
Research on the Correlation Filter Tracking Model Based on the Deep-Pruned Feature Network


Abstract
:1. Introduction
2. Related Works
2.1. Deep Convolutional Neural Network Pruning
2.2. Online Updating of Feature Network
- (1)
- Based on our existing research results of channel-importance-propagation-based deep feature networks Pruning (PCIP), we implement a pre-pruning of the feature extraction network;
- (2)
- For the pre-pruned tracking feature network, the optimal determination of the global tracking pruning rate () of the deep feature network of the tracking model is proposed to maximize the tracking speed (which should at least meet the minimum requirement of 25 FPS for practical applications) under the precondition of satisfying the tracking accuracy;
- (3)
- Based on the optimally-determined (), alternative convolutional kernels are defined, and each alternative convolutional kernel is used to integrate the joint action of multiple unimportant convolutional kernels. Based on alternative convolutional kernels, a specific method for the secondary pruning of feature networks is given for the pre-pruned feature extraction network;
- (4)
- This paper presents an online updating method for the feature network based on SSIM (structural similarity index measurement) for changes in the tracking environment and the target;
- (5)
- An integration of the above methods is used to form the “correlation filter tracking model based on the deep-pruned feature network”;
- (6)
- Based on the OTB2013 dataset [29], the model proposed in this paper is verified.
3. Methods
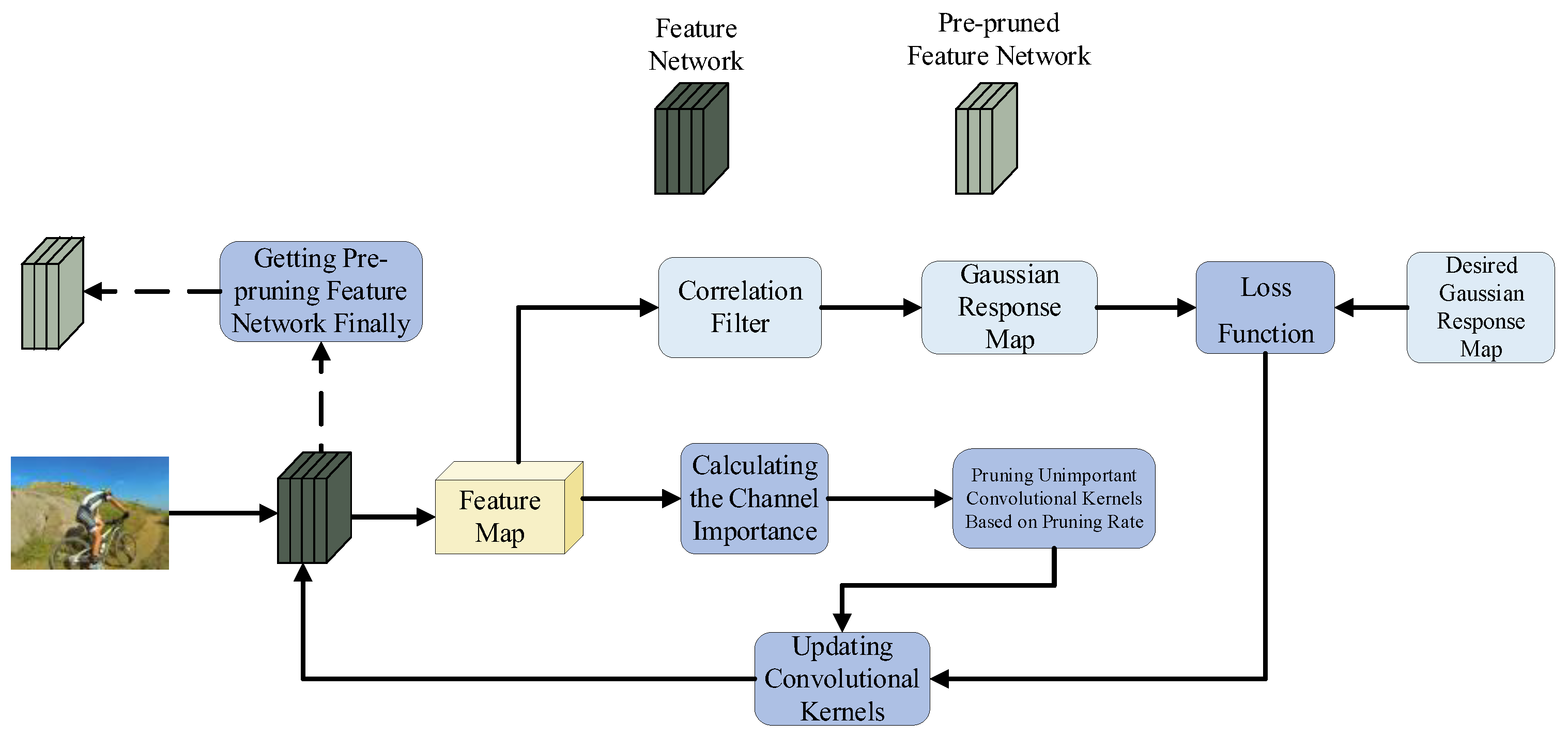
3.1. PCIP-Based Pre-Pruning of Deep Feature Network
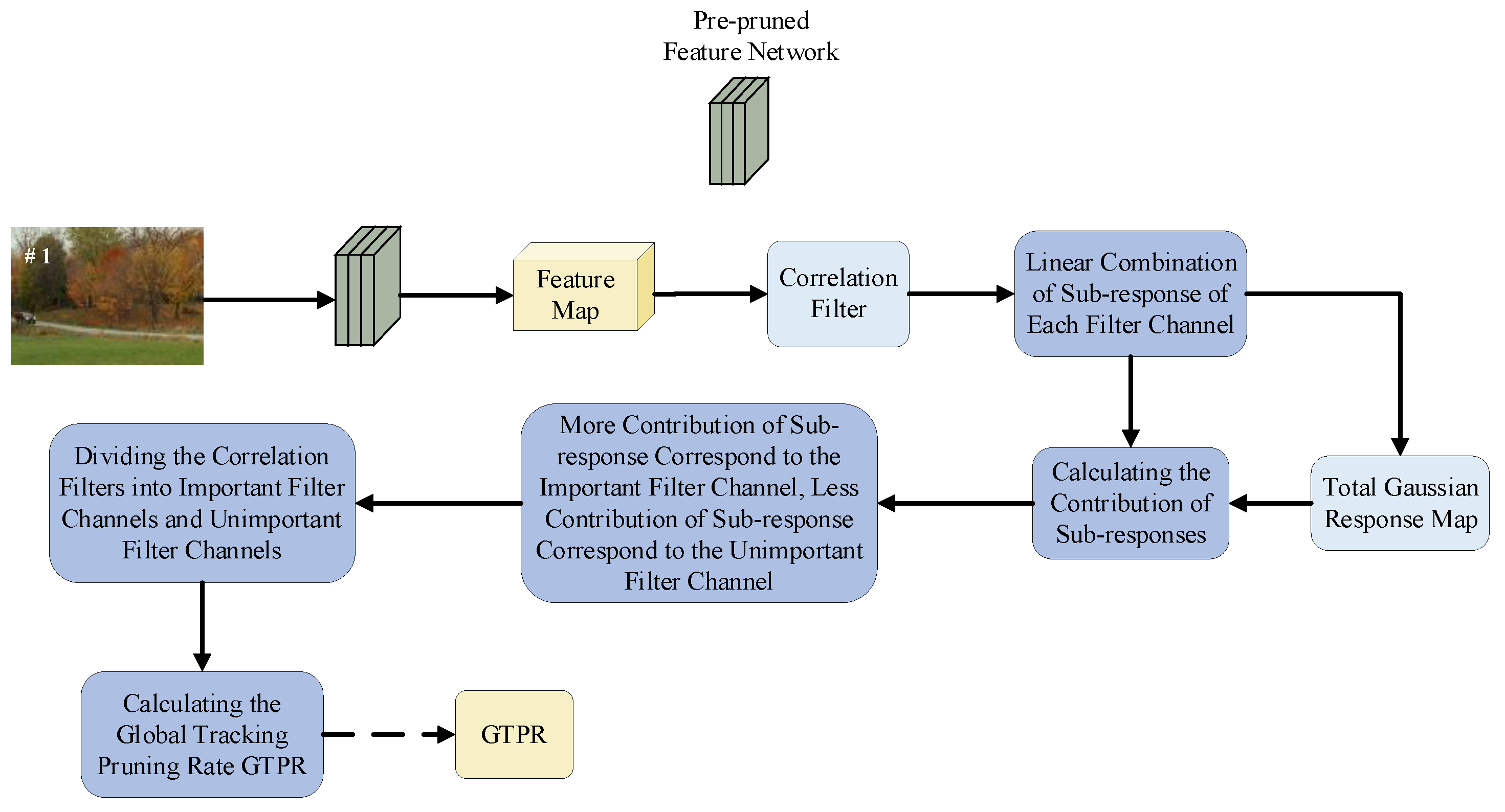
3.2. Optimal Determination of Global Tracking Pruning Rate Based on Tracking Response Contribution
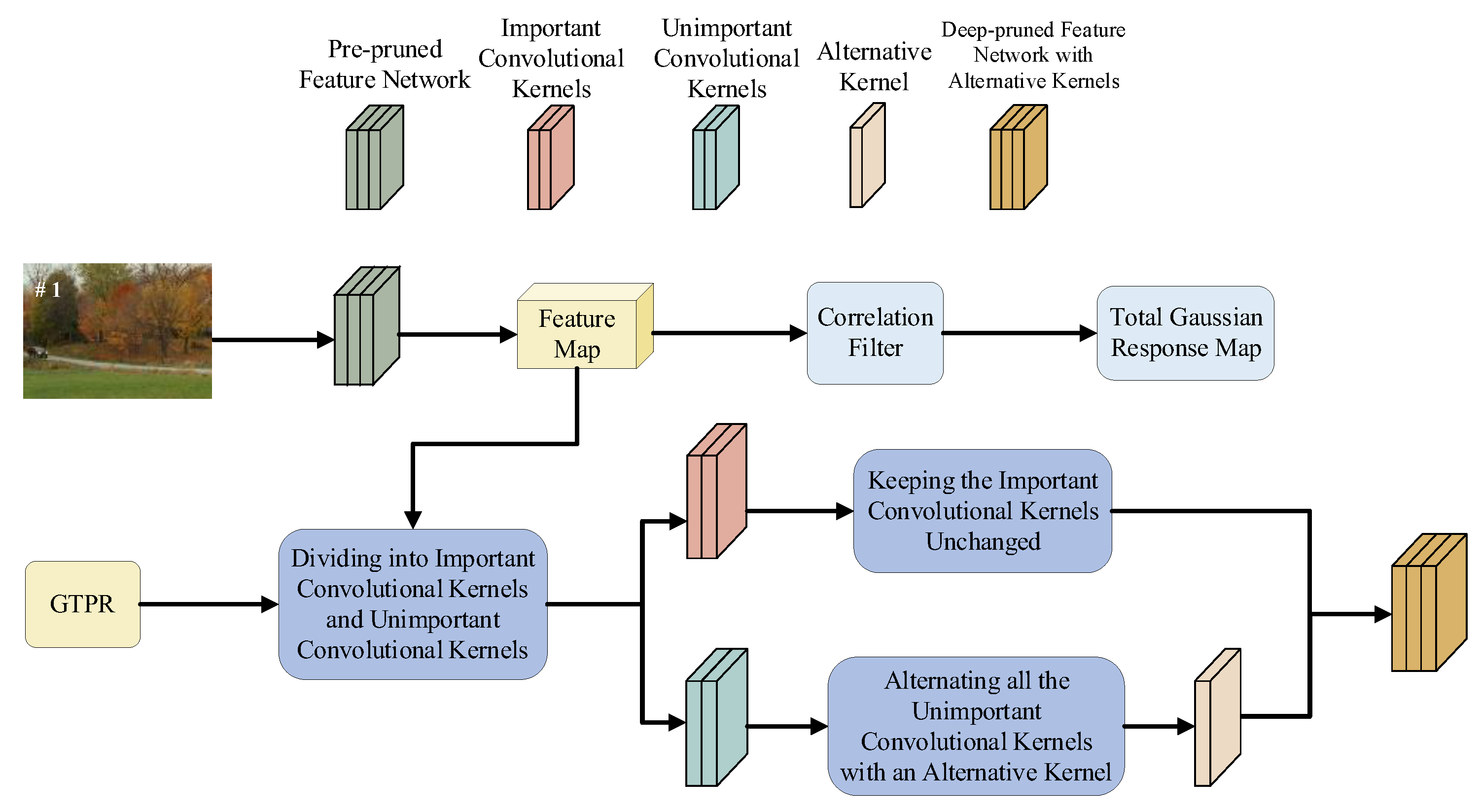
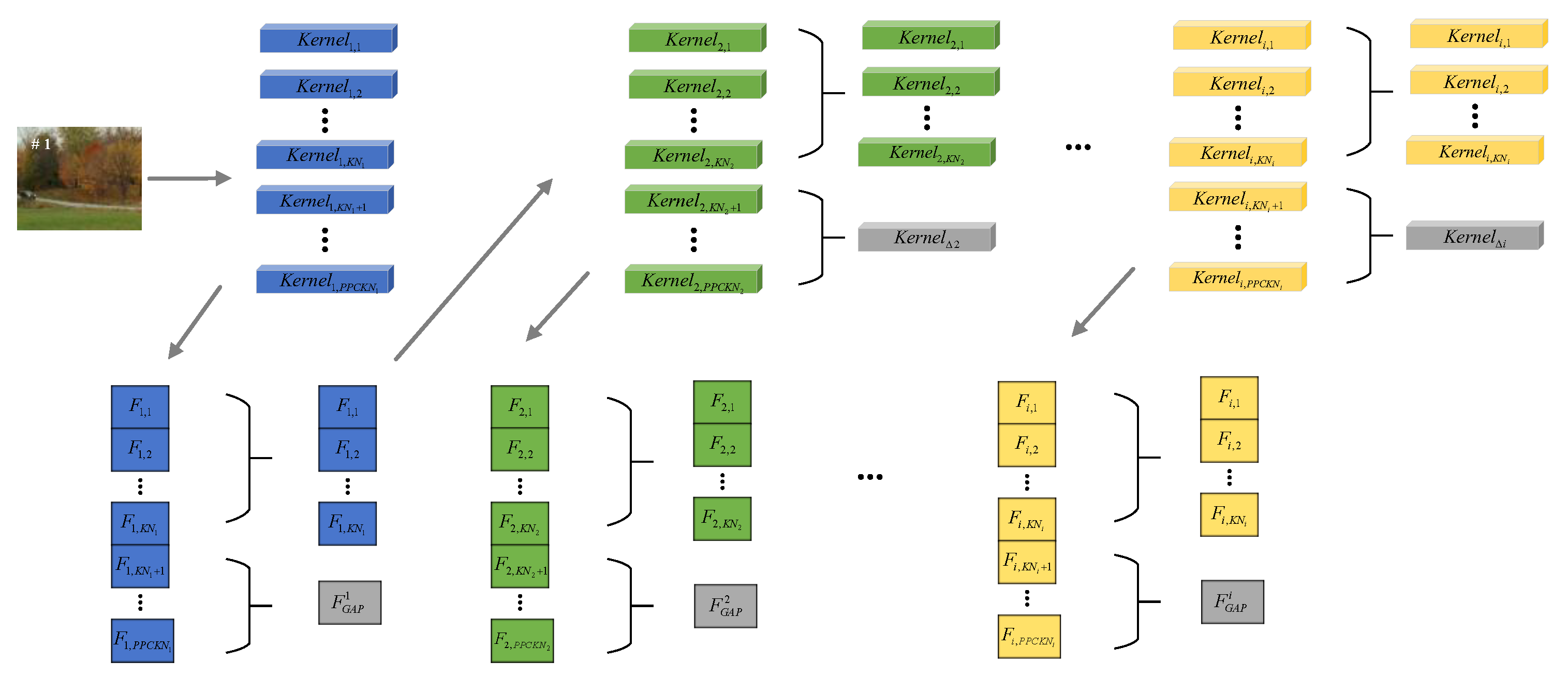
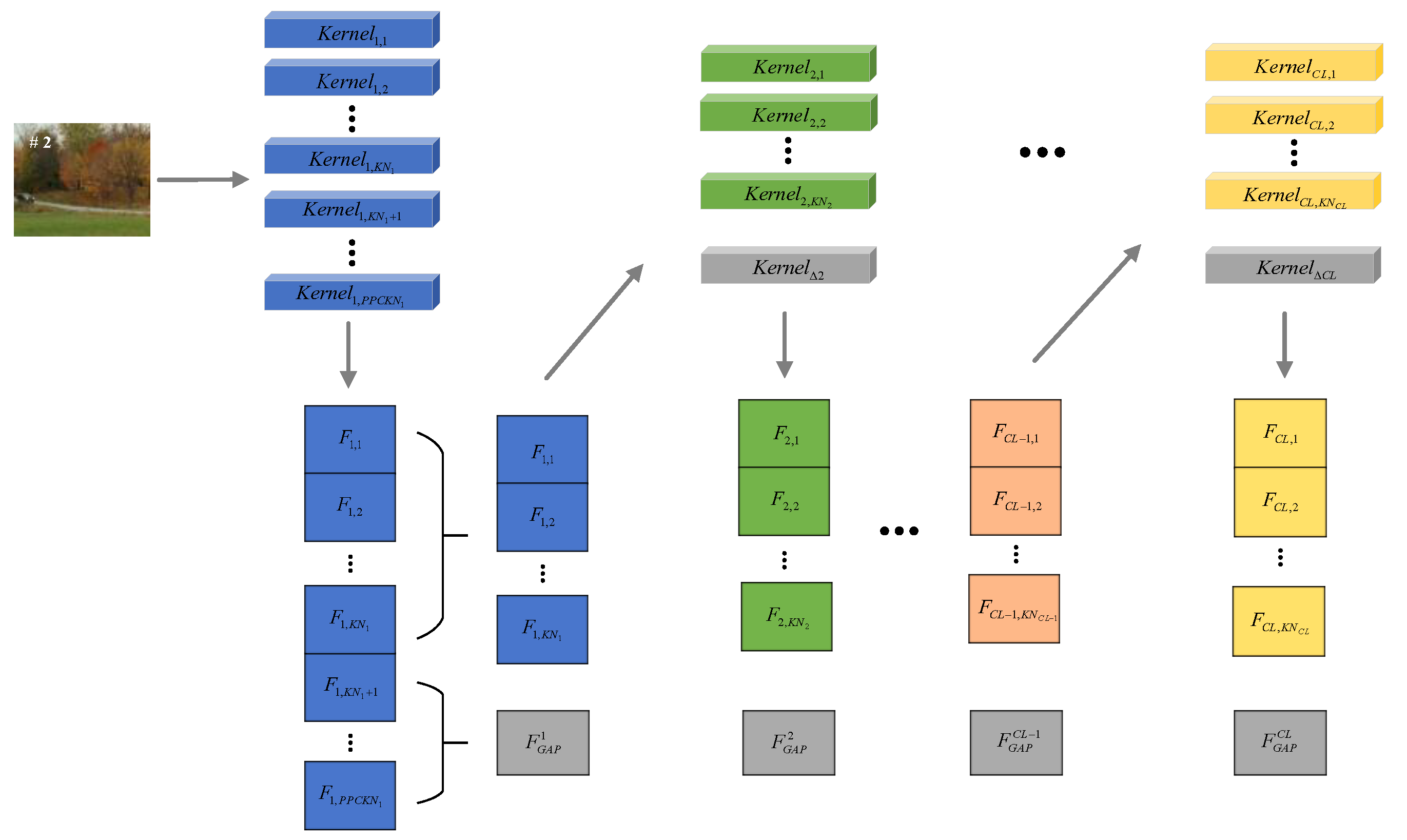
3.3. Secondary Pruning of Feature Extraction Network Based on Alternative Convolutional Kernels
3.4. Correlation Filter Tracking Model Based on the Deep-Pruned Feature Network
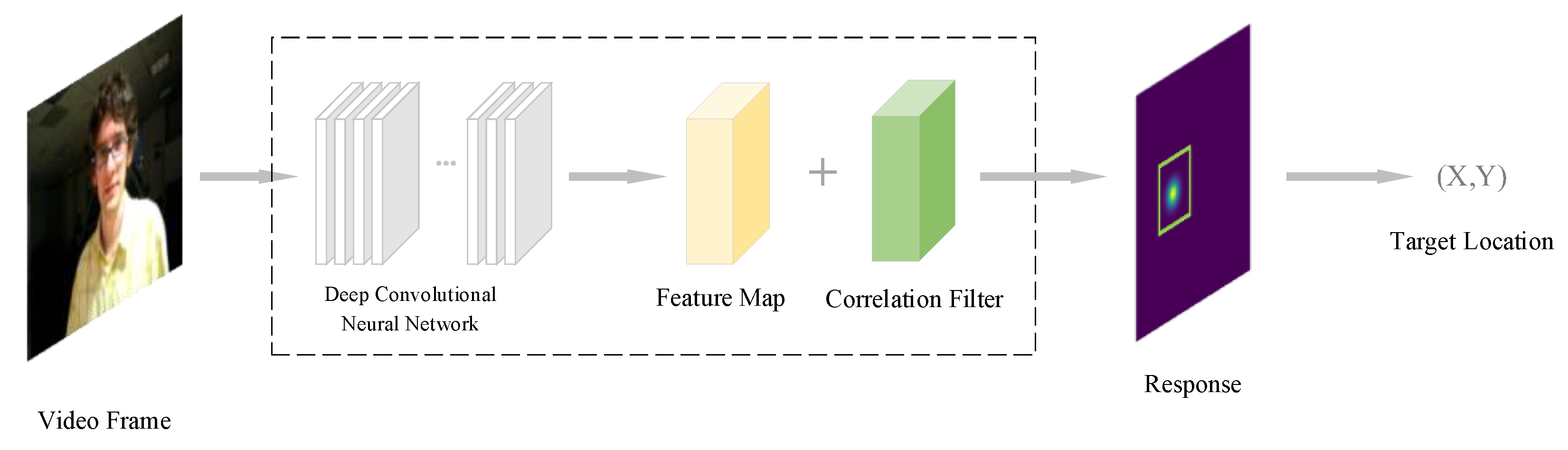
3.4.1. Feature Extraction
3.4.2. Correlation Filter Initialization
