
Uncertainty-Controlled Remaining Useful Life Prediction of Bearings with a New Data-Augmentation Strategy

Abstract
:1. Introduction
- (1)
- A data augmentation method based on degradation process modeling and Sobol sampling augments the run-to failure training data;
- (2)
- A new loss function for the Wiener–LSTM model is proposed, and the Wiener process is introduced into the LSTM network to control the uncertainty.
2. Problem Statement
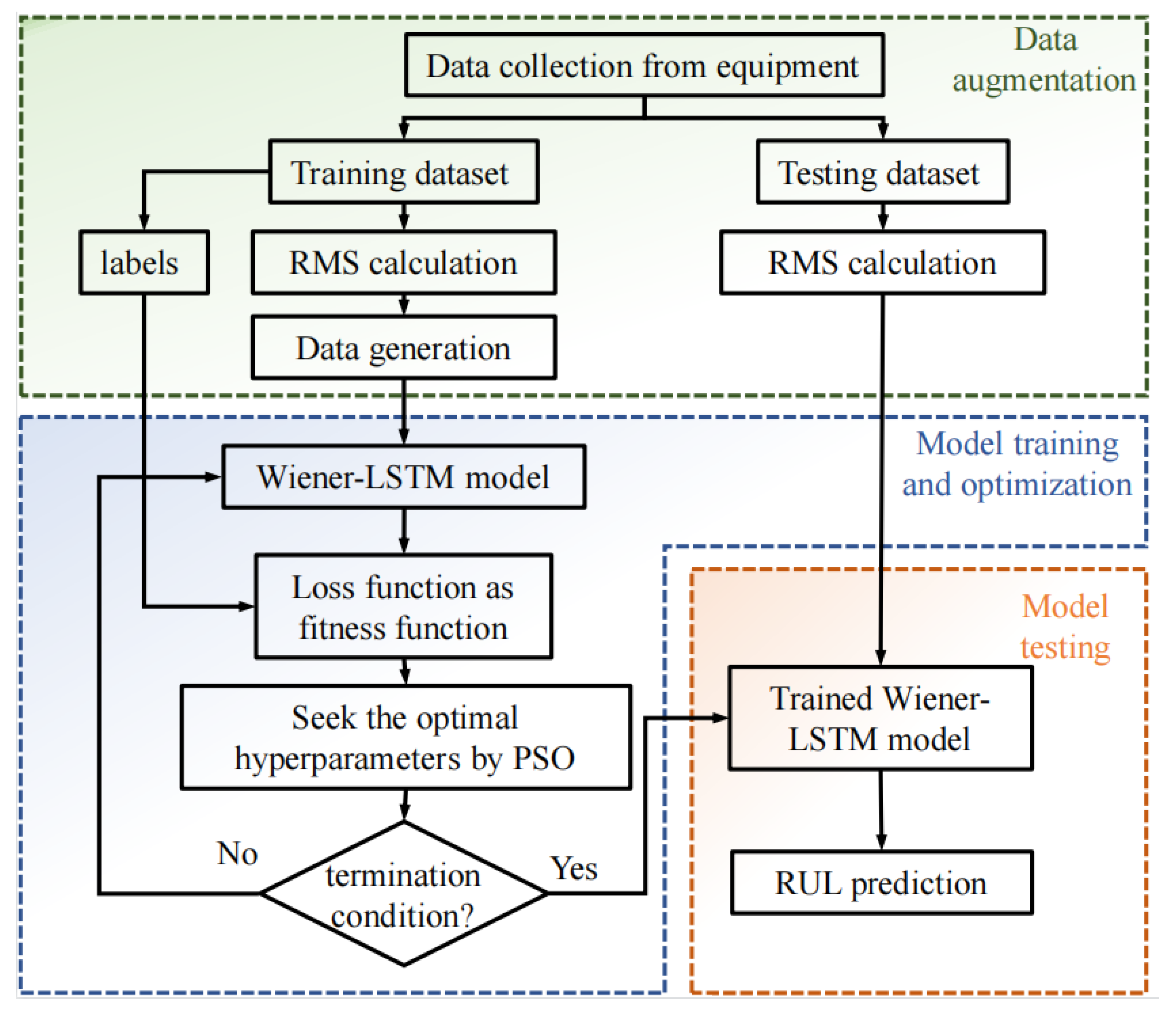
3. Uncertainty-Controlled Remaining Useful Life Prediction with a Data Augmentation Strategy
3.1. Data Augmentation Based on Degradation Modeling and Sobol Sampling
- (1)
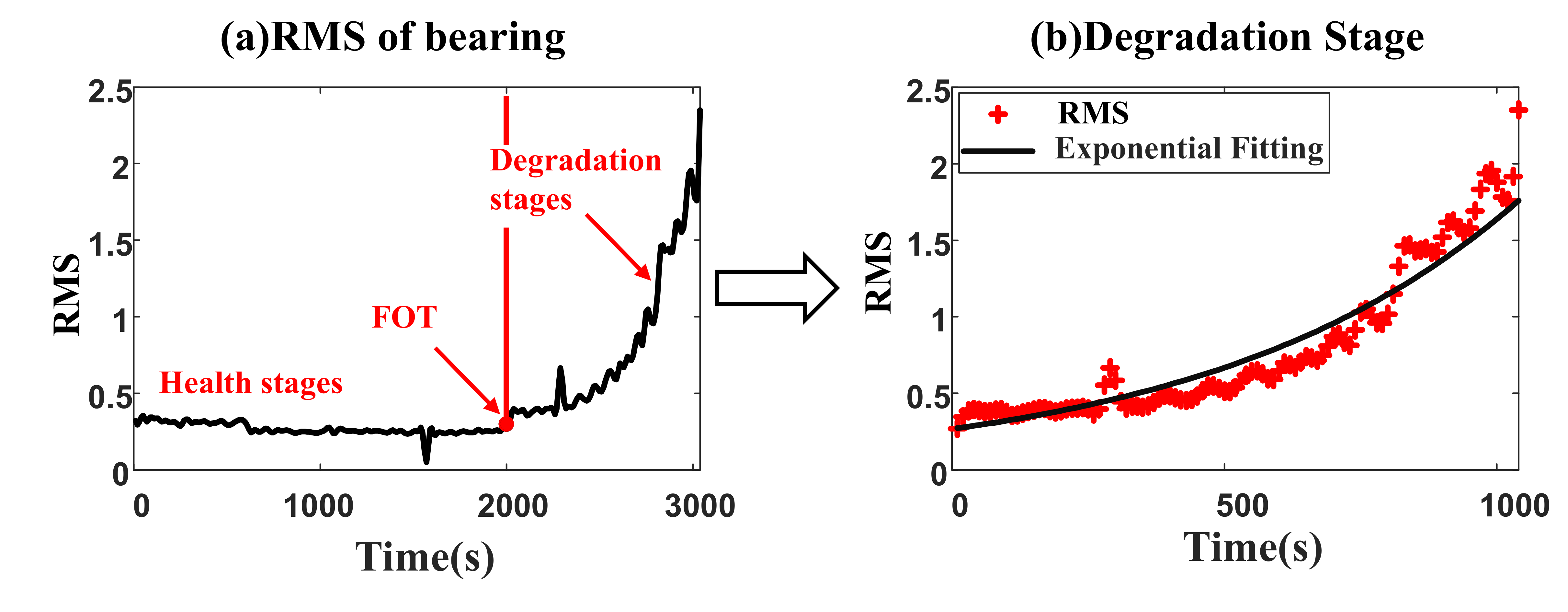
- Degradation modeling is the first step. The RMS is a commonly used time-domain feature, which can reflect the degradation process. Thus, the RMS of the monitored bearing is chosen as the health indicator. The RMS of the whole life bearing signal is shown in Figure 2a, which can be divided into two different stages [36]. The bearing is in the health stage at an early time. RUL prediction is not necessary for this stage because RMS value in the health stage shows a smooth trend. At the Fault Occurrence Time (FOT), the bearing gets into the degradation stage. The degradation can be modeled aswhere the is the FOT, it is a random variable because different bearing has different FOT. When , the bearing is in the healthy stage. The m is a normal random variable representing a stable level of normal bearing health. The is a noise variance in this healthy stage. , in is independent at different time. RUL prediction often starts from FOT to the failure time, which means the stage is always used for RUL prediction. At this stage, a is a log-normal random variable representing the magnitude of the exponential degradation trend. b is a normal random variable representing the slope of the exponentially degenerate trend. e is the noise variance in the degradation process. If there are N number of vibration signal data at each sampling point as . In [37], commonly used health indicators in residual useful life prediction are root mean square (RMS), kurtosis, peak value, and so on. The RMS is a commonly used indicator to describe the degradation trends of bearings, due to its ability to reflect the vibration energy characteristics with robustness. In [38], it is also stated that the RMS indicator is a commonly used indicator in the machinery fault diagnosis and remaining useful life prediction. The RMS is chosen as the indicator in the proposed method, and the unit of RMS is ‘g’. The RMS of the vibration signal is calculated firstly as the health indicator aswhere is the signal in the sampling point. is the mean of the signal recorded from 0–N. The FOT of the RMS is then calculated using the laida criterion, also known as the 3 rules. The RMS health stage mean and standard deviation are calculated. The first value, which exceeds 3 is assumed as the FOT. Then the data from FOT to failure are collected and prepared for the next step.
