
ME-YOLO: Improved YOLOv5 for Detecting Medical Personal Protective Equipment

Abstract
:1. Introduction
- 1.
- We propose a new medical personal protective equipment detection algorithm—ME-YOLO. Firstly, to solve the problem of poor feature extraction by the backbone network when the size of objects varies, a feature fusion module (FFM) is proposed and merged with the C3 module, named C3_FFM. Secondly, to solve the problem of the traditional up-sampling method, an enhanced up-sampling module is proposed. Thirdly, to solve the problem of slow convergence of prediction box regression in CIoU loss, EIoU loss is used as the loss function of the border regression.
- 2.
- Compared with the other mainstream object detection algorithms, the experiments demonstrate that the ME-YOLO network structure has good detection accuracy and a high detection speed, enabling it to be applied for real-time detection.
2. Related Work
2.1. Existing Work
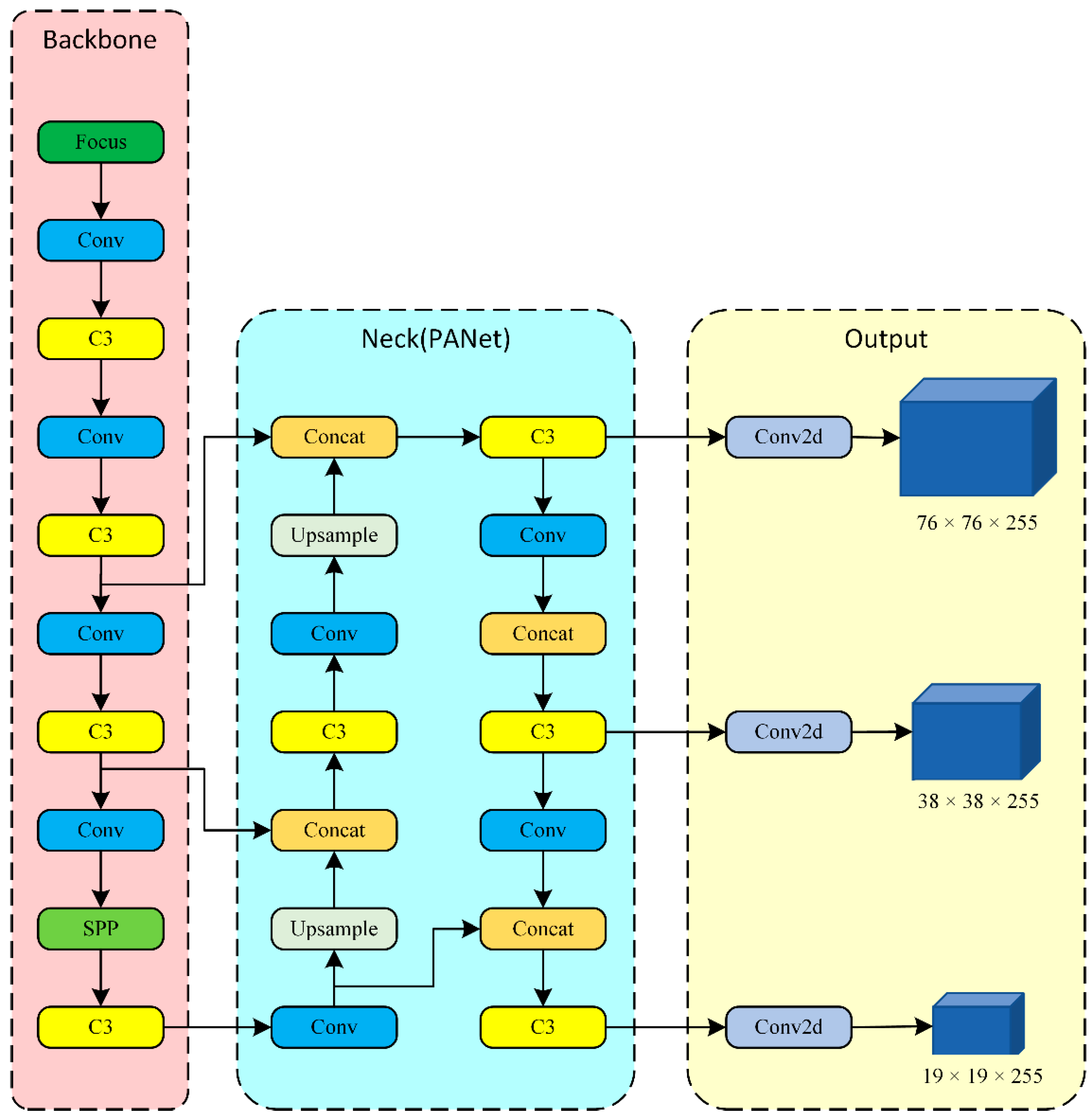
2.2. YOLOv5 Network Structure