3.4.3. Target Location Prediction
3.4.4. Updating of Correlation Filter
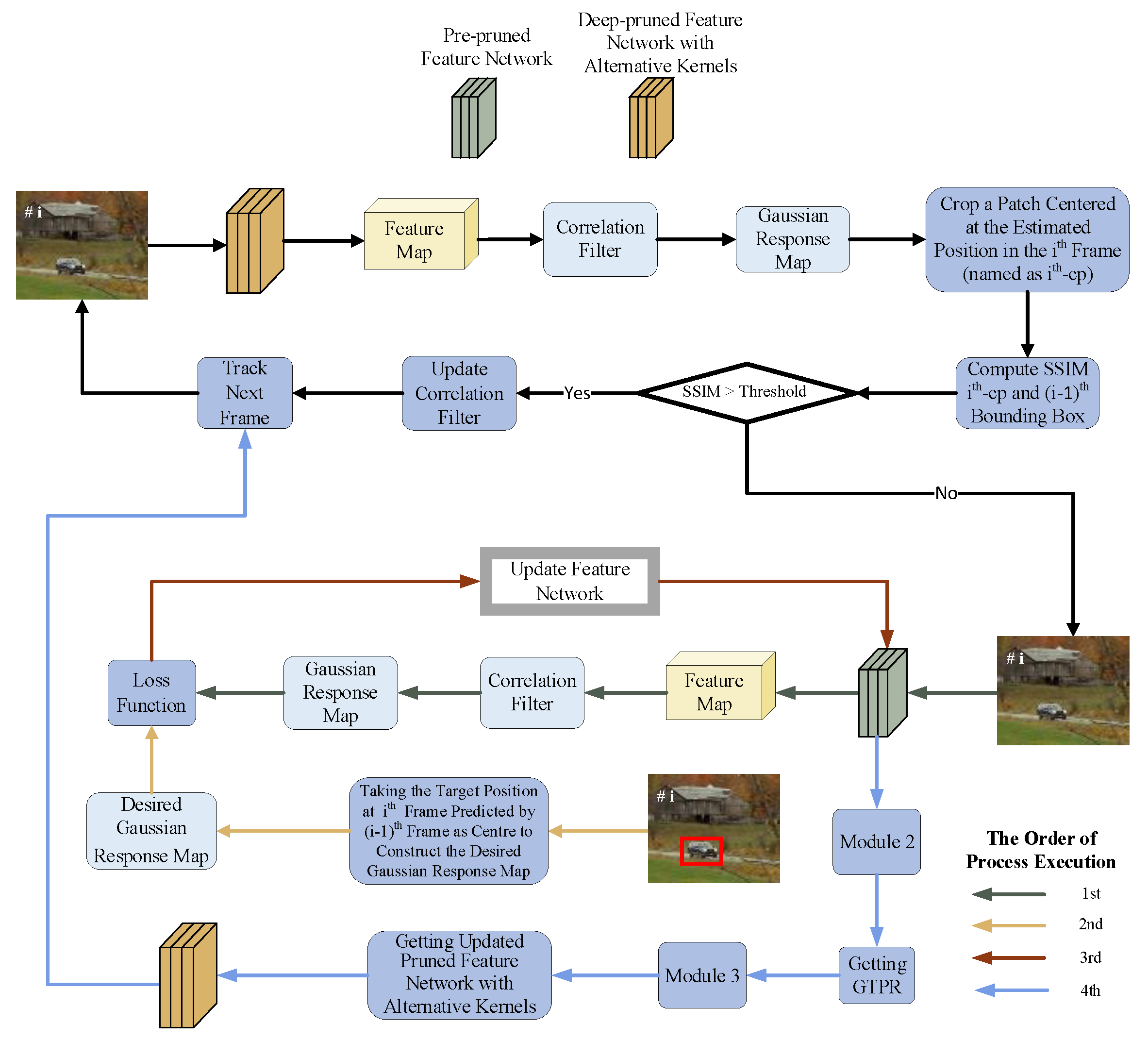
3.5. Online Updating of Deep-Pruned Feature Network with Alternative Kernels
- Step 1. The desired gaussian response map, denoted as DGRM, is constructed by centering on the target location of the frame predicted by frame , and the DGRM is used as Ground Truth.
- Step 2. The convolutional kernel parameters of the pre-pruned feature network are used as the initial values of the updating process, denoted as .
- Step 3. Using the frame as input, feature extraction is performed with the pre-pruned feature network, and the output features are correlated with the filter to generate the output response; i.e., Response. The error between Response and DGRM is calculated by the loss function defined in Equation (21), and the convolutional kernel parameters are updated once based on Equations (1)–(4). The convolutional kernel in layer of the updated pre-pruned feature network is denoted as .
- Step 4. The frame sequence is used as the input of the updated pre-pruned feature network, and the is redetermined using Equations (5)–(8).
- Step 5. Based on the redetermined , the updated deep-pruned feature network with alternative kernels is obtained by updating the alternative convolutional kernels using Equations (9)–(11).
- Step 6. The updated deep-pruned feature network with alternative kernels is used as the new feature extraction network to continue tracking from the frame sequence.
