1. Introduction
Data clustering is an aspect of data mining where knowledge discovery from data requires that the data reveals the existing groups within itself. In cluster analysis, objects are grouped such that the intra-cluster distances among data objects are minimized while the inter-cluster distances are maximized. K-means is one of the most popular traditional clustering algorithms used for cluster analysis, due to its efficiency and simplicity. The k-means algorithm randomly selects a specified k number of initial cluster centroids as a representative center of each group. It then assigns data objects to their nearest cluster, based on the sum of squares point to nearest centroid distance. The mean of each cluster is calculated to generate an initial cluster with an updated cluster centroid. These data object assignment and centroid update processes are iteratively repeated until an optimum cluster solution is obtained. The need to specify the number of clusters a priori makes the K-means algorithm unsuitable for automatic clustering. According to [
1], estimating the optimal number of clusters in a dataset is a fundamental problem in cluster analysis, referred to as ‘automatic clustering’. In most cases, K-means is hybridized with metaheuristic algorithms for automatic clustering [
2].
The standard K-means algorithm is sensitive to noisy data and outliers [
3,
4]. Intuitively, the data points that are far away from their nearest neighbors are described as outliers [
5]. The sensitivity of K-means to noise and outliers comes from the least square optimization procedure, normally employed for cluster analysis. K-means’ reliance on the outlier-sensitive statistics (mean) for cluster updates compromises the clustering results when outliers are present in datasets. Several proposals have been reported in the literature that add a separate module for detecting and removing outliers as a data pre-processing step embedded in the K-means algorithm, before the actual data clustering procedure. A separate module for outlier detection significantly compromises the efficiency of the K-means algorithm. Chawla and Gionis [
6] proposed an algorithm that simultaneously detected and removed outliers from the dataset during the clustering process, eliminating the need for a separate module. Their algorithm incorporated outlier detection into the K-means algorithm without complicated modification to the standard algorithm. However, their algorithm required specifying the desired number of outliers within the dataset, like how the desired number of clusters had to be specified. Olukanmi et al. [
7] proposed a K-means variant for automatic outlier detection with the automatic specification of the number of clusters via Chebyshev-type inequalities. This paper incorporated this automatic detection and exclusion of outliers in the centroid update process of the standard K-means section of SOSK-means for a more robust hybridized algorithm.
The symbiotic organisms search (SOS) algorithm is a nature-inspired metaheuristic algorithm proposed by [
8]. The algorithm has no basic control algorithm-specific parameter in its initialization stage. It works similarly to other well-known metaheuristic algorithms, such as the genetic algorithm (GA), the particle swarm optimization (PSO) algorithm, and the firefly algorithm (FA). The algorithm is inspired by the symbiotic relationships among organisms in a natural habitat, necessary to their survival in the ecosystem. The three symbiotic relationships (mutualism, commensalism, and parasitism) are modeled to find optimal solutions to optimization problems. As a population-based algorithm, the first two phases (mutualism and commensalism) use the best solution to exploit the population information in searching for potential solutions. The parasitism phase creates new solutions by modifying the existing solution, while, at the same time, removing inferior solutions [
9]. The SOS algorithm is rated among the most competitive swarm intelligence-based metaheuristic algorithms for solving optimization algorithms, based on its simplicity and parameter-less attributes. SOS has been used to find the solution to many different real-world problems [
10,
11,
12,
13,
14,
15,
16]. Tejani et al. [
17] introduced a parameter setting of the beneficial factor, based on the normalized value of organisms, to create an adaptive SOS algorithm for structural optimization problems. A discrete version of SOS was designed and implemented by [
18] for task scheduling in a cloud computing environment. Cheng, Prayogo and Tran [
11] introduced another discrete SOS for multiple resources leveling optimization. Panda and Pani [
10] introduced multi-objective SOS for handling multi-objective optimization problems. Kawambwa et al. [
12] proposed a cloud-based model SOS using cloud-based theory to generate random number operators in the mutualism phase for power system distributed generators. Mohammadzadeh and Gharehchopogh [
19] proposed three variants of SOS to solve the feature selection challenge, and Cheng, Cao, and Herianto [
14] proposed an SOS optimized neural network–long short-term memory for obtaining hyperparameters of the neural network and long short-term memory for the establishment of a robust hybridization model for cash flow forecasting.
