1. Introduction
Music is an important aspect of any human culture, being able to induce a range of intense and complex emotions both in musicians involved in composing pieces and individuals listening to them. The digital age involved sizeable changes in the economy, in the industrial and social spheres, with interesting advances and transformations also in the music field. With regard to the music streaming market, its size was valued at USD 29.45 billion in 2021 and is expected to expand at a compound annual growth rate (CAGR) of 14.7% from 2022 to 2030 [
1]. The penetration of music streaming platforms, as well as the ubiquity of smartphones, will boost the music market growth, accordingly. Furthermore, platforms that allow streaming services are gaining popularity, offering services such as song recommendations and automatic playlist personalizations by supporting individuals in suggesting similar (and preferred) pieces. On the other hand, emotion/mood has become a fundamental criterion used by digital technologies in predicting social behaviors or conditioning people in their social interactions and work activities.
In light of this, music systems that regulate mood and emotions in our daily life are arousing particular interest. Consequently, a great deal of research has been undertaken in the
affective computing community to model the relationship between music and emotion [
2,
3,
4,
5]. More in general, applications of affective computing studies can be found in education, health care, entertainment, ambient intelligence, multimedia retrieval, and music retrieval and generation. As for the specific musical context, most of these works consist of context-sensitive recommendation tools that consider the listener’s emotional state. Unfortunately, few results have been obtained in the study of music systems for
induction of future emotional states, i.e., methods for influencing the emotional state of listeners and adapting interaction with technology to their affective state. Unlike games or movies [
6,
7], where the study of the induction of emotional states has recently obtained interesting results, especially in educational or commercial contexts, the potential of music as a means of inducing emotions still leaves significant possibilities for study.
Inductive systems use
affective contents for induction of emotional states, assuming that the emotions conveyed by the affective content (
perceived emotions) are always consistent with emotions brought to mind in users’ (
induced emotions) games or movies [
2]. There are at least two main perspectives in such systems: user and system perspectives. Users perceive and interpret the content (perceived emotions). Systems usually provide
emotional annotations that describe which emotions are expected by the users during an interaction step (intended emotions). In general, perceived and induced emotions are not usually considered separately in studies on affective content. However, some studies on “music emotions” have shown that in music, traditionally regarded as an art form that can make people produce emotional responses or induce their emotions naturally [
8,
9], emotions perceived are not always consistent with the emotions elicited in listeners [
10].
This is particularly evident in most music recommendation systems. Recommender systems have been widely studied in recent years [
11,
12], but they do not always lead to the best possible designs for affective recommendation systems.
Several studies showed that emotions could play a significant role in designing intelligent music recommendation systems, and most of them focused on “recognizing” emotions induced by music [
