1. Introduction
Human speech is a sophisticated signal that contains significantly more information than lexical words. Only 7% of the message is communicated by spoken words or verbal attitude; 38% is communicated by non-verbal vocal characteristics, which reflect emotional state; 55% is transmitted by facial expression [
1]. Non-linguistic information, such as emotional state, plays an essential role in human social interaction [
2].
In recent years, interaction with machines has become commonplace in various aspects, such as entertainment, security, and healthcare, due to tremendous technological progress [
3,
4,
5]. One of the most critical aspects of human–machine interaction is voice interaction. Despite developments that have been made, many of the current systems cannot express emotion and the resulting voice does not seem natural because of the lack of essential emotions.
Voice transformation (VT) intends to modify one or more characteristics of a speech signal without altering its linguistic content. It can be used to change a speaker’s speaking style, such as switching from neutral to emotional speech or mimicking a native speaker’s accent. VT can also be used to change the identification of the speaker by the voice conversion (VC) approach. VC seeks to modify the speech of a source speaker so that the output is viewed as a sentence spoken by a target speaker [
6]. Emotional voice conversion (EVC) is a subset of VT, which refers to converting the emotion from the source utterance to the target utterance without changing the linguistic information or speaker identity [
7,
8].
It is necessary for us to convey our intentions, feelings, and social attitudes through the emotional expression that we use in our everyday talking. Therefore, one of the most important aspects of speech synthesis is the generation of speech signals with designated emotional attributes [
7]. The interest in virtual assistants has grown due to advances in speech processing systems, dialogue systems, and natural language processing. The synthesis of emotional speech by machines bears enormous application potential, particularly in human–machine communication. People would feel more comfortable if the virtual assistant was emotionally controlled, giving it great commercial and social value. Devices such as Alexa, Cortana, and Siri are currently able to broadly synthesize speech, but not yet in different varieties of emotions [
8,
9]. A human-like speech interaction between humans and machines can be achieved through the ability of EVC to control synthetic speech emotion [
8].
EVC’s primary challenge is the low availability of training data, especially for under-resourced languages such as Arabic. Indeed, speech collection with emotion annotation necessitates the performance of the required emotions by trained specialists. Another difficulty is that people may disagree with the emotion that is being expressed. It is also challenging to assess emotion control mechanisms due to the subjectivity of speech [
7,
8]. There is relatively little progress in the field of EVC due to the complexities of emotional features.
Deep neural networks have enabled several EVC frameworks to achieve higher performance than frameworks based on conventional models. Recently, generative adversarial networks (GANs), with their different variants (e.g., cycle-consistent generative adversarial network (CycleGAN, StarGANs, etc.), and autoencoder are the most common techniques used in EVC frameworks [
1,
10].
There is a significant gap in the research between Arabic and other more widely disseminated languages such as English and Chinese. We might argue that studies on this topic are extremely rare and scarce, where we found only this study [
11] on emotional Arabic voice conversion (A-EVC). To the best of our knowledge, this is the first study on an Arabic emotional voice conversion (A-EVC) using StarGANv2-VC.
The lack of Arabic emotional databases, and the scarcity of studies in this field, represent a significant challenge in A-EVC. This work represents the starting point of our project. The primary goal is to answer the following questions: Is the performance of an A-EVC using a pre-trained automatic speech recognition (ASR) network and fundamental frequency (F0) models in another language possible? How good is the quality of the converted voice? To answer these questions, we performed an A-EVC using the StarGANv2-VC model [
12] and emotional Arabic speech corpus KSUEmotions [
13]. F0 and ASR models are trained in English using the CSTR’s VCTK Corpus (Centre for Speech Technology Voice Cloning Toolkit) [
14]. The remaining sections of this work are arranged as follows: The second section contains a literature review, while the third section discusses the StarGANv2-VC model. In
Section 4 and
Section 5, respectively, the details of the experiments and the evaluation are described.
Section 6 contains the conclusions.
2. Literature Review
Earlier studies on voice conversion primarily relied on parallel training data (parallel VC), referring to a pair of utterances with the same content but distinct emotions from the same speaker. Through the paired feature vectors, the conversion model learns a mapping from the source to the target emotion during training [
1,
6]. Many parallel VC studies adopt a sequence-to-sequence conversion method and encoder–decoder sequence-to-sequence architecture with an attention mechanism. Spectrum [
15], prosody features (F0 and energy contour) [
15,
16], spectral features [
17,
18], intensity [
16], and mel-spectrograms [
19] are extracted simultaneously from both the source and the target emotional voice. Deep bidirectional long short-term memory (DBLSTM) [
15], artificial neural networks (ANNs), deep belief networks (DBNs) [
17], dual supervised adversarial networks [
20], recurrent neural networks (RNN), and LSTM are used to propose emotional voice conversion frameworks for German, Telugu, Japanese, and English languages.
Many VC techniques (including those mentioned above) are part of the parallel VC method, which uses training data for the parallel vocalization pairs to learn to map. However, this method has two significant drawbacks: first, obtaining data, which is frequently time-consuming or impractical, and second, using time alignment, which most VC methods rely on but which occasionally fails and necessitates other time-consuming operations, such as pre-checking the exact or manual correction [
21].
