
DeepProfile: Accurate Under-the-Clothes Body Profile Estimation


Abstract
:1. Introduction
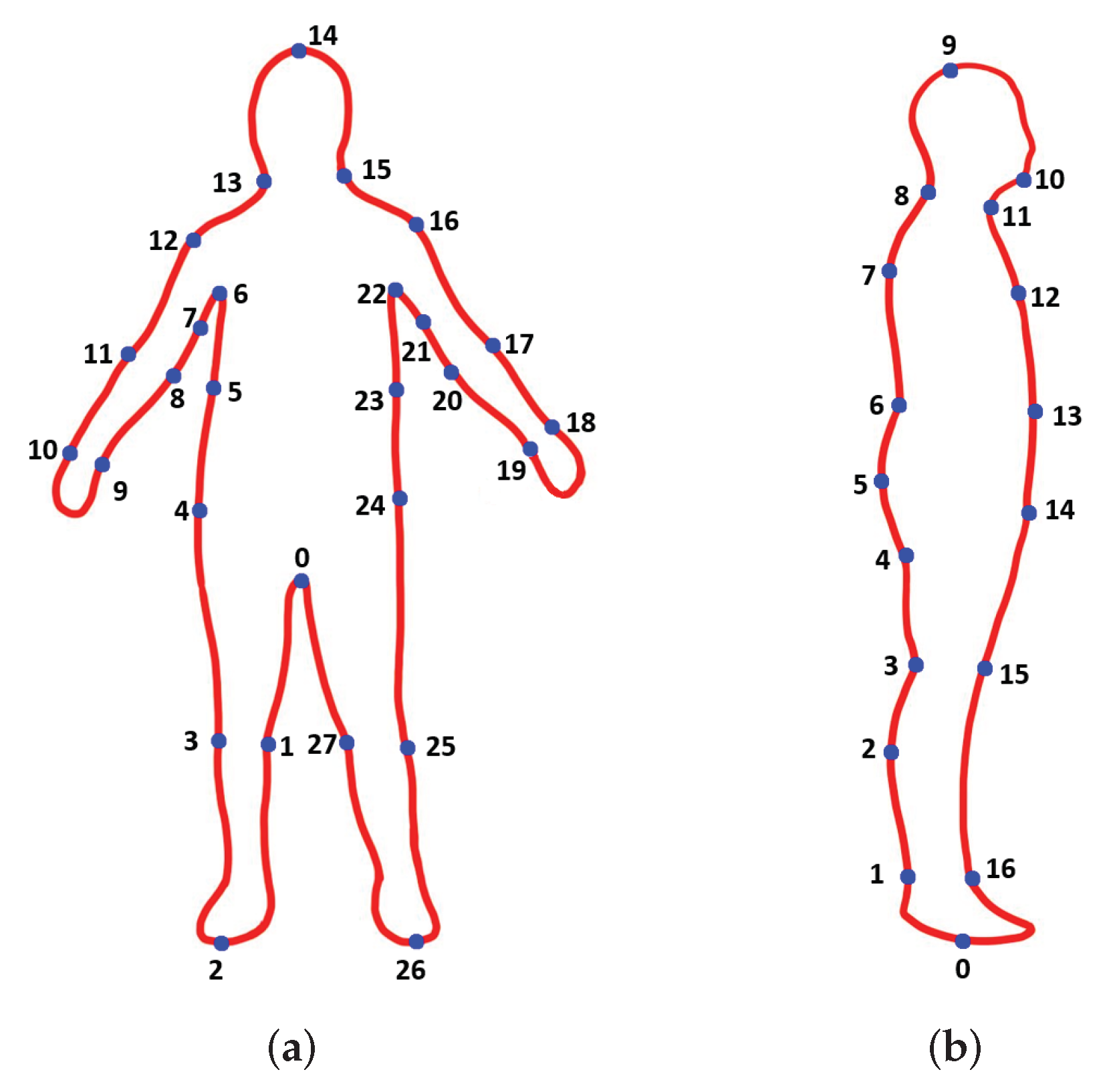
- We constructed an under-the-clothes contour keypoint dataset including a total of 9016 different persons, each person having one front-view image and one side-view image. There were, in total, 45 contour keypoints, 28 for the front view and 17 for the side view. We trained a separate model for each view.