13,
14,
15,
16,
17,
18], nearly no attempts have been made to model musical emotions and their changes over time in terms of a target “emotion to induce”. In this paper, we explore this direction, and we focus on the problem of defining an intelligent music recommendation system that, given a future
target emotional state to induce, and starting from the assumption that an emotional state is determined entirely by a sequence of music pieces recently listened to, selects the list of music pieces that better “match” it.
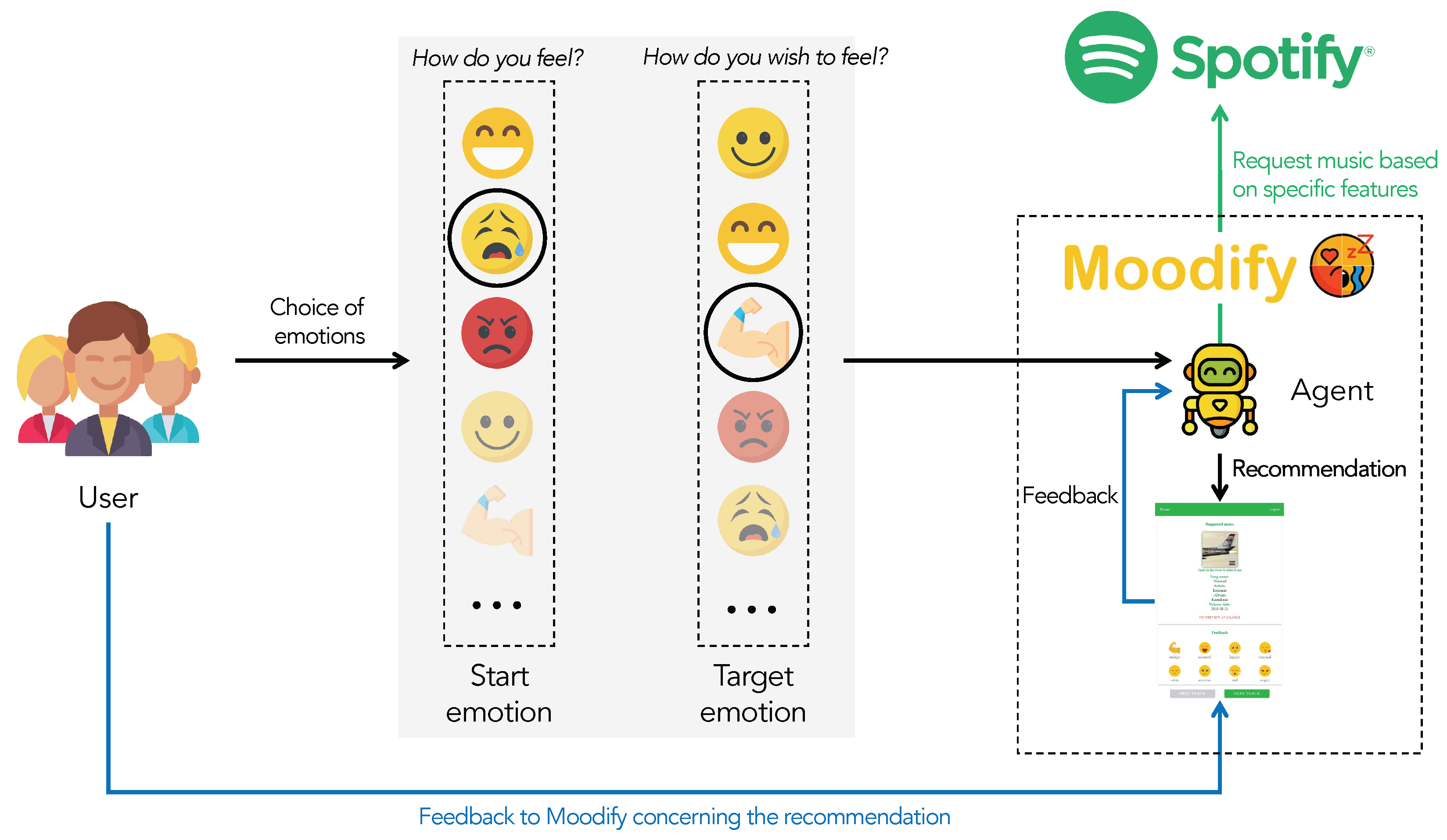
In order to “recommend” music for inducing a
target emotional state, we exploit reinforcement learning (RL) techniques that were proven effective in recommendation music systems. The idea is to train an intelligent agent capable of recommending songs such that the user’s mood changes from a given current emotional state to a desired target emotional state based on the user’s musical preferences (see
Figure 1 for an overview of the proposal). The agent learns the user’s preferences and the best trajectories for inducing the target emotion through a feedback-based mechanism. However, to face sparse and deceptive problems, we propose a novel method based on Go-Explore [
19]. Go-Explore has proven particularly effective on hard-exploration problems, a category that many real-world issues belong to. We will show that this also applies to the problem of affective computing in the musical recommendation.
The main contributions of this paper can be summarized as follows.
We propose Moodify, a novel music recommendation system based on Go-Explore, which takes into account the listener’s emotional state for inducing a future target emotion; the main novelty is that it adopts a “look-forward-recommendation”, i.e., it recommends music intended to induce (in the future) a specific target emotion. Previous works in the literature have proposed methods that, based on the current user’s mood, recommend music or artists to listen to, for example, by computing similarities between artists’ and users’ moods.
To analyze its effectiveness and overall user satisfaction, we have involved 40 people in testing Moodify, with one million music playlists from the Spotify platform; results obtained show that the proposed system can bring both significant overall user satisfaction and high performance. To the best of our knowledge, this is one of the few proposals of a system which undergone an evaluation phase of this kind.
The proposed method has been developed as a Web application, namely MoodifyWeb, which exploits Spotify API for developers and JavaScript. To the best of our knowledge, this is one of the first proposals deployed in software for end-users.
The remaining parts of the paper are structured as follows. First, in
Section 2, we offer an overview of the most used recommendation approaches in the literature, and we discuss some relevant works that inspired the proposed one. With respect to these points, we place our proposal highlighting similarities and differences with previous works. Then, in
Section 3, we provide preliminary knowledge to understand the methods and techniques used in
Moodify. In
Section 4, we formalize the music recommendation system highlighting the relation with Go-Explore. Next,
Section 5 offers details on the web application implemented that revolves around the proposed music recommendation method.
Section 6 is devoted to discussing the results obtained when surveying users about the usability and satisfaction of MoodifyWeb. Lastly, in
Section 7, we provide final remarks with envisioned future directions of this research.
