
Deep Learning for Intelligent Human–Computer Interaction


Abstract
:1. Introduction
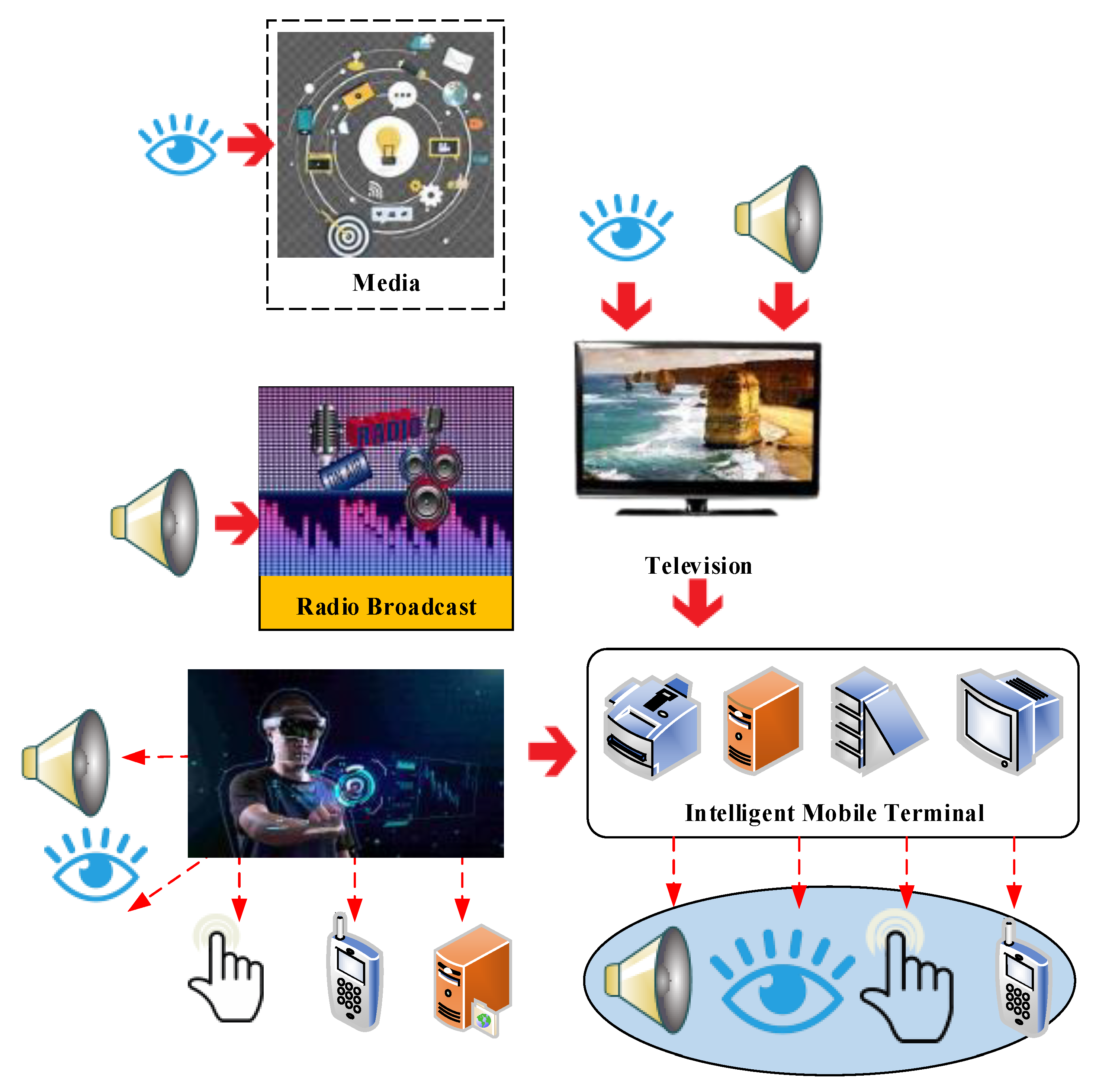
2. Adoption Status of Deep Learning in Intelligent HCI
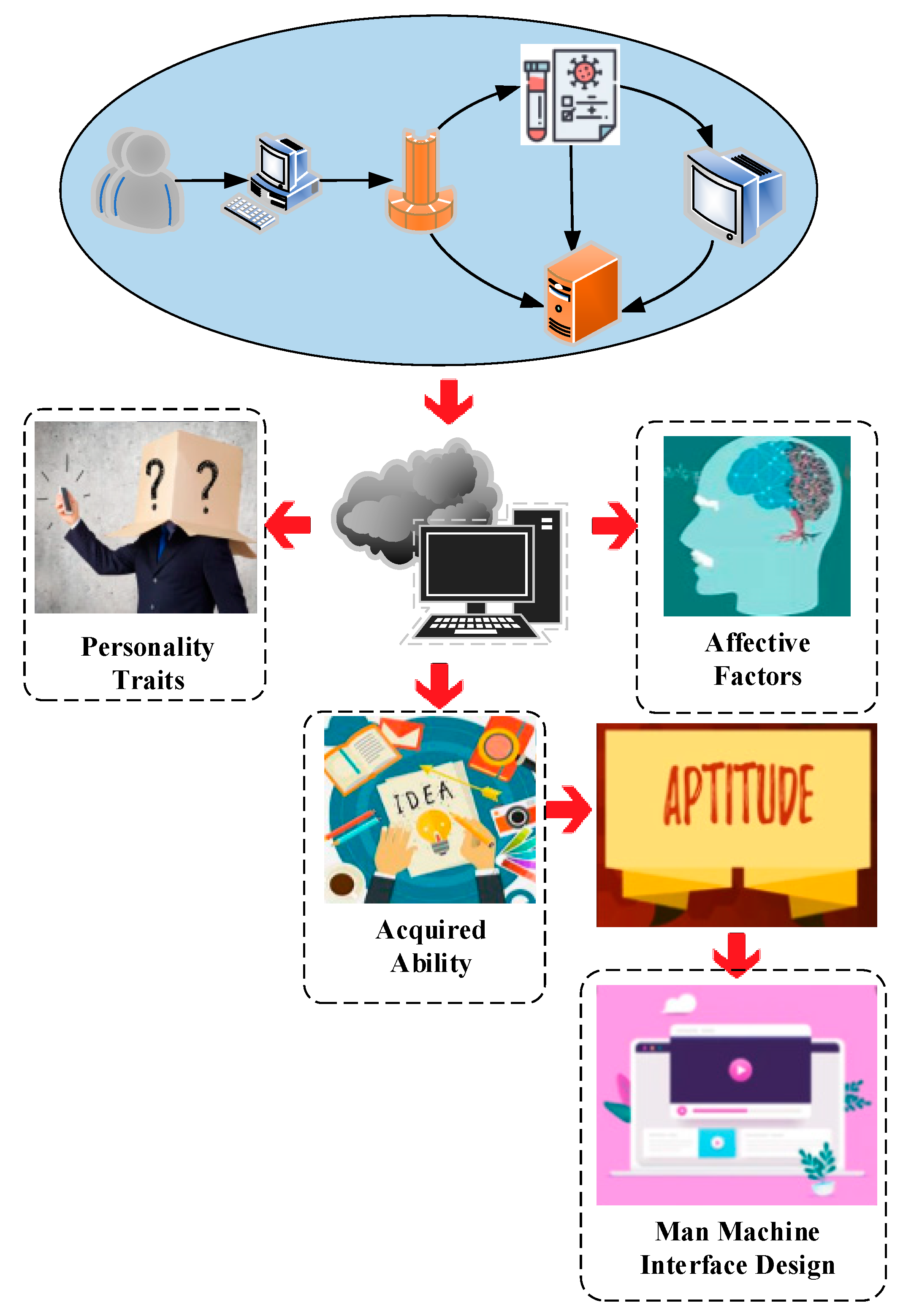
3. Application of Deep Learning in HCI Intelligent Systems
4. Development Status of Intelligent Voice Interaction System
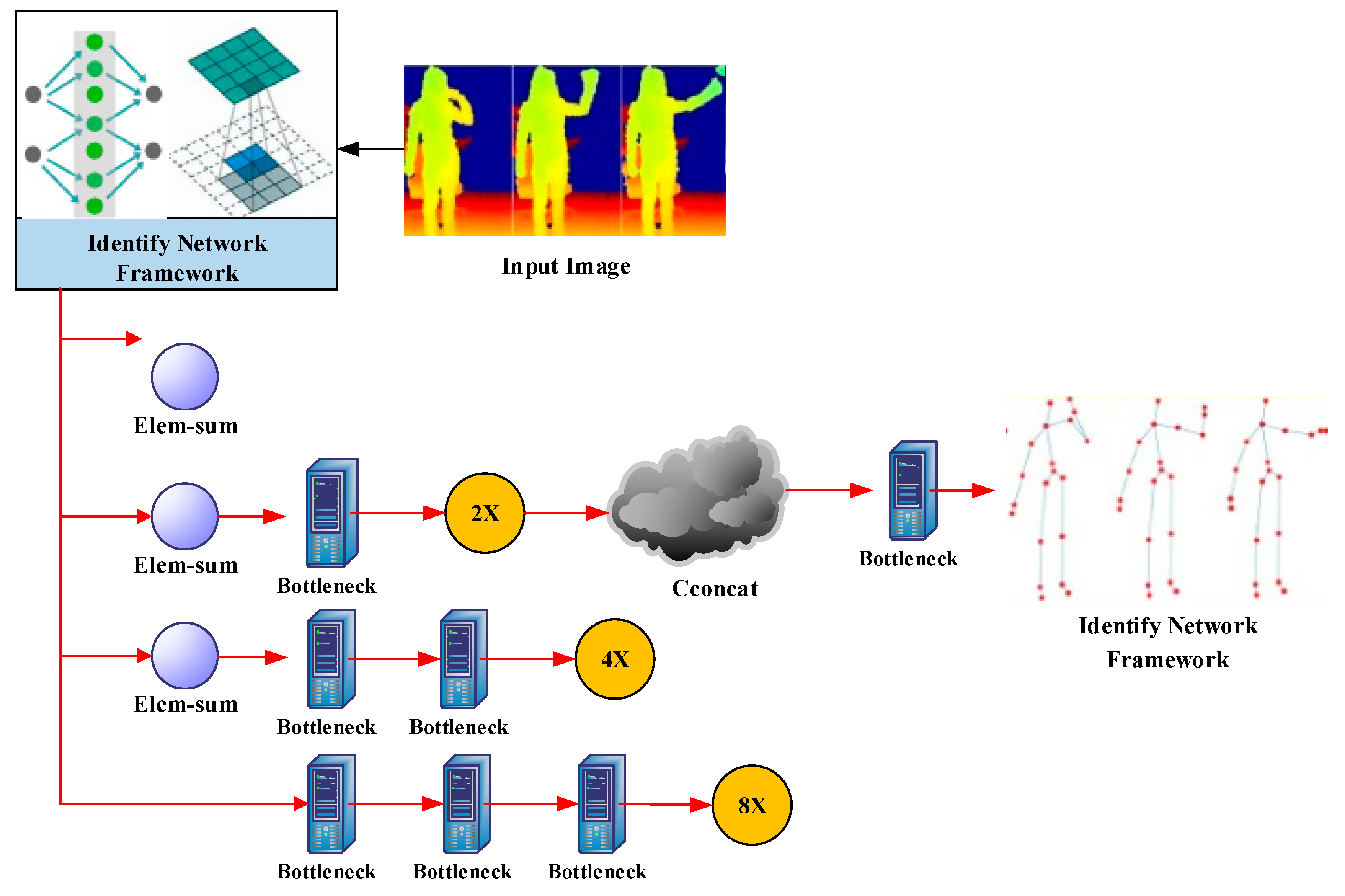
5. Human Gesture Recognition Based on Deep Learning
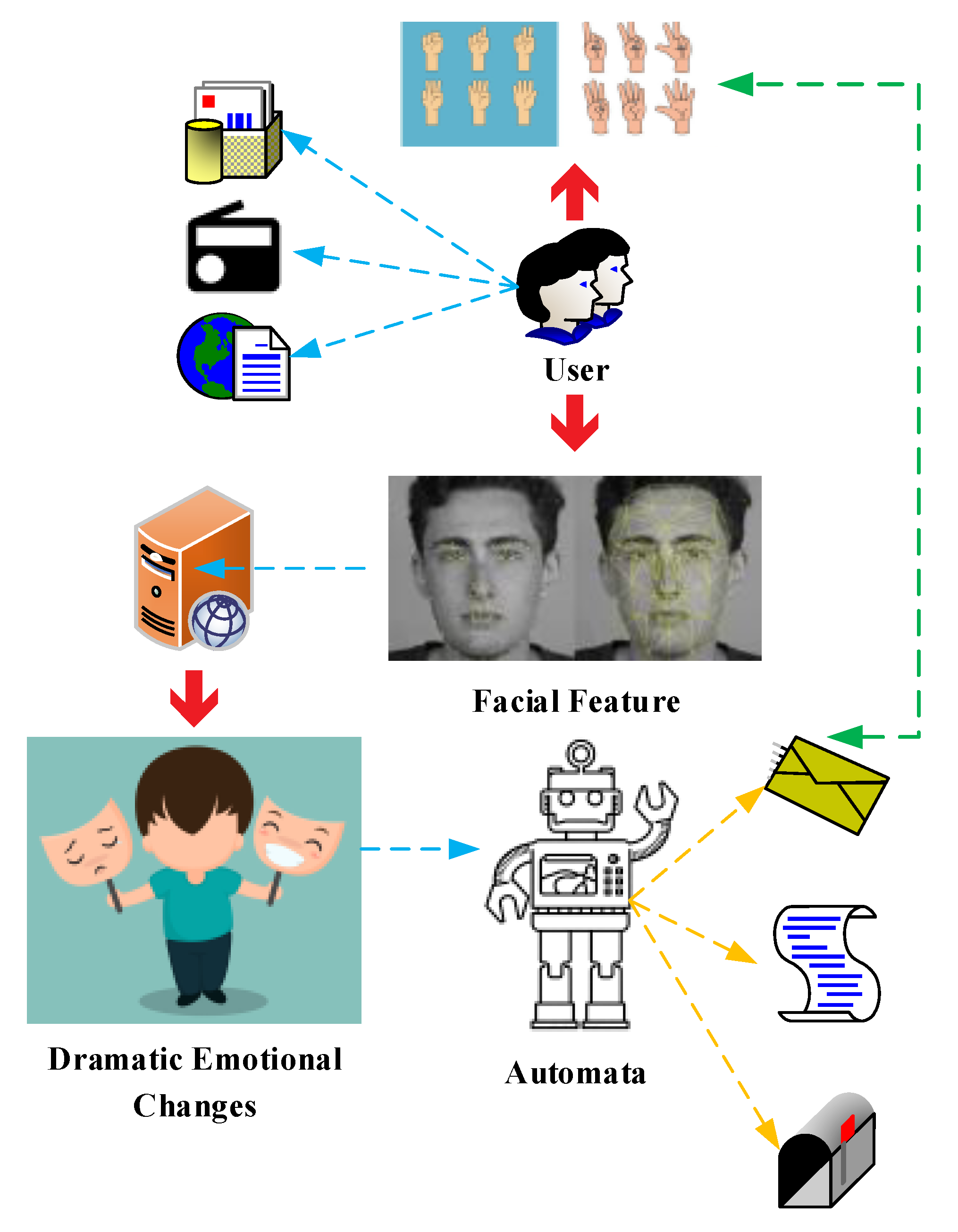
6. Natural Language Processing and HCI
7. Summary of the Application Status of Deep Learning in HCI
8. Challenges of Deep Learning in Intelligent HCI
9. Conclusions
Funding
Conflicts of Interest
References
- Jarosz, M.; Nawrocki, P.; Śnieżyński, B.; Indurkhya, B. Multi-Platform Intelligent System for Multimodal Human-Computer Interaction. Comput. Inform. 2021, 40, 83–103. [Google Scholar] [CrossRef]
- Prathiba, T.; Kumari, R.S.S. Content based video retrieval system based on multimodal feature grouping by KFCM clustering algorithm to promote human–computer interaction. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 6215–6229. [Google Scholar] [CrossRef]
- Wang, Z.; Jiao, R.; Jiang, H. Emotion Recognition Using WT-SVM in Human-Computer Interaction. J. New Media 2020, 2, 121–130. [Google Scholar] [CrossRef]
- Fu, Q.; Lv, J. Research on Application of Cognitive-Driven Human-Computer Interaction. Am. Sci. Res. J. Eng. Technol. Sci. 2020, 64, 9–27. [Google Scholar]
- Ince, G.; Yorganci, R.; Ozkul, A.; Duman, T.B.; Köse, H. An audiovisual interface-based drumming system for multimodal human–robot interaction. J. Multimodal User Interfaces 2020, 15, 413–428. [Google Scholar] [CrossRef]
- Raptis, G.; Kavvetsos, G.; Katsini, C. MuMIA: Multimodal Interactions to Better Understand Art Contexts. Appl. Sci. 2021, 11, 2695. [Google Scholar] [CrossRef]
- Wang, J.; Cheng, R.; Liu, M.; Liao, P.-C. Research Trends of Human–Computer Interaction Studies in Construction Hazard Recognition: A Bibliometric Review. Sensors 2021, 21, 6172. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, J.; Zhao, Q. Multimodal Fused Emotion Recognition About Expression-EEG Interaction and Collaboration Using Deep Learning. IEEE Access 2020, 8, 133180–133189. [Google Scholar] [CrossRef]
- Lai, H.; Chen, H.; Wu, S. Different Contextual Window Sizes Based RNNs for Multimodal Emotion Detection in Interactive Conversations. IEEE Access 2020, 8, 119516–119526. [Google Scholar] [CrossRef]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. A review of multimodal human activity recognition with special emphasis on classification, applications, challenges and future directions. Knowledge-Based Syst. 2021, 223, 106970. [Google Scholar] [CrossRef]
- Mosquera-DeLaCruz, J.H.; Loaiza-Correa, H.; Nope-Rodríguez, S.E.; Restrepo-Girón, A.D. Human-computer multimodal interface to internet navigation. Disabil. Rehabil. Assist. Technol. 2021, 16, 807–820. [Google Scholar] [CrossRef] [PubMed]
- Nayak, S.; Nagesh, B.; Routray, A.; Sarma, M. A Human–Computer Interaction framework for emotion recognition through time-series thermal video sequences. Comput. Electr. Eng. 2021, 93, 107280. [Google Scholar] [CrossRef]
- Yang, T.; Hou, Z.; Liang, J.; Gu, Y.; Chao, X. Depth Sequential Information Entropy Maps and Multi-Label Subspace Learning for Human Action Recognition. IEEE Access 2020, 8, 135118–135130. [Google Scholar] [CrossRef]
- Panjaitan, M.I.; Rajagukguk, D.M. Development of computer-based photoshop learning media using computer based interaction method. J. Sci. 2020, 8, 37–41. [Google Scholar]
- Liu, X.; Zhang, L. Design and Implementation of Human-Computer Interaction Adjustment in Nuclear Power Monitoring System. Mi-croprocessors and Microsystems. Microprocess. Microsyst. 2021, 104096. [Google Scholar] [CrossRef]
- Yuan, J.; Feng, Z.; Dong, D.; Meng, X.; Meng, J.; Kong, D. Research on Multimodal Perceptual Navigational Virtual and Real Fusion Intelligent Experiment Equipment and Algorithm. IEEE Access 2020, 8, 43375–43390. [Google Scholar] [CrossRef]
- Dybvik, H.; Erichsen, C.K.; Steinert, M. Demonstrating the feasibility of multimodal neuroimaging data capture with a wearable electoencephalography + functional near-infrared spectroscopy (eeg+fnirs) in situ. Proc. Des. Soc. 2021, 1, 901–910. [Google Scholar] [CrossRef]
- Hu, Y.; Li, Z. Research on Human-Computer Interaction Control Method in the Background of Internet of Things. J. Interconnect. Networks 2022, 22, 2143015. [Google Scholar] [CrossRef]
