
FastDARTSDet: Fast Differentiable Architecture Joint Search on Backbone and FPN for Object Detection

 ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Object Detection
2.2. One-Shot Architecture Search
2.3. NAS for Object Detection
3. Method
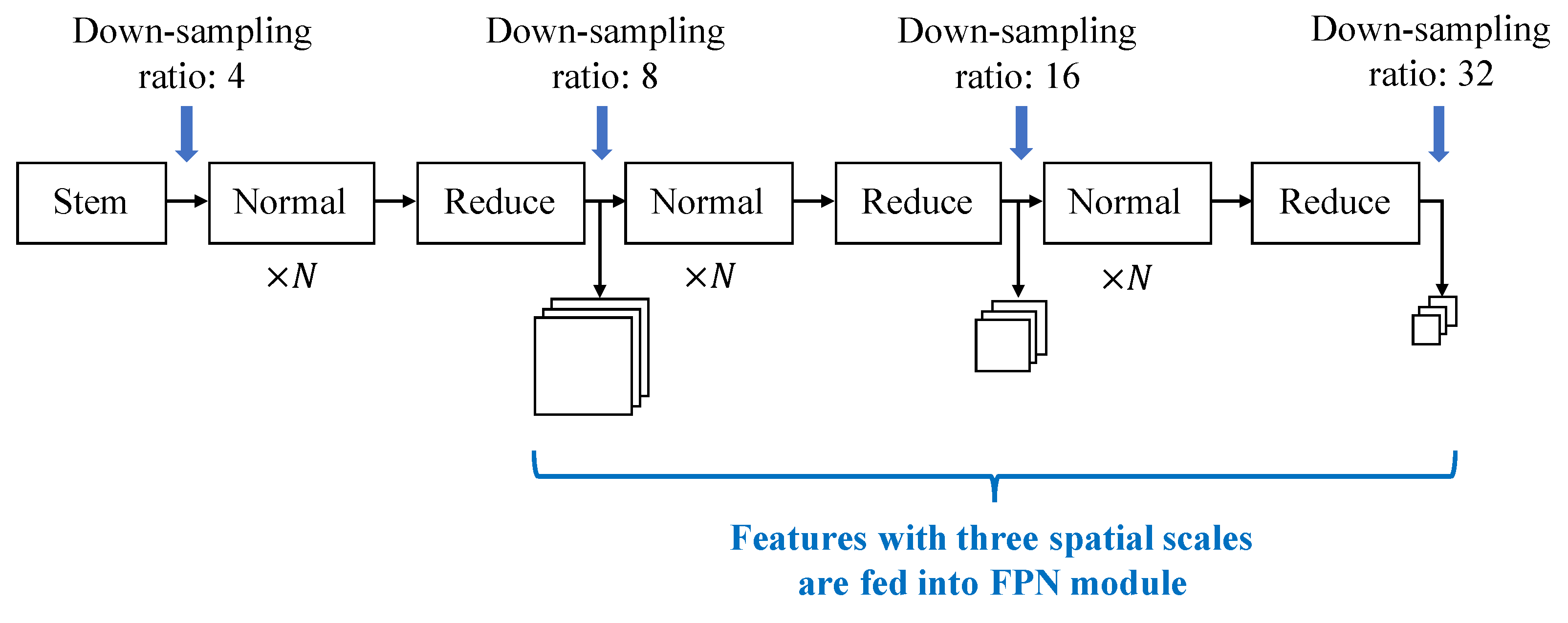
3.1. Search Space
3.1.1. Search Space for Backbone
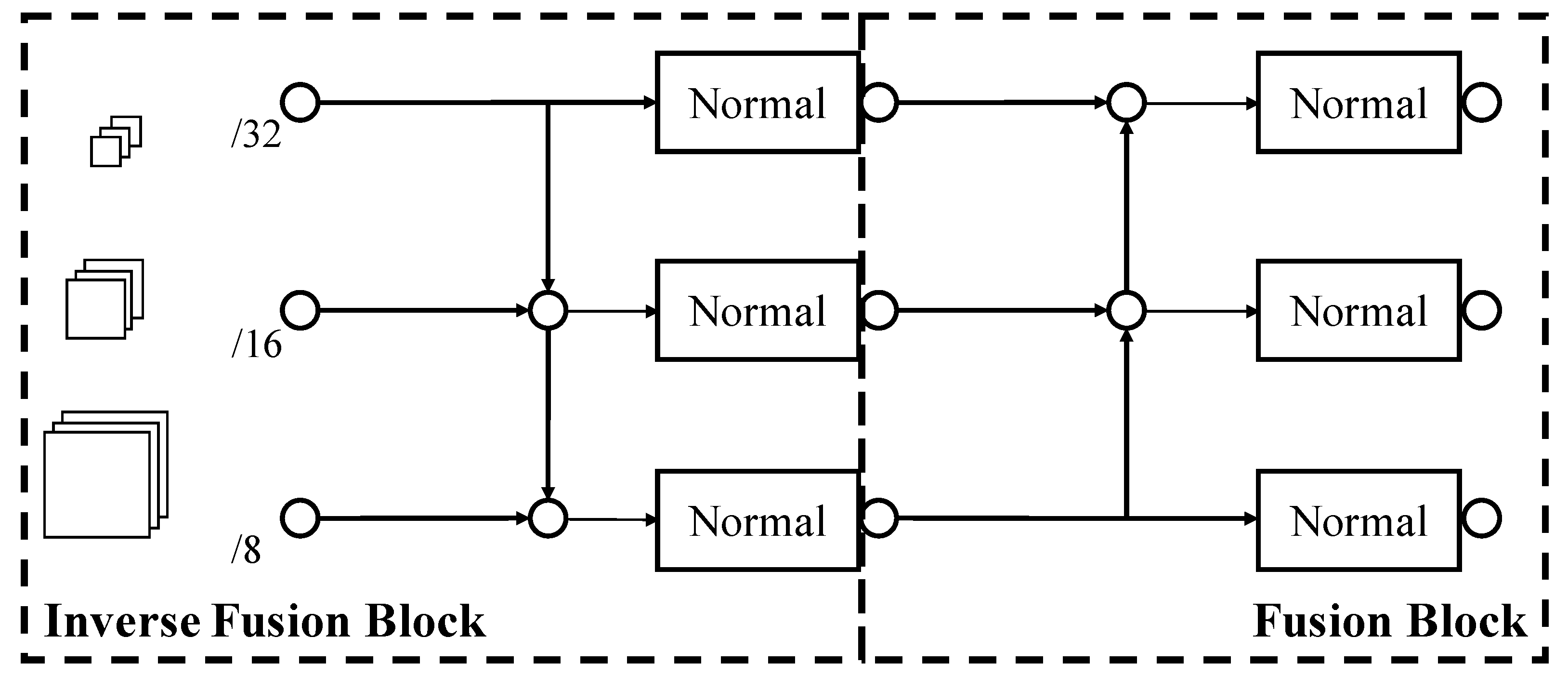
3.1.2. Search Space for FPN
3.2. The Proposed FastDARTSDet
4. Experiments
4.1. Protocols
4.1.1. MS-COCO Dataset
4.1.2. Experimental Settings
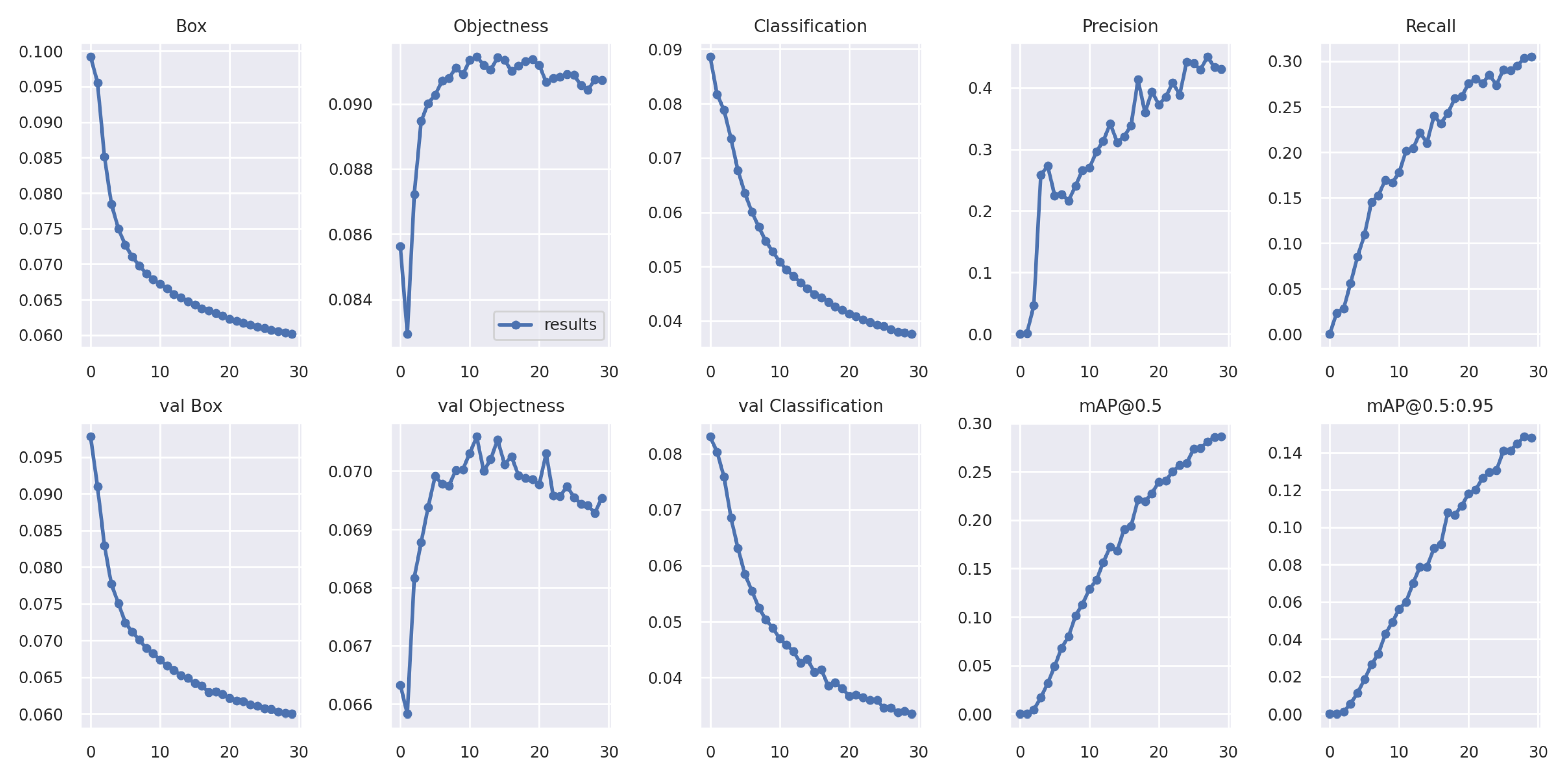
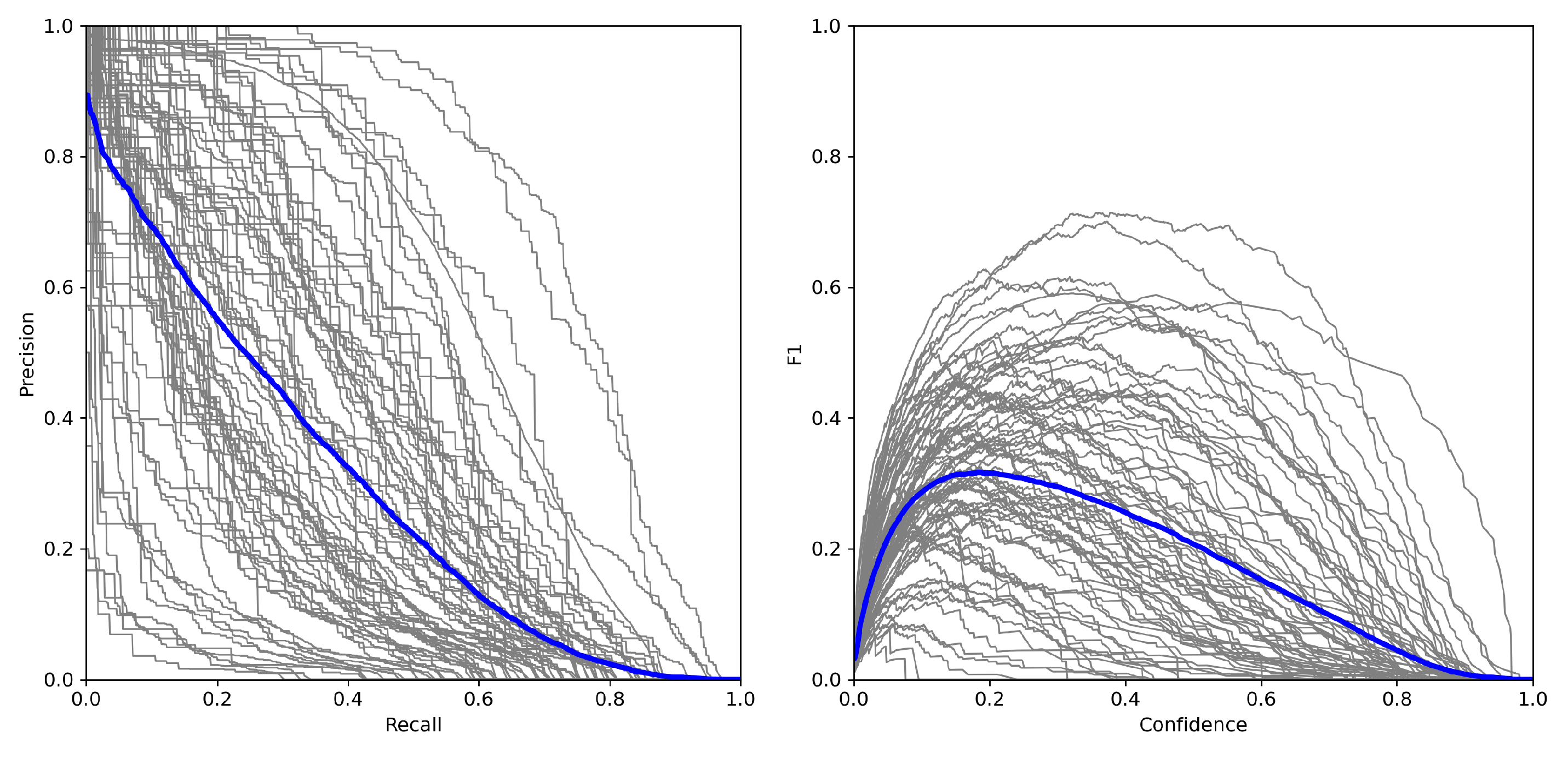
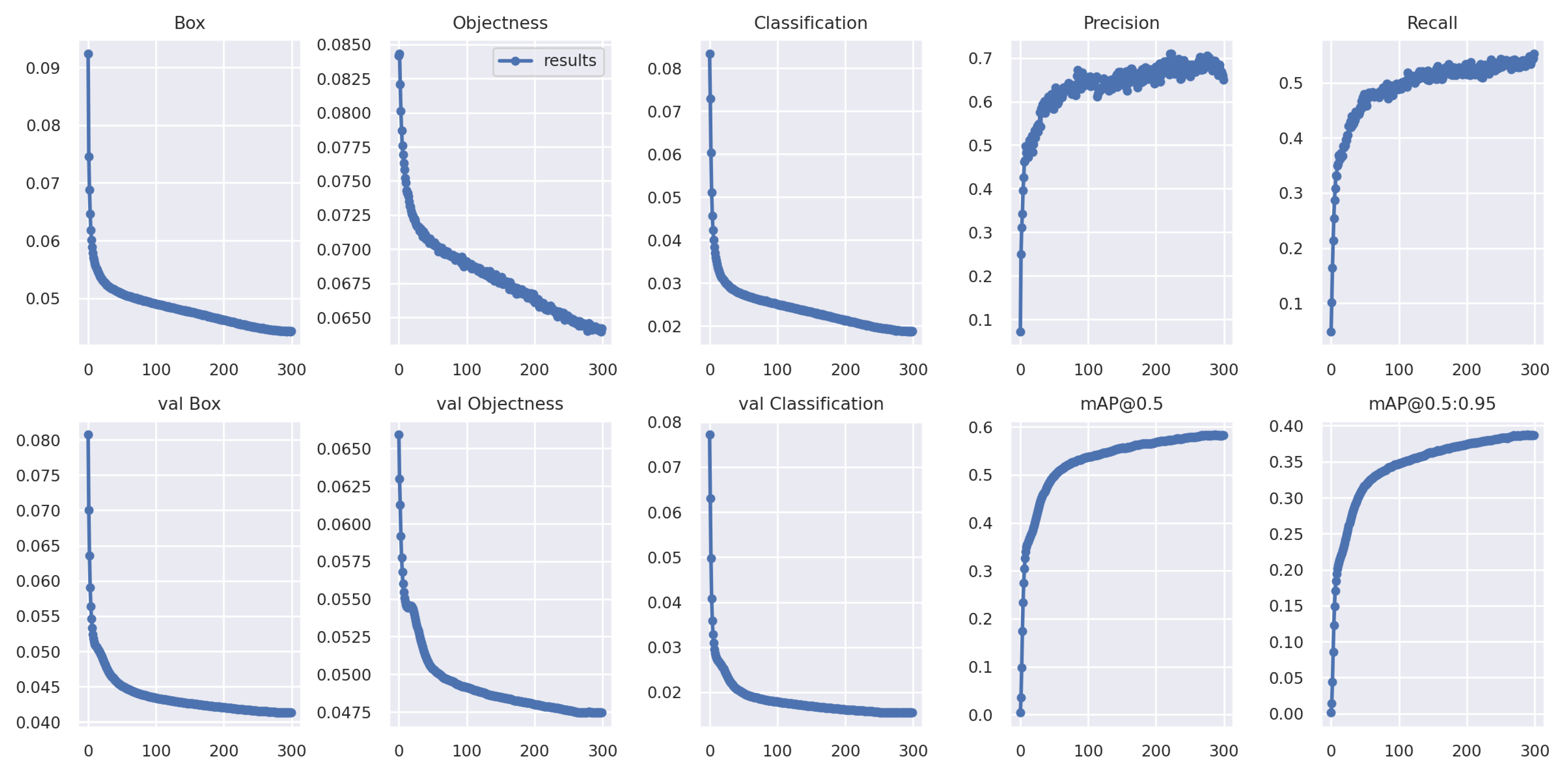
4.2. Performance of the Supernet
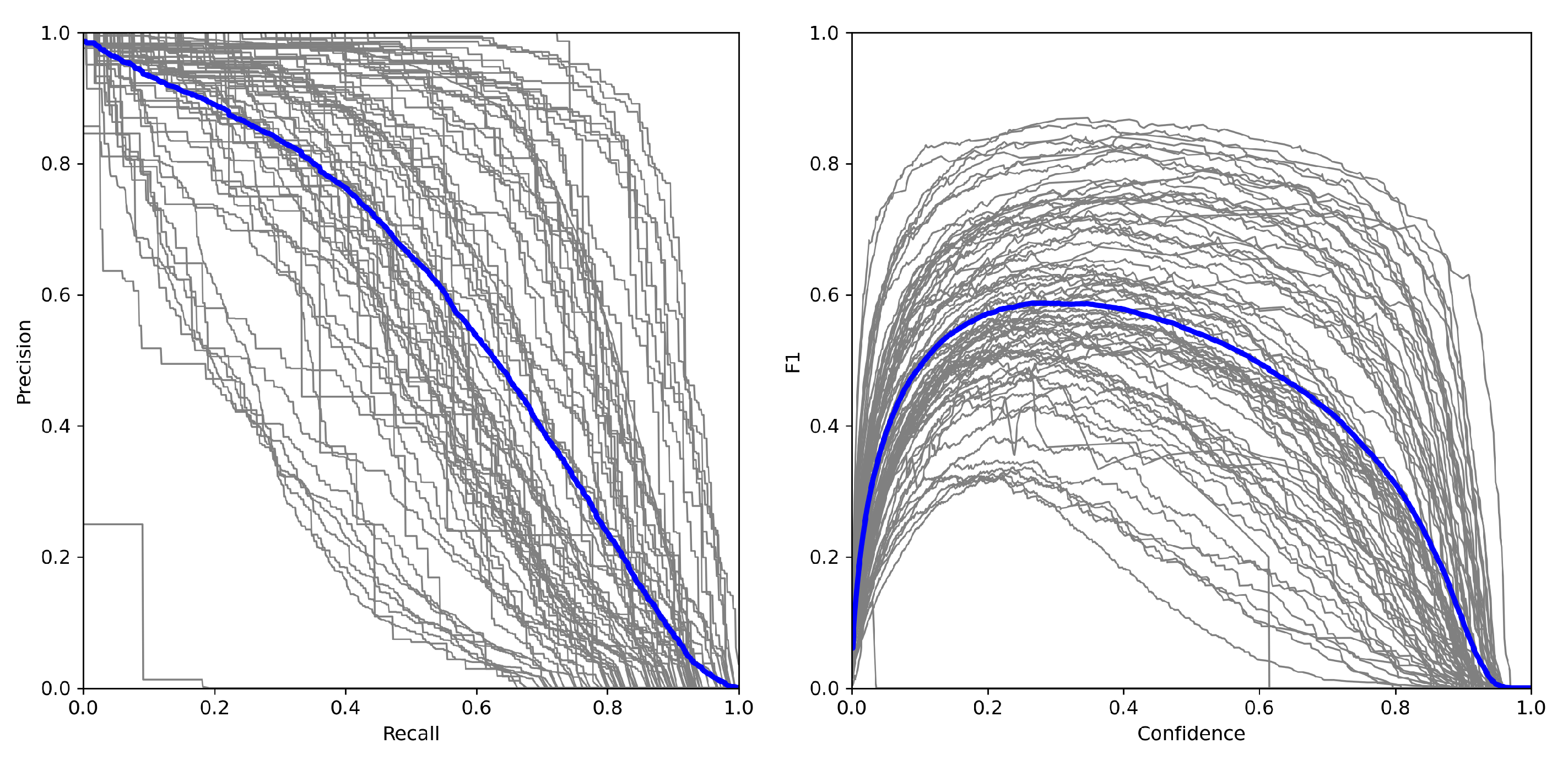
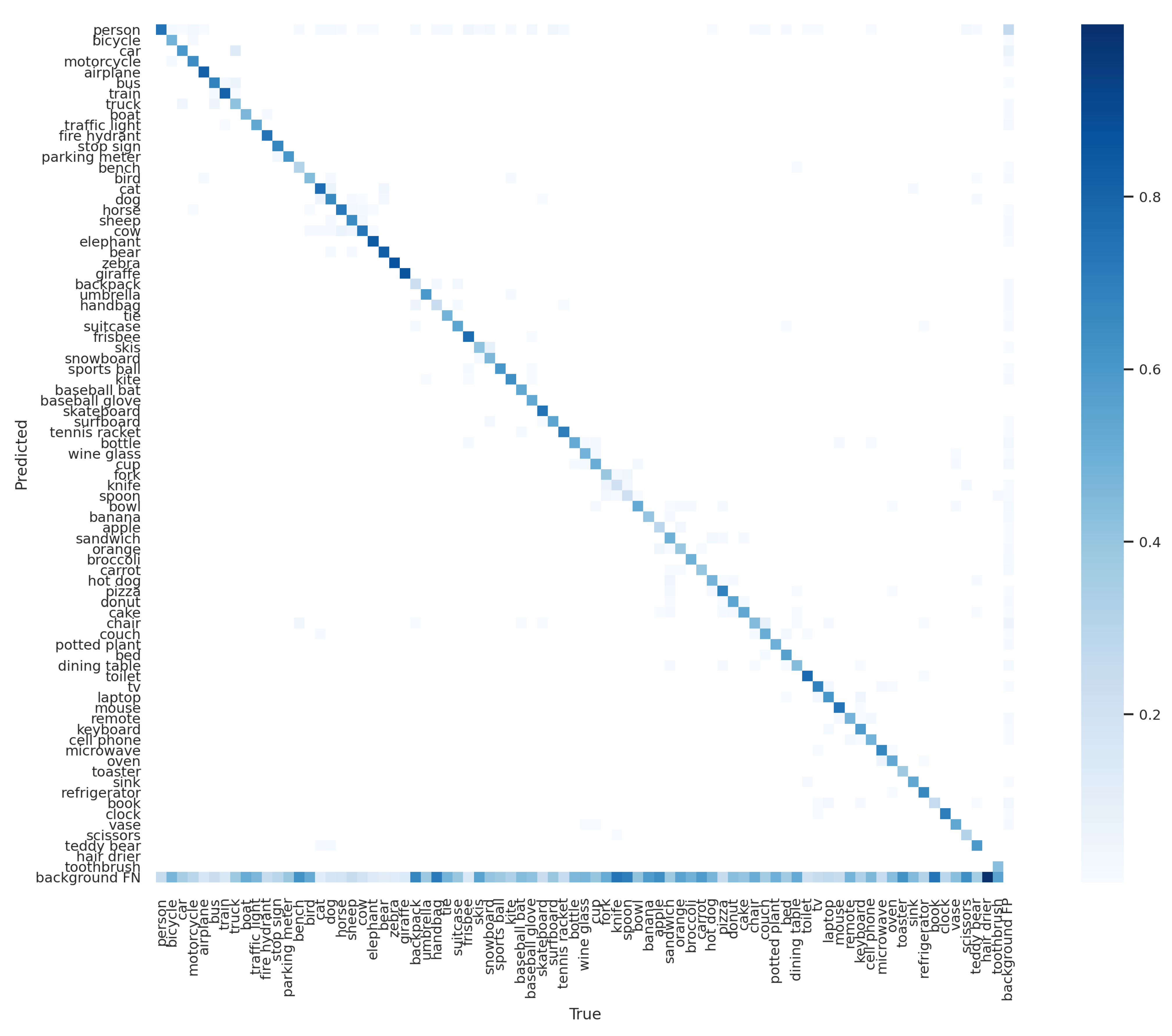
4.3. Performance of the Searched Model
4.4. Ablation Study
4.5. Comparison with Prior Methods
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Cao, J.; Mao, D.; Cai, Q.; Li, H.; Du, J. A review of object representation based on local features. J. Zhejiang Univ. Sci. C 2013, 14, 495–504. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Kou, F.; Du, J.; Lin, Z.; Liang, M.; Li, H.; Shi, L.; Yang, C. A semantic modeling method for social network short text based on spatial and temporal characteristics. J. Comput. Sci. 2018, 28, 281–293. [Google Scholar] [CrossRef]
