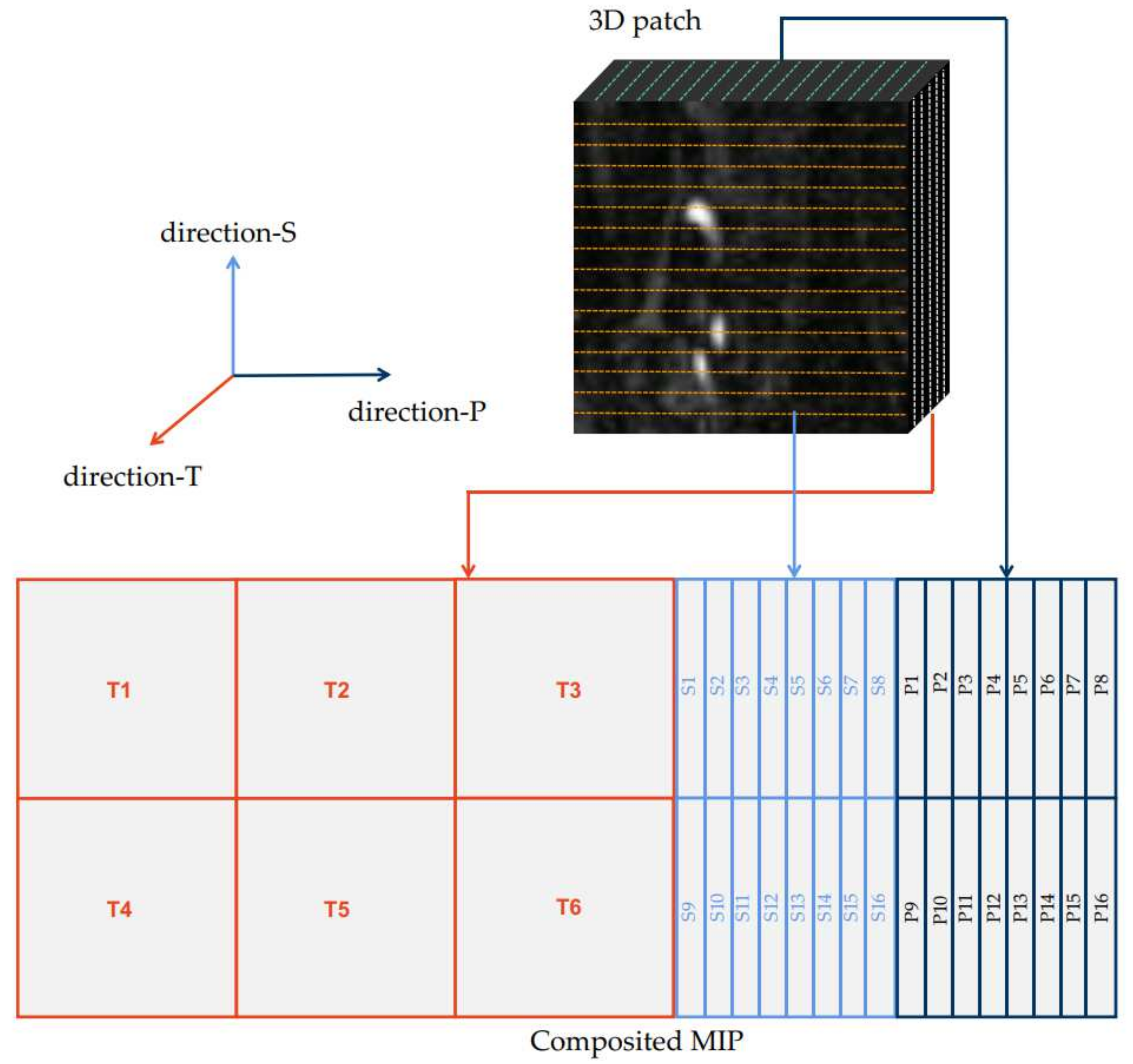
2.2. Multi-Directional MIP
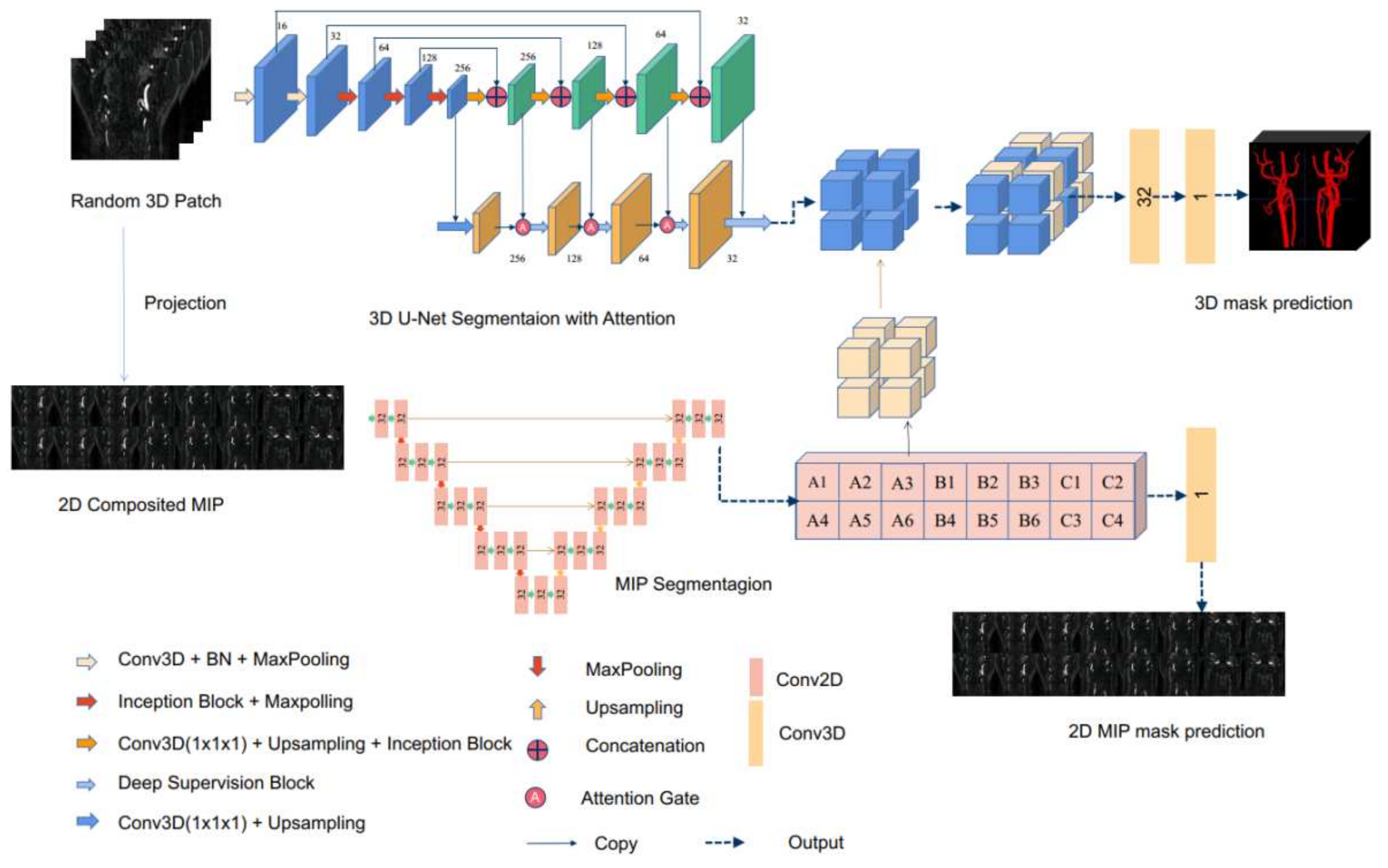
2.3. Network Architecture
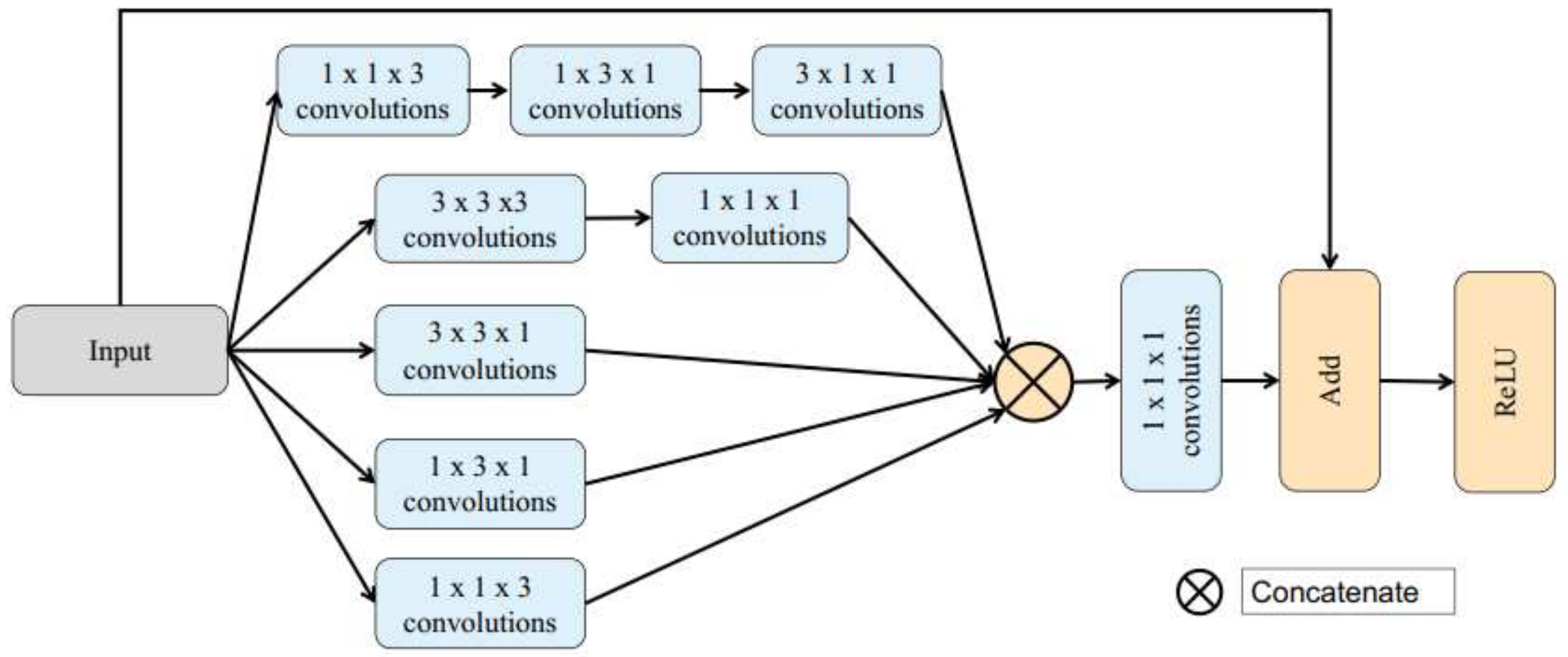
2.3.1. Inception Block
- To extract line-wise features, 1 × 1 × 3, 1 × 3 × 1, and 3 × 1 × 1 convolution units are used;
- To exact 3D features, 3 × 3 × 3 3D convolution units are employed as a supplement, followed by a 1 × 1 × 1 convolution unit, which is used to reduce the number of depth channels and extract point-wise features;
- To extract plane-wise features, 1 × 3 × 3, 3 × 1 × 3, and 3 × 3 × 1 convolution units are introduced;
- A residual structure is added to the Inception block by directly connecting the input to the addition block to accelerate training of network, while the performance is also improved;
- ReLU is employed as the activation function for each layer and batch normalization is performed in each Inception block.