2. Related Work
In the literature, there are many solutions for recommending music suited to the listeners’ environment, and in general, in all areas that refer to IT for “well-being”, e.g., gyms [
20] or home settings [
21]. From a
musical point of view, the music generation takes place either by selecting existing music from platforms such as Spotify or Youtube or by using sophisticated generative music composition techniques [
22,
23]. From a
technological point of view, most such systems combine Artificial Intelligence (AI) and Internet of Things (IoT) techniques to ensure intelligent musical choices that satisfy listeners [
21]. Therefore, given the vastness of the topic, in this section, we limit ourselves to an analysis of the works most closely related to the one proposed in this paper, essentially classifying them into four main categories:
collaborative filtering (
Section 2.1),
content-based filtering (
Section 2.2),
context-based filtering (
Section 2.3), and
emotion-based filtering systems (
Section 2.4).
2.1. Collaborative Filtering
Collaborative filtering generates automatic predictions about users’ interests by collecting preferences from a large user base. This approach adopts
user ratings to recommend songs. Such systems are built on the following assumption: users who rate songs similarly in the past will continue to rate them similarly in the future [
24]. Usually, clustering algorithms are employed to deliver recommendations. Ratings can be of two kinds:
explicit or
implicit. Examples of explicit ratings are the stars-based systems that e-commerce sites use: the user has to express a rating often based on a five-star score where the higher is the better (e.g., Trustpilot (Available online:
https://it.trustpilot.com, accessed on 18 October 2022)). These ratings are explicitly provided by the users. Instead, implicit ratings can be collected by throwing light on the user’s behaviors. For instance, play counts can be employed for implicit rating: a song played thousands of times gets a higher implicit rating than some others that have listened a dozen times. The biggest drawback of these kinds of systems is that they offer poor recommendations in the early stages. Especially for songs with very few ratings, recommendations are performed in a not-very-reliable [
25] fashion. This is a well-known issue in the literature, named the
cold-start problem. When a new user joins the system, the recommender cannot offer effective suggestions, as the user has never interacted before and hence has not rated anything yet. Another challenge of collaborative filtering is related to human effort. In general, users are not willing to rate every item on a system that requires a lot of effort and attention to generate recommendations. Among the closest articles in the literature, there is the proposal by [
26] in which association rules and music features were added to a collaborative filtering mechanism. The system considers users’ preferences for different song features and uses the similarity of interests among different users to suggest music. The system has been implemented in a Web application as we did, and the author also performed an experiment with 20 real users. The main difference is that we do not use a collaborative filtering method, but the suggestion is only tailored to the specific user; we employ an RL-based method to recommend music and not a rule-based algorithm; lastly, the deployed Web application is not described thoroughly as well as the user evaluation, which is, furthermore, only a preliminary one and does not involve, for example,
confirmation of expectation test. In addition, the results of the evaluation are not clear.
Moodify employs an explicit rating “encapsulated” in an RL approach tailored to one user only. Every user has his/her own agent tailored, through usage, to his/her needs. Such a rating mechanism is used to define a reward function, i.e., by asking the user to evaluate how much the emotion felt at the end of each listening is similar to target emotion.
2.2. Content-Based Filtering
In the content-based filtering approach, music is recommended to exploit the system’s comparison between the items’ content and a user’s profile. Each item’s content is represented as a set of tags. In the case of textual documents, the tags can describe the words within a document. In the case of music, the tag—in the simplest form—can be related to the genre. Several issues must be considered when implementing such a category of systems:
tags can either be assigned automatically or manually;
the tags must be generated or assigned such that both the user’s profile and the items can be easily matched and compared to derive a similarity measure;
a learning algorithm must be chosen that learns and classifies the user’s profile based on played songs (i.e., seen items) and offers recommendations based on it.
To recommend music, the song’s features, such as loudness, tempo, and danceability, are analyzed. Among the widely used methods to perform content-based filtering and measure similarities between user’s profile and songs are (i) clustering [
27] and (ii) expectation-maximization with Monte Carlo sampling. These techniques can recommend music tracks also with very little data; thus, they solve the cold-start problem (seen in
Section 2.1). The major challenge of these approaches is in the appropriateness of the item model [
28]. Another major drawback is that, with tags trying to describe the songs’ macro-characteristics, these approaches fail to differentiate crucial musical differences between similar songs in terms of tags.