- Li, W.; Sun, J.; Jia, Y.; Du, J.; Fu, X. Variance-constrained state estimation for nonlinear complex networks with uncertain coupling strength. Digit. Signal Process. 2017, 67, 107–115. [Google Scholar] [CrossRef]
- Li, W.; Jia, Y.; Du, J.; Yu, F. Gaussian mixture PHD filter for multi-sensor multi-target tracking with registration errors. Signal Process. 2013, 93, 86–99. [Google Scholar] [CrossRef]
- Li, Q.; Du, J.; Song, F.; Chao, W.; Liu, H.; Cheng, L. Region-based multi-focus image fusion using the local spatial frequency. In Proceedings of the 25th Chinese Control and Decision Conference, CCDC, Guiyang, China, 25–27 May 2013. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing Neural Network Architectures using Reinforcement Learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhong, Z.; Yan, J.; Wu, W.; Shao, J.; Liu, C. Practical Block-Wise Neural Network Architecture Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2423–2432. [Google Scholar] [CrossRef] [Green Version]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Pham, H.; Guan, M.Y.; Zoph, B.; Le, Q.V.; Dean, J. Efficient Neural Architecture Search via Parameter Sharing. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Xue, C.; Wang, X.; Yan, J.; Li, C.G. A Max-Flow based Approach for Neural Architecture Search. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022. [Google Scholar]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Suematsu, Y.L.; Tan, J.; Le, Q.V.; Kurakin, A. Large-scale evolution of image classifiers. In Proceedings of the International Conference on Machine Learning, ICML, Sydney, Australia, 6–8 August 2017. [Google Scholar]
- Liu, H.; Simonyan, K.; Vinyals, O.; Fernando, C.; Kavukcuoglu, K. Hierarchical Representations for Efficient Architecture Search. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized Evolution for Image Classifier Architecture Search. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, AAAI, Honolulu, HI, USA, 27 January–1 February 2019; pp. 4780–4789. [Google Scholar]
- Miikkulainen, R.; Liang, J.; Meyerson, E.; Rawal, A.; Fink, D.; Francon, O.; Raju, B.; Shahrzad, H.; Navruzyan, A.; Duffy, N.; et al. Evolving deep neural networks. In Artificial Intelligence in the Age of Neural Networks and Brain Computing; Elsevier: Amsterdam, The Netherlands, 2019; pp. 293–312. [Google Scholar]
