
An ICS Traffic Classification Based on Industrial Control Protocol Keyword Feature Extraction Algorithm
Abstract
:1. Introduction
2. Related Work
2.1. Traffic Classification Methods Based on ML
2.2. Traffic Classification Methods Based on DL

{kind=link}
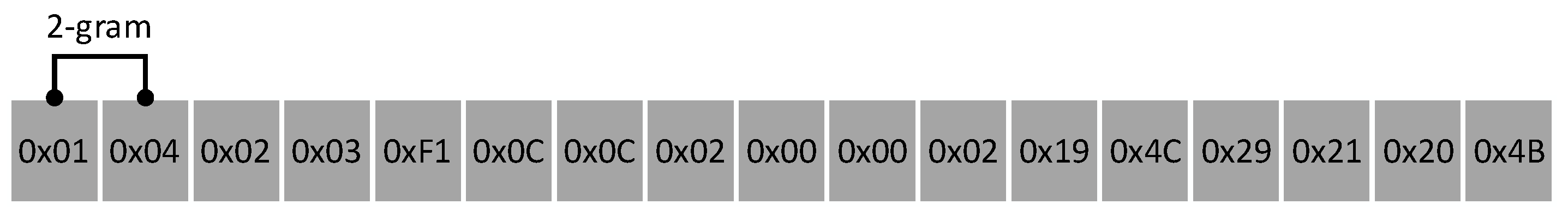{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research | Method | Feature Extraction | Training time | Classification Time | Accuracy |
|---|---|---|---|---|---|
| Literature [13] | ML-based | Manual | 0.31 s | Unknown | 97.2% |
| Literature [14] | ML-based | Manual | Unknown | Unknown | 100% |
| Literature [15] | ML-based | Manual | 104.85 s | 12.75 s | 82.31% |
| Literature [16] | ML-based | Manual | 2.21 s | 0.0505 s | 99% |
| Literature [17] | ML-based | Manual | Unknown | 0.187 s | 99% |
| Literature [18] | DL-based | Automatic | 100 s | Unknown | Unknown |
| Literature [19] | DL-based | Automatic | Unknown | Unknown | 95% |
| Literature [20] | DL-based | Automatic | 54.2 s | 0.185 ms | 98.98% |
| Literature [21] | DL-based | Automatic | 61.31 s | 2.36 s | 99% |
| Literature [22] | DL-based | Automatic | 121.9 min | Unknown | 94% |
| Our method | ML-based | Automatic | 0.34 s | 0.264 s | 99.99% |
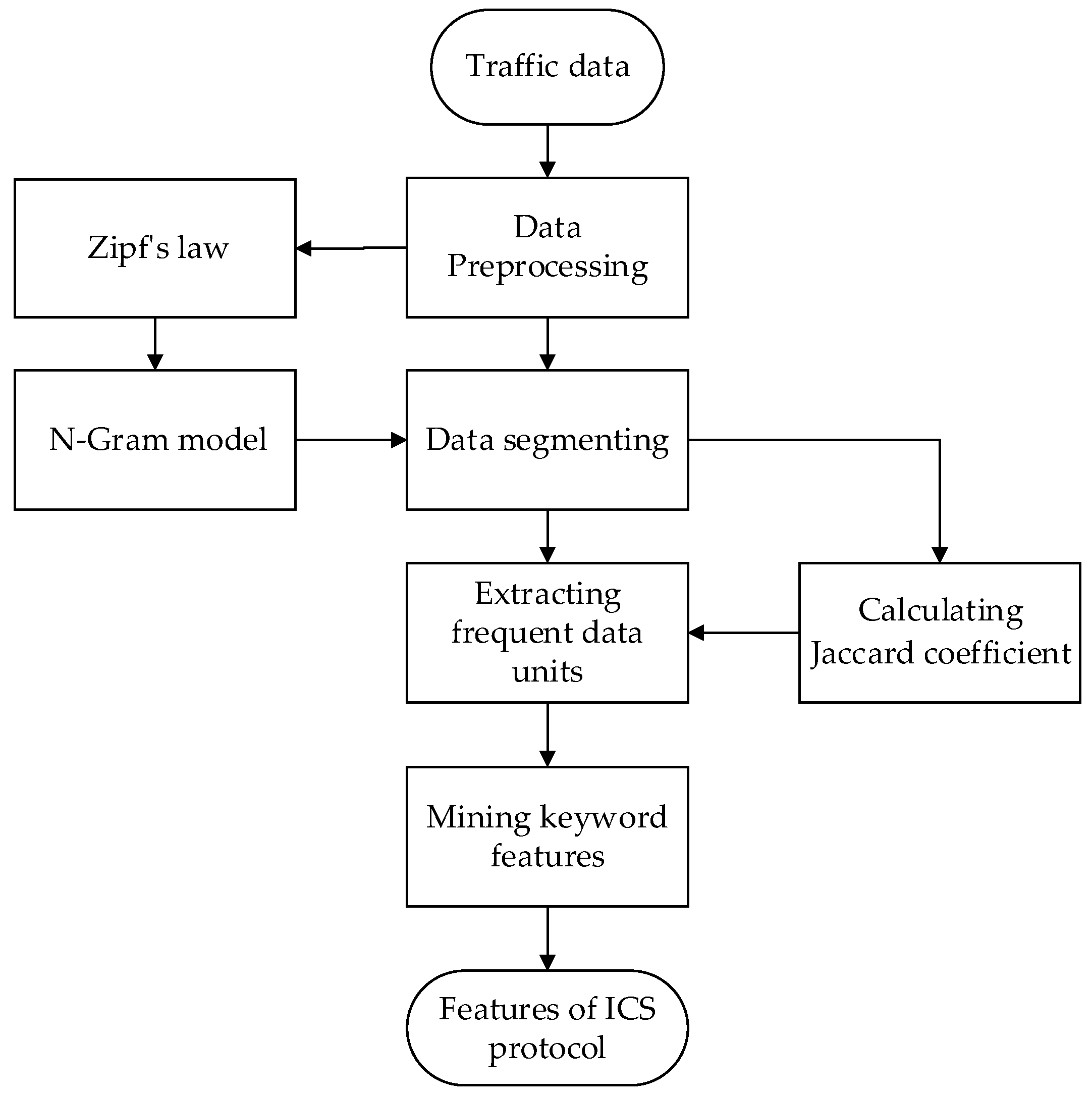