As a solution to the parallel VC issues, a non-parallel VC that refers to the multi-emotion utterances that do not share the same lexical content across emotions [
1,
6] has been presented. Zhu et al. [
22] suggested a CycleGAN model for unpaired image-to-image translation that learns without paired samples. Many different non-parallel training data for the emotive VC framework are employed with the CycleGAN schema. Zhou et al. [
23] performed spectrum and prosody conversion based on CycleGAN, Shankar et al. [
24] presented a hybrid architecture that depends on a CycleGAN, and Liu et al. [
2] examined how effective the use of CycleGAN was for the Chinese emotional VC task. The fundamental frequency energy contour as well as the mel-frequency cepstral coefficients are the features that are utilized to carry out VC tasks [
2,
23,
24].
StarGAN schema was also applied for EVC. Kameoka et al. [
25] used StarGAN, which allows non-parallel many-to-many VC with no parallel utterances, transcriptions, or time-alignment procedures for speech generator training. Rizos et al. [
26] used a StarGAN similar to that described in [
25] to convert real emotional speech samples into various target emotions as a data augmentation method; it was then verified using a multi-class speech affect recognition test. Furthermore, Moritani et al. [
7] employed the same network architecture used in [
25]. They investigated how well StarGAN-VC can achieve non-parallel many-to-many EVC for Japanese phrases when applied only to spectral envelope transformation.
Hsu et al. [
27] developed a non-parallel VC system with a variational autoencoding Wasserstein GANs (VAW-GAN). Zhou et al. in [
28,
29] developed a speaker-independent EVC framework based on VAE-GAN [
27]. The main aim was to convert anyone’s emotion without needing parallel data. Gao et al. [
30] suggested an unsupervised non-parallel emotional speech conversion based on style transfer autoencoders. Their model is simple to use in real-world scenarios and does not require paired data, transcripts, or temporal alignment. In [
31], Cao et al. used another non-parallel emotional speech conversion method in the English language based on VAE-GAN by improved CycleGAN. Their results show that the submitted method outperforms their baseline [
30]. The submitted approach in [
32] is closest to the VAW-GAN in [
28], where they employed a similar encoder–decoder structure with a VAE encoder with some slight differences, but they operated on mel-spectrograms and trained with multilingual data. In another effort, Shankar et al. [
33] extracted contextual pitch and spectral information from parallel data as input features to train a highway neural network by using diffeomorphic curve registration for emotion conversion.
Elgaar et al. [
8] utilized the factorized hierarchical variational autoencoder to generate disentangled representations of emotion, hence substantially facilitating emotional VC. With a small amount of emotional speech data, Zhou et al. [
34] developed a novel two-stage training technique for sequence-to-sequence emotional VC for both spectrum and prosody.
Table 1 provides detailed information on previous studies in this field, illustrating the language, database, selected emotions, the model used, and evaluation metrics in each study.
In summary, there are no significant previous studies related to Arabic speech, as all previous studies were conducted primarily using the English language.
3. Method
The StarGAN v2 [
38] image-to-image translation model creates a mapping between several visual domains with a sufficient amount of variation in the output images and scalability over many domains using a single discriminator and generator. Using the same architecture as StarGAN v2, StarGANv2-VC [
12] converts voices by treating each speaker as a separate domain. In our work, we employed the same architecture as StarGANv2-VC [
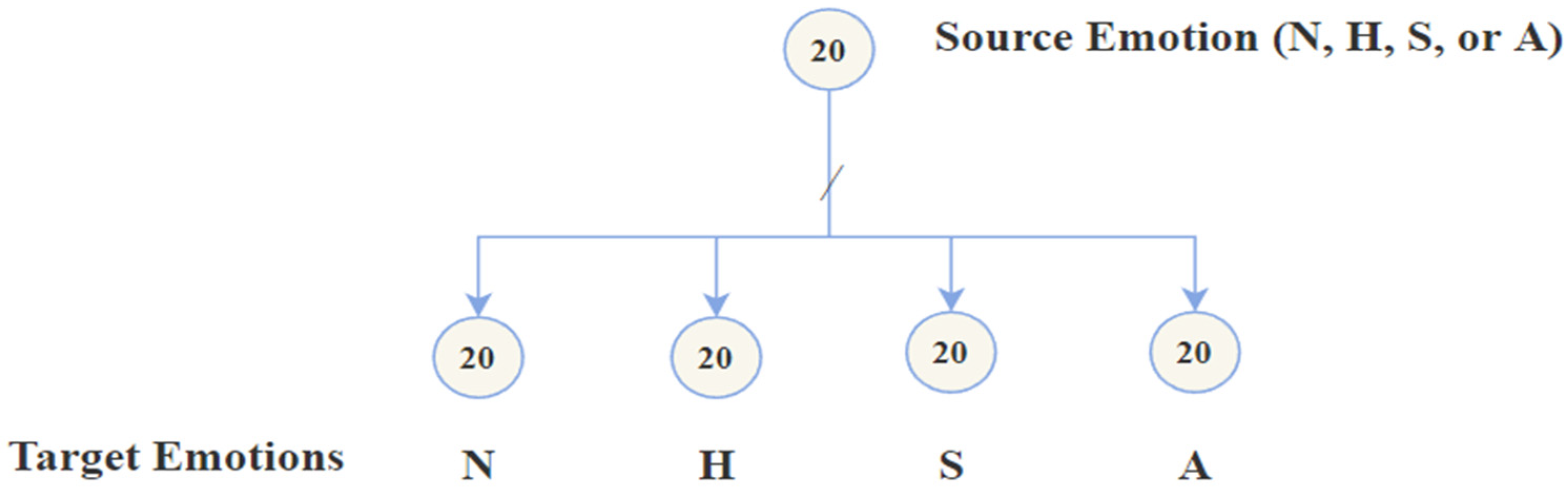
12] for emotional voice conversion and considered each of the following four emotions as a separate domain: neutral, happiness, sadness, and anger.