- Fox, J.; Gambino, A. Relationship Development with Humanoid Social Robots: Applying Interpersonal Theories to Human–Robot Interaction. Cyberpsychol. Behav. Soc. Netw. 2021, 24, 294–299. [Google Scholar] [CrossRef]
- Henschel, A.; Hortensius, R.; Cross, E.S. Social cognition in the age of human–robot interaction. Trends Neurosci. 2020, 43, 373–384. [Google Scholar] [CrossRef]
- Sebo, S.; Stoll, B.; Scassellati, B.; Jung, M.F. Robots in groups and teams: A literature review. Proc. ACM Hum.-Comput. Interact. 2020, 4, 176. [Google Scholar] [CrossRef]
- Lei, X.; Rau, P.-L.P. Should I Blame the Human or the Robot? Attribution within a Human–Robot Group. Int. J. Soc. Robot. 2021, 13, 363–377. [Google Scholar] [CrossRef]
- Iio, T.; Yoshikawa, Y.; Chiba, M.; Asami, T.; Isoda, Y.; Ishiguro, H. Twin-Robot Dialogue System with Robustness against Speech Recognition Failure in Human-Robot Dialogue with Elderly People. Appl. Sci. 2020, 10, 1522. [Google Scholar] [CrossRef] [Green Version]
- Pan, S. Design of intelligent robot control system based on human–computer interaction. Int. J. Syst. Assur. Eng. Manag. 2021, 1–10. [Google Scholar] [CrossRef]
- Ma, G.; Hao, Z.; Wu, X.; Wang, X. An optimal Electrical Impedance Tomography drive pattern for human-computer interaction applications. IEEE Trans. Biomed. Circuits Syst. 2020, 14, 402–411. [Google Scholar] [CrossRef]
- Li, X. Human–robot interaction based on gesture and movement recognition. Signal Process. Image Commun. 2020, 81, 115686. [Google Scholar] [CrossRef]
- Robert, L.P., Jr.; Bansal, G.; Lütge, C. ICIS 2019 SIGHCI workshop panel report: Human–computer interaction challenges and opportunities for fair, trustworthy and ethical artificial intelligence. AIS Trans. Hum.-Comput. Interact. 2020, 12, 96–108. [Google Scholar] [CrossRef]
- Shu, Y.; Xiong, C.; Fan, S. Interactive design of intelligent machine vision based on human–computer interaction mode. Microprocess. Microsyst. 2020, 75, 103059. [Google Scholar] [CrossRef]
- Luria, M.; Sheriff, O.; Boo, M.; Forlizzi, J.; Zoran, A. Destruction, Catharsis, and Emotional Release in Human-Robot Interaction. ACM Trans. Hum.-Robot Interact. 2020, 9, 22. [Google Scholar] [CrossRef]
- Demir, M.; McNeese, N.J.; Cooke, N.J. Understanding human-robot teams in light of all-human teams: Aspects of team interaction and shared cognition. Int. J. Hum.-Comput. Stud. 2020, 140, 102436. [Google Scholar] [CrossRef]
- Johal, W. Research Trends in Social Robots for Learning. Curr. Robot. Rep. 2020, 1, 75–83. [Google Scholar] [CrossRef]
- Jyoti, V.; Lahiri, U. Human-Computer Interaction based Joint Attention cues: Implications on functional and physiological measures for children with autism spectrum disorder. Comput. Hum. Behav. 2020, 104, 106163. [Google Scholar] [CrossRef]
- Suwa, S.; Tsujimura, M.; Ide, H.; Kodate, N.; Ishimaru, M.; Shimamura, A.; Yu, W. Home-care Professionals’ Ethical Perceptions of the Development and Use of Home-care Robots for Older Adults in Japan. Int. J. Hum.-Comput. Interact. 2020, 36, 1295–1303. [Google Scholar] [CrossRef]
- Gervasi, R.; Mastrogiacomo, L.; Franceschini, F. A conceptual framework to evaluate human-robot collaboration. Int. J. Adv. Manuf. Technol. 2020, 108, 841–865. [Google Scholar] [CrossRef]
- Pretto, N.; Poiesi, F. Towards gesture-based multi-user interactions in collaborative virtual environments. In Proceedings of the 5th International Workshop LowCost 3D-Sensors, Algorithms, Applications, Hamburg, Germany, 28–29 November 2017; pp. 203–208. [Google Scholar]
- Pani, M.; Poiesi, F. Distributed data exchange with Leap Motion. In International Conference on Augmented Reality, Virtual Reality and Computer Graphics; Springer: Cham, Switzerland, 2018; pp. 655–667. [Google Scholar]
- Cao, Y.; Geddes, T.A.; Yang, J.Y.H.; Yang, P. Ensemble deep learning in bioinformatics. Nat. Mach. Intell. 2020, 2, 500–508. [Google Scholar] [CrossRef]
- Wang, G.; Ye, J.C.; De Man, B. Deep learning for tomographic image reconstruction. Nat. Mach. Intell. 2020, 2, 737–748. [Google Scholar] [CrossRef]
- Yu, K.; Tan, L.; Lin, L.; Cheng, X.; Yi, Z.; Sato, T. Deep-Learning-Empowered Breast Cancer Auxiliary Diagnosis for 5GB Remote E-Health. IEEE Wirel. Commun. 2021, 28, 54–61. [Google Scholar] [CrossRef]
- Panwar, H.; Gupta, P.; Siddiqui, M.K.; Morales-Menendez, R.; Singh, V. Application of deep learning for fast detection of COVID-19 in X-rays using nCOVnet. Chaos Solitons Fractals 2020, 138, 109944. [Google Scholar] [CrossRef]
- Ma, W.; Liu, Z.; Kudyshev, Z.A.; Boltasseva, A.; Cai, W.; Liu, Y. Deep learning for the design of photonic structures. Nat. Photonics 2021, 15, 77–90. [Google Scholar] [CrossRef]
