
Point Cloud Segmentation from iPhone-Based LiDAR Sensors Using the Tensor Feature

Abstract
:Featured Application
Abstract
1. Introduction
2. Related Works
- (1)
- Point cloud segmentation based on the geometric feature extraction.
- (2)
- Point cloud segmentation based on the deep-learning neural network
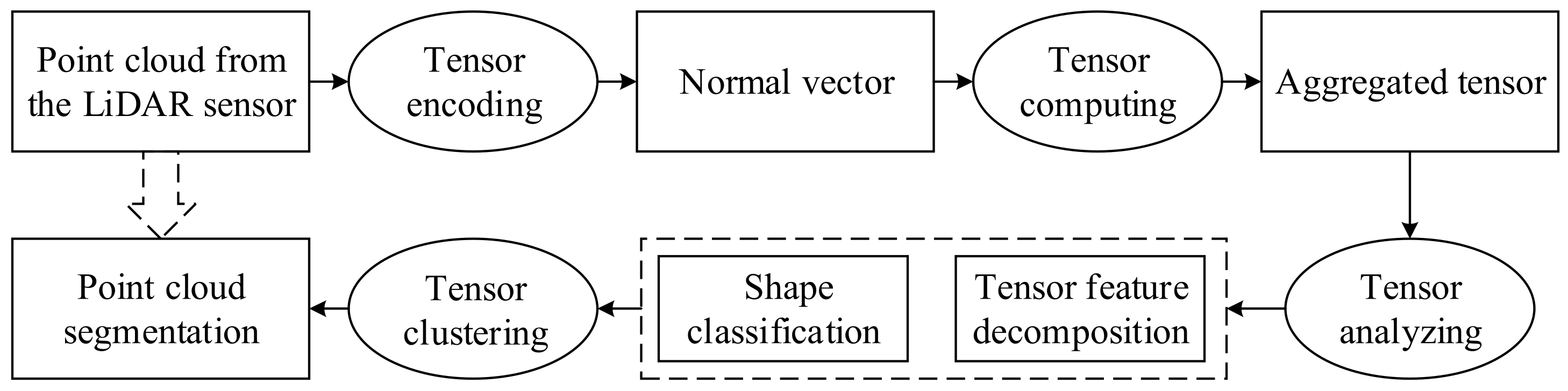
3. Methodology
- (1)
- normal vector computation based on the initial tensor encoding.
- (2)
- tensor aggregation from the tensor encoded with normal information.
- (3)
- tensor feature decomposition and shape classification by tensor analysis.
- (4)
- point cloud segmentation according to the tensor clustering.
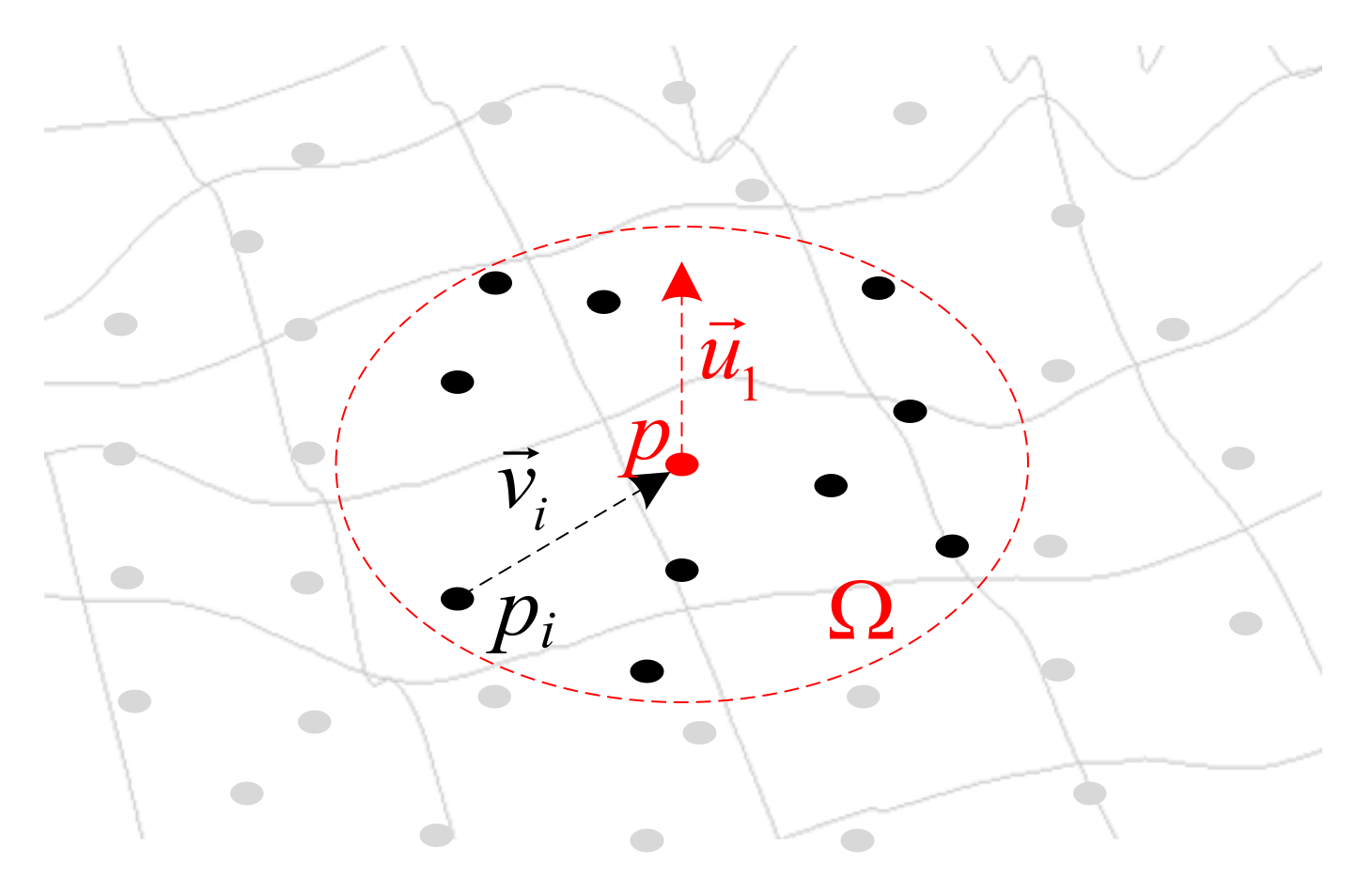
3.1. Normal Vector Computation Based on Initial Tensor Encoding
- (1)
- arbitrarily pick up a point pi from the neighborhood , and compute the vector from pi to p, as shown in Equation (2), then normalize the vector as .
- (2)
- compute the tensor Ti of tangent subspace SN-d using the Kronecker delta of in Equation (2), and obtain the normal subspace Sd, based on Equation (1).
- (3)
- gather the initial tensor from the neighborhood , using the weight function w based on the vector , as shown in Equation (4). The weight w is a Gaussian function .
- (4)
- calculate eigenvectors of the tensor T and choose the vector (as shown in Figure 2) with the largest eigenvalues as the normal vector of point p. Here p can be treated as a point in the surface, and is the 1-dimensional stick structure.
3.2. Tensor Aggregation Based on Normal Tensor Assembling
- (1)
- tensor representation in each dimension using normal information
- (2)
- geometric structure propagation based on tensor assembling
- (3)
- tensor aggregation of each dimensional structure from neighborhood
3.3. Tensor Feature Decomposition and Shape Classification Based on Tensor Analyzing
- (1)
- eigenvalues with descending order, i.e., referred to as the intensity of each eigenvector;
- (2)
- eigenvectors , i.e., referred to as the dimension of the normal space, which is orthogonal to the manifold structures of G.
- (1)
- the geometric structure with the 1-dimensional stick-shaped normal space, where there is just one normal vector (), tends to be the “surface”, and the geometric structure saliency ;
- (2)
- the geometric structure with 2-dimensional surface-shaped normal space, where there are two normal vectors (), tends to be the “line” and the geometric structure saliency ;
- (3)
- the geometric structure with 3-dimensional ball-shaped normal space, where there are three normal vectors (), tends to be the “point” and the geometric structure saliency .