Figure 1 presents an overview of the starGANv2-VC framework, which contains a generator and a discriminator in addition to the F0 network, mapping network, and style encoder.
The generator receives an input mel-spectrogram and the fundamental frequency in is converted into output (, , ) reflective of a domain-specific style code either by the style encoder or the mapping network. The primary objective of the F0 network is to extract the from a mel-spectrogram input, while the mapping network generates a style vector for domain-specific style code and shares for all domains until the last layer is accessed with a random latent code. The latent coding is sampled from a Gaussian distribution to generate diverse style representations across all domains. The style encoder extracts the style code for a domain-specific style code and shares it across all domains. Discriminator comprises two classifiers that learn the original domain of changed samples. These classifiers share layers that learn the similarities between real and fake samples across all domains to provide feedback regarding features that do not vary from the generator .
Training Objectives
StarGANv2-VC includes adversarial loss (), adversarial source classifier loss (), style reconstruction loss (), style diversification loss (), F0 consistency loss (), speech consistency loss (), norm consistency loss (), and cycle consistency loss (). Given a mel-spectrogram , the source and target domains and , respectively, in addition to a style code . We trained our model with the following loss functions:
The generator objective function calculation is as follows:
The discriminator’s objective function is calculated as follows:
denoted to the
adversarial loss that figures out how to generate a new mel-spectrogram
G (
X,
s) as in Equation (3):
where
X is the mel-spectrogram that was given as an input and
s is a style vector.
X and
s are the inputs of the generator
G;
is the real or fake classifier’s output for the domain
.
denotes the
adversarial source classifier loss obtained by using the cross-entropy loss function
CE(·) with the source classifier as in Equation (4):
represents the
style reconstruction loss that is applied to ensure that the generated samples can be used to reconstruct the style code as in Equation (5):
denotes the
style diversification loss which is used to push the generator to generate a wide variety of samples, each with a unique combination of style codes by maximizing
, which is defined in Equation (6):
where
and
represent two randomly sampled style codes from
;
denotes the output of convolutional layers of
network
.
denotes the
F0 consistency loss that is applied to obtain F0-consistent results and is defined in Equation (7):
where
normalizes the absolute F0 values by its temporal mean.
denotes
