1. Introduction
Relation classification [
1,
2] is an important task in natural language processing. In natural language processing task architectures, relational classification is an important antecedent between tasks, such as document summarization [
3], question-and-answer systems [
4], machine translation [
5], and knowledge graphs [
6]. The relationship classification task is a supervised task. The main objective is to extract relation information from a sentence with an entity identifier, determine the relationship between two entities in a sentence, and classify the relationship. Take the sentence in
Table 1 as an example, the sentence includes <
>, </
>, <
>, </
>, which are four position markers. Tags are used to mark the exact location of entities in a sentence. The example sentence is labeled with two entities “elephant” and “animal”. The task of relationship classification is to identify the relationship between the two entities as entity-origin(
,
).
Earlier traditional methods of relational classification used kernel-based approaches [
7,
8,
9]. Kernel-based algorithms mainly include support vector machine (SVM), radial basis function (RBF), and linear discriminate analysis (LDA). SVM is mainly used in relation classification tasks to classify entity relations. SVM is a classification model that solves binary classification problems through supervised learning. Such methods are of course helpful to improve the accuracy of relational classification tasks. However, SVM is based on the binary classification of the relationship based on the kernel function. Not all features can be divided according to the kernel function. When the relationship between entities is complex or there are multi-category relationships between entities, the error probability will increase. Therefore, the kernel-based relationship classification method has problems, such as a high error rate, low classification accuracy, and serious feature loss. Relational classification methods based on neural networks and deep learning have become a hot issue for research in recent years [
10]. Such methods require only simple pre-work or even methods without pre-work for automatic learning of feature parameters, such as convolutional neural network (CNN), recurrent neural network (RNN), and long short-term memory network (LSTM), and neural networks based on attention mechanisms. In recent years, research has mainly been based on CNN and RNN-based relationship classification models. Such models typically use the traditional form of mapping literals to vectors. After the pre-training model was published, the focus of research gradually shifted to the pre-training model. The latest models basically use the feature output by the pre-trained model for downstream tasks. However, when using the pre-training model, the feature output of the last layer is habitually used for tasks, resulting in the importance of shallow features being ignored. The above model surpasses the traditional model in terms of relational classification effect but still has the following problems.
First, the shallow features are ignored. The existing models [
11,
12,
13,
14] retain only the deep features extracted by the neural network. Deep features have rich semantic information and are more suitable for performing relational classification tasks. However, shallow-level features have richer fine-grained features and clearer location information [
15]. The shallow information can be used as auxiliary information in the classification network to enhance the effective part of the deep features.