In [
29], the authors introduce MoodPlay, a system for recommending music artists based on the general mood of the artists and the self-reported mood of users. The authors proposed the method and the visual (graph-based) interface of the system. In addition, they performed an experiment with more than 200 final users. From these experiments, it emerged that mood plays a crucial role in the recommendation. The main differences from this work are (i) we recommend songs, not artists; (ii) we only base our recommendations on the starting emotion and target emotion; thus, we do not consider artists’ general mood; (iii) our system is designed to induce a particular emotion, not to recommend a specific artist based on “the similarity” between certain user and artist moods; (iv) the ultimate goal of [
29] was more related to understanding how users perceive recommendations through visual interfaces than generating an affective recommender system.
With respect to these kinds of systems, Moodify does not use pre-defined item content to compare with the user profile. It “dynamically” builds an intelligent agent capable of selecting the music most suited to the user’s target emotional state simply by observing the choices and the ratings assigned by the user himself during a training phase.
2.3. Context-Based Filtering
The context-based filtering approach takes advantage of the public perception of a music track in its suggestions. It exploits social media such as Facebook and Twitter and video platforms such as YouTube to collect information and derive insights about the public opinion of songs. Then, it recommends such music tracks accordingly to the users. This approach considers the users’ listening history of collecting user data; next, it recommends similar songs based on the engagement the songs have generated on social media. The context-based technique can build a “For You section” for the user through intelligent exploitation of user preferences (i.e., the listening history) and social media engagement of different music tracks. Another technique in this category of filtering uses the user’s location to suggest appropriate music tracks. The basic idea is that listeners in the same place may like similar music, and the system suggests music tracks with this assumption. The literature offered insights into the performance of this model, that is, it could perform as well as the amount of social information collected [
30], but it needs to integrate with various sources and exploit a joint analysis of a massive data load to ensure good performance.
A different kind of context-based technique exploits data captured from the users, for example, from their activities that are treated as context. In [
31], the authors propose a smartphone-based mobile system to recognize human activities and recommend music accordingly. In the proposed method, a deep recurrent neural network is applied to obtain a high level of activity recognition accuracy from accelerometer signals on the smartphone. Music recommendation is performed using the relationship between recognized human activities and the music files that reflect user preference models in order to achieve high user satisfaction. The results of comprehensive experiments with real data confirm the accuracy of the proposed activity-aware music recommendation framework. In this case, the authors have not developed the system as an application for end-users, and they have not evaluated their method with listeners. Conversely, in the present work, we provide insights from end-users on the MoodifyWeb app deployed. Similarly, in [
21], the author proposed a framework based on deep learning and IoT architectures to build a music recommendation system, but did not provide any software or evaluation to listeners. Both the aforementioned works revolve around the recognition of emotion through different devices and the recommendation of a suitable song. Differently, we aim to induce emotion through a series of songs with
Moodify.
With respect to context-based filtering, our solution does not build a listening history nor collect information to be used for the recommendation. Instead, the listening history is implicitly employed in the training phase to build the agent and the reward of our method. The only listening information exploited concerns the audio features from Spotify of the songs listened to during the training sessions.
2.4. Emotion-Based Filtering
As explained above, music and human emotions are closely intertwined, so we have a recommended approach that considers human emotions, namely emotion-based filtering. Different audio features of the music tracks are used to understand emotions that they may trigger or induce. Then, music streaming sites build playlists based on human emotions and moods tailored to a feeling that a user might experience while listening to those songs. In this field, the research on affective computing has produced a series of interesting solutions (see [
32] for a recent survey on the topic related to music). We have identified various works [
33,
34,
35,
36,
37,
38,
39,
40,
41,
42]. Some studies identify emotions through facial expressions. Others analyzed EEG [
40], physiological, and video signals. These works show that musical recommendation is generally carried out by combining physiological signals, heart and respiratory rates, and facial expressions, and in general, AI methods (generally deep learning techniques) were used to analyze such information. Among the works on this kind of filtering, we found [
43], where the authors propose an emotion-based music recommendation framework that learns the emotion of a user from the signals obtained via wearable sensors. In particular, a user’s emotion is classified by a wearable computing device integrated with a galvanic skin response and photoplethysmography sensors. The experimental results were obtained from 32 subjects’ data. The authors evaluated several machine learning methods, such as decision tree, support vector machines, and k-nearest neighbors. The results of experiments on real data confirmed the accuracy of the proposed recommender system. With respect to [
43], we deploy an RL-based recommender system for music to induce emotions in a prototype Web application, and we perform a real-world experiment with end-users to get their perceptions about
Moodify.