- (2)
- Since the RUL prediction is not necessary for the stage . The model fitting is implemented only in the stage to acquire the parameters a, b, and e in Equation (6). The follows a normal distribution, which can not be fitted in this process. All the training samples are fitted by the function of the degradation model. Different parameters are acquired after fitting different samples. If there are M run-to-failure data, M sets of parameters of and e can be acquired after the model fitting on the M run-to-failure datasets. Among these sets of parameters, the maximum and minimum values should be chosen. Ranges of each parameter can be recorded as , and .
- (3)
- The Sobol sequence sampling is used to get different combinations of parameters. Random sampling algorithms are quasi-random and limited to one period. When the cycle is exceeded the period, they are repeated and are no longer mutually independent random numbers. Sobol sequences sampling method focus on producing uniform distributions in the probability space compared with the random sampling method. Localized clustering can be avoided in this way. As one of the low deviation sequences, Sobol sequence sampling is superior to other low deviation sequences. The random numbers generated afterward will be distributed to the areas that were not previously sampled. A set of independent parameters can be acquired after one Sobol sequence sampling among the ranges of , and . The algorithm of Sobol sequence sampling is as follows.Consider i random data are generated in the range of . follows the normal distribution. A non-integrable polynomial can be constructed aswhere the n is the highest order. The is the coefficients of the polynomial. The direction value can be acquired aswhere the ⊕ is binary logic operation. ⌊⌋ is the rounding down operation. The random data can be based on the direction value aswhere the is the binary representation of i. After the Sobol sequence sampling operation is implemented on the ranges of parameters , and e. i sets of parameters of the degradation model can be acquired.
- (4)
- Now, i sets of parameters sampled in the last step are substitute to the degradation model function in Equation 6 again without to get i new run-to-failure data asthe rand noise is added in the new sample to imitate the random shock in the working situation in the last step. The i run-to-failure data are prepared and can be sent to the Wiener–LSTM model for the training process.

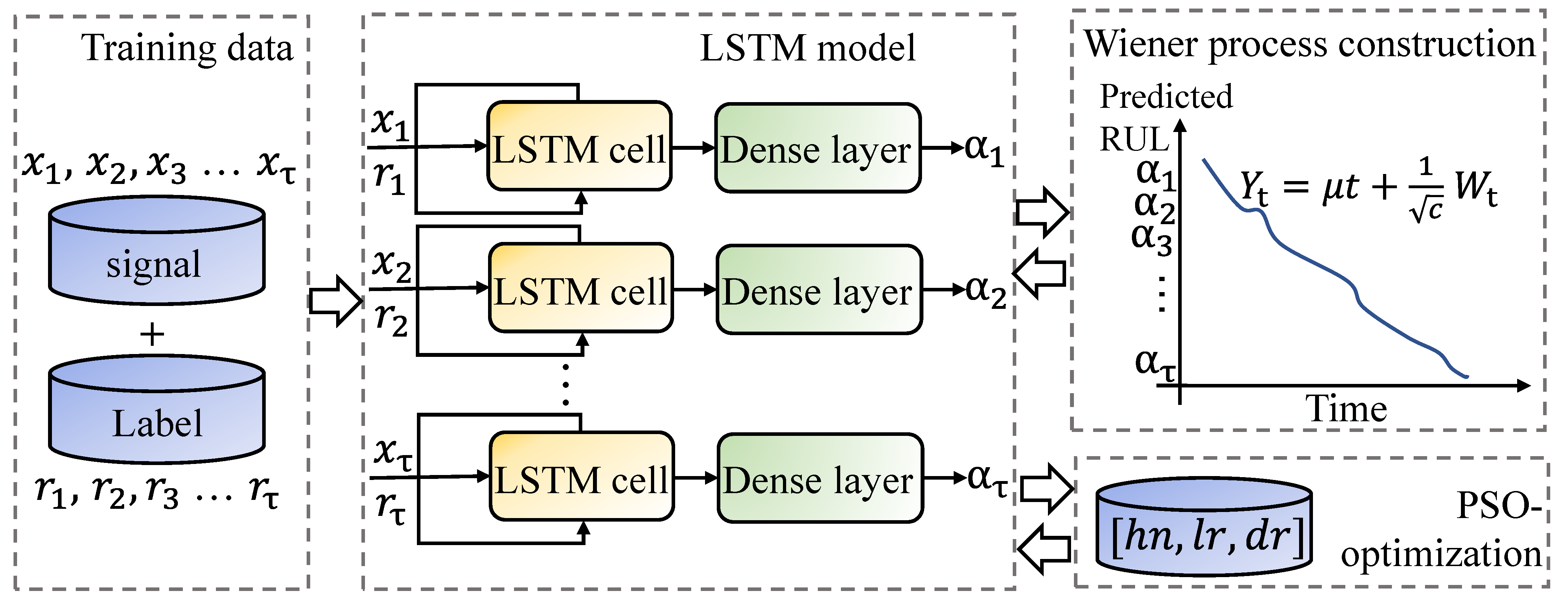
3.2. Wiener–LSTM Bearing RUL Prediction Model
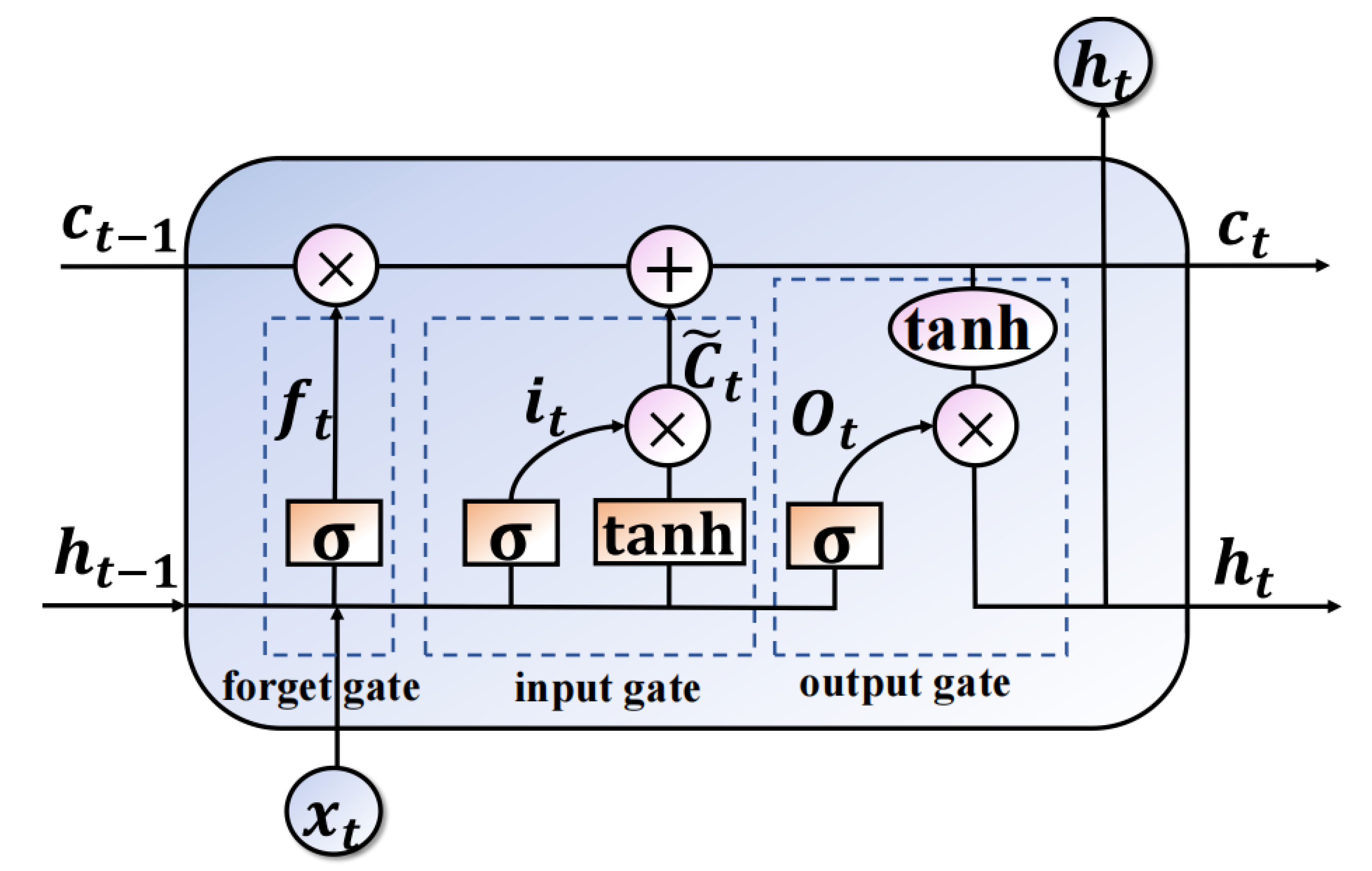
3.2.1. Forward Propagation of the LSTM
3.2.2. The Wiener–LSTM Model with Joint Optimization Loss Function
3.2.3. Optimization of the Hyperparameters by PSO Algorithm
- Step 1: Parameter initialization. The particle dimension, population size, iterations, learning factors, inertia weight, velocity, and position are determined.
