
Late-Stage Optimization of Modern ILP Processor Cores via FPGA Simulation


Abstract
:1. Introduction
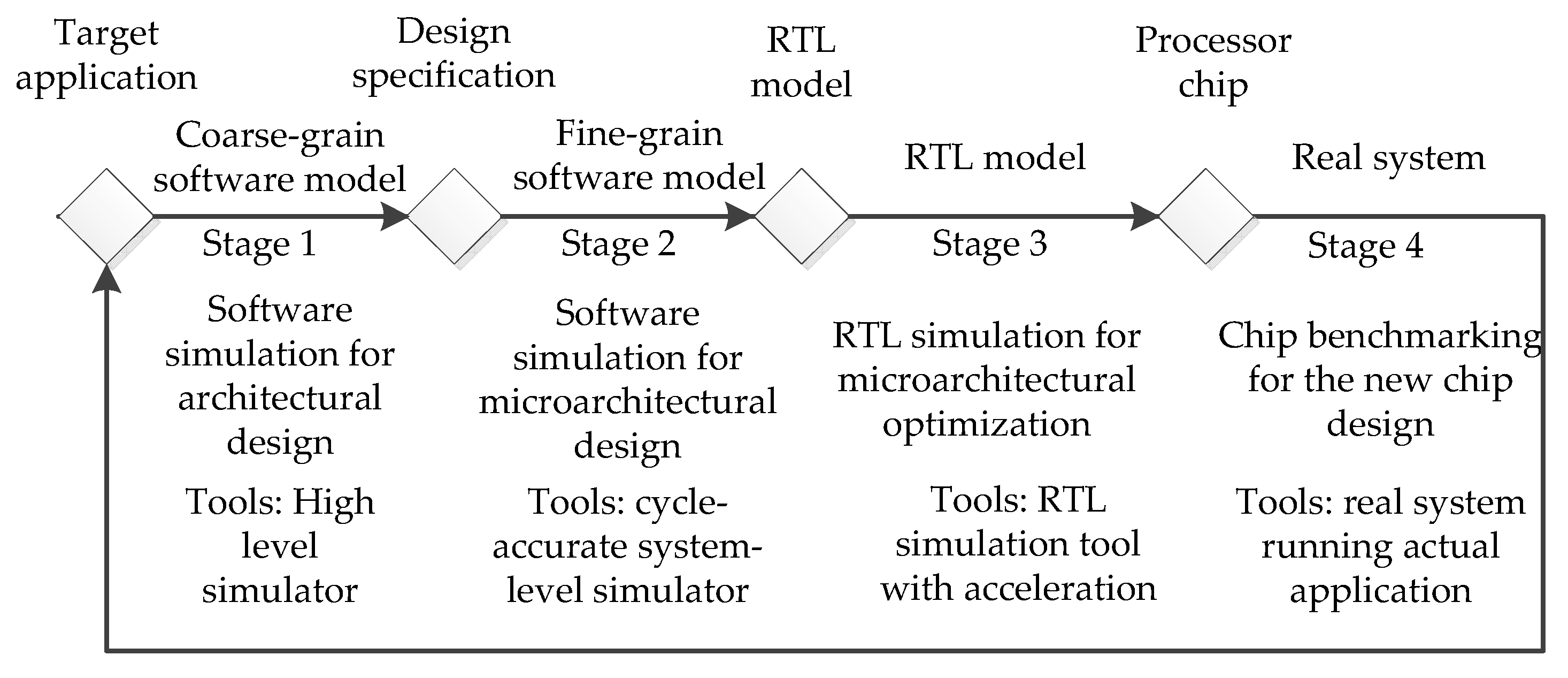
2. Conventional Processor Design Flow
3. FPGA-Enhanced Design Flow
3.1. Categorization Decision Method for Early- and Late-Stage
3.2. Late-Stage Aware RTL Design
3.3. RTL Design Categories
4. FPGA Implementation
4.1. PNX Processor Architecture
4.2. FPGA System
4.2.1. Performance Optimization
4.2.2. Simulation Accuracy
4.2.3. Design Space Exploration
5. Evaluation
5.1. FPGA Implementation Results
5.2. Late-stage Optimization Case Studies
5.2.1. L2 Cache Parameter (PAR)
5.2.2. Pipeline Parameter Exploration (PAR/lMAX/MIN)
5.2.3. FIFO Configuration Analysis (PAR)
5.3. Early- and Late-Stage Optimization Walkthrough Case Study
5.3.1. Early-Stage Optimization
5.3.2. Late-Stage Optimization
6. Related Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Perais, A.; Seznec, A. BeBoP: A Cost Effective Predictor Infrastructure for Superscalar Value Prediction. In Proceedings of the EEE 21st International Symposium on High Performance Computer Architecture (HPCA), HPCA ’15, Burlingame, CA, USA, 7–11 February 2015; pp. 13–25. [Google Scholar] [CrossRef] [Green Version]
- Eyerman, S.; Heirman, W.; Steen, S.; Hur, I. Enabling Branch-Mispredict Level Parallelism by Selectively Flushing Instructions. In Proceedings of the 54th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Virtual Event, Greece, 18–22 October 2021; pp. 767–778. [Google Scholar]
- Akram, A.; Sawalha, L. A Survey of Computer Architecture Simulation Techniques and Tools. IEEE Access 2019, 7, 78120–78145. [Google Scholar] [CrossRef]
- Austin, T.; Larson, E.; Ernst, D. SimpleScalar: An Infrastructure for Computer System Modeling. Computer 2002, 35, 59–67. [Google Scholar] [CrossRef] [Green Version]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The Gem5 Simulator. SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Lu, S.L.L.; Yiannacouras, P.; Kassa, R.; Konow, M.; Suh, T. An FPGA-based Pentium in a Complete Desktop System. In Proceedings of the 2007 ACM/SIGDA 15th International Symposium on Field Programmable Gate Arrays, FPGA ’07, Monterey, CA, USA, 18–20 February 2007; ACM: New York, NY, USA, 2007; pp. 53–59. [Google Scholar]
