
High Performance IoT Cloud Computing Framework Using Pub/Sub Techniques
Abstract
:1. Introduction
2. Background and Related Works
3. Computing Platform Using MQTT and Kafka
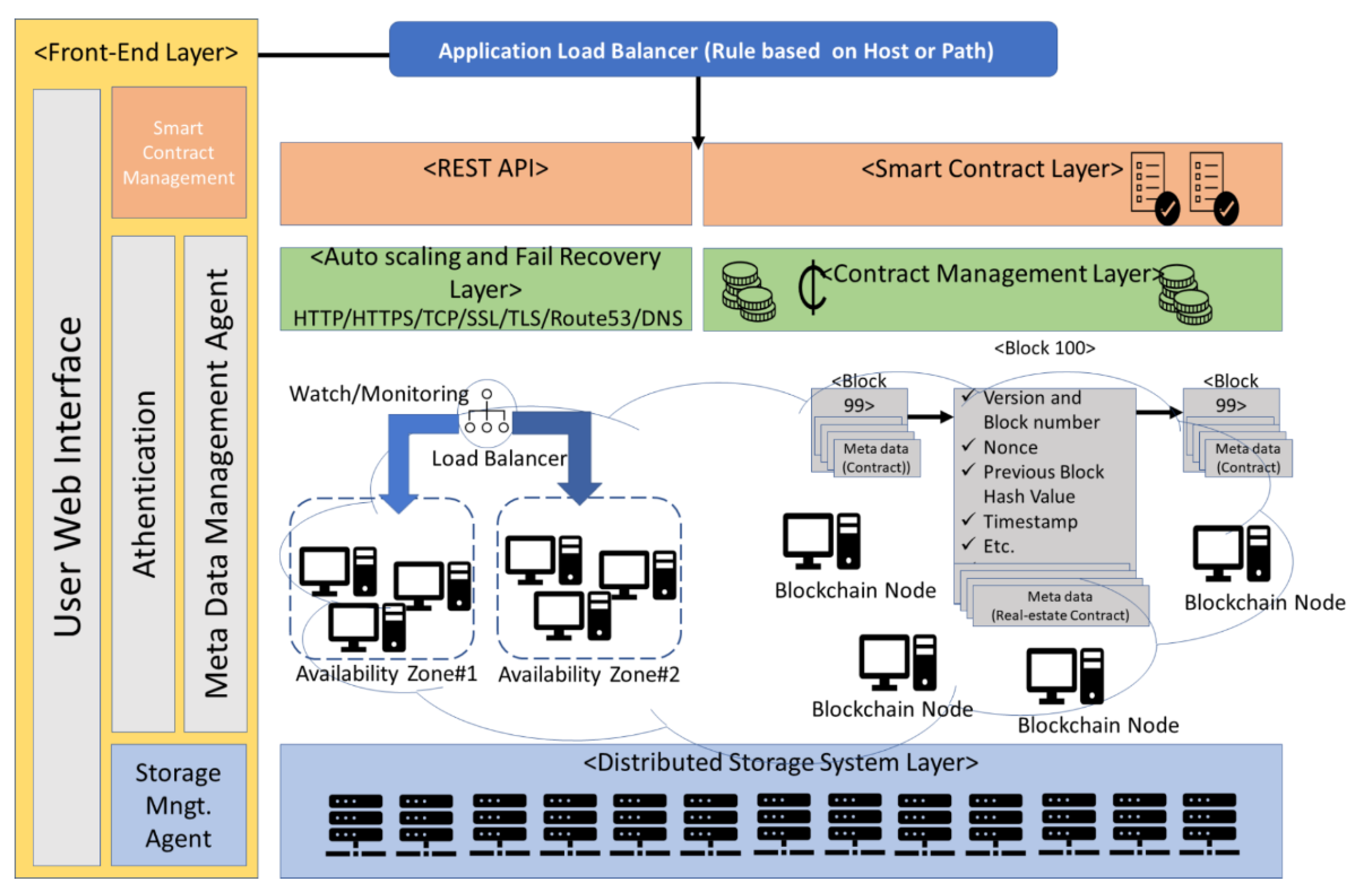
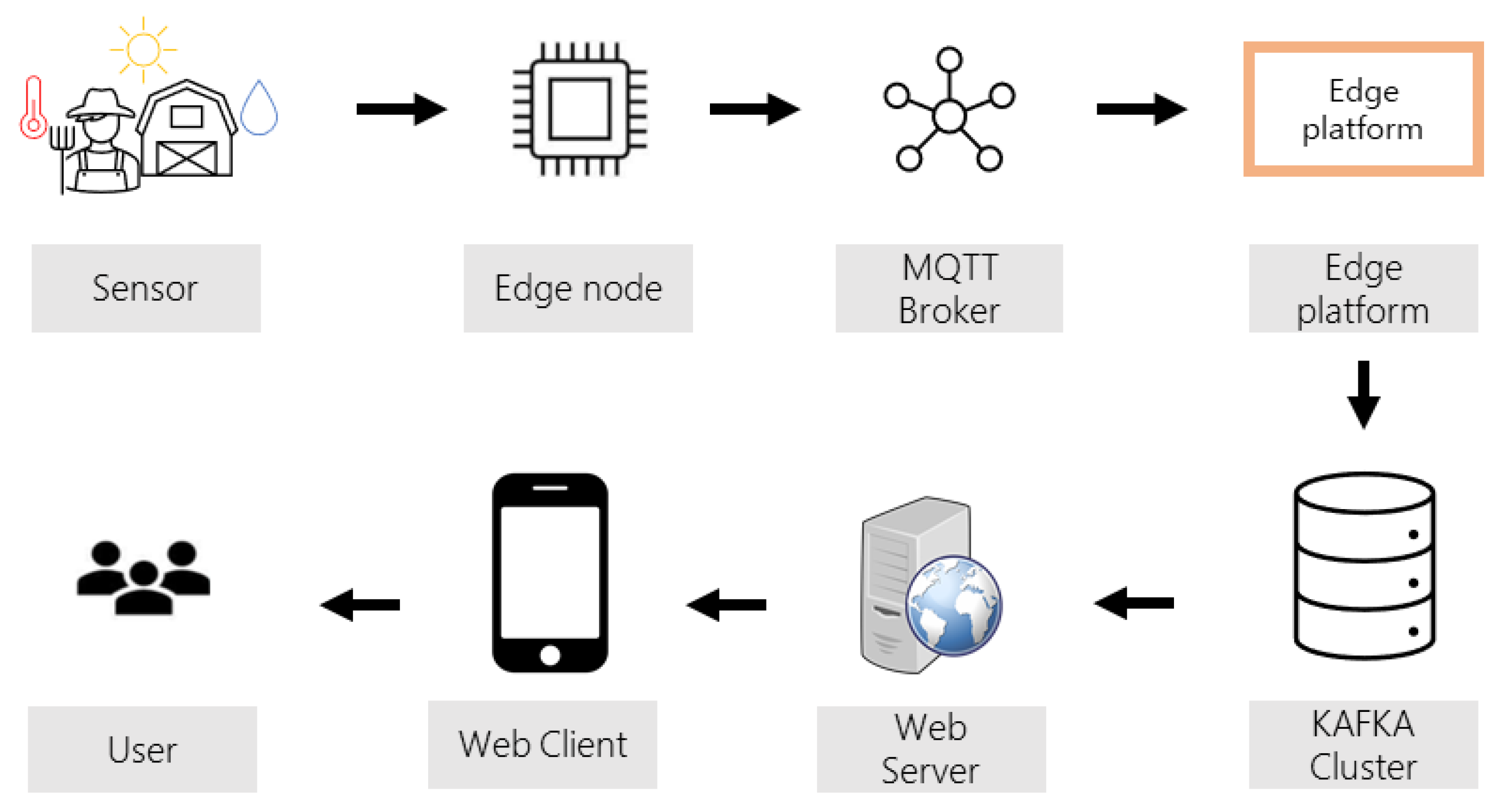
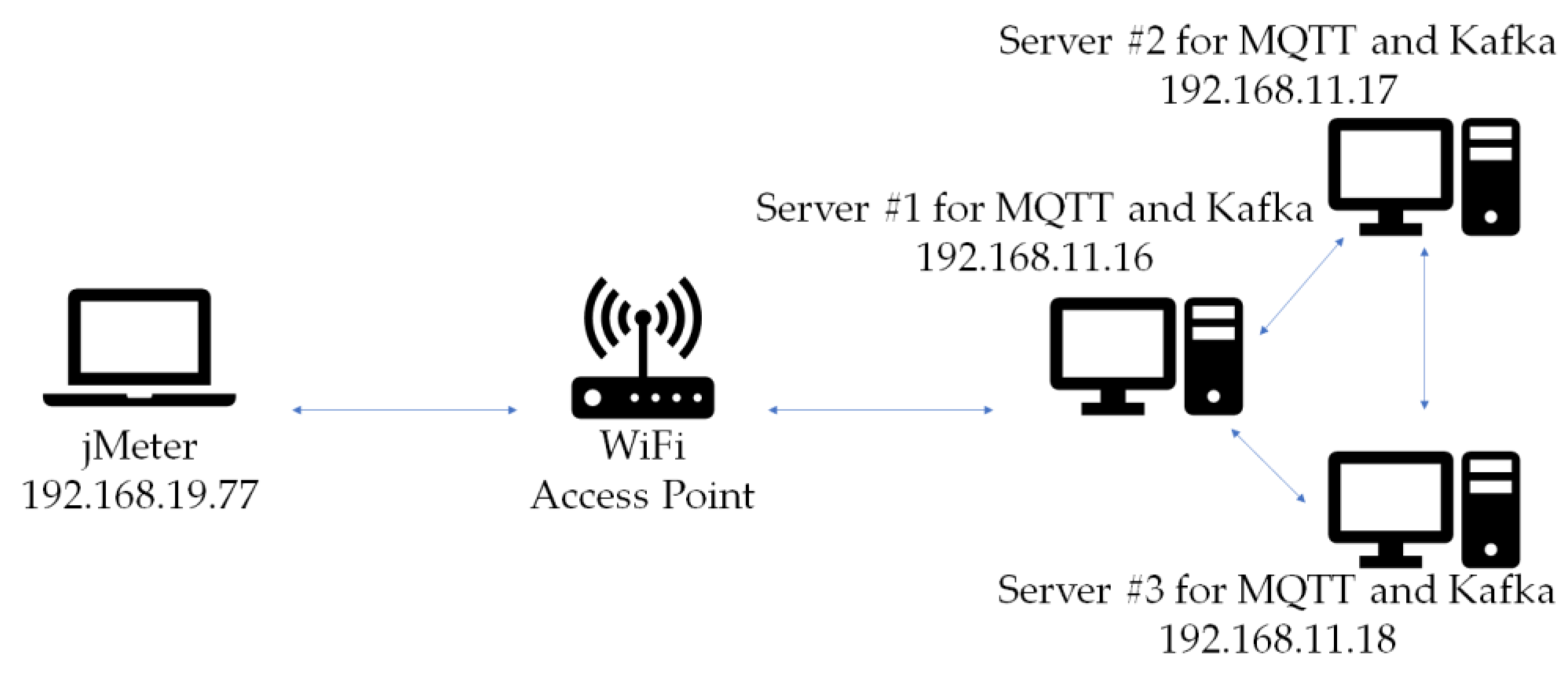
3.1. Overall System Architecture
3.2. Data Processing Based on Publish and Subscribe Architecture
3.3. System Implementation
4. Performance Analysis
4.1. Response Time
- (1)
- (2)
- Run JMeter as an administrator after acquiring JWT token
- (3)
- File -> Open and load the test data jmx file
- (4)
- Input variables corresponding to user defined variables using Table 5
- (5)
- Press Ctrl + R to run the performance evaluation
- (6)
- Repeat No. 5 ten times with Table 6 parameters, measure the time until a response arrives ten times, and take the average value to calculate the processing time in ms.
4.2. Concurrent Client Connections per Server
- (1)
- Run Apache JMeter using Table 7.
- (2)
- Add mqtt-xmeter-2.0.2-jar-with-dependencies.jar and jmeter-plugins-graphs-basic-2.0.jar libraries to JMeter for test evaluation of the MQTT protocol.
- (3)
- Set the following variables in the user-defined variables of Apache JMeter.
- (4)
- Execute Apache JMeter evaluation.
- (5)
- Run (4) for 1 min and judge the result by the average. We obtained the result shown in Table 8.
4.3. Server-Client Data Processing Performance
- (1)
- Connect to the MQTT KAFKA configuration server.
- (2)
- Enter the following command in Table 9 to create a topic.
- (3)
- Input the test code in Table 10 and check the output result.
- (4)
- Check the data processing performance per second through the log output from the performance evaluation program.
