
oneM2M-Enabled Prediction of High Particulate Matter Data Based on Multi-Dense Layer BiLSTM Model


Abstract
:1. Introduction
- We used the hardware architecture, based on oneM2M technology, to achieve IoT system compatibility in the semiconductor factory cleanroom;
- We showed that our Multi-Dense Layer BiLSTM model can accurately forecast PM2.5 from multi-size PM concentration datasets (PM0.3, PM0.5, PM1, PM2.5, PM5, and PM10);
- We created a system with a small number of parameters, making it computationally efficient, potent, and stable;
- Our findings revealed that the Multi-Dense Layer BiLSTM approach yields the lowest error when compared to the RNN, LSTM, CNN-LSTM, and Single-Dense Layer BiLSTM methods.
2. System Overview
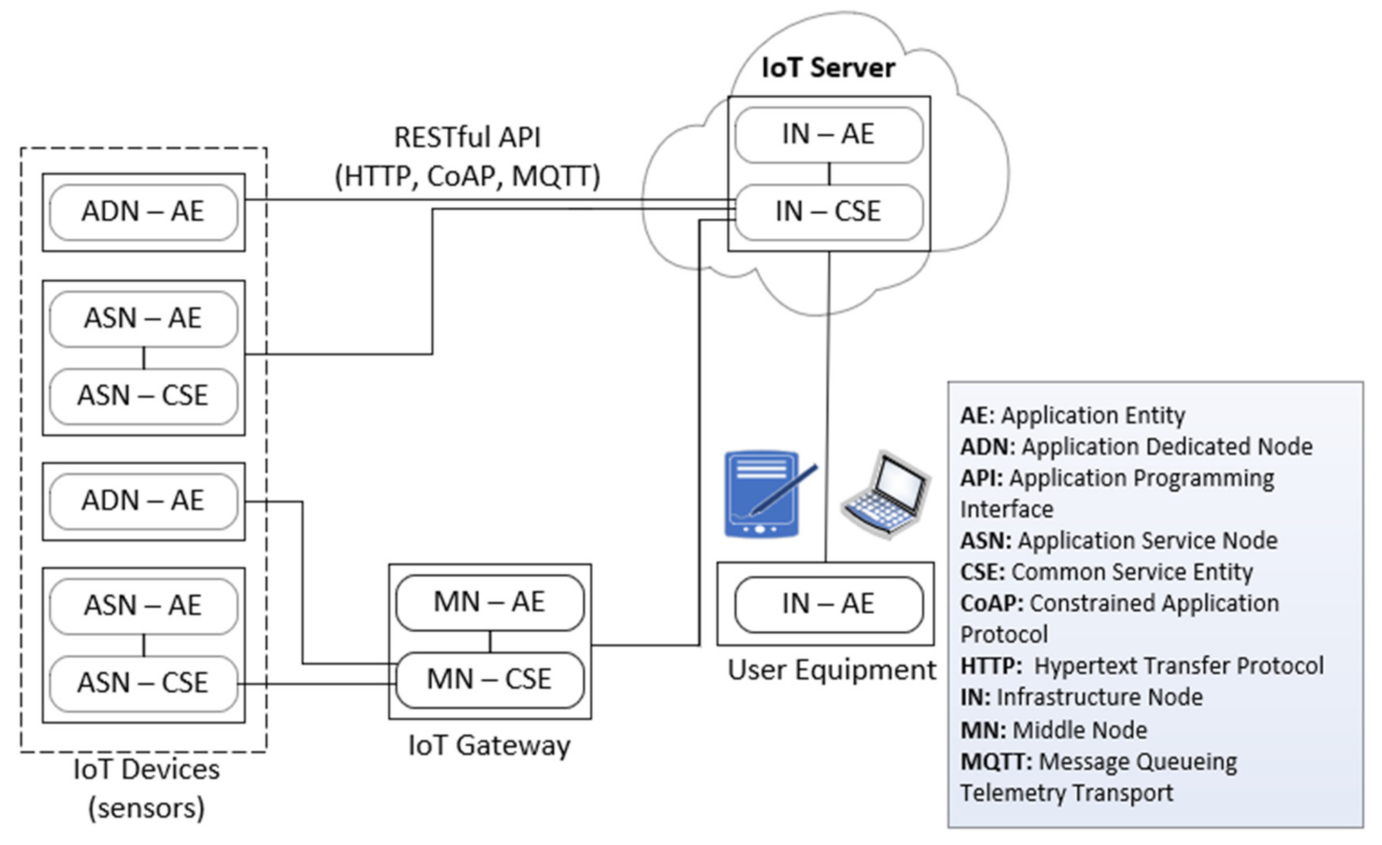
2.1. Communication Interface
2.2. oneM2M Technology Standard
3. Methodology
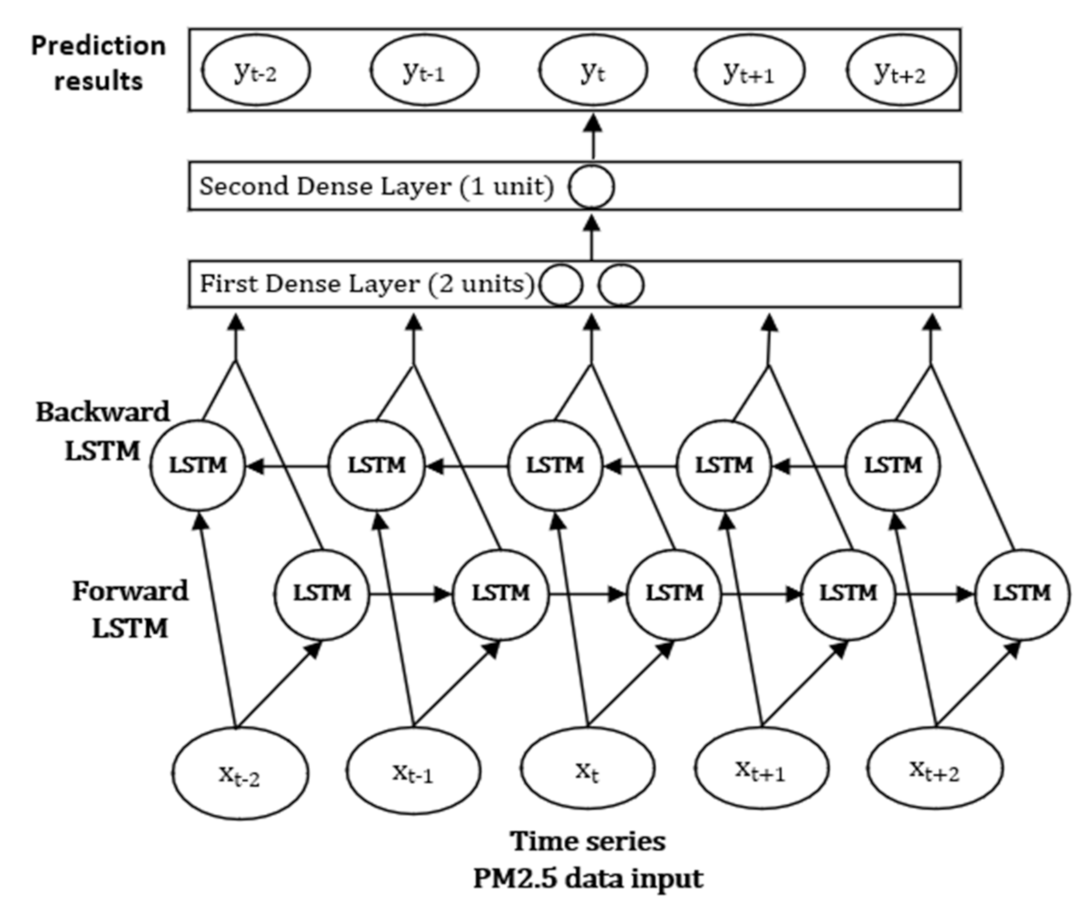