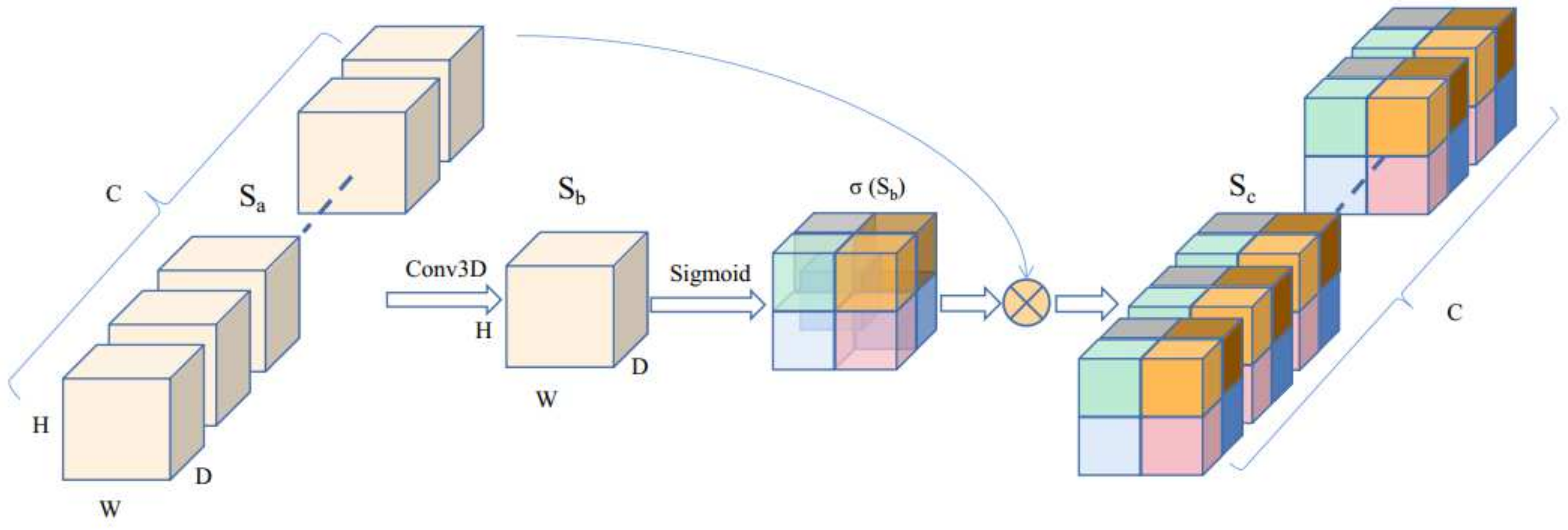
2.3.2. Attention Block
2.4. Loss Function and Metrics
3. Experiment and Results
3.1. Experiments
3.1.1. Data Pre-Processing and Augmentation
- We cropped the MRA image randomly from 320 × 320 × 200 or 960 × 960 × 180 voxels to 128 × 128 × 16 voxels to train our network due to memory limitation. For each volume, 100 patches were randomly extracted. For example, there were 64 cases in the dataset, and we obtained 6400 patches for training after extracting;
- We flipped along each 3D axis randomly with a probability of 0.5.
3.1.2. Training Details
3.1.3. Post-Processing
- Noisy pixels on borders or further away from the main volume were removed by eroding operations;
- The surfaces of the predicted result were smoothed by the smoothing operator;
- Holes inside the cerebrovascular segmentation result were removed by removing the connected domains with smaller volumes.