3. Feature Extraction Algorithm for Industrial Control Protocol
3.1. Data Preprocessing
3.2. Protocol Payload Segmentation Based on N-Gram Model
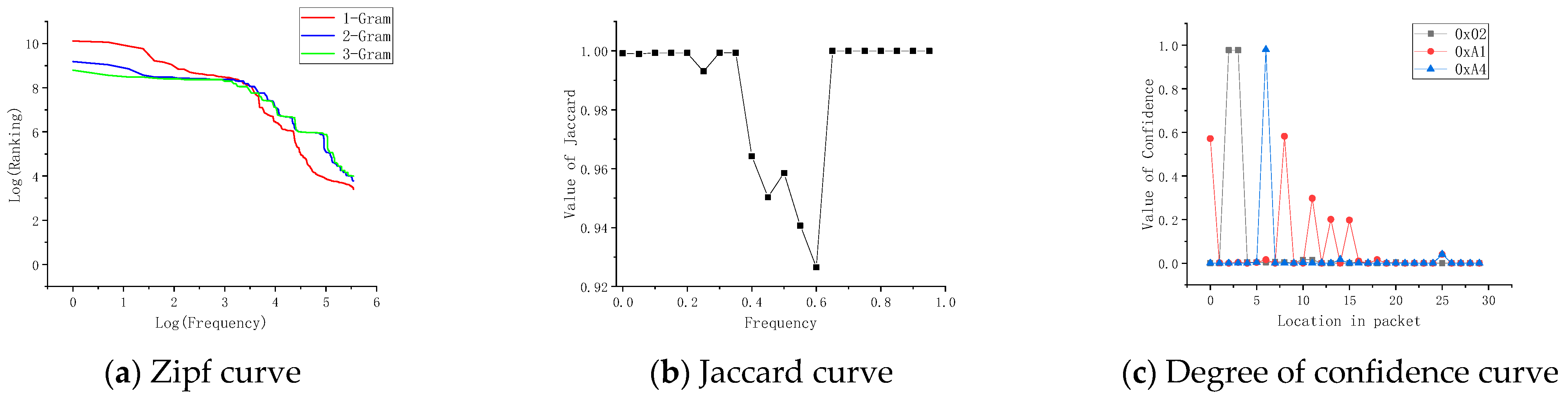
3.3. Frequent Item Extraction Based on Jaccard Coefficient
3.4. Feature Byte Mining Based on Association Rules
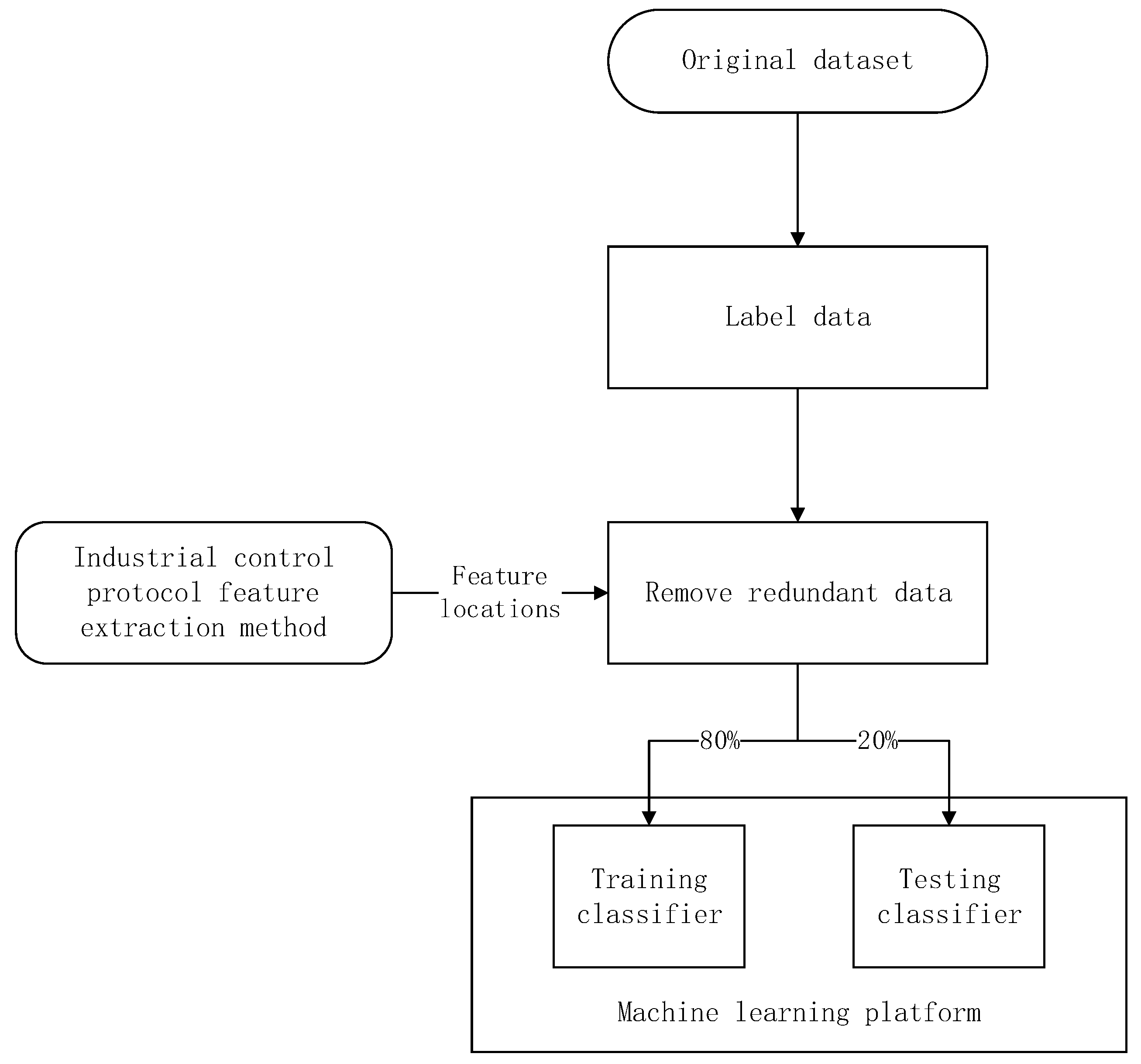
4. Industrial Control Network Traffic Classifier Based on Feature Extraction Dataset
4.1. Classifier Selection Based on Discrete Uncorrelated Features
4.2. Decision Tree Classifier Training and Testing Based on Feature Dataset
5. Experiments and Results
5.1. Experimental Environment
5.2. Dataset Description
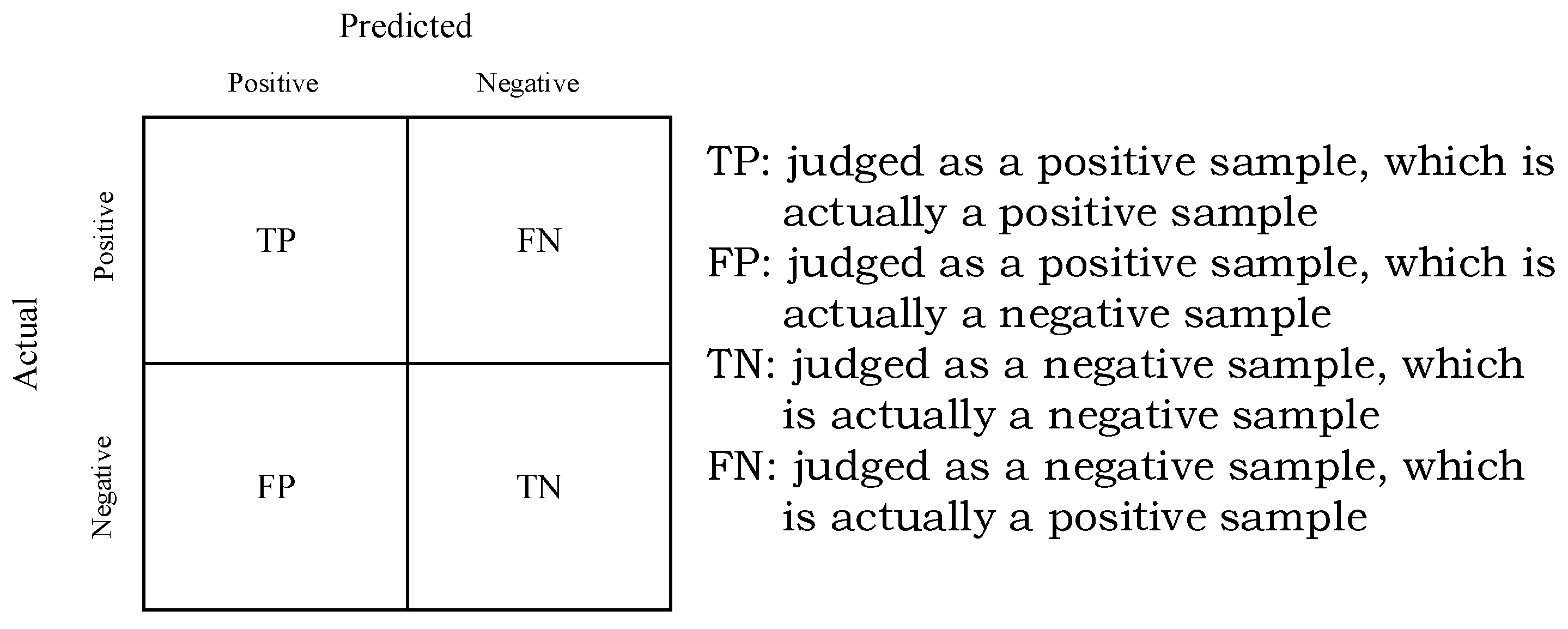
5.3. Classifier Evaluation Metrics
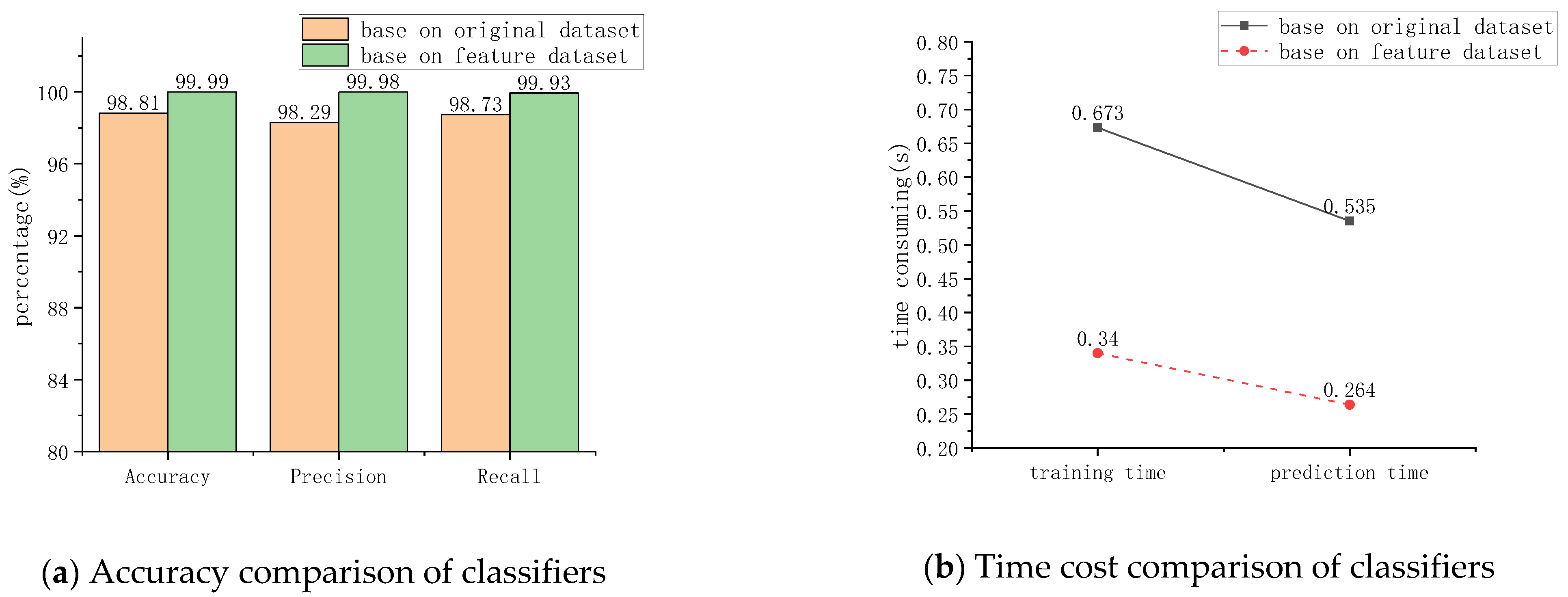
5.4. Results
6. Discussion
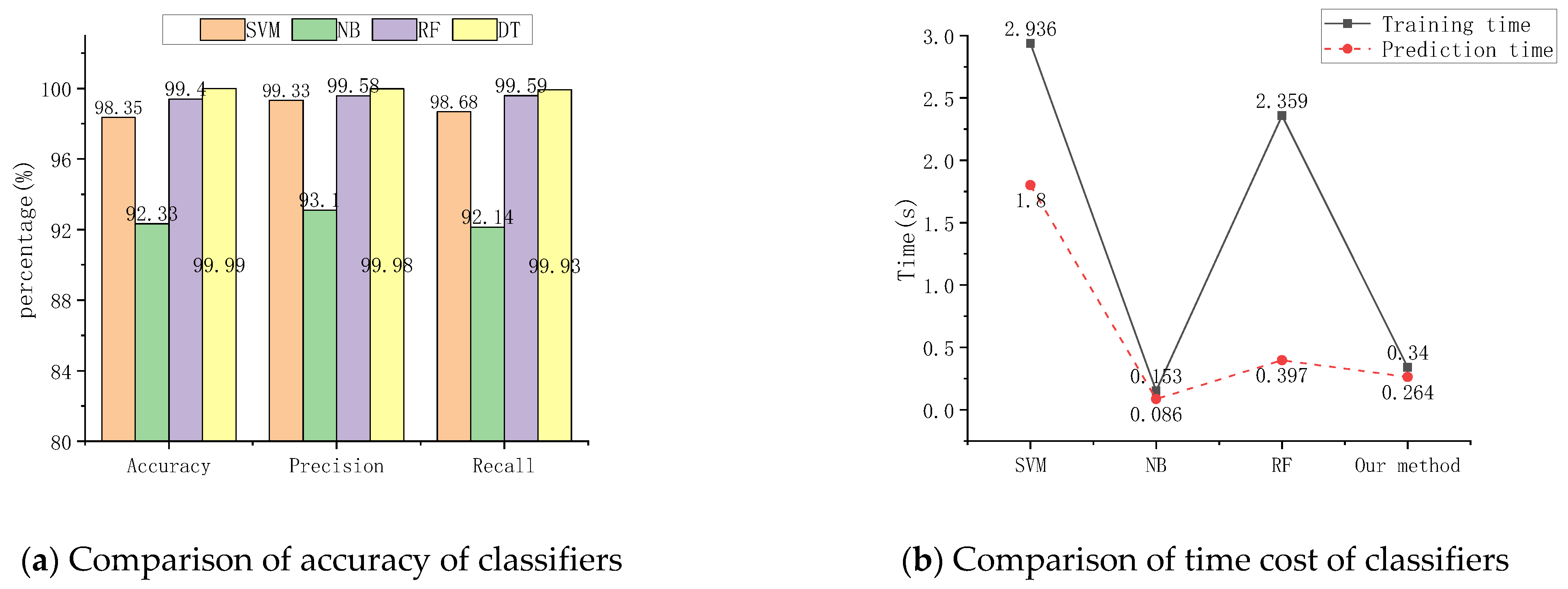
6.1. Classification Effect of Different ML Algorithms
6.2. Classification Effect of Different Methods in the Literature
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| ICS | Industrial control system |
| SCADA | Supervisory control and data acquisition |
| DPI | Deep packet inspection |
| ML | Machine learning |
| DL | Deep learning |
| TCP/IP | Transmission control protocol/internet protocol |
