

Enhancing Detection of Arabic Social Spam Using Data Augmentation and Machine Learning


Abstract
:1. Introduction
- Handling different categories of Arabic spam content such as advertising, spreading malware, adult content, hate speech, and meaningless content.
- Creation of a public and available Arabic spam dataset containing the original tweets and the corresponding annotations.
- Applying replacement embedding data augmentation technique for Arabic text.
- Evaluation of the overall framework by comparing its accuracy to the original (non-augmented) dataset, which leads to improvement of the overall Macro F1 up to ∼32% and recalls improvement of the spam class of up to ∼38%.
2. Background and Related Work
2.1. Data Augmentation
- Noise Induction: Randomly insert, delete, swap, and substitute words.
- Synonym Replacement: The paraphrasing transformation of text instances by replacing certain words with synonyms (WordNet) is the popular form of data augmentation.
- Embedding Replacement: Comparable to synonym replacement, embedding replacement strategies look for words that fit well into the textual context and do not change the text’s basic substance. To achieve this, close words from similar contexts are translated into a latent representation space [20]. Word embeddings can be static (word vectors), pre-trained classic word embeddings such as self-trained W2V, Glove, and Google-News W2V, to perform similarity searches. On the contrary, the other type applies contextual data augmentation, such as BERT, which replaces words with words predicted from a bidirectional language model according to the context of the original word.
- Sentiment analysis, Mohammed et al. [21] used shuffling by randomly changing the order of words inside the small size context window and Duwairi et al. [22] used a set of rules to alter or swap branches of the parse trees as per Arabic syntax to generate new sentences with the same labels, and others to insert negation particles into the sentences and, thus, generate new sentences with opposite labels.
- Named entity recognition, Sabty et al. [23] used a set of data augmentation techniques, namely: Word random insertion, swap and deletion in the sentence, sentence back-translation, and word embedding substitution.
2.2. Spam Detection Techniques
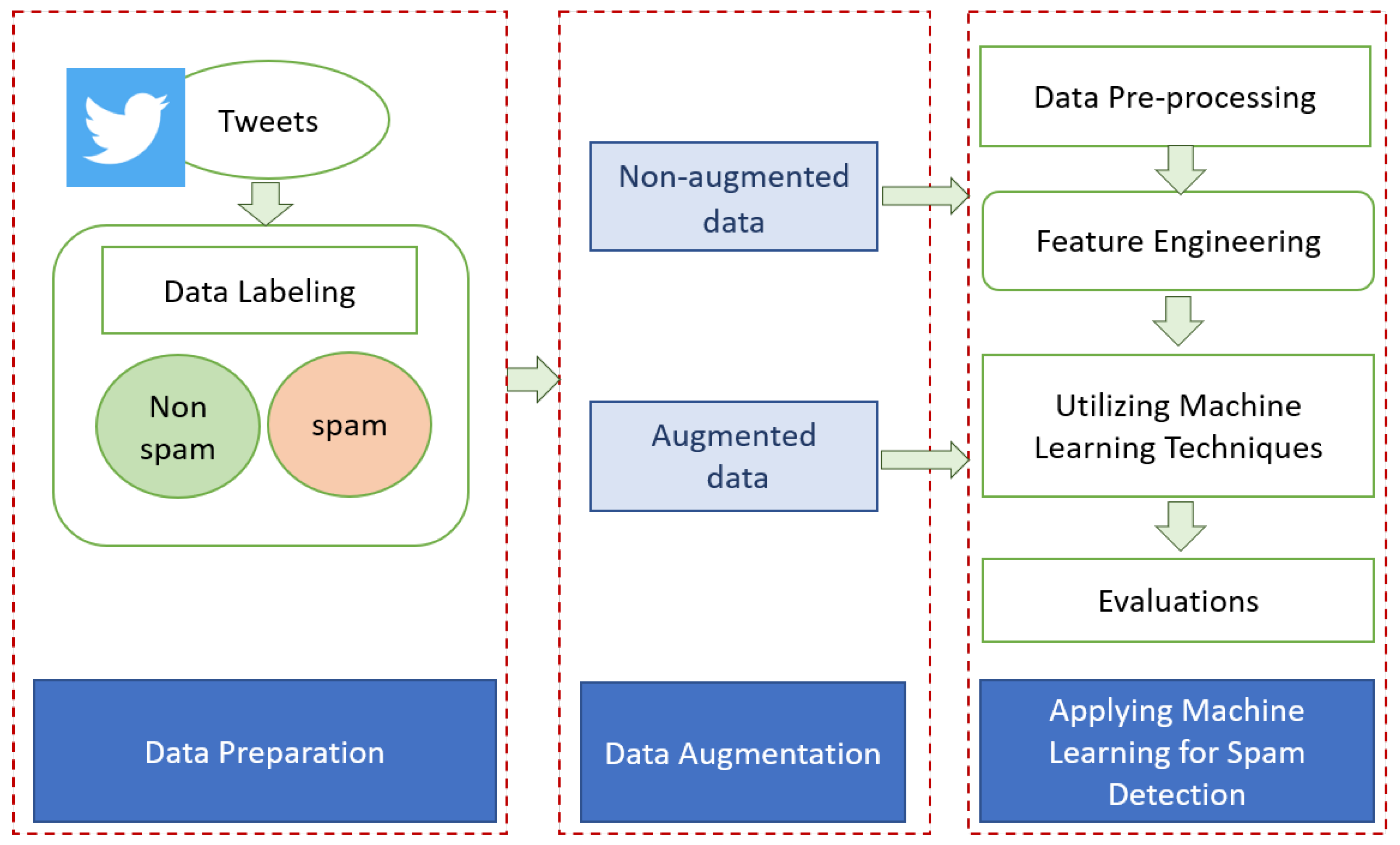
3. Proposed Framework for Enhancing Arabic Spam Detection
3.1. Data Preparation
3.1.1. Data Extraction
3.1.2. Data Labeling
- Before starting the annotation process, each annotator was given our definition of spam text as well as some examples of spam content. We asked annotators to carefully read a tweet before evaluating whether it contained spam content (spam class); or did not contain spam content (non-spam class).