speech consistency loss that is applied to guarantee that the converted speech contains the same linguistic content as the source. It is defined in Equation (8):
where
represents the linguistic feature.
represents the
norm consistency loss that is applied for the purpose of preserving the speech/silence intervals of generated samples as in Equation (9):
For a mel-spectrogram
X with
N mels and
T frames at the
tth frame, the absolute column-sum norm function is performed as follows:
where
is the frame index.
denotes the
cycle consistency loss that is applied to preserve all other features of the input as defined in Equation (10):
where
represents the estimated style code of the input in the source domain.
represents the
source classifier loss and is given in Equation (11):
where
λadvcls,
λasr,
λsty,
λf0,
λds,
λcyc,
λnorm, and
are hyperparameters for each term.
5. Evaluation
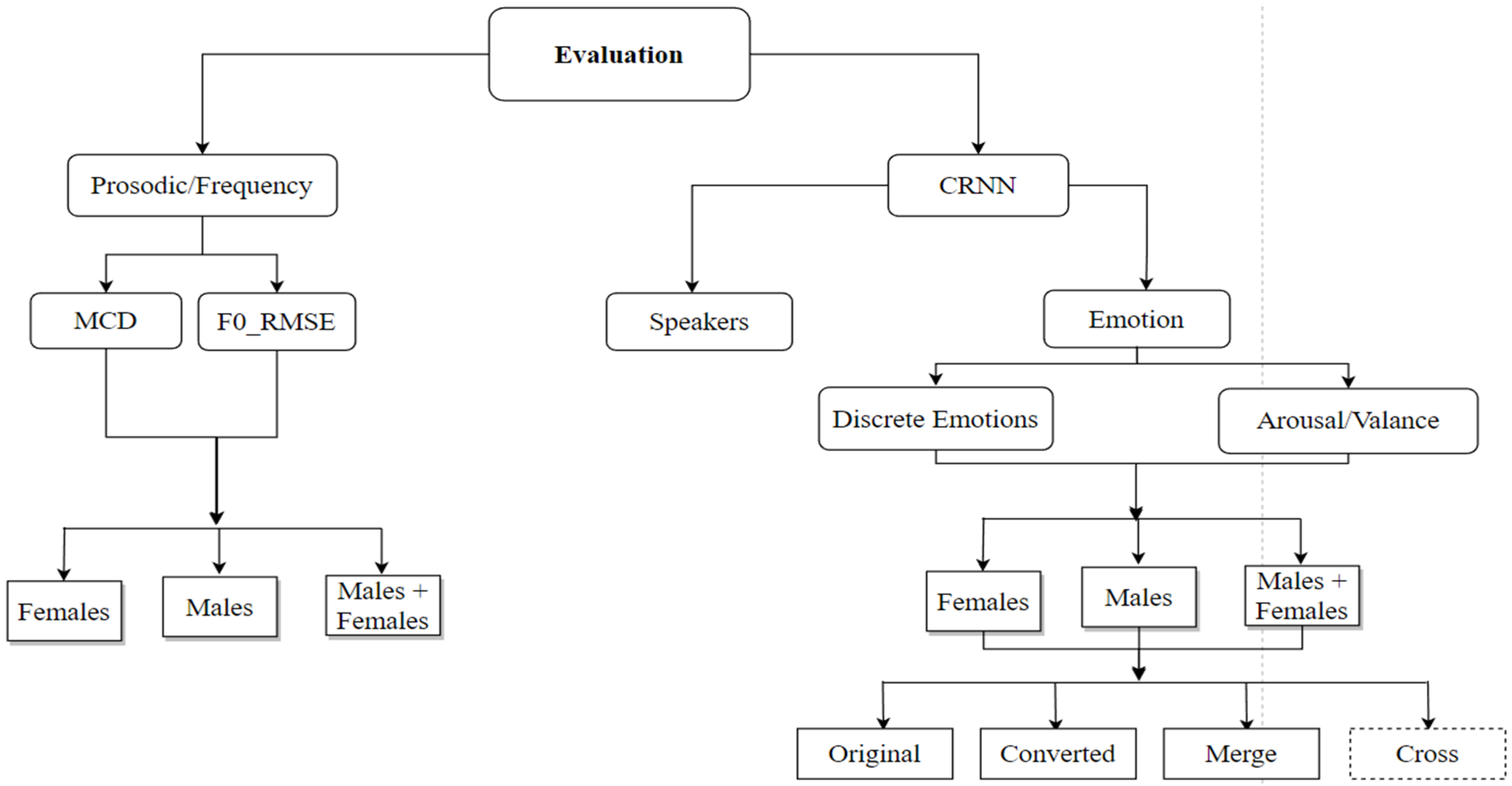
The assessment of speech quality produced by conversion and by measuring the system’s accuracy compared with state-of-the-art approaches is a fundamental stage in speech conversion. Speaker similarity, speech quality, and speech intelligibility are criteria for evaluating the performance of the VC system. In general, the results are measured in terms of objective and subjective measurements.
The standard objective evaluation measures comprise mel-frequency cepstral distortion (MCD) for spectrum and root-mean-square error (RMSE) for prosody [
41]. In the subjective evaluation, which is usually performed by listeners, the lowest number of listeners in the relevant literature review was 10 [
17,
18,
20] and, in some cases, it reached 87 [
35]. Collecting a sufficient number of listeners and then preparing them for a human perceptual test to evaluate the generated files is costly in time and money. Due to the significant effort and resources required for subjective evaluation, we decided to perform the evaluation process objectively, as shown in
Figure 4.
5.1. Spectrum and Prosody Conversion
We used MCD, to evaluate the performance of spectrum conversion. MCD compares the converted mel-frequency cepstra to the target mel-frequency cepstra and measures the amount of distortion. In this work, 24-dimensional mel-cepstral coefficients (MCEPs) are extracted from each frame; MCD is defined as [
29,
42].
where the terms
and
stand for the target and converted mel-frequency cepstra, respectively.
We used root-mean-square error (RMSE) [
43], which is a measure for prosody conversion performance and is defined as
where the terms
and
stand for the target and converted
F0 features, respectively. If the MCD and F0-RMSE values are low, this indicates that the distortion or prediction error is reduced as well.
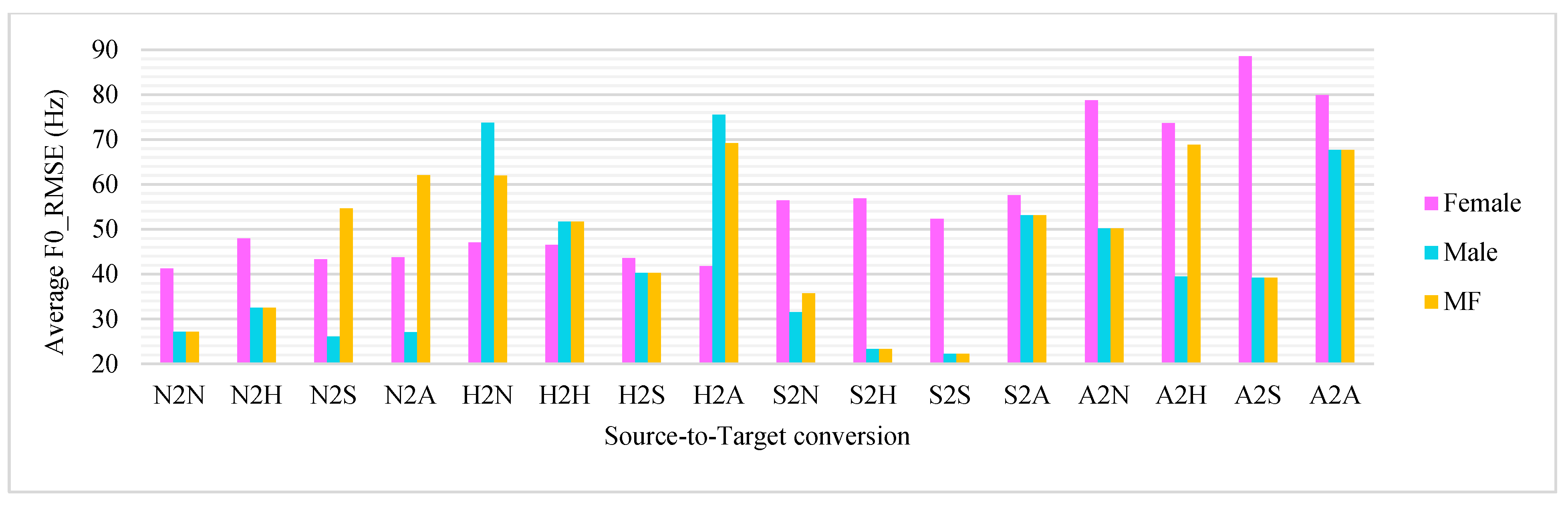
The MCD and F0-RMSE average results of converting one emotion to another for different combinations are reported in
Table 5 for the female set, male set, and male and female set (MF).