- Wang, S.; Zha, Y.; Li, W.; Wu, Q.; Li, X.; Niu, M.; Wang, M.; Qiu, X.; Li, H.; Yu, H.; et al. A fully automatic deep learning system for COVID-19 diagnostic and prognostic analysis. Eur. Respir. J. 2020, 56, 2000775. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning–based Text Classification: A Comprehensive Review. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Calvo, I.; Tropea, P.; Viganò, M.; Scialla, M.; Cavalcante, A.B.; Grajzer, M.; Gilardone, M.; Corbo, M. Evaluation of an Automatic Speech Recognition Platform for Dysarthric Speech. Folia Phoniatr. Logop. 2021, 73, 432–441. [Google Scholar] [CrossRef]
- Tao, F.; Busso, C. End-to-End Audiovisual Speech Recognition System with Multitask Learning. IEEE Trans. Multimedia 2020, 23, 1–11. [Google Scholar] [CrossRef]
- Bhatt, S.; Jain, A.; Dev, A. Continuous Speech Recognition Technologies—A Review. In Recent Developments in Acoustics; Springer: Singapore, 2021; pp. 85–94. [Google Scholar] [CrossRef]
- Shen, C.-W.; Luong, T.-H.; Ho, J.-T.; Djailani, I. Social media marketing of IT service companies: Analysis using a concept-linking mining approach. Ind. Mark. Manag. 2019, 90, 593–604. [Google Scholar] [CrossRef]
- Shen, C.-W.; Chen, M.; Wang, C.-C. Analyzing the trend of O2O commerce by bilingual text mining on social media. Comput. Hum. Behav. 2019, 101, 474–483. [Google Scholar] [CrossRef]
- Pustejovsky, J.; Krishnaswamy, N. Embodied Human Computer Interaction. KI-Künstl. Intell. 2021, 35, 307–327. [Google Scholar] [CrossRef]
- Duan, H.; Sun, Y.; Cheng, W.; Jiang, D.; Yun, J.; Liu, Y.; Liu, Y.; Zhou, D. Gesture recognition based on multi-modal feature weight. Concurr. Comput. Pract. Exp. 2021, 33, e5991. [Google Scholar] [CrossRef]
- Wang, P.; Liu, H.; Wang, L.; Gao, R.X. Deep learning-based human motion recognition for predictive context-aware human-robot collaboration. CIRP Ann. 2018, 67, 17–20. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, L.; Dai, T.; Wang, Y. Deep memory network with Bi-LSTM for personalized context-aware citation recommendation. Neurocomputing 2020, 410, 103–113. [Google Scholar] [CrossRef]
- Wang, R.; Wu, Z.; Lou, J.; Jiang, Y. Attention-based dynamic user modeling and Deep Collaborative filtering recommendation. Expert Syst. Appl. 2022, 188, 116036. [Google Scholar] [CrossRef]
- Gurcan, F.; Cagiltay, N.E.; Cagiltay, K. Mapping Human–Computer Interaction Research Themes and Trends from Its Existence to Today: A Topic Modeling-Based Review of past 60 Years. Int. J. Hum.-Comput. Interact. 2021, 37, 267–280. [Google Scholar] [CrossRef]
- Chhikara, P.; Singh, P.; Tekchandani, R.; Kumar, N.; Guizani, M. Federated Learning Meets Human Emotions: A Decentralized Framework for Human–Computer Interaction for IoT Applications. IEEE Internet Things J. 2020, 8, 6949–6962. [Google Scholar] [CrossRef]
- Ren, F.; Bao, Y. A review on human-computer interaction and intelligent robots. Int. J. Inf. Technol. Decis. Mak. 2020, 19, 5–47. [Google Scholar] [CrossRef] [Green Version]
- Miao, H.; Cheng, G.; Zhang, P.; Yan, Y. Online Hybrid CTC/Attention End-to-End Automatic Speech Recognition Architecture. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1452–1465. [Google Scholar] [CrossRef]
- Liao, Y.-F.; Chang, Y.-H.S.; Lin, Y.-C.; Hsu, W.-H.; Pleva, M.; Juhar, J. Formosa Speech in the Wild Corpus for Improving Taiwanese Mandarin Speech-Enabled Human-Computer Interaction. J. Signal Process. Syst. 2020, 92, 853–873. [Google Scholar] [CrossRef]
- Ho, N.-H.; Yang, H.-J.; Kim, S.-H.; Lee, G. Multimodal Approach of Speech Emotion Recognition Using Multi-Level Multi-Head Fusion Attention-Based Recurrent Neural Network. IEEE Access 2020, 8, 61672–61686. [Google Scholar] [CrossRef]
- Hazer-Rau, D.; Meudt, S.; Daucher, A.; Spohrs, J.; Hoffmann, H.; Schwenker, F.; Traue, H.C. The uulmMAC Database—A Multimodal Affective Corpus for Affective Computing in Human-Computer Interaction. Sensors 2020, 20, 2308. [Google Scholar] [CrossRef] [Green Version]
- Dokuz, Y.; Tufekci, Z. Mini-batch sample selection strategies for deep learning based speech recognition. Appl. Acoust. 2021, 171, 107573. [Google Scholar] [CrossRef]
- Sun, X.; Yang, Q.; Liu, S.; Yuan, X. Improving Low-Resource Speech Recognition Based on Improved NN-HMM Structures. IEEE Access 2020, 8, 73005–73014. [Google Scholar] [CrossRef]