3.1. Multi-Dense Layer BiLSTM
3.2. Sigmoid Activation Function
4. Experimental Setup
4.1. Dataset and Preprocessing
4.2. Hyperparameters Setting
4.3. Performance Criteria
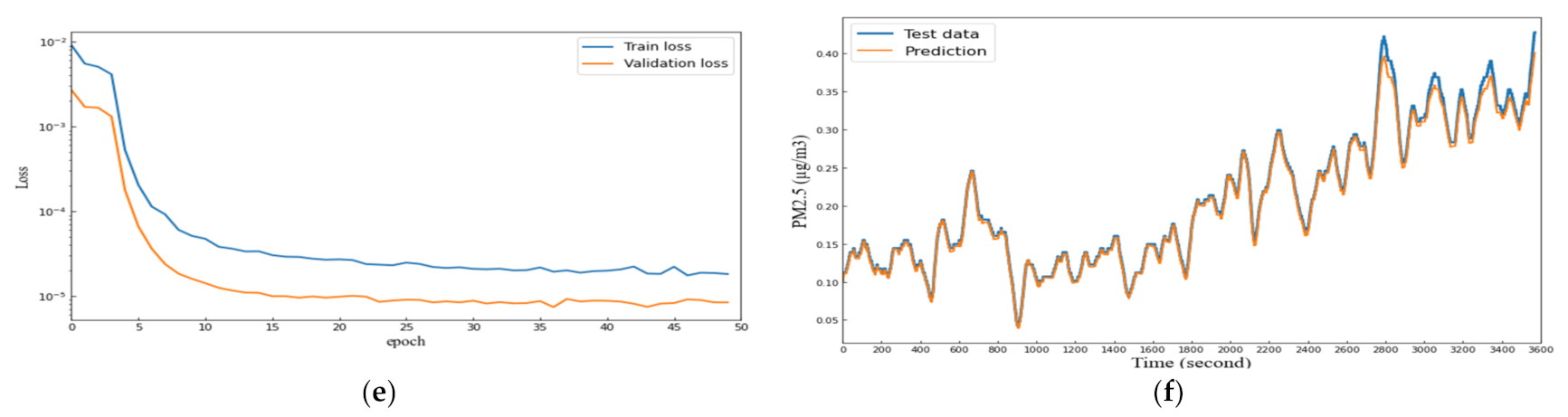
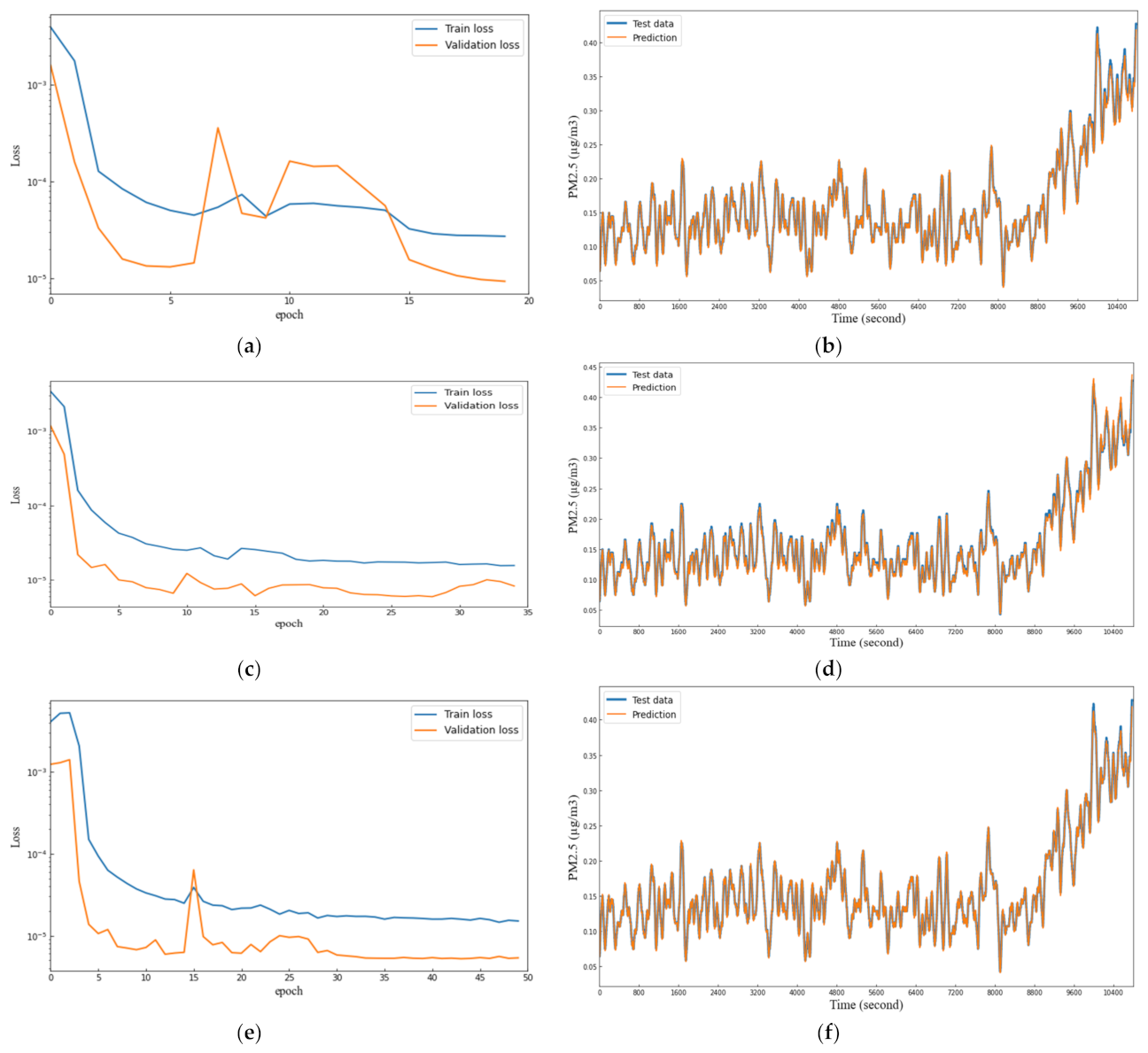
5. Result and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADAM | Adaptive Momentum Estimation |
| ADN | Application Dedicated Nodes |
| AE | Application Entity |
| ANN | Artificial Neural Network |
| API | Application Programming Interface |
| ASN | Application Service Node |
| BiLSTM | Bidirectional Long Short-Term Memory |
| BPTT | Backpropagation Through Time |
| CMAQ | Community Multiscale Air Quality |
| CNN-LSTM | Convolutional Neural Network—Long Short-Term Memory |
| CONVLSTM2D | Convolutional Long Short-Term Memory Two-Dimensional |
| CPS | Cyber-Physical System |
| DL | Deep Learning |
| IN | Infrastructure Node |