Moodify belongs to this class. However, some novelties need to be highlighted. First, the equipment needed for the recommendation. Such solutions require EEG or ECG, facial expression, or physiological information to recommend adequate songs. However, the devices need to capture those traits for the mood analysis are not common and quite expensive in some cases. Our idea is that Moodify can recommend music without requiring further devices or equipment. Though, Moodify can be extended with appropriate modules to consider traits like facial expression, and EEG for recognizing the mood while in use. Furthermore, Moodify adopts a “look-forward-recommendation”, i.e., it recommends music with the aim of inducing (in the future) a specific target emotion. All the methods described, instead, adopt a “look-back-recommendation”, i.e., to recommend music only by using previously collected or observed information.
2.5. Summarizing Literature’s Proposals
In this section, we summarize the proposals available in the literature and we list the similarities and differences with ours. Such information is reported in
Table 1, where we sketch the papers based on: (i) type of approach (collaborative, emotion, etc.); (ii) the idea behind the proposal; (iii) whether a method is presented; (iv) whether the software is presented/available; (v) whether a user evaluation/study has been carried out.
4. Music Recommendation Based on Go-Explore
In this section, we propose
Moodify, a music recommendation system based on Go-Explore and able to induce target emotions in the user.
Table 3 summarizes the main project decisions made to exploit the Go-explore paradigm for defining the proposed system.
In the following, we first dwell on definitions and preliminary information (
Section 4.1). Next, we formalize the problem (
Section 4.2, then we show the methodology adopted (
Section 4.3) with details about the two main steps of
Moodify, i.e., listen until solved (
Section 4.3.2)—with related cell and state representation, selection, exploration and update—and emotion robustification (
Section 4.3.3). Lastly, we dwell on the limitations of the method (
Section 4.3.4).
4.1. Preliminaries and Definitions
During a preliminary analysis, we observed that given an initial emotional state, the induction through music recommendation of a target emotional state practically never occurs through listening to a single piece of music. In fact, it is usually necessary to listen to different songs with the passage of intermediate emotions. Formally, let be the start emotional state and be the target emotional state of a user, and let be the sequence of musical songs that induces in the user starting from . We observed that . This interesting observation justifies using an RL-based approach to define an emotion-based music recommendation system able to induce emotions.
We define as a musical trajectory from to for the user, and the corresponding emotional trajectory from to for the user, where is the intermediate emotional state induced in the user, after listening to .
Observe that, let
E be an emotional state, it corresponds to a specific point in the two-dimensional space of the circumplex model shown in
Figure 2. So, given two emotional states
and
, we say that the distance between
and
, denoted with
, is the euclidean distance between the point in the circumplex model corresponding to
and the point in the circumplex model corresponding to
.
4.2. Problem Description
We emphasize that let be the start emotional state and be the target emotional state of a user, Moodify will be trained to propose the “best trajectory” from to . In our context, the concept of “best trajectory” is related to two aspects. On the one hand, we are interested in finding the musical trajectory that allows the listener to reach an emotional state that is “as close as possible” to the chosen target emotional state (appropriateness of the recommendation). On the other hand, we are interested in reaching the emotional state in the shortest possible time, therefore, in waiting as short as possible (responsiveness of the recommendation).
Thus, the problem faced at each request for a music recommendation can be formalized as follows: given a start emotional state
and a target emotional state
, the goal is to find the musical trajectory
, which, starting from
,
(i) minimize the distance between
and
, where
is the target emotional state reached after listening
, and
(ii) minimize the length
N of the musical trajectory
. In the following, we propose a Go-Explore-based system to face such a problem. The idea is to recommend music according to the best policy built by such a system. As we will see in
Section 6, a preliminary evaluation study has been conducted to evaluate this approach.
4.3. The Methodology
This section provides details about the methodology followed to build Moodify. First, we will reformulate our decision-making context in terms of MDP. Then, we will describe the main steps of the proposed Go-Explore-based approach.
4.3.1. Induced Emotion-Based Music Recommendation as MDP
In this section, we define the notions of state, action, reward, and transition model.
state: one state corresponds to one specific emotion defined in the circumplex model (
Section 3.1), represented as the pair
where
x and
y are the coordinates in the two-dimensional plane; at each request of recommendation, the user starts with a start state, chooses a target state, and after listening each song reaches a new state.
action: the action space is the set of possible
musical songs; given a current state
and it’s coordinate in the circumplex model
x and
y, our model recommends a song and stores
which are the
acousticness,
danceability,
energy,
instrumentalness,
loudness,
speechness,
tempo, and
valence (see the Spotify audio features in
Table 2); therefore, a recommendation is a tuple
.
reward: as also detailed in the following, in our approach, we adopt a “feedback-based reward”, i.e., after each listening, the user assigns a score (integer in ) which represents the perception of the user on “how much the emotion perceived after the listening is similar to the chosen target emotion”.