3.4. Point Cloud Segmentation Based on Tensor Clustering
- (1)
- point feature filtering based on the ball tensor detecting
- (2)
- line feature extraction based on the line tensor classifying
- (3)
- surface feature segmentation based on the surface tensor clustering
- (1)
- sort the surface saliency s1 in descending order, and take the point with the largest saliency as the seed point p;
- (2)
- initialize the cluster set C and seed set E, push p into E, and search the neighborhood points of p using the searching radius r;
- (3)
- for each of the point pi in the , compute the angle difference between the normal vector of p and pi. Push pi to C if , in addition, push pi to Q if ;
- (4)
- delete the current seed point p from Q, and repeat step 3 until there is no seed point in Q.
3.5. The Algorithm of the Point Cloud Segmentation Workflow
| Algorithm 1 The algorithm of the point cloud segmentation workflow |
| Point cloud Segmentation based on the Tensor Feature PSTF(P, r) INPUT: point cloud P, the searching distance for the neighborhood r, segmentation thresholds {,,,} OUTPUT: segmented point cloud sets PSeg //Stage 1: Normal vector computation based on initial tensor encoding FOREACH p in P = GetNeighborhood(p, r);//get the neighborhood of p []= ComputeVoteVector(p,pi);//based on Equation (2) T = VoteEncodingByNeighborhood(p, pi, );//based on Equations (3) and (4) = GetOneDimStickVector(T);//based on Equation (1) END //Stage 2: Tensor aggregation based on normal tensor assembling FOREACH p in P Tnew = ReEncoding();//based on Equation (5) [] = EigenDecomposition(Tnew);//get the decomposed