| HVAC | Heating Ventilation and Air Conditioning |
| IoT | Internet of Things |
| JSON | JavaScript Object Notation |
| LSTM | Long Short-Term Memory |
| M2M | Machine to machine |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| ML | Machine Learning |
| MN | Middle Node |
| MQTT | Message Queue Telemetry Transport |
| MSE | Mean Square Error |
| PM | Particulate Matter |
| PM0.3 | Particulate Matter of 0.3 µm |
| PM0.5 | Particulate Matter of 0.5 µm |
| PM1.0 | Particulate Matter of 1.0 µm |
| PM2.5 | Particulate Matter of 2.5 µm |
| PM5 | Particulate Matter of 5 µm |
| PM10 | Particulate Matter of 10 µm |
| RDBMS | Relational Database Management System |
| REST | Representational State Transfer |
| RNN | Recurrent Neural Network |
| RTU | Remote Terminal Unit |
Appendix A


References
- Park, S.H.; Kim, S.; Baek, J.G. Kernel-Density-Based Particle Defect Management for Semiconductor Manufacturing Facilities. Appl. Sci. 2018, 8, 224. [Google Scholar] [CrossRef] [Green Version]
- Choi, K.-M. Airborne PM2.5 Characteristics in Semiconductor Manufacturing Facilities. AIMS Environ. Sci. 2018, 5, 216–228. [Google Scholar] [CrossRef]
- Prihatno, A.T.; Nurcahyanto, H.; Ahmed, M.F.; Rahman, M.H.; Alam, M.M.; Jang, Y.M. Forecasting PM2.5 Concentration Using a Single-Dense Layer Bilstm Method. Electronics 2021, 10, 1808. [Google Scholar] [CrossRef]
- Wali, F.; Knotter, D.M.; Kuper, F.G. Impact OfNano Particles on Semiconductor Manufacturing. In Proceedings of the 2008 IEEE International Conference on Multi Topi, Karachi, Pakistan, 23–24 December 2008; pp. 97–99. [Google Scholar]
- The International Technology Roadmap for Semiconductors 2.0. Available online: https://www.semiconductors.org/wp-content/uploads/2018/06/4_2015-ITRS-2.0-ESH.pdf (accessed on 30 December 2021).