Table 5’s left side displays the MCD results, while the right side displays the F0-RMSE results. For more clarity,
Figure 5 and
Figure 6 show MCD and F0_RMSE for the conversion from one emotion to the other targeted emotions for females, males, and MF.
Table 5 and
Figure 5 and
Figure 6 show that, with a simple exception, males have the lowest values of MCD and F0 RMSE. This conclusion is consistent with our previous study in emotion recognition regarding evaluating the original database, human perceptual test results [
44], convolutional recurrent neural network, and residual neural network [
45], which indicated that males were evaluated more favorably than females. This result is compatible with our new findings.
Figure 7 and
Figure 8 show the overall mean of MCD and F0_RMSE for each emotion. As shown in
Figure 7, the lowest value of the MCD was noticed when converting from the emotion of neutral to the other different emotions and then when converting from the emotion of sadness to the other emotions. On the other hand, the highest value of MCD was observed while converting from anger to other emotions, followed by a minor difference when converting from happy to other emotions.
As in the MCD result, the value of F0_RMSE is lowest when converting from neutral to other different emotions for males only or females only and when converting from sadness to other emotions for MF. However, the highest value of F0_RMSE was observed during the conversion from anger to other different emotions for females only and MF, and when converting from happiness to other emotions for males.
The best and worst emotion conversion based on MCD and F0 RMSE values regarding gender are presented in
Table 6. The latter is based on the findings presented in
Table 5 and
Figure 5, as well as
Figure 6, and compares emotions that have converted from better (which got the lowest value) to worse. Neutral, sadness, happiness, and anger is the order from the best to the worst for females, males, and MF. For F0_RMSE, the best and worst are not in the same style as in MCD, as shown in
Table 6, where neutral is the best for males only or females only and the worst is anger for females and happiness for males. For the MF, sadness, neutral, anger, and happiness are ordered from best to worst.
Considering the best and worst emotion conversion from a specific emotion based on MCD and F0 RMSE, each emotion was converted into four emotions (the other three emotions and the emotion itself). The conversion is ranked from best to worst for each emotion in
Table 7. As shown in the table, the original emotion is on the left (column called “From Emotion”), followed by the best emotion which converted to it, for females, males, and MF, and the worst for the same categories.
Regarding the MCD values in
Table 7, according to what was predicted, the optimum outcome of the conversion was the conversion to the emotion itself; hence, the best outcome for the neutral emotion was the conversion to the neutral emotion, and so on for the rest of the emotions. On the other hand, the worst consequence of converting from the emotion of neutral was the conversion from it to the emotions of anger and happiness. For emotions of happiness and anger, the conversion’s worst outcome was when converting to the emotion of sadness for both. For sadness, it was the worst result of its conversion into an emotion of anger for males only, as well as for MF, and when converting into happiness for females.
Regarding the F0_RMSE values, the results for neutral and sadness are, with exceptions, comparable to their findings regarding MCD. When it comes to the emotions of anger and happiness, the data presented in the table reveal that the most favorable outcome for anger occurred when the emotion was converted from anger to happiness, while the most favorable outcome for happiness occurred when anger was converted from happiness to anger in relation to happiness, as shown in
Table 7.
5.2. Automatic Recognition
5.2.1. Emotion Recognition Experiments
We have conducted several experiments to obtain the best automatic evaluation; these were divided and carried out according to the type of emotion, gender, and data, as shown in
Figure 4.
Based on the type of emotion, we defined two primary experiments: the first relates to discrete emotions (neutral, happiness, sadness, and anger), and the second relates to arousal (high and low) and valence (positive and negative) emotions, as shown in
Table 8 [
46].
Based on gender, the data were divided into three independent sets (females only, males only, and females and males together) and experiments were carried out on each set separately.
The data were divided into four categories: original, converted, merged, and crossed. “Original data” refers to the original KSUEmotions database, while “converted data” refers to the data that were newly generated. “Merged data” includes both the original and the converted data, and in the “crossed data”, we used the original data for training and the converted data for testing. The recognition experiments were conducted individually on each type.