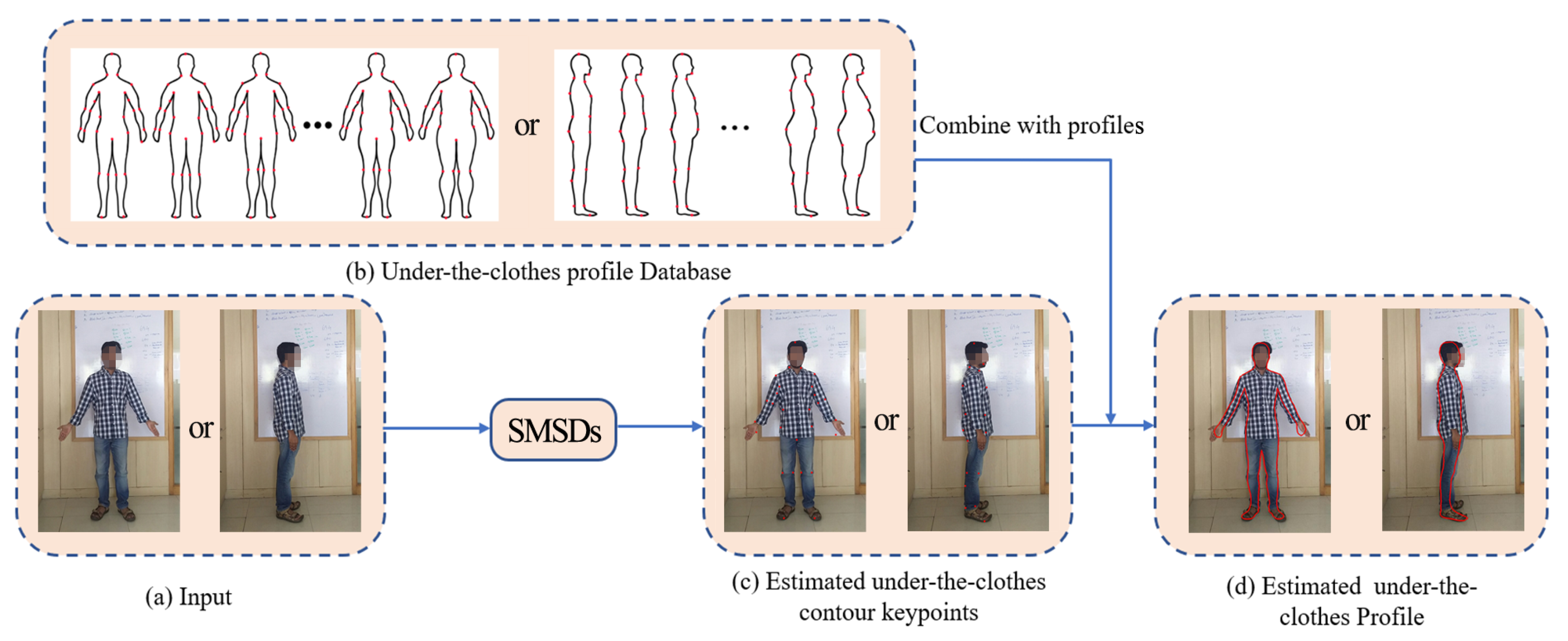
- We put forward DeepProfile, an effective method to estimate accurate under-the-clothes human body profiles, which is generated by contour keypoints extracted from images. Compared with image segmentation methods, it reduced data labeling time and cost by requiring only several contour keypoints to be labeled.