- Kumar, M.; Kim, S.H.; Lord, C.; Lyon, T.D.; Narayanan, S. Leveraging Linguistic Context in Dyadic Interactions to Improve Automatic Speech Recognition for Children. Comput. Speech Lang. 2020, 63, 101101. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhong, J.; Kamruzzaman, M. Complicated robot activity recognition by quality-aware deep reinforcement learning. Futur. Gener. Comput. Syst. 2021, 117, 480–485. [Google Scholar] [CrossRef]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand Gesture Recognition Based on Computer Vision: A Review of Techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef]
- Pareek, P.; Thakkar, A. A survey on video-based Human Action Recognition: Recent updates, datasets, challenges, and applications. Artif. Intell. Rev. 2021, 54, 2259–2322. [Google Scholar] [CrossRef]
- Munea, T.L.; Jembre, Y.Z.; Weldegebriel, H.T.; Chen, L.; Huang, C.; Yang, C. The Progress of Human Pose Estimation: A Survey and Taxonomy of Models Applied in 2D Human Pose Estimation. IEEE Access 2020, 8, 133330–133348. [Google Scholar] [CrossRef]
- Tsai, T.-H.; Huang, C.-C.; Zhang, K.-L. Design of hand gesture recognition system for human-computer interaction. Multimedia Tools Appl. 2020, 79, 5989–6007. [Google Scholar] [CrossRef]
- Yang, H.; Gu, Y.; Zhu, J.; Hu, K.; Zhang, X. PGCN-TCA: Pseudo Graph Convolutional Network With Temporal and Channel-Wise Attention for Skeleton-Based Action Recognition. IEEE Access 2020, 8, 10040–10047. [Google Scholar] [CrossRef]
- Sun, Y.; Weng, Y.; Luo, B.; Li, G.; Tao, B.; Jiang, D.; Chen, D. Gesture recognition algorithm based on multi-scale feature fusion in RGB-D images. IET Image Process. 2020, 14, 3662–3668. [Google Scholar] [CrossRef]
- Li, J.; Xie, X.; Pan, Q.; Cao, Y.; Zhao, Z.; Shi, G. SGM-Net: Skeleton-guided multimodal network for action recognition. Pattern Recognit. 2020, 104, 107356. [Google Scholar] [CrossRef]
- Afza, F.; Khan, M.A.; Sharif, M.; Kadry, S.; Manogaran, G.; Saba, T.; Ashraf, I.; Damaševičius, R. A framework of human action recognition using length control features fusion and weighted entropy-variances based feature selection. Image Vis. Comput. 2021, 106, 104090. [Google Scholar] [CrossRef]
- Chen, Y.; Ma, G.; Yuan, C.; Li, B.; Zhang, H.; Wang, F.; Hu, W. Graph convolutional network with structure pooling and joint-wise channel attention for action recognition. Pattern Recognit. 2020, 103, 107321. [Google Scholar] [CrossRef]
- Zhu, A.; Wu, Q.; Cui, R.; Wang, T.; Hang, W.; Hua, G.; Snoussi, H. Exploring a rich spatial–temporal dependent relational model for skeleton-based action recognition by bidirectional LSTM-CNN. Neurocomputing 2020, 414, 90–100. [Google Scholar] [CrossRef]
- Yang, H.; Yuan, C.; Zhang, L.; Sun, Y.; Hu, W.; Maybank, S.J. STA-CNN: Convolutional Spatial-Temporal Attention Learning for Action Recognition. IEEE Trans. Image Process. 2020, 29, 5783–5793. [Google Scholar] [CrossRef] [PubMed]
- Jegham, I.; Ben Khalifa, A.; Alouani, I.; Mahjoub, M.A. Vision-based human action recognition: An overview and real world challenges. Forensic Sci. Int. Digit. Investig. 2020, 32, 200901. [Google Scholar] [CrossRef]
- Qiao, H.; Liu, S.; Xu, Q.; Liu, S.; Yang, W. Two-Stream Convolutional Neural Network for Video Action Recognition. KSII Trans. Internet Inf. Syst. 2021, 15, 3668–3684. [Google Scholar]
- Vishwakarma, D.K. A two-fold transformation model for human action recognition using decisive pose. Cogn. Syst. Res. 2020, 61, 1–13. [Google Scholar] [CrossRef]
- Tran, D.-S.; Ho, N.-H.; Yang, H.-J.; Baek, E.-T.; Kim, S.-H.; Lee, G. Real-Time Hand Gesture Spotting and Recognition Using RGB-D Camera and 3D Convolutional Neural Network. Appl. Sci. 2020, 10, 722. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Yu, C.; Tu, C.; Lyu, Z.; Tang, J.; Ou, S.; Fu, Y.; Xue, Z. A Survey on Hand Pose Estimation with Wearable Sensors and Computer-Vision-Based Methods. Sensors 2020, 20, 1074. [Google Scholar] [CrossRef] [Green Version]
- Ozcan, T.; Basturk, A. Human action recognition with deep learning and structural optimization using a hybrid heuristic algorithm. Clust. Comput. 2020, 23, 2847–2860. [Google Scholar] [CrossRef]
- Khan, M.A.; Sharif, M.; Akram, T.; Raza, M.; Saba, T.; Rehman, A. Hand-crafted and deep convolutional neural network features fusion and selection strategy: An application to intelligent human action recognition. Appl. Soft Comput. 2020, 87, 105986. [Google Scholar] [CrossRef]
- Seinfeld, S.; Feuchtner, T.; Maselli, A.; Müller, J. User Representations in Human-Computer Interaction. Hum.-Comput. Interact. 2021, 36, 400–438. [Google Scholar] [CrossRef] [Green Version]