- Wang, P.H.; Collins, J.D.; Weaver, C.T.; Kuttanna, B.; Salamian, S.; Chinya, G.N.; Schuchman, E.; Schilling, O.; Doil, T.; Steibl, S.; et al. Intel® Atom™ Processor Core Made FPGA-Synthesizable. In Proceedings of the ACM/SIGDA International Symposium on Field Programmable Gate Arrays, FPGA ’09, Monterey CA, USA, 22–24 February 2009; ACM: New York, NY, USA; pp. 209–218. [Google Scholar]
- Asaad, S.; Bellofatto, R.; Brezzo, B.; Haymes, C.; Kapur, M.; Parker, B.; Roewer, T.; Saha, P.; Takken, T.; Tierno, J. A Cycle-accurate, Cycle-Reproducible multi-FPGA System for Accelerating Multi-Core Processor Simulation. In Proceedings of the ACM/SIGDA International Symposium on Field Programmable Gate Arrays, FPGA ’12, Monterey, CA, USA, 22–24 February 2012; ACM: New York, NY, USA, 2012; pp. 153–162. [Google Scholar]
- Asaad, S. Modeling, Validation, and Co-design of IBM Blue Gene/Q: Tools and Examples. IBM J. Res. Dev. 2013, 57, 67–77. [Google Scholar]
- Schelle, G.; Collins, J.; Schuchman, E.; Wang, P.; Zou, X.; Chinya, G.; Plate, R.; Mattner, T.; Olbrich, F.; Hammarlund, P.; et al. Intel Nehalem Processor Core Made FPGA Synthesizable. In Proceedings of the 18th annual ACM/SIGDA International Symposium on Field Programmable Gate Arrays, FPGA ’10, Monterey, CA, USA, 21–23 February 2010; ACM: New York, NY, USA, 2010; pp. 3–12. [Google Scholar]
- Vyazigin, S.; Dyusembaev, A.; Mansurova, M. Emulation of x86 Computer on FPGA. In Proceedings of the IEEE 8th Workshop on Advances in Information, Electronic and Electrical Engineering (AIEEE), Vilnius, Lithuania, 22–24 April 2021; pp. 1–6. [Google Scholar]
- Harris, S.L.; Chaver, D.; Piñuel, L.; Gomez-Perez, J.; Liaqat, M.H.; Kakakhel, Z.L.; Kindgren, O.; Owen, R. RVfpga: Using a RISC-V Core Targeted to an FPGA in Computer Architecture Education. In Proceedings of the 31st International Conference on Field-Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021; pp. 145–150. [Google Scholar]
- Karandikar, S.; Mao, H.; Kim, D.; Biancolin, D.; Amid, A.; Lee, D.; Pemberton, N.; Amaro, E.; Schmidt, C.; Chopra, A.; et al. FireSim: FPGA-Accelerated Cycle-Exact Scale-Out System Simulation in the Public Cloud. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018; pp. 29–42. [Google Scholar] [CrossRef]