We remark that the complexity of the recommendation task of the MDP described above depends on several terms. First, it depends on the number of emotions
described in the circumplex model. As explained in
Section 5, in this preliminary work, we focus on 8 emotional states (see
Figure 3). Furthermore, the complexity also depends on the domains of each Spotify feature described in
Table 2, which represent the parameters that the model changes from time to time to “adapt” the trajectory. Finally, the complexity also depends on the length
N of the trajectory (number of songs)
chosen by the model to reach the target emotional state.
Formally, the complexity of the described MDP is:
where
x, with
is a Spotify audio feature (see
Table 2) and
is the range of
x. However, as discussed in
Section 6, we have evaluated the system’s responsiveness during real-experience time windows. As a result, the involved users positively rated the system’s capability to recommend music in a timely manner.
4.3.2. Step 1: Listen until Solved
The goal is to discover high-performing trajectories in the emotion space, to be improved in Step 2. The result is an archive of different emotional states, named “cells”, and trajectories to follow to reach these states.
This step is organized into several listening sessions. The goal of each session is to find high-performing trajectories for one specific target emotional state chosen by the user. Indeed, at the beginning of the session, the user declares the state he would like to reach at the end of it, i.e., the target emotion he would like to experience after the listening session. At the beginning of each session, the archive only contains the initial emotion selected by the user (start state). From there, the system repeats the following steps: (i) select a cell from the current archive, (ii) explore from that cell location stochastically, i.e., recommend random music and collect feedback from the user after the listening, (iii) add new cells and their trajectory to the archive. Here, we provide details about the cell, state representation, and the reward function based on the feedback the user provided at the end of each listening.
Cell and State Representation
In order to be tractable in high-dimensional state spaces like the emotional space (see
Figure 2), Step 1 of
Moodify reduces the dimensionality of the search space into a significant low-dimensional space. Our idea is to conflate “similar” emotions in terms of musical features required to stimulate them in the user, in the cell representation. To this aim, in our approach, first, we have discretized the emotions space represented by the circumplex model (see
Section 3.1) into a grid in which each cell is
. Then, we decided that each state contains information about a specific emotion and the set of audio features that a music song should have to arouse this emotion.
Selecting and Returning to Cells
Step 1 selects a cell at each iteration. Moodify preferred cells (i) not visited often, (ii) recently used to discover a new cell, and (iii) expected near undiscovered cells. Moodify stores the sequence of musical songs that lead to a cell to avoid added exploration.
Exploration from Cells
Once a cell is reached, Moodify explores the emotion perceived by the user for each of training musical songs randomly selected from Spotify, with a 70% probability of listening to the previous music at each step. After each listening, the user selects the emotion perceived, i.e., the state reached. Then, he assigns a score to the reached state, i.e., an integer value in which represents “how much the emotion perceived after listening to the song is similar/close to a target emotion established at the beginning of the session”. Finally, the audio features of such a state are updated. Formally, let be the start state, and let the audio features of the listened song. Then, if then set , for each . Otherwise, set , for each .
Exploration can be terminated at the end of listening to the selected k training songs limit for exploration or when the user stops the exploration/listening session.
How to Update the Archive
During the exploration of a cell, the archive can be updated in two cases. First, the agent explores a cell not contained in the archive. In this case, details about such a cell are added to the archive, together with some related information: (i) the full “trajectory” (both musical and emotional), in terms of a sequence of state-vectors, to follow for reaching that cell from the starting state; (ii) the current environment state; (iii) the trajectory score; (iv) the trajectory length in terms of the number of listened songs. The second case is when the trajectory is “better” (higher score) than that belonging to a cell already saved the archive.
4.3.3. Step 2: Emotion Robustification
As a result of Step 1,
Moodify collected a set of high-performing trajectories. To make the trajectories robust to any noise, Step 2 creates a policy via
imitation learning. The idea is to build a policy that performs as well as the trajectory discovered during the exploration, but at the same time, it must be able to deal with circumstances not present in the original trajectory. As proposed in [
19], to train the policy, we chose a
Learning from Demonstration algorithm that proved to be able to improve upon its demonstrations, i.e., the
Backward Algorithm [
51]. It works as follows: (i) the agent starts near the trajectory’s last state
t and runs a standard RL algorithm (in our approach, we chose the Q-Learning approach [
46]) from such a state, (ii) when the algorithm has learned to get a better reward than
t, the algorithm repeats the process by starting from a point near to the trajectory and repeats the process, (iii) if for each trajectory form the initial state the agent is able to obtain a better score, then stop the process.
