
An Object Detection and Localization Method Based on Improved YOLOv5 for the Teleoperated Robot

Abstract
:1. Introduction
- (1)
- Improve the classic YOLOv5 object detection network model; the improved model can effectively increase the accuracy and detection speed of object detection.
- (2)
- Prune the YOLOv5 network model; the resulting lightweight network structure is easier to deploy on embedded devices with insufficient computing power, which is more suitable for the teleoperated robot.
- (3)
- Propose an object localization algorithm based on the improved YOLOv5 network model and the binocular stereo vision ranging principle, which achieves accurate object localization.
- (4)
- Design and establish an object-detection platform for a teleoperated robot, and create a small dataset to validate the proposed method.
2. Method
2.1. Object Detection
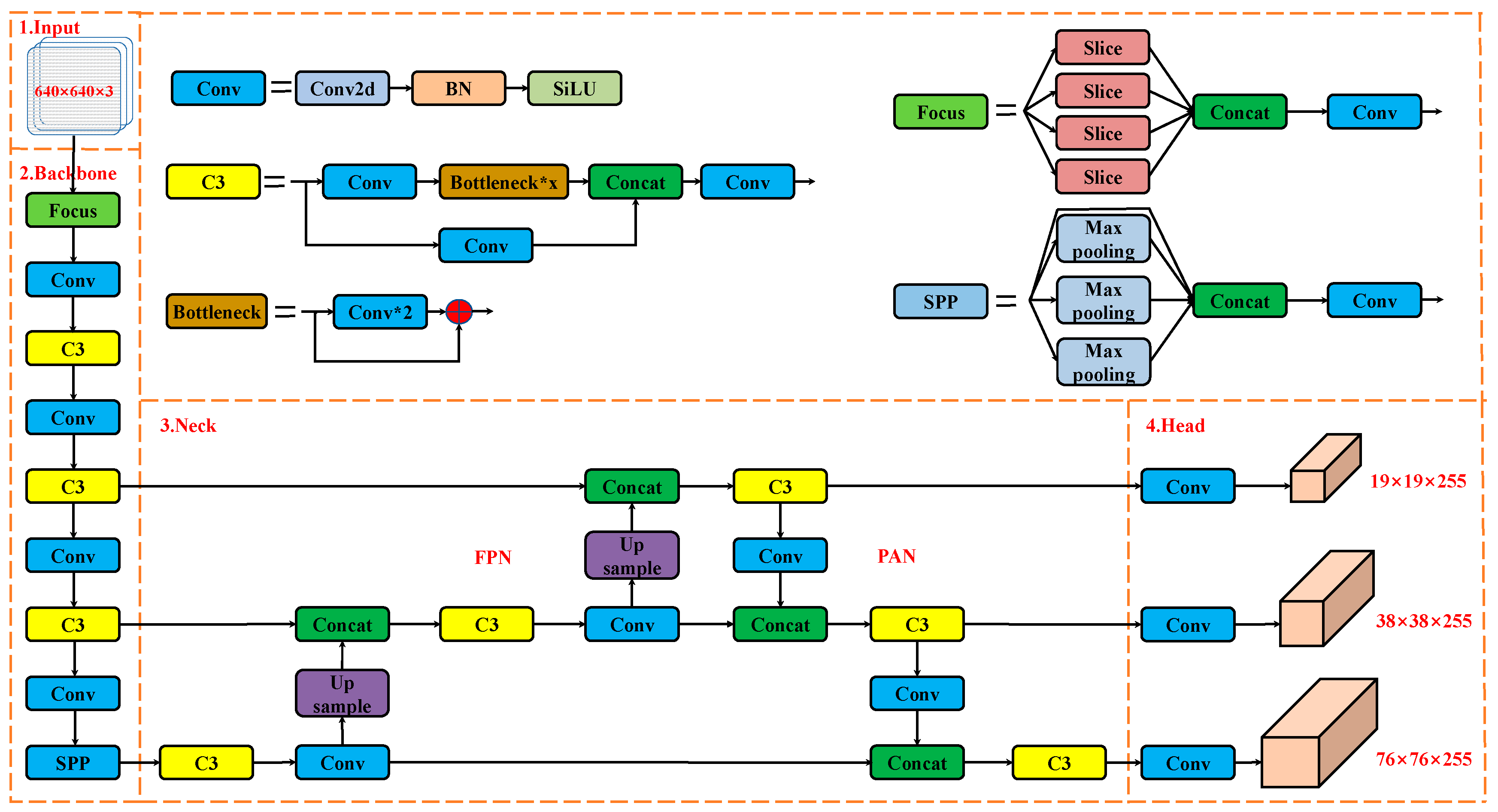
2.1.1. YOLOv5 Network Structure
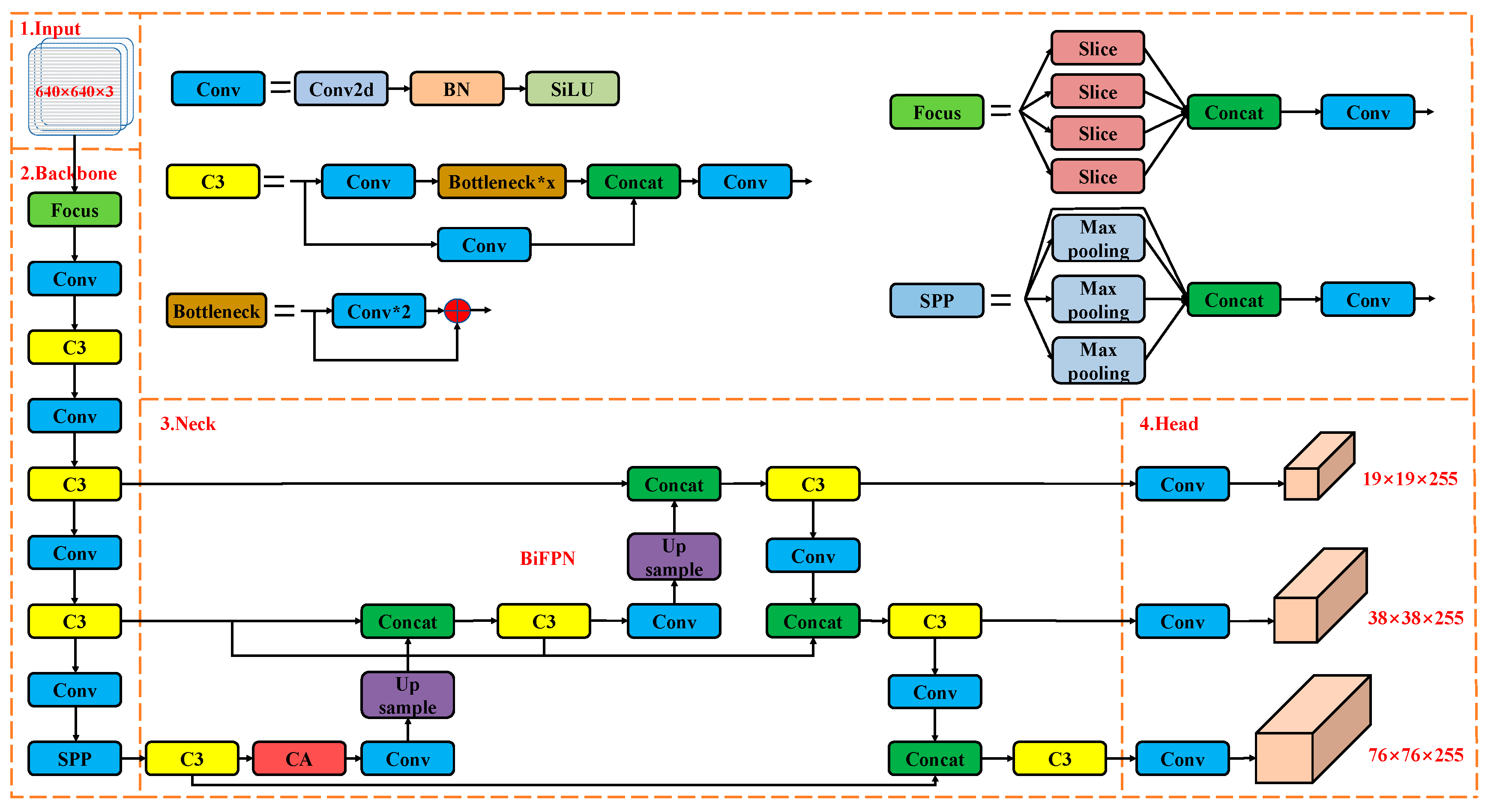
2.1.2. Improvement of YOLOv5 Network Structure
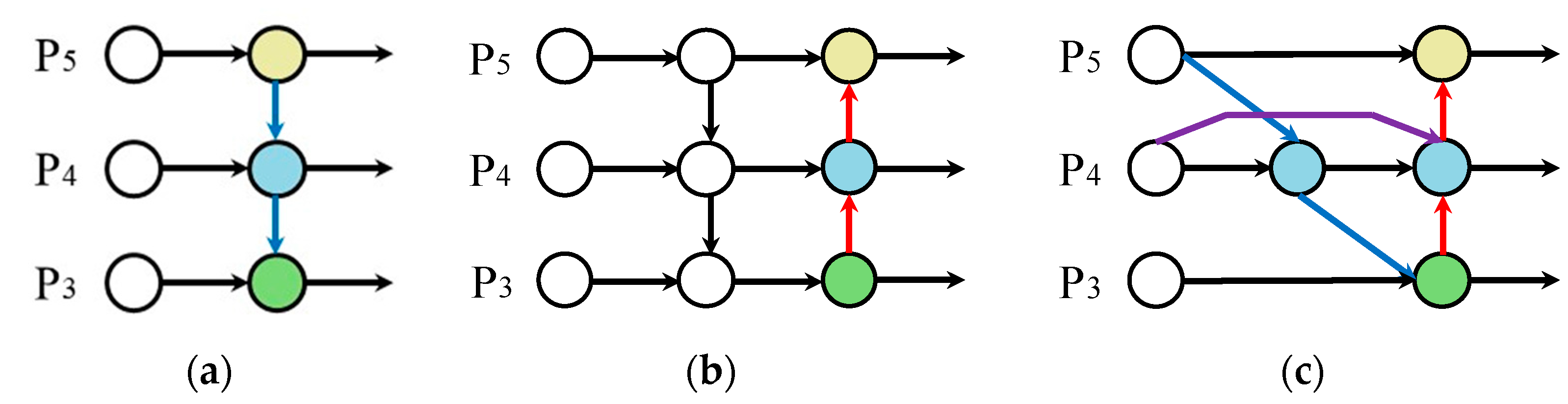
Feature Fusion Network Structure Design
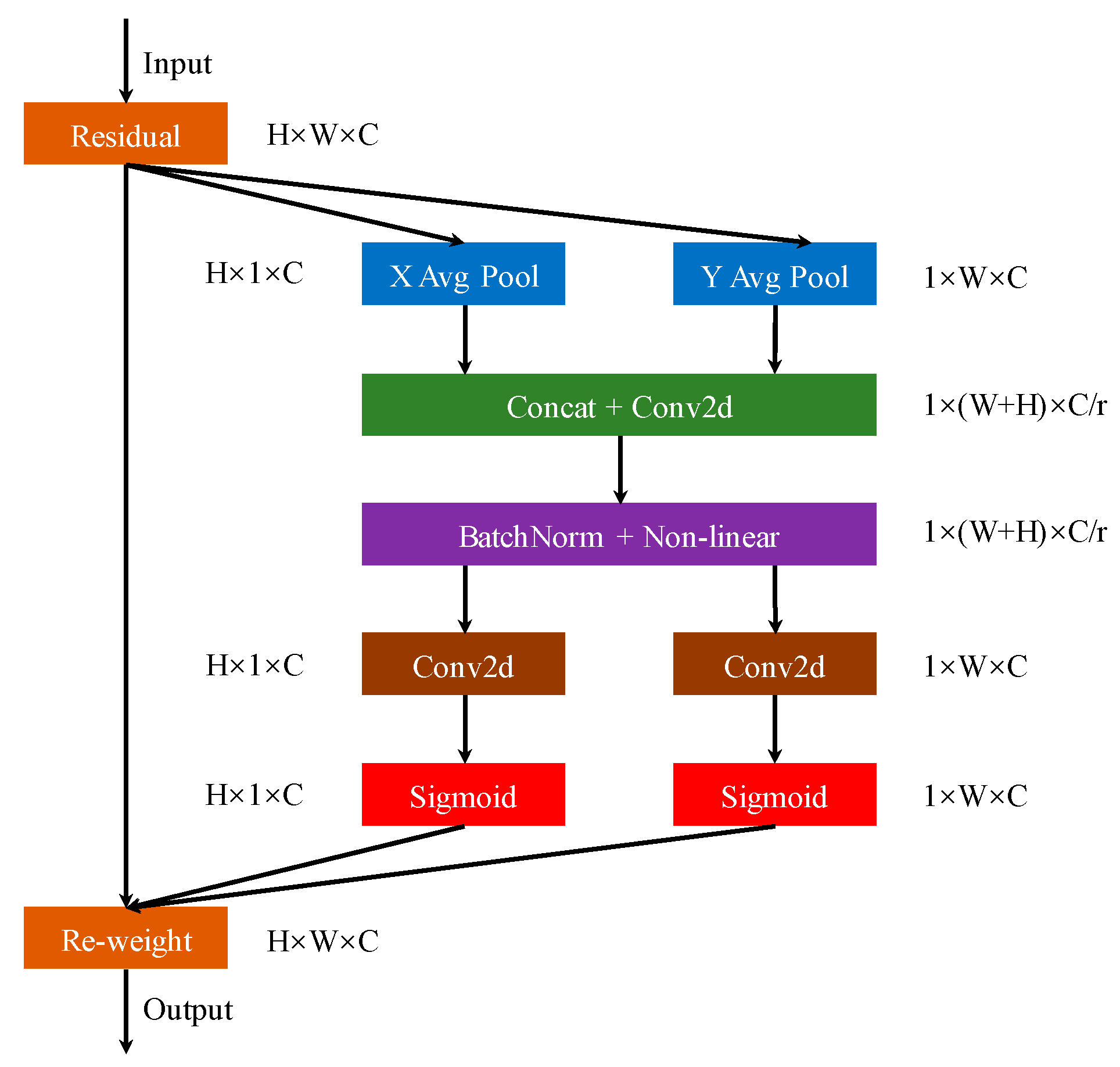
Coordinate Attention Module Design