- We applied our body profiles in two scenarios, including accurate 3D human model construction and body size measurement. The 3D human model was generated from front-view and side-view under-the-clothes profiles and the body size measurement results satisfy the criteria of the clothing industry.
2. Related Works
2.1. Image-Based Human Segmentation
2.2. Three-Dimensional Body Shape Estimation
2.3. Keypoint Detection Techniques
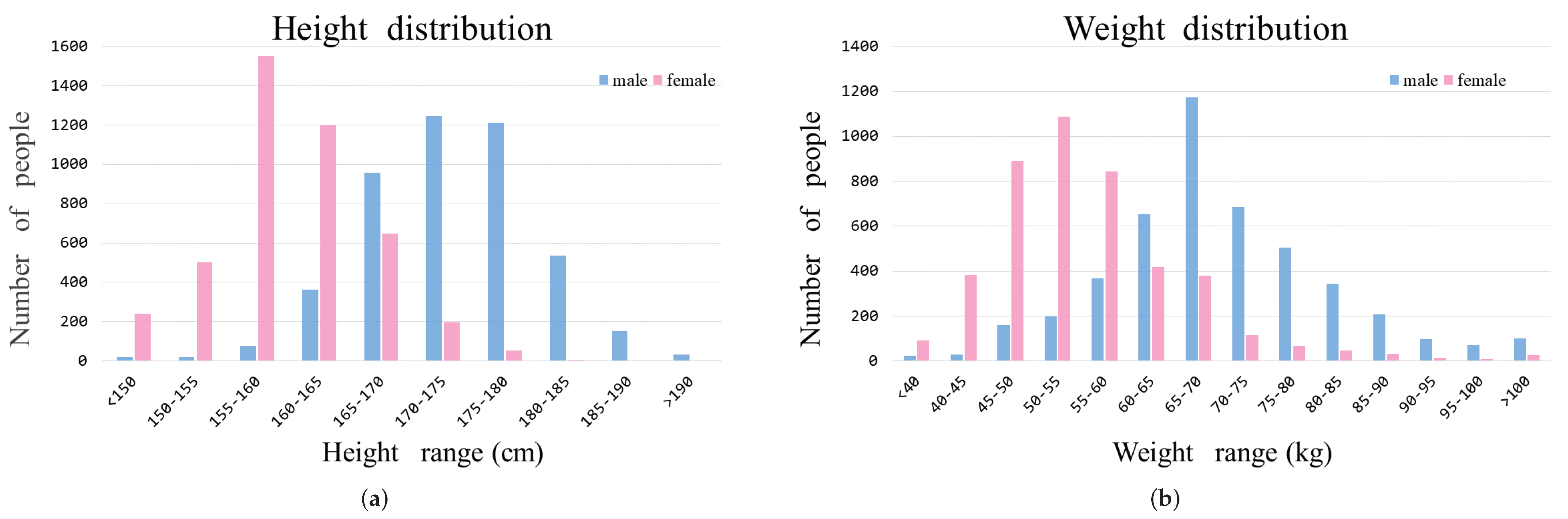
3. Dataset
4. Our Approach
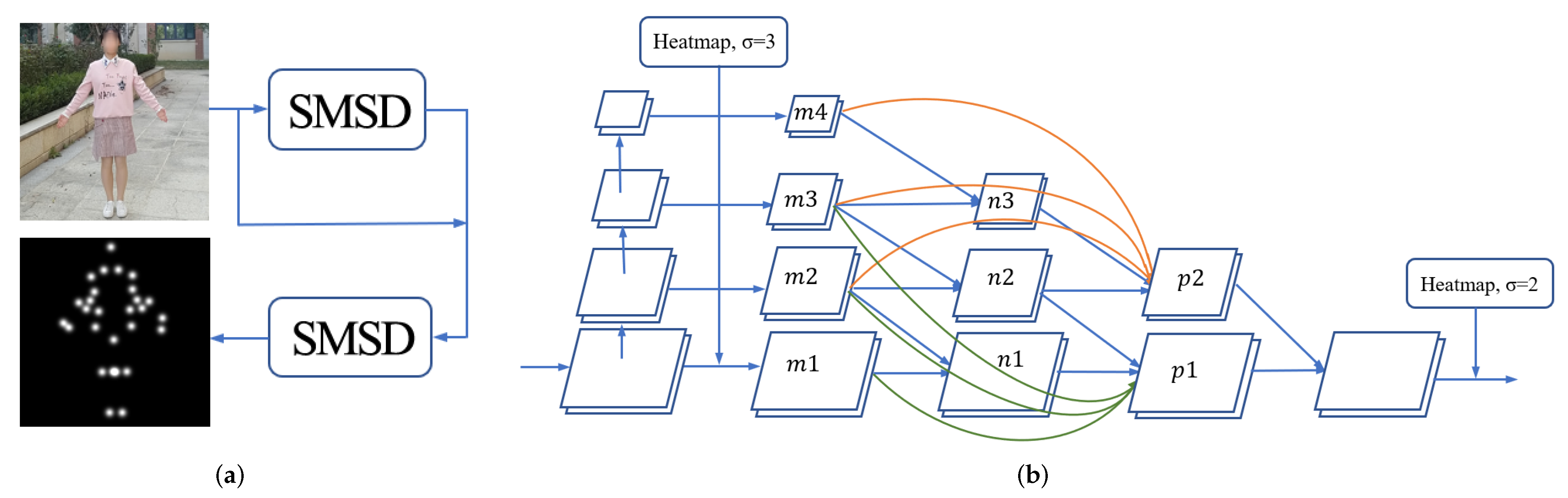
4.1. Contour Keypoint Extraction
- In general, a smaller resolution feature has a larger receptive field and a larger resolution feature has a smaller receptive field but keeps more details. In order to take