2. Literature Review
In the literature, most studies on warehouse order picking have focused only on picker routing or order batching. Articles that only consider order picking can be classified into certain [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17] and uncertain cases [
18,
19]. Picker routing can be considered a traditional traveling-salesman problem (TSP). Through the distance between storage spaces, pickers plan how to visit each storage space through the shortest path before returning to the starting point. However, when the number of storage spaces increases, the computation time required to obtain an optimal solution is long [
20]. Among the certain cases, many studies have considered the operating environment of AS/RS [
4,
5,
10,
11,
12,
13,
14,
17]. Storage systems, capacity, and strategies were introduced in [
14,
17]. Zone picking was used as the picking method in [
8,
15,
16]. Petersen [
21] evaluated the returning characteristic in routing policies to ensure that pickers enter an aisle to collect the required items, exit through the path they entered, and then, travel to subsequent aisles in succession. Regarding algorithm design, the genetic algorithm (GA) can be seen in [
9,
15].
In the area of order batching, most of the papers are certain cases [
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34]. Uncertain issues can only be seen in [
35,
36]. Hwang and Kim [
25] developed an order-batching algorithm that is based on cluster analysis by considering three outing policies, namely traversal, return, and midpoint routing. Moreover, De Koster et al. [
37] applied the midpoint method in which pickers enter from one end of an aisle to pick goods, and then, turn to another aisle in succession as each aisle is completed. Henn and Wäscher [
38] resolved the question of how to combine customer orders to shorten the total picking distance. They suggested two metaheuristic algorithms, namely a classic tabu search (TS) algorithm and an attribute-based hill-climbing approach, and both approaches were superior to existing methods. Hwang et al. [
39] solved batch order processing as a clustering problem. They defined items as attribute vectors and used three similarity measures to develop six cluster classification algorithms. The experimental results proved that merging orders with higher degrees of similarity improved the picking efficiency. The heterogeneous pick devices [
34] and multiple pickers [
36] were extended to the batching problem. Regarding the algorithm design, GA [
28,
31,
33] and VNS [
29,
34,
36] were widely introduced.
Among the integration issues considered together with order picking and order batching, we can see that most of them are certain issues [
3,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50] and uncertain issues can be found in [
51,
52]. The concept of storage systems, capacity, and strategy was introduced in [
45,
51]. Yu and Koster [
52] used AS/RS as the operating environment.
Regarding the algorithm design, Won and Olafasson [
40] solved the order-batching and picking-sequence problem by using hybrid heuristic algorithms. The first heuristic determines order batching, and the second heuristic identifies the picking sequence. Kulak et al. al. [
3] and Henn [
44] used TS to deal with the problem of order batching, while on the issue of picking, Kulak et al. [
3] adopted a 2-opt method, and Henn [
44] proposed a picking strategy. Tsai et al. [
53] employed a two-stage GA to solve an order-batching and picking-sequence problem. The objective was to minimize the total traveling time. The first stage of the GA involved determining the order batches, and the second stage entailed determining the shortest picking paths for these batches. Lin et al. [
48] considered a picking route based on the Manhattan distance and used particle swarm optimization (PSO) to solve the joint order-batching and picking-route problem. Cheng et al. [
47] used PSO to deal with order batching and used ACO to find the most efficient route for each batch. Van Gils [
49] set high customer service level and improved picking efficiency as its goals and developed an iterated local search algorithm to solve.
3. Problem Statement
This study deals with the order-batching problem and picking-route-sequence problem in the picker-to-part system; that is, in the conventional rectangular warehouse, the different orders are first classified and sorted into batches, with group orders with similar paths grouped together as much as possible. For the items to be picked in order,
,
,
, and
represent the
-th order, storage location
,
-th batch, and the picking distance of order
k or batch
, respectively.
m represents the distance unit.