- Chang-Hoi, H.; Park, I.; Oh, H.R.; Gim, H.J.; Hur, S.K.; Kim, J.; Choi, D.R. Development of a PM2.5 Prediction Model Using a Recurrent Neural Network Algorithm for the Seoul Metropolitan Area, Republic of Korea. Atmos. Environ. 2021, 245, 118021. [Google Scholar] [CrossRef]
- Tsai, Y.T.; Zeng, Y.R.; Chang, Y.S. Air Pollution Forecasting using RNN with LSTM. In Proceedings of the 2018 IEEE 16th International Conference on Dependable, Autonomic and Secure Computing, 16th International Conference on Pervasive Intelligence and Computing, 4th International Conference on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; pp. 1068–1073. [Google Scholar]
- Park, J.; Chang, S. A Particulate Matter Concentration Prediction Model Based on Long Short-Term Memory and an Artificial Neural Network. Int. J. Environ. Res. Public Health 2021, 18, 6801. [Google Scholar] [CrossRef]
- Huang, C.J.; Kuo, P.H. A Deep Cnn-Lstm Model for Particulate Matter (Pm2.5) Forecasting in Smart Cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Hua, M.; Wu, X.U. A Hybrid CNN-LSTM Model for Forecasting Particulate Matter (PM2.5). IEEE Access 2020, 26933–26940. [Google Scholar] [CrossRef]
- Seong, N. Deep Spatiotemporal Attention Network for Fine Particle Matter 2.5 Concentration Prediction with Causality Analysis. IEEE Access 2021, 9, 73230–73239. [Google Scholar] [CrossRef]
- Castelli, M.; Clemente, F.M.; Popovič, A.; Silva, S.; Vanneschi, L. A Machine Learning Approach to Predict Air Quality in California. Complexity 2020, 2020, 8049504. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, H.; Zhao, G.; Lian, J. Constructing a PM2.5 Concentration Prediction Model by Combining Auto-Encoder with Bi-LSTM Neural Networks. Environ. Model. Softw. 2020, 124, 104600. [Google Scholar] [CrossRef]
- Wu, J.; Tian, K.; Dong, Q.; Sun, L.; Zhang, L.; Liu, X. A Low Voltage Low Power Adaptive Transceiver for Twisted-Pair Cable Communication. IEEE Trans. Nucl. Sci. 2015, 62, 3140–3147. [Google Scholar] [CrossRef]
- Seneca. The Advantages of ModBUS RTU Protocol. Available online: https://blog.seneca.it/en/the-advantages-of-modbus-rtu-protocol/ (accessed on 30 December 2021).
- Prihatno, A.T. Artificial Intelligence Platform Based for Smart Factory. In Proceedings of the Korea Artificial Intelligence Conference, online, South Korea, 16–18 December 2020; pp. 1–2. [Google Scholar]
- Figueredo, K. Building a Flexible Standard to Deliver a Thriving IoT Ecosystem. IEEE Commun. Stand. Mag. 2020, 4, 10–11. [Google Scholar]
- oneM2M. Partners Benefits of oneM2M. Available online: https://www.onem2m.org/using-onem2m/what-is-onem2m (accessed on 12 November 2021).
- Yun, J.; Woo, J. IoT-Enabled Particulate Matter Monitoring and Forecasting Method Based on Cluster Analysis. IEEE Internet Things J. 2021, 8, 7380–7393. [Google Scholar] [CrossRef]
- Prihatno, A.T.; Nurcahyanto, H.; Jang, Y.M. Smart Factory Based on IoT Platform. In Proceedings of the KIC Summer Conference, online, Belgium, 22–23 October 2020; pp. 2–4. [Google Scholar]
- Zhao, R.; Wang, L.; Zhang, X.; Zhang, Y.; Wang, L.; Peng, H. A oneM2M-Compliant Stacked Middleware Promoting IoT Research and Development. IEEE Access 2018, 6, 63546–63559. [Google Scholar] [CrossRef]
- Xu, S.S.D.; Chen, C.H.; Chang, T.C. Design of oneM2M-Based Fog Computing Architecture. IEEE Internet Things J. 2019, 6, 9464–9474. [Google Scholar] [CrossRef]
- Shabanian, S.; Arpit, D.; Trischler, A.; Bengio, Y. Variational Bi-LSTMs. arXiv 2017, arXiv:1711.05717. [Google Scholar]
- Shah, S.R.B.; Chadha, G.S.; Schwung, A.; Ding, S.X. A Sequence-to-Sequence Approach for Remaining Useful Lifetime Estimation Using Attention-Augmented Bidirectional LSTM. Intell. Syst. Appl. 2021, 10–11, 200049. [Google Scholar] [CrossRef]
- Li, Y.H.; Harfiya, L.N.; Purwandari, K.; Lin, Y. Der Real-Time Cuffless Continuous Blood Pressure Estimation Using Deep Learning Model. Sensors 2020, 20, 5606. [Google Scholar] [CrossRef]
- Rampurawala, M. Classification with TensorFlow and Dense Neural Networks. Available online: https://heartbeat.fritz.ai/classification-with-tensorflow-and-dense-neural-networks-8299327a818a (accessed on 1 June 2021).