- The 5 k tweets have been split into five chunks, each chunk containing 1000 tweets. After that, every three annotators have worked on the same 1000 tweets separately so that the annotation score (spam/non-spam) is calculated based on the three annotators, as illustrated in the following step
- Finally, the annotation results for the 5k tweets from the 15 annotators are grouped, such that each tweet has three annotated values, each from a different expert. We marked the tweet as spam or non-spam according to the mode (most occurring value) result. After labeling, we found that the data are imbalanced with 420 spam tweets and 4580 non-spam tweets.
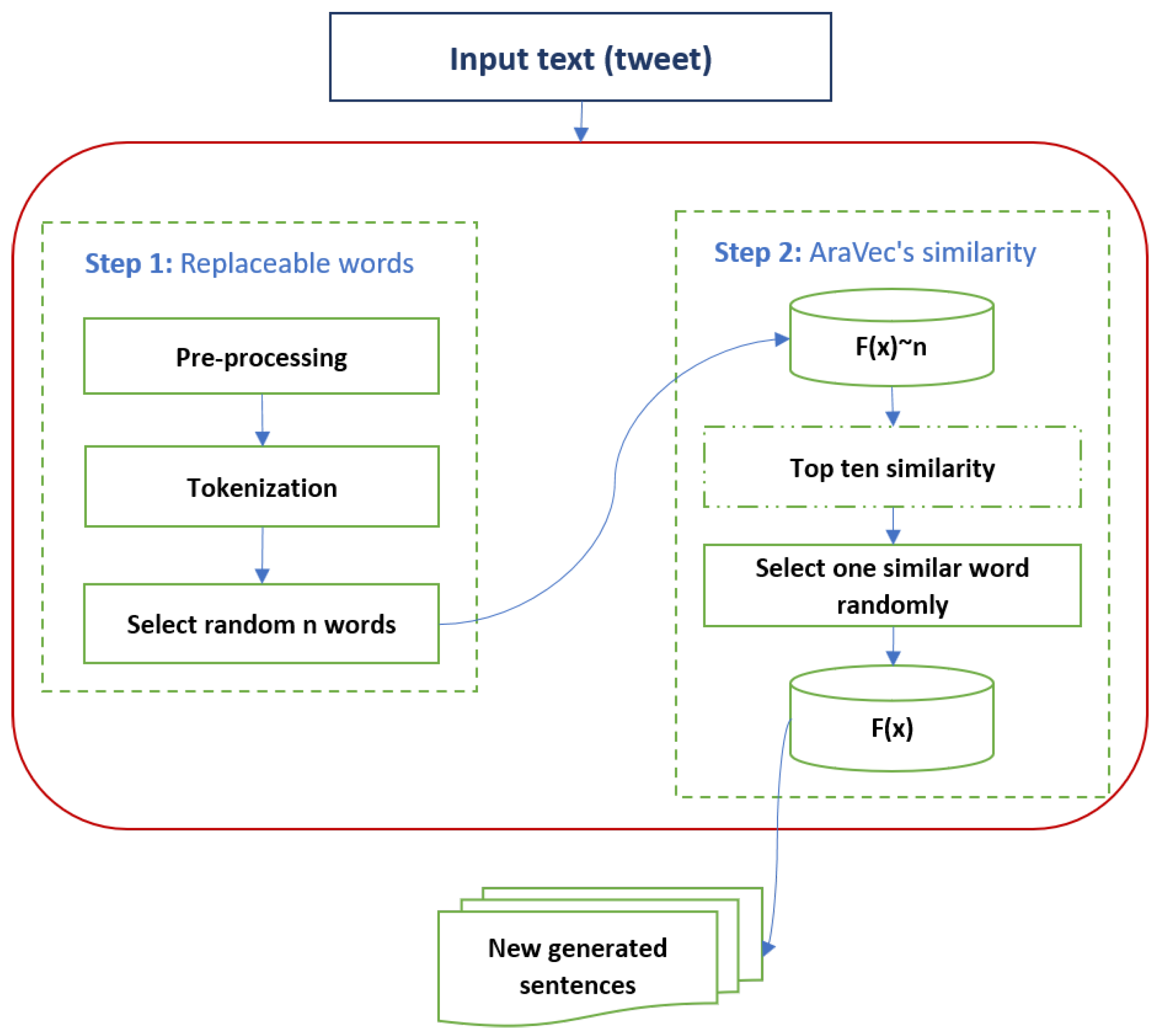
3.2. Applying Data Augmentation to Collected Data
3.3. Applying Machine Learning for Spam Detection
3.3.1. Data Pre-Processing
3.3.2. Feature Engineering
- Content Features:
- –
- TF-IDF: Some language features are used, such as Term-Frequency-based (TF-IDF), which is the most popular feature extraction method. This method typically represents each sentence as a vector of term frequencies (TF) and assigns a score for each word in the text based on the number of times its occurrence and how likely it can be found in texts. (TF-IDF) would show the relative importance of a term in a document compared to other words in the corpus.