3.2. Quantitative Comparison
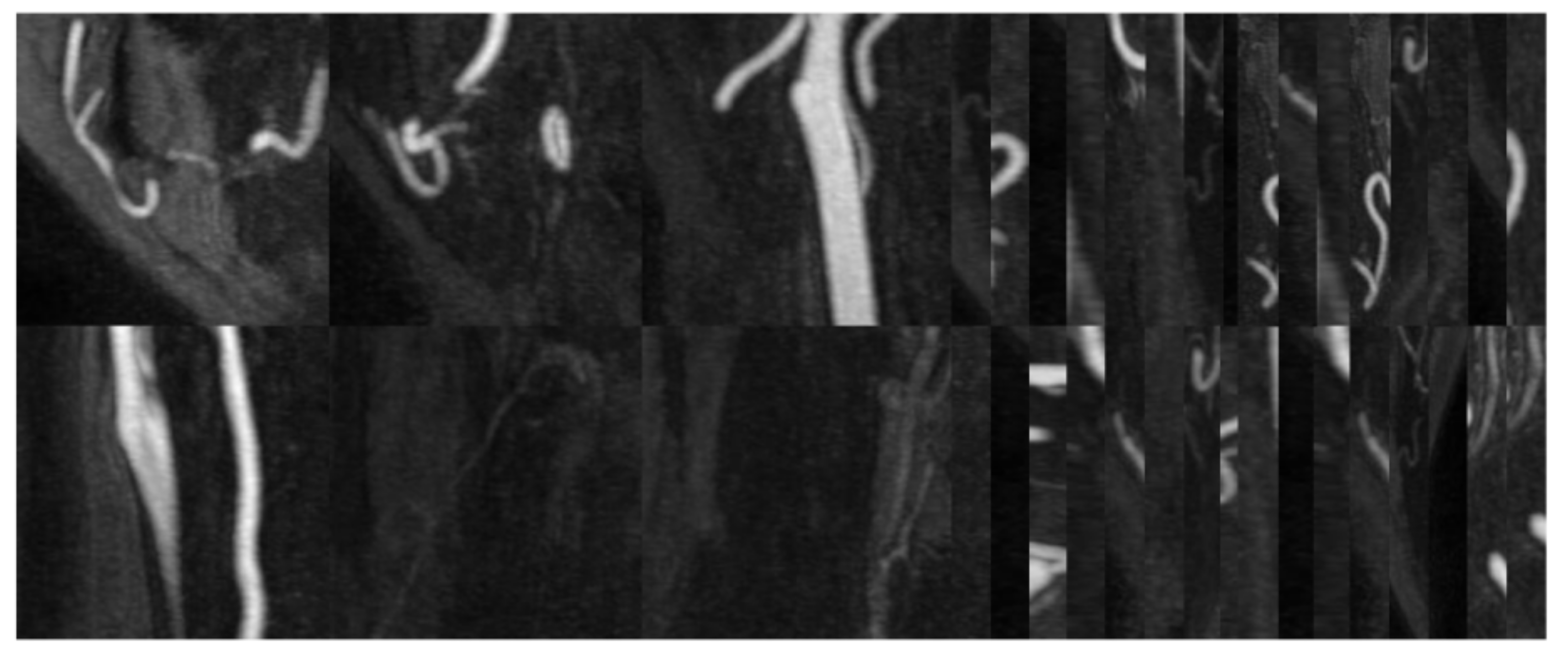
3.3. Qualitative Comparison
3.4. Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bi, J. A Novel Thinning Algorithm of 3D Image Model Based on Spatial Wavelet Interpolation. J. Comput. 2013, 8, 3012–3019. [Google Scholar] [CrossRef] [Green Version]
- Pujari, A.K.; Mitra, C.; Mishra, S. A new parallel thinning algorithm with stroke correction for odia characters. In Advanced Computing, Networking and Informatics-Volume 1; Springer: Berlin/Heidelberg, Germany, 2014; pp. 413–419. [Google Scholar]
- Kwon, J.-S. Improved parallel thinning algorithm to obtain unit-width skeleton. Int. J. Multimed. Appl. 2013, 5, 1–14. [Google Scholar] [CrossRef]
- Gayathri, S.; Sridhar, V. An improved fast thinning algorithm for fingerprint image. Int. J. Eng. Sci. Innov. Technol. 2013, 2, 264–270. [Google Scholar]
- Fabbri, R.; Costa, L.D.F.; Torelli, J.C.; Bruno, O.M. 2D Euclidean distance transform algorithms: A comparative survey. ACM Comput. Surv. 2008, 40, 1–44. [Google Scholar] [CrossRef]
- Gurumoorthy, K.S.; Rangarajan, A. Distance Transform Gradient Density Estimation Using the Stationary Phase Approximation. SIAM J. Math. Anal. 2012, 44, 4250–4273. [Google Scholar] [CrossRef]
- Rong, G.; Tan, T.-S. Jump flooding in GPU with applications to Voronoi diagram and distance transform. In Proceedings of the 2006 Symposium on Interactive 3D Graphics and Games, Redwood City, CA, USA, 14–17 March 2006; pp. 109–116. [Google Scholar]
- Breu, H.; Gil, J.; Kirkpatrick, D.; Werman, M. Linear-Time Euclidean Distance Transform Algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 529–533. [Google Scholar] [CrossRef]
- Olabarriaga, S.D.; Breeuwer, M.; Niessen, W. Evaluation of Hessian-Based Filters to Enhance the Axis of Coronary Arteries in CT Images; International Congress Series; Elsevier: Amsterdam, The Netherlands, 2003; pp. 1191–1196. [Google Scholar]
- Truc, P.T.H.; Khan, M.A.U.; Lee, Y.K.; Lee, S.; Kim, T.S. Vessel enhancement filter using directional filter bank. Comput. Vis. Image Underst. 2009, 113, 101–112. [Google Scholar] [CrossRef]
- Faber, S.C.; Hoffmann, A.; Ruedig, C.; Reiser, M. MRI-induced stimulation of peripheral nerves: Dependency of stimulation threshold on patient positioning. Magn. Reson. Imaging 2003, 21, 715–724. [Google Scholar] [CrossRef]