= {
}, indicating that order 1 needs to be picked from storage positions 3, 6, and 8. If there are five orders,
= {
};
=
;
= {
};
= {
}; and
= {
} are to be classified into batches, and then, the distance of the orders individually calculated. As shown in
Figure 1 and
Figure 2, if we pick the items by following the number sequence, in order 1, it takes 4 m to travel from the entrance to position 3, 3 m from position 3 to 6, 2 m from position 6 to 8, and 9 m from position 8 to the entrance and exit. Hence, the distances of order 1 to order 5,
, are 18 m, 40 m, 16 m, 46 m, and 40 m. Since order 1 and order 3 are both picked in the first aisle, they can be grouped into batch 1,
. The distance of batch 1,
, is 18 m. Without order batching, the total distance of these two orders is 34 m. Orders 2, 4, and 5 can be classified into batch 2,
, based on a similar situation. If the items are picked by individual order, the total distance of these three orders is 126 m, but the distance of batch 2,
, is largely decreased to 46 m.
After combining the orders into batches, the picker picks items in sequence according to the sorted picking list of the batch, but if the picking route is different, the picker might go as far as possible in the warehouse. For example, {37,64,21,19,43} and {19,37,21,43,64} are picking routes 1 and 2 of the order. The distances of picking routes 1 and 2 are 68 m and 42 m, respectively.
We adopted the model proposed by Kulak et al. [
3] to address the batching and picking problems and minimize the overall route. The problem assumptions, notations, and model are as follows.
Problem Assumptions:
Warehouses have a picker-to-part system and parallel aisles.
The storage strategy is dedicated location, so each storage position has a fixed size. Only one item can be stored or picked, and the quantity of the same item being picked is fixed at one.
There is only one picker; that is, there is only one picker on the aisle, and the picker will take the path with the shortest distance and will not choose the path that bypasses the aisle.
It is prohibited to split the order into different batches, and the items in the order cannot be cut into different batches. The size of one order cannot be over the size of one batch.
The picker can pass up and down the aisle and pick the item on the left or the right. The picker picks the item in front of the storage position, and the distance and time from the picker to the item can be ignored.