- –
- Hashtag count and URLs count: These features can help us detect spam profiles because they tend to share a lot of spam tweets with URLs and hashtags as an advertising strategy. These values should be higher for the spammer than for the regular users [66].
- –
- Spam words: The number of spam words in tweets should be higher in spam profiles than in regular profiles. As a result, this feature is important in detecting spam tweets, and is calculated based on the spam words dictionary. This dictionary is constructed based on spam tweets in our labeled dataset, and only the most common and relevant words were selected from the resulting list, which was manually filtered [66].
- Interaction Features:
- –
- Tweets duplication count: As noticed, the spammers frequently repeat the same tweet to gain the attention of users to its content. Therefore, we believe that this feature is critical to know whether content is spam or not [66].
- –
- Retweet count: This feature can be used to distinguish between spam and non-spam tweets because spam tweets are not usually retweeted [66].
- –
- Mention count: This feature can help us detect spam profiles because they tend to share a lot of spam tweets with mentions as an advertisement strategy. These values should be greater for the spammer than for the regular users [66].
- –
- Favorite count: Spam tweets are usually not marked as favorites. This value should be higher for the regular than the spammer users [66].
- User Features:
- –
- User followers and user friends count: These features can help us detect spam profiles. If the result of the ratio between followers and friends is too small, then the probability of being a spam user will increase [66].
- –
- User description length: Number of characters in the user description. If the result is zero, then the probability of being a spam user will increase.
3.3.3. Utilizing Machine Learning Techniques
4. Experiments
4.1. Experiment 1: Non-Augmented Dataset with TF-IDF Feature
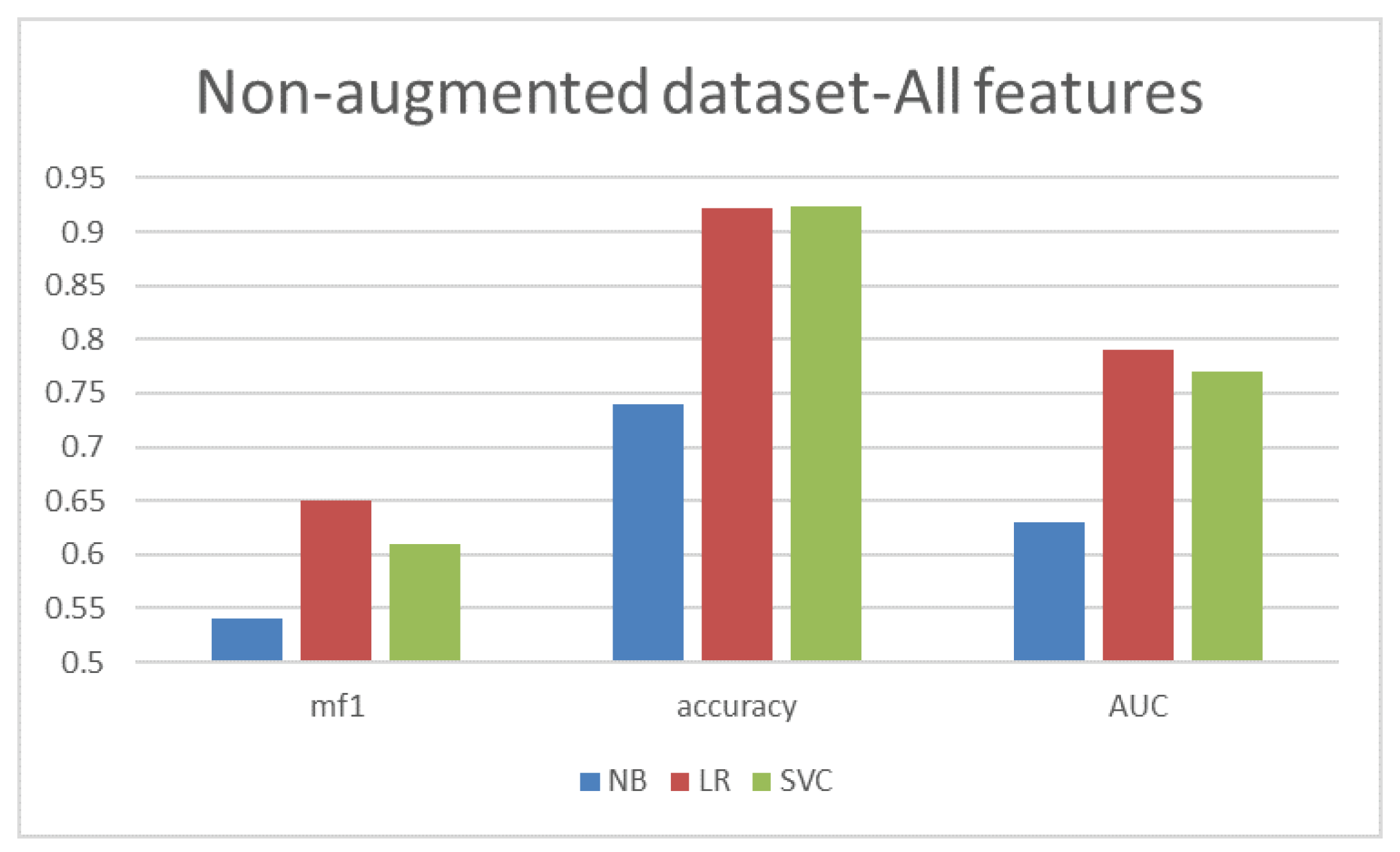