advantage of different resolution features, we upsample with nearest neighbor sampling and add it to to generate new features, . We then repeat the process with (, ) and (, ) to generate features and , respectively.
- With the input of , and , two features of and are produced by using the same operation in step 1. Unlike FPN [41], which directly upsamples the high-level features and combines them with the low-level features, we add dense connections from , , and to and . These short-skip connections not only strengthen the information flow in our network, but also strengthen the back propagation between the loss function and current features, which makes our network easy to train.
- Finally, we fuse two features, and , to obtain the heatmaps of the first SMSD block.
4.2. Profile Estimation from Contour Keypoints
5. Experimental Results and Discussions
5.1. Data Preprocessing and Evaluation of Contour Keypoints
5.2. Training and Comparison for Contour Keypoints
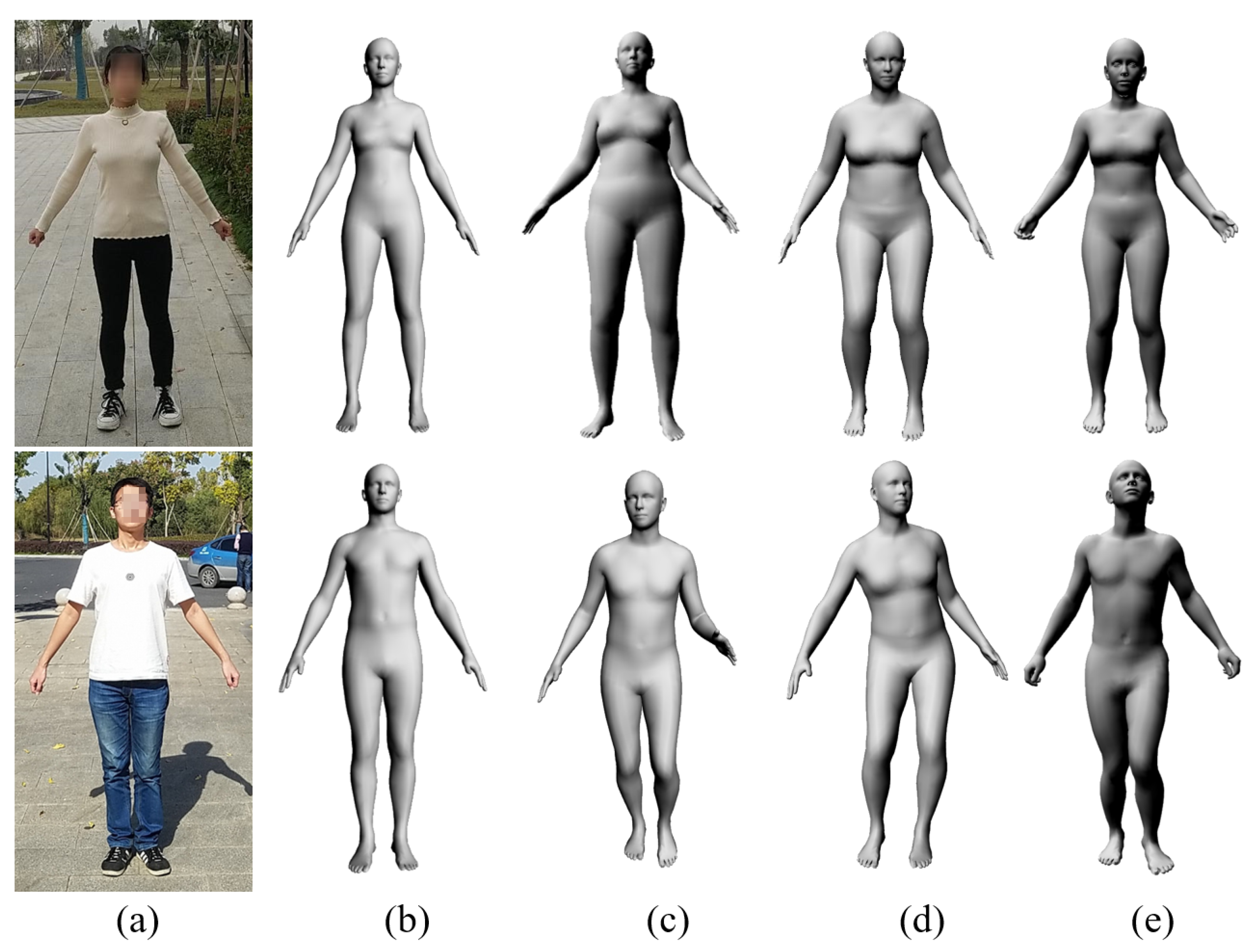
5.3. Body Profile Results
6. Body Profile Applications
- (1)
- Extract the cross-sectional 2D size features from the subject’s profiles estimated in Section 4;
- (2)
- Predict 3D shape features from 2D size features for each layer, which is based on relationship models pre-learned between 2D size features and cross-sectional 3D shape features from a large scale of real human scanned models;
- (3)
- A template model is then deformed with the predicted cross-sectional 3D shapes.