3. Proposed Method
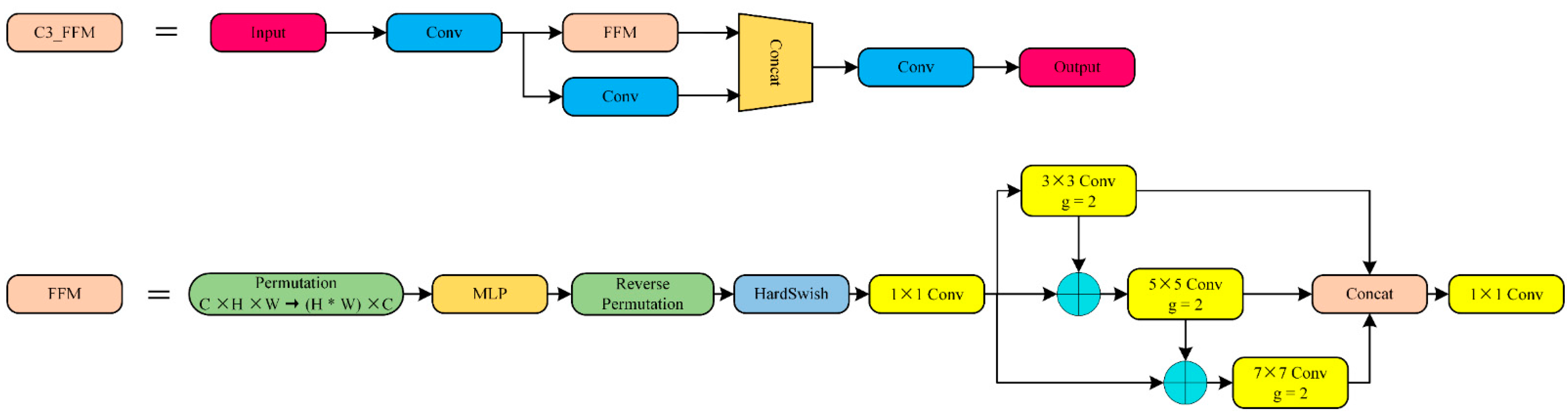
3.1. C3_FFM
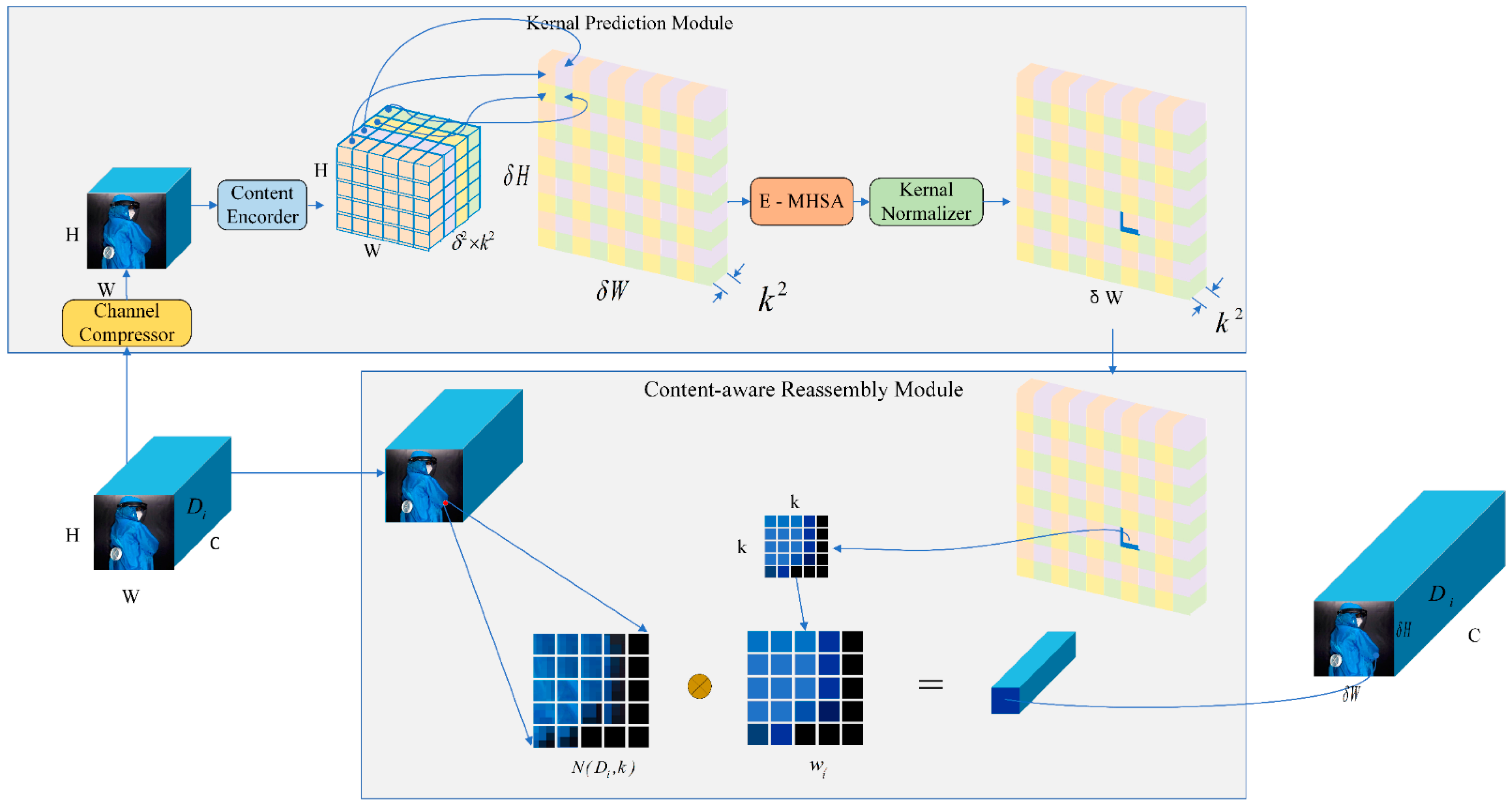
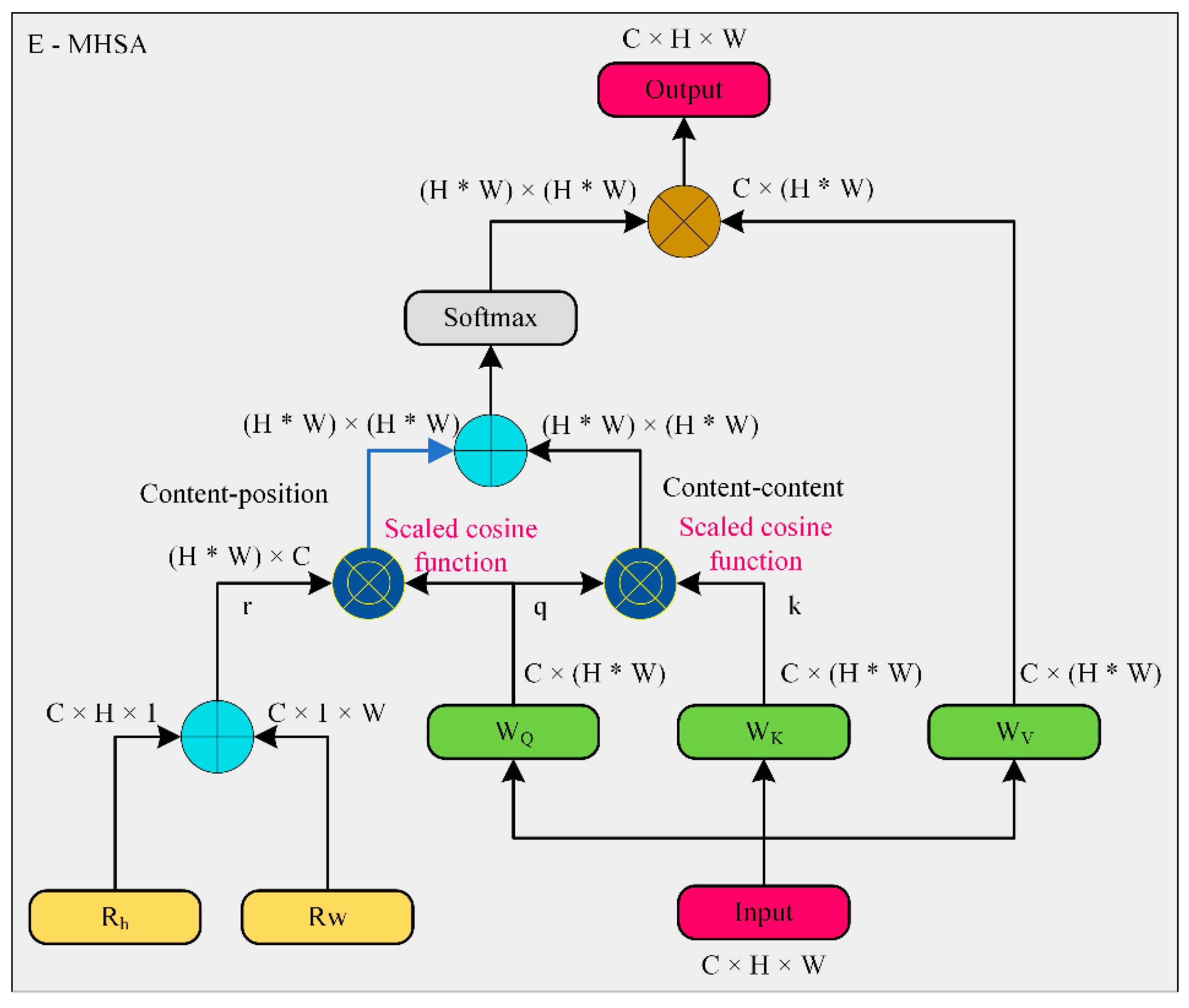
3.2. Up-Sampling Enhancement Module
3.3. Improvement of the Loss Function
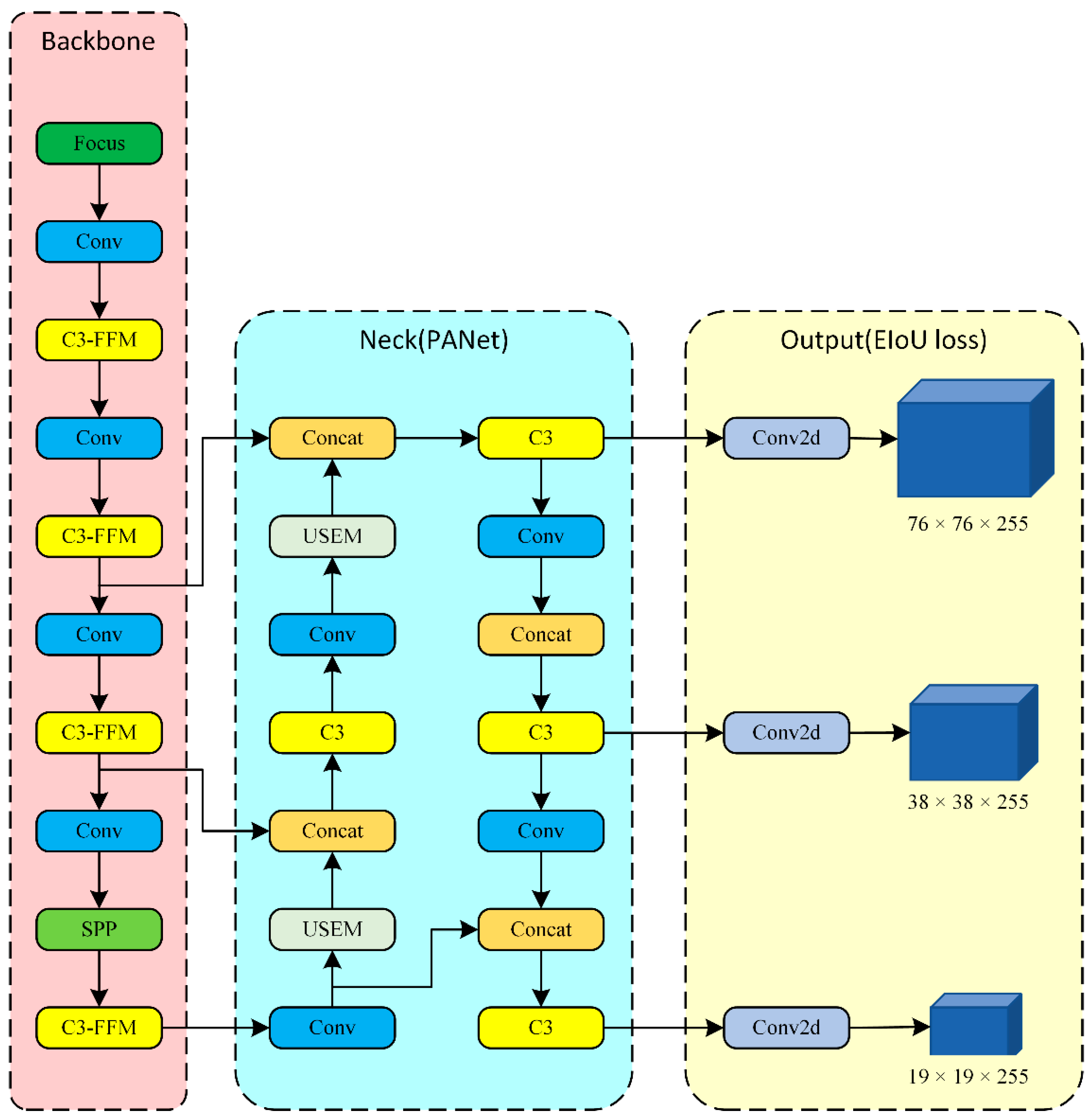
3.4. ME-YOLO Network Structure
4. Experiments and Results
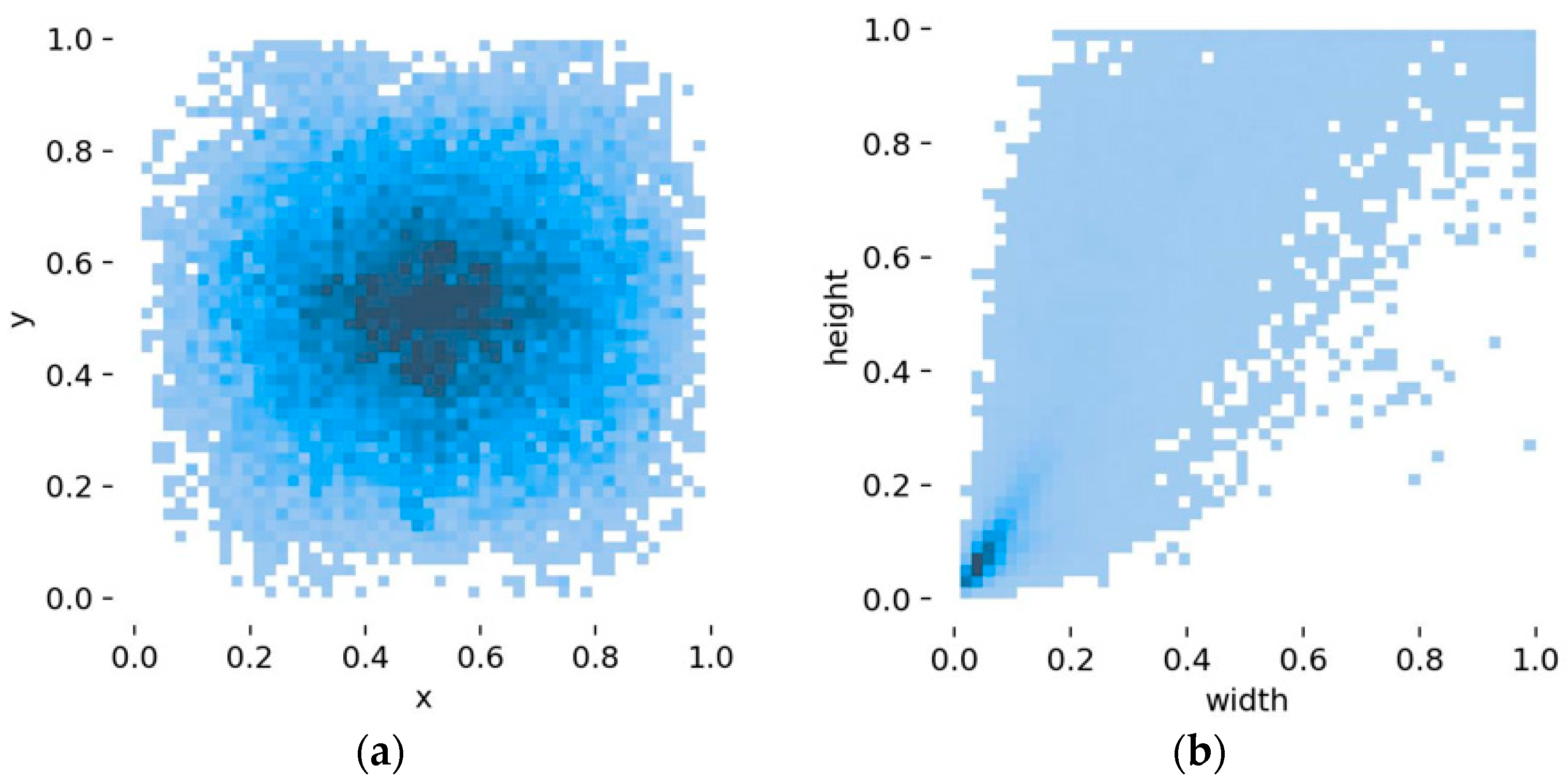
4.1. Dataset and Expansion Method
4.2. Experimental Environment
4.3. Evaluation Metrics
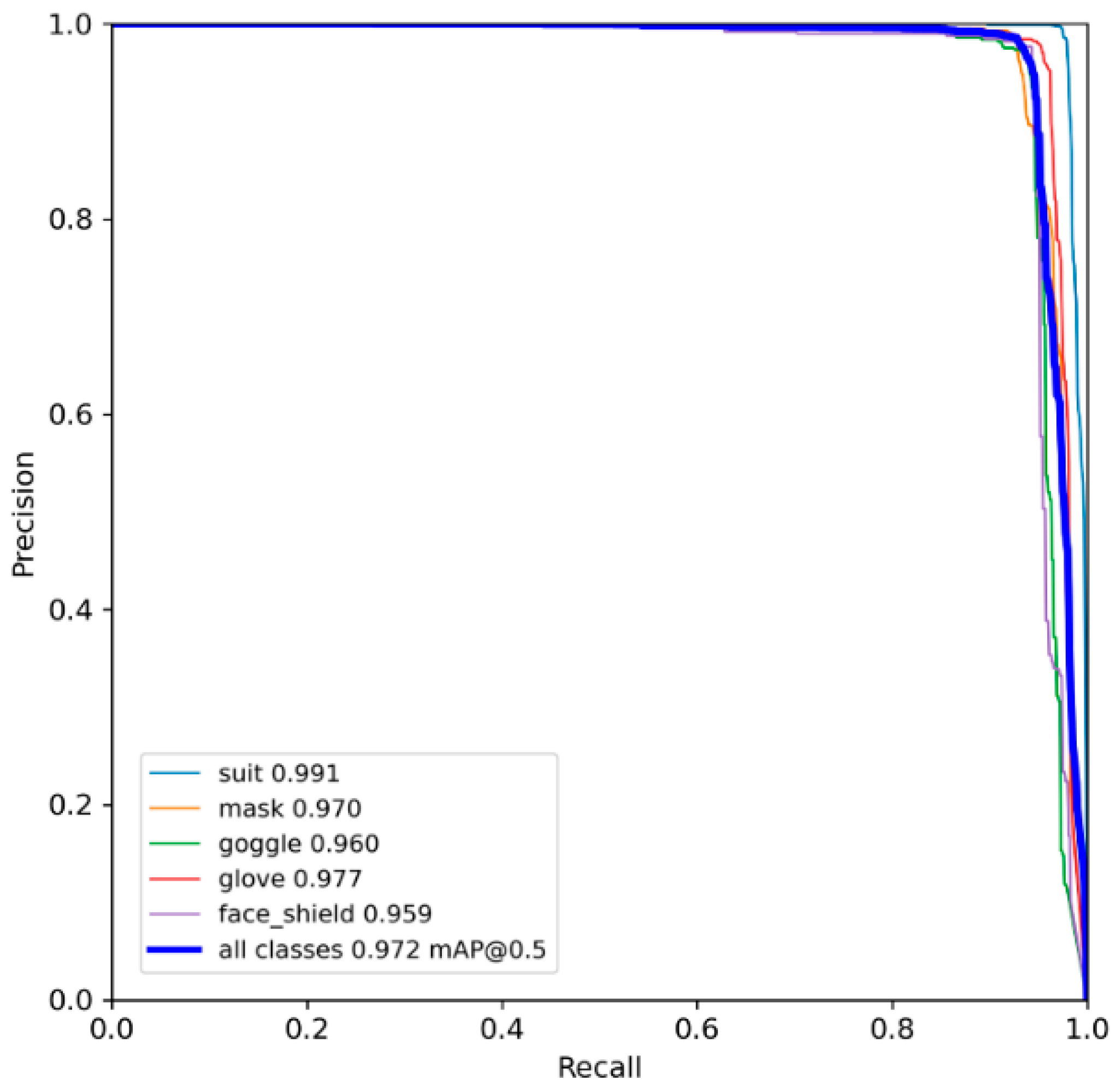
4.4. Training Results and Analysis
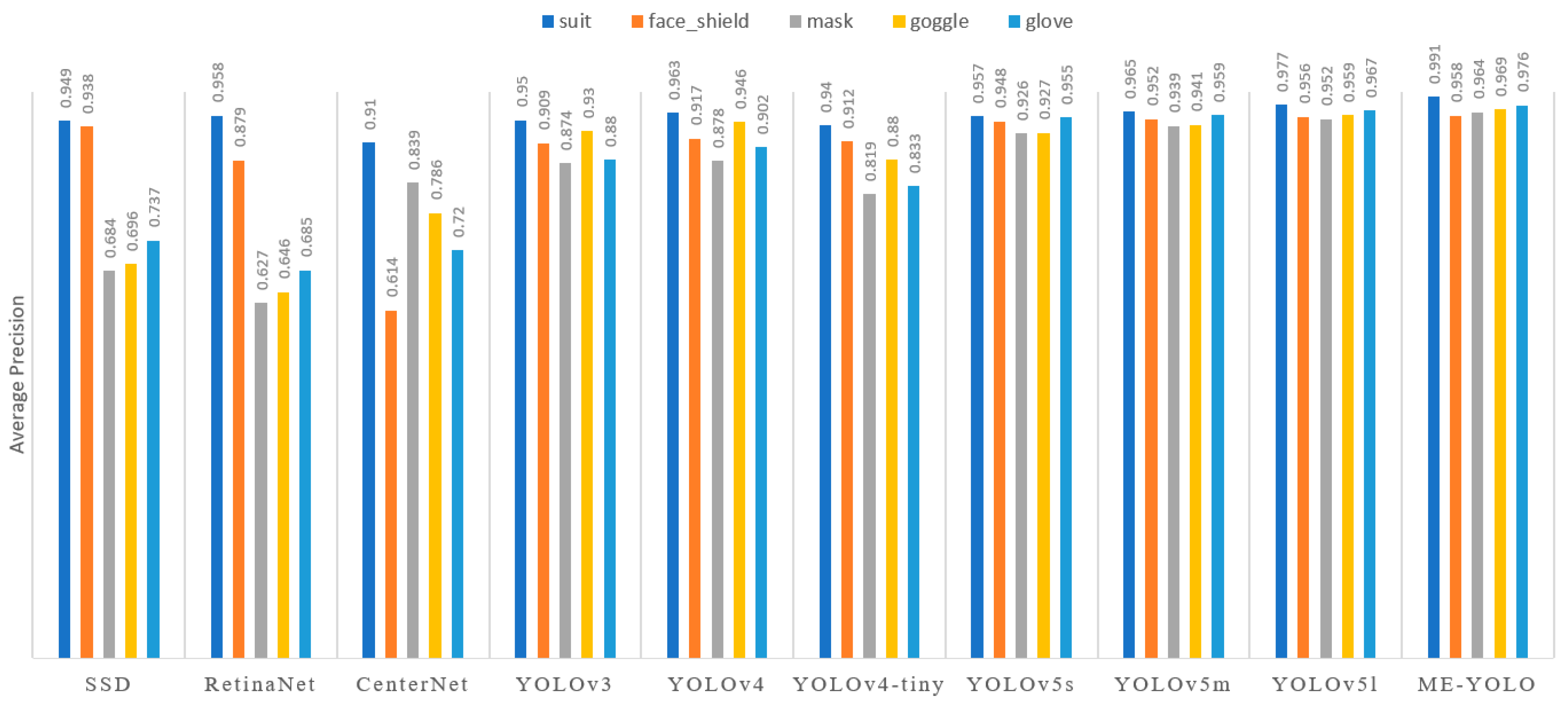
4.5. Comparison of Mainstream Object Detection Models
4.6. Analysis of Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, D.H.; Yao, F.F.; Wang, L.J.; Zheng, L.; Gao, Y.J.; Ye, J.; Guo, F.; Zhao, H.; Gao, R.B. A Comparative Study on the Clinical Features of Coronavirus 2019 (COVID-19) Pneumonia with Other Pneumonias. Clin. Infect. Dis. 2020, 71, 756–761. [Google Scholar] [CrossRef] [Green Version]