- Step 2: Initialize the particle positions and velocities, then generate population particle () at random.
- Step 3: The loss function in Equation (23) is chosen to be the fitness function in the PSO algorithm here. The particle position and velocity are updated by epoch. The extreme individual value and extreme global value are then updated by computing the fitness value in accordance with the new situation.
- Step 4: Judge whether the termination conditions are met. If satisfied, the algorithm ends and outputs the optimization result (); otherwise, return to Step 1.

4. Experiment
4.1. Data Description
4.2. Data Generation Based on the Degradation Model and Sobol Sampling
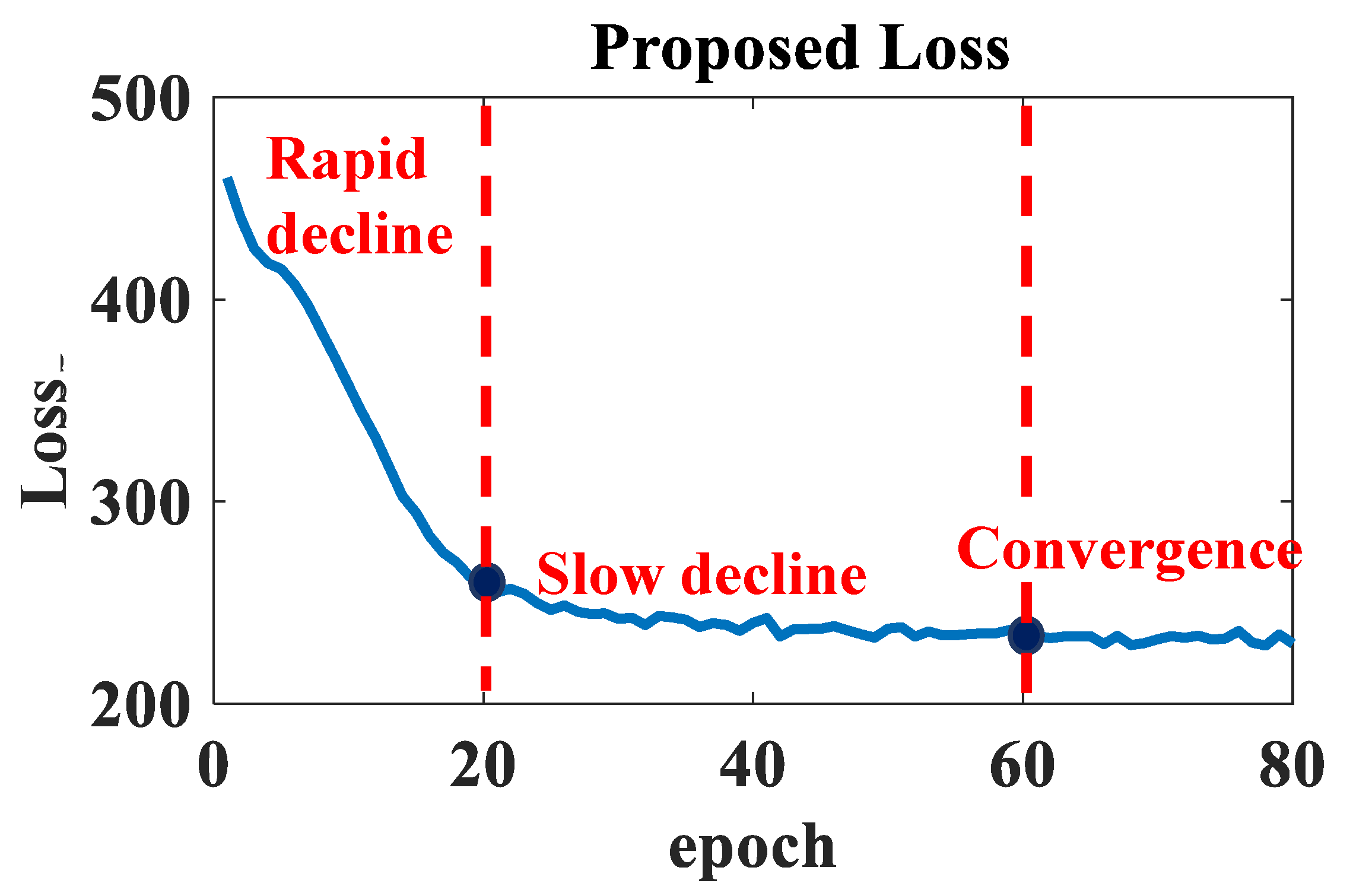
4.3. Wiener–LSTM Training and Optimization
| Algorithm 1: Down-sample algorithm based on mini-batch |
| Input: Training data X, corresponding RUL r, epoch of training process I |
| 1: initialization and c of the network. |
| 2: If i < I |
| 3: are under-sampled on training data X. |
| 4: Update parameter c by Equation (22) |
| 5: Update parameter by random gradient descent algorithm by the loss function in Equation (23) |
| 6: End |
| 7: return (, )=argmin(log(loss(, c, X))). |
| Output:, |
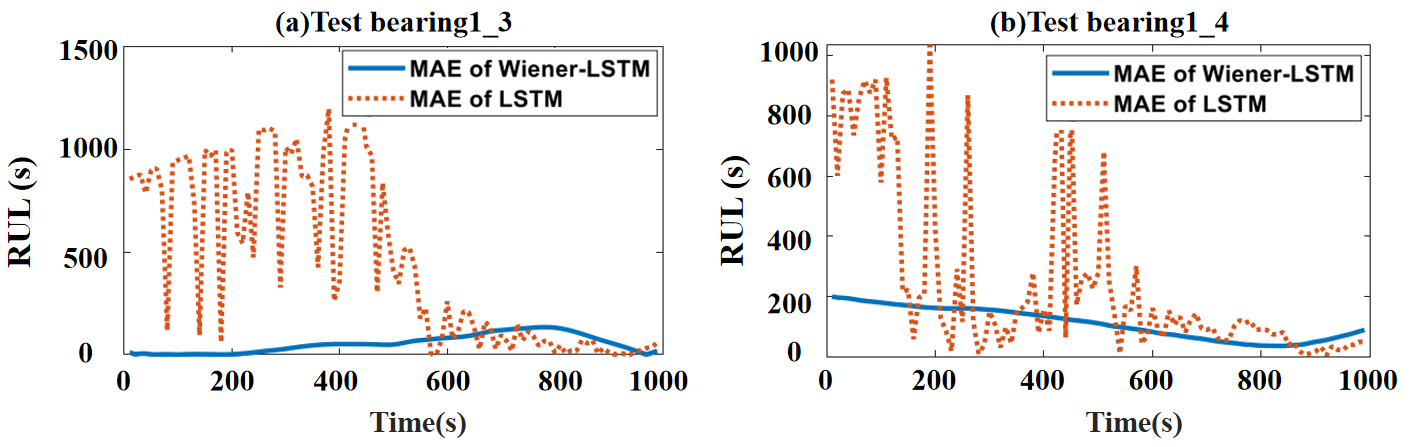
4.4. Results and Discussions
4.4.1. Comparison 1
4.4.2. Comparison 2
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ueda, M.; Wainwright, B.; Spikes, H.; Kadiric, A. The effect of friction on micropitting. Wear 2022, 488–489, 204130. [Google Scholar] [CrossRef]
- Ambrożkiewicz, B.; Syta, A.; Gassner, A.; Georgiadis, A.; Litak, G.; Meier, N. The influence of the radial internal clearance on the dynamic response of self-aligning ball bearings. Mech. Syst. Signal Process. 2022, 171, 108954. [Google Scholar] [CrossRef]
- Sahu, P.K. Grease Contamination Detection in the Rolling Element Bearing Using Deep Learning Technique. Int. J. Mech. Eng. Robot. 2022, 11, 275–280. [Google Scholar] [CrossRef]
- Xie, Z.; Jiao, J.; Yang, K.; He, T.; Chen, R.; Zhu, W. Experimental and numerical exploration on the nonlinear dynamic behaviors of a novel bearing lubricated by low viscosity lubricant. Mech. Syst. Signal Process. 2023, 182, 109349. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Shen, C. A new data-driven transferable remaining useful life prediction approach for bearing under different working conditions. Mech. Syst. Signal Process. 2020, 139, 106602. [Google Scholar] [CrossRef]
- Zhang, Z.X.; Si, X.S.; Hu, C.; Lei, Y. Degradation Data Analysis and Remaining Useful Life Estimation: A Review on Wiener-Process-Based Methods. Eur. J. Oper. Res. 2018, 271, 775–796. [Google Scholar] [CrossRef]
- Liao, G.; Yin, H.; Chen, M.; Lin, Z. Remaining useful life prediction for multi-phase deteriorating process based on Wiener process. Reliab. Eng. Syst. Saf. 2021, 207, 107361. [Google Scholar] [CrossRef]