4.2. Experiment 2: Non-Augmented Dataset with All Features
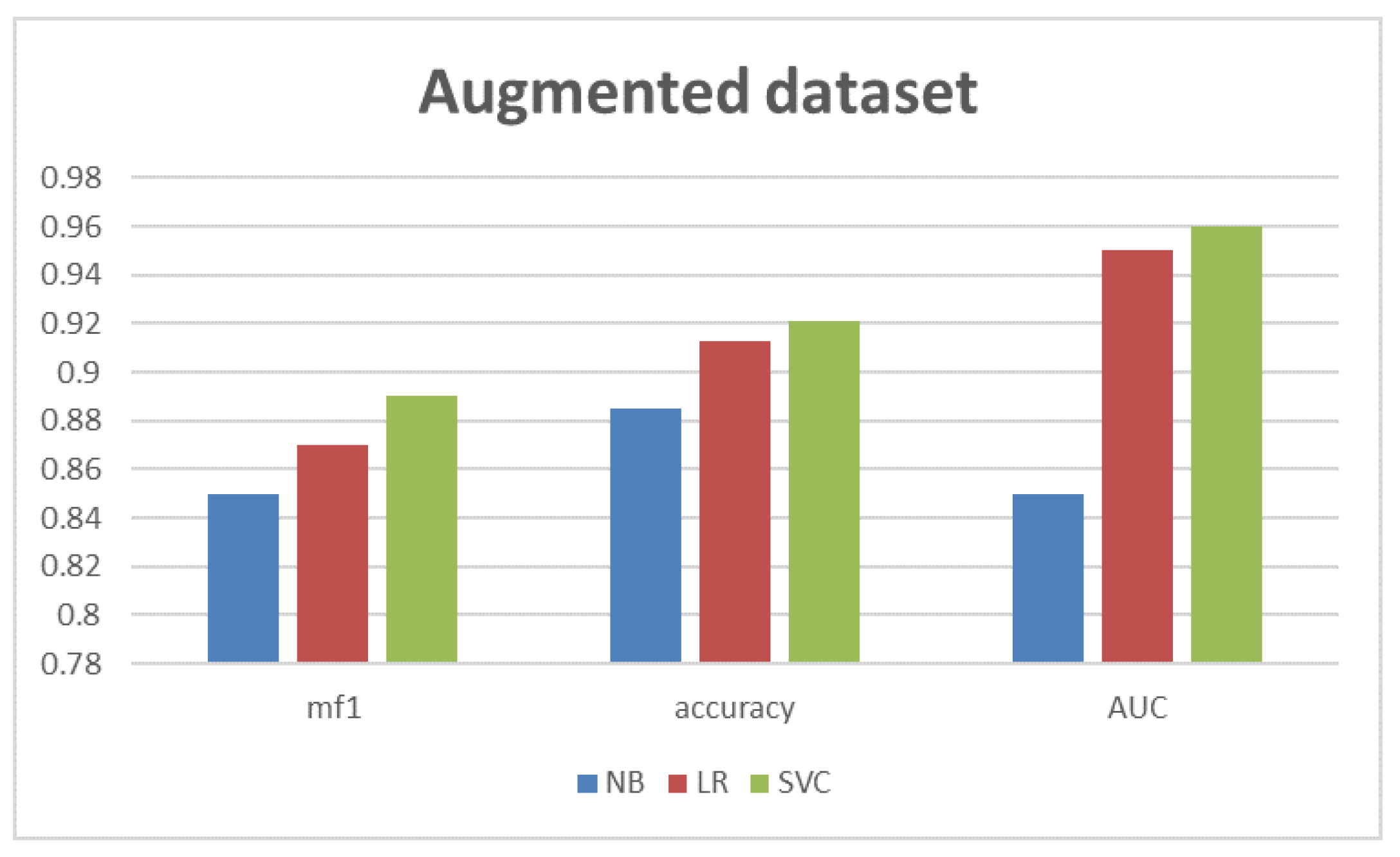
4.3. Experiment 3: Augmented Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AraBERT | Arabic Bidirectional Encoder Representations from Transformers |
| AUC | Area Under the receiver operating characteristic Curve (ROC) |
| BERT | Bidirectional Encoder Representations from Transformers |
| CBOW | Continuous Bag of Words Model |
| DASD | Data Augmentation for Arabic Spam Detection |
| DT | Decision Trees |
| KNN | k-Nearest Neighbours |
| LR | Logistic Regression |
| NB | Naive Bayes |
| NLP | Natural Language Processing |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| SMO | Social Media Optimization |
| SVM | Support Vector Machine |
| TF-IDF | Term Frequency-Inverse Document Frequency |
References
- Masood, F.; Almogren, A.; Abbas, A.; Khattak, H.A.; Din, I.U.; Guizani, M.; Zuair, M. Spammer detection and fake user identification on social networks. IEEE Access 2019, 7, 68140–68152. [Google Scholar] [CrossRef]
- Liu, N.; Hu, X. Spam Detection on Social Networks. In Encyclopedia of Social Network Analysis and Mining; Alhajj, R., Rokne, J., Eds.; Springer: New York, NY, USA, 2018; pp. 2851–2859. [Google Scholar] [CrossRef]
- Benevenuto, F.; Magno, G.; Rodrigues, T.; Almeida, V. Detecting spammers on twitter. In Proceedings of the Collaboration, Electronic Messaging, Antiabuse and Spam Conference (CEAS), Redmond, WA, USA, 13–14 July 2010; Volume 6, p. 12. [Google Scholar]
- Shen, H.; Liu, X.; Zhang, X. Boosting Social Spam Detection via Attention Mechanisms on Twitter. Electronics 2022, 11, 1129. [Google Scholar] [CrossRef]
- Jain, G.; Sharma, M.; Agarwal, B. Spam detection in social media using convolutional and long short term memory neural network. Ann. Math. Artif. Intell. 2019, 85, 21–44. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Huy, D.T.N.; Le, T.H.; Hang, N.T.; Gwoździewicz, S.; Trung, N.D.; Van Tuan, P. Further researches and discussion on machine learning meanings-and methods of classifying and recognizing users gender on internet. Adv. Mech. 2021, 9, 1190–1204. [Google Scholar]