- WHO. Coronavirus Disease (COVID-19) Dashboard. Available online: https://www.who.int (accessed on 9 November 2022).
- Rahmani, A.M.; Mirmahaleh, S.Y.H. Coronavirus disease (COVID-19) prevention and treatment methods and effective parameters: A systematic literature review. Sustain. Cities. Soc. 2021, 64, 102568. [Google Scholar] [CrossRef] [PubMed]
- Liao, M.; Liu, H.; Wang, X.; Hu, X.; Huang, Y.; Liu, X.; Brenan, K.; Mecha, J.; Nirmalan, M.; Lu, J.R. A technical review of face mask wearing in preventing respiratory COVID-19 transmission. Curr. Opin. Colloid Interface Sci. 2021, 52, 101417. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Kalia, A.; Sharma, A.; Kaushal, M. A hybrid tiny YOLO v4-SPP module based improved face mask detection vision system. J. Ambient. Intell. Humaniz. Comput. 2021, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Gedik, O.; Demirhan, A. Comparison of the Effectiveness of Deep Learning Methods for Face Mask Detection. Trait Signal 2021, 38, 947–953. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.J. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M.J. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02698. [Google Scholar]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M.J.M. A hybrid deep transfer learning model with machine learning methods for face mask detection in the era of the COVID-19 pandemic. Measurement 2021, 167, 108288. [Google Scholar] [CrossRef] [PubMed]
- Su, X.P.; Gao, M.; Ren, J.; Li, Y.H.; Dong, M.; Liu, X. Face mask detection and classification via deep transfer learning. Multimed. Tools Appl. 2022, 81, 4475–4494. [Google Scholar] [CrossRef]
- Nagrath, P.; Jain, R.; Madan, A.; Arora, R.; Kataria, P.; Hemanth, J. SSDMNV2: A real time DNN-based face mask detection system using single shot multibox detector and MobileNetV2. Sustain. Cities Soc. 2021, 66, 102692. [Google Scholar] [CrossRef]
- Yu, J.M.; Zhang, W. Face Mask Wearing Detection Algorithm Based on Improved YOLO-v4. Sensors 2021, 21, 3263. [Google Scholar] [CrossRef]