eigenvectors and eigenvalues from the re-encoded tensor = GetNeighborhood(p, r);//get the neighborhood of p FOREACH d in N//structures in each dimension for point p Dd = ComputeStructureTensor();//based on Equation (6) si = ComouteSturctureSaliency();//based on Equation (7) [vn, vt, vk] = ComputeVector(p, pk);//compute vectors for the voting = ComputeAngleDifference(vt, vk);//based on Equation (8) vnk = ComputePropergatedVector(vn, vt, );//based on Equation (9) = ComputeTensorFeature(vnk);//based on Equation (10) = ComputeDDimensionalTensor(, , pk);//based on Equations (11)–(13). END = AggregateTensor(si, );//based on Equation (14) = PropagateTensor();//based on Equation (15) END //Stage 3: Tensor feature decomposition based on tensor analyzing [] = EigenDecomposition(Tagg);//get the decomposed eigenvectors and eigenvalues from the aggregated tensor [s1,s2,…,sn] = ComputeGeometricDescriptor();//geometric structure decomposition //Stage 4: Point cloud segmentation based on tensor clustering Ppoint = PointFeatureFiltering(s,);//based on Equation (16) Ppoint = LineFeatureExtration(s,);//based on Equation (17) Psurface = SurfaceFeatureFiltering(s,,);//get the surface feature RETURN PSeg{Ppoint, Pline, Psurface} |
4. Experiments and Discussions
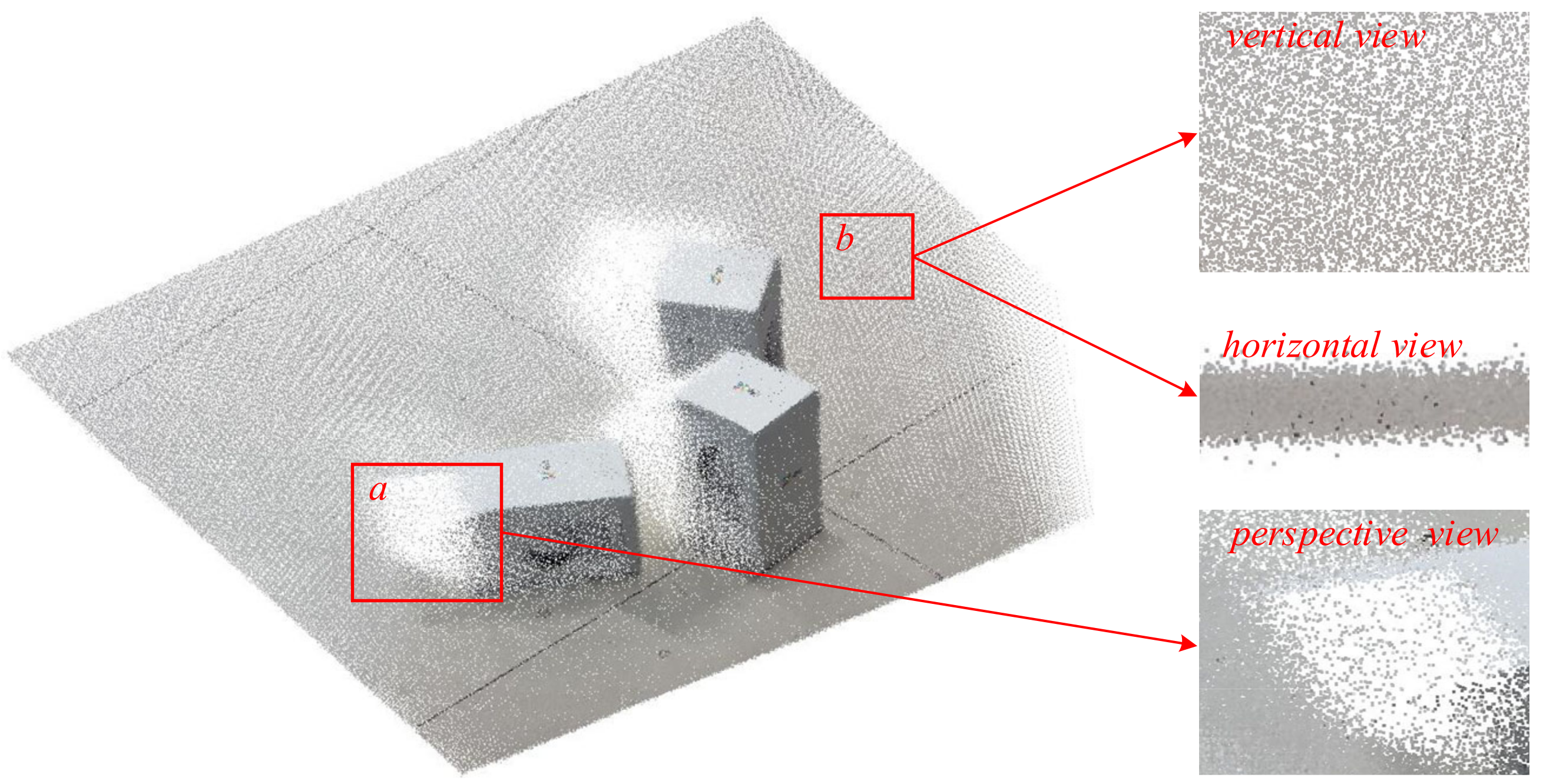
4.1. Datasets from the iPhone-Based LiDAR Sensor
4.2. Normal Vector Computation and Refinement Based on the Tensor Feature Encoding
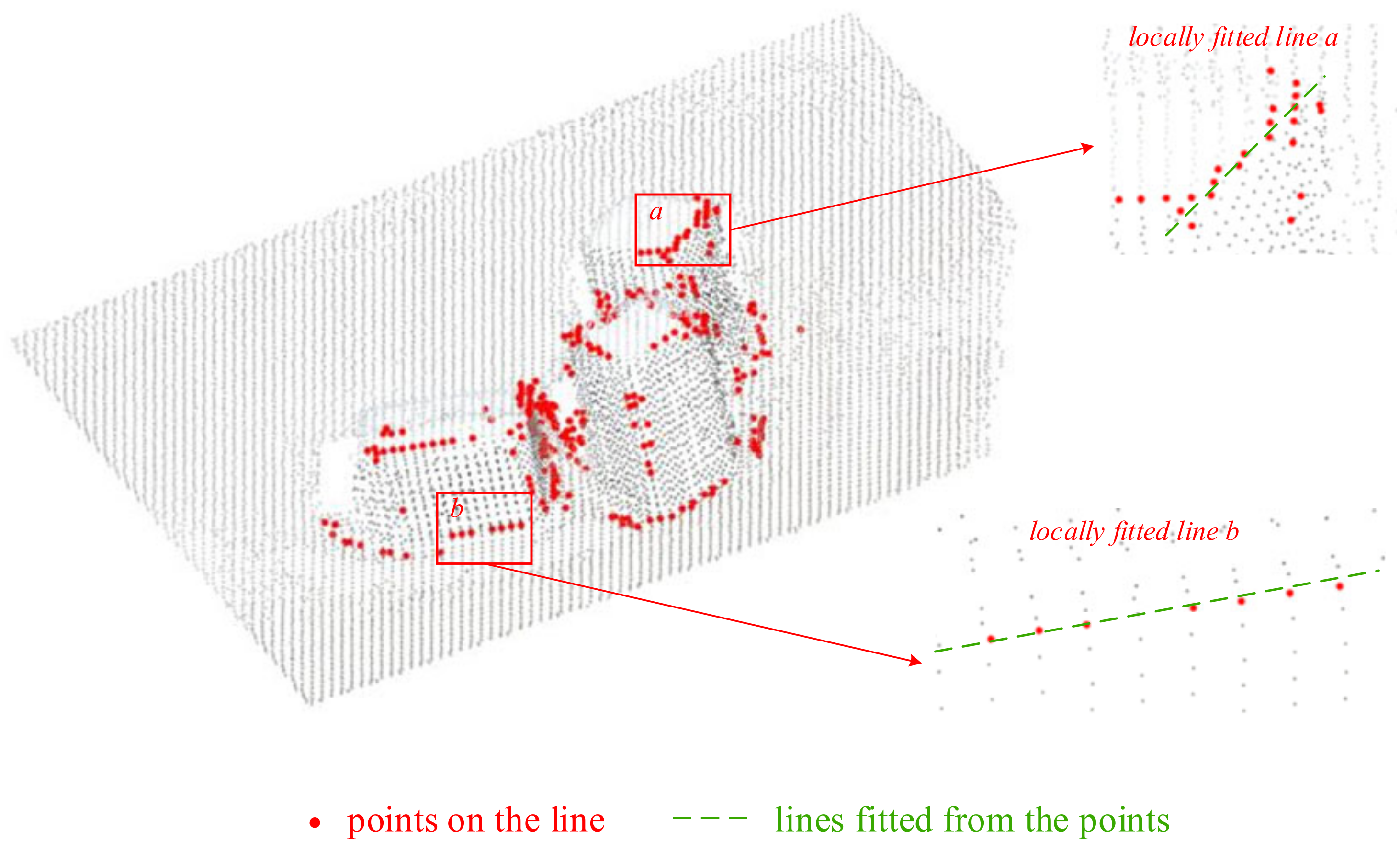
4.3. Shape Description Using the Tensor Analyzing
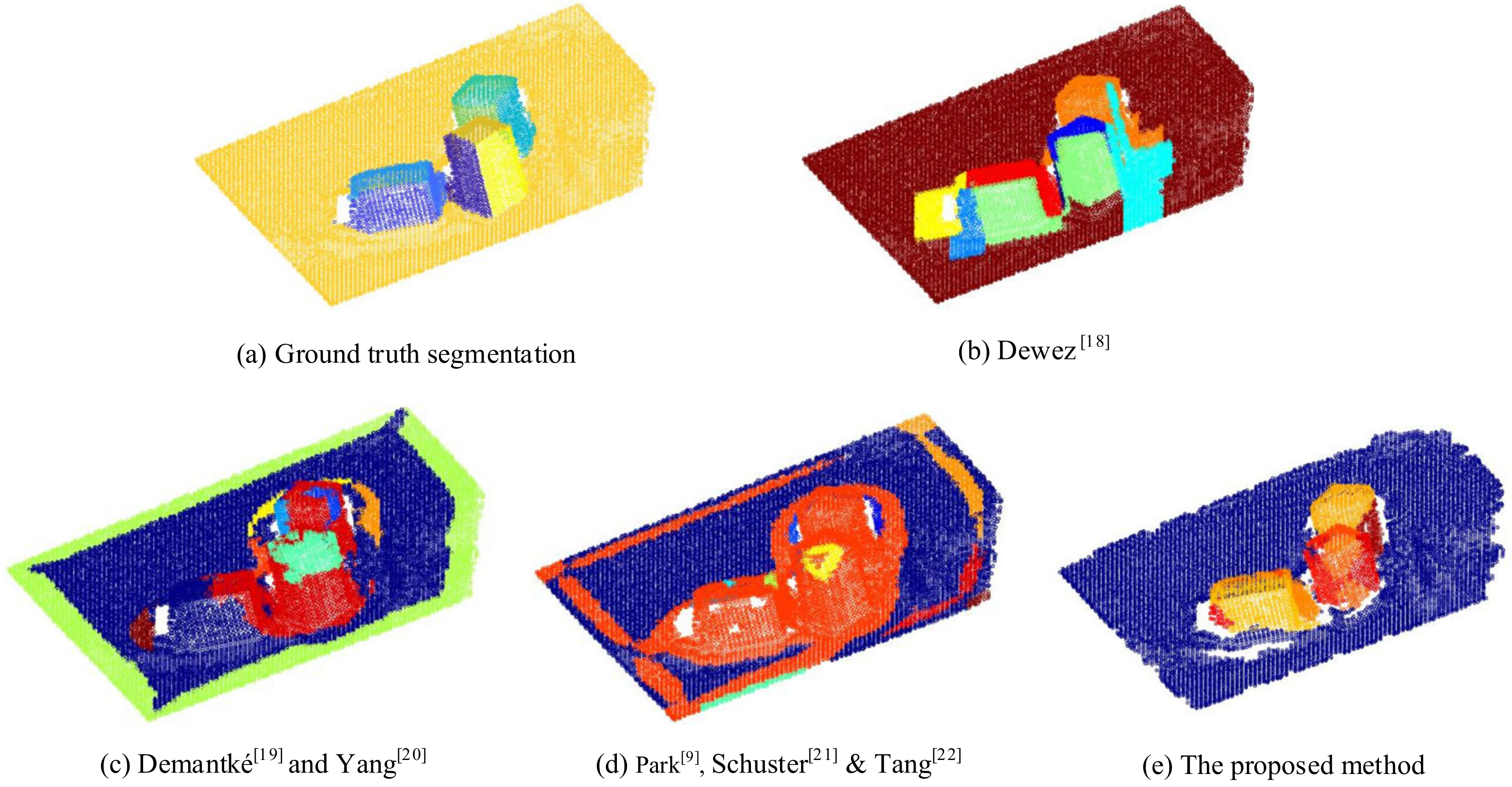
4.4. Point Cloud Segmentation Based on the Tensor Clustering
