1. Introduction
Shortly, the Cyber Security Law, which has been in force for more than five years in China, will be revised for the first time. It is expected to increase the maximum penalty to 5% of annual revenue. Cyber security has been paid more and more attention. How to identify various attacks quickly and in real time, especially unforeseen attacks, is an inevitable problem at present. An Intrusion Detection System (IDS) can identify the existing or ongoing intrusion and has become an important research object in the field of information security.
The IDS technique is mainly composed of misuse detection and anomaly detection [
1,
2,
3,
4]. Misuse detection, also called signatures-based detection, focuses on detecting attacks using signatures. Generally, misuse detection systems consist of a set of signature databases that must be updated in time to detect the latest attack types. The advantage of misuse detection is that the False Positive Rate is low, and the detailed attack types and possible causes can be obtained. However, misuse detection lacks the ability to detect unknown attacks, has a high False Positive Rate and needs to maintain a huge signature database. Anomaly detection needs to define a normal profile. Once the network behavior deviates from the normal behavior, it is considered that an attack has occurred. Anomaly detection has strong generalization ability and can identify unknown attacks. Its disadvantage is that it has a high False Positive Rate and cannot provide the possible causes of anomalies. Although the IDS has been developed for decades, it still faces many challenges, such as lower Detection rate and high False Negative Rate and False Positive Rate [
1,
2,
3,
4].
Machine-learning methods have been widely used to improve the performance of IDS. However, each machine-learning method has its advantages and disadvantages. The No Free Lunch (NFL) theorem points out that different machine-learning algorithms have their own application scenarios and there is no optimal and universal algorithm [
5]. Ensemble learning, sometimes called a multiple classifier system or committee-based learning, completes the learning task by constructing and combining multiple learners. The ensemble methods are widely used to solve various problems because of their advantages in accuracy, stability and generalization [
6,
7]. According to whether the types of the generated base learners are the same, the ensemble methods can be divided into homogeneous methods and heterogeneous methods. For the homogeneous method, the same learning algorithm is used to generate base learners. The Random Forest (RF) method, a well-known ensemble learning method, belongs to this type, in which all its base learners are in the Decision Tree. In the heterogeneous method, different technologies with different performances are used to form base learners.
Ensemble learning mainly involves generation, system topology and combination. In the first period, a large number of base learners to be ensembled are trained. There are six main ways to generate accuracy and diverse base learners, including different initializations, different parameters, different architectures, different classifier models, different training sets and different feature sets [
8]. In the second stage, the base learners generated above can be organized in a parallel or serial manner. In the parallel structure, the classifiers are independent. In the serial topology, base learners are applied sequentially. First, the lead base learner in the sequence has to make a decision. If the main learner fails to decide, the task is handed over to the secondary learner, and so on. Most of the ensemble models reported in the literature adopt the parallel topology. In the last stage, the results of the base learner are combined to make the final decision.
Some methods use a function to combine the outputs of all base learners. The combining method includes the weighting method, probabilistic methods, evidential reasoning-based approaches and meta-learning methods [
9]. The ideal combination method should be able to use the advantages of the base learners and minimize their disadvantages. There are three output types of the base learner, including crisp labels, class rankings and soft outputs. The three types of output carry different amounts of information. Among them, the soft output contains the highest amount of information, while the crisp labeling method has the least amount of information. Liu et al. [
10] believe that the combination methods can also be classified into three groups. The crisp labels can be combined by voting approaches while the class rankings can be combined by class set reduction/reordering approaches. The Bayesian rule, fuzzy integrals and evidential reasoning can be applied to merge the soft outputs [
10]. However, with the increase of the data complexity, some flexible methods are needed as the combination methods of the ensemble, which can be adjusted according to the attributes of the dataset used. Some scholars indicate that the efficiency of combinatorial methods can be improved by assigning weights to the classifiers [
11]. Sava et al. [
12] point out that it is necessary to assign weights to different base learners according to their performance in the heterogeneous learning. Cao et al. [
13] provide two weight-optimization methods under the framework of the Class-Level Soft-Voting Ensemble. They suggest that the class-specific soft-voting method can refine the weights from classifiers to classes and improve the combinative performance.
In this paper, the Class-Level Soft-Voting Ensemble (CLSVE) is used for intrusion detection. Through literature research and extensive empirical analysis, the Support Vector Machine (SVM), K-Nearest Neighbor (KNN) and Decision Tree (DT) are selected as the base learners [
14,
15,
16,
17]. On the other hand, the Chaos Bat Algorithm with Opposition-Based Learning (OBL) is used for the weight optimization of the ensemble. The Bat Algorithm (BA) has better performance than the Genetic Algorithm (GA) and Particle Swarm Optimization Algorithm (PSO) [
18]. However, it still has the disadvantages of the declining population diversity and local convergence in the searching processes [
19,
20]. Note that the combination of chaos and metaheuristic algorithms is a promising research field [
21]. Due to its dynamic characteristics, chaotic mapping has been widely recognized in the field of optimization, which makes the Optimization Algorithm explore the search space more actively and globally. Moreover, the OBL strategy [
22], which aims to boost the efficiency of the Bat Algorithm, is also used for the initialization of the population. Therefore, a new soft-voting scheme based on the Chaos Bat Algorithm with Opposition-Based Learning is used to combine the base learners of the ensemble.