- Wong, C. Analyzing Easy Data Augmentation Techniques for Text Classification. Ph.D. Thesis, Harvard College, Cambridge, MA, USA, 2021. [Google Scholar]
- Anaby-Tavor, A.; Carmeli, B.; Goldbraich, E.; Kantor, A.; Kour, G.; Shlomov, S.; Tepper, N.; Zwerdling, N. Do not have enough data? Deep learning to the rescue! In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7383–7390. [Google Scholar]
- Wang, W.Y.; Yang, D. That’s so annoying!!!: A lexical and frame-semantic embedding based data augmentation approach to automatic categorization of annoying behaviors using# petpeeve tweets. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2557–2563. [Google Scholar]
- Li, B.; Hou, Y.; Che, W. Data augmentation approaches in natural language processing: A survey. AI Open 2022, 3, 71–90. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Tran, T.; Pham, T.; Carneiro, G.; Palmer, L.; Reid, I. A bayesian data augmentation approach for learning deep models. Adv. Neural Inf. Process. Syst. 2017, 30, 2794–2803. [Google Scholar]
- Al-Dhabyani, W.; Gomaa, M.; Khaled, H.; Aly, F. Deep learning approaches for data augmentation and classification of breast masses using ultrasound images. Int. J. Adv. Comput. Sci. Appl 2019, 10, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Jaitly, N.; Hinton, G.E. Vocal tract length perturbation (VTLP) improves speech recognition. In Proceedings of the ICML Workshop on Deep Learning for Audio, Speech and Language, Atlanta, GA, USA, 16–21 June 2013; Volume 117, p. 21. [Google Scholar]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-end multimodal emotion recognition using deep neural networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef]
- Gao, J. Data Augmentation in Solving Data Imbalance Problems. Master’s Thesis, KTH, School of Electrical Engineering and Computer Science (EECS), Stockholm, Sweden, 2020. Available online: http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-289208 (accessed on 1 October 2022).