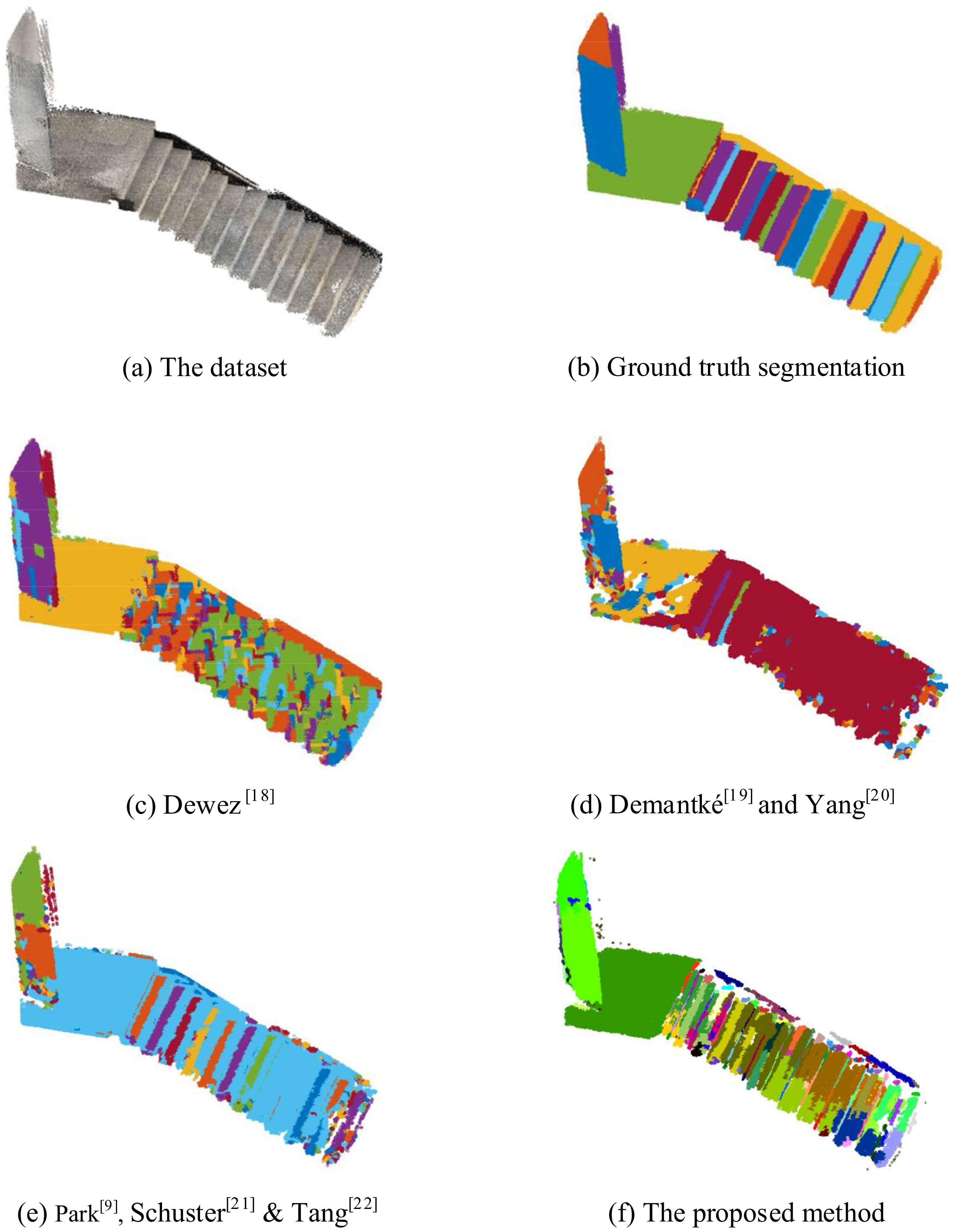
4.5. Point Cloud Segmentation for the Dataset in the Large Area
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, B.; Zhao, Y.; Yu, J.C.; Ikeuchi, K.; Zhu, S.C. Beyond Point Clouds: Scene Understanding by Reasoning Geometry and Physics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3127–3134. [Google Scholar]
- Nguyen, A.; Le, B. 3d Point Cloud Segmentation: A Survey. In Proceedings of the 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013; pp. 225–230. [Google Scholar]
- Grilli, E.; Menna, F.; Remondino, F. A review of point clouds segmentation and classification algorithms. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2017, 42, 339–344. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhao, X.; Chen, Z.; Lu, Z. A Review of Deep Learning-Based Semantic Segmentation for Point Cloud. IEEE Access 2019, 7, 179118–179133. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3d Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Li, G.; Wu, S.; Liu, Y.; Gao, Y. Guided point cloud denoising via sharp feature skeletons. Vis. Comput. 2017, 33, 857–867. [Google Scholar] [CrossRef]
- Wei, M.; Liang, L.; Pang, W.M.; Wang, J.; Li, W.; Wu, H. Tensor voting guided mesh denoising. IEEE Trans. Autom. Sci. Eng. 2016, 14, 931–945. [Google Scholar] [CrossRef]
- Sun, L.; Deng, Z. A Fast and Robust Rotation Search and Point Cloud Registration Method for 2D Stitching and 3D Object Localization. Appl. Sci. 2021, 11, 9775. [Google Scholar] [CrossRef]
- Park, M.K.; Lee, S.J.; Lee, K.H. Multi-scale tensor voting for feature extraction from unstructured point clouds. Graph. Model. 2012, 74, 197–208. [Google Scholar] [CrossRef]