Network Pruning
Loss Function Design
2.2. Object Localization
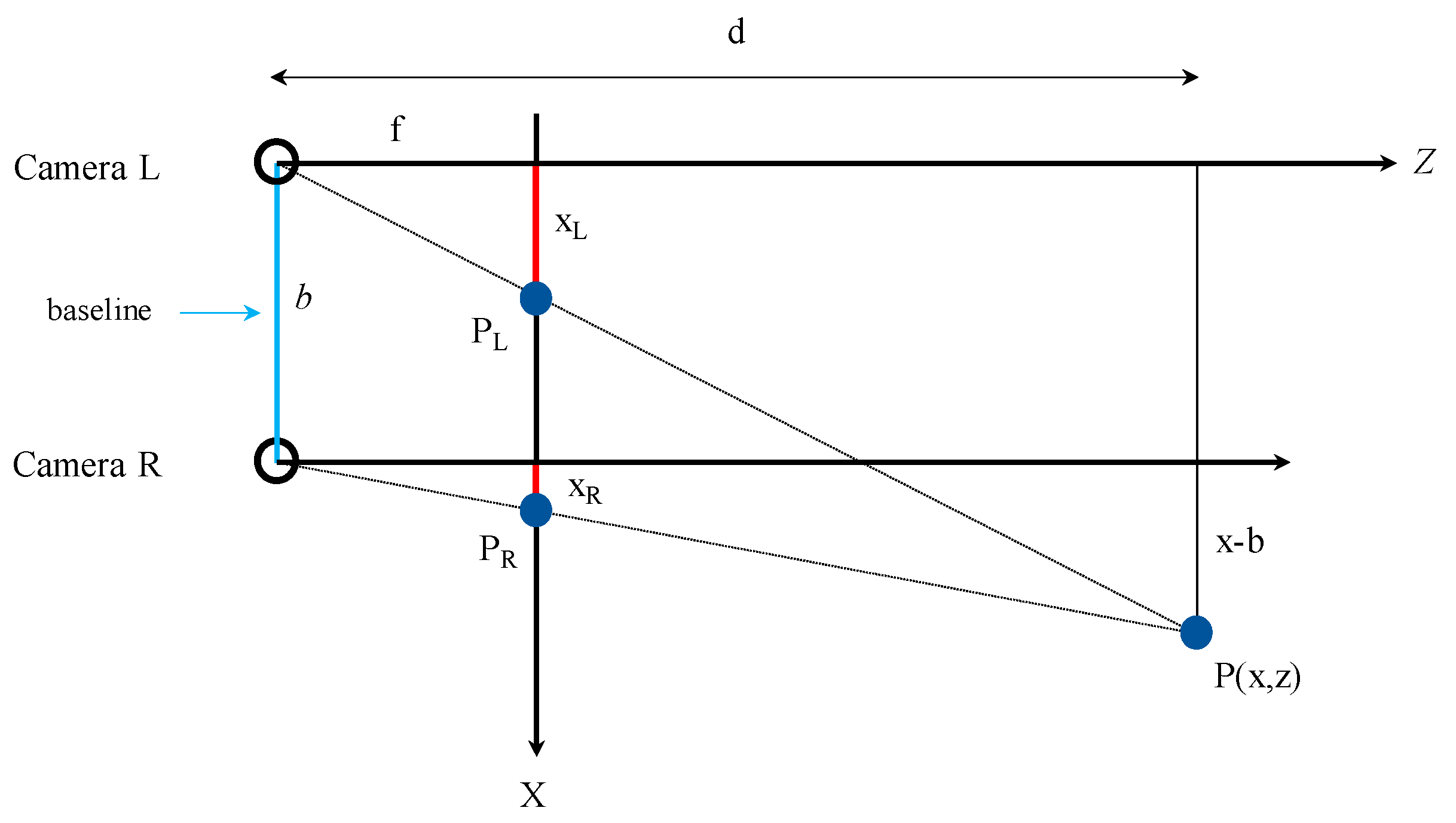
2.2.1. Binocular Ranging Principle
2.2.2. Distance Estimation
| Algorithm 1 Object Detection and Distance Estimation |
| Require: Self-trained YOLOv5 model and ZED2 depth camera |
| Ensure: Objects class and their distance from the camera’s left eye |
| 1: Initialize the depth camera(HD720p, 60FPS, depth minimum distance = 0.3 m) |
| 2: Load the self-trained YOLOv5 model |
| 3: While(true) |
| 4: Stereo image is captured for each frame (3D image) |
| 5: The image is pre-processed and resized to (640 × 640) |
| 6: Input the image into the self-trained YOLOv5 model for object detection and return (xmin, ymin, xmax, ymax) |
| 7: for each object do |
| 8: if (object == 1) then |
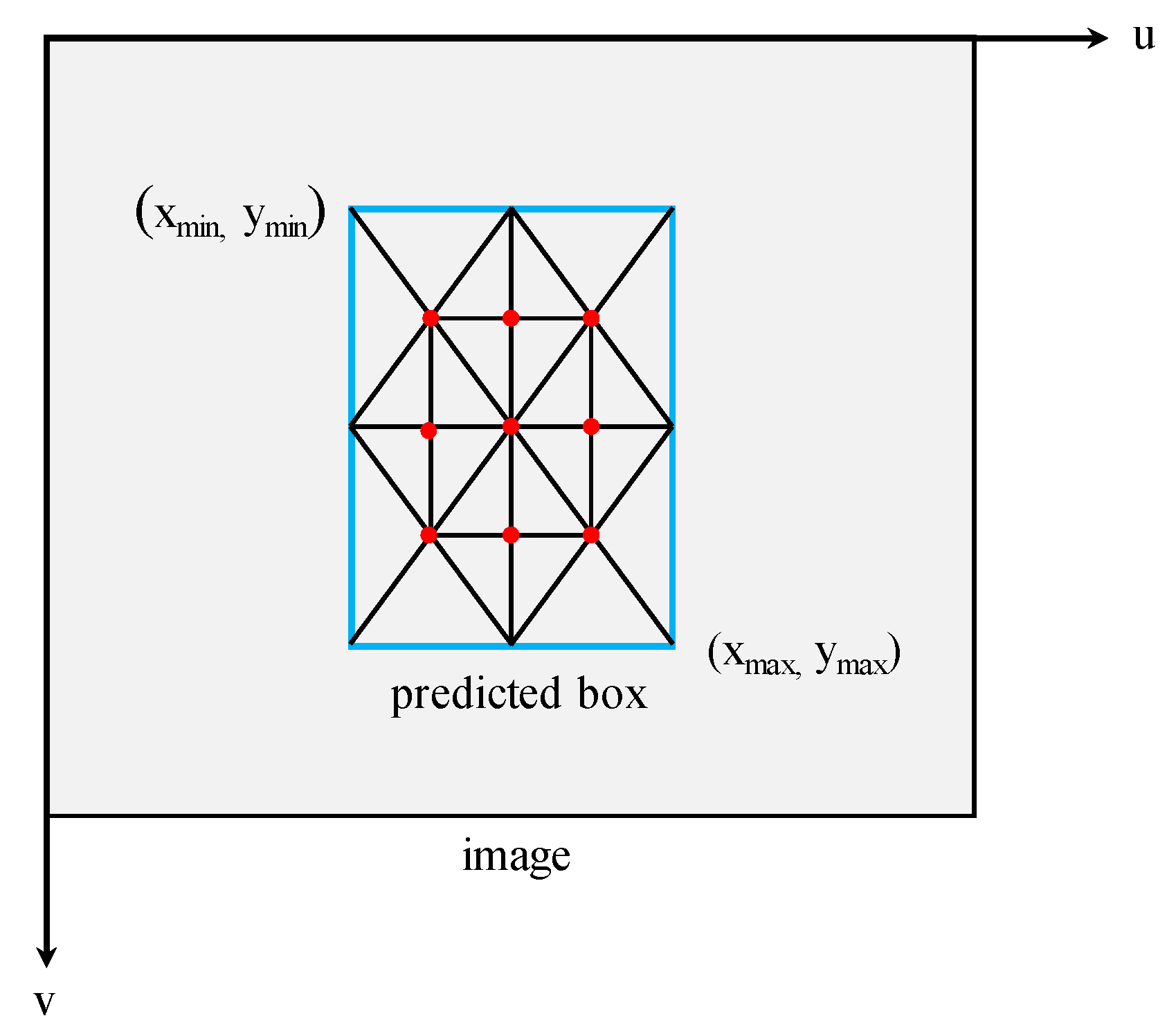
| 9: Calculate the coordinates of 9 points |
| 10: distance = 0, n = 0 |
| 11: for each pointi do |
| 12: if (pointi.isValidMeasure()) then |
| 13: |
| 14: distance = (distance ∗ n + disi)/(n + 1) |
| 15: n = n + 1 |
| 16: end if |
| 17: end for |
| 18: if (0.3 ≤ distance and distance ≤ 3) then |
| 19: Plot predicted box, class, confidence, distance labels |
