In the computer architecture, the cache replacement algorithm directly affects the cache hit ratio. The higher the cache hit ratio, the less the job execution time [
12,
13,
14,
15]. Li et al. [
15] insisted that the costs of recomputing should be considered as a main factor. Then, GD-Wheel was proposed, which integrates the frequency of accessing and cost of recomputing to design the cache data weight. The experiment shows that compared to LRU, GD-Wheel reduces the recomputation cost by as much as 90%. Xuan et al. [
16] adopted a method of the decision tree to design the caching replacement algorithm in the background of Web Proxy Caching. In JMT software, the simulation results shows the better performance compared to the original method. In recent years, Fei Long [
17] introduced the deep learning method to the cache management field. He found that the most current optimization methods do not take into account that the size of the cache in cloud scenarios is much smaller than the size of the workload. To improve the performance of cloud computing, a collaborative two-stage deep reinforcement learning framework, called CAPCBS, is proposed. Ruan et al. [
18] found the popularity of content is a essential factor for VR video. They designed the weight by the ratio of the video characteristic information and the user feature information. According to these works, we can conclude that the special cache replacement algorithm has limited scence scope, and it is not suitable to Spark. In Spark, Duan et al. [
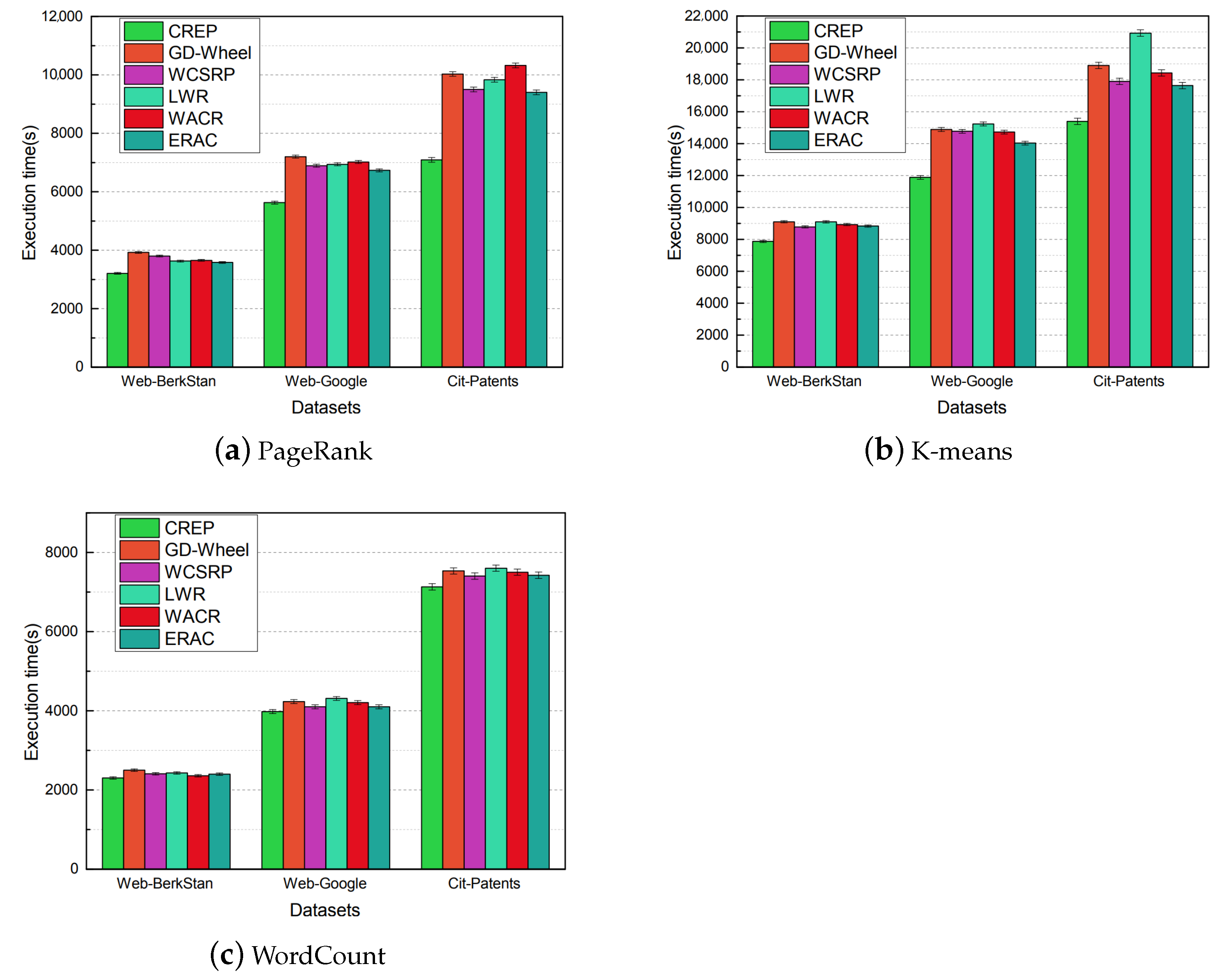
19] considered the partition size, storage time, usage times and calculation cost to design a new weight replacement algorithm. The experimental results showed that the execution time of jobs was obviously improved. Liu et al. [
20] analyzed the architecture of Spark and confirmed that the location attributes of the partitions were vital to the cache replacement algorithm. Then, a location-aware cache replacement algorithm was proposed, called WCSRP, considering the location attributes of the partitions. Bian et al. [