- Bayer, M.; Kaufhold, M.A.; Reuter, C. A survey on data augmentation for text classification. arXiv 2021, arXiv:2107.03158. [Google Scholar] [CrossRef]
- Mohammed, A.; Kora, R. Deep learning approaches for Arabic sentiment analysis. Soc. Netw. Anal. Min. 2019, 9, 52. [Google Scholar] [CrossRef]
- Duwairi, R.; Abushaqra, F. Syntactic-and morphology-based text augmentation framework for Arabic sentiment analysis. Peerj Comput. Sci. 2021, 7, e469. [Google Scholar] [CrossRef]
- Sabty, C.; Omar, I.; Wasfalla, F.; Islam, M.; Abdennadher, S. Data augmentation techniques on arabic data for named entity recognition. Procedia Comput. Sci. 2021, 189, 292–299. [Google Scholar] [CrossRef]
- Feng, S.Y.; Gangal, V.; Wei, J.; Chandar, S.; Vosoughi, S.; Mitamura, T.; Hovy, E. A survey of data augmentation approaches for nlp. arXiv 2021, arXiv:2105.03075. [Google Scholar]
- Wei, J.; Huang, C.; Vosoughi, S.; Cheng, Y.; Xu, S. Few-shot text classification with triplet networks, data augmentation, and curriculum learning. arXiv 2021, arXiv:2103.07552. [Google Scholar]
- Yoo, K.M.; Park, D.; Kang, J.; Lee, S.W.; Park, W. Gpt3mix: Leveraging large-scale language models for text augmentation. arXiv 2021, arXiv:2104.08826. [Google Scholar]
- Peng, W.; Huang, C.; Li, T.; Chen, Y.; Liu, Q. Dictionary-based data augmentation for cross-domain neural machine translation. arXiv 2020, arXiv:2004.02577. [Google Scholar]
- Xia, M.; Kong, X.; Anastasopoulos, A.; Neubig, G. Generalized data augmentation for low-resource translation. arXiv 2019, arXiv:1906.03785. [Google Scholar]
- Pasunuru, R.; Celikyilmaz, A.; Galley, M.; Xiong, C.; Zhang, Y.; Bansal, M.; Gao, J. Data augmentation for abstractive query-focused multi-document summarization. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2021), Online, 2–9 February 2021; pp. 13666–13674. [Google Scholar]
- Asai, A.; Hajishirzi, H. Logic-guided data augmentation and regularization for consistent question answering. arXiv 2020, arXiv:2004.10157. [Google Scholar]
- Zhang, R.; Yu, Y.; Zhang, C. Seqmix: Augmenting active sequence labeling via sequence mixup. arXiv 2020, arXiv:2010.02322. [Google Scholar]
- Yu, T.; Wu, C.S.; Lin, X.V.; Wang, B.; Tan, Y.C.; Yang, X.; Radev, D.; Socher, R.; Xiong, C. GraPPa: Grammar-augmented pre-training for table semantic parsing. arXiv 2020, arXiv:2009.13845. [Google Scholar]
- Wan, Z.; Wan, X.; Wang, W. Improving grammatical error correction with data augmentation by editing latent representation. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 2202–2212. [Google Scholar]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Cai, H.; Chen, H.; Song, Y.; Zhang, C.; Zhao, X.; Yin, D. Data manipulation: Towards effective instance learning for neural dialogue generation via learning to augment and reweight. arXiv 2020, arXiv:2004.02594. [Google Scholar]
- Barushka, A.; Hajek, P. Review spam detection using word embeddings and deep neural networks. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Crete, Greece, 24–26 May 2019; pp. 340–350. [Google Scholar]
- Jain, N.; Kumar, A.; Singh, S.; Singh, C.; Tripathi, S. Deceptive reviews detection using deep learning techniques. In Proceedings of the International Conference on Applications of Natural Language to Information Systems, Salford, UK, 26–28 June 2019; pp. 79–91. [Google Scholar]
- Erşahin, B.; Aktaş, Ö.; Kılınç, D.; Akyol, C. Twitter fake account detection. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Samsun, Turkey, 11–15 September 2019; pp. 388–392. [Google Scholar]
- Gharge, S.; Chavan, M. An integrated approach for malicious tweets detection using NLP. In Proceedings of the 2017 International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 10–11 March 2017; pp. 435–438. [Google Scholar]
- Concone, F.; De Paola, A.; Re, G.L.; Morana, M. Twitter analysis for real-time malware discovery. In Proceedings of the 2017 AEIT International Annual Conference, Cagliari, Italy, 20–22 September 2017; pp. 1–6. [Google Scholar]
- Chen, C.; Wang, Y.; Zhang, J.; Xiang, Y.; Zhou, W.; Min, G. Statistical features-based real-time detection of drifted Twitter spam. IEEE Trans. Inf. Forensics Secur. 2016, 12, 914–925. [Google Scholar] [CrossRef] [Green Version]
- Buntain, C.; Golbeck, J. Automatically identifying fake news in popular twitter threads. In Proceedings of the 2017 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 3–5 November 2017; pp. 208–215. [Google Scholar]