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ruan, T.; Liu, T.; Huang, Z.; Wei, Y.; Wei, S.; Zhao, Y. Devil in the details: Towards accurate single and multiple human parsing. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 17 July 2019; Volume 33, pp. 4814–4821. [Google Scholar]
- Liang, X.; Gong, K.; Shen, X.; Lin, L. Look into person: Joint body parsing & pose estimation network and a new benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 4, 871–885. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Huang, G.; Chen, D.; Li, T.; Wu, F.; van der Maaten, L.; Weinberger, K.Q. Multi-scale dense networks for resource efficient image classification. arXiv 2017, arXiv:1703.09844. [Google Scholar]
- Zhu, S.; Mok, P.Y. Predicting realistic and precise human body models under clothing based on orthogonal-view photos. Procedia Manuf. 2015, 3, 3812–3819. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5228–5237. [Google Scholar]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Boudiaf, M.; Kervadec, H.; Masud, Z.I.; Piantanida, P.; Ayed, I.B.; Dolz, J. Few-Shot Segmentation Without Meta-Learning: A Good Transductive Inference Is All You Need? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13974–13983. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.-M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4002–4011. [Google Scholar]
- Yamaguchi, K.; Kiapour, M.H.; Ortiz, L.E.; Berg, T.L. Parsing clothing in fashion photographs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3570–3577. [Google Scholar]
- Dong, J.; Chen, Q.; Shen, X.; Yang, J.; Yan, S. Towards Unified Human Parsing and Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 843–850. [Google Scholar]
- Liu, S.; Liang, X.; Liu, L.; Shen, X.; Yang, J.; Xu, C.; Lin, L.; Cao, X.; Yan, S. Matching-CNN meets KNN: Quasi-parametric human parsing. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1419–1427. [Google Scholar]
- Tripathi, S.; Collins, M.; Brown, M.; Belongie, S. Pose2instance: Harnessing keypoints for person instance segmentation. arXiv 2017, arXiv:1704.01152. [Google Scholar]
- Papandreou, G.; Zhu, T.; Chen, L.C.; Gidaris, S.; Tompson, J.; Murphy, K. PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 282–299. [Google Scholar]
- Zhang, S.H.; Li, R.; Dong, X.; Rosin, P.; Cai, Z.; Han, X.; Yang, D.; Huang, H.; Hu, S.M. Pose2Seg: Detection Free Human Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 889–898. [Google Scholar]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-end recovery of human shape and pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7122–7131. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Güler, R.A.; Neverova, N.; Kokkinos, I. DensePose: Dense Human Pose Estimation in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7297–7306. [Google Scholar]