| 20: end if |
| 21: end if |
| 22: end for |
3. Experimental Design
3.1. Dataset
3.2. Simulation
3.3. Distance Estimation
4. Result and Analysis
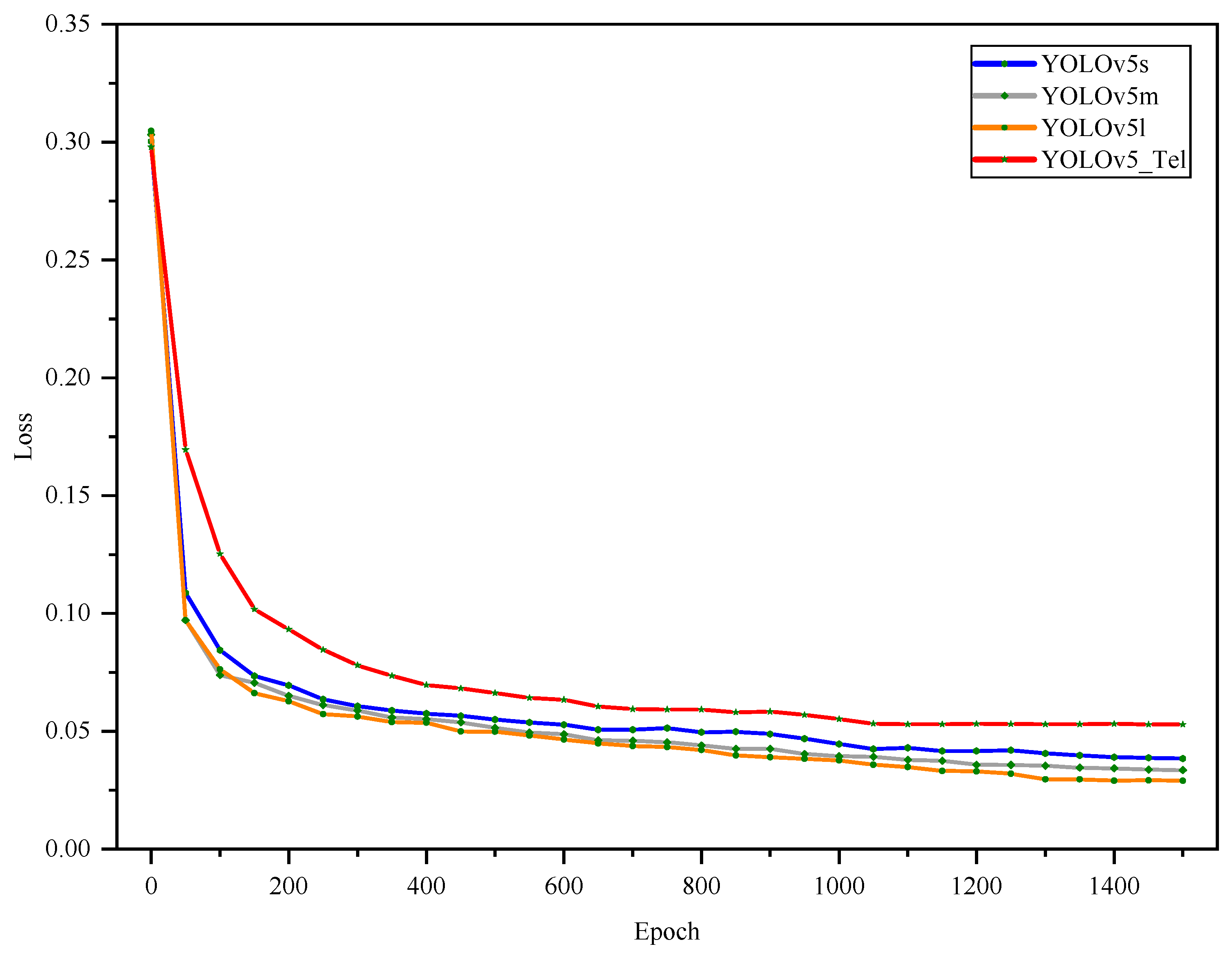
4.1. Simulation Results and Analysis
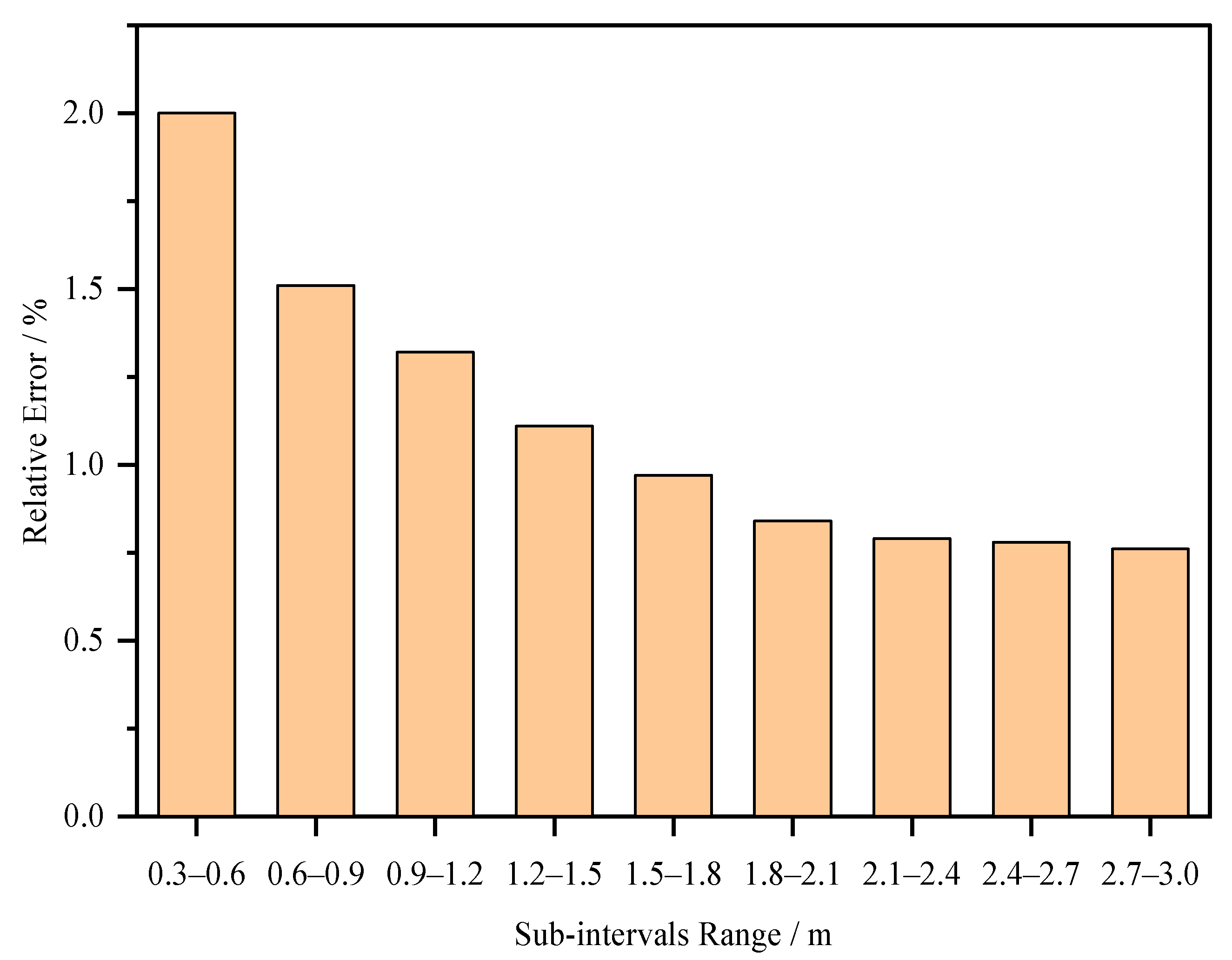
4.2. Distance Estimation Results and Analysis
5. Conclusions
- (1)
- The model simulation experiment shows that the YOLOv5_Tel model is more accurate, lighter, and faster in object detection. The YOLOv5_Tel model’s precision, recall, mAP value, and F1 score are 92.6%, 99.4%, 99.4%, and 95.9%, respectively. The YOLOv5_Tel model’s mAP value increased in comparison to the classic YOLOv5s, YOLOv5m, and YOLOv5l models by 0.8%, 0.9%, and 1.0%, respectively. The model size decreased by 11.1%, 70.0%, and 86.4%, respectively, whereas the inference time decreased by 9.1%, 42.9%, and 58.3%.
- (2)
- The distance estimation experiment shows that the object localization method has good localization accuracy and robustness, with an average relative error of distance estimation of 1.12% and a RMSE of relative error of 0.4%.