SOS has also been employed in solving automatic clustering problems [
20,
21,
22,
23,
24,
25]. Boushaki, Bendjeghaba, and Kamel [
20] proposed a biomedical document clustering solution using accelerated symbiotic organisms search, which required no parameter tuning. Yang and Sustrino [
25] proposed a clustering-based solution for high-dimensional optimization problems using SOS with only one control parameter. Chen, Zhang, and Ning proposed an adaptive clustering-based algorithm using SOS for automatic path planning of heterogeneous UAVs [
22]. Zainal and Zamil [
23] proposed a novel solution for software module clustering problems using a modified symbiotic organism search with levy flights. The effectiveness of the SOS algorithm in solving automatic clustering problems was demonstrated by [
21], where the SOS algorithm was used in clustering different UCI datasets. SOS has been hybridized with other metaheuristic algorithms for performance enhancement in cluster analysis. Rajah and Ezugwu [
24] combined the SOS algorithm with four different metaheuristic algorithms to solve the automatic clustering problem and compared the clustering performances of each hybrid algorithm. Our earlier work combined the SOS algorithm with K-means to boost the traditional clustering algorithm’s performance for automatic clustering [
26].
However, SOS exhibits some limitations, such as slow convergence rate and high computational complexity [
17,
26,
27,
28]. Modifications have been made to the standard SOS to improve its performance. Tejani, Savsani and Patel [
17] introduced adaptive benefit factors to the classical SOS algorithm, proposing three modified variants of SOS for improved efficiency. Adaptive benefit factors and benefit factors were effectively combined to achieve a good exploration–exploitation balance in the search space. Nama, Saha, and Ghosh [
27] introduced a random weighted reflective parameter, to enhance searchability within the additional predation phase, to the classical SOS algorithm to improve the solving of multiple complex global optimization problems and improve the algorithm’s performance. Secui [
29] sought to improve the algorithm’s capacity for the timely identification of stable and high-quality solutions by introducing new relations for solution updates at the mutualism and commensalism phases. A logistic map-generated chaotic component for finding promising zones was also added for the enhancement of the algorithm’s exploration capacity. The removal of the parasitism phase reduced the computational load. Nama, Saha, and Ghosh [
30] combined SOS with simple quadratic interpolation (SQI) for handling large-scale and real-world problems. Although their proposed hybrid SOS algorithm increased the algorithms’ complexity, it provided an efficient and effective quality solution, with an improved convergence rate. Ezugwu and Adewumi [
31] improved and extended the classical SOS using three mutation-based local search operators to improve population reconstruction, exploration, and exploitation capability and to accelerate the convergence speed. Other improvements reported in the literature include [
32,
33,
34,
35,
36,
37,
38]. According to Chakraborty, Nama, and Saha [
9], most of the proposed improvements could not guarantee finding the best optimal solution. As such, they proposed using a non-linear benefit factor where the mutual vector was calculated, based on the weights of two organisms for a broader and more thorough search. They also altered the parasitism phase to reduce the computational burden of the algorithm.