- Xie, L.; Yuille, A.L. Genetic CNN. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Venice, Italy, 22–29 October 2017; pp. 1388–1397. [Google Scholar] [CrossRef]
- Elsken, T.; Metzen, J.H.; Hutter, F. Efficient Multi-Objective Neural Architecture Search via Lamarckian Evolution. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Bender, G.; Kindermans, P.; Zoph, B.; Vasudevan, V.; Le, Q.V. Understanding and Simplifying One-Shot Architecture Search. In Proceedings of the International Conference on Machine Learning, ICML, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable Architecture Search. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Xu, Y.; Xie, L.; Zhang, X.; Chen, X.; Qi, G.J.; Tian, Q.; Xiong, H. PC-DARTS: Partial Channel Connections for Memory-Efficient Architecture Search. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, X.; Xue, C.; Yan, J.; Yang, X.; Hu, Y.; Sun, K. MergeNAS: Merge Operations into One for Differentiable Architecture Search. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, IJCAI, Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Bi, K.; Hu, C.; Xie, L.; Chen, X.; Wei, L.; Tian, Q. Stabilizing DARTS with Amended Gradient Estimation on Architectural Parameters. arXiv 2019, arXiv:1910.11831. [Google Scholar]
- Zela, A.; Elsken, T.; Saikia, T.; Marrakchi, Y.; Brox, T.; Hutter, F. Understanding and Robustifying Differentiable Architecture Search. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; Keutzer, K. FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xie, S.; Zheng, H.; Liu, C.; Lin, L. SNAS: Stochastic neural architecture search. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Dong, X.; Yang, Y. Searching for a Robust Neural Architecture in Four GPU Hours. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 15–20 June 2019; pp. 1761–1770. [Google Scholar]
- Chen, X.; Xie, L.; Wu, J.; Tian, Q. Progressive differentiable architecture search: Bridging the depth gap between search and evaluation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1294–1303. [Google Scholar]
- Chen, Y.; Yang, T.; Zhang, X.; Meng, G.; Xiao, X.; Sun, J. DetNAS: Backbone Search for Object Detection. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 6638–6648. [Google Scholar]
- Jiang, C.; Xu, H.; Zhang, W.; Liang, X.; Li, Z. SP-NAS: Serial-to-Parallel Backbone Search for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 11860–11869. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 7036–7045. [Google Scholar] [CrossRef] [Green Version]
- Xu, H.; Yao, L.; Li, Z.; Liang, X.; Zhang, W. Auto-FPN: Automatic Network Architecture Adaptation for Object Detection Beyond Classification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 6648–6657. [Google Scholar] [CrossRef]
- Wang, N.; Gao, Y.; Chen, H.; Wang, P.; Tian, Z.; Shen, C.; Zhang, Y. NAS-FCOS: Fast Neural Architecture Search for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 11940–11948. [Google Scholar] [CrossRef]
- Yao, L.; Xu, H.; Zhang, W.; Liang, X.; Li, Z. SM-NAS: Structural-to-modular neural architecture search for object detection. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. ECCV; Lecture Notes in Computer Science; Fleet, D.J., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Zurich, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Video Database with Scalable Annotation Tooling. arXiv 2018, arXiv:abs/1805.04687. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:abs/1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. YOLOv5 Documentation. Available online: https://docs.ultralytics.com/ (accessed on 3 August 2020).