- Wang, J.; Wan, M.; Wang, J.; Wang, X.G.; Wang, Y.G.; Liu, F.; Min, W.X.; Lei, H.; Wang, L.H. Defects Detection System of Medical Gloves Based on Deep Learning. In Proceedings of the 6th International Conference on Smart Computing and Communication (SmartCom), Chengdu, China, 29–31 December 2021; pp. 101–111. [Google Scholar]
- Le, N.T.; Wang, J.W.; Wang, C.C.; Nguyen, T.N. Novel Framework Based on HOSVD for Ski Goggles Defect Detection and Classification. Sensors 2019, 19, 5538. [Google Scholar] [CrossRef] [Green Version]
- Xiong, R.X.; Tang, P.B. Pose guided anchoring for detecting proper use of personal protective equipment. Autom. Constr. 2021, 130, 103828. [Google Scholar] [CrossRef]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? arXiv 2021, arXiv:2108.08810. [Google Scholar]
- Srinivas, A.; Lin, T.-Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the 2021 Conference on Computer Vision and Pattern Recognition (CVPR), Montreal, BC, Canada, 11–17 October 2021; pp. 2304–2311. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.J.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. arXiv 2022, arXiv:2111.09883. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T.J.N. Focal and efficient IOU loss for accurate bounding box regression. arXiv 2022, arXiv:2101.08158. [Google Scholar] [CrossRef]
- Dagli, R.; Shaikh, A.M.J. CPPE-5: Medical Personal Protective Equipment Dataset. arXiv 2021, arXiv:2112.09569. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Suit | Face Shield | Goggle | Mask | Glove |
|---|---|---|---|---|
| 10,101 | 3298 | 4133 | 10,188 | 9937 |
| Device | Configuration |
|---|---|
| System | Ubuntu18.04 |
| CPU | Intel®Xeon E5-2680 v4@2.40 GHz |
| GPU | GeForce RTX 2080Ti, 12G |
| GPU accelerator | CUDA 11.2, Cudnn 11.0 |
| Frames | PyTorch |
| Compilers | PyCharm, Anaconda |
| Python version | 3.6 |
| Feature Map | Receptive Field | Prior Box Size |
|---|---|---|
| 19 × 19 | Large object | (163 × 214) (179 × 501) (365 × 601) |
| 38 × 38 | Medium object | (53 × 81) (82 × 133) (93 × 61) |
| 76 × 76 | Small object | (20 × 31) (30 × 60) (46 × 43) |