This paper proposes an improved version of the hybrid SOSK-means algorithm [
24], called ISOSK-means, to address the common limitations of the individual classical algorithms and their hybridization variants for a more robust, efficient, and stable hybrid algorithm. The algorithm adopted a population size of
for a well distributed initial population sample, based on the assumption that selecting the right sample size produces a sample mean that approximates the true centroid on Gaussian distribution [
39]. This ensured a substantially large population size at each iteration for early convergence in the SOS phase of the hybrid algorithm. The modified algorithm also employed a global threshold of point-to-centroid distance distribution in the K-means algorithm phase to detect outliers for subsequent exclusion in calculating the new centroids [
3]. The detection and exclusion of outliers in the K-means phase assisted in improving the cluster result. The performance of the SOS algorithm was enhanced by introducing self-adaptive benefit factors, with a three-part mutualism phase, as suggested in [
28]. These techniques enhanced the search for the optimum centroids in the solution space and improved the convergence rate of the hybrid algorithm. The performance of the proposed algorithm was evaluated on 42 datasets with varying sizes and dimensions. Davies Bouldin (DB) index [
40] and cluster separation (CS) index [
41] were used as cluster validity indices for evaluating the performance of the algorithm. The choice of the two clustering validity indices was based on the duo’s cluster validity approach of minimizing the intra-cluster similarity and maximizing the inter-cluster similarity, which is the same as the primary objective of data clustering. The CS index was only applied to 12 datasets for comparison with the classical version of the improved hybrid algorithm. The two indices, based on their validity approach, are credited with the ability to produce clusters that are well separated, with the minimum intra-cluster distance and maximum inter-cluster distance [
42,
43,
44]. The DB index can guide the clustering algorithm using a partitioning approach without the need to specify the number of clusters, and the CS index is known for its excellent performance in the identification of clusters with varying densities and sizes [
40,
41,
43]. The enhanced outcomes were compared with the existing hybrid SOSK-means algorithm and other comparative non-hybrid and hybrid metaheuristic algorithms on large dimensional datasets. The performance of the proposed improved hybrid algorithm was further validated using the nonparametric Friedman mean rank tests and Wilcoxon signed-rank statistical tests. The results of the extensive computational experiments showed that the proposed improved hybrid algorithm (ISOSK-means) outperformed the existing SOSK-means algorithm, and demonstrated superior performance over some of the competing hybrid and non-hybrid metaheuristic algorithms. The main contributions of this paper are as follows:
Integration of a robust module in the proposed SOS-based K-means hybrid algorithm using outlier detection and the exemption technique in the K-means phase for a more effective cluster analysis with compact clusters.
Integration of a three-part mutualism phase with a random weighted reflection coefficient into the SOS phase, for a more productive search in the solution space for early convergence and reduced computational time.
Adopting a population size of for a well-distributed initial population in the SOS phase, allowing for a large enough solution space per iteration, aimed to ensure early convergence of the proposed clustering algorithm.
The remaining sections of this paper are organized as follows.
Section 2 presents related work on hybrid algorithms involving SOS and K-means. It also includes a brief introduction to the standard K-means algorithm, standard SOS algorithm and hybrid SOSK-means.
Section 3 describes the improvements integrated into the K-means and SOS algorithms and presents the description of the proposed ISOSK-means. The simulation and comparison of results of the proposed ISOSK-means are presented in
Section 4, while
Section 5 presents the concluding remarks and suggestions for future directions.
2. Related Work
There are existing works in the literature that reported hybridizations involving either K-means or symbiotic organism search or both. However, it is worth stating here that hybridizations for clustering problems are few. In [
45], the SOS algorithm was hybridized with the improved opposition-based learning firefly algorithm (IOFA) to improve the exploitation and exploration of IOFA. SOS was combined with differential evolution (DE) in [
46] to improve the convergence speed and optimal solution quality of shape and size truss structure optimization in engineering optimization problems. The conventional butterfly optimization algorithm (BOA) was combined with the first two phases of the SOS for enhancement of global and local search behavior of the BOA. In [
47], a modified strategy of SOS was hybridized with the mutation strategy of the DE to ensure the preservation to the SOS local search capability, while maintaining its ability to conduct global search. Other reported hybrids involving SOS include the following: Ref. [
48] combined GA, PSO and SOS algorithms for continuous optimization problems; Ref. [
24] reported four hybrid algorithms for automatic clustering, combining SOS with FA, for teaching–learning based optimization (TLBO), DE, and PSO algorithms. Other hybridization algorithms involving SOS can be found in the review work on SOS algorithms conducted by [
49].
Several hybridizations involving K-means with other metaheuristic algorithms were reported in the review work presented by [
2]. Recent hybridizations involving K-means include the following: Ref. [
50] combined GA with K-means and support vector machine (SVM) for automatic selection of optimized cluster centroid and hyperparameters tunning; Ref. [
51] combined multi-objective individually directional evolutionary algorithm (IDEA) with K-means for multi-dimensional medical data modeling using fuzzy cognitive maps; Ref. [
52] presented an hybrid of K-means with PSO for semantic segmentation of agricultural products; Ref. [
53], combined K-means algorithm with particle swarm optimization for customer segmentation.