21] designed a method to collect the frequency of RDD and gave a weight of RDD to take the frequency of RDD into consideration. A lowest weight replacement algorithm, called LWR, is proposed. At the same time, they proposed a cache management strategy, called SACM, to reduce the job execution time for Spark. Kun et al. [
22] designed an adaptive cache replacement algorithm, called WACR, which takes into account the influence of four weight factors, including computation cost, usage times, partition size and life cycle of RDDs by reasonably calcuting the RDD partition weight values. Wei et al. [
23] propose an efficient RDD automatic cache algorithm, called ERAC, to distinguish the high reused RDD and set different degrees to replace old RDD. SuzhenWang et al. [
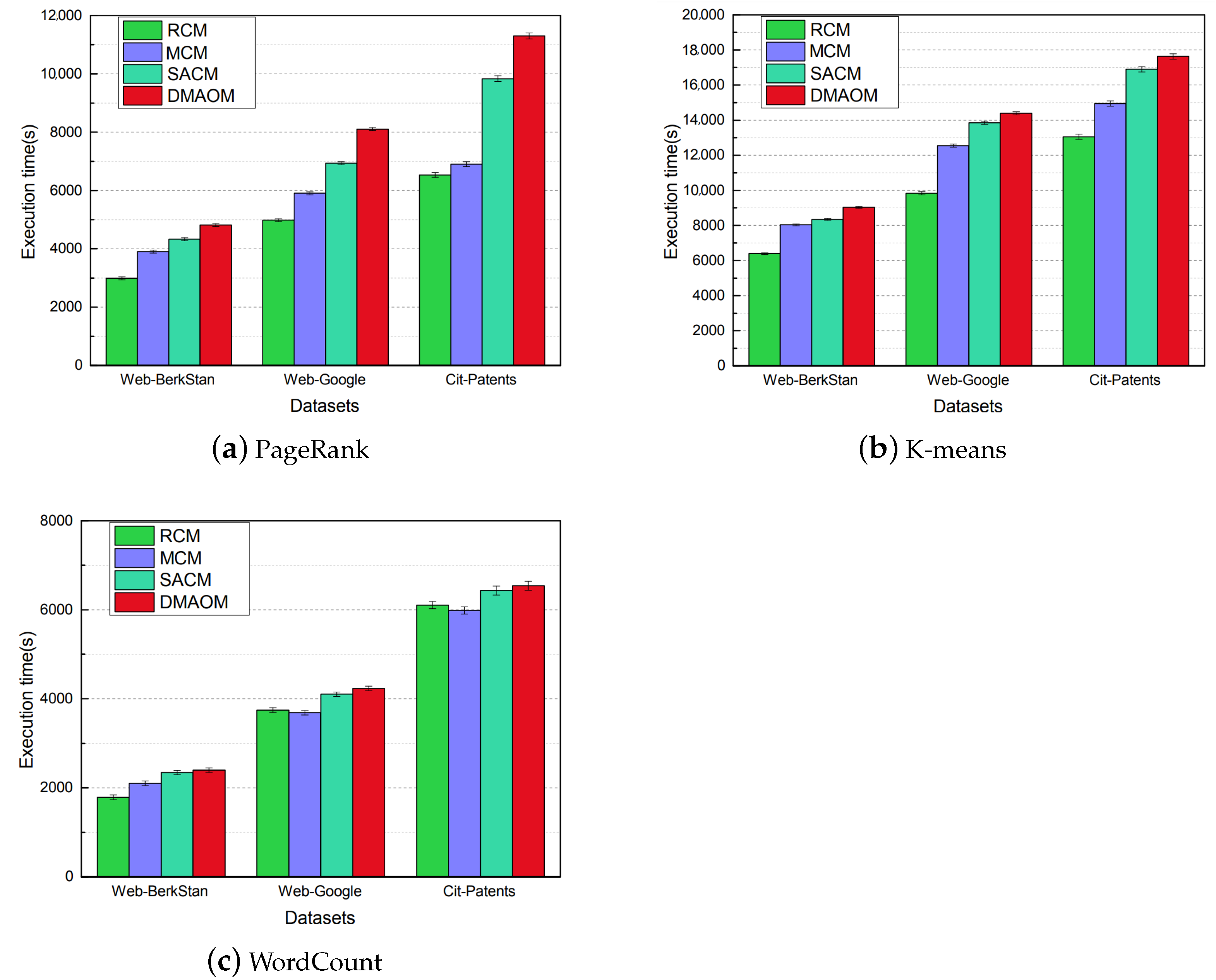
24] propose the implementation of memory on-demand allocation algorithm, called DMAOM, and according to the task request memory size proportionally allocate memory from the resource