- Omran, M.; Lassner, C.; Pons-Moll, G.; Gehler, P.; Schiele, B. Neural body fitting: Unifying deep learning and model based human pose and shape estimation. In Proceedings of the 2018 International Conference on 3D Vision, Verona, Italy, 5–8 September 2018; pp. 484–494. [Google Scholar]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.; Tzionas, D.; Black, M.J. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10967–10977. [Google Scholar]
- Bogo, F.; Kanazawa, A.; Lassner, C.; Gehler, P.; Romero, J.; Black, M.J. Keep It SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 561–578. [Google Scholar]
- Bălan, A.O.; Black, M.J. The Naked Truth: Estimating Body Shape Under Clothing. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2016; pp. 15–29. [Google Scholar]
- Wuhrer, S.; Pishchulin, L.; Brunton, A.; Shu, C.; Lang, J. Estimation of human body shape and posture under clothing. Comput. Vis. Image Underst. 2021, 17, 3793–3802. [Google Scholar] [CrossRef] [Green Version]
- Hu, P.; Kaashki, N.N.; Dadarlat, V.; Munteanu, A. Learning to Estimate the Body Shape Under Clothing From a Single 3-D Scan. IEEE Trans. Ind. Informatics 2021, 17, 3793–3802. [Google Scholar] [CrossRef]
- Streuber, S.; Quiros-Ramirez, M.A.; Hill, M.Q.; Hahn, C.A.; Zuffi, S.; O’Toole, A.; Black, M.J. Body talk: Crowdshaping realistic 3D avatars with words. Acm Trans. Graph. 2016, 35, 1–14. [Google Scholar] [CrossRef]
- Shigeki, Y.; Okura, F.; Mitsugami, I.; Yagi, Y. Estimating 3D human shape under clothing from a single RGB image. Ipsj Trans. Comput. Vis. Appl. 2018, 10, 1–6. [Google Scholar] [CrossRef]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 472–487. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Nie, X.; Feng, J.; Zhang, J.; Yan, S. Single-stage multi-person pose machines. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6950–6959. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3711–3719. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Li, W.; Wang, Z.; Yin, B.; Peng, Q.; Du, Y.; Xiao, T.; Yu, G.; Lu, H.; Wei, Y.; Sun, J. Rethinking on multi-stage networks for human pose estimation. arXiv 2019, arXiv:1901.00148. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-Aware Coordinate Representation for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7091–7100. [Google Scholar]
- Geng, Z.; Sun, K.; Xiao, B.; Zhang, Z.; Wang, J. Bottom-Up Human Pose Estimation via Disentangled Keypoint Regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14671–14681. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arnab, A.; Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Larsson, M.; Kirillov, A.; Savchynskyy, B.; Rother, C.; Kahl, F.; Torr, P.H.S. Conditional random fields meet deep neural networks for semantic segmentation: Combining probabilistic graphical models with deep learning forstructured prediction. IEEE Signal Process. Mag. 2018, 35, 37–52. [Google Scholar] [CrossRef]