- Aly, S.; Aly, W. DeepArSLR: A Novel Signer-Independent Deep Learning Framework for Isolated Arabic Sign Language Gestures Recognition. IEEE Access 2020, 8, 83199–83212. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep Learning Models for Real-time Human Activity Recognition with Smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Maulud, D.H.; Zeebaree, S.R.; Jacksi, K.; Sadeeq, M.A.M.; Sharif, K.H. State of art for semantic analysis of natural language processing. Qubahan Acad. J. 2021, 1, 21–28. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, F.R.; Keith, P.K. Exploring the potential of natural language processing to support microgenetic analysis of collaborative learning discussions. Br. J. Educ. Technol. 2019, 50, 3047–3063. [Google Scholar] [CrossRef]
- Narechania, A.; Srinivasan, A.; Stasko, J. NL4DV: A Toolkit for Generating Analytic Specifications for Data Visualization from Natural Language Queries. IEEE Trans. Vis. Comput. Graph. 2020, 27, 369–379. [Google Scholar] [CrossRef]
- Alexakis, G.; Panagiotakis, S.; Fragkakis, A.; Markakis, E.; Vassilakis, K. Control of Smart Home Operations Using Natural Language Processing, Voice Recognition and IoT Technologies in a Multi-Tier Architecture. Designs 2019, 3, 32. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans. Comput. Healthc. 2021, 3, 1–23. [Google Scholar] [CrossRef]
- Feder, A.; Keith, K.A.; Manzoor, E.; Pryzant, R.; Sridhar, D.; Wood-Doughty, Z.; Eisenstein, J.; Grimmer, J.; Reichart, R.; Roberts, M.E.; et al. Causal inference in natural language processing: Estimation, prediction, interpretation and beyond. Trans. Assoc. Comput. Linguist. 2022, 10, 1138–1158. [Google Scholar] [CrossRef]
- Kang, Y.; Cai, Z.; Tan, C.-W.; Huang, Q.; Liu, H. Natural language processing (NLP) in management research: A literature review. J. Manag. Anal. 2020, 7, 139–172. [Google Scholar] [CrossRef]
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial attacks on deep-learning models in natural language processing: A survey. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Z.; Deng, Y.; Li, X.; Naumann, T.; Luo, Y. Natural language processing for EHR-based computational phenotyping. IEEE/ACM Trans. Comput. Biol. Bioinform. 2018, 16, 139–153. [Google Scholar] [CrossRef]
- Yunanto, A.A.; Herumurti, D.; Rochimah, S.; Kuswardayan, I. English Education Game using Non-Player Character Based on Natural Language Processing. Procedia Comput. Sci. 2019, 161, 502–508. [Google Scholar] [CrossRef]
- Pramanick, P.; Sarkar, C.; Banerjee, S.; Bhowmick, B. Talk-to-Resolve: Combining scene understanding and spatial dialogue to resolve granular task ambiguity for a collocated robot. Robot. Auton. Syst. 2022, 155, 104183. [Google Scholar] [CrossRef]
- El-Komy, A.; Shahin, O.R.; Abd El-Aziz, R.M.; Taloba, A.I. Integration of computer vision and natural language processing in multimedia robotics application. Inf. Sci. Lett. 2022, 11, 9. [Google Scholar]
- Recupero, D.R.; Spiga, F. Knowledge acquisition from parsing natural language expressions for humanoid robot action commands. Inf. Process. Manag. 2020, 57, 102094. [Google Scholar] [CrossRef]
- Nistor, A.; Zadobrischi, E. The Influence of Fake News on Social Media: Analysis and Verification of Web Content during the COVID-19 Pandemic by Advanced Machine Learning Methods and Natural Language Processing. Sustainability 2022, 14, 10466. [Google Scholar] [CrossRef]
- Wang, D.; Su, J.; Yu, H. Feature Extraction and Analysis of Natural Language Processing for Deep Learning English Language. IEEE Access 2020, 8, 46335–46345. [Google Scholar] [CrossRef]
- Sun, B.; Li, K. Neural Dialogue Generation Methods in Open Domain: A Survey. Nat. Lang. Process. Res. 2021, 1, 56. [Google Scholar] [CrossRef]
- Li, Y.; Ishi, C.T.; Inoue, K.; Nakamura, S.; Kawahara, T. Expressing reactive emotion based on multimodal emotion recognition for natural conversation in human–robot interaction. Adv. Robot. 2019, 33, 1030–1041. [Google Scholar] [CrossRef]
- Jia, K. Chinese sentiment classification based on Word2vec and vector arithmetic in human–robot conversation. Comput. Electr. Eng. 2021, 95, 107423. [Google Scholar] [CrossRef]
- Korpusik, M.; Glass, J. Deep Learning for Database Mapping and Asking Clarification Questions in Dialogue Systems. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1321–1334. [Google Scholar] [CrossRef]
- Chang, Y.-C.; Hsing, Y.-C. Emotion-infused deep neural network for emotionally resonant conversation. Appl. Soft Comput. 2021, 113, 107861. [Google Scholar] [CrossRef]
- Marge, M.; Rudnicky, A.I. Miscommunication Detection and Recovery in Situated Human–Robot Dialogue. ACM Trans. Interact. Intell. Syst. 2019, 9, 1–40. [Google Scholar] [CrossRef]