Second, only the semantic information of whole sentences is extracted and analyzed in existing networks. In this paper, we argue that in addition to the overall features of the whole sentence, the features corresponding to each entity are also important for the relational classification task. By fitting the feature vectors corresponding to the two entities to the overall vector of the whole sentence, in-depth, not only the quality of the features can be improved, but also the influence of irrelevant words in the sentence on the classification network can be weakened. In response to the above issues and challenges, the main contributions of this paper can be summarized as follows:
(1) In this paper, we propose a model FA-RCNet for relational classification tasks to improve the effectiveness of relational classification models through feature fusion and channel attention mechanisms.
(2) A feature fusion module is proposed to combine different hidden layer features in the BERT model with sentence features, realize the combination of shallow fine-grained features and deep abstract features, and further enrich the semantic information in the feature vector.
(3) An attention module is proposed. This attention module analyzes the importance of each semantic feature. Weights are assigned according to the degree of importance to enhance the role of important semantic information in the model and reduce the negative impact of irrelevant semantic noise on the model.
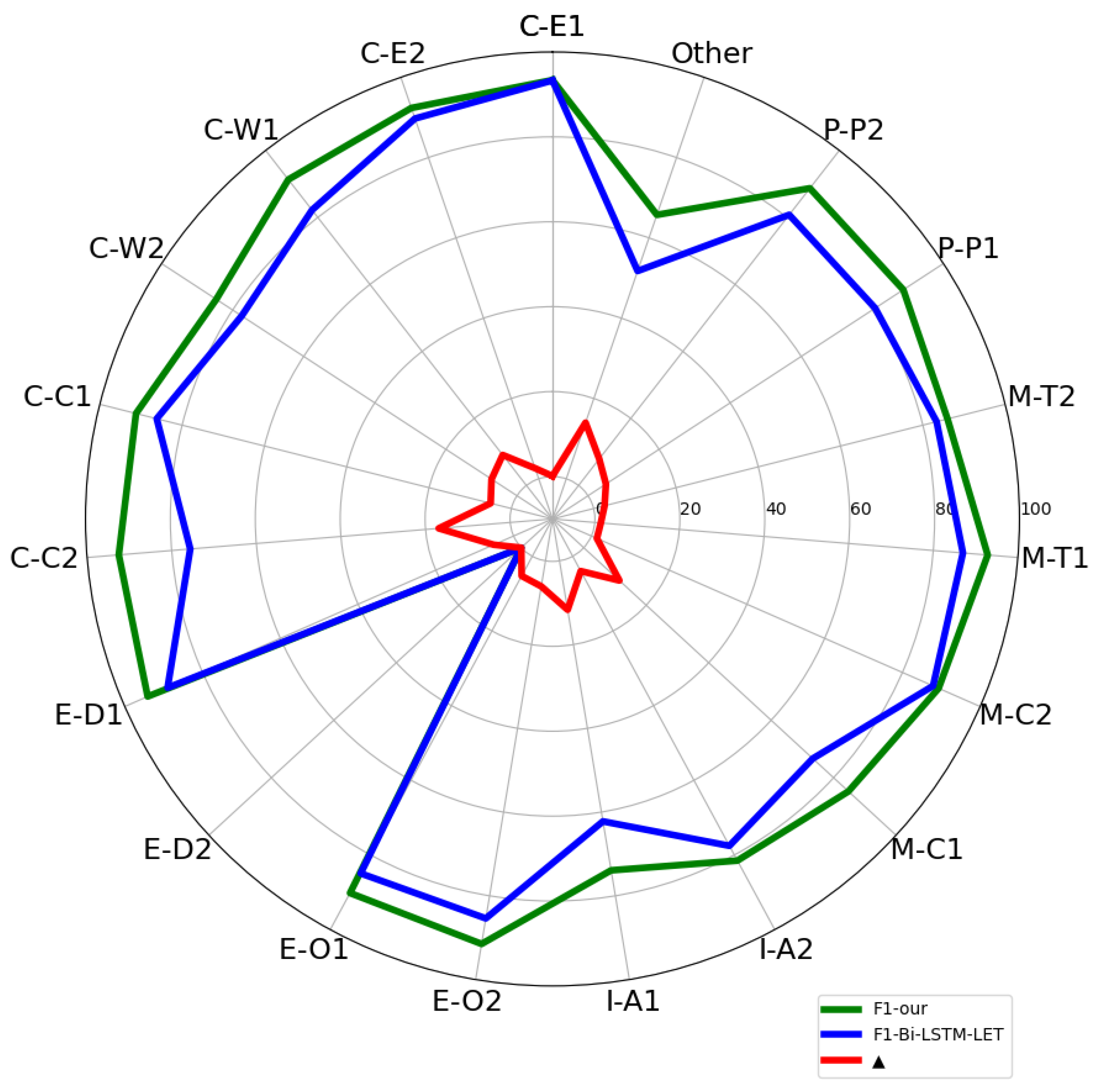
(4) Through experimental tests, the relationship classification model proposed in this paper achieves good results on the SemEval-2010 Task8 dataset and the KBP37 dataset. The accuracy of recognition in different directions of the same relationship was also improved on the SemEval-2010 Task8 dataset.
The remainder of this paper is structured as follows.
Section 2 provides an overview of the work involved.
Section 3 presents the general architecture and details of the relational classification model proposed in this paper. The data set, hyperparameters, and environment of the experiments, as well as the experimental results and analysis, are given in
Section 4.
Section 5 provides a summary and outlook on the work of this paper.
3. Methodology
The most recent relational classification models use BERT, a pre-trained model, for sentence feature extraction. Then the sentence features are further processed to obtain the classification probability for performing classification tasks. The BERT pre-trained model is applied to a variety of downstream tasks in natural language processing including relational classification. BERT-GMAN [
11] proposed a relationship extraction model based on BERT-gated multi-window attention network, which achieved good results in the Semeval-2010 Task 8 dataset. BertSRC [
42] proposed to extract the entity relationship in the medical field based on BERT and achieved good results in the data set of the proprietary field. AugFake-BERT [
43] proposes a BERT-based data augmentation model. Using the enhanced data set for model training can obtain better model weights. CRSAtt [
44] proposes a BERT-based relation classification model. CRSAtt processes BERT output features by fusing sentences and entity features. At the same time, the attention mechanism is used instead of the fully connected layer to predict the relationship category. The above work proves the effectiveness of the features extracted by BERT for downstream tasks, so this paper uses BERT as the feature extraction module. Since the attention mechanism was proposed, it has achieved good results in many fields. In computer vision tasks, the visual attention mechanism [
45,
46] can make the model better notice the key information in the picture. In natural language processing tasks, the attention mechanism [
44,
47,
48] can analyze the relationship between each word in the text and words of different parts of speech through the attention mechanism. The purpose of this is to obtain higher-quality semantic features. Therefore, this paper uses the attention mechanism to further process the feature vector.