- Verma, Y. A Complete Understanding of Dense Layers in Neural Networks. Available online: https://analyticsindiamag.com/a-complete-understanding-of-dense-layers-in-neural-networks/] (accessed on 3 December 2021).
- Islam, M.N.; Sulaiman, N.; Al Farid, F.; Uddin, J.; Alyami, S.A.; Rashid, M.; Majeed, A.P.P.A.; Moni, M.A. Diagnosis of Hearing Deficiency Using EEG Based AEP Signals: CWT and Improved-VGG16 Pipeline. PeerJ Comput. Sci. 2021, 7, e638. [Google Scholar] [CrossRef]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of Trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Narayan, S. The Generalized Sigmoid Activation Function: Competitive Supervised Learning. Inf. Sci. 1997, 99, 69–82. [Google Scholar] [CrossRef]
- Noor, N.M.; Al Bakri Abdullah, M.M.; Yahaya, A.S.; Ramli, N.A. Comparison of Linear Interpolation Method and Mean Method to Replace the Missing Values in Environmental Data Set. Mater. Sci. Forum 2015, 803, 278–281. [Google Scholar] [CrossRef]
- Alaya, B.; Medjiah, S.; Monteil, T.; Drira, K.; Khalil, D. Towards Semantic Data Interoper-Ability in oneM2M Standard. IEEE Commun. Mag. Inst. Electr. Electron. Eng. 2015, 53, 35–41. [Google Scholar]
- Gao, X.; Li, W. A Graph-Based LSTM Model for PM2.5 Forecasting. Atmos. Pollut. Res. 2021, 12, 101150. [Google Scholar] [CrossRef]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation Between Training and Testing Sets: A Pedagogical Explanation. Dep. Tech. Rep. 2018, 2, 1–6. [Google Scholar]
- Lendave, V. A Guide to Different Evaluation Metrics for Time Series Forecasting Models. Available online: https://analyticsindiamag.com/a-guide-to-different-evaluation-metrics-for-time-series-forecasting-models/ (accessed on 30 December 2021).
- Bhuiya, S. Disadvantages of CNN Models. Available online: https://iq.opengenus.org/disadvantages-of-cnn/ (accessed on 30 December 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Input Variables | Unit |
|---|---|---|
| Temperature | TEMP | °C |
| Humidity | HUMID | %RH |
| Air pollutant variables | PM0.3 | µg/m3 |
| Air pollutant variables | PM0.5 | µg/m3 |
| Air pollutant variables | PM1 | µg/m3 |
| Air pollutant variables | PM2.5 | µg/m3 |
| Air pollutant variables | PM5 | µg/m3 |
| Air pollutant variables | PM10 | µg/m3 |
| Hyperparameter | RNN | LSTM | CNN-LSTM | Single-Dense Layer BiLSTM | Multi-Dense Layer BiLSTM |
|---|---|---|---|---|---|
| Model nodes | 2 RNN nodes | 64 LSTM nodes | 128 LSTM nodes | 64 BiLSTM nodes | 64 BiLSTM nodes |
| Epoch | 20/35/50 | 20/35/50 | 20/35/50 | 20/35/50 | 20/35/50 |
| Batch size | 16 | 64 | 16 | 16 | 16 |
| Interpolate method | linear | linear | N/A | linear | linear |
| Train data (% dataset) | 64 | 64% | 64% | 80% | 80% |