4.3.4. Limitations of the method
At the end of the training, if
are the emotions on which the system has been trained, then Moodify has
N Q-Table available, each of which will be used when the corresponding emotion is used as target emotion. The problem with this approach is that when we face complex environments, such as the emotional space described by the circumplex model shown in
Figure 2, where the number of states and actions can grow, then Q-tables can become unfeasible. As we will see in
Section 5, in this preliminary work, we focused on only 8 emotional states. However, as also highlighted in
Section 7, in future work, we have planned to exploit Deep Q-learning techniques. Such techniques exploit power deep feedforward neural networks for computing Q-value, i.e., to use the output of such neural networks to get new Q-value.
5. MoodifyWeb: The Web Application
We developed a Web application, namely MoodifyWeb, which uses the method described in
Section 4 to enable listening to music songs from Spotify according to target emotions selected by the user. For the development, we used
Vue.js (Available online:
https://vuejs.org/, accessed on 18 October 2022), a JavaScript framework and the Spotify API for developers (Available online:
https://developer.spotify.com/, accessed on 18 October 2022). More details on the architecture and technologies involved are available in
Appendix A.
The typical usage is as follows:
(i) the user accesses the platform by using his/her Spotify credentials or
Moodify’s ones created through a registration form (
Figure 4a);
(ii) once access is obtained, the platform offers the user the screen necessary for selecting his/her current mood (
current emotion), i.e., the emotion currently perceived by the user, and a
target emotion, i.e., the emotion that the user would like to feel after having listened to the song(s) that the system will recommend (
Figure 4b); we remark that, as a preliminary study, currently the platform allows the user to select 8 possible emotional states (see
Figure 3):
energy,
fun,
happiness,
sensuality,
calm,
anxiety, and
anger; once the emotional states have been selected, if the user clicks on the button “Confirm”, then the system uses, given the current emotion, the method described in
Section 4 to select and recommend a song on Spotify (
Figure 4c); specifically, let
E the current emotion selected by the user, the system identifies the corresponding
, and uses
to query a song from Spotify; furthermore, the system allows the user to discard the recommended song and to repeat the query; at the end of the listening, if the user has selected the “training” modality, the emotion selected as feedback is used to train the policy, as described in
Section 4; in addition, this screen provides a section (right-side column) which summarizes several information of the user profile, such as
user name,
email, and
music preferences, i.e., preferred artists, and visualizes statistics about the favorite music genres; by clicking on username on the top of such column, MoodifyWeb proposes a screen to manage the user’s profile (
Figure 4d).
6. Moodify’s Assessment by Users
In this section, we show the preliminary evaluation study performed to evaluate
Moodify in terms of effectiveness and overall user satisfaction, with a methodology already applied in earlier works [
20]. We have recruited 40 participants split among musicians (
) and not musicians (
). Participants used the machines available in our Lab, i.e., desktop computers equipped with Intel i7 quad-core processor and 16 GB RAM DDR3. The participants’ sample was 60% male and 40% female, with a mean age of 24 (Standard Deviation =
). Participants were informed that the information provided remains confidential. In
Table 4, we report further details on the participants.
6.1. Method
The study included several steps: a
Preliminary Step, a
Testing Step, and a
Summary Step, as defined in [
53,
54,
55]. In the
Preliminary Step, participants had to fill in a question-based assignment concerning demographic and background information.
The Testing Step’s goal is to assess the experiences recommended during an
experience time window, including ten
listening sessions. It lasted roughly twenty days, with the longest session, which took two days. During the sessions, participants dealt with MoodifyWeb, thus, giving feedback concerning 3
usability aspects: (i)
“Appropriateness of the music”, which measures the perceived
effectiveness of the system’s behavior (recommended music), (ii)
“User satisfaction”, which measures the satisfaction of the users using your system, (iii)
“System responsiveness”, which measures the responsiveness of the system. Users expressed their feedback by answering question items on a 5-point Likert scale (from “Strongly disagree” to “Strongly agree”).
Lastly, in the
Summary Step, participants had to spend 5 minutes filling out a
confirmation of expectations test [
56]. Furthermore, additional 5 minutes were required to answer a question-based assignment for a two-fold goal: (i) to gather clues on imaginable improvements and (ii) to grasp the perception concerning the participants’ perspectives of long-term usage. The question-based assignment has been administered through a specific functionality offered by MoodifyWeb. For what concerns
confirmation of expectations test—rooted into the
Expectation-confirmation theory (ECT) [
57] – such a test has been exploited to study the users’ perceptions towards the tested system in terms of expectation, acceptance, confirmation, and satisfaction.The whole assessment study with participants lasted three weeks.