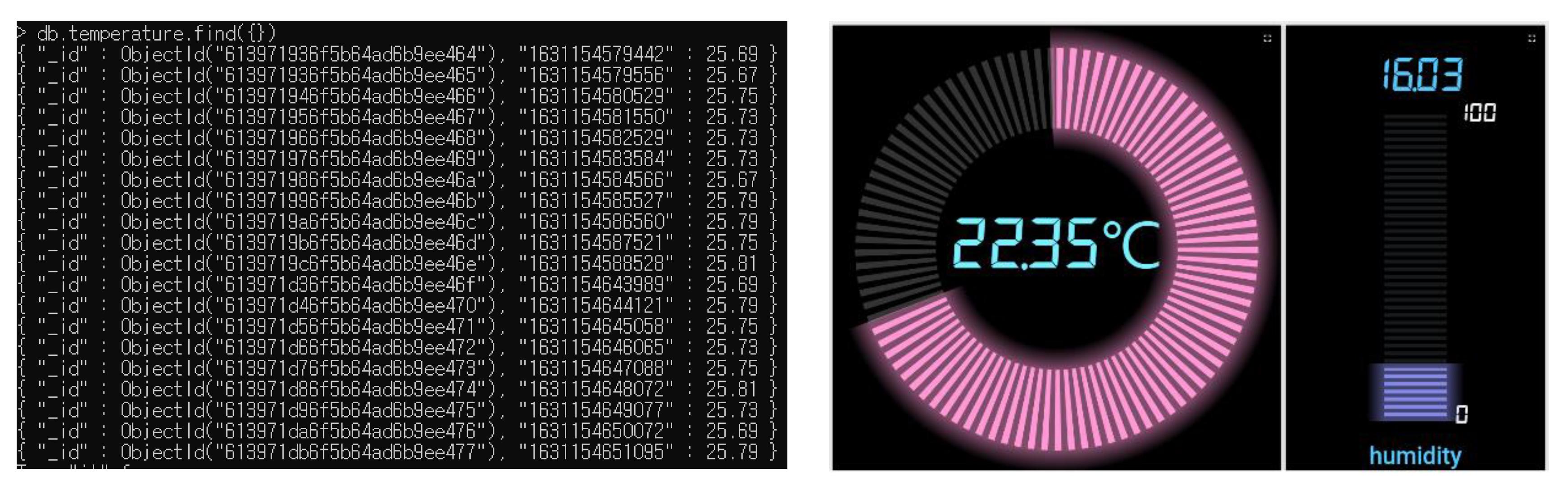
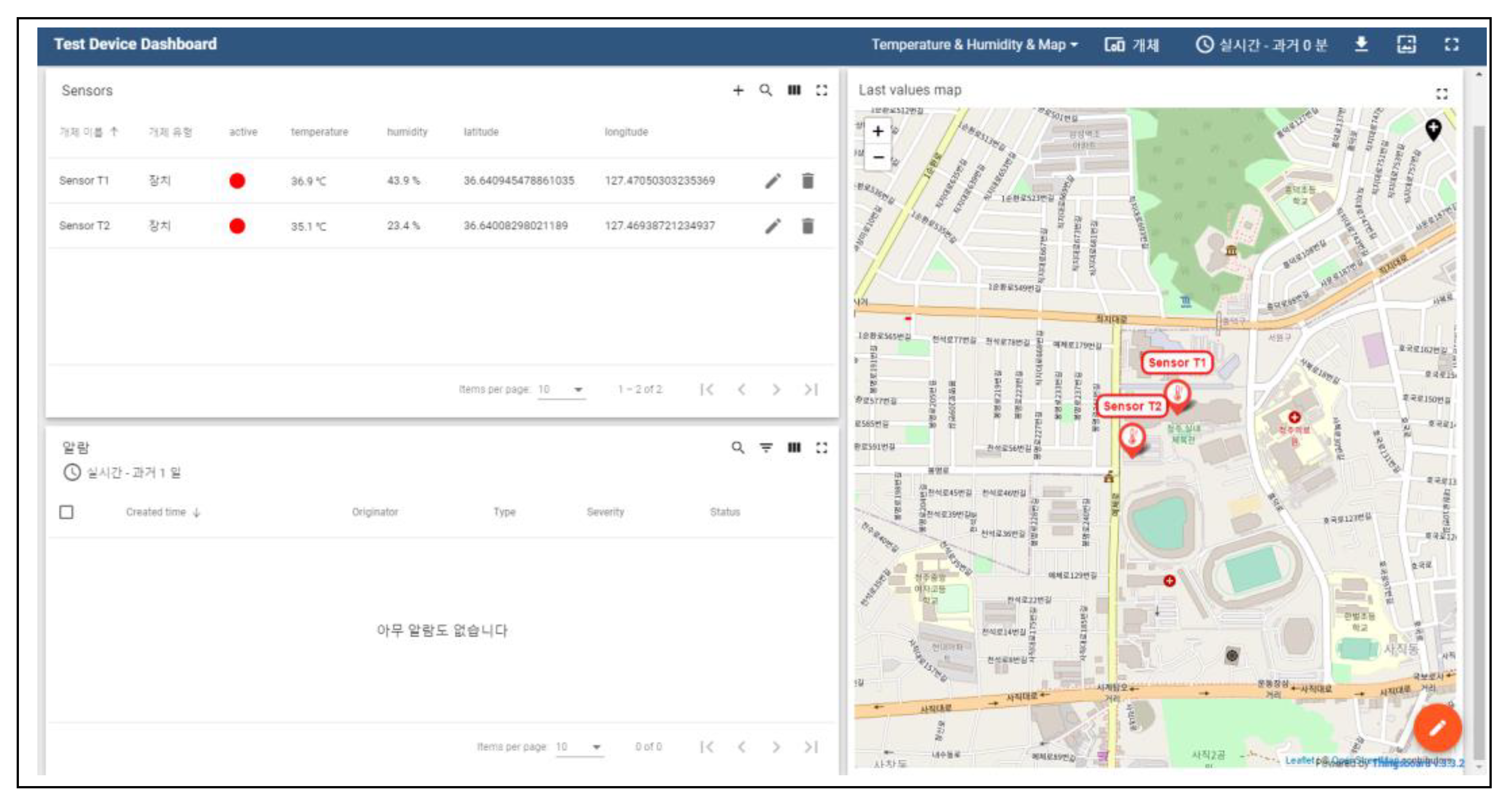
4.4. Actual Data Acquisition Performance Measurement
4.5. In-Order Data Transmission
- (1)
- Run IntelliJ IDEA Community Edition and add Spring-Kafka and Apache’s Kafka-clients library to evaluate whether the data transmission order is guaranteed when transmitting 3000 bytes of data for a specific topic or single partition.