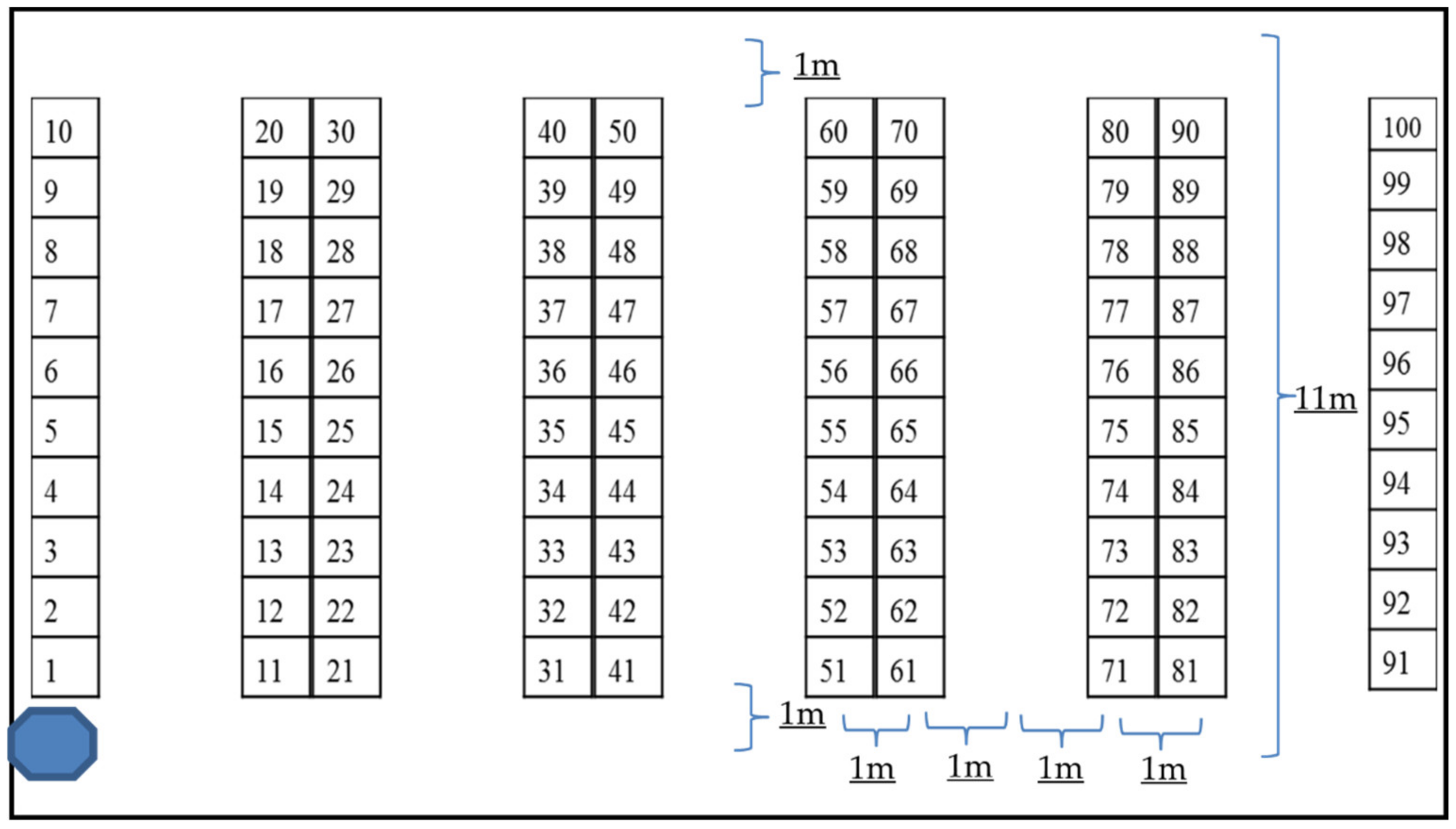
The warehouse layout plan shown in
Figure 2 is a conventional rectangular warehouse, starting from and finally returning to the I/O point to complete the closed loop. There are 10 storage spaces in a row—two rows on the left and right in one aisle, and five aisles, with a total of 100 storage positions.
All customers are known in advance, and no orders will be inserted, reduced, or changed in the middle of the process.
Notations:
Objective (1) represents the objective function of the total picker route distance of all batches. Constraints (2) and (3) indicate that in order to avoid repetitive calculations, storage i can serve as the depot and destination only once. In addition, the constraints can be used to express whether the batches in storage have been picked. Constraint (4) represents a subcycle-eliminating constraint that prevents the formation of subcycles. The limiting function ensures that all picking points are picked and that each storage unit that requires picking is picked only once. Constraint (5) forces the selected orders and items in a batch to transform into binary variables. Constraint (6) reveals that an order can be assigned to only one batch to prevent such an order from being repetitively assigned to various batches. Constraint (7) indicates the capacity of the picking vehicle, signifying that the batch weight after order consolidation cannot exceed the maximum vehicle load. Constraint (8) indicates that all variables are binary.
4. Proposed Algorithm
The concept of the proposed algorithm is to decompose the order-batching and picking-route problem into two independent algorithms. First, in the first algorithm (order batching), the encoding solution, obtained from the initial batch order or the order-batching neighborhood (mutation/swap), is the input of the second algorithm (picking route). In the second algorithm, the initial picking route is obtained from storage locations with lower numbers to those with high numbers. The picking-route neighborhood (swap/insert) is used to obtain the best route of the current batches. Then, the distance of the best route is the objective value (distance) of the first algorithm. The whole framework of the proposed algorithm can be seen in
Figure 3.