6.2. Results
The Preliminary Step’s results led us to outline a profile of the participants involved. Specifically, it sheds light on the users’ habits. Indeed, they have the propensity to listen to music with the aim of experiencing a specific emotion, which in most cases is relaxing (70% answered more than once per day). Moreover, 35% of them have thought to use a specific tool designed for “recommending music” and “taking into account music preferences”. Furthermore, users involved had a high familiarity with a variety of music platforms, such as Spotify and YouTube.
Table 5 shows, for each usability aspect described above, the mean scores concerning the ten separated experiences periods. As it is possible to notice, all sessions were positively rated. Specifically, as for the “Appropriateness of the recommendation”, the best result was obtained in experiences #5, #8, and #10 with an average response of 4.75.
With the aim of strengthening the validation of experiences, the
confirmation of expectations test has been carried out. We measured the expectation level through a 7-point Likert scale with “Strongly disagree” (“1”) and “Strongly agree” (“7”) as verbal anchors [
58]. Responses were provided, also in this case, via MoodifyWeb. Next, we calculated the minimum, maximum, and average scores for participants’ confirmation of expectations, i.e., 4.7, 6.45, and 7, respectively. Lower values mean that participants’ expectations were too high, and so the “recommendation” is worse than expected; conversely, a high value suggests that participants’ expectations were too low, and so the “recommendation” is better than they thought. The value of
confirms the latter for most of the participants:
Moodify recommendations were satisfying with respect to participants’ emotional demands.
Lastly, in the (Summary Step), we gathered suggestions about imaginable enhancements to the music recommendation system. Among the most interesting imaginable enhancements, we found: “It would be interesting to directly integrate Moodify into a plug-in for Spotify", and “It would be interesting to consider on MoodifyWeb other aspects such as the environment in which the user is and/or the activity carried out by the user while listening to music".
7. Conclusions
In the digital age, emotion/mood has become a fundamental criterion used by ICT systems in predicting social behaviors or conditioning people in their social interactions and work activities. In light of this, music systems that regulate mood and emotions in our daily life are arousing particular interest. Therefore, the affective computing research community has put efforts into modeling the relationship between music and emotion.
Applications of affective computing studies can be found in education, health care, entertainment, affective ambient intelligence, multimedia retrieval, and music retrieval and generation. As for the specific musical context, most of these works consist of context-sensitive recommendation tools which take into account the emotional state of the listener. Few results have been obtained in the study of music systems for induction of emotional states, i.e., methods to influence the emotional state of listeners and adapt interaction with technology to their affective state.
In this work, we have employed RL methods for developing Moodify, a novel music recommendation system that can induce a target emotional state in the listener. We implemented Moodify in MoodifyWeb, a Web platform delivered to end-users. The results of an evaluation study carried out with potential end-users proved that our system is useful and satisfactory for all participants involved.
Limitations and Future Works of the Project
There are a series of envisioned steps for the next future of Moodify that we try to summarize as follows. Currently, MoodifyWeb interacts with Spotify by searching specific music tracks and recommending them to the user, but we have planned to directly “incorporate” it in the Spotify interface (e.g., Spotify plug-in). By doing so, the user does not have to switch between MoodifyWeb and Spotify but can use one only integrated application.
Furthermore, we have planned to make
Moodify more extensive by considering other aspects that could influence the listener’s emotion, such as the environment in which the user activity is carried out while listening to music. At the moment, the system is designed to consider only the starting and target emotions. It could be helpful to add more context to the recommendations, as it happens—with some variations—in context-based filtering techniques. This contextual information may come from the ambient and the type of activity the user is involved in, e.g., gym [
20] where the trajectory for inducing a specific emotion could be different than the one used when at home. Of course, this kind of improvement will need extensive study and validation with final stakeholders.
Another future direction is represented by the extension of
Moodify so to collect and analyze users’ behavioral information, e.g., interactions with a mobile or IoT device [
20,
59,
60], to better tailor the songs recommended and include the implicit feedback typical of collaborative filtering mechanisms. Different studies have found a connection between emotions and the way we use smartphones [
61,
62,
63,
64,
65]. Currently, MoodifyWeb always asks for explicit feedback from listeners. Based on the insights coming from the literature, we will extend the system so that the emotions captured from smartphone interaction will provide implicit feedback. For instance, if we capture sadness through the smartphone interaction while listening to a song, MoodifyWeb could avoid asking for explicit feedback and apply the sad emotion to that song, adjusting the RL method’s trajectory appropriately.
Finally, to face the problem of the Q-Learning scaling (see
Section 4.3.4), as a future development, we are going to exploit Deep Q-learning techniques, which utilize the virtues of deep learning with so-called Deep Q-networks, i.e., feed-forward neural networks used for computing Q-value.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}