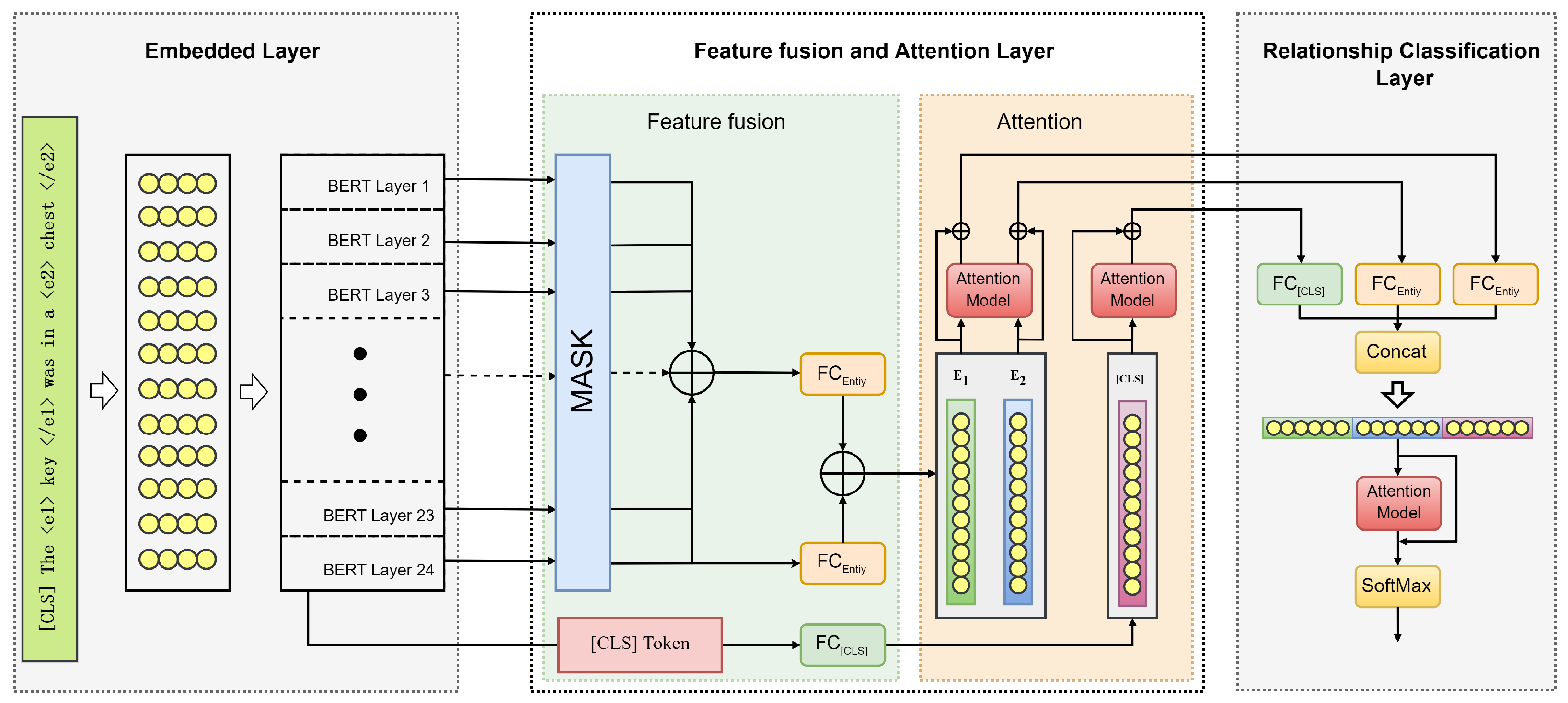
3.1. Overview
In this section, a three-layer FA-RCNet is proposed to solve the relationship classification task in NLP. The first layer is the embedding layer. It is used to form word embedding information after fusing word embedding, positional embedding and segmentation embedding of the sentence. The second layer is the feature fusion and attention module. The role is to fuse the feature vectors of each layer of the preprocessing model. At the same time, the attention module captures the rich relational features in the semantic information. The feature weights corresponding to the relationships between entities in the semantic features are increased. The third layer is the relationship classification layer. The entity feature outputs from the second layer are spliced with the global features. The weight of positive features is enhanced by the attention module. Moreover, the negative impact of negative features on classification accuracy is reduced.
Figure 1 shows the general framework of the FA-Net model. The definitions of the symbols used in this paper are shown in
Table 2.
3.2. Embedded Layers
In the embedding layer, the data in the dataset are preprocessed and the two entities in the sentence are annotated by “$” and “#”, respectively. For example, in the following sentence, entity I corresponds to “woman” and entity II corresponds to “village”.
The $ woman $ was born in the # village #.