5.2.2. Speaker Identification Experiments
To evaluate speaker identification, we conducted several experiments regarding the speaker’s gender and data category. The experiments were conducted on a separate set of females, consisting of seven speakers. Next, they were conducted on a set of males, also composed of seven speakers. Finally, they were conducted on all speakers, both male and female together. All these experiments were carried out in the original database and with converted data, merged data, and crossed data, as described in the previous section.
5.2.3. Used Features and Model
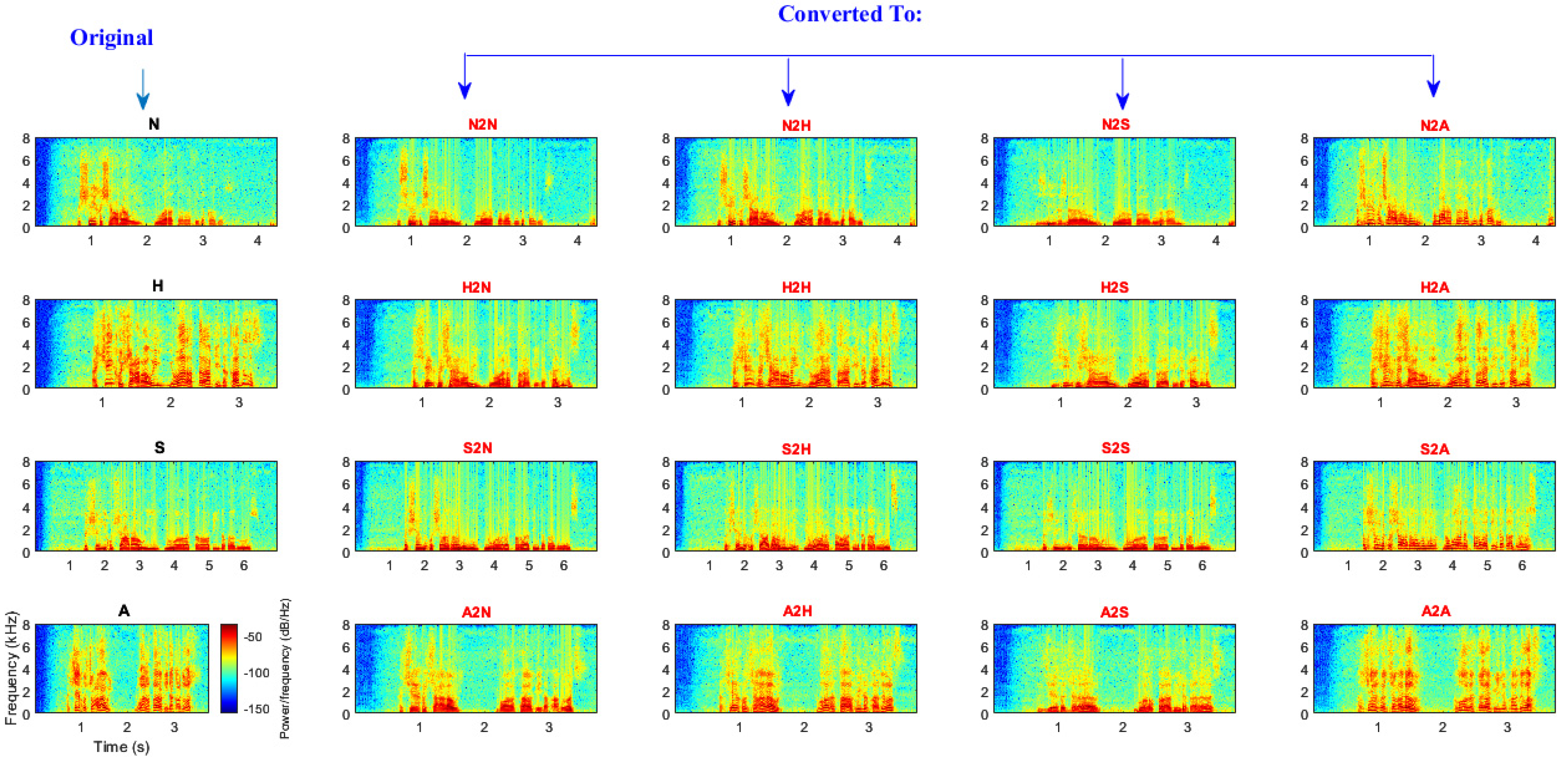
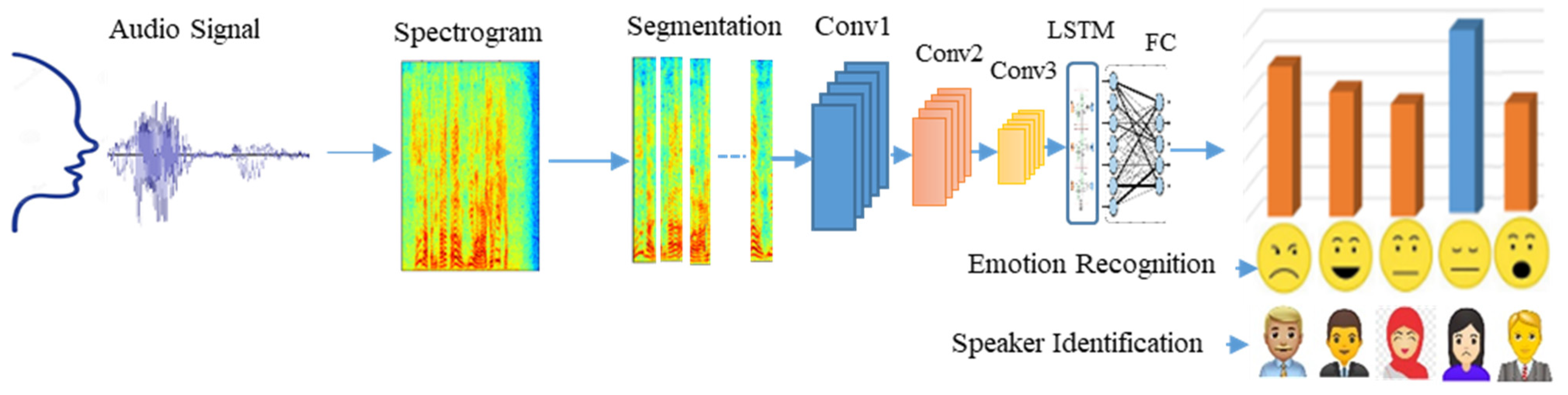
As a feature for emotion recognition and speaker identification, the spectrogram was generated for each original and converted audio file. We utilized the CRNN model, which is a combination of a convolutional neural network (CNN) and long short-term memory (LSTM), as demonstrated in
Figure 9.