- Wang, H.; Liao, H.; Ma, X.; Bao, R. Remaining Useful Life Prediction and Optimal Maintenance Time Determination for a Single Unit Using Isotonic Regression and Gamma Process Model. Reliab. Eng. Syst. Saf. 2021, 210, 107504. [Google Scholar] [CrossRef]
- Lin, C.P.; Ling, M.H.; Cabrera, J.; Yang, F.; Yu, D.Y.W.; Tsui, K.L. Prognostics for lithium-ion batteries using a two-phase gamma degradation process model. Reliab. Eng. Syst. Saf. 2021, 214, 107797. [Google Scholar] [CrossRef]
- Du, W.; Hou, X.; Wang, H. Time-Varying Degradation Model for Remaining Useful Life Prediction of Rolling Bearings under Variable Rotational Speed. Appl. Sci. 2022, 12, 4044. [Google Scholar] [CrossRef]
- Song, K.; Cui, L. A common random effect induced bivariate gamma degradation process with application to remaining useful life prediction. Reliab. Eng. Syst. Saf. 2022, 219, 108200. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y.; Zi, Y. Switching State-Space Degradation Model With Recursive Filter/Smoother for Prognostics of Remaining Useful Life. IEEE Trans. Ind. Inform. 2019, 15, 822–832. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, J.; Cheng, Y.; Wang, J.; Hu, K. Memory-enhanced hybrid deep learning networks for remaining useful life prognostics of mechanical equipment. Measurement 2022, 187, 110354. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Li, N. A Hybrid Prognostics Approach for Estimating Remaining Useful Life of Rolling Element Bearings. IEEE Trans. Reliab. 2020, 69, 401–412. [Google Scholar] [CrossRef]
- Soualhi, A. Bearing Health Monitoring Based on Hilbert–Huang Transform, Support Vector Machine, and Regression. IEEE Trans. Instrum. Meas. 2014, 64, 52–62. [Google Scholar] [CrossRef] [Green Version]
- Chelmiah, E.T.; McLoone, V.I.; Kavanagh, D.F. Remaining Useful Life Estimation of Rotating Machines through Supervised Learning with Non-Linear Approaches. Appl. Sci. 2022, 12, 4136. [Google Scholar] [CrossRef]
- Di Maio, F.; Tsui, K.L.; Zio, E. Combining Relevance Vector Machines and exponential regression for bearing residual life estimation. Mech. Syst. Signal Process. 2012, 31, 405–427. [Google Scholar] [CrossRef]
- Wang, Q.; Kun, X.; Kong, X.; Huai, T. A linear mapping method for predicting accurately the RUL of rolling bearing. Measurement 2021, 176, 109127. [Google Scholar] [CrossRef]
- Ye, Z.; Zhang, Q.; Shao, S.; Niu, T.; Zhao, Y. Rolling Bearing Health Indicator Extraction and RUL Prediction Based on Multi-Scale Convolutional Autoencoder. Appl. Sci. 2022, 12, 5747. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, W.; Yang, X.; Zhang, S. RUL Prediction of Rolling Bearings Based on a DCAE and CNN. Appl. Sci. 2021, 11, 1516. [Google Scholar] [CrossRef]