- Mateen, M.; Iqbal, M.A.; Aleem, M.; Islam, M.A. A hybrid approach for spam detection for Twitter. In Proceedings of the 2017 14th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 10–14 January 2017; pp. 466–471. [Google Scholar]
- Eshraqi, N.; Jalali, M.; Moattar, M.H. Detecting spam tweets in Twitter using a data stream clustering algorithm. In Proceedings of the 2015 International Congress on Technology, Communication and Knowledge (ICTCK), Mashhad, Iran, 11–12 November 2015; pp. 347–351. [Google Scholar]
- Gupta, A.; Kaushal, R. Improving spam detection in online social networks. In Proceedings of the 2015 International Conference on Cognitive Computing and Information Processing (CCIP), Noida, India, 3–4 March 2015; pp. 1–6. [Google Scholar]
- Chen, C.; Zhang, J.; Xie, Y.; Xiang, Y.; Zhou, W.; Hassan, M.M.; AlElaiwi, A.; Alrubaian, M. A performance evaluation of machine learning-based streaming spam tweets detection. IEEE Trans. Comput. Soc. Syst. 2015, 2, 65–76. [Google Scholar] [CrossRef]
- Stafford, G.; Yu, L.L. An evaluation of the effect of spam on twitter trending topics. In Proceedings of the 2013 International Conference on Social Computing, Washington, DC, USA, 8–14 September 2013; pp. 373–378. [Google Scholar]
- Mubarak, H.; Abdelali, A.; Hassan, S.; Darwish, K. Spam detection on arabic twitter. In Proceedings of the International Conference on Social Informatics, Pisa, Italy, 8 October 2020; pp. 237–251. [Google Scholar]
- Mataoui, M.; Zelmati, O.; Boughaci, D.; Chaouche, M.; Lagoug, F. A proposed spam detection approach for Arabic social networks content. In Proceedings of the 2017 International Conference on Mathematics and Information Technology (ICMIT), Adrar, Algiers, 4–5 December 2017; pp. 222–226. [Google Scholar]
- Al-Azani, S.; El-Alfy, E.S.M. Detection of arabic spam tweets using word embedding and machine learning. In Proceedings of the 2018 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakhier, Bahrain, 18–20 November 2018; pp. 1–5. [Google Scholar]
- Abozinadah, E.A.; Mbaziira, A.V.; Jones, J. Detection of abusive accounts with Arabic tweets. Int. J. Knowl. Eng.-IACSIT 2015, 1, 113–119. [Google Scholar] [CrossRef] [Green Version]
- Alshehri, A.; El Moatez Billah Nagoudi, H.A.; Abdul-Mageed, M. Think before your click: Data and models for adult content in arabic twitter. In Proceedings of the TA-COS 2018: 2nd Workshop on Text Analytics for Cybersecurity and Online Safety, Miyazaki, Japan, 7–12 May 2018; Volume 15. [Google Scholar]
- Albadi, N.; Kurdi, M.; Mishra, S. Are they our brothers? analysis and detection of religious hate speech in the arabic twittersphere. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; pp. 69–76. [Google Scholar]
- Hassan, S.; Samih, Y.; Mubarak, H.; Abdelali, A. ALT at SemEval-2020 task 12: Arabic and English offensive language identification in social media. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; pp. 1891–1897. [Google Scholar]
- Hassan, S.; Samih, Y.; Mubarak, H.; Abdelali, A.; Rashed, A.; Chowdhury, S.A. ALT Submission for OSACT Shared Task on Offensive Language Detection. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 12 May 2020; pp. 61–65. [Google Scholar]
- Mubarak, H.; Darwish, K. Arabic offensive language classification on twitter. In Proceedings of the International Conference on Social Informatics, Doha, Qatar, 18–21 November 2019; pp. 269–276. [Google Scholar]
- Saeed, R.M.; Rady, S.; Gharib, T.F. An ensemble approach for spam detection in Arabic opinion texts. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 1407–1416. [Google Scholar] [CrossRef]
- Abu Hammad, A.S. An Approach for Detecting Spam in Arabic Opinion Reviews. Int. Arab. J. Inf. Technol. 2015, 12, 9–16. [Google Scholar]
- Najadat, H.; Alzubaidi, M.A.; Qarqaz, I. Detecting Arabic spam reviews in social networks based on classification algorithms. Trans. Asian-Low-Resour. Lang. Inf. Process. 2021, 21, 1–13. [Google Scholar] [CrossRef]
- Alharbi, A.R.; Aljaedi, A. Predicting rogue content and Arabic spammers on twitter. Future Internet 2019, 11, 229. [Google Scholar] [CrossRef] [Green Version]
- El-Mawass, N.; Alaboodi, S. Detecting Arabic spammers and content polluters on Twitter. In Proceedings of the 2016 Sixth International Conference on Digital Information Processing and Communications (ICDIPC), Beirut, Lebanon, 21–23 April 2016; pp. 53–58. [Google Scholar]
- Al-Khalifa, H.S. On the analysis of twitter spam accounts in Saudi Arabia. Int. J. Technol. Diffus. (IJTD) 2015, 6, 46–60. [Google Scholar] [CrossRef] [Green Version]