The spectrogram was segmented after being generated for each audio file. These segments, with a size of × 512, were used as an input for the proposed model, where represents the segment size in frames and 512 is the number of frequency points output by the short-time FFT.
The proposed model contains three convolutional layers: the first one includes 16 kernels of dimension size 12 × 16, the second one includes 24 kernels of dimension size 8 × 12, and the third one consists of 32 kernels of dimension size 5 × 7. These convolutional layers were applied with a one-pixel stride. Each layer is followed by an exponential linear unit (ELU) to help the CNNs train much faster. The ELU in each layer is attached by a max-pooling layer (2 × 2) with a stride of two. Bidirectional-LSTM (BLSTM) layers follow these layers with 128 units in addition to a dropout layer with a dropout ratio of 40% to prevent overfitting. Finally, a fully connected layer (FC) follows with several neurons equal to the number of emotions or speakers. At the end of the FC layer, a sigmoid function was used to make classification outputs in the form of prediction accuracy for different emotions or speakers.
We used a probabilistic evaluation for system prediction using a mean prediction-based reasoning approach for outcome prediction calculation. There were various numbers of segments in each audio file. To determine the correctness of the entire audio recording, the accuracy of each segment was calculated. If the model correctly predicted more than 50% of the audio files, the accuracy was deemed acceptable.
Figure 10 presents an example of one speech file segmented into four segments (S1, S2, S3, and S4). Each segment is used as an input for the proposed model and the outcome for each segment is shown in
Figure 10. In the final step, the average of all segments for one file is calculated. The maximum average is the predicted emotion.
As an optimizer, the Adam adaptive gradient descent algorithm [
47] was utilized for training and the learning rate was set at 0.001. A softmax layer was applied following training to achieve a prediction accuracy output for various emotions or speakers. The training procedure was executed ten times for a maximum of 200 epochs, with 128 samples per batch, using Google Colab Pro [
48] and the following settings: hardware accelerator: GPU; runtime structure: High-RAM. This model was developed using TensorFlow [
49] and Keras [
50] as the front-end system.
5.2.4. Discrete Emotion Recognition Results
The average accuracy of 10 runs, the standard deviation, and the highest and lowest accuracy are illustrated in
Table 9 for each set separately (females, males, and females with males) and for the data in the four original, converted, merged, and crossed cases.
Figure 11 shows that, generally, males perform better than females in all data types, where the average male accuracy reached 77.34% compared with 71.41% for converted females. It is evident that the categorization accuracy for the crossed data is the lowest compared with other data categories. As indicated previously, the male result is likewise the highest, at 59.16%, compared with 55.59% for females and 52.75% for all data, males and females combined.
Regarding the merged data, the accuracy percentage in the merged data declined by 0.94% points for females and by 3.74% points for males compared with the original data. The difference in the classification accuracy percentage between the original and the converted data sets presents more in-depth comparison. Although the classification accuracy score for males is generally higher, the standard deviation scale of the male group is larger than that of the female group. In addition, the gap between the highest and lowest classification accuracy for the female group is 9.37%, whereas for the male group it is 18.75%. Additionally, compared with males, the accuracy of females decreased less in the merged data compared with the original data.
The confusion matrices that were obtained after running 10 iterations using the original database, converted data, merged data, and crossing data are presented in
Table 10.
Figure 12 displays each emotion independently for the four cases (for females, males, and females and males). In the case of the original, merged, and crossed data, the emotion of anger obtained the highest accuracy in the case of the females, males, and both females and males. However, in the case of the converted data, the emotion of happiness obtained the highest accuracy in the females, and the emotion of sadness got the highest accuracy in the case of the males, and both females and males. When compared with the emotions of anger and sadness, the classification accuracy for the emotions of happiness and neutrality was the lowest.
The accuracy of sadness corresponds with the results of the sadness that were discussed above, where the sadness conversion results, in general, are good.
5.2.5. Arousal–Valence Emotion Recognition Results
Arousal and valence are the most commonly two-dimensional spaces used to understand emotions according to what occurs within a dimensional space. Emotional arousal relates to the intensity of the emotional state, which can be high or low, whereas emotional valence denotes the degree to which an emotion is positive or negative [
51].