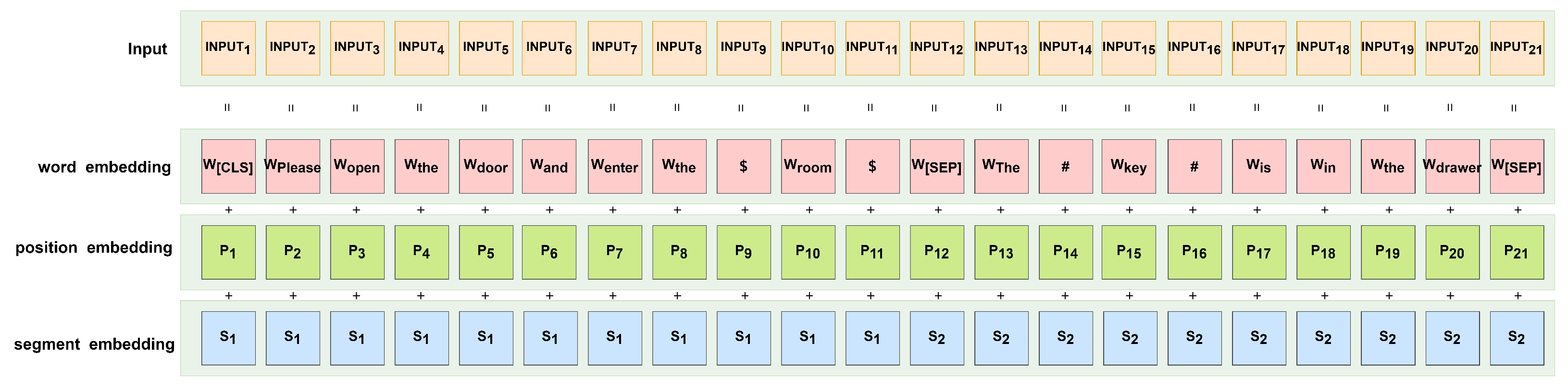
The pre-processed data are embedded by word embedding, location embedding, and segmentation embedding to obtain the embedding vector. The role of word embedding is to convert the text into vectors. The text information is fed into the feature extraction model in the form of vectors. In this paper, word embeddings obtained from pre-training are used. It was shown that word embeddings obtained by training with unlabeled samples have better results than randomly generated word embeddings in the task of relation extraction and relation classification [
35].
The word embedding contains only the information corresponding to a word and does not record the information on the position of the word appearing in the sentence. In this paper, each sentence as a whole is numbered sequentially from 0 according to the order of word occurrences in the sentence. This allows the position of words in the sentence to be mapped to numbers. The order of the numbers by their size enables the model to accurately identify the position of the words in the sentence.
In a practical relational classification task, two entities may appear in two sentences. The same entity in two sentences may have an impact on the meaning of the entities. Even the different order of appearance of two entities in a sentence may have this problem. In this case, it is necessary to use split embedding to distinguish the two sentences. The purpose is to allow the model to obtain an accurate correspondence between entities and clauses.
Figure 2 shows the flow of the embedding layer.
3.3. Feature Fusion and Attention Layers
After receiving the word embeddings from the output of the embedding layer, the input word vectors are feature extracted using a pre-trained BERT model. Receive the hidden layer output from each layer of the BERT module. Extraction of two entity vectors from the hidden layer output by the mask matrix. The entity vectors from each layer are fused and sent to the attention module, with the aim of increasing the feature weights corresponding to the relationship between the two entities in the feature vectors by the attention module.
3.3.1. Feature Fusion Layer
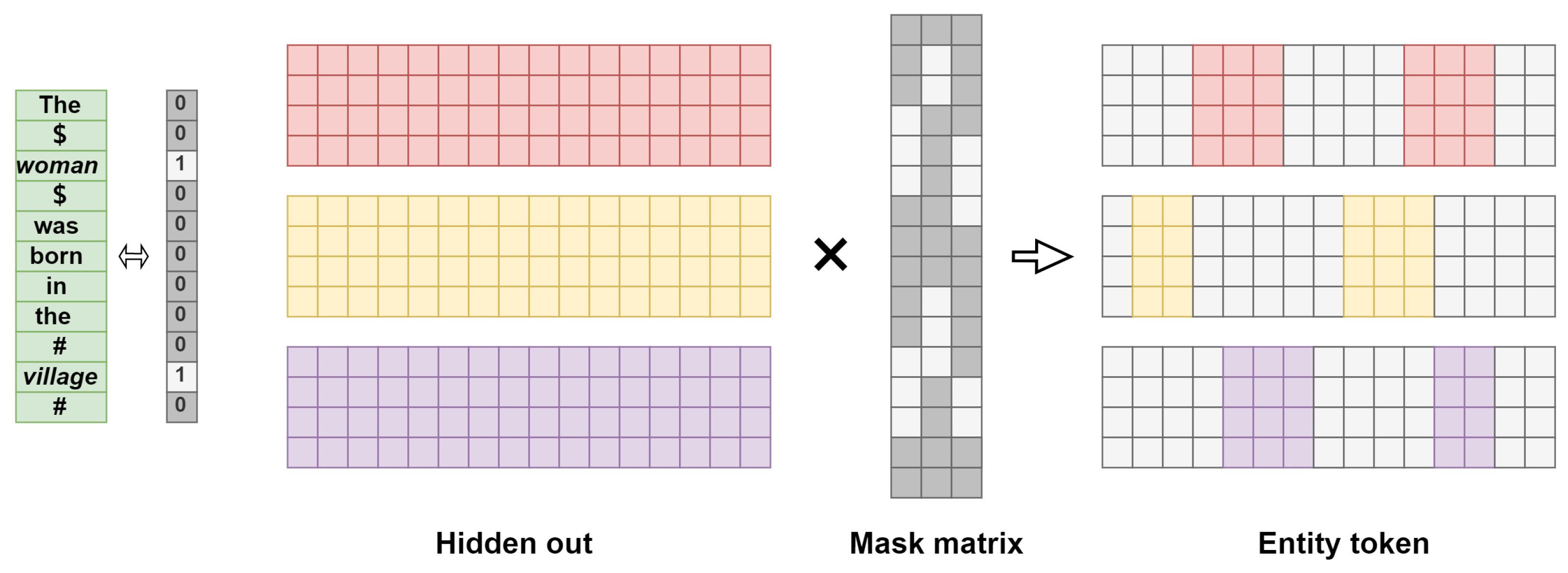
The word vectors output from the embedding layer are trained by BERT to produce a hidden layer output
at each layer. The mask matrix consists of 0s and 1s and is generated automatically by reading the entity identifiers “
$” and “#” in the sentence. The number of the position corresponding to the vector between two markers is 1, indicating retention, and the number of all positions outside the vector corresponding to the two entities is 0, indicating discard.