4. Experiment
4.1. Experiment Environment
4.2. Evaluation Metrics
4.3. Experiment Design
4.4. Experimental Results Analysis
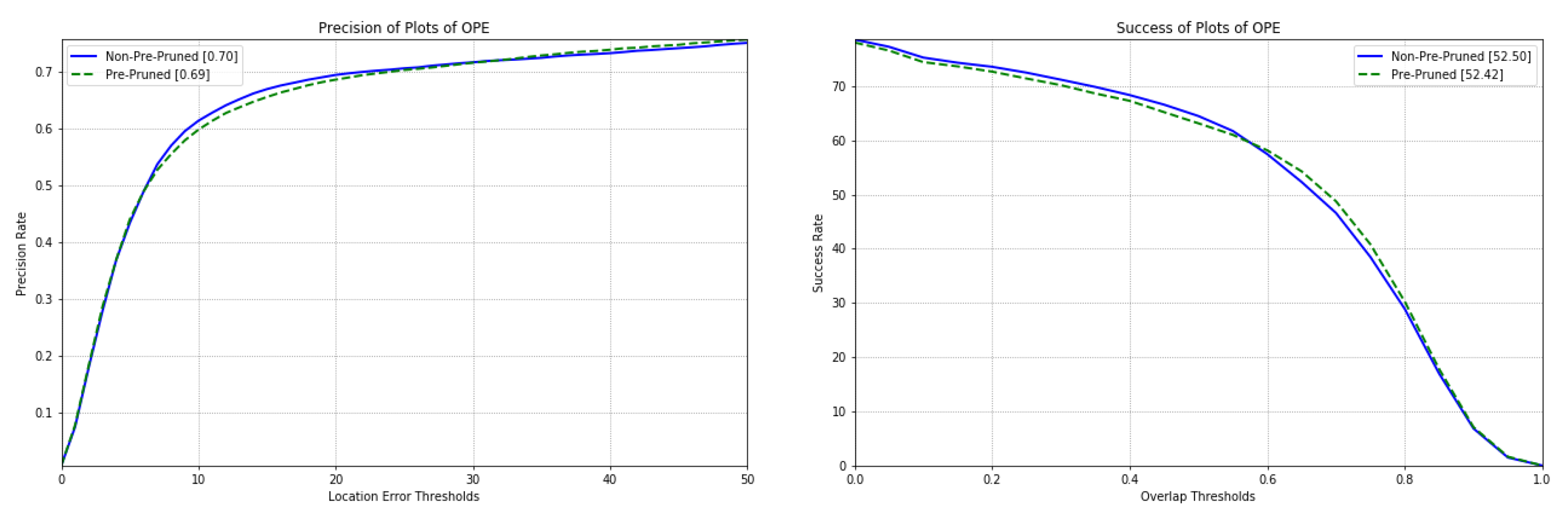
4.4.1. Comparative Study on Tracking Accuracy and Speed of Pre-Trained Feature Network before and after Pruning
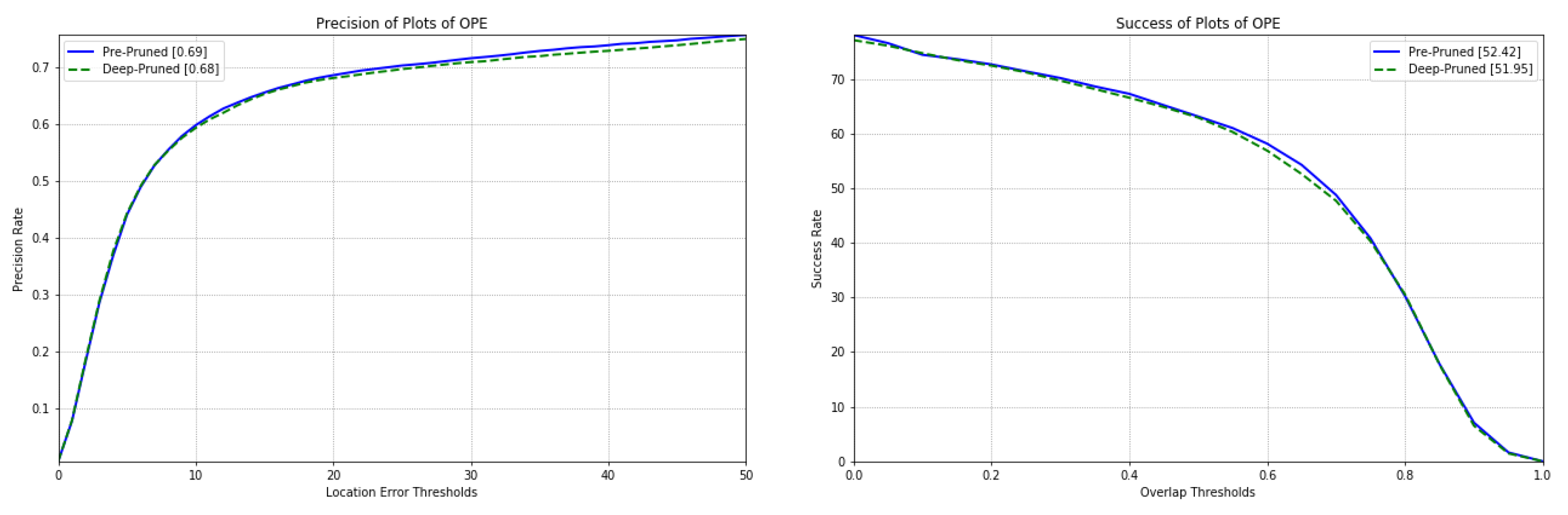
4.4.2. Comparative Study on Tracking Accuracy and Speed of Pre-Pruned Feature Network and Deep-Pruned Feature Network
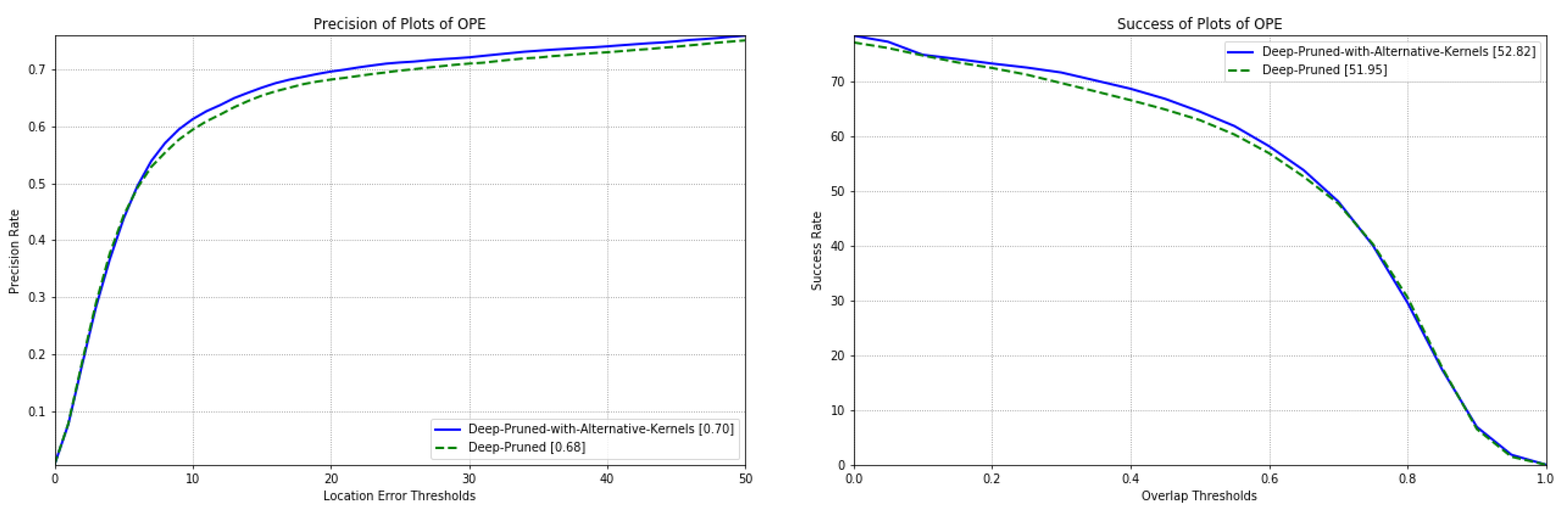
4.4.3. Comparative Study on Tracking Accuracy and Speed of Feature Network with or without Alternative Kernels
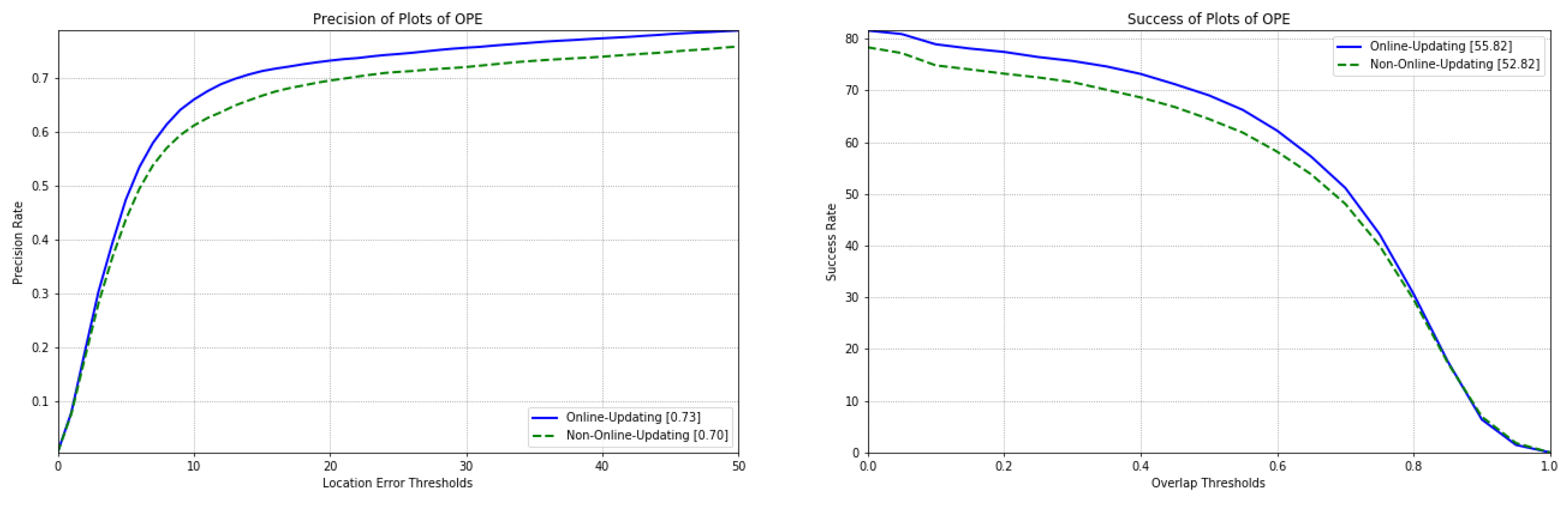
4.4.4. Comparative Study on Tracking Accuracy and Speed of Feature Network with or without Online Updating
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, C.; Chen, H. Research on lightweight deep correlation filter tracking algorithm based on fuzzy decision. In Proceedings of the 2021 2nd International Conference on Computer Science and Management Technology (ICCSMT), Shanghai, China, 12–14 November 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Chen, H.; Li, C. Pruning deep feature networks using channel importance propagation. In Proceedings of the 2021 2nd International Conference on Computer Science and Management Technology (ICCSMT), Shanghai, China, 12–14 November 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Yang, G.; Li, C.; Chen, H. Research on deep correlation filter tracking based on channel importance. EURASIP J. Adv. Signal Process 2022, 2022, 28. [Google Scholar] [CrossRef]
- Li, C.; Yang, G. Deep correlation filter visual tracking algorithm based on channel importance and target similarity. (unpublished).