4.1. Initial Batch Order
Through order consolidation, each reduced batch can shorten the picking route of an order. Consequently, the only factor considered in determining the initial batch is capacity restriction. Moreover, we excluded route proximity from the criteria used to determine the initial batch. We considered five approaches for obtaining the initial solutions of the batching problem, and among these approaches, the picking route was not considered. The single-order (SO) method differs from the other methods, and this method involves considering one order as one picking batch. The random batch (RB) method was adopted to enable comparison between random and planned operations.
Gupta and Ho [
54] focused on a one-dimensional bin-packing problem and proposed three evaluation methods to minimize the number of batches: the first-fit-decreasing (FFD), best-fit (BF), and best-fit-decreasing (BFD) approaches. Because the bin-packing problem is similar to the order-batching problem, we thus adopted these three approaches in this study. The FFD method is applied to address weight limitations. Because of the capacity restriction for each batch, on the basis of the FFD method, orders with heavy weights should be assigned first; however, when such orders are assigned later, they generate a new batch, thus increasing the total number of batches and adding another picking route. The batches can be determined on the basis of the principle of determining the average batch weight (i.e., the BF method). We eventually combined the FFD and BF methods and denoted the integrated method as BFD. In this hybrid method, orders are assigned initially according to the FFD method and their weight, and they are subsequently assigned according to the BF method.
- A.
SO method
The SO method was adopted to enable comparison of the results before and after batch consolidation. In contrast to batching methods, which are used to consolidate several orders into a single order, the SO method facilitates arranging the order-picking sequence. Each order comprises a batch, and dissimilar orders are categorized into different batches.
- B.
RB method
The RB method involves randomly generating each order’s assigned batch. The orders are randomly selected from the pool of orders and assigned to a batch individually. When the batch to which an order is assigned cannot accommodate the weight of the order, the system reassigns another batch. The process continues until all orders are assigned.
- C.
FFD method
Compared with light-weight orders, heavy-weight orders tend to be more difficult to assign to batches. Therefore, the system starts assigning batches from the heaviest orders. In addition, each batch load is expected to reach the maximum load. The orders are assigned to batches sequentially according to their weight, from the heaviest to the lightest. The assigning principle involves minimizing the remaining weight of each batch. When a batch is fully loaded, the order is reallocated to a new batch.
- D.
BF method
Maintaining a balanced batch weight facilitates neighboring solutions to jump from the local optima when the swap move operator is used. The assignment starts from the heaviest order, and an order is assigned to the batch with the greatest remaining weight. In other words, when there are several batches to select from, the system selects the batch with the lowest remaining capacity (batch total capacity–batch present capacity) after an order is assigned to it. Specifically, an order is assigned to the least full batch, and when the batch cannot contain the order, the order is reassigned to a new batch, thus balancing the weight among batches.
- E.
BFD method
This method is a combination of the BF and FFD methods. Orders are first prioritized using the FFD approach and are subsequently assigned to batches through the BF method. Orders are assigned sequentially from the heaviest to the lightest batch, and during the assignment, the guiding principle involves minimizing the remaining weight of a batch. Specifically, when there are several batches to select from, the system selects the batch with the lowest remaining capacity (batch total capacity–batch present capacity) after an order is assigned to it. When a batch cannot contain the order, the order is reassigned to a new batch.
4.2. Initial Picking Route
Because the number of picking items is arranged according to orders, the optimal order-picking route is constructed on the basis of the number of picking items. In the same batch, the initial picking route moves from locations with lower numbers to those with high numbers. The relative shortest distance matrix of these locations can be easily obtained because in warehouses, storage is arranged from left to right and from bottom to top.
4.3. Encoding
In this study, we encode the batch numbers and number of orders that must be picked. The batch number of orders is obtained from the phase of the initial batch order, and the total weight must remain within the vehicle capacity. The number of order-picking items represents the items from which orders must be picked in a batch.