- Yoo, Y.; Baek, J.G. A Novel Image Feature for the Remaining Useful Lifetime Prediction of Bearings Based on Continuous Wavelet Transform and Convolutional Neural Network. Appl. Sci. 2018, 8, 1102. [Google Scholar] [CrossRef] [Green Version]
- Jiang, G.; Zhou, W.; Chen, Q.; He, Q.; Xie, P. Dual residual attention network for remaining useful life prediction of bearings. Measurement 2022, 199, 111424. [Google Scholar] [CrossRef]
- Yang, B.; Liu, R.; Zio, E. Remaining Useful Life Prediction Based on A Double-Convolutional Neural Network Architecture. IEEE Trans. Ind. Electron. 2019, 66, 9521–9530. [Google Scholar] [CrossRef]
- Chen, D.; Qin, Y.; Wang, Y.; Zhou, J. Health indicator construction by quadratic function-based deep convolutional auto-encoder and its application into bearing RUL prediction. ISA Trans. 2020, 114, 44–56. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Yuan, Q. A novel deep learning scheme for multi-condition remaining useful life prediction of rolling element bearings. J. Manuf. Syst. 2021, 61, 450–460. [Google Scholar] [CrossRef]
- Xiang, S.; Qin, Y.; Zhu, C.; Wang, Y.; Chen, H. LSTM networks based on attention ordered neurons for gear remaining life prediction. ISA Trans. 2020, 106, 343–354. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Ding, Y.; Wang, Z.; Wang, C.; Ma, J.; Lu, C. An interpretable data augmentation scheme for machine fault diagnosis based on a sparsity-constrained generative adversarial network. Expert Syst. Appl. 2021, 182, 115234. [Google Scholar] [CrossRef]
- Pan, Y.; Jing, Y.; Wu, T.; Kong, X. Knowledge-based data augmentation of small samples for oil condition prediction. Reliab. Eng. Syst. Saf. 2022, 217, 108114. [Google Scholar] [CrossRef]
- Liu, S.; Chen, J.; He, S.; Xu, E.; Lv, H.; Zhou, Z. Intelligent fault diagnosis under small sample size conditions via Bidirectional InfoMax GAN with unsupervised representation learning. Knowl. Based Syst. 2021, 232, 107488. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, C.; Jiang, X. Imbalanced fault diagnosis of rolling bearing using improved MsR-GAN and feature enhancement-driven CapsNet. Mech. Syst. Signal Process. 2022, 168, 108664. [Google Scholar] [CrossRef]
- Behera, S.; Misra, R. Generative adversarial networks based remaining useful life estimation for IIoT. Comput. Electr. Eng. 2021, 92, 107195. [Google Scholar] [CrossRef]
- Liu, K.; Shang, Y.; Ouyang, Q.; Widanage, W.D. A Data-Driven Approach With Uncertainty Quantification for Predicting Future Capacities and Remaining Useful Life of Lithium-ion Battery. IEEE Trans. Ind. Electron. 2021, 68, 3170–3180. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Yan, T.; Li, N.; Guo, L. Recurrent convolutional neural network: A new framework for remaining useful life prediction of machinery. Neurocomputing 2020, 379, 117–129. [Google Scholar] [CrossRef]