| Models | Backbone | mAP (%) | F1 | Parameters (M) | FPS (Frame·s−1) |
|---|---|---|---|---|---|
| SSD | VGG16 | 80.1 | 75 | 90.6 | 30 |
| RetinaNet | ResNet50 | 76.0 | 58 | 138.9 | 27 |
| CenterNet | ResNet50 | 77.4 | 67 | 124.0 | 71 |
| YOLOv3 | Darknet-53 | 90.5 | 86 | 234.7 | 25 |
| YOLOv4 | CSPDarknet53 | 92.1 | 88 | 244.0 | 22 |
| YOLOv4-tiny | CSPDarknet53 | 87.8 | 83 | 22.6 | 67 |
| YOLOv5s | CSPDarknet53 | 94.2 | 93 | 7.0 | 56 |
| YOLOv5m | CSPDarknet53 | 95.4 | 94 | 21.2 | 47 |
| YOLOv5l | CSPDarknet53 | 96.1 | 94 | 46.5 | 32 |
| ME-YOLO | - | 97.2 | 96 | 7.5 | 53 |
| Models | One Image Test Time(s) | All Reasoning Time(s) | FPS (Frames·s−1) |
|---|---|---|---|
| YOLOv3 | 0.047 | 23.5 | 21 |
| YOLOv4 | 0.059 | 29.5 | 17 |
| YOLOv5s | 0.022 | 11.0 | 46 |
| YOLOv5m | 0.026 | 13.0 | 38 |
| YOLOv5l | 0.037 | 18.5 | 27 |
| ME-YOLO | 0.023 | 11.5 | 42 |
| Models | C3_FFM | USEM | EIoU | AP (%) | P (%) | R (%) | mAP (%) | GFLOPS | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Suit | Face Shield | Goggle | Mask | Glove | ||||||||