| SVM | Support vector machines |
| NB | Naive bayes |
| RF | Random forest |
| DT | Decision tree |
References
- Zhou, S.; Wang, S.J. Research on classificati-on method of private industrial control protocol. Inf. Technol. Netw. Secur. 2021, 40, 19–24. [Google Scholar]
- Dainotti, A.; Pescape, A.; Claffy, K.C. Issues and future directions in traffic classification. IEEE Netw. 2012, 26, 35–40. [Google Scholar] [CrossRef] [Green Version]
- Moore, A.W.; Papagiannaki, K. Toward the accurate identification of network applications. In Proceedings of the International Workshop on Passive and Active Network Measurement, Boston, MA, USA, 31 March–1 April 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 41–54. [Google Scholar]
- Khandait, P.; Hubballi, N.; Mazumdar, B. Efficient keyword matching for deep packet inspection based network traffic classification. In Proceedings of the 2020 International Conference on COMmunication Systems & NETworkS (COMSNETS), Bangalore, India, 7–11 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 567–570. [Google Scholar]
- Gu, Y.; Li, D.; Gao, K.H. Research on network traffic classification based on machine learning and deep learning. Telecommun. Sci. 2021, 37, 105–113. [Google Scholar]
- Pacheco, F.; Exposito, E.; Gineste, M.; Baudoin, C.; Aguilar, J. Towards the deployment of machine learning solutions in network traffic classification: A systematic survey. IEEE Commun. Surv. Tutor. 2018, 21, 1988–2014. [Google Scholar] [CrossRef] [Green Version]
- Dong, S. Multi class SVM algorithm with active learning for network traffic classification. Expert Syst. Appl. 2021, 176, 114885. [Google Scholar] [CrossRef]
- Li, J.; Pan, Z. Network traffic classification based on deep learning. KSII Trans. Internet Inf. Syst. (TIIS) 2020, 14, 4246–4267. [Google Scholar]
- Shapira, T.; Shavitt, Y. FlowPic: A generic representation for encrypted traffic classification and applications identification. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1218–1232. [Google Scholar] [CrossRef]
- Wang, X.; Lv, K.; Li, B. IPART: An automatic protocol reverse engineering tool based on global voting expert for industrial protocols. Int. J. Parallel Emergent Distrib. Syst. 2020, 35, 376–395. [Google Scholar] [CrossRef]
- Ni, J.; Yin, W.; Jiang, Y.; Zhao, J.; Hu, Y. Periodic mining of traffic information in industrial control networks. In Proceedings of the International Conference on Advanced Information Networking and Applications, Caserta, Italy, 15–17 April 2020; Springer: Cham, Switzerland, 2020; pp. 176–183. [Google Scholar]