- Deng, Y.; Bucchianico, A.D.; Pechenizkiy, M. Controlling the accuracy and uncertainty trade-off in RUL prediction with a surrogate Wiener propagation model. Reliab. Eng. Syst. Saf. 2020, 196, 106727. [Google Scholar] [CrossRef]
- Chen, N.; Tsui, K.L. Condition Monitoring and Remaining Useful Life Prediction Using Degradation Signals: Revisited. TIE Trans. 2012, 45, 939–952. [Google Scholar] [CrossRef]
- Cerrada, M.; Sánchez, R.V.; Li, C.; Pacheco, F.; Cabrera, D.; Valente de Oliveira, J.; Vásquez, R.E. A review on data-driven fault severity assessment in rolling bearings. Mech. Syst. Signal Process. 2018, 99, 169–196. [Google Scholar] [CrossRef]
- Liao, L. Discovering Prognostic Features Using Genetic Programming in Remaining Useful Life Prediction. IEEE Trans. Ind. Electron. 2014, 61, 2464–2472. [Google Scholar] [CrossRef]
- Jeanblanc, M.; Yor, M.; Chesney, M. Mathematical Methods for Financial Markets. Finance 2010, 31, 81. [Google Scholar] [CrossRef]
- Fei, Z.; Wu, Z.; Xiao, Y.; Ma, J.; He, W. A new short-arc fitting method with high precision using Adam optimization algorithm. Optik 2020, 212, 164788. [Google Scholar] [CrossRef]
- Ren, X.; Liu, S.; Yu, X.; Dong, X. A method for state-of-charge estimation of lithium-ion batteries based on PSO-LSTM. Energy 2021, 234, 121236. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, PHM’12, Denver, CO, USA, 18 June 2012; pp. 1–8. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Operation Conditions | ||
|---|---|---|---|
| Conditions 1 | Conditions 2 | Conditions 3 | |
| Load (N) | 4000 | 4200 | 5000 |
| Speed (rpm) | 4800 | 1650 | 1500 |
| Training set | Bearing 11 | Bearing 21 | Bearing 31 |
| Bearing 12 | Bearing 22 | Bearing 32 | |
| Testing set | Bearing 13 | Bearing 23 | Bearing 33 |
| Bearing 14 | Bearing 24 | ||
| Bearing 15 | Bearing 25 | ||
| Bearing 16 | Bearing 26 | ||
| Bearing 17 | Bearing 27 | ||
| Proposed | LSTM | |
|---|---|---|
| Test Bearing | MAE | MAE |
| Bearing1_3 | 6.34 | 43.6 |
| Bearing1_4 | 8.03 | 23.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Yan, F.; Shi, R.; Yu, L.; Deng, Y. Uncertainty-Controlled Remaining Useful Life Prediction of Bearings with a New Data-Augmentation Strategy. Appl. Sci. 2022, 12, 11086. https://doi.org/10.3390/app122111086
Wang R, Yan F, Shi R, Yu L, Deng Y. Uncertainty-Controlled Remaining Useful Life Prediction of Bearings with a New Data-Augmentation Strategy. Applied Sciences. 2022; 12(21):11086. https://doi.org/10.3390/app122111086
Chicago/Turabian StyleWang, Ran, Fucheng Yan, Ruyu Shi, Liang Yu, and Yingjun Deng. 2022. "Uncertainty-Controlled Remaining Useful Life Prediction of Bearings with a New Data-Augmentation Strategy" Applied Sciences 12, no. 21: 11086. https://doi.org/10.3390/app122111086