Figure 3 shows the Mask operation flow.
Hidden out is the output of the hidden layer of the BERT model. The mask matrix is the mask matrix for entity feature extraction. The entity token is the set of entity vectors obtained after the mask matrix.
One entity may correspond to more than one word, so one entity may correspond to more than one hidden layer output. Taking the first hidden layer output as an example, the hidden layer outputs corresponding to two entities in a sentence are extracted from
by Mask matrix. This process is expressed mathematically as Equation (
1):
where
–
and
–
can be represented as the set of vectors corresponding to entity I and entity II in the first hidden layer.
and
denote the first and last elements in the output of the hidden layer.
and
denote the first and last elements of the mask matrix.
The set of vectors obtained by extraction is averaged to obtain the feature vectors corresponding to the two entities in the first hidden layer. The 24 hidden layer outputs of the BERT model are masked and averaged separately. The 24 feature vectors are obtained for each of the two entities. In order to make full use of the deep semantic information and the shallow semantic information in the hidden layer output, the sum operation is applied to these 24 feature vector pairs. This allows the semantic information contained in the output of each hidden layer to be combined. The combined vectors are all applied to the word vector generation process. This process can be expressed mathematically as Equations (
2) and (
3):
where
is the feature sum corresponding to entity I;
is the feature sum corresponding to entity II;
-
is the starting position of the feature vector corresponding to entity I at layer a; and
-
are the starting and ending positions of the feature vector corresponding to entity II at layer a.
In the previous relational classification models, only the hidden state output of the last layer or the last two layers of the BERT model was used for relational classification tasks, such as R-bert, etc. It is shown that the deeper feature vectors contain more semantic information and are more suitable for relational classification tasks, so the hidden state of the last layer is output separately as the first feature enhancement module. The classification task requires not only the semantic features of the two entities but also the global features of the whole sentence. In this paper, the global features of the whole sentence are output separately as the second feature enhancement module. An activation function is added to the fused features , , the last layer of the hidden state outputs , , and the global feature vector , respectively. A fully connected layer is also connected.
The fusion vector is passed through the fully connected layer to produce a semantic feature vector. The final layer of hidden state output is passed through the fully connected layer to produce a semantic feature vector. The above two are added together to obtain a fusion feature that is more suitable for the classification task. This feature is a feature vector (
and
) that focuses on deep semantics and fuses shallow sub-semantics.
and
are sent to the attention module for further feature extraction along with
generated by the global feature vector after the fully connected layer. The above process can be expressed as Equations (
4)–(
6) using the mathematical formula.
where
and
are the fused feature vectors after the fully connected layer.
and
are the feature vectors of the last hidden layer output after the fully connected layer.
is the global feature vector of the fully connected layer output.
(
i =
,
,
,
,
) is the weight matrix in the fully connected layer.
(
i =
,
,
,
,
) is the bias term in the fully connected layer.
3.3.2. Attention Layers
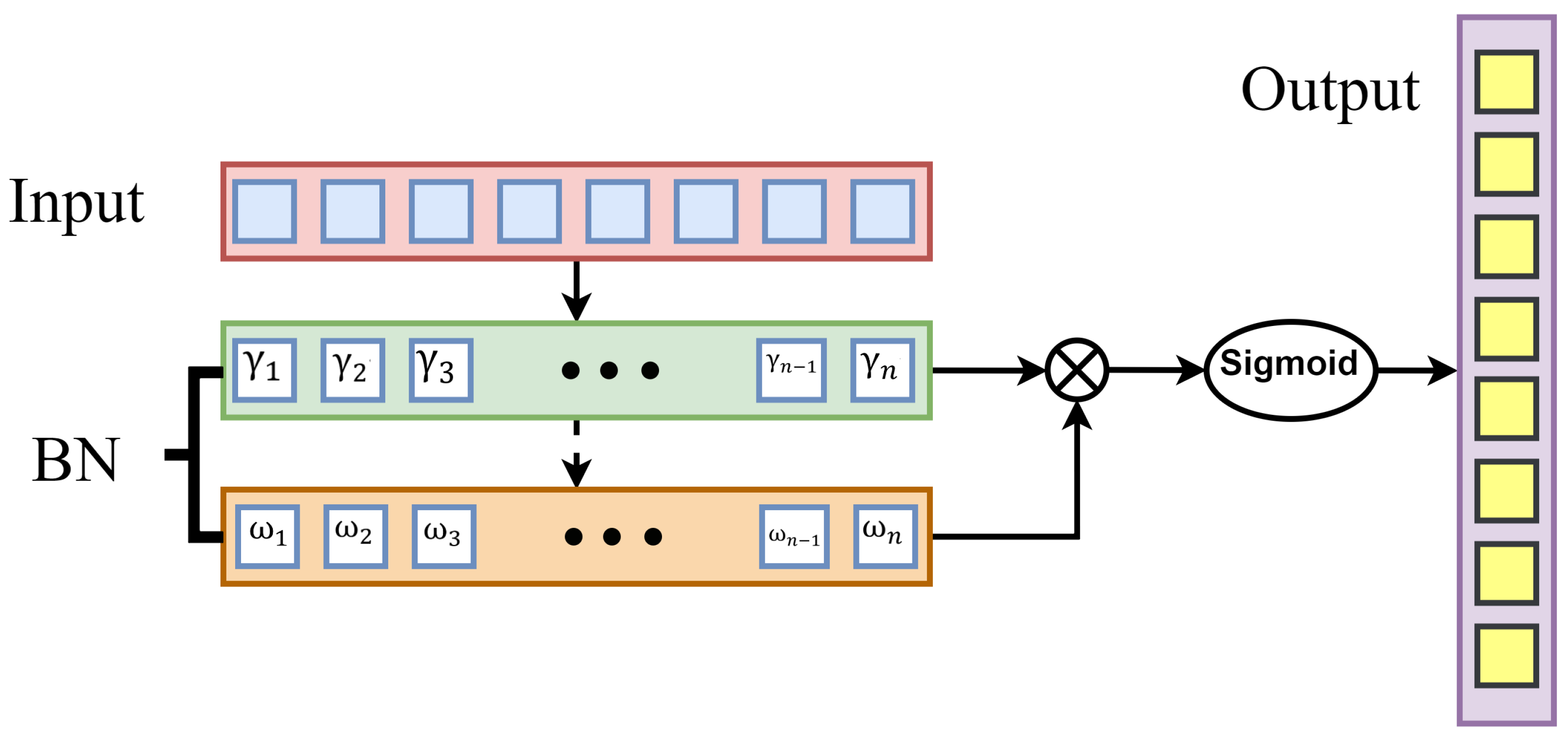