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Adamides, G.; Katsanos, C.; Parmet, Y.; Christou, G.; Xenos, M.; Hadzilacos, T.; Edan, Y. HRI usability evaluation of interaction modes for a teleoperated agricultural robotic sprayer. Appl. Ergon. 2017, 62, 237–246. [Google Scholar] [CrossRef] [PubMed]
- Qian, K.; Song, A.; Bao, J.; Zhang, H. Small Teleoperated Robot for Nuclear Radiation and Chemical Leak Detection. Int. J. Adv. Robot. Syst. 2012, 9, 70. [Google Scholar] [CrossRef] [Green Version]
- Rahman, M.M.; Balakuntala, M.V.; Gonzalez, G.; Agarwal, M.; Kaur, U.; Venkatesh, V.L.N.; Sanchez-Tamayo, N.; Xue, Y.; Voyles, R.M.; Aggarwal, V.; et al. SARTRES: A semi-autonomous robot teleoperation environment for surgery. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2020, 9, 376–383. [Google Scholar] [CrossRef]
- Novák, P.; Kot, T.; Babjak, J.; Konečný, Z.; Moczulski, W.; Rodriguez López, Á. Implementation of Explosion Safety Regulations in Design of a Mobile Robot for Coal Mines. Appl. Sci. 2018, 8, 2300. [Google Scholar] [CrossRef] [Green Version]
- Koh, K.H.; Farhan, M.; Yeung, K.P.C.; Tang, D.C.H.; Lau, M.P.Y.; Cheung, P.K.; Lai, K.W.C. Teleoperated service robotic system for on-site surface rust removal and protection of high-rise exterior gas pipes. Autom. Constr. 2021, 125, 103609. [Google Scholar] [CrossRef]