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef] [Green Version]
- Shi, J. Good features to track. In Proceedings of the 1994 Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; IEEE: Piscataway, NJ, USA, 1994; pp. 593–600. [Google Scholar]
- Nummiaro, K.; Koller-Meier, E.; Van Gool, L. An adaptive color-based particle filter. Image Vis. Comput. 2003, 21, 99–110. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-Detection with Kernels. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume Part IV. [Google Scholar]
- Henriques, J.F.; Rui, C.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration. In Proceedings of the Computer Vision–ECCV 2014 Workshops, Zurich, Switzerland, 6–12 September 2014; Agapito, L., Bronstein, M.M., Rother, C., Eds.; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep residual shrinkage networks for fault diagnosis. IEEE Trans. Ind. Inform. 2019, 16, 4681–4690. [Google Scholar] [CrossRef]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate Scale Estimation for Robust Visual Tracking; Bmva Press: Blue Mountain, ON, Canada, 2014. [Google Scholar]
- Xin, J.; Du, X.; Zhang, J. Deep learning for robust outdoor vehicle visual tracking. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Cheng, J.; Wang, P.; Li, G.; Hu, Q.; Lu, H. Recent advances in efficient computation of deep convolutional neural networks. Front. Inform. Technol. Elect. Eng. 2018, 19, 64–77. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Wang, D.; Wang, L.; Lu, H. Deep visual tracking: Review and experimental comparison. Pattern Recognit. 2018, 76, 323–338. [Google Scholar] [CrossRef]
- Voigtlaender, P.; Leibe, B. Online adaptation of convolutional neural networks for video object segmentation. arXiv 2017, arXiv:1706.09364. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Song, Y.; Ma, C.; Gong, L.; Zhang, J.; Lau, R.W.; Yang, M. Crest: Convolutional residual learning for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2–29 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Li, Y.; Song, L.; Chen, Y.; Li, Z.; Zhang, X.; Wang, X.; Sun, J. Learning dynamic routing for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Jia, X.; De Brabandere, B.; Tuytelaars, T.; Gool, L.V. Dynamic filter networks. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; p. 29. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft filter pruning for accelerating deep convolutional neural networks. arXiv 2018, arXiv:1808.06866. [Google Scholar]
- Yang, X.; Lu, H.; Shuai, H.; Yuan, X.T. Pruning Convolutional Neural Networks via Stochastic Gradient Hard Thresholding. In Proceedings of the Second Chinese Conference, PRCV 2019, Xi’an, China, 8–11 November 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 373–385. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2–29 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Ye, Y.; You, G.; Fwu, J.; Zhu, X.; Yang, Q.; Zhu, Y. Channel pruning via optimal thresholding. In Proceedings of the 27th International Conference, ICONIP 2020, Bangkok, Thailand, 18–22 November 2020; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Zhuling, Q.; Yufei, Z.; Peng, Z.; Min, W. Visual Tracking Algorithm Based on Online Feature Discrimination with Siamese Network. Acta Opt. Sin. 2019, 39, 915003. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M. Online object tracking: A benchmark. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Wang, Q.; Gao, J.; Xing, J.; Zhang, M.; Hu, W. Dcfnet: Discriminant correlation filters network for visual tracking. arXiv 2017, arXiv:1704.04057. [Google Scholar]
- Curran-Everett, D.; Taylor, S.; Kafadar, K. Fundamental concepts in statistics: Elucidation and illustration. J. Appl. Physiol. 1998, 85, 775–786. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Danelljan, M.; Robinson, A.; Shahbaz Khan, F.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the 4th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Option | Non-Pre-Pruned | Pre-Pruned |
|---|---|---|
| AOR | 52.50 | 52.42 |
| APE | 0.70 | 0.69 |
| Speed | 68.50 | 76.30 |
| Training Option | Pre-Pruned | Deep-Pruned |
|---|---|---|
| AOR | 52.42 | 51.95 |
| APE | 0.69 | 0.68 |
| Speed | 76.30 | 99.50 |
| Training Option | Deep-Pruned | Deep-Pruned with Alternative Kernels |
|---|---|---|
| AOR | 51.95 | 52.82 |
| APE | 0.68 | 0.70 |
| Speed | 99.50 | 97.60 |
| Training Option | Non-Online-Updating | Online-Updating |
|---|---|---|
| AOR | 52.82 | 55.82 |
| APE | 0.70 | 0.73 |
| Speed | 97.60 | 84.80 |
| Training Option | Non-Pre-Pruned | Pre-Pruned | Deep-Pruned | Deep-Pruned with Alternative Kernels | Online-Updating |
|---|---|---|---|---|---|
| AOR | 52.50 | 52.42 | 51.95 | 52.82 | 55.82 |
| APE | 0.70 | 0.69 | 0.68 | 0.70 | 0.73 |
| Speed | 68.50 | 76.30 | 99.50 | 97.60 | 84.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Li, C.; Chaomurilige. Research on the Correlation Filter Tracking Model Based on the Deep-Pruned Feature Network. Appl. Sci. 2022, 12, 11490. https://doi.org/10.3390/app122211490
Chen H, Li C, Chaomurilige. Research on the Correlation Filter Tracking Model Based on the Deep-Pruned Feature Network. Applied Sciences. 2022; 12(22):11490. https://doi.org/10.3390/app122211490
Chicago/Turabian StyleChen, Honglin, Chunting Li, and Chaomurilige. 2022. "Research on the Correlation Filter Tracking Model Based on the Deep-Pruned Feature Network" Applied Sciences 12, no. 22: 11490. https://doi.org/10.3390/app122211490