The attention modules used in existing relational classification models are all attention mechanisms based on encoder and decoder structures. The weight of each feature is determined by querying the similarity between the features. For the relational classification task, most of the features are extracted using the attention mechanism for all words in a sentence. However, the classification task is the discrimination of the relationship between two entities. Using the above attention mechanism weakens the relationship weights between two entities. To solve the above problem, the feature amplification attention module is proposed in this paper. The mean and variance in a feature vector are calculated and the importance of the feature vector is determined by the scale factor in the BN [
49,
50] mechanism. The feature values are also normalized in the linear part of the nonlinear function. The feature values are then scaled by a weight scaling factor
. The purpose is to allow positive features to be feature-enhanced and negative features to be suppressed. This process can be expressed mathematically as Equation (
7):
where
and
are trainable affine transform parameters.
is the input to the BN layer.
is the output of the BN layer.
is the mean of the elements in a feature vector.
is the variance of the elements in a feature vector with a constant
> 0 to ensure that it does not divide by zero.
Figure 4 shows the feature amplification attention module.
In feature amplification attention, the feature vector of a single entity and the global feature vector containing the contextual information of the whole sentence are fed into the attention module, and each element of the feature vector is mapped to a single feature value. Through the attention mechanism, not only the important features in the global feature can be amplified to make the contextual information richer, but also the relationship between two entities can be better fitted. This not only preserves more positive semantic information but also enhances the sensitivity of the model to the directionality of the relationship due to the further enrichment of contextual information.
Meanwhile, an attention residual module is designed in this paper. The input and output of the attention module are added with the purpose of further increasing the weights of the effective features while retaining the original features. In this way, all features can be involved in the subsequent learning and updating of the network. Another role of the residual network is to effectively avoid the problems of gradient explosion and gradient disappearance when the number of layers of the neural network increases. The above process can be expressed as Equations (
8)–(
10):
where
is the weight scaling factor.
and
are the fusion vectors of the two entities output by the feature fusion module.
is the feature vector corresponding to [CLS]. Sigmoid is the nonlinear activation function.
,
, and
are the fusion vectors of the two entities with [CLS] corresponding to the attentional output.
,
, and
correspond to the attentional input, respectively.
3.4. Relationship Classification Layer
The relational classification layer receives three outputs from the attention module. A tanh nonlinear activation function is added and a fully connected layer is connected, respectively. The fully-connected layer maps the feature space computed by the first two layers of the network to the feature space of the dataset samples. The purpose is to reduce the impact of feature positions on the results of the relational classification task. The robustness of the network is improved. This process is expressed mathematically as Equations (
11)–(
13):
where
,
, and
are the feature vectors corresponding to entity I, entity II, and [CLS] tokens output from the attention layer, respectively,
,
, and
are the learnable parameter matrices, tanh is the nonlinear activation function, and
(
i =
,
,
) is the bias term.