pool. The weight is proportional to the cache hitting rate. In a limited time scope, the cache hitting rate is high. However, as time passed, the hitting rate become low. These works ignore the time loss of weight during the job running, which leads to a low hitting rate to some degree. Song et al. [
25] insisted that the optimization of cache replacement is limited when the memory is severely insufcient. An advanced memory management method is proposed, called MCM, to improve performance by reducing contention. Compared to similar works, MCM reduces the execution time by 28.3%.
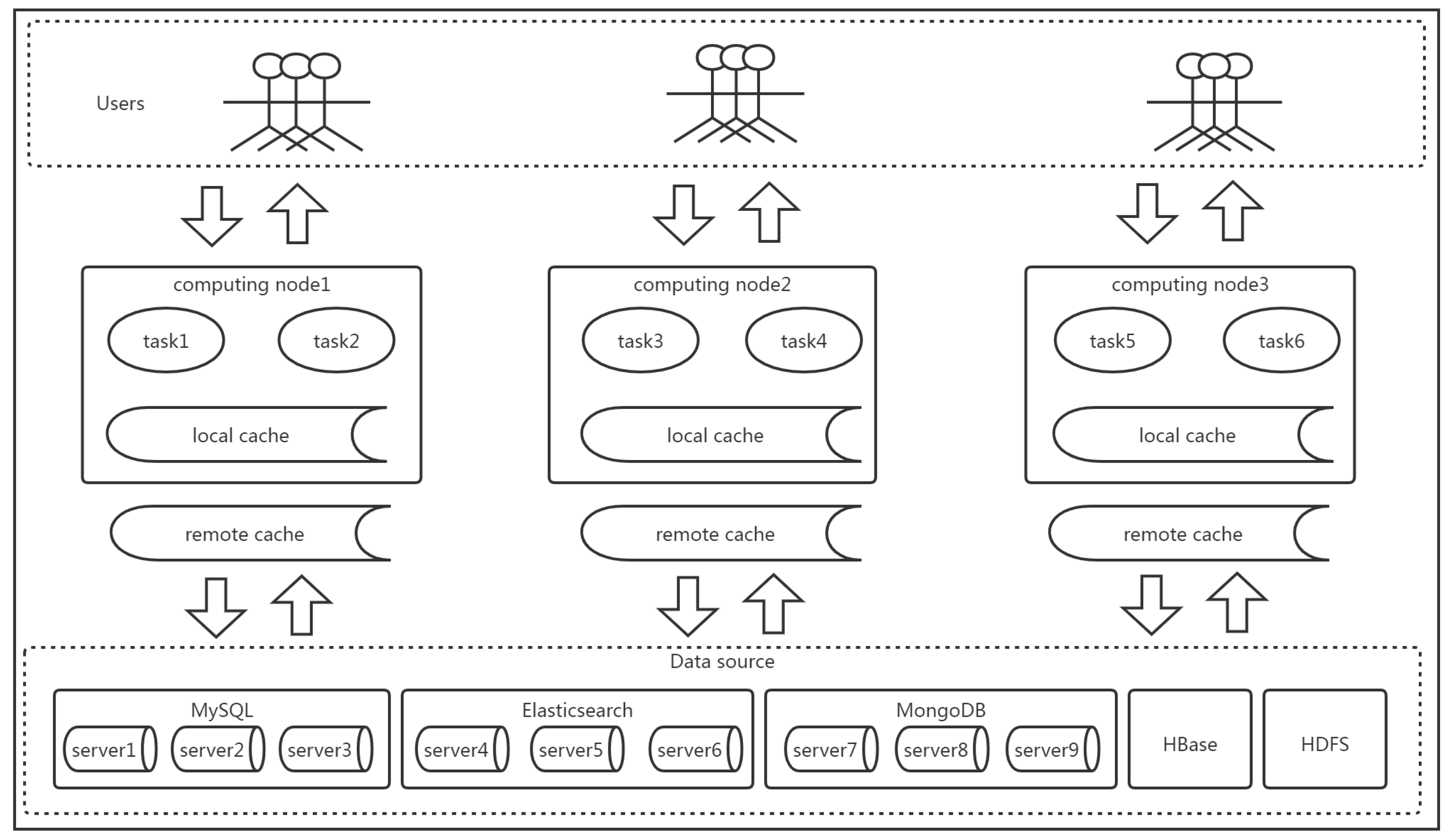
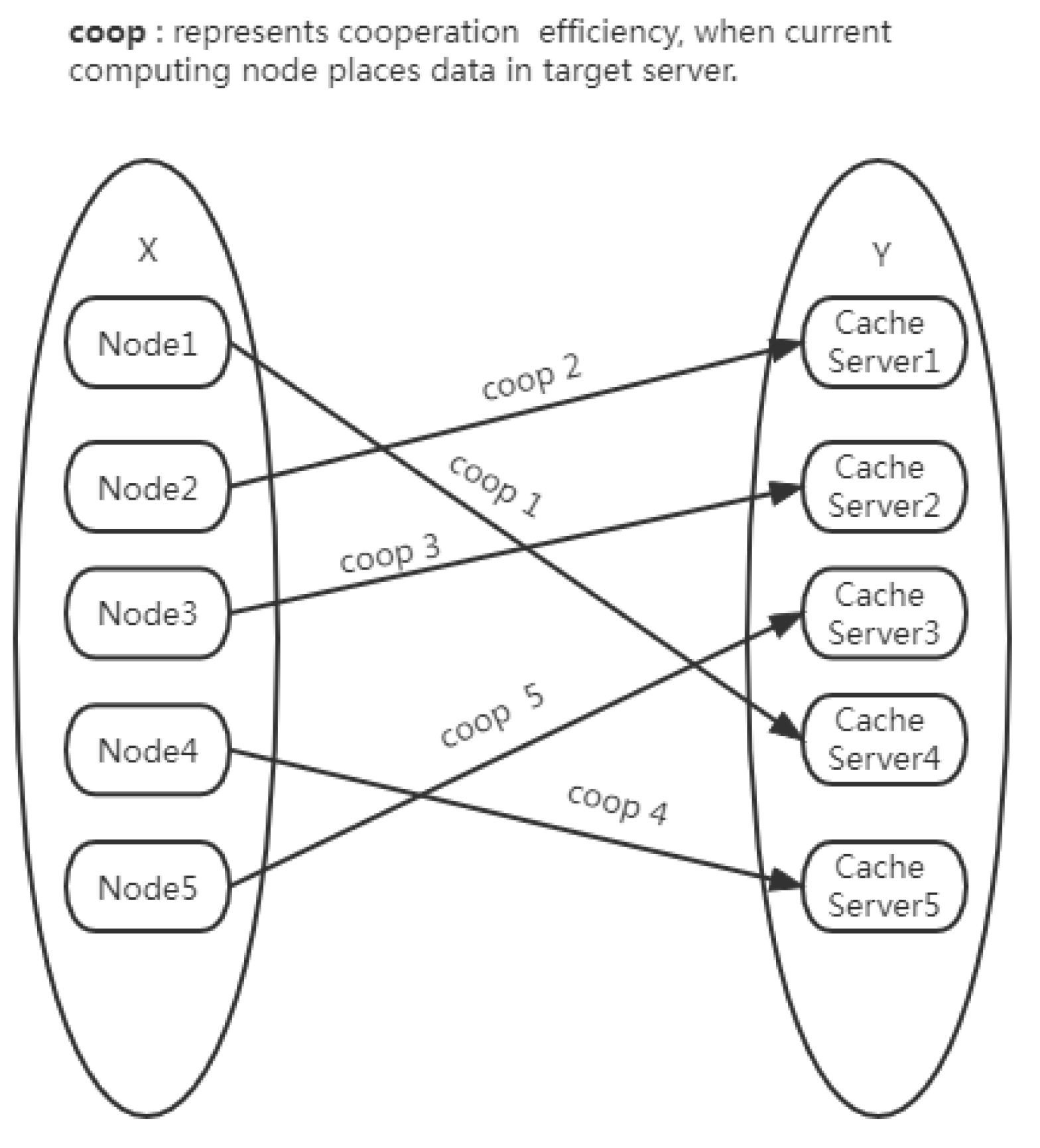
The cache data placement problem is similar to the virtual machine placement problem (VMP), and the related placement strategies have great guiding significance [
26,
27]. A virtual machine (VM) is a computer with a logically specific resource configuration. A physical machine (PM) refers to the computer configured by physical hardware resources. Actually, VMs