- (2)
- The Kafka producer program source code is in Figure 19.
- (3)
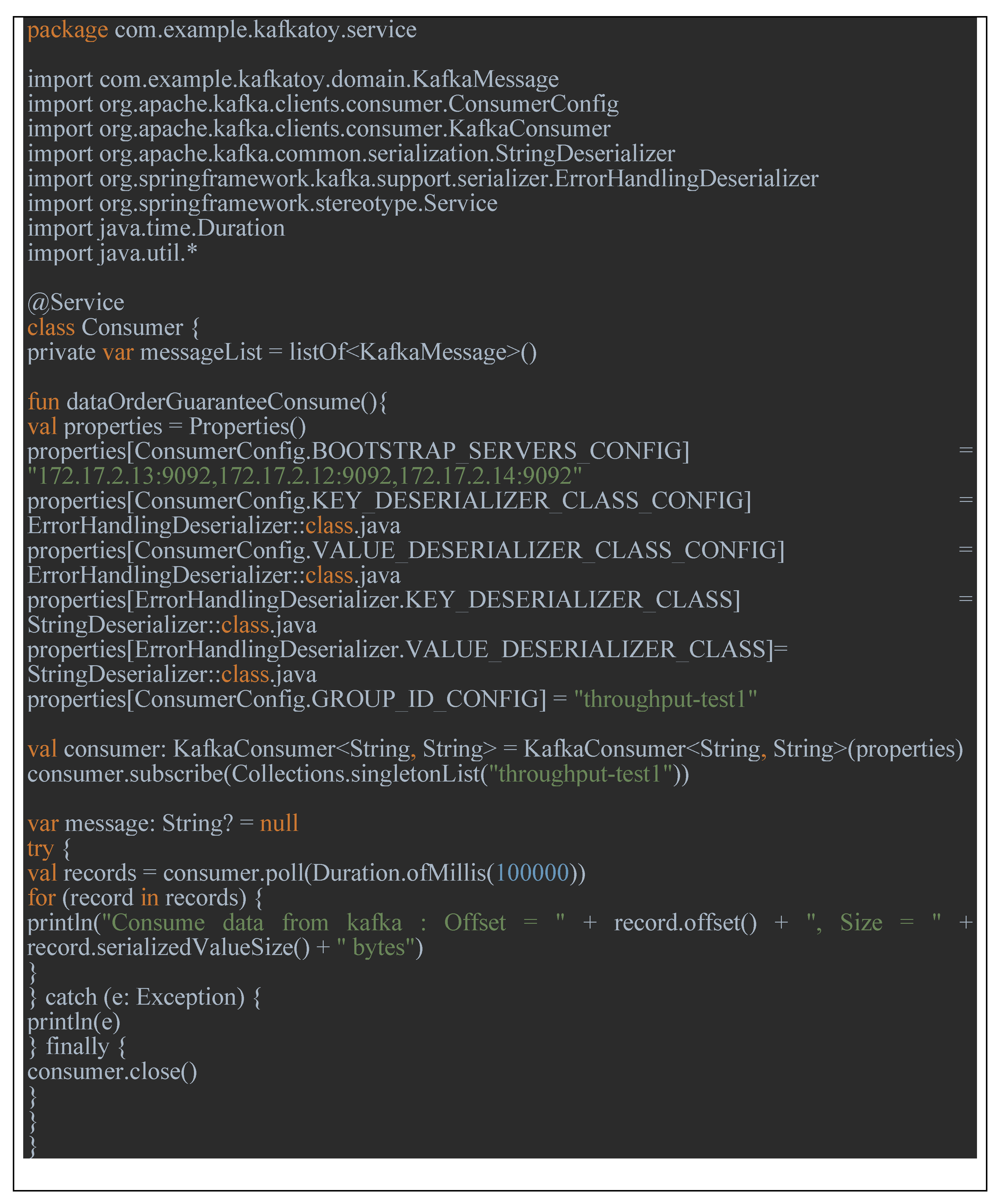
- Kafka consumer program code in Figure 20.