- Nguyen, T.T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv. Tutor. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Cao, J.; Wang, D.; Qu, Z.; Sun, H.; Li, B.; Chen, C.-L. An Improved Network Traffic Classification Model Based on a Support Vector Machine. Symmetry 2020, 12, 301. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.R.; Chen, Y.T. Industrial Control System Anomaly Detection and Classification Based on Network Traffic. IEEE Access 2022, 10, 41874–41888. [Google Scholar] [CrossRef]
- Aouedi, O.; Piamrat, K.; Parrein, B. Performance evaluation of feature selection and tree-based algorithms for traffic classification. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Mokhtari, S.; Abbaspour, A.; Yen, K.K.; Sargolzaei, A. A machine learning approach for anomaly detection in industrial control systems based on measurement data. Electronics 2021, 10, 407. [Google Scholar] [CrossRef]
- Lan, H.; Zhu, X.; Sun, J.; Li, S. Traffic data classification to detect man-in-the-middle attacks in industrial control system. In Proceedings of the 2019 6th International Conference on Dependable Systems and Their Applications (DSA), Harbin, China, 3–6 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 430–434. [Google Scholar]
- Ling, J.; Zhu, Z.; Luo, Y.; Wang, H. An intrusion detection method for industrial control systems based on bidirectional simple recurrent unit. Comput. Electr. Eng. 2021, 91, 107049. [Google Scholar] [CrossRef]
- Lin, K.; Xu, X.; Gao, H. TSCRNN: A novel classification scheme of encrypted traffic based on flow spatiotemporal features for efficient management of IIoT. Comput. Netw. 2021, 190, 107974. [Google Scholar] [CrossRef]
- Ren, X.; Gu, H.; Wei, W. Tree-RNN: Tree structural recurrent neural network for network traffic classification. Expert Syst. Appl. 2021, 167, 114363. [Google Scholar] [CrossRef]
- Mendonca, R.V.; Silva, J.C.; Rosa, R.L.; Saadi, M.; Rodriguez, D.Z.; Farouk, A. A lightweight intelligent intrusion detection system for industrial internet of things using deep learning algorithms. Expert Syst. 2022, 39, e12917. [Google Scholar] [CrossRef]
- Zhai, L.; Zheng, Q.; Zhang, X.; Hu, H.; Yin, W.; Zeng, Y.; Wu, T. Identification of Private ICS Protocols Based on Raw Traffic. Symmetry 2021, 13, 1743. [Google Scholar] [CrossRef]