- Wang, X.; Lin, J.; Yan, J.; Zhao, J.; Yang, X. EAutoDet: Efficient Architecture Search for Object Detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: Design backbone for object detection. In Proceedings of the European Conference on Computer Vision, ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Washington, DC, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. In Proceedings of the AAAI Conference on Artificial Intelligence, AAAI, Virtually, 2–9 February 2021. [Google Scholar]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In Proceedings of the International Conference on Machine Learning, ICML, Virtual, 18–24 July 2021. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-Oriented Object Detection with Circular Smooth Label. In Proceedings of the European Conference on Computer Vision, ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense Label Encoding for Boundary Discontinuity Free Rotation Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Virtual, 20–25 June 2021. [Google Scholar]
- Yang, X.; Yan, J. On the Arbitrary-Oriented Object Detection: Classification based Approaches Revisited. Int. J. Comput. Vis. 2022, 130, 1340–1365. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning High-Precision Bounding Box for Rotated Object Detection via Kullback-Leibler Divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. SCRDet++: Detecting Small, Cluttered and Rotated Objects via Instance-Level Feature Denoising and Rotation Loss Smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 2022, 1. [Google Scholar] [CrossRef] [PubMed]
- Nayman, N.; Noy, A.; Ridnik, T.; Friedman, I.; Jin, R.; Zelnik-Manor, L. XNAS: Neural Architecture Search with Expert Advice. Adv. Neural Inf. Process. Syst. 2019, 32, 1975–1985. [Google Scholar]
- Zhou, H.; Yang, M.; Wang, J.; Pan, W. BayesNAS: A Bayesian Approach for Neural Architecture Search. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7603–7613. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. TPAMI 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Du, X.; Lin, T.-Y.; Jin, P.; Ghiasi, G.; Tan, M.; Cui, Y.; Le, Q.V.; Song, X. SpineNet: Learning scale-permuted backbone for recognition and localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 11589–11598. [Google Scholar]
- Guo, J.; Han, K.; Wang, Y.; Zhang, C.; Yang, Z.; Wu, H.; Chen, X.; Xu, C. Hit-Detector: Hierarchical Trinity Architecture Search for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 11402–11411. [Google Scholar]
- Liang, T.; Wang, Y.; Tang, Z.; Hu, G.; Ling, H. OPANAS: One-Shot Path Aggregation Network Architecture Search for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Virtual, 19–25 June 2021; pp. 10195–10203. [Google Scholar]
- Wang, R.; Hua, H.; Liu, G.; Zhang, J.; Yan, J.; Qi, F.; Yang, S.; Yang, X. A Bi-Level Framework for Learning to Solve Combinatorial Optimization on Graphs. Adv. Neural Inf. Process. Syst. 2021, 34, 21453–21466. [Google Scholar]
- Bengio, Y.; Lodi, A.; Prouvost, A. Machine learning for combinatorial optimization: A methodological tour d’horizon. Eur. J. Oper. Res. 2021, 290, 405–421. [Google Scholar] [CrossRef]
- Yan, J.; Cho, M.; Zha, H.; Yang, X.; Chu, M.S. Multi-Graph Matching via Affinity Optimization with Graduated Consistency Regularization. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1228–1242. [Google Scholar] [CrossRef]
- Wang, R.; Yan, J.; Yang, X. Combinatorial Learning of Robust Deep Graph Matching: An Embedding based Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 2020, 1. [Google Scholar] [CrossRef]