- Passat, N.; Ronse, C.; Baruthio, J.; Armspach, J.P.; Foucher, J. Watershed and multimodal data for brain vessel segmentation: Application to the superior sagittal sinus. Image Vis. Comput. 2007, 25, 512–521. [Google Scholar] [CrossRef] [Green Version]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Ding, K.; Xiao, L.; Weng, G. Active contours driven by region-scalable fitting and optimized Laplacian of Gaussian energy for image segmentation. Signal Process. 2017, 134, 224–233. [Google Scholar] [CrossRef]
- Jin, R.; Weng, G. Active contours driven by adaptive functions and fuzzy c-means energy for fast image segmentation. Signal Process. 2019, 163, 1–10. [Google Scholar] [CrossRef]
- Weng, G.; Dong, B.; Lei, Y. A level set method based on additive bias correction for image segmentation. Expert Syst. Appl. 2021, 185, 115633. [Google Scholar] [CrossRef]
- Kayalibay, B.; Jensen, G.; van der Smagt, P. CNN-based segmentation of medical imaging data. arXiv 2017, arXiv:1701.03056. [Google Scholar]
- Fu, H.; Xu, Y.; Lin, S.; Wong, D.W.K.; Liu, J. Deepvessel: Retinal vessel segmentation via deep learning and conditional random field. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 132–139. [Google Scholar]
- Sanchesa, P.; Meyer, C.; Vigon, V.; Naegel, B. Cerebrovascular network segmentation of MRA images with deep learning. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 768–771. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athina, Greece, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 424–432. [Google Scholar]
- Tetteh, G.; Efremov, V.; Forkert, N.D.; Schneider, M.; Kirschke, J.; Weber, B.; Zimmer, C.; Piraud, M.; Menze, B.H. DeepVesselNet: Vessel Segmentation, Centerline Prediction, and Bifurcation Detection in 3-D Angiographic Volumes. Front. Neurosci. 2020, 14, 592352. [Google Scholar] [CrossRef]
- Wu, Y.; Xia, Y.; Song, Y.; Zhang, D.; Liu, D.; Zhang, C.; Cai, W. Vessel-Net: Retinal vessel segmentation under multi-path supervision. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 264–272. [Google Scholar]
- Wang, Y.; Yan, G.; Zhu, H.; Buch, S.; Wang, Y.; Haacke, E.M.; Hua, J.; Zhong, Z. JointVesselNet: Joint Volume-Projection Convolutional Embedding Networks for 3D Cerebrovascular Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Istanbul, Turkey, 4–8 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 106–116. [Google Scholar]
- Prokop, M.; Shin, H.O.; Schanz, A.; SchaeferProkop, C.M. Use of maximum intensity projections in CT angiography: A basic review. Radiographics 1997, 17, 433–451. [Google Scholar] [CrossRef]
- Angermann, C.; Haltmeier, M. Random 2.5 d u-net for fully 3d segmentation. In Machine Learning and Medical Engineering for Cardiovascular Health and Intravascular Imaging and Computer Assisted Stenting; Springer: Berlin/Heidelberg, Germany, 2019; pp. 158–166. [Google Scholar]