- Biancolin, D.; Magyar, A.; Karandikar, S.; Amid, A.; Nikolić, B.; Bachrach, J.; Asanović, K. Accessible, FPGA Resource-Optimized Simulation of Multiclock Systems in FireSim. IEEE Micro 2021, 41, 58–66. [Google Scholar] [CrossRef]
- Karandikar, S.; Ou, A.J.; Amid, A.; Mao, H.; Katz, R.H.; Nikolic, B.; Asanovic, K. FirePerf: FPGA-Accelerated Full-System Hardware/Software Performance Profiling and Co-Design. In Proceedings of the ASPLOS ’20: Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; Larus, J.R., Ceze, L., Strauss, K., Eds.; ACM: New York, NY, USA, 2020; pp. 715–731. [Google Scholar] [CrossRef] [Green Version]
- Martínez, J.; Bazegui, C.; Renau, J. SCOORE: Santa Cruz Out-of-Order RISC Engine, FPGA Design Issues. In Proceedings of the Workshop on Architectural Research Prototyping (WARP), Held in Conjunction with ISCA-33, WARP ’06, Portland, OR, USA, 14 June 2006; pp. 61–70. [Google Scholar]
- Tan, Z.; Waterman, A.; Cook, H.; Bird, S.; Asanović, K.; Patterson, D. A Case for FAME: FPGA Architecture Model Execution. In Proceedings of the 37th Annual International Symposium on Computer Architecture, ISCA ’10, Saint-Malo, France, 19–23 June 2010; ACM: New York, NY, USA, 2010; pp. 290–301. [Google Scholar]
- Dwiel, B.H.; Choudhary, N.K.; Rotenberg, E. FPGA Modeling of Diverse Superscalar Processors. In Proceedings of the 2012 IEEE International Symposium on Performance Analysis of Systems & Software, ISPASS ’12, New Brunswick, NJ, USA, 1–3 April 2012; IEEE Computer Society: Washington, DC, USA, 2012; pp. 188–199. [Google Scholar]
- LaForest, C.E.; Steffan, J.G. Efficient Multi-ported Memories for FPGAs. In Proceedings of the 18th Annual ACM/SIGDA International Symposium on Field Programmable Gate Arrays, FPGA ’10, Monterey, CA, USA, 21–23 February 2010; ACM: New York, NY, USA, 2010; pp. 41–50. [Google Scholar]
- Xilinx. Vivado Design Suite User Guide: Design Analysis and Closure Techniques. 2017. Available online: https://www.xilinx.com/support/documentation/sw_manuals/xilinx2017_2/ug906-vivado-design-analysis.pdf (accessed on 23 May 2019).
- Xilinx. Vivado Design Suite User Guide Hierarchical Design. 2014. Available online: http://www.xilinx.com/support/documentation/sw_manuals/xilinx2014_4/ug905-vivado-hierarchical-design.pdf (accessed on 17 January 2017).