4.4. Neighborhood Searching
To minimize the number of batches and shorten the total picking-route distance, we used neighborhood searching to determine the optimal neighboring solution for batching and picking problems. These two problems require different neighboring solution designs. First, to effectively reduce the number of batches, a mutation procedure is applied. For example, when a mutated order is the only order in a batch, the mutation of the order from the original batch to another batch can reduce the batch by one. In addition, a swap procedure changes the existing combination of batches in pairs according to a fixed total number of batches. Second, according to existing picking solutions, we designed a swap procedure to improve picking routes to a small extent. Moreover, to increase the extent of improvement, the insertion procedure is adopted for generating neighboring solutions by inserting one order into another and, hence, moving the remaining items in the order by one place.
- A.
Order Batching
Using the existing number corresponding to each order to conduct neighborhood searching can reveal whether more effective solutions are available. Mutation and swap procedures can be applied in the search process; adopting mutation procedures can effectively reduce the total number of batches. The original batch can be emptied, and thus, eliminated by mutating batches that exhibit only one order to another batch. In contrast to the mutation procedure, which is used to reconstruct overall batches, the swap procedure improves the batch arrangement and is the most commonly applied method in neighborhood design. The swap procedure is a type of optimization procedure, and it cannot be used to reduce the number of batches; however, it facilitates reassigning the orders to optimal batches. When the aforementioned two methods are used, vehicle capacity must be considered during neighborhood search processes.
- B.
Order Picking
When the picking route is arranged, items should be collected according to prioritized orders. Each batch has a specific picking order, and minor changes can be implemented on the basis of the existing picking order. Order optimization can be performed within batches by assessing whether the changed orders are more favorable than the original orders. Therefore, the shortest picking route can be obtained by conducting neighborhood searches on the existing picking solutions. The neighboring solutions can be acquired through swapping, insertion, and random-selection procedures. Because the number of items remaining to be picked is fixed, new combinations must be sequenced. In designing neighboring solutions, a two-point swap is most commonly used and an insertion procedure that remains farther from the neighborhood can be used to obtain more varied neighboring results.
4.5. SA Algorithm
Because this study involved two problems, a single-solution metaheuristic is more suitable for solving the problems compared with a population-based metaheuristic. If a population-based metaheuristic is adopted, then multiple solutions are generated at the first stage, and each solution results in the generation of several solutions at the second stage, thereby reducing the efficiency of deriving solutions. In addition, the SA algorithm involves a random mechanism; hence, it was applied for solving the problems in the two stages.
The SA algorithm can be applied to solve both TSPs and batching and packing problems. Therefore, we initially combined two types of SA. First, the framework of the first stage was used when solving the batches through the SA algorithm. Each time the neighboring solution was substituted, the SA algorithm applied to the picking routes was reconsidered. The distance of the picking routes must be determined to yield the neighboring solution of the batch. The following parameter values must be established first:
- (1)
Starting temperature (): Temperature setting is crucial in the SA algorithm. If the value is excessively high, then the convergence is slow; however, if the value is excessively low, then the solution quality becomes unsatisfactory.
- (2)
Maximum chain length (): The chain length is determined to control the search frequency at each temperature. If the length is too short, then the execution time can be shortened; however, the quality of solutions cannot be enhanced. If the length is too long, then the eventual quality and effect of the solution increase. However, the additional execution time reduces the efficiency of obtaining solutions. The maximum batching and picking chain lengths are set as and , respectively.
- (3)
Annealing parameter (): The variable represents the annealing frequency and represents a parameter whose value is set at 1; moreover, .
- (4)
Stopping criterion: To avoid falling into infinite loops, a terminal temperature and computation time are set.
The SA algorithm steps are described as follows:
Step 1: Set the starting temperature as , the number of maximum order items as , number of minimum order items as , the Boltzmann constant as , the number of orders as , the maximum location of an item as , the minimum location of an item as , the maximum capacity in terms of weight as , the minimum capacity as , the annealing parameter as , the maximum picking chain length as , the maximum batching chain length as , and the starting chain length as and .
Step 2: For each order, randomly generate the weight of the order , and set the order item numbers as and the item location as .