For hybridization involving SOS and K-means, as mentioned earlier, the reported literature works are very minimal showing that research in this aspect is still shallow. In [
25], a clustering-based SOS for high-dimensional optimization problems was proposed, combining an automatic K-means with symbiotic organism search for efficient computation and better searching quality. The automatic K-means was used to generate subpopulations for the SOS algorithm to create a sub-ecosystem that made the combination of global and local searches possible. The mutualism and commensalism phases formed the local search, where solutions were allowed to interact within each cluster. For the global search, only best solutions from each cluster were allowed to interact across the clusters under the parasitism phase. In this case, the K-means algorithm was used as a pre-processing phase for the SOS algorithm to enhance its performance in finding solutions to high dimensional optimization problems. In [
26], the standard algorithms SOS and K-means were combined to solve automatic clustering problems. The SOS phase resolved the initialization challenge for the K-means algorithm by automatically determining the optimum number of clusters and generating the corresponding initial cluster centers. This ensured the K-means algorithm avoided the possibility of local optimum convergence while improving the cluster analysis capability of the algorithm. However, the problem of low convergence persisted in the hybrid algorithm.
In this work, we hoped to further improve on the clustering performance of the previous SOS-based K-means hybrid algorithm in [
26] for automatic clustering of high-dimensional datasets, by incorporating some improvements into each of the standard algorithms, SOS and K-means, so as to achieve better convergence and more compact clusters.
2.1. K-Means Algorithm
The K-means algorithm is a partitional clustering algorithm that iteratively groups a given dataset
X in R
d into
k number of clusters
such that:
based on a specified fitness function. The K-means algorithm handles the partitioning process as an optimization problem to minimize the within-cluster variance
:
with cluster center
uniquely defining each cluster as:
with the set of
centres
representing the solution to the K-means algorithm [
54].
The standard K-means algorithm involves three major phases: the initialization phase, the assignment phase, and the centroid update phase. During the initialization phase, the initial cluster centers are randomly selected to represent each cluster. This is followed by the data object assignment phase, where each data point in the dataset is then assigned to the nearest cluster, based on the shortest centroid-point distance. Each cluster centroid is then re-evaluated during the centroid update phase. The last two phases are repeated until the centroid value remains constant in consecutive iterations [
44].
The K-means clustering is an NP-hard optimization problem [
55], with the algorithm having a time complexity of
where
represents the number of data points in the dataset,
represents the number of clusters, and
denotes the number of iterations required for convergence. The computational complexity is a function of the size of the dataset, hence, clustering large real-world, or dynamic, datasets using the K-means algorithm incurs a sizeable computational time overhead. Moreover, the number of clusters
is required to be a user-specified parameter for the K-means algorithm. In most real-world datasets, the number of clusters is not known a priori; therefore, specifying the correct number of clusters in such a dataset is arduous. Furthermore, the random selection of initial cluster centroids incurs the possibility of the algorithm getting stuck in the local optimum [
54]. Based on these challenges, many variants of K-means have been proposed in the literature [
2,
4] to improve the performance of the K-means algorithm. One of the areas being exploited for improving the standard K-means algorithm is hybridizing K-means with metaheuristic algorithms [
2].
2.2. SOS Algorithm
Cheng and Prayogo [
8] proposed the concept of SOS simulating the interactive relationships between organisms in an ecosystem. In an ecosystem, most organisms do not live in isolation because they need to interact with other organisms for their survival. These relationships between organisms, known as symbiotic relationships, are, thus, defined using three possible major interactions: mutualism, commensalism, and parasitism. Mutualism represents a symbiotic relationship where the participating organisms benefit from each other. For instance, an oxpecker feeds on the parasites living on the body of a zebra or rhinoceros, while the symbiont, in turn, enjoys the benefit of pest control. Commensalism describes a relationship where only one of the participating organisms benefits from the association while the other organism does not benefit from the relationship, although it is not negatively affected either. An example of this is orchids, which grow on branches and trunks of trees to access sunlight and obtain nutrients from the branches. As a slim, tender plant, their existence does not harm the tree on which they grow. The relationship between humans and mosquitos provides a perfect scenario of the parasitism symbiotic relationship, in which one of the organisms (mosquito) benefits from the association while simultaneously causing harm to the symbiont (human). These three relationships are captured in the SOS algorithm [
8]. In most cases, the type of relationship increases the fitness of benefiting organisms, giving them a long-term survival advantage.