- Dai, H.; Li, H.; Chen, C.S.; Shang, W.; Chen, T.H. Logram: Efficient log parsing using N-Gram dictionaries. IEEE Trans. Softw. Eng. 2022, 48, 879–892. [Google Scholar] [CrossRef]
- Lei, Q.; Li, H.; Wei, R. Leveraging Zipf’s Law to Analyze Statistical Distribution of Chinese Corpus. In Proceedings of the 2021 IEEE International Conference on Software Engineering and Artificial Intelligence (SEAI), Xiamen, China, 11–13 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Yu, T.T.; Xu, P.N.; Jiang, Y.E. Text similarity method based on the improved Jaccard coefficient. Comput. Syst. Appl. 2017, 26, 137–142. [Google Scholar]
- Cui, Y.; Bao, Z.Q. Survey of association rule mining. Appl. Ions Res. Comput. 2016, 33, 330–334. [Google Scholar]
- Charbuty, B.; Abdulazeez, A. Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Mathur, A.P.; Tippenhauer, N.O. SWaT: A water treatment testbed for research and training on ICS security. In Proceedings of the 2016 International Workshop on Cyber-Physical Systems for Smart Water Networks (CySWater), Vienna, Austria, 11 April 2016; pp. 31–36. [Google Scholar]
- Singapore University of Technology and Design (SUTD). Electric Power and Intelligent Control (EPIC) Testbed. Available online: https://itrust.sutd.edu.sg/itrust-labs-home/itrust-labs_epic/ (accessed on 13 January 2021).