- Permatasari, D.A.; Maharani, D.A. Combination of Natural Language Understanding and Reinforcement Learning for Booking Bot. J. Electr. Electron. Inf. Commun. Technol. 2021, 3, 12–17. [Google Scholar] [CrossRef]
- Ghiță, A.; Gavril, A.F.; Nan, M.; Hoteit, B.; Awada, I.A.; Sorici, A.; Mocanu, I.G.; Florea, A.M. The AMIRO Social Robotics Framework: Deployment and Evaluation on the Pepper Robot. Sensors 2020, 20, 7271. [Google Scholar] [CrossRef]
- Rofi’ah, B.; Fakhrurroja, H.; Machbub, C. Dialogue management using reinforcement learning. TELKOMNIKA Telecommun. Comput. Electron. Control 2021, 19, 931–938. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
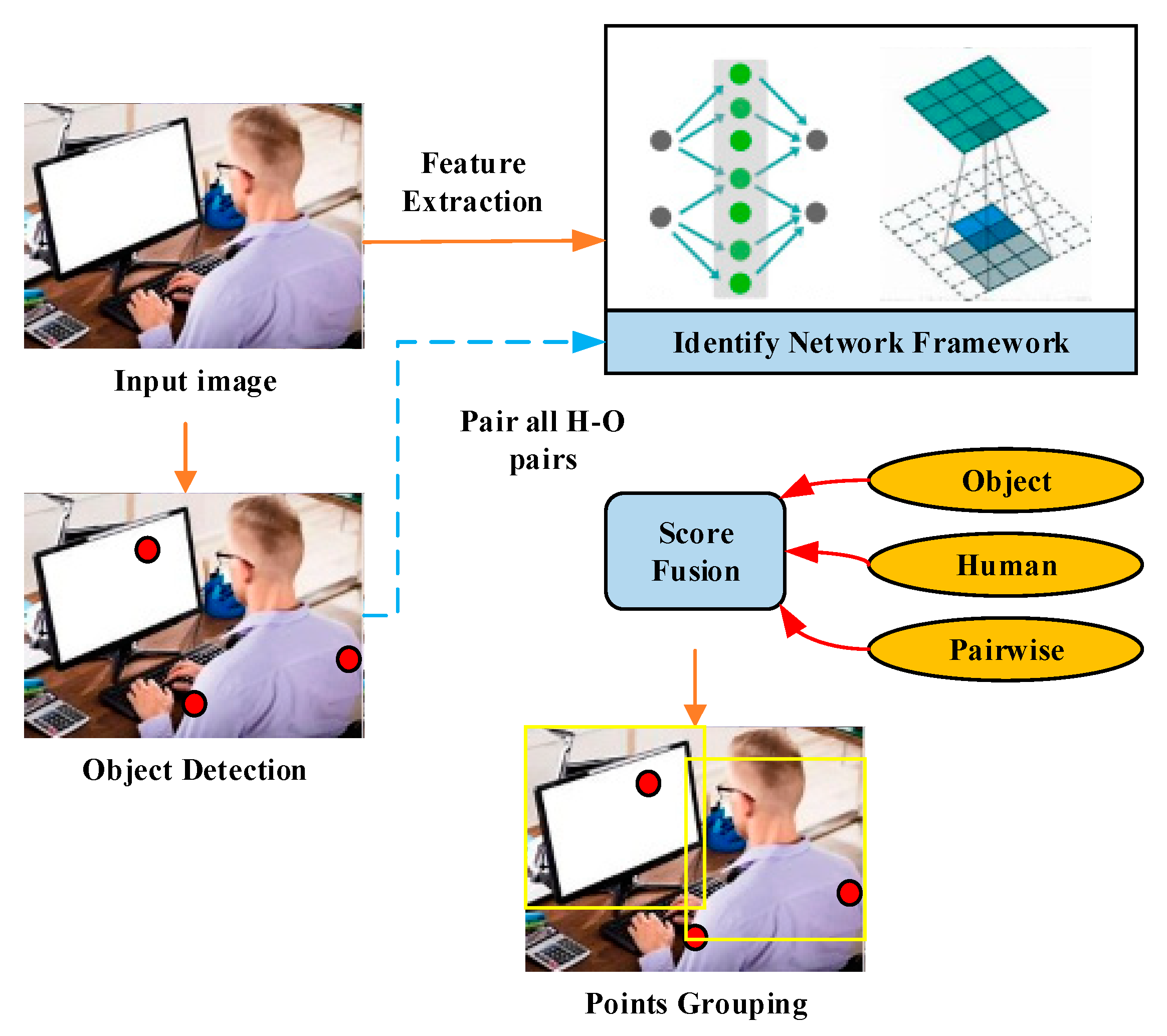{kind=link}
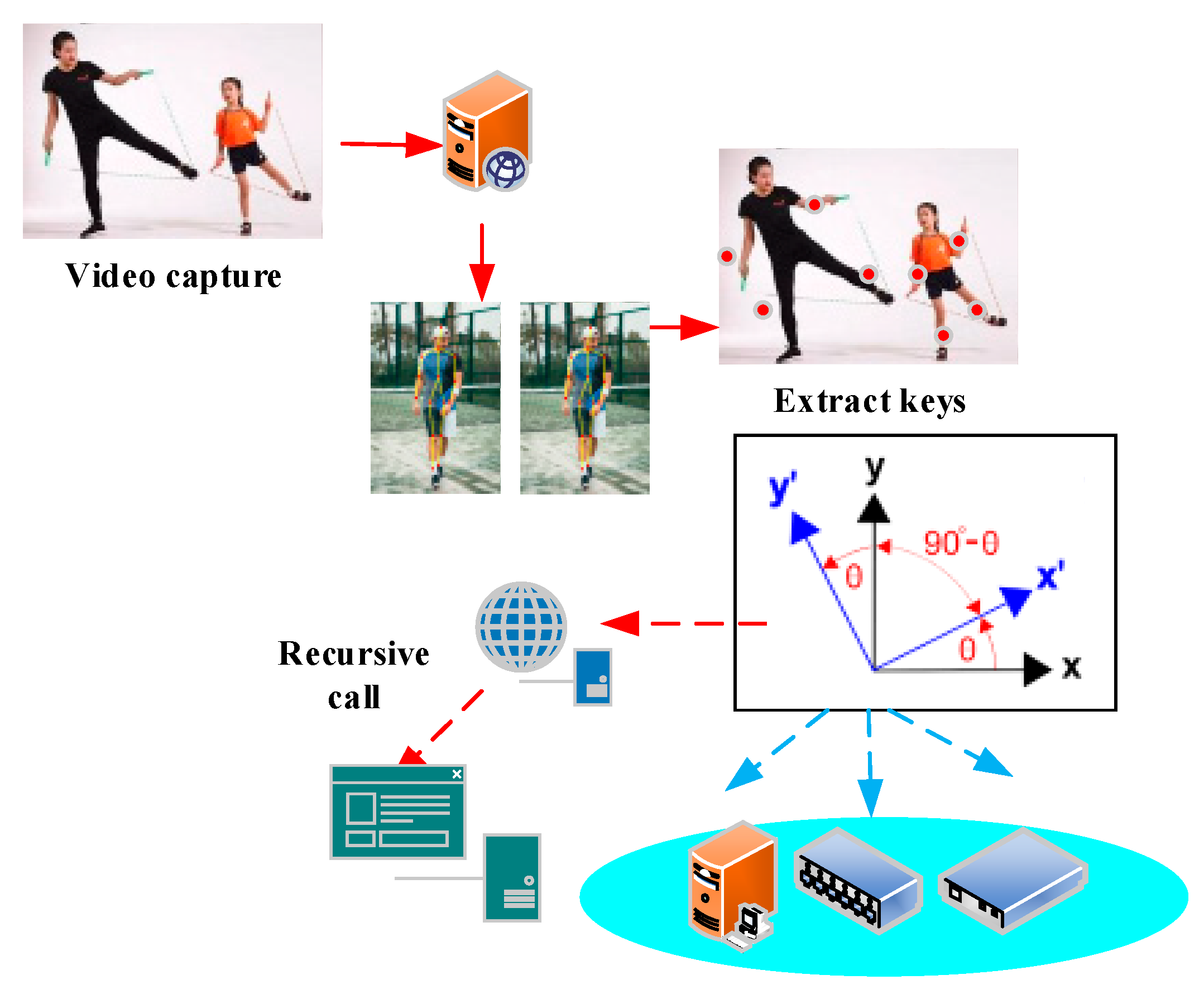{kind=link}
| Author and Year | Research Scope | The Research Methods | Results | Analysis |
|---|---|---|---|---|
| Miao et al. (2020) | Speech recognition | Online hybrid CTC/Attention end-to-end ASR architecture. | Compared with the offline CTC/attention model, the online CTC/attention model proposed in this study improves the real-time factors of HCI services and maintains a moderate degradation of its performance. | It takes advantage of the advantages of CTC and attention, which is a significant advance for end-to-end speech automation architecture. |
| Liao et al. (2020) | Voice HCI | Collect a large-scale Taiwan Province Putonghua pronunciation and corpus. | The evaluation results showed that the Taiwan-specific Mandarin speech recognition system achieved a Chinese character error rate of 8.1 percent. | We think that the specific Mandarin speech recognition system in Taiwan Province is necessary to improve the performance of man–machine interaction of Putonghua speech in Taiwan Province. |
| Ho et al. (2020) | Speech emotion recognition | Multilevel multi-head fusion attention mechanism and recurrent neural network. | Experimental results on three databases show that the multimodal speech emotion recognition method has better performance than using a single model. | Recognizing human emotions from speech requires characteristic audio and text features before the data can be fed into appropriate deep-learning algorithms. |
| Hazer-Rau et al. (2020) | Affective computing in speech interaction | uulmMAC database | The uulmMAC database has made a valuable contribution to the field of effective computing and multimodal data analysis. | Affective computing datasets including classification, feature analysis, multimodal fusion, or intertemporal survey can improve the efficiency of affective computing. |
| Dokuz and Tufekci (2021) | Speech recognition system | Mini-batch gradient descent | Compared with the standard small-batch sample selection strategy, the proposed strategy performs better. | The deep learning system makes the speech recognition system better adapt to the new language by training algorithms. |
| Sun et al. (2020) | Speech recognition | Hybrid Hidden Markov Models-phoneme-level neural networks | It applies to all widely used network structures today. The average relative character error rate is reduced by 8.0%. | Acoustic model performance can be improved without the use of data augmentation or transfer learning methods. |
| Kumar et al. (2020) | Speech recognition for children | Lexical repetition and semantic response generation | The context adaptation model results in a significant improvement over the baseline. | It is applicable to improve the performance of children’s speech recognition by using information transmission from adult interlocutors. |
| Author and Year | Research Scope | The Interaction Technology Adopted | Results | Summary and Analysis |
|---|---|---|---|---|
| Pareek and Thakkar (2020) | Human behavior recognition | Public datasets and Deep learning | Action recognition technology and applications of human behavior recognition are reviewed. | Content-based video HCI, education, healthcare, and abnormal activity detection can achieve better results on the basis of effective datasets. |
| Tsai et al. (2020) | Gesture recognition | Multiple visual techniques and connected component labeling algorithm | A low-cost HCI system with gesture recognition function is established, and the recognition rate is very high. | To perform gesture interpretation quickly and with high accuracy, a reliable labeling algorithm is needed. |
| Yang et al. (2020) | Human action recognition | Graph Convolutional network and Human skeleton modeling | Performance comparable to state-of-the-art methods is achieved on NTU-RGB+D and HDM05 datasets. | Graph convolutional neural networks can help solve the dependence relationship between unconnected distant joints and improve recognition accuracy. |