- Lin, Z.; Gao, A.; Ai, X.; Gao, H.; Fu, Y.; Chen, W.; Yang, G.-Z. ARei: Augmented-Reality-Assisted Touchless Teleoperated Robot for Endoluminal Intervention. IEEE/ASME Trans. Mechatron. 2021, 27, 1–11. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Li, D.; Ji, Y.; Zhou, H.; Wu, W.; Liu, K. Toward New Retail: A Benchmark Dataset for Smart Unmanned Vending Machines. IEEE Trans. Ind. Inform. 2020, 16, 7722–7731. [Google Scholar] [CrossRef]
- Xue, J.; Zheng, Y.; Dong-Ye, C.; Wang, P.; Yasir, M. Improved YOLOv5 network method for remote sensing image-based ground objects recognition. Soft Comput. 2022, 26, 10879–10889. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Z.; Zhang, Y.; Zhou, J.; Wu, J.; Li, P. Real-Time Detection and Location of Potted Flowers Based on a ZED Camera and a YOLO V4-Tiny Deep Learning Algorithm. Horticulturae 2021, 8, 21. [Google Scholar] [CrossRef]
- Lin, S.Y.; Li, H.Y. Integrated Circuit Board Object Detection and Image Augmentation Fusion Model Based on YOLO. Front. Neurorobot. 2021, 15, 762702. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Wu, R.; Lin, Y.; Li, C.; Chen, S.; Yuan, Z.; Chen, S.; Zou, X. Plant Disease Recognition Model Based on Improved YOLOv5. Agronomy 2022, 12, 365. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.M.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.L.; Shrivastava, A.; Gupta, A. A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3039–3048. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv 2017, arXiv:1705.09587. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; NanoCode012; Chaurasia, A.; Liu, C.; Xie, T.; Abhiram, V.; Laughing; Tkianai; et al. Ultralytics/yolov5: v5.0-YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube integrations. Zenodo 2021, 2021, 4679653. [Google Scholar] [CrossRef]
- Li, X.; Tian, M.; Kong, S.; Wu, L.; Yu, J. A modified YOLOv3 detection method for vision-based water surface garbage capture robot. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420932715. [Google Scholar] [CrossRef]
- Xu, F.; Dong, P.; Wang, H.; Fu, X. Intelligent detection and autonomous capture system of seafood based on underwater robot. J. Beijing Univ. Aeronaut. Astronaut. 2019, 45, 2393–2402. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Mingxing, T.; Ruoming, P.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar] [CrossRef]