- Wang, R.; Yan, J.; Yang, X. Neural Graph Matching Network: Learning Lawler’s Quadratic Assignment Problem with Extension to Hypergraph and Multiple-graph Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5261–5279. [Google Scholar] [CrossRef]
- Yan, J.; Yang, S.; Hancock, E. Learning Graph Matching and Related Combinatorial Optimization Problems. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI, Yokohama, Japan, 11–17 July 2020. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
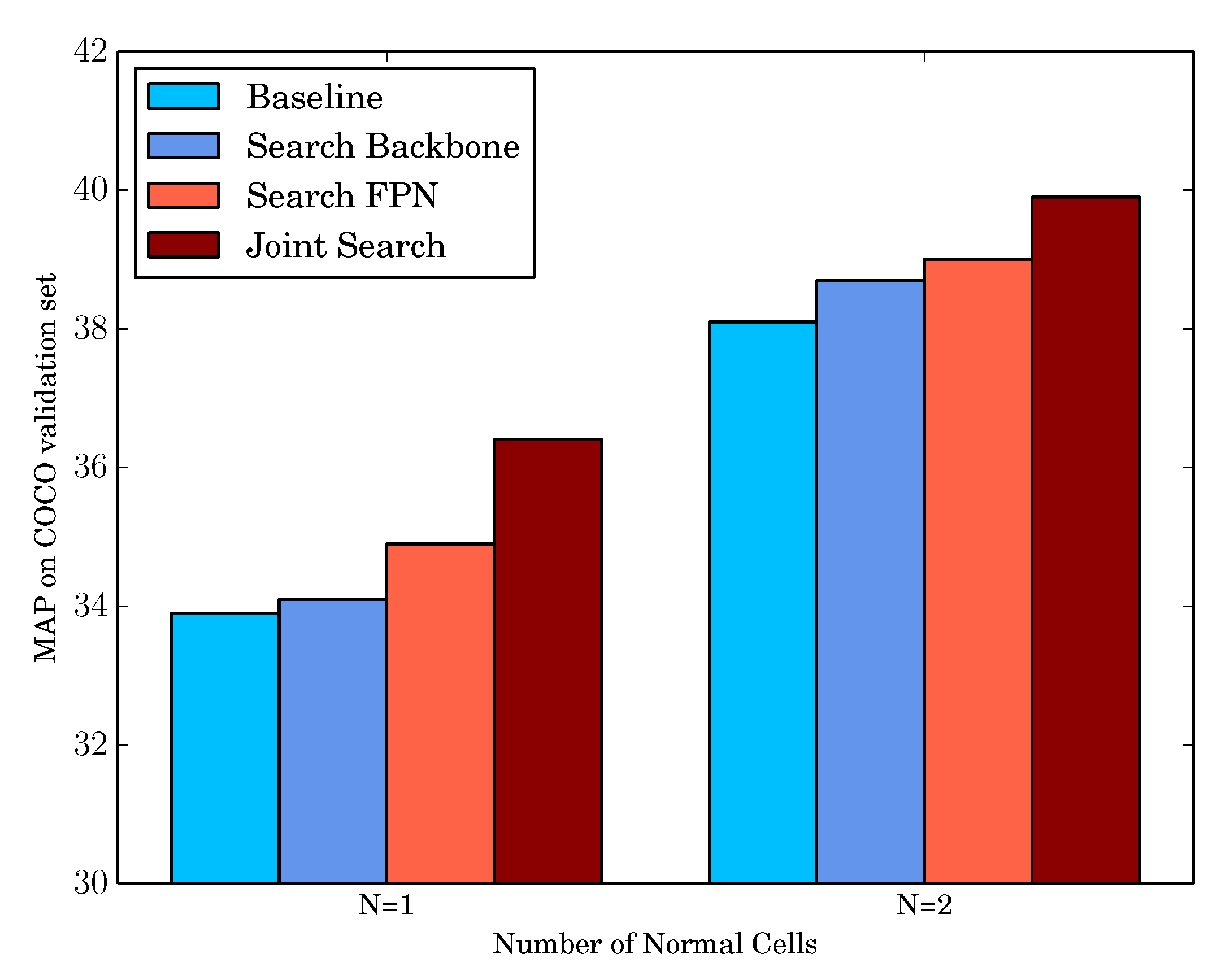
| Number of Normal Cell | Architecture | mAP | Number of Parameters | Search Cost GPU-Days | |
|---|---|---|---|---|---|
| Backbone | FPN | ||||
| N = 1 | default | default | 33.9 | 5.81 M | 1.0 |
| searched | default | 34.1 | 5.93 M | 4.2 | |
| default | searched | 34.9 | 5.87 M | 5.2 | |
| searched | searched | 36.4 | 5.76 M | 4.2 | |
| N = 2 | default | default | 38.1 | 6.82 M | 1.0 |
| searched | default | 38.7 | 7.29 M | 4.2 | |
| default | searched | 39.0 | 7.03 M | 5.2 | |
| searched | searched | 39.9 | 6.94 M | 4.2 | |
| Method | Backbone | Resolution | FPS | #Params | mAP | AP50 | AP75 | APS | APM | APL | Search |
|---|---|---|---|---|---|---|---|---|---|---|---|
| (M) | (%) | (%) | (%) | (%) | (%) | (%) | Cost | ||||
| EfficientDet-D0 [61] | Efficient-B0 | BiFPN | 512 | 3.9 | 33.8 | 52.2 | 35.8 | 12.0 | 38.3 | 51.2 | - |
| NAS-FPN [33] | Res50 | Searched | 640 | 60.3 | 39.9 | - | - | - | - | - | 333 * |
| NAS-FCOS@128 [35] | Res50 | Searched | 1333 × 800 | 27.8 | 37.9 | - | - | - | - | - | 28 |
| SpineNet-49S [62] | Searched | FPN | 640 | 11.9 | 39.5 | 59.3 | 43.1 | 20.9 | 42.2 | 54.3 | - |
| SM-NAS:E2 [36] | Search the combination | 800×600 | - | 40.0 | 58.2 | 43.4 | 21.1 | 42.4 | 51.7 | 187 | |
| EfficientDet-D1 [61] | Efficient-B1 | BiFPN | 640 | 6.6 | 39.6 | 58.6 | 42.3 | 17.9 | 44.3 | 56.0 | - |
| DetNAS [31] | Searched | FPN | 1333 × 800 | - | 42.0 | 63.9 | 45.8 | 24.9 | 45.1 | 56.8 | 44 |
| NAS-FPN [33] | Res50 | Searched | 1024 | 60.3 | 44.2 | - | - | - | - | - | 333 * |
| Auto-FPN [34] | Res50 | Searched | 800 | 32.6 | 40.5 | 61.5 | 43.8 | 25.6 | 44.9 | 51.0 | 16 |
| NAS-FCOS@256 [35] | R-101 | Searched | 1333 × 800 | 57.3 | 43.0 | - | - | - | - | - | 28 |
| SpineNet-49 [62] | Searched | FPN | 640 | 28.5 | 42.8 | 62.3 | 46.1 | 23.7 | 45.2 | 57.3 | - |
| SM-NAS:E3 [36] | Search the combination | 800 × 600 | - | 42.8 | 61.2 | 46.5 | 23.5 | 45.5 | 55.6 | 187 | |
| Hit-Detector [63] | Searched | Searched | 1200 × 800 | 27.1 | 41.4 | 62.4 | 45.9 | 25.2 | 45.0 | 54.1 | - |
| OPA-FPN@64 [64] | Res50 | Searched | 1333 × 800 | 29.5 | 41.9 | - | - | - | - | - | 4 |
| FastDARTSDet (N = 1) | Searched | Searched | 640 | 5.8 | 36.4 | 53.4 | 38.0 | 18.6 | 39.4 | 45.3 | 4.2 |
| FastDARTSDet (N = 2) | Searched | Searched | 640 | 6.9 | 40.0 | 59.4 | 41.7 | 20.5 | 41.1 | 54.3 | 4.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Wang, X.; Wang, Y.; Hu, S.; Chen, H.; Gu, X.; Yan, J.; He, T. FastDARTSDet: Fast Differentiable Architecture Joint Search on Backbone and FPN for Object Detection. Appl. Sci. 2022, 12, 10530. https://doi.org/10.3390/app122010530
Wang C, Wang X, Wang Y, Hu S, Chen H, Gu X, Yan J, He T. FastDARTSDet: Fast Differentiable Architecture Joint Search on Backbone and FPN for Object Detection. Applied Sciences. 2022; 12(20):10530. https://doi.org/10.3390/app122010530
Chicago/Turabian StyleWang, Chunxian, Xiaoxing Wang, Yiwen Wang, Shengchao Hu, Hongyang Chen, Xuehai Gu, Junchi Yan, and Tao He. 2022. "FastDARTSDet: Fast Differentiable Architecture Joint Search on Backbone and FPN for Object Detection" Applied Sciences 12, no. 20: 10530. https://doi.org/10.3390/app122010530