The accuracy of arousal–valence emotion recognition is shown in
Table 11 for 10 runs of the original, converted, and merged data. We observe here that the accuracy of the converted data due to arousal (high and low) is equivalent to the accuracy of the original data and might even grow significantly in the case of females. In the case of the merged data, the overall accuracy improved significantly. In contrast, the accuracy of the converted data for the valence emotion was generally lower than that of the original data. Regarding the accuracy of the results with regard to gender, we find that the results of valence are comparable to the previous results in general, as the accuracy for males is higher than that of females, except in the case of the merged data. In contrast to the emotion of arousal, females had a higher rate of accuracy.
5.2.6. Speaker Identification Results
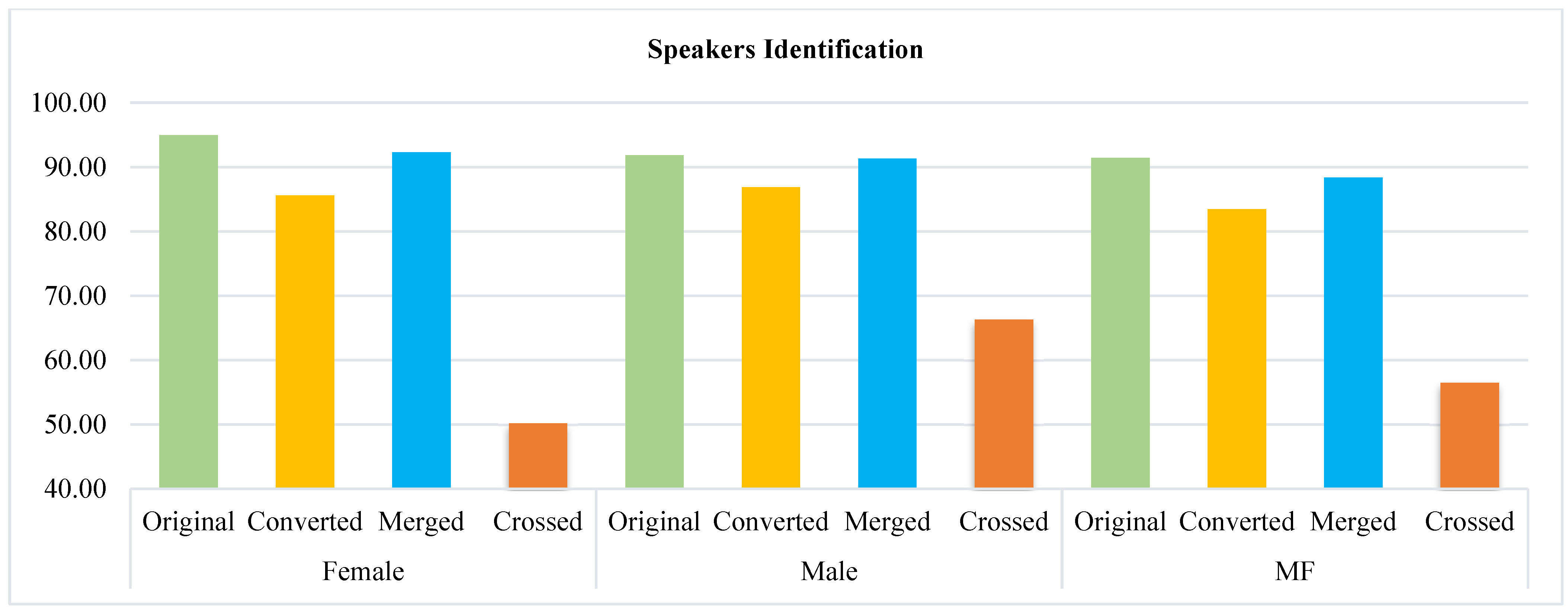
Table 12 provides a summary of the results of speaker identification using the original, converted, merged, and crossed database, which includes the mean accuracy for 10 runs, higher and lower accuracy, and the standard deviation. The results are presented for males, females, and males and females together. For further understanding,
Figure 13 presents the overall average accuracy. According to the table and the figure, the identification accuracy of female speakers was 94.97% greater than that of male speakers, which was 91.85%, and greater than male and female speakers combined, which was 91.44%. Compared with the converted data, we noticed that the accuracy of identifying male and female speakers is comparable, with a small increase for males. The accuracy of speaker identification reduced somewhat (0.5% for males, 2.66% for females, and 3.07% for all speakers) when the original data were combined with the converted data. In the case of crossed data, males have the highest accuracy, as depicted in the image.
Comparing the values of the standard deviation and the difference between the highest and lowest accuracy, the value of the standard deviation for females in both the original data and the converted data is higher than the value for males, but in the case of the merged data it is the lowest.
In the summary of the evaluation results in general, whether using the spectrum and prosody conversion or automatic recognition, we found that the results of males are, in general, better than the results of females, with a few notable exceptions. This finding is consistent with the outcomes of our previous study in emotion recognition regarding the whole of the database, whether such investigations were carried out with the human perceptual test or with the CRNN classifier [
44,
45]. Regarding the used pre-trained model, the overall accuracy of emotion recognition utilizing translated data ranged from 66.17% to 77.33%, which we consider to be an acceptable level of accuracy when utilizing the pre-trained model.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}