- King, B.J. Range Data Analysis by Free-Space Modeling and Tensor Voting; Rensselaer Polytechnic Institute: Troy, NY, USA, 2008. [Google Scholar]
- Vo, A.-V.; Truong-Hong, L.; Laefer, D.F.; Bertolotto, M. Octree-based region growing for point cloud segmentation. ISPRS J. Photogramm. Remote Sens. 2015, 104, 88–100. [Google Scholar] [CrossRef]
- Xu, Y.; Yao, W.; Hoegner, L.; Stilla, U. Segmentation of building roofs from airborne LiDAR point clouds using robust voxel-based region growing. Remote Sens. Lett. 2017, 8, 1062–1071. [Google Scholar] [CrossRef]
- Ni, H.; Lin, X.; Zhang, J. Classification of ALS Point Cloud with Improved Point Cloud Segmentation and Random Forests. Remote Sens. 2017, 9, 288. [Google Scholar] [CrossRef] [Green Version]
- Ying, S.; Xu, G.; Li, C.; Mao, Z. Point Cluster Analysis Using a 3D Voronoi Diagram with Applications in Point Cloud Segmentation. ISPRS Int. J. Geo-Inf. 2015, 4, 1480–1499. [Google Scholar] [CrossRef]
- Zhan, Q.; Yu, L.; Liang, Y. A Point Cloud Segmentation Method Based on Vector Estimation and Color Clustering. In Proceedings of the 2nd International Conference on Information Science and Engineering, Hangzhou, China, 4–6 December 2010; pp. 3463–3466. [Google Scholar] [CrossRef]
- Hulik, R.; Spanel, M.; Smrz, P.; Materna, Z. Continuous plane detection in point-cloud data based on 3D Hough Transform. J. Vis. Commun. Image Represent. 2014, 25, 86–97. [Google Scholar] [CrossRef]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for Point-Cloud Shape Detection. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2007; Volume 26, pp. 214–226. [Google Scholar]