- Qibin, H.; Daquan, Z.; Jiashi, F. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; JunYoung, G.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Manjari, K.; Verma, M.; Singal, G.; Kumar, N. QAOVDetect: A Novel Syllogistic Model with Quantized and Anchor Optimized Approach to Assist Visually Impaired for Animal Detection using 3D Vision. Cogn. Comput. 2022, 14, 1269–1286. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Number of Residual Components in C3 | |||||||
|---|---|---|---|---|---|---|---|---|
| Backbone | Neck | |||||||
| First | Second | Third | First | Second | Third | Fourth | Fifth | |
| YOLOv5s | 1 | 3 | 3 | 1 | 1 | 1 | 1 | 1 |
| YOLOv5m | 2 | 6 | 6 | 2 | 2 | 2 | 2 | 2 |
| YOLOv5l | 3 | 9 | 9 | 3 | 3 | 3 | 3 | 3 |
| YOLOv5_Tel | 2 | 4 | 4 | 1 | 1 | 1 | 1 | 1 |
| Model | Number of Convolution Kernels | ||||
|---|---|---|---|---|---|
| Focus | First Conv | Second Conv | Third Conv | Fourth Conv | |
| YOLOv5s | 32 | 64 | 128 | 256 | 512 |
| YOLOv5m | 48 | 96 | 192 | 384 | 768 |