In this paper, the feature vector outputs from the fully connected layer are concatenated. The tandem vector connects a feature amplification attention module with the residual structure. The purpose is to extract the association features in entities and sentences to further strengthen the semantic connection between entities and sentences. The features that identify the relationship between two entities are given greater weights. A softmax layer is connected after the attention module, which is used to map the extracted feature vectors to the number of relations. Finally, the probability value corresponding to each category is obtained, by virtue of which the entity relations are classified. This process can be expressed mathematically as Equations (
14) and (
15):
where
,
,
are the output feature vectors of the fully connected layer.
T is the tandem vector. Sigmoid is the nonlinear activation function. Softmax is the classifier.
5. Conclusions and Future Work
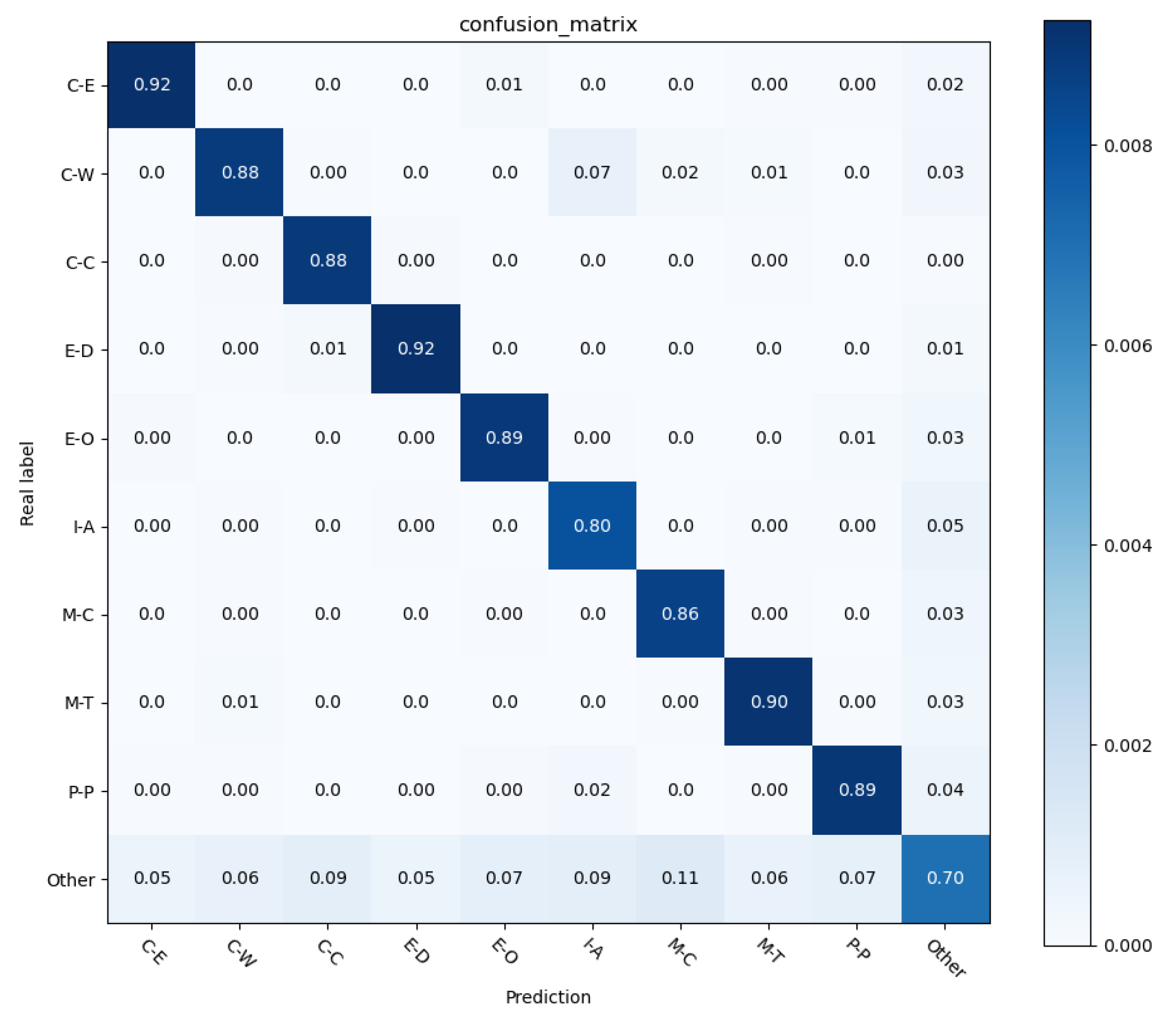
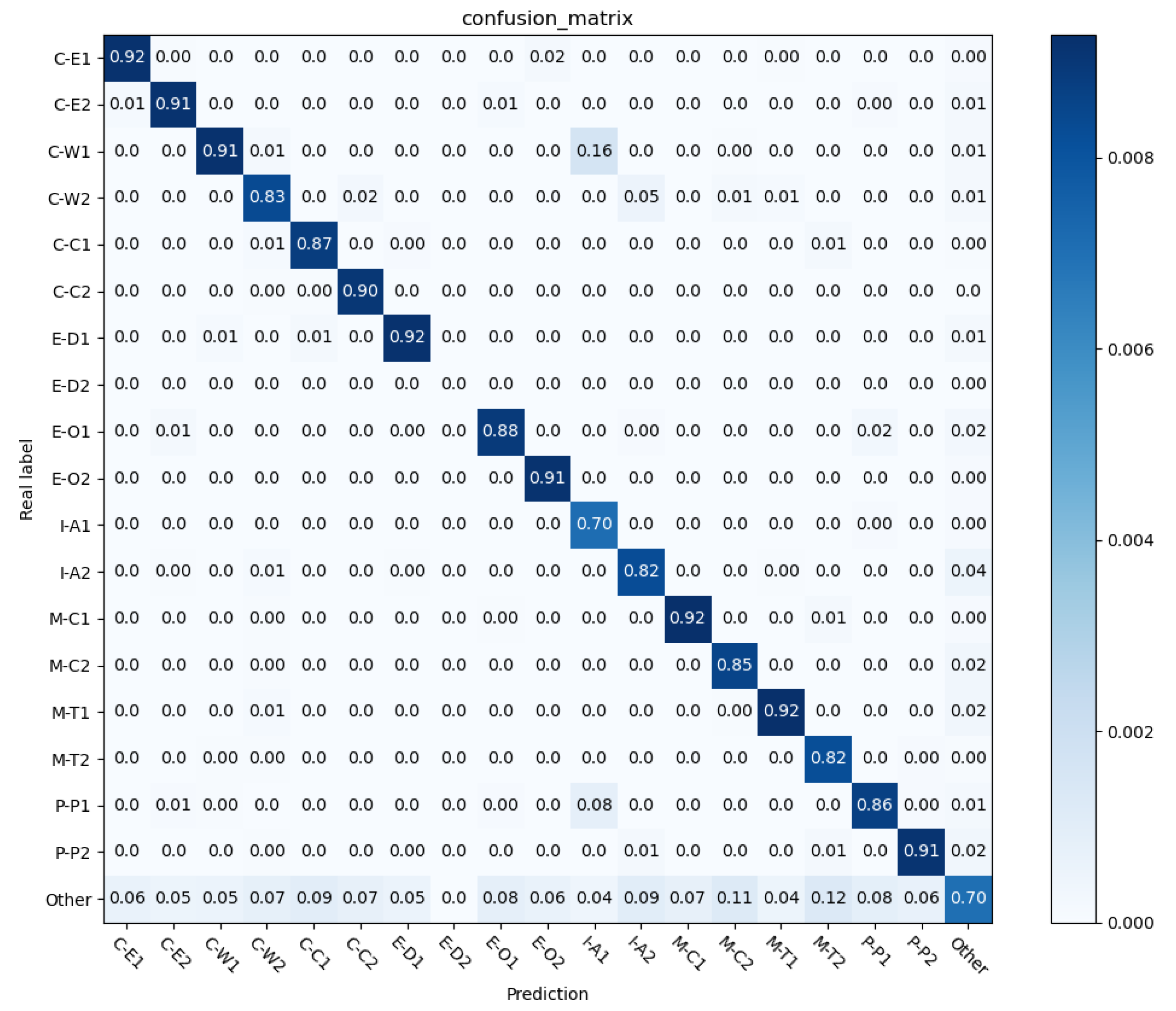
In this paper, a new FA-RCNet entity relationship classification model is proposed. The study found that the shallow information of the BERT model also has a positive effect on the relationship classification task. Therefore, the FA-RCNet model fuses the feature outputs of different levels of the BERT pre-training model. A fusion feature containing shallow semantic information and deep semantic information is formed. Improving the accuracy of subsequent relation classification tasks by fusing rich features in features. At the same time, a feature amplification attention module is designed to amplify the positive features and suppress the negative features in the semantic features. Through this operation, the effect of highlighting positive features is achieved. The formed semantic features can further improve the accuracy of relation classification tasks. At the same time, the experiments of FA-RCNet on the SemEval-2010 Task 8 and KBP37 data sets show that the performance of the FA-RCNet model is better than those of the existing methods, and the F1 values reach 90.33% and 69.95%, respectively. Ablation experiments on two datasets show that different modules in the FA-RCNet model have positive effects on relation classification tasks.
In addition, we believe that the FA-RCNet model is still insufficient in dealing with multi-entity relationship problems. The model can only recognize two entities in a sentence, which is determined by the mask matrix that extracts entity features. When there are multiple entities in a sentence, there may be a problem that the relationship between a certain pair of entities cannot be identified. In addition, when there are multiple relationships between two entities, the model in this paper can usually only identify the relationship with a higher probability, and cannot accurately identify all of them. This is the problem with our model.
In future work, we will continue to conduct research on how to dynamically generate the mask matrix according to the data format in the dataset to realize the relationship extraction between multiple entities. At the same time, we will look into how to introduce external information in the feature fusion stage to accurately identify the various relationships between entities.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}