In short, the main contributions of this paper are as follows:
- (1)
An improved ensemble framework named CBA-CLSVE is proposed. The Class-Level Soft-Voting Ensemble (CLSVE) is selected for intrusion detection.
- (2)
The Chaos Bat Algorithm (CBA) with the Opposition-Based Learning method is used to generate class-level weights to create the weighted voting ensemble.
- (3)
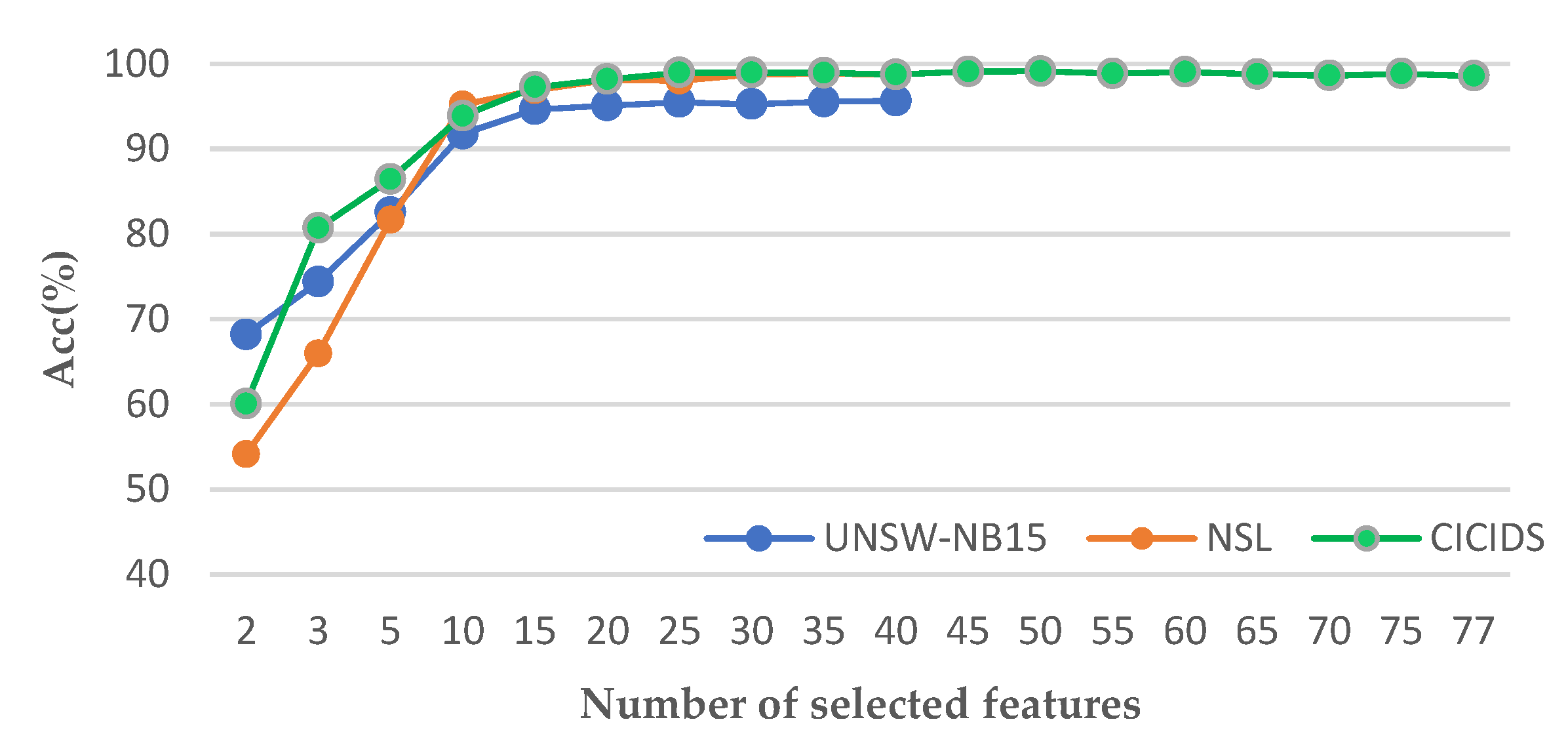
The soft-voting schemes are compared with the hard-voting methods based on the same learners. We also compare the performance of different voting ensemble methods with or without feature selection. It is verified that the Class-Level Soft-Voting method based on the CBA can be used to improve the ensemble performance. It also shows that the same performance of the ensemble can be obtained with half the total number of features or fewer.