| YOLOv5l | 64 | 128 | 256 | 512 | 1024 |
| YOLOv5_Tel | 30 | 60 | 120 | 240 | 480 |
| Models | Precision (%) | Recall (%) | mAP (%) | F1 (%) | Model Size (MB) | Inference Time (ms) |
|---|---|---|---|---|---|---|
| YOLOv5s | 91.7 | 98.6 | 98.6 | 95.0 | 14.4 | 22 |
| YOLOv5m | 91.5 | 98.5 | 98.5 | 94.9 | 42.6 | 35 |
| YOLOv5l | 91.4 | 98.4 | 98.4 | 94.8 | 93.8 | 48 |
| YOLOv5_Tel | 92.6 | 99.4 | 99.4 | 95.9 | 12.8 | 20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Li, X.; Wang, L.; Shi, Y.; Sun, Z.; Sun, W. An Object Detection and Localization Method Based on Improved YOLOv5 for the Teleoperated Robot. Appl. Sci. 2022, 12, 11441. https://doi.org/10.3390/app122211441
Chen Z, Li X, Wang L, Shi Y, Sun Z, Sun W. An Object Detection and Localization Method Based on Improved YOLOv5 for the Teleoperated Robot. Applied Sciences. 2022; 12(22):11441. https://doi.org/10.3390/app122211441
Chicago/Turabian StyleChen, Zhangyi, Xiaoling Li, Long Wang, Yueyang Shi, Zhipeng Sun, and Wei Sun. 2022. "An Object Detection and Localization Method Based on Improved YOLOv5 for the Teleoperated Robot" Applied Sciences 12, no. 22: 11441. https://doi.org/10.3390/app122211441