Step 3: Assign orders to batches according to the order sequence; specifically, the order number corresponds to the batch number. Assume that the results acquired are from the initial batching solution. Moreover, assign , , and to the corresponding batches, and set the initial batching solution as the current batching solution .
Step 4: Using the sequence as the picking order of the initial batching solution, start from the minimum and proceed to the maximum. In addition, set the current picking order as , calculate the picking distance of each batch , and sum all batch distances to obtain the current total distance . Set the optimal total distance as = , the optimal picking order as = , and the optimal batch as = , and then, proceed to Step 6.
Step 5: In , randomly select the swap or mutation procedure to generate the neighboring batching solution , and then, proceed to Step 6.
Step 6: In the current picking order, randomly choose the swap or insertion procedure to generate neighboring solutions for the picking order .
Step 7: Calculate the picking distance of each batch according to , and sum the distances of all batches to obtain the total distance of the neighboring picking order .
Step 8: Calculate the objective value deviation .
Step 9: Determine whether . If yes, proceed to Step 10; otherwise, proceed to Step 13.
Step 10: Substitute with , and then, proceed to Step 11.
Step 11: When the solutions are substituted, reset the picking chain length as and proceed to Step 12.
Step 12: If , then proceed to Step 15; otherwise, substitute with .
Step 13: According to the uniform (0,1), generate a random probability value and proceed to Step 14.
Step 14: Determine whether . If yes, return to Step 10; otherwise, proceed to Step 15.
Step 15: Determine whether is . If yes, then perform Step 16; otherwise, return to Step 6.
Step 16: Execute the annealing procedure. Set the picking temperature as and the picking chain length as ; subsequently, proceed to Step 17.
Step 17: Determine whether the picking temperature . If yes, then export and proceed to Step 18; otherwise, return to Step 7.
Step 18: Calculate the objective value deviation .
Step 19: Determine whether . If yes, proceed to Step 22; otherwise, proceed to Step 20.
Step 20: According to the uniform (0, 1), generate a random probability value .
Step 21: Determine whether . If yes, then proceed to Step 22; otherwise, return to Step 5.
Step 22: Substitute with , and then, proceed to Step 23.
Step 23: When the solutions are substituted, reset the batching chain length as = + 1 and proceed to Step 24.
Step 24: If , then substitute with and proceed to Step 25. Otherwise, no substitution procedure is required; proceed to Step 25.
Step 25: Determine whether the batching chain length . If yes, perform Step 26; otherwise, return to Step 6.
Step 26: Perform the annealing procedure. Set the batching temperature as and the batching chain length as and proceed to Step 27.
Step 27: Determine whether the batching terminal temperature is lower than or the computation time is met. If yes, end the procedure; otherwise, return to Step 5.
4.6. VNS Algorithm
Compared with the SA algorithm, the VNS algorithm involves fewer parameters, thus rendering it relatively easy to control during its application. In this algorithm, a problem is divided into two stages: batching and picking. The picking distance must be recalculated with every batching substitution. Hence, the process consistently proceeds to picking insertion and swapping. Compared with swapping, insertion can be used to search for solutions in a wider range; therefore, insertion was adopted as the first neighborhood when searching neighboring picking routes. After completing the search process in the first neighborhood, we proceeded to search the second neighborhood, adopting picking swapping. The eventual export value of the picking distance obtained from a complete search of all neighborhoods represents the objective value of batching neighboring solutions. Next, we compared the search results with the current solution until all mutated neighborhoods in the batch were searched. Subsequently, we proceeded with the search process through batch swapping. Batch mutation was applied first because it can quickly consolidate orders into batches. By contrast, batch swapping is less effective in reducing the number of batches.