| Sun et al. (2020) | Gesture recognition algorithm | Dual stream convolutional neural network and Kinect sensor | The multilevel feature fusion model of dual stream convolutional neural network is established and trained. For gesture tracking and recognition in complex backgrounds, the average detection accuracy increased by 1.08% and the average accuracy increased by 3.56%. | Sensor technology, artificial intelligence, and big data technology make the HCI of video gesture recognition more natural and flexible. |
| Li et al. (2020) | Gesture recognition | Skeleton-guided multimodal network | In this way, skeleton features can guide RGB features in action recognition, to enhance the important RGB information closely related to actions. | The single-mode human behavior recognition mode of RGB or bone is integrated and complementary to describe the action, and the recognition performance can be optimized. |
| Afza et al. (2020) | Gesture recognition | Sparse activation function and feature fusion and weighted entropy-variance | The recognition rate is 97.9%, 100%, 99.3%, and 94.5% in four famous action datasets, respectively. | The action recognition technology based on feature fusion and best feature selection has high recognition rate. |
| Chen et al. (2020) | Gesture recognition | Graph convolutional network | The new graph convolution network based on structure graph pooling scheme and joint channel attention module reduces the number of parameters and computational cost. | An effective feature aggregation method is one of the keys to skeleton-based action recognition. Attention mechanisms can enhance the model’s ability to classify confusing behaviors. |
| Zhu et al. (2020) | Gesture recognition | Two-way LSTM-CNN | The new spatiotemporal model of end-to-end bidirectional low frequency modulation (BiLSTM-CNN) is effective on NTU RGB+D, SBU interaction, and UTD-MHAD datasets. | Efficient and low-cost human bone capture systems rely on the complementary performance of neural networks. |
| Yang et al. (2020) | Gesture recognition | Spatiotemporal attention convolutional neural networks | The spatiotemporal attention mechanism automatically mines discriminative temporal fragments from long, noisy videos. State-of-the-art performance was achieved on datasets UCF-101 (95.8%) and HMDB-51 (71.5%). | Convolutional neural networks alone can achieve high accuracy in object recognition of delicate images, but the improvement effect of motion recognition in video is not obvious. |
| Author and Year | Research Scope | The Interaction Technology Adopted | Results | Summary and Analysis |
|---|---|---|---|---|
| Yunanto et al. (2019) | Educational games and NPCS | Natural language processing | The average score of an educational game with this NPC is higher than 75% of users. | The presence of intelligent NPCS in educational games can increase user interest. |
| Recupero and Spiga (2020) | Human–computer dialog and Natural language processing | Natural language and speech interaction | For each action the robot can perform, a corresponding element is simulated in the ontology to understand human natural language. | Robots are being given the ability to read natural language more intelligently, a huge step forward in understanding human movement and speech. |
| Li et al. (2019) | Man–machine dialog and sentiment analysis | Multimodal sentiment analysis and Natural language processing | The user experience is improved by reducing low-level identification errors. | To achieve a truly natural human–computer conversation, it needs to combine sentiment analysis. |
| Marge and Rudnicky (2019) | Speech recognition and HCI | TeamTalk and Nearest neighbor algorithm | A recovery strategy is selected for virtual robots that encounter unexplained instructions | Information from the robot’s path planner and its surroundings can help the robot detect and recover from miscommunication in a conversation. |
| Jia (2021) | The man–machine dialog | Emotion classification and Language processing | This strategy makes the multi-emotion and polarity classification 3% to 4% more accurate than the next best-performing baseline classifier. | It makes sense that emoticons should be considered in sentiment classification schemes. |
| Yunanto et al. (2019) | Educational games and NPCS | Natural language processing | The average score of an educational game with this NPC is higher than 75% of users. | The presence of intelligent NPCS in educational games can increase user interest. |