- (4)
- Run src -> main -> kotlin -> com.example.kafkatoy-> kafkaToyApplication.kt file.
- (5)
- Run Postman, enter the address to send the GET request to as Figure 22, and send.
- (6)
- Request GET against the Spring Framework (POSTMAN).
- (7)
- Check whether Offset is guaranteed in order through the log output to the IntelliJ IDEA console.
5. Conclusions
- ✓ We realized a high-performance IoT cloud platform architecture which is for data interworking between each node, and this system also provides the ability to record key facts.
- ✓ As a result of performance evaluation, our system is effective for use in environments where network bandwidth is limited or a large amount of data is continuously transmitted and received.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gokhale, P.; Bhat, O.; Bhat, S. Introduction to IOT. Int. Adv. Res. J. Sci. Eng. Technol. 2018, 5, 41–44. [Google Scholar]
- Naresh, M.; Munaswamy, P. Smart Agriculture System using IoT Technology. Int. J. Recent Technol. Eng. 2019, 7, 98–102. [Google Scholar]
- Bauer, J.; Aschenbruck, N. Design and Implementation of an Agricultural Monitoring System for Smart Farming. In Proceedings of the 2018 IoT Vertical and Topical Summit on Agriculture—Tuscany (IOT Tuscany), Tuscany, Italy, 8–9 May 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Verma, M.S.; Gawade, S.D. A Machine Learning Approach for Prediction System and Analysis of Nutrients Uptake for Better Crop Growth in the Hydroponics System. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; IEEE: New York, NY, USA, 2021; pp. 150–156. [Google Scholar]
- Vanipriya, C.; Maruyi; Malladi, S.; Gupta, G. Artificial intelligence enabled plant emotion xpresser in the development hydroponics system. Mater. Today Proc. 2021, 45, 5034–5040. [Google Scholar] [CrossRef]
- Triantafyllou, A.; Sarigiannidis, P.; Lagkas, T.D. Network Protocols, Schemes, and Mechanisms for Internet of Things (IoT): Features, Open Challenges, and Trends. Wirel. Commun. Mob. Comput. 2018, 2018, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Gilmore, B. The Next Step in Internet Evolution: The Internet of Things. Internet Things Cmswire 2014. [Google Scholar]
- Hammad, M.; Iliyasu, A.M.; Elgendy, I.A.; Abd El-Latif, A.A. End-to-End Data Authentication Deep Learning Model for Securing IoT Configurations. Hum. Cent. Comput. Inf. Sci. 2022, 12, 4. [Google Scholar]
- Anusha, A.; Guptha, A.; Rao, G.S.; Tenali, R.K. A Model for Smart Agriculture Using IOT. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 6. [Google Scholar]
- Guillermo, J.C.; García-Cedeño, A.; Rivas-Lalaleo, D.; Huerta, M.; Clotet, R. Iot Architecture Based on Wireless Sensor Network Applied to Agricultural Monitoring: A Case of Study of Cacao Crops in Ecuador. In International Conference of ICT for Adapting Agriculture to Climate Change; Springer: Cham, Switzerland, 2018; pp. 42–57. [Google Scholar]
- El Azzaoui, A.; Choi, M.Y.; Lee, C.H.; Park, J.H. Scalable Lightweight Blockchain-Based Authentication Mechanism for Secure VoIP Communication. Hum. Cent. Comput. Inf. Sci. 2022, 12, 8. [Google Scholar]
- Li, G.; Yang, K. Study on Data Processing of the IOT Sensor Network Based on a Hadoop Cloud Platform and a TWLGA Scheduling Algorithm. J. Inf. Processing Syst. 2021, 17, 1035–1043. [Google Scholar] [CrossRef]
- La, H.J.; An, K.H.; Kim, S.D. Design Patterns for Mitigating Incompatibility of Context Acquisition Schemes for IoT Devices. KIPS Trans. Softw. Data Eng. 2016, 5, 351–360. [Google Scholar] [CrossRef] [Green Version]
- Shin, S.; Eom, S.; Choi, M. Soft Core Firmware-Based Board Management Module for High Performance Blockchain/Fintech Servers. Hum. Cent. Comput. Inf. Sci. 2022, 12, 3. [Google Scholar]