In the SOS algorithm, the three-symbiosis relationship is simulated as the three phases of the algorithm. At the initial stage, a population of candidate solutions are randomly generated to the search space for solution representations for optimal global solution search. This set of solutions forms the initial ecosystem. where each individual candidate solution represents an organism in the ecosystem. A fitness value is associated with each organism to determine the measure of its adaptation capability with respect to the desired objective. Subsequently, each candidate solution is further updated using the three simulated symbiotic relationship phases to generate a new solution. For each phase, a new solution is only accepted if its fitness value is better than the previous one. Otherwise, the initial solution is retained. This iterative optimization process is performed until the termination criteria are met. The three simulated symbiotic relationship phases of the SOS algorithm are described below.
Given two organisms
and
co-existing in an ecosystem such that
and
represent the iterative values of the optimization, ranging from
to
where
is the problem dimension and
an organism,
is randomly selected during the mutualism phase to participate in a mutual relationship with
such that the two organisms enjoy a common benefit from their interaction for survival. Their interaction yields new solutions
and
based on Equations (7) and (8), respectively, with Equation (9) representing the mutual benefit
enjoyed by both organisms.
The expression (
) as shown in Equations (7) and (8), represents the mutual survival efforts exhibited by each organism to remain in the ecosystem. The highest degree of adaptation achieved in the ecosystem is represented by the
which acts as the target point for increasing the fitness of the two interacting organisms. Each organism’s benefit level of value 1 or 2 is randomly determined to indicate the organism’s benefit from the relationship, which can either be full or partial. This benefit level is denoted as
BF (benefit factor) in the equations. The
BF value is generated using Equation (10):
As stated earlier, the newly generated solutions are accepted as a replacement for the existing solution if, and only if, they are better. In other words, new solutions are rejected if the existing solutions are better. Equations (11) and (12) incorporate this:
In simulating the commensalism phase, an organism
is randomly selected for interaction with organism
exhibiting the characteristic of the commensalism symbiosis relationship where only one of the two organisms
derives a benefit from the relationship. This relationship is simulated using Equation (13):
Thus, only the benefiting organisms generate a new solution, as reflected by Equation (10). The new solution is accepted only if it is better, in terms of fitness, than the previous solution before the interaction.
The parasitism phase is the last phase, which is simulated using Equation (14). In simulating the parasitism symbiotic relationship in the SOS algorithm, a duplicate copy of the
organism is created as a parasite vector with some of its selected dimensions modified using a random number. An organism
is then randomly selected from the ecosystem to play host to the parasite vector
. If the fitness value of
is better than that of
, then
replaces
in the ecosystem. If the opposite happens, and
builds immunity against
, then
is removed from the ecosystem:
2.3. Description of Data Clustering Problem
In data clustering problems, data objects sharing similar characteristics are grouped together into a cluster, such that data objects in one cluster are different from data objects in other clusters. In most cases, the number of clusters is specified, while in some cases, especially in high dimensional datasets, predetermining the number of clusters is not feasible. In optimization terms, data objects are clustered, based on the similarity or dissimilarity between them, such that the inter-cluster similarity is minimized (maximizing inter-cluster dissimilarity), while maximizing the intra-cluster similarity (or minimizing intra-cluster dissimilarity). The description of a clustering problem as an optimization problem is given below.