The VNS algorithm begins to solve the problem from the initial batching solution. With each substitution of neighboring mutation or swapping solutions, the search process must proceed to the neighboring picking solutions to calculate the objective distance value. The search process begins with picking swapping, and all solutions are calculated and compared with the optimal solutions. Subsequently, the search proceeds with picking insertion; the solutions are also calculated and compared with the optimal solutions, and an objective value representing the neighboring batching solution is exported. Batching mutation is applied to ensure that the solutions change rapidly and to eliminate local solutions. In comparison, the batch-swapping procedure is less effective.
The steps of the VNS algorithm are as follows:
Step 1: First, identify the objective function value, current optimal solution, current solution, and number of iterations.
Step 2: Construct the initial batching, examine whether the construction corresponds to the vehicle capacity. If the construction corresponds to the vehicle capacity, then construct an initial picking route and proceed to the next step; otherwise, repeat the construction process.
Step 3: Assuming that the iteration number , use mutation and swapping procedures to improve the current batching solution. Next, examine whether the new solution corresponds to the vehicle capacity. If yes, then the new solution is adopted as a neighboring solution of this step; otherwise, return to Step 3. If the solution is improved, then update the current solution with , recalculate , and re-execute Step 3; otherwise, proceed to Step 4.
Step 4: Adopt the insertion or swapping procedure to improve the current solution and assess whether the new solution corresponds to the vehicle capacity. If yes, then the new solution is adopted as a neighboring solution of this step; otherwise, return to Step 4. If the solution is improved, then update the current solution P with P_neigh, recalculate count = count + 1, and re-execute Step 4; otherwise, proceed to Step 5.
Step 5: Examine whether count = 0. If yes, then proceed to Step 6; otherwise, return to Step 3.
Step 6: Conduct a perturbation process on the current solution. Specifically, S_ratio * number of orders = number of perturbations. Proceed to other neighborhoods, apply mutation and swapping procedures to improve the current batching solution, and examine whether the current solution corresponds to vehicle capacity. If yes, then the solution after the perturbation process is derived; otherwise, repeat the perturbation process.
Step 7: Examine whether the terminating condition of the solution searching time has been satisfied. If yes, then terminate the algorithm; otherwise, return to Step 3.
6. Conclusions
In this study, we investigated how warehouses can effectively divide received orders into batches, obtain efficient picking routes for each batch to achieve the shortest total distance, and consequently, reduce costs and enhance competitiveness. In small-scale problems, the exhaustion method may be applied to determine the optimal solution, but as the number of orders increases and the problems become more complex, an algorithm becomes indispensable for efficiently obtaining solutions.
The basic limitation of this study is that the same order cannot be divided into different batches, and the capacity of the picking vehicle will be greater than that of any single order; therefore, this study is more applicable to retail items purchased by general consumers, that is, small- and medium-sized online shopping retail warehouses or traditional retail warehouses with a large number of items. Each order contains several items, and the quantity of each item is only one to several pieces. Furthermore, all orders are known in advance and order insertion/removal are not allowed. This means that the algorithm for static problems is considered. This is mainly because most of the picking is a daily routine, and therefore, in the general retail industry, there is rarely a need to adjust the order in time.
For this order-batching and picking-route problem, we mainly introduce two-stage SA and VNS algorithms based on a set of neighborhood search algorithms. The concept is clear and easy to understand, and the solution speed is excellent. In addition, for such research, it is easy to extend to various single-solution-based algorithms such as tabu search and iterated local search because the concept of the algorithm is clear. Moreover, with even a little adjustment, it is easy to apply methods to swarm intelligence algorithms.
