
Classification of Valvular Regurgitation Using Echocardiography

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
Contributions
- An automated system is designed to classify valvular regurgitation using echo with all the steps involved, such as preprocessing, keyframe extraction, segmentation, feature extraction, and classification.
- In contrast to most of the existing work where authors use image file format, here, we have used videographic images to classify valvular regurgitation.
- Using videographic images, the number of frames is large, and there may be similar frames. In this work, we have used the keyframe extraction technique, which reduces the number of frames from video and also minimizes redundancy. This is the beginning of the application of keyframe extraction in regurgitation classification. Here, the reference keyframe extraction and redundant frame keyframe extraction techniques have been incorporated.
- The data used are validated by a cardiologist in the case of classification.
- The utilization of videographic images, keyframe extraction, and methodologies such as Level set, Haralick features, and GLCM with Random Forest distinguish this research from others.
- To evaluate the robustness of the model, we have used both segmented images and non-segmented images and evaluate the performance of the model.
- The results of the proposed method are compared to several existing methodologies, and the results show that our implemented method provides higher performance accuracy than other state-of-art techniques.
2. Related Works
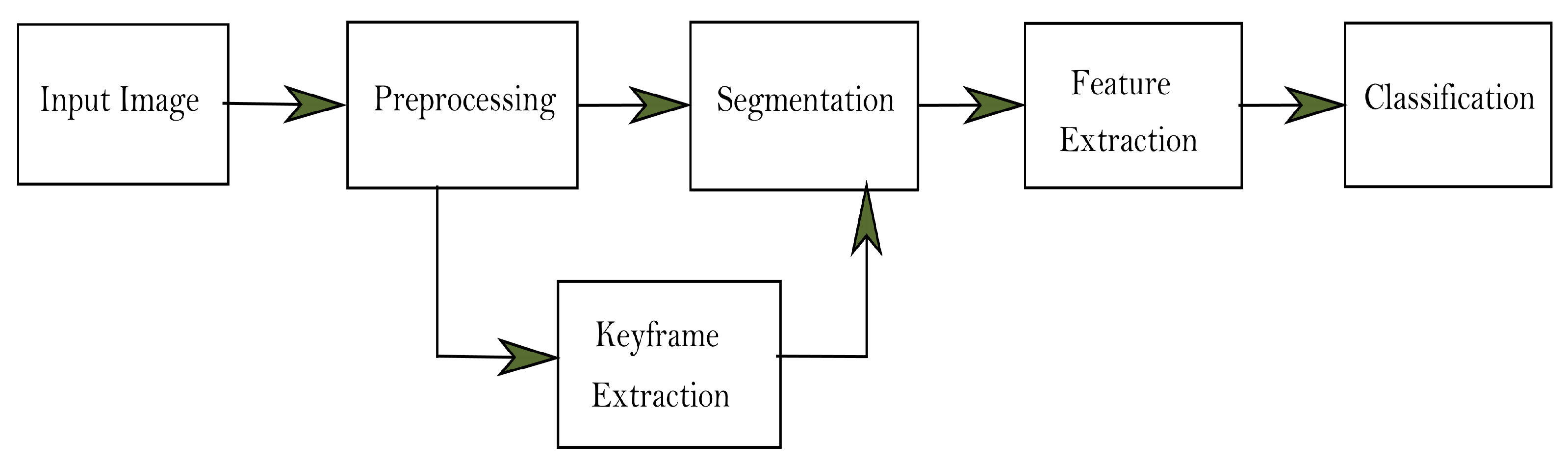