Given a dataset
of dimension
which represents the number of attributes or features of the data objects in the datasets such that
where
is the number of data objects in the dataset. Each data object
where
represents all the features for data object
. The dataset
can be represented in a matrix form as shown in Equation (15):
is required to be grouped into number of clusters to satisfy Equations (1)–(3), using Equation (4) as the objective function, with each cluster having a cluster center defined in Equations (5) and (6). For an automatic clustering, the number of clusters is not defined. Therefore, finding the optimum number of clusters represented by equation (6) becomes the optimization problem that seeks to optimize the function over all possible clustering of where function represents the global validity index for obtaining the best quality clustering solution and represents the distance metric measure, stated in Equation (4).
2.4. Cluster Validity Indices
The cluster validity indices are qualitative methods, like the statistical mathematical functions, for evaluating the clustering quality of a clustering algorithm. A cluster validity index has the capacity to accurately determine the cluster number in a dataset, as well as find the proper structure of each cluster in the dataset [
56]. The principal concerns of most validity indices in clustering are to determine clustering compactness, separation, and cohesion. The cluster validity indices are presented as the fitness function during the optimization process of the clustering algorithms. The DB index and CS index are used as the cluster validity indices to evaluate the quality of the clustering results.
The DB index determines the quality of a clustering result by using the average inter-cluster similarity between any two clusters and the intra-cluster similarity between data objects within a cluster. The average intra-cluster similarity value is evaluated against the average inter-cluster similarity value using Equations (16) and (17). In the DB index, the fitness function is minimized during the data clustering. This implies that a smaller index value indicates better compactness or separation, and vice versa:
where
and
represent the within-cluster distance for clusters
and
,
represents the inter-cluster distance between the two clusters
and
. The
is the inter-cluster distance between the two cluster centroids
of the respective clusters
and
.
The CS index estimates the quality of a clustering result by finding the ratio of the sum of the intra-cluster scatter to the inter-cluster separation using Equation (18):
where
represents within-cluster scatter and between-cluster separation with the distance measure given as
. The CS index is rated as being more computationally intensive but more efficient, compared with the DB index, and gives a more quality solution than the DB index. In the CS index, the fitness function is also minimized, therefore a lower validity index implies better separation or compactness, while a higher index value implies weak separation or compactness.
2.5. Hybrid SOSK-Means
A hybridization of SOS and K-means proposed by [
26] found the solution to the automatic clustering algorithm. The proposed algorithm employed the standard SOS algorithm to globally search for the optimum initial cluster centroids for the K-means algorithm. This resolved the problems associated with the random generation of the initial cluster centroid without initial specification of the value of
. The problem of multiple parameter controls required in most nature-inspired population-based metaheuristic algorithms (e.g., GA, PSO, FA) was also avoided, since the SOS required only the basic control parameters for a metaheuristic algorithm, such as the number of iterations and population size, with no algorithm-specific parameters. The SOS as a global search algorithm ensured that K-means returned a global optimum solution to the clustering problem, canceling the possibility of getting stuck in the local optimum. According to [
26], the SOSK-means algorithm combined the local exploitation capability of the standard K-means with less parameter tuning and global exploration, as provided by the SOS algorithm with implementation simplicity common to the two algorithms, to produce a powerful, efficient, and effective automatic clustering algorithm. The resulting hybrid algorithm was credited with better cluster solutions than the results from the standard SOS and K-means algorithms executed separately.
The SOSK-means algorithm commences by initializing the population of 𝑛 organisms representing the ecosystem, randomly generated using Equation (19), and the fitness value of each organism is calculated based on the fitness function for the optimization process. The initial organisms are generated by the expression
in the equation, representing random and uniformly distributed points within the ecosystem, the solution search space is bounded between specified lower and upper limits
and
respectively, for the clustering problem:
New candidate solutions are subsequently generated using the three phases of the SOS algorithm, described under the SOS algorithm. The optimum result from the phases of the SOS algorithm is passed as the optimum cluster centroids for initializing the K-means algorithm. These processes are iteratively performed until the stopping criterion is achieved. The details on the design and performance of hybrid SOSK-means can be found in [
26]. Algorithm 1 presents the pseudocode for the hybrid SOSK-means algorithm. The flowchart for Algorithm 1 can be found in [
26].