- Tan, Z. Using FPGAs to Simulate Novel Datacenter Network Architectures At Scale; Technical Report; University of California: Berkeley, CA, USA, 2013. [Google Scholar]
- Seznec, A. A New Case for the TAGE Branch Predictor. In Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture, MICRO 44, Porto Alegre, Brazil, 3–7 December 2011; ACM: New York, NY, USA, 2011; pp. 117–127. [Google Scholar]
- Seznec, A.; Michaud, P. A case for (partially) TAgged GEometric History Length Branch Prediction. J. Instr.-Level Parallelism 2006, 8, 23. [Google Scholar]
- Chiou, D.; Sunwoo, D.; Kim, J.; Patil, N.A.; Reinhart, W.; Johnson, D.E.; Keefe, J.; Angepat, H. FPGA-Accelerated Simulation Technologies (FAST): Fast, Full-System, Cycle-Accurate Simulators; IEEE Computer Society: Washington, DC, USA, 2007; pp. 249–261. [Google Scholar]
- Casper, J.; Krashinsky, R.; Batten, C.; Asanovic, K. A Parameterizable FPGA Prototype of a Vector-Thread Processor. In Proceedings of the Workshop on Architecture Research Using FPGA Platforms, San Francisco, CA, USA, 13 February 2005. [Google Scholar]
- Wawrzynek, J.; Patterson, D.; Oskin, M.; Lu, S.L.; Kozyrakis, C.; Hoe, J.C.; Chiou, D.; Asanovic, K. RAMP: Research Accelerator for Multiple Processors. IEEE Micro 2007, 27, 46–57. [Google Scholar] [CrossRef] [Green Version]
- Wee, S.; Casper, J.; Njoroge, N.; Tesylar, Y.; Ge, D.; Kozyrakis, C.; Olukotun, K. A Practical FPGA-based Framework for Novel CMP Research. In Proceedings of the 2007 ACM/SIGDA 15th International Symposium on Field Programmable Gate Arrays, FPGA ’07, Monterey, CA, USA, 18–20 February 2007; ACM: New York, NY, USA, 2007; pp. 116–125. [Google Scholar]
- Pellauer, M.; Adler, M.; Kinsy, M.; Parashar, A.; Emer, J. HAsim: FPGA-based High-detail Multicore Simulation Using Time-division Multiplexing. In Proceedings of the 2011 IEEE 17th International Symposium on High Performance Computer Architecture, HPCA ’11, San Antonio, TX, USA, 12–16 February 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 406–417. [Google Scholar]
- Celio, C.; Chiu, P.F.; Nikolic, B.; Patterson, D.A.; Asanović, K. BOOM v2: An Open-Source Out-of-Order RISC-V Core; Technical Report UCB/EECS-2017-157; EECS Department, University of California: Berkeley, CA, USA, 2017. [Google Scholar]
- Wong, H.; Betz, V.; Rose, J. Microarchitecture and Circuits for a 200 MHz Out-of-Order Soft Processor Memory System. ACM Trans. Reconfig. Technol. Syst. 2016, 10, 7:1–7:22. [Google Scholar] [CrossRef]
- Mashimo, S.; Fujita, A.; Matsuo, R.; Akaki, S.; Fukuda, A.; Koizumi, T.; Kadomoto, J.; Irie, H.; Goshima, M.; Inoue, K.; et al. An Open Source FPGA-Optimized Out-of-Order RISC-V Soft Processor. In Proceedings of the 2019 International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019; pp. 63–71. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Method | Speed | Accuracy | Configurability | Design Efforts | Cost |
|---|---|---|---|---|---|---|
| Early-stage | Software simulator | Low (100 KHz–1 MHz) | Low | High | Very low | Low |
| Accelerated simulation | High (N/A) | Very low | High | Very low | Very low | |
| Late-stage | RTL software simulator | Very Low (100 Hz–10 KHz) | High | Medium | Medium | Low |
| RTL emulator | Media (500 KHz–2 MHz) | High | Medium | Medium | High | |
| FPGA simulator | High (4 MHz–80 MHz) | High | Medium | Medium | Medium | |
| Test chip (real chip) | Very High (500 MHz–2 GHz) | Very high | Low | Very high | Very high |
| Module | Parameter | Op-Type | RTL | Effort |
|---|---|---|---|---|
| FUs | Count | PT | MAX | H |
| opLat | VT | MIN | M | |
| issueLat | VT | MIN | M | |
| opclass | CT | IMP | M | |
| BPU | preType | PT | IMP | M |
| TableSize | VT | PAR | E | |