- Choi, M.; Kiran, S.R.; Oh, S.-C.; Kwon, O.-Y. Blockchain-Based Badge Award with Existence Proof. Appl. Sci. 2019, 9, 2473. [Google Scholar] [CrossRef] [Green Version]
- Keswani, B.; Mohapatra, A.G.; Mohanty, A.; Khanna, A.; Rodrigues, J.J.P.C.; Gupta, D.; de Albuquerque, V.H.C. Adapting weather conditions based IoT enabled smart irrigation technique in precision agriculture mechanisms. Neural Comput. Appl. 2018, 31, 277–292. [Google Scholar] [CrossRef]
- Heble, S.; Kumar, A.; Prasad, K.V.D.; Samirana, S.; Rajalakshmi, P.; Desai, U.B. A Low Power IoT Network for Smart Agriculture. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5 February 2018; IEEE: New York, NY, USA, 2018; pp. 609–614. [Google Scholar]
- Jawad, H.M.; Nordin, R.; Gharghan, S.K.; Jawad, A.M.; Ismail, M.; Abu-AlShaeer, M.J. Power Reduction with Sleep/Wake on Redundant Data (SWORD) in a Wireless Sensor Network for Energy-Efficient Precision Agriculture. Sensors 2018, 18, 3450. [Google Scholar] [CrossRef] [PubMed]
- Opensource IoT Dashboard Platform, ThingsBoard-Open-Source IoT Platform. Available online: http://thingboard.io (accessed on 29 July 2022).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Address | Read Access |
|---|---|---|
| Melexis reserved | 0x00 | Yes |
| … | … | … |
| Melexis reserved | 0x03 | Yes |
| Raw data IR channel 1 | 0x04 | |
| Raw data IR channel 2 | 0x05 | |
| TA | 0x06 | Yes |
| TOBJ1 | 0x07 | Yes |
| TOBJ2 | 0x08 | Yes |
| Melexis reserved | 0x09 | Yes |
| … | … | … |
| Melexis reserved | 0x1f | Yes |
| Modules | Version | |
|---|---|---|
| Run time | Node.js | v14.17.3 |
| Webserver | ThingsBoard | v3.3.1 |
| MQTT client | mqtt.js | v0.46.1 |
| MQTT broker | aedes.js | v4.2.8 |
| Database | MongoDB | v4.4.6 |
| Database client | mongodb.js | v4.1.1 |
| Kafka server | Apache Kafka | v2.8.0 |
| Framework | Spring Boot | v2.3.3 |
| Web frontend | React | v1613.1 |
| Kafka client | kafka.js | v1.15.0 |
| Type | Purpose |
|---|---|
| MQTT server | Server for processing sensor data |
| Kafka server cluster | Cluster server for image data processing and Kafka server stability |
| Apache JMeter | Create a virtual client for testing on the MQTT Kafka server |
| Address | 172.17.x.xx/api/auth/login | |
| Header | Content-Type | application/json |
| Accept | application/json | |
| Body | { "username":"xxxxxx@thingsboard.org", "password":"xxxxxx" } | |
| HTTP_HOST | 172.17.XX.XXX |
| HTTP_PORT | 8080 |
| NUMBER_OF_USERS | 1 |
| TOKEN | JWT token you get from our server through POSTMAN |
| entityType | DEVICE |
| entityId | 24b14a40-7ff0-11ec-88a7-2d9d3861528f |
| scope | ANY |
| Test Result (Processing Time, ms) | |
|---|---|
| 1 | 88 |
| 2 | 100 |
| 3 | 103 |
| 4 | 104 |
| 5 | 103 |
| 6 | 98 |
| 7 | 99 |
| 8 | 99 |
| 9 | 99 |
| 10 | 101 |
| average | 99.4 |
| MQTT_HOST | 172.xx.xx.xx |
| MQTT_PORT | 1884 |
| TOPIC | Test |
| NUMBER_OF_USERS | 50 |
| NUMBER_OF_DATA_TRANSFERS | 200 |
| USER_NAME | xxxx |
| PASSWORD | xxxxxx |
| Throughput (req./s) | Unit Time (s) | Throughput (req./min) |
|---|---|---|
| 64,313.1 | 60 | 3,858,786 |
| /usr/local/kafka/bin/kafka-topics.sh \ --create \ --partitions 1 \ --replication-factor 1 \ --topic throughput-test \ --bootstrap-server 172.17.XX.XXX:9092,172.17.XX.XXX:9092,172.17.XX.XXX:9092 |
| /usr/local/kafka/bin/kafka-producer-perf-test.sh \--topic throughput-test \--throughput –1 \--num-records 20000000 --record-size 512 --producer-propsbootstrap.servers=172.17.XX.XXX:9092,172.17.XX.XXX:9092,172.17.XX.XXX:9092 |
| Test Result (record/ms) | |
|---|---|
| 1 | 114,948.2 |
| 2 | 117,603.6 |
| 3 | 116,698.6 |
| 4 | 107,369.2 |
| 5 | 116,661.0 |
| 6 | 111,039.0 |
| 7 | 112,493.6 |
| 8 | 113,449.4 |
| 9 | 111,433.2 |
| 10 | 109,653.1 |
| Average | 113,134.89 |
| Test Result (Transmission Time, ms) | |
|---|---|
| 1 | 199.5 |
| 2 | 196.0 |
| 3 | 299.0 |