| ******document content****** |
| [‘01’, ‘04’, ‘02’, ‘03’, ‘F1’, ‘0C’, ‘0C’, ‘02’, ‘00’, ‘00’, ‘02’, ‘19’, ‘4C’, ‘29’, ‘21’, ‘20’, ‘4B’, …] [‘01’, ‘00’, ‘30’, ‘F1’, ‘0C’, ‘0C’, ‘02’, ‘00’, ‘00’, ‘02’, ‘19’, ‘4C’, ‘29’, ‘21’, ‘3E’, ‘C4’, ‘01’, …] [‘01’, ‘04’, ‘02’, ‘03’, ‘F2’, ‘0C’, ‘0C’, ‘02’, ‘00’, ‘00’, ‘02’, ‘19’, ‘4C’, ‘29’, ‘22’, ‘08’, ‘87’, …] [‘01’, ‘00’, ‘30’, ‘F2’, ‘0C’, ‘0C’, ‘02’, ‘00’, ‘00’, ‘02’, ‘19’, ‘4C’, ‘29’, ‘22’, ‘3E’, ‘C4’, ‘01’, …] … |
| Protocol Message Type | Subsequent Data Length | Frame Start Flag |
|---|---|---|
| 1 Bytes | 1 Byte | 2 Bytes |
| invoke id | Service type | subsequent data length |
| 2 Bytes | 1 Byte | 1 Byte |
| content | ||
| Accumulated data of tag–length–value | ||
| Dataset | Number of Samples | Number of Features | Data Memory |
|---|---|---|---|
| Feature dataset | 140,000 | 13 | 7.28 MB |
| Original dataset | 140,000 | 50 | 28 MB |
| Protocol Category | Precision | Recall |
|---|---|---|
| IEC 61850-MMS | 98.26% | 98.95% |
| Ethernet/IP | 98.31% | 98.52% |
| Protocol Category | Precision | Recall |
|---|---|---|
| IEC 61850-MMS | 100% | 99.87% |
| Ethernet/IP | 99.96% | 99.98% |
| Protocol Category | Precision | Recall |
|---|---|---|
| IEC 61850-MMS | 99.26% | 98.95% |
| Ethernet/IP | 99.40% | 98.01% |
| Protocol Category | Precision | Recall |
|---|---|---|
| IEC 61850-MMS | 92.26% | 92.27% |
| Ethernet/IP | 93.94% | 92.01% |
| Protocol Category | Precision | Recall |
|---|---|---|
| IEC 61850-MMS | 99.26% | 98.95% |
| Ethernet/IP | 99.99% | 99.23% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, C.; Zhang, Z.; Gao, M. An ICS Traffic Classification Based on Industrial Control Protocol Keyword Feature Extraction Algorithm. Appl. Sci. 2022, 12, 11193. https://doi.org/10.3390/app122111193
Yu C, Zhang Z, Gao M. An ICS Traffic Classification Based on Industrial Control Protocol Keyword Feature Extraction Algorithm. Applied Sciences. 2022; 12(21):11193. https://doi.org/10.3390/app122111193
Chicago/Turabian StyleYu, Changhong, Ze Zhang, and Ming Gao. 2022. "An ICS Traffic Classification Based on Industrial Control Protocol Keyword Feature Extraction Algorithm" Applied Sciences 12, no. 21: 11193. https://doi.org/10.3390/app122111193