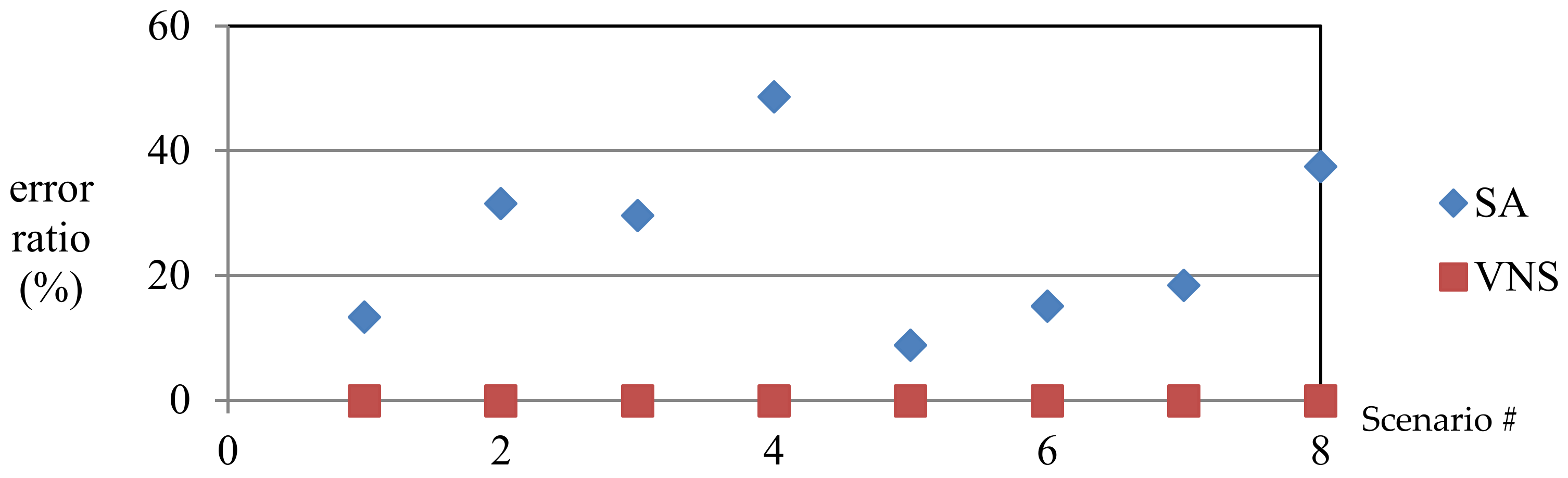
Five initial order-batching methods are proposed; we further tested these solutions under eight scenarios and with three random seeds. The results revealed that the BFD method yielded favorable results under all scenarios. In addition, the chain length and perturbation factors of the solutions were considered. Finally, the SA and VNS algorithms were incorporated into the solution comparisons. The algorithm processes were divided into two stages: The first stage involved batching, and the second stage involved optimizing the route. Under various scenarios, the VNS algorithm returned more favorable solutions than did the SA algorithm; moreover, the VNS algorithm demonstrated a faster solving speed. By contrast, the SA algorithm exhibited a slow solving speed in large-scale problems and converged slowly.
This study takes the conventional rectangular warehouse layout as an example layout. However, in practical applications, the layouts of almost all warehouses are different. This does not affect the algorithm design of order batching, but only affects the optimal picking distance between any two points in the order-picking-route problem. The distance between any two points can be obtained by calculating the minimum distance between any two points in advance, that is, it does not affect the implementation of the overall algorithm. Therefore, in practical applications, for the retail industry, small- and medium-sized online shopping retail warehouses or traditional retail warehouse can utilize this two-stage algorithm for their daily routine picking jobs. As for the picking of large objects in practice, the picking efficiency can be measured over time by increasing the picking time of some picking points. The objective can be adjusted to the minimal picking time and the concept of the whole two-stage algorithm can still be applied.
In further studies, this topic could be divided into three aspects to discuss. First, some restrictions could be loosened in the problem. For example, the same order could be divided into different batches, the picking time could be used to measure the picking efficiency, and different types of picking container equipment could be considered. Secondly, more effective initial batching methods could be developed because a good initial batching solution can save much computational time. Some metaheuristic algorithms newly developed in recent years, such as the spotted hyena optimizer (SHO) and dandelion algorithm (DA), could be developed for this problem because of their simple steps and fast computation. Finally, more warehouse layouts could be covered in the study in order to test the pros and cons of the proposed algorithm.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}