| BTBEntries | VT | PAR | E | |
| BTBTagSize | VT | PAR | E | |
| RASSize | VT | PAR | E | |
| LSU | LQEntries | VT | PAR | E |
| SQEntries | VT | PAR | E | |
| LFSTSize | VT | PAR | E | |
| SSITSize | VT | PAR | E | |
| Pipeline | fetchWidth | PT | MAX | M |
| fetchBufferSize | VT | PAR | E | |
| decodeWidth | PT | MAX | M | |
| dispatchWidth | PT | MAX | M | |
| issueWidth | PT | MAX | M | |
| commitWidth | PT | MAX | M | |
| squashWidth | PT | MAX | M | |
| trapLatency | VT | MIN | E | |
| backComSize | VT | PAR | E | |
| forwardComSize | VT | PAR | E | |
| numPhysIntRegs | VT | PAR | E | |
| numPhysFloatRegs | VT | PAR | E | |
| numIQEntries | VT | PAR | E | |
| numROBEntries | VT | PAR | E | |
| various latencies | VT | MIN | H | |
| Cache (L1I/D L2/L3) | hit_latency | VT | MIN | M |
| mshrs | VT | PAR | E | |
| tgts_per_mshr | VT | PAR | E | |
| size | VT | PAR | E | |
| assoc | PT | IMP | M | |
| write_buffers | VT | PAR | E | |
| prefetch_on_access | CT | IMP | M |
| Block | Unit | Configuration |
|---|---|---|
| Fetch block | Branch predictor | BTBEntries (2K), TableSize (4K), |
| RASSize (32), | ||
| IndirectPredictorSize (512), | ||
| preType (TAGE algorithm) | ||
| Ifetch | fetchBufferSize (32) | |
| Decode | decodeWidth (4) | |
| Out-of-order block | Rename | RenameMapTableSize (32), |
| RenameQueueSize (16) | ||
| Dispatch | DispatchQueueSize (12), | |
| RenameRegisterSize (128), | ||
| RegisterFilePortNum (12), | ||
| numROBEntries (128) | ||
| ALULatency (2), | ||
| Execution | Execution | FPLatency (adder: 3, multiplier: 4), |
| block | units | Load/StoreQueue (32) |
| SIMDUnitPresence (yes) | ||
| Cache | L1 ICache | TLBSize (L1I: 64, L1D: 64, |
| L2: 1K), pageSize (4K), | ||
| L1 DCache | Size (L1I: 32 KB, | |
| L1D: 32 KB, L2: 512 KB), | ||
| L2 Cache | prefetch_on_access (L1I: next-line | |
| L1D/L2: stride-based) |
| FPGA | Resource | Utilization | Available | % |
|---|---|---|---|---|
| FF | 899,632 | 5,065,920 | 17.8 | |
| LUT | 912,541 | 2,532,960 | 36.0 | |
| Memory LUT | 39,157 | 459,360 | 8.5 | |
| VU440 | I/O | 571 | 1456 | 39.2 |
| Block RAM | 1406 | 2520 | 55.8 | |
| Vivado | BUFG | 12 | 1440 | 0.8 |
| MMCM | 3 | 30 | 10.0 | |
| PLL | 3 | 60 | 5.0 |
| Parameter | Description | Range | Stage | Early-Stage | Late-Stage | Cost Impact |
|---|---|---|---|---|---|---|
| NT | Number of tagged components | 3∼5 | Early | 4 | - | High |
| LOGTi | Width of entry index for the sub-predictors | 6∼9 | Early | 9/8/8/9/9 | - | High |
| CW | Width of | 2∼3 | Early | 2 | - | Middle |
| UW | Width of u bit | 1∼2 | Early | 1 | - | Middle |
| TAGWi | Width of tag bits | 6∼12 | Early&Late | 10/10/10/10 | 8/8/10/10 | Middle |
| L(1) | The basic value of history length | 2∼7 | Early&Late | 4 | 7 | Low |
| The exponent of history length | 1.5∼3 | Early&Late | 3 | 2 | Low | |
| NB | Number of branches in a entry considered | 0∼4 | Early&Late | 2 | 2 | Low |
| ALT | Width of alternate prediction count | 4 | Early&Late | 4 | 3 | Low |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, M.; Huang, L.; Yang, L.; Ma, S.; Yan, R.; Wang, Y.; Xu, W. Late-Stage Optimization of Modern ILP Processor Cores via FPGA Simulation. Appl. Sci. 2022, 12, 12225. https://doi.org/10.3390/app122312225
Lan M, Huang L, Yang L, Ma S, Yan R, Wang Y, Xu W. Late-Stage Optimization of Modern ILP Processor Cores via FPGA Simulation. Applied Sciences. 2022; 12(23):12225. https://doi.org/10.3390/app122312225
Chicago/Turabian StyleLan, Mengqiao, Libo Huang, Ling Yang, Sheng Ma, Run Yan, Yongwen Wang, and Weixia Xu. 2022. "Late-Stage Optimization of Modern ILP Processor Cores via FPGA Simulation" Applied Sciences 12, no. 23: 12225. https://doi.org/10.3390/app122312225