- Verma, D.; Gulati, K.; Goel, V.; Shah, R.R. Fashionist: Personalising outfit recommendation for cold-start scenarios. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 4527–4529. [Google Scholar]
- Sagar, D.; Garg, J.; Kansal, P.; Bhalla, S.; Shah, R.R.; Yu, Y. Pai-bpr: Personalized outfit recommendation scheme with attribute-wise interpretability. In Proceedings of the 2020 IEEE Sixth International Conference on Multimedia Big Data, New Delhi, India, 24–26 September 2020; pp. 221–230. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input Size | Orient | Params | ||||
|---|---|---|---|---|---|---|---|
| 8-stage Hourglass [33] | Front | ||||||
| CPN [36] | Front | ||||||
| SimpleBaseline [31] | Front | ||||||
| HRNet [38] | Front | ||||||
| MSPN [37] | Front | ||||||
| DARK(HRNet-W32) [39] | Front | ||||||
| DEKR(HRNet-W32) [40] | Front | ||||||
| Ours | Front | 79.42 | |||||
| 8-stage Hourglass [33] | Side | ||||||
| CPN [36] | Side | ||||||
| SimpleBaseline [31] | Side | ||||||
| HRNet [38] | Side | ||||||
| MSPN [37] | Side | ||||||
| DARK(HRNet-W32) [39] | Side | ||||||
| DEKR(HRNet-W32) [40] | Side | ||||||
| Ours | Side |
| Method | mAP/Front | mAP/Side |
|---|---|---|
| Res2Net-50 [43] | ||
| 1 SMSD w/o dense | ||
| 1 SMSD w/ dense | ||
| 2 SMSDs w/ dense | ||
| 3 SMSDs w/ dense |
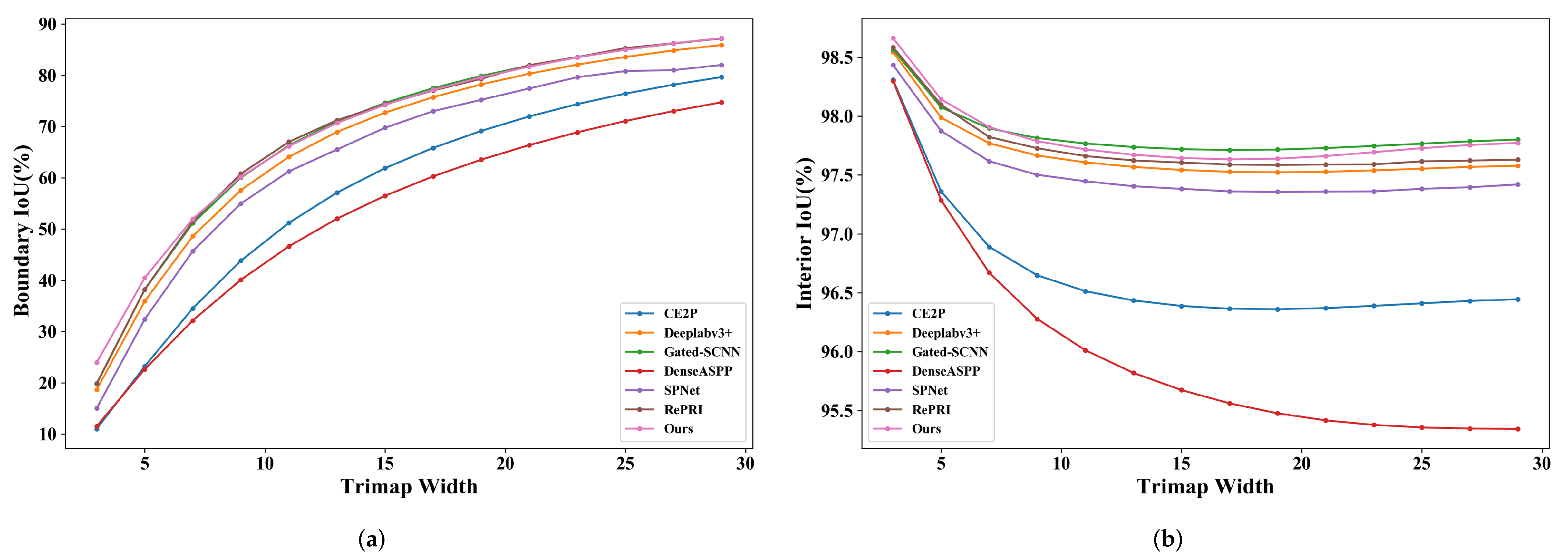
| Method | Backbone | Pixel Acc | mIoU | dis |
|---|---|---|---|---|
| DenseASPP [9] | DenseNet121 | 6.193 | ||
| Gated-SCNN [10] | ResNet101 | 2.676 | ||
| SPNet [13] | ResNet101 | 2.951 | ||
| CE2P [1] | ResNet50 | 3.02 | ||
| Deeplabv3+ [7] | ResNet50 | 2.656 | ||
| RePRI [12] | ResNet50 | 2.419 | ||
| Our method | ResNet50 | 2.362 |
| ID | Sex | Chest (Gt)/cm | Chest (Err)/cm | Abdominal (Gt)/cm | Abdominal (Err)/cm | Calf (Gt)/cm | Calf (Err)/cm |
|---|---|---|---|---|---|---|---|
| 1 | M | 83 | 75 | 38 | |||
| 2 | M | 89 | 83 | 37 | |||
| 3 | M | 87 | 80 | 34 | |||
| 4 | M | 101 | 104 | 42 | |||
| 5 | M | 93 | 83 | 37 | |||
| 6 | F | 82 | 67 | 32 | |||
| 7 | F | 83 | 62 | 29 | |||
| 8 | F | 80 | 66 | 32 | |||
| 9 | F | 80 | 72 | 33 | |||
| 10 | F | 86 | 82 | 35 | |||
| 11 | M | 89 | 84 | 38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, S.; Lu, F.; Shou, X.; Zhu, S. DeepProfile: Accurate Under-the-Clothes Body Profile Estimation. Appl. Sci. 2022, 12, 2220. https://doi.org/10.3390/app12042220
Lu S, Lu F, Shou X, Zhu S. DeepProfile: Accurate Under-the-Clothes Body Profile Estimation. Applied Sciences. 2022; 12(4):2220. https://doi.org/10.3390/app12042220
Chicago/Turabian StyleLu, Shufang, Funan Lu, Xufeng Shou, and Shuaiyin Zhu. 2022. "DeepProfile: Accurate Under-the-Clothes Body Profile Estimation" Applied Sciences 12, no. 4: 2220. https://doi.org/10.3390/app12042220