| Algorithm 1: Hybrid SOSK-means clustering pseudocode [26] |
| Input:Eco_size: population size ULSS: upper limit for search space |
| Max_iter: maximum number of iterations LLSS: lower limit for search space |
| PDim: problem dimension ObjFn(X): fitness (objective) function |
| Output: Optimal Solution |
| 1: Create an initial population of organisms …, |
| 2: Calculate the fitness of each organism |
| 3: Keep the initial population’s best solution |
| 4: while |
| 5: for do |
| 6: // 1st Phase: Mutualism // |
| 7: Select index j |
| 8: |
| 9: |
| 10: |
| 11: for do |
| 12: |
| 13: |
| 14: end for |
| 15: if |
| 16: |
| 17: end if |
| 18: if |
| 19. |
| 20: end if |
| 21: // 2nd Phase: Commensalism // |
| 22: Select index j randomly |
| 23: for do |
| 24: |
| 25: end for |
| 26: if |
| 27: |
| 28: end if |
| 29: //3rd Phase: Parasitism // |
| 30: Select index j |
| 31: for do |
| 32: if |
| 33: |
| 34: else |
| 35: |
| 36: end if |
| 37: end for |
| 38: if |
| 39: |
| 40: end if |
| 41: Update current population’s best solution BestX |
| 42: //K-means Clustering Section// |
| 43: K-means’ initialization using the position of the BestX |
| 44: Execute K-means clustering |
| 45: end for |
| 46: iter = iter + 1 |
| 47: end while |
5. Conclusions and Future Directions
In this study, an improved hybrid ISOSK-means metaheuristic algorithm is presented. Several improvements were incorporated into each of the two classical algorithms combined in the hybridization. In the initialization phase of the SOS algorithm, the population size was constructed using for a well-distributed initial population of solutions that scaled well with the data size. This resulted in a convergence rate increase and lower computational time. For performance upgrade, a three-part mutualism phase, with a random weighted reflection coefficient, was also integrated into the SOS algorithm with a random probability for determining whether an organism would be engaged in the three-part mutualism. To improve the quality of the clustering solution, the benefit factor was modified, by incorporating consideration for fitness value relativity with respect to the maximum fitness value.
The misleading effects of outliers in the dataset were addressed by the improvement incorporated into the K-means phase of the improved hybrid algorithm. A method for detecting and excluding putative outliers during the centroid update phase of the classical algorithm was added. The algorithm uses a point-to-centroid distance threshold for the centroid update, instead of using the means of data points. The point-to-centroid distance threshold uses the median absolute deviation, which is considered to be a robust measure of statistical dispersion and is known to be more resilient to outliers. This ensured that outliers were excluded from contributing to minimizing the mean square error in the K-means. This resulted in a more compact cluster output.