The organization of the paper is as follows. The related work is provided in
Section 2.
Section 3 presents the background including the hard-voting and soft-voting method, the base learners and the basic Bat Algorithm. The proposed CBA-CLSVE framework for intrusion detection is described in
Section 4. The experimental results are introduced in
Section 5. The paper is concluded in
Section 6.
2. Related Work
A large number of machine-learning algorithms, including shallow or deep learning, are applied to intrusion detection. Gu et al. [
23] proposed a hybrid model containing SVM and Naïve Bayes (NB). Naïve Bayes was used to generate high-quality data and then sent to the SVM classifier. Liu et al. [
24] applied the KNN and the Arithmetic Optimization Algorithm (AOA) to the intrusion detection. The AOA was used to optimize the relevant parameters of KNN. Kan et al. [
25] designed an intrusion-detection model based on the Convolutional Neural Network (CNN) and PSO for the Internet of Things (IoT). Sahu et al. [
26] introduced an attack-detection mechanism combining CNN and LSTM to detect infected devices in the Internet of Things.
There are also many intrusion-detection mechanisms based on ensemble learning. Amini et al. [
27] proposed a new ensemble method using the Radial Basis Function (RBF) neural networks. To increase the diversity of classifiers, classifiers were trained using different subsets that were divided by the Fuzzy C-Means (FCM) method. The membership grade generated by the fuzzy clustering technology was used as the classifier weight to combine multiple classifiers. Experimental results showed that the proposed method has a better detection effect for small classes of samples compared with simple voting and weighted majority voting. Gu et al. [
28] proposed an intrusion-detection framework based on an SVM ensemble. The authors used the ratio transformations technique to improve the quality of training data. The FCM method was also used to enhance the diversity of SVM classifiers. Finally, the authors used a nonlinear combination method to aggregate these SVM classifiers. Yang et al. [
29] proposed a Gradient Boosting Decision Tree (GBDT) parallel quadratic ensemble learning method for intrusion detection. Firstly, the traditional ensemble learning method GBDT was used to make the prediction based on the spatial feature, and the temporal method Bidirectional Gated Recurrent Unit (Bi-GRU) was employed to capture the temporal information. Then, the GBDT model and Bi-GRU model were combined to form a quadratic ensemble. Euh et al. [
30] introduced tree-based ensemble learning models such as AdaBoost, XGBoost, RF, extra trees and rotation trees for malware detection. Gao et al. [
31] introduced an adaptive ensemble method for intrusion detection. The base classifiers, including DT, RF, KNN, and deep neural network, were combined using the voting method with class weights. The weights can be obtained by calculating the training accuracy of each algorithm for different attack types.
The ensemble learning, especially the weighted voting scheme, can also be applied to other fields, such as bankruptcy prediction, text sentiment classification, Named Entity Recognition (NER), etc. Zelenkov et al. [
32] proposed an ensemble method for bankruptcy prediction in which GA was used to select relevant features and classifier weights. In the ensemble, the most extensive models, including Logistic Regression (LR), KNN, SVM, NB, and DT, were used. Zelenkov et al. [
33] proposed an ensemble model for bankruptcy prediction in which different classifiers were combined by the soft-voting rule. The ensemble model can minimize the False Positive Rate (FPR) and False Negative Rate (FNR) simultaneously. Onan et al. [
34] proposed a static classifier-selection ensemble for text sentiment classification in which five different classifiers were combined. A multi-objective Differential Evolution Algorithm was used to generate class-level weights. Saleena et al. [
35] introduced a weighted ensemble approach for tweet sentiment analysis in which the NB, RF, SVM and LR were used as the basic classifiers. The weight of each classifier is obtained by its training accuracy. Saha et al. [
36] proposed a classifier ensemble scheme using the weighted voting based on GA for NER. The experiments showed that instead of completely eliminating some classifiers, it is better to quantify the voting amount for each class in each classifier. Ekbal et al. [
37] designed a classifier ensemble technology-based on the Maximum Entropy (ME), Conditional Random Field (CRF) and SVM. The multi-objective simulated annealing technique was used to determine the appropriate votes for each class per classifier in NER.
In summary, in most weighted voting ensembles, the classifier-level weight is usually used instead of class-level weight. The weight can be obtained according to the training result or using a metaheuristics method such as the Genetic Algorithm. To our knowledge, the method of using an improved Bat Algorithm to generate the class-level weight has not been reported. This paper explains the research conducted around this technique.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}