- Angermann, C.; Haltmeier, M.; Steiger, R.; Pereverzyev, S.; Gizewski, E. Projection-based 2.5 d u-net architecture for fast volumetric segmentation. In Proceedings of the 2019 13th International Conference on Sampling Theory and Applications (SampTA), Bordeaux, France, 8–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Jeon, S.J.; Kwak, H.S.; Chung, G.H. Widening and Rotation of Carotid Artery with Age: Geometric Approach. J Stroke Cereb. Dis 2018, 27, 865–870. [Google Scholar] [CrossRef]
- Jeong, S.K.; Lee, J.H.; Nam, D.H.; Kim, J.T.; Ha, Y.S.; Oh, S.Y.; Park, S.H.; Lee, S.H.; Hur, N.; Kwak, H.S.; et al. Basilar artery angulation in association with aging and pontine lacunar infarction: A multicenter observational study. J. Atheroscler. Thromb. 2015, 22, 509–517. [Google Scholar] [CrossRef] [Green Version]
- Yushkevich, P.A.; Gao, Y.; Gerig, G. ITK-SNAP: An interactive tool for semi-automatic segmentation of multi-modality biomedical images. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3342–3345. [Google Scholar]
- Marquis, H.; Deidda, D.; Gillman, A.; Willowson, K.; Gholami, Y.; Hioki, T.; Eslick, E.; Thielemans, K.; Bailey, D. Theranostic SPECT Reconstruction for Improved Lesion Dosimetry in Radionuclide Therapy. J. Nucl. Med. 2021, 62 (Suppl. 1), 1533. [Google Scholar]
- Li, S.; Zhao, Y.; Ye, Y. Improved minimum intensity projection in holographic reconstruction via SNR-enhanced holography. J. Mod. Opt. 2021, 68, 322–326. [Google Scholar] [CrossRef]
- Kawel, N.; Seifert, B.; Luetolf, M.; Boehm, T. Effect of Slab Thickness on the CT Detection of Pulmonary Nodules: Use of Sliding Thin-Slab Maximum Intensity Projection and Volume Rendering. Am. J. Roentgenol. 2009, 192, 1324–1329. [Google Scholar] [CrossRef]
- Fujii, S.; Matsusue, E.; Kanasaki, Y.; Kanamori, Y.; Nakanishi, J.; Sugihara, S.; Kigawa, J.; Terakawa, N.; Ogawa, T. Detection of peritoneal dissemination in gynecological malignancy: Evaluation by diffusion-weighted MR imaging. Eur. Radiol. 2008, 18, 18–23. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Yao, D.; Chen, J.; Liu, Y.; Li, W.; Shi, Y. 2d–3d Hierarchical Feature Fusion Network For Segmentation Of Bone Structure In Knee Mr Image. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 575–578. [Google Scholar]
- Jadhav, S.; Deng, G.; Zawin, M.; Kaufman, A.E. COVID-view: Diagnosis of COVID-19 using Chest CT. IEEE Trans. Vis. Comput. Graph. 2021. [CrossRef] [PubMed]