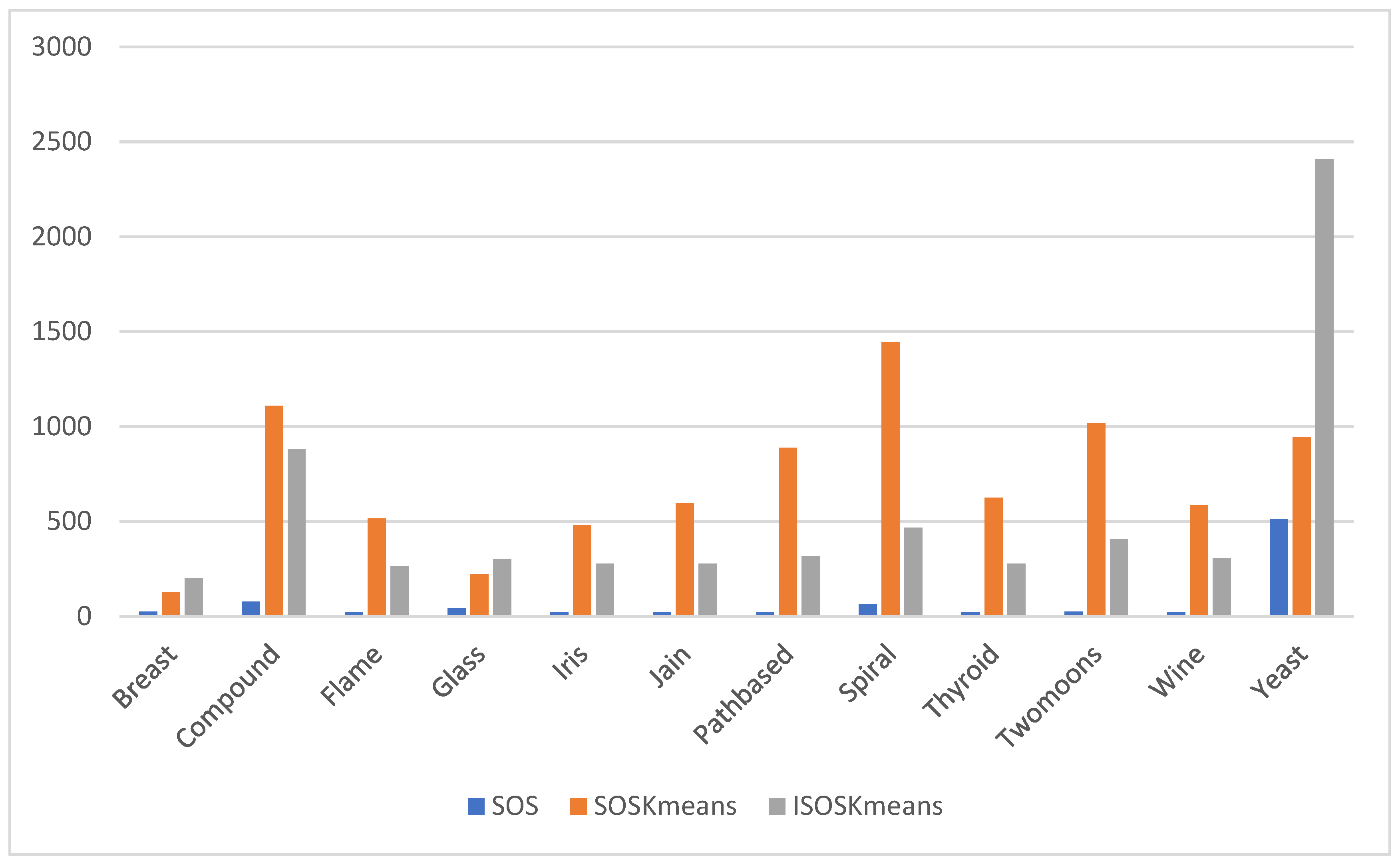
The improved hybrid algorithm was evaluated on 42 datasets (18 synthetic and 24 real-life) with varying characteristics, such as being high dimensional datasets, low dimensional datasets, synthetically generated datasets, image datasets, shape datasets, and location datasets, with varied dataset sizes and clusters. The performance of the improved hybrid algorithm was compared with the standard hybrid and non-hybrid algorithms. The performance was also compared with the two standard algorithms SOS and K-means on 12 real life datasets. A Friedman means rank test was applied to analyze the significant difference between the ISOSK-means and the competing algorithms. A pairwise post hoc Wilcoxon signed-rank sum test was also performed to highlight the performance of the ISOSK-means in comparison with the competing algorithms. The ISOSK-means algorithm outperformed the three algorithms with lower computational time and higher convergence rate, as reflected in the convergence curve for the competing algorithms.
The ISOSK-means clustering results were compared with four non-hybrid metaheuristic algorithms and three hybrid metaheuristic algorithms from the literature. The ISOSK-means had fair competitiveness, in terms of clustering performance measured using the DB validity index, on 42 datasets. The ISOSK-means recorded the lowest standard deviation score for most datasets, compared with the competing algorithms.
For future research, the K-means phase of the hybridized algorithm could be improved to efficiently manage large datasets and, thereby, reduce the algorithm’s computational complexity. Other suggested improvements to the SOS algorithm from literature could also be incorporated into the algorithm, or be used as a replacement to the current SOS phase of the ISOSK-means, for further performance enhancement, while reducing the algorithm run time. The real-life application of the proposed improved hybrid algorithm is another area of research that could be exploited. Using other cluster validity indices in implementing this algorithm would also be an interesting area for future research.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}