- Soliman, A.B.; Eissa, K.; El-Beltagy, S.R. Aravec: A set of arabic word embedding models for use in arabic nlp. Procedia Comput. Sci. 2017, 117, 256–265. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Madukwe, K.J.; Gao, X.; Xue, B. Token replacement-based data augmentation methods for hate speech detection. World Wide Web 2022, 25, 1129–1150. [Google Scholar] [CrossRef]
- Herzallah, W.; Faris, H.; Adwan, O. Feature engineering for detecting spammers on Twitter: Modelling and analysis. J. Inf. Sci. 2018, 44, 230–247. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detecting Level | Features | Classifiers | Dataset | Results (Accuracy-F1) |
|---|---|---|---|---|
| [48] content-level | content-based, user-based | AraBERT, SVM | 133,500 tweets. | F1 98% |
| [49] content-level | content-based | NB, SMO, LR | 2224 Facebook comments | 91.73% |
| [51] user -level | content-based, user-based | NB, SVM | 500 accounts | 90% |
| [52] content-level | content-based | SVM | - | 79% |
| [53] content-level | content-based | LR, SVM, RNN | 6000 Arabic tweets | 79% |
| [50] content-level | content-based | NB, SVM, DT | 3503 Arabic tweets | 87% |
| [57] content-level | content-based | LR, SVM, NB, RF | 1600 hotels reviews | 95.25% |
| [58] content-level | content-based, user-based | NB, KNN, SVM | 2848 hotels reviews | F1 99.59% |
| [59] content-level | content-based | KNN, SVM, NB | 3000 Facebook comments | 92.63% |
| [60] user-level | content-based, user-based | RF | 12,486 accounts | 90% |
| [61] user-level | content-based, user-based | NB, RF, SVM | 5000 tweets | 92.59% |
| Feature Name | Description | |
|---|---|---|
| Content Features | TF-IDF | Multiplication of TF and IDF scores whereas TF is a scoring of the frequency of the word in the current document and IDF is a scoring of how rare the word is across documents. TF = (Frequency of a word in the document)/(Total words in the document)IDF = Log ((Total number of docs)/(Number of docs containing the word)). |
| Spam words | Number of spam words in the tweet | |
| Hashtag counts | Number of hashtags in the tweet | |
| URLs counts | Number of URLs in the tweet | |
| Interaction features | Retweet counts | Number of retweets for the tweet |
| Mention counts | Number of mentions in the tweet | |
| Duplication counts | The count of tweet text duplication | |
| Favorite count | Number of favorites for the tweet | |
| Account features | Followers count | Number of followers of this Twitter user |
| Friends count | Number of followings/friends of this Twitter user | |
| Description length | Number of characters in the user description |
| Algorithm | Non-Augmented Dataset | ||||||
|---|---|---|---|---|---|---|---|
| Class | Precision | Recall | F1 | Macro-F1 | Accuracy | AUC | |
| NB | 0 | 0.22 | 0.29 | 0.20 | 0.57 | 0.891 | 0.59 |
| 1 | 0.96 | 0.93 | 0.94 | ||||
| LR | 0 | 0.24 | 0.31 | 0.22 | 0.58 | 0.893 | 0.75 |
| 1 | 0.96 | 0.93 | 0.94 | ||||
| SVC | 0 | 0.12 | 0.55 | 0.18 | 0.57 | 0.918 | 0.74 |
| 1 | 1.00 | 0.92 | 0.96 | ||||
| Algorithm | Non-Augmented Dataset-All Features | ||||||
|---|---|---|---|---|---|---|---|
| Class | Precision | Recall | F1 | Macro-F1 | Accuracy | AUC | |
| NB | 0 | 0.52 | 0.16 | 0.25 | 0.54 | 0.74 | 0.63 |
| 1 | 0.76 | 0.95 | 0.84 | ||||
| LR | 0 | 0.24 | 0.59 | 0.33 | 0.65 | 0.922 | 0.79 |
| 1 | 0.98 | 0.93 | 0.96 | ||||
| SVC | 0 | 0.16 | 0.65 | 0.26 | 0.61 | 0.923 | 0.77 |
| 1 | 0.99 | 0.93 | 0.96 | ||||
| Algorithm | Augmented Dataset | ||||||
|---|---|---|---|---|---|---|---|
| Class | Precision | Recall | F1 | Macro-F1 | Accuracy | AUC | |
| NB | 0 | 0.78 | 0.78 | 0.78 | 0.85 | 0.885 | 0.85 |
| 1 | 0.92 | 0.92 | 0.92 | ||||
| LR | 0 | 0.81 | 0.85 | 0.83 | 0.87 | 0.913 | 0.95 |
| 1 | 0.95 | 0.93 | 0.94 | ||||
| SVC | 0 | 0.76 | 0.93 | 0.84 | 0.89 | 0.921 | 0.96 |
| 1 | 0.98 | 0.92 | 0.95 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkadri, A.M.; Elkorany, A.; Ahmed, C. Enhancing Detection of Arabic Social Spam Using Data Augmentation and Machine Learning. Appl. Sci. 2022, 12, 11388. https://doi.org/10.3390/app122211388
Alkadri AM, Elkorany A, Ahmed C. Enhancing Detection of Arabic Social Spam Using Data Augmentation and Machine Learning. Applied Sciences. 2022; 12(22):11388. https://doi.org/10.3390/app122211388
Chicago/Turabian StyleAlkadri, Abdullah M., Abeer Elkorany, and Cherry Ahmed. 2022. "Enhancing Detection of Arabic Social Spam Using Data Augmentation and Machine Learning" Applied Sciences 12, no. 22: 11388. https://doi.org/10.3390/app122211388