| Recupero and Spiga (2020) | Human–computer dialog and Natural language processing | Natural language processing and speech interaction | For each action the robot can perform, a corresponding element is simulated in the ontology to understand human natural language. | Robots are being given the ability to read natural language more intelligently, a huge step forward in understanding human movement and speech. |
| Ghiță et al. (2020) | Social robot | Natural language processing and robot operating system and voice interaction | It focuses on the quantitative evaluation of each functional module, discussing their performance and possible improvements in different settings. | Social robots can provide economic efficiency and growth in areas such as retail, entertainment, and active and assisted living. |
| Rofi’ah et al. (2021) | Dialog robot | Reinforcement learning and voice interaction | Reinforcement learning approaches that overcome the knowledge limitations of robots achieve new dialog goals for patient assistants. | The hospital’s assistive robot uses reinforcement learning to help it grow its database of knowledge conversations, making the robot more understanding. |
| Author and Year | Research Scope | Algorithm (Model) | Dataset |
|---|---|---|---|
| Hazer-Rau et al. (2020) | Emotional computing | Affective computing and multimodal data analysis methods | uulmMAC |
| Iio et al. (2020) | Social robot | The question–answer–response dialog model | A collection of conversations from the nursing home site |
| Li (2021) | Gesture recognition | HCI model of manipulator operated by manipulator | Subject site collection |
| Calvo et al. (2021) | Speech recognition and interaction | Mobile and personal voice assistant platforms | Questionnaire survey results and on-site evaluation |
| Tao and Busso (2020) | Speech recognition and interaction | Multitask learning and automatic audiovisual speech recognition systems | An audio–visual corpus |
| Duan et al. (2021) | Gesture recognition | Weight adaptive algorithm combining different features | Gesture image dataset |
| Wang et al. (2020) | Context awareness | Context-aware citation recommendation model based on end-to-end memory network | Three real datasets |
| Miao et al. (2020) | Speech recognition | Online hybrid based on connectionist temporal classification/attention end-to-end automatic speech recognition architecture | LibriSpeech |
| Ho et al. (2020) | Speech emotion recognition | Multimodal speech emotion recognition method based on multilevel multi-head fusion attention mechanism and recurrent neural network | CMU-MOSEI, IEMOCA and MELD |
| Chen et al. (2020) | Motion recognition | A novel graph convolution network based on structure graph pooling scheme and joint channel attention module | NTU-RGB+D, Kinetics-M, and SYSU-3D |
| Zhu et al. (2020) | Motion recognition | A new spatiotemporal model of end-to-end bidirectional Low-frequency modulation (BiLSTM-CNN) | NTU RGB+D, SBU Interaction and UTD-MHAD |
| Yang et al. (2020) | Motion recognition | Spatiotemporal concern convolutional neural network model | UCF-101 (95.8%) and HMDB-51 (71.5%) |
| Aly and Aly (2020) | Gesture recognition | Hidden Markov model and Color-based hand segmentation algorithm | Hand graphics collection based on DeepLabv3 |
| Li et al. (2019) | Man–machine dialog | An algorithm that combines prosody valence with text emotion through decision-level fusion | A survey of the subject’s experience |
| Marge and Rudnicky (2019) | Man–machine dialog | Nearest neighbor learning algorithm | Crowd-sourced data and user experience data |
| Jia (2021) | Dialog robot | Word2vec and vector arithmetic and improved k-means similarity calculation | Emotional dictionary |
| Permatasari and Maharani (2021) | Robot | Support vector machine and feature extraction combination algorithm | Chatbot dialog collection |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, Z.; Poiesi, F.; Dong, Q.; Lloret, J.; Song, H. Deep Learning for Intelligent Human–Computer Interaction. Appl. Sci. 2022, 12, 11457. https://doi.org/10.3390/app122211457
Lv Z, Poiesi F, Dong Q, Lloret J, Song H. Deep Learning for Intelligent Human–Computer Interaction. Applied Sciences. 2022; 12(22):11457. https://doi.org/10.3390/app122211457
Chicago/Turabian StyleLv, Zhihan, Fabio Poiesi, Qi Dong, Jaime Lloret, and Houbing Song. 2022. "Deep Learning for Intelligent Human–Computer Interaction" Applied Sciences 12, no. 22: 11457. https://doi.org/10.3390/app122211457