| YOLOv5s | × | × | × | 95.7 | 94.8 | 92.6 | 92.7 | 95.5 | 95.5 | 90.1 | 94.2 | 15.9 |
| YOLOv5s | √ | × | × | 95.6 | 94.9 | 95.3 | 95.9 | 96.6 | 96.4 | 93.4 | 95.7 | 16.8 |
| YOLOv5s | √ | √ | × | 99.0 | 95.0 | 95.5 | 96.5 | 96.5 | 97.0 | 94.3 | 96.5 | 17.5 |
| YOLOv5s | √ | √ | √ | 99.1 | 95.9 | 96.0 | 97.0 | 97.7 | 97.7 | 94.4 | 97.2 | 17.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, B.; Pang, C.; Zeng, X.; Hu, X. ME-YOLO: Improved YOLOv5 for Detecting Medical Personal Protective Equipment. Appl. Sci. 2022, 12, 11978. https://doi.org/10.3390/app122311978
Wu B, Pang C, Zeng X, Hu X. ME-YOLO: Improved YOLOv5 for Detecting Medical Personal Protective Equipment. Applied Sciences. 2022; 12(23):11978. https://doi.org/10.3390/app122311978
Chicago/Turabian StyleWu, Baizheng, Chengxin Pang, Xinhua Zeng, and Xing Hu. 2022. "ME-YOLO: Improved YOLOv5 for Detecting Medical Personal Protective Equipment" Applied Sciences 12, no. 23: 11978. https://doi.org/10.3390/app122311978