- Yousefirizi, F.; Martineau, P.; Uribe, C.; Rahmim, A. Enhancement of conventional segmentation techniques to achieve deep framework performance for lymphoma lesion segmentation in PET images. J. Nucl. Med. 2021, 62 (Suppl. 1), 1427. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2818–2826. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 652–660. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 558–567. [Google Scholar]
- Isensee, F.; Petersen, J.; Klein, A.; Zimmerer, D.; Jaeger, P.F.; Kohl, S.; Wasserthal, J.; Koehler, G.; Norajitra, T.; Wirkert, S. Nnu-net: Self-adapting framework for u-net-based medical image segmentation. arXiv 2018, arXiv:1809.10486. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| λ | DSC | Recall | Specificity | Precision |
|---|---|---|---|---|
| 0.15 | 92.40 | 86.34 | 99.96 | 92.82 |
| 0.25 | 93.84 | 91.35 | 99.96 | 93.92 |
| 0.35 | 93.68 | 88.60 | 99.96 | 93.86 |
| ... | ... | ... | ... | ... |
| 0.90 | 68.02 | 70.22 | 99.86 | 75.35 |
| Network | DSC | Recall | Specificity | Precision |
|---|---|---|---|---|
| VesselNet [22] | 73.29 | 72.51 | 99.92 | 75.36 |
| DeepVessel [18] | 82.61 | 81.49 | 99.94 | 84.26 |
| DeepVesselNet [21] | 84.59 | 82.62 | 99.94 | 85.18 |
| 2D U-Net [27] | 87.48 | 85.31 | 99.94 | 89.54 |
| 3D U-Net [20] | 90.43 | 88.60 | 99.96 | 90.49 |
| JointVesselNet [23] | 92.82 | 90.13 | 99.96 | 92.95 |
| Ours | 93.84 | 91.35 | 99.96 | 93.92 |
| Network | AttentionMechanism | Loss Function | Dice (%) |
|---|---|---|---|
| 3D U-Net | Without attention | Dice Loss | 93.63 |
| Tversky Loss | 92.15 | ||
| Focal Tversky Loss | 93.06 | ||
| With attention | Dice Loss | 93.69 | |
| Tversky Loss | 92.25 | ||
| Focal Tversky Loss | 93.43 | ||
| 3D U-Net (Inception block) | Without attention | Dice Loss | 93.67 |
| Tversky Loss | 92.65 | ||
| Focal Tversky Loss | 93.77 | ||
| With attention | Dice Loss | 93.71 | |
| Tversky Loss | 93.78 | ||
| Focal Tversky Loss | 93.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Kwak, H.-S.; Oh, I.-S. Cerebrovascular Segmentation Model Based on Spatial Attention-Guided 3D Inception U-Net with Multi-Directional MIPs. Appl. Sci. 2022, 12, 2288. https://doi.org/10.3390/app12052288
Liu Y, Kwak H-S, Oh I-S. Cerebrovascular Segmentation Model Based on Spatial Attention-Guided 3D Inception U-Net with Multi-Directional MIPs. Applied Sciences. 2022; 12(5):2288. https://doi.org/10.3390/app12052288
Chicago/Turabian StyleLiu, Yongwei, Hyo-Sung Kwak, and Il-Seok Oh. 2022. "Cerebrovascular Segmentation Model Based on Spatial Attention-Guided 3D Inception U-Net with Multi-Directional MIPs" Applied Sciences 12, no. 5: 2288. https://doi.org/10.3390/app12052288