run on the PMs. VMP refers to assigning a group of VMs to PMs using placement strategies to improve service efficiency. Recently, the research of VMP focuses on two aspects: the optimization of the matching algorithm and the definition of the objective function. For optimization of the matching algorithm, many mathematical optimization techniques are put to use. Hui Zhao et al. [
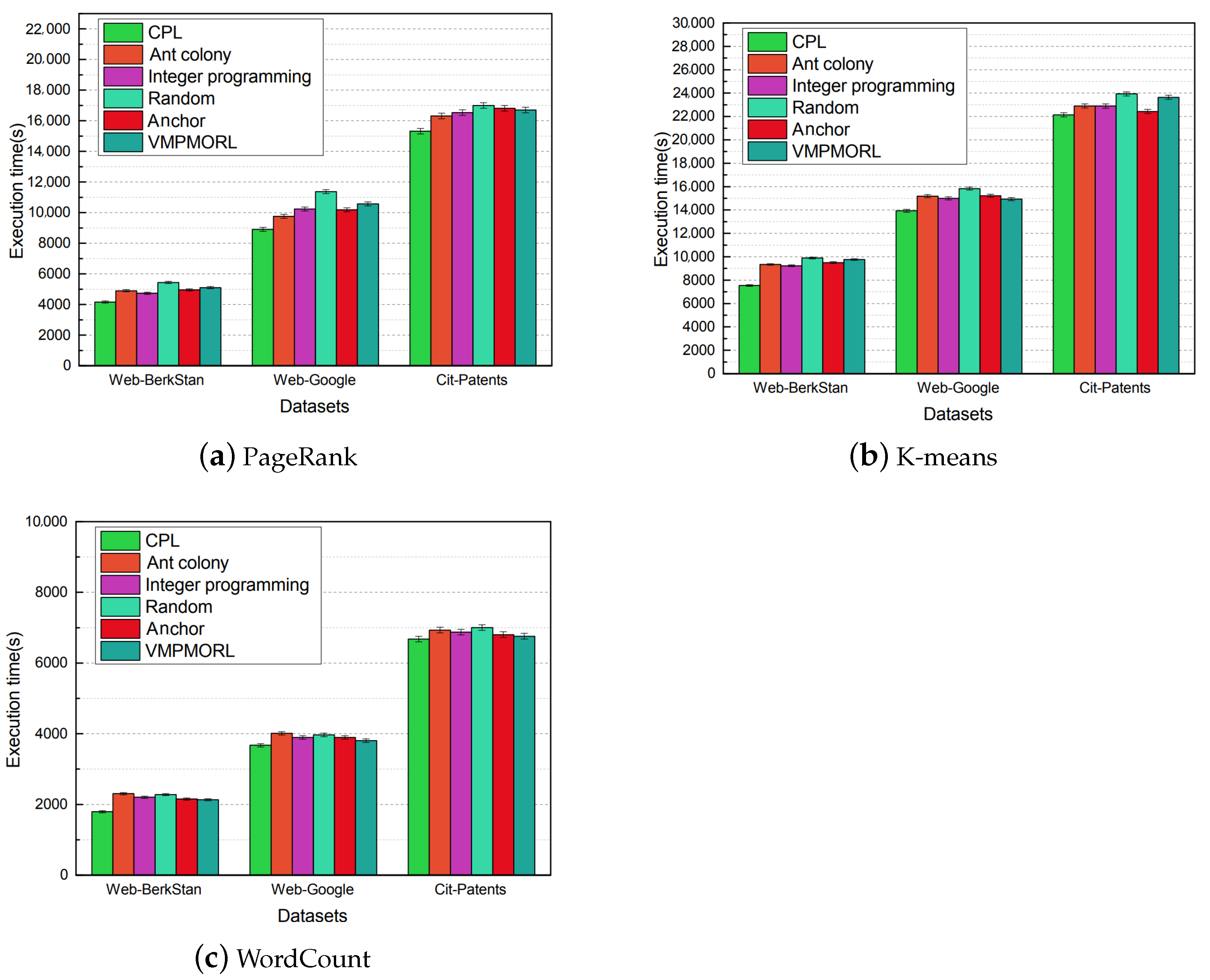
28] proposed an algorithm based on ant colony to minimize PM power consumption and guarantee VM performance. Ye et al. [
29] adopted an Integer Programming Model to minimize the number of PMs. Xu et al. [
30] proposed a new many-to-one stable matching theory, called Anchor, that efficiently matches VMs with heterogeneous resource needs to servers. For the definition of objective function, Qin et al. [
31] proposed a multi-objective virtual machine (VM) placement method, called VMPMORL, to minimize energy consumption and resource wastage simultaneously. Riahi et al. [
32] propose an efficient framework based on multi-objective genetic algorithm and Bernoulli simulation that aims to minimize simultaneously used hosts and resource wastage in each PM of the cloud computing platform. Mann et al. [
33] argue that it is necessary to simplify the model of scheduling issues. Then, they propose a multicore-aware virtual machine placement algorithm by constraint programming techniques. From what has been discussed aboved, they give different target functions and search algorithms to find the best match. However, the target function ignores the cooperation efficiency between computing node and cache servers. It is a key to measure which server is efficient. These search algorithms make it difficult to find the optimal solution in bipartite graph. The cache data placement problem can draw lessons from these research studies of VMP. However, the definition of thet objective function and more efficient matching algorithm need to be further explored in our study.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}