| Validation data (% dataset) | 16% | 16% | 16% | N/A | N/A |
| Test data (% dataset) | 20% | 20% | 20% | 20% | 20% |
| Optimizer | ADAM | SGD | ADAM | ADAM | ADAM |
| Activation | Linear | Linear | ReLU | Linear | Sigmoid |
| Learning rate | 0.01 | 0.01 | 0.001 | 0.001 | 0.001 |
| Dense layer | N/A | N/A | 3 | 1 | 2 |
| Model | Prediction Time Length | MSE | MAE | MAPE | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 20 Epoch | 35 Epoch | 50 Epoch | 20 Epoch | 35 Epoch | 50 Epoch | 20 Epoch | 35 Epoch | 50 Epoch | ||
| RNN | 1 h | 0.1072 | 0.1141 | 0.1001 | 0.2415 | 0.2371 | 0.2199 | 29.8106 | 31.0264 | 27.7334 |
| 2 h | 0.1012 | 0.1138 | 0.1165 | 0.1778 | 0.1986 | 0.2097 | 23.89 | 27.4217 | 29.8114 | |
| 3 h | 0.0833 | 0.0908 | 0.072 | 0.2501 | 0.2337 | 0.2132 | 54.1121 | 56.2735 | 52.1554 | |
| LSTM | 1 h | 0.0058 | 0.0048 | 0.0045 | 0.0626 | 0.0548 | 0.055 | 11.4597 | 8.8899 | 9.1937 |
| 2 h | 0.0187 | 0.0771 | 0.0217 | 0.125 | 0.1985 | 0.1325 | 25.617 | 68.8899 | 27.6512 | |
| 3 h | 0.0619 | 0.0724 | 0.066 | 0.1703 | 0.2023 | 0.1765 | 60.5662 | 67.6347 | 63.2913 | |
| CNN-LSTM | 1 h | 5.838 | 3.907 | 3.69 | 2.305 | 1.706 | 1.676 | 6.061 | 3.613 | 4.332 |
| 2 h | 3.871 | 3.992 | 3.871 | 1.659 | 1.739 | 1.659 | 4.864 | 4.948 | 4.864 | |
| 3 h | 8.434 | 8.434 | 8.434 | 2.598 | 2.598 | 2.598 | 7.64 | 7.64 | 7.64 | |
| Single-Dense Layer BiLSTM | 1 h | 0.0016 | 0.0017 | 0.0016 | 0.0029 | 0.0034 | 0.3266 | 0.3385 | 0.3434 | 0.3047 |
| 2 h | 0.0015 | 0.0027 | 0.0014 | 0.318 | 0.0042 | 0.3105 | 0.3046 | 0.4193 | 0.2814 | |
| 3 h | 0.0053 | 0.0047 | 0.0063 | 0.0067 | 0.0064 | 0.0073 | 0.673 | 0.6433 | 0.7322 | |
| Multi-Dense Layer BiLSTM | 1 h | 0.0009 | 0.0014 | 0.0011 | 0.0023 | 0.0028 | 0.0027 | 0.2258 | 0.2849 | 0.2701 |
| 2 h | 0.0014 | 0.0008 | 0.0009 | 0.0027 | 0.002 | 0.0021 | 0.2713 | 0.1991 | 0.2058 | |
| 3 h | 0.001 | 0.0018 | 0.0006 | 0.0022 | 0.0035 | 0.0019 | 0.223 | 0.3507 | 0.1873 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prihatno, A.T.; Utama, I.B.K.Y.; Jang, Y.M. oneM2M-Enabled Prediction of High Particulate Matter Data Based on Multi-Dense Layer BiLSTM Model. Appl. Sci. 2022, 12, 2260. https://doi.org/10.3390/app12042260
Prihatno AT, Utama IBKY, Jang YM. oneM2M-Enabled Prediction of High Particulate Matter Data Based on Multi-Dense Layer BiLSTM Model. Applied Sciences. 2022; 12(4):2260. https://doi.org/10.3390/app12042260
Chicago/Turabian StylePrihatno, Aji Teguh, Ida Bagus Krishna Yoga Utama, and Yeong Min Jang. 2022. "oneM2M-Enabled Prediction of High Particulate Matter Data Based on Multi-Dense Layer BiLSTM Model" Applied Sciences 12, no. 4: 2260. https://doi.org/10.3390/app12042260