| 4 | 283.0 |
| 5 | 196.4 |
| 6 | 213.3 |
| 7 | 204.8 |
| 8 | 211.0 |
| 9 | 252.4 |
| 10 | 223.8 |
| 227.92 | |
| Produce data from kafka: Offset = 13,671,130, Size = 3000 bytes Produce data from kafka: Offset = 13,671,131, Size = 3000 bytes Produce data from kafka: Offset = 13,671,132, Size = 3000 bytes Produce data from kafka: Offset = 13,671,133, Size = 3000 bytes Produce data from kafka: Offset = 13,671,134, Size = 3000 bytes Produce data from kafka: Offset = 13,671,135, Size = 3000 bytes Produce data from kafka: Offset = 13,671,136, Size = 3000 bytes Produce data from kafka: Offset = 13,671,137, Size = 3000 bytes Produce data from kafka: Offset = 13,671,138, Size = 3000 bytes Produce data from kafka: Offset = 13,671,139, Size = 3001 bytes Produce data from kafka: Offset = 13,671,140, Size = 3001 bytes Produce data from kafka: Offset = 13,671,141, Size = 3001 bytes Produce data from kafka: Offset = 13,671,142, Size = 3001 bytes Produce data from kafka: Offset = 13,671,143, Size = 3001 bytes Produce data from kafka: Offset = 13,671,144, Size = 3001 bytes Produce data from kafka: Offset = 13,671,145, Size = 3001 bytes Produce data from kafka: Offset = 13,671,146, Size = 3001 bytes Produce data from kafka: Offset = 13,671,147, Size = 3001 bytes Produce data from kafka: Offset = 13,671,148, Size = 3001 bytes Produce data from kafka: Offset = 13,671,149, Size = 3001 bytes Produce data from kafka: Offset = 13,671,150, Size = 3001 bytes Produce data from kafka: Offset = 13,671,151, Size = 3001 bytes Produce data from kafka: Offset = 13,671,152, Size = 3001 bytes Produce data from kafka: Offset = 13,671,153, Size = 3001 bytes | Consume data from kafka: Offset = 13,671,206, Size = 3001 bytes Consume data from kafka: Offset = 13,671,207, Size = 3001 bytes Consume data from kafka: Offset = 13,671,208, Size = 3001 bytes Consume data from kafka: Offset = 13,671,209, Size = 3001 bytes Consume data from kafka: Offset = 13,671,210, Size = 3001 bytes Consume data from kafka: Offset = 13,671,211, Size = 3001 bytes Consume data from kafka: Offset = 13,671,212, Size = 3001 bytes Consume data from kafka: Offset = 13,671,213, Size = 3001 bytes Consume data from kafka: Offset = 13,671,214, Size = 3001 bytes Consume data from kafka: Offset = 13,671,215, Size = 3001 bytes Consume data from kafka: Offset = 13,671,216, Size = 3001 bytes Consume data from kafka: Offset = 13,671,217, Size = 3001 bytes Consume data from kafka: Offset = 13,671,218, Size = 3001 bytes Consume data from kafka: Offset = 13,671,219, Size = 3001 bytes Consume data from kafka: Offset = 13,671,220, Size = 3001 bytes Consume data from kafka: Offset = 13,671,221, Size = 3001 bytes Consume data from kafka: Offset = 13,671,222, Size = 3001 bytes Consume data from kafka: Offset = 13,671,223, Size = 3001 bytes Consume data from kafka: Offset = 13,671,224, Size = 3001 bytes Consume data from kafka: Offset = 13,671,225, Size = 3001 bytes Consume data from kafka: Offset = 13,671,226, Size = 3001 bytes Consume data from kafka: Offset = 13,671,227, Size = 3001 bytes Consume data from kafka: Offset = 13,671,228, Size = 3001 bytes Consume data from kafka: Offset = 13,671,229, Size = 3002 bytes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nam, J.; Jun, Y.; Choi, M. High Performance IoT Cloud Computing Framework Using Pub/Sub Techniques. Appl. Sci. 2022, 12, 11009. https://doi.org/10.3390/app122111009
Nam J, Jun Y, Choi M. High Performance IoT Cloud Computing Framework Using Pub/Sub Techniques. Applied Sciences. 2022; 12(21):11009. https://doi.org/10.3390/app122111009
Chicago/Turabian StyleNam, Jaekyung, Youngpyo Jun, and Min Choi. 2022. "High Performance IoT Cloud Computing Framework Using Pub/Sub Techniques" Applied Sciences 12, no. 21: 11009. https://doi.org/10.3390/app122111009