- Dewez TJ, B.; Girardeau-Montaut, D.; Allanic, C.; Rohmer, J. Facets: A Cloudcompare Plugin to Extract Geological Planes from Unstructed 3D Point Clouds. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing & Spatial Information Sciences, Prague, Czech Republic, 12–19 June 2016; pp. 799–804. [Google Scholar]
- Demantké, J.; Mallet, C.; David, N.; Vallet, B. Dimensionality Based Scale Selection in 3D Lidar Point Clouds. In Proceedings of the ISPRS Workshop on Laser Scanning, Calgary, AB, Canada, 29–31 August 2011; pp. 29–31. [Google Scholar]
- Yang, B.; Dong, Z. A shape-based segmentation method for mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2013, 81, 19–30. [Google Scholar] [CrossRef]
- Schuster, H.F. Segmentation of LiDAR data using the tensor voting framework. International Archives of Photogrammetry. Remote Sens. Spat. Inf. Sci. 2004, 35, 1073–1078. [Google Scholar]
- Tang, C.-K.; Medioni, G. Curvature-augmented tensor voting for shape inference from noisy 3D data. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 858–864. [Google Scholar] [CrossRef]
- Zhan, Q.; Liang, Y.; Xiao, Y. Color-based segmentation of point clouds. Laser Scan. 2009, 38, 155–161. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-View Convolutional Neural Networks for 3d Shape Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 945–953. [Google Scholar]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-View Convolutional Neural Networks for 3d Shape Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 264–272. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Hoegner, L.; Tuttas, S.; Stilla, U. VOXEL and graph-based point cloud segmentation of 3d scenes using perceptual grouping laws. In Proceedings of the ISPRS Annals of Photogrammetry, Remote Sensing & Spatial Information Sciences, Hannover, Germany, 6–9 June 2017; Volume 4, pp. 43–50. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3d Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. Adv. Neural Inf. Processing Syst. 2018, 31, 820–830. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Markham, A. RandLA-net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11108–11117. [Google Scholar]
- Te, G.; Hu, W.; Zheng, A.; Guo, Z. RGCNN: Regularized Graph CNN for Point Cloud Segmentation. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 746–754. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep Convolutional Networks on 3d Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10296–10305. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Lyu, H.; Mao, T.; He, W.; Chen, Q. Point Cloud Segmentation from iPhone-Based LiDAR Sensors Using the Tensor Feature. Appl. Sci. 2022, 12, 1817. https://doi.org/10.3390/app12041817
Wang X, Lyu H, Mao T, He W, Chen Q. Point Cloud Segmentation from iPhone-Based LiDAR Sensors Using the Tensor Feature. Applied Sciences. 2022; 12(4):1817. https://doi.org/10.3390/app12041817
Chicago/Turabian StyleWang, Xuan, Haiyang Lyu, Tianyi Mao, Weiji He, and Qian Chen. 2022. "Point Cloud Segmentation from iPhone-Based LiDAR Sensors Using the Tensor Feature" Applied Sciences 12, no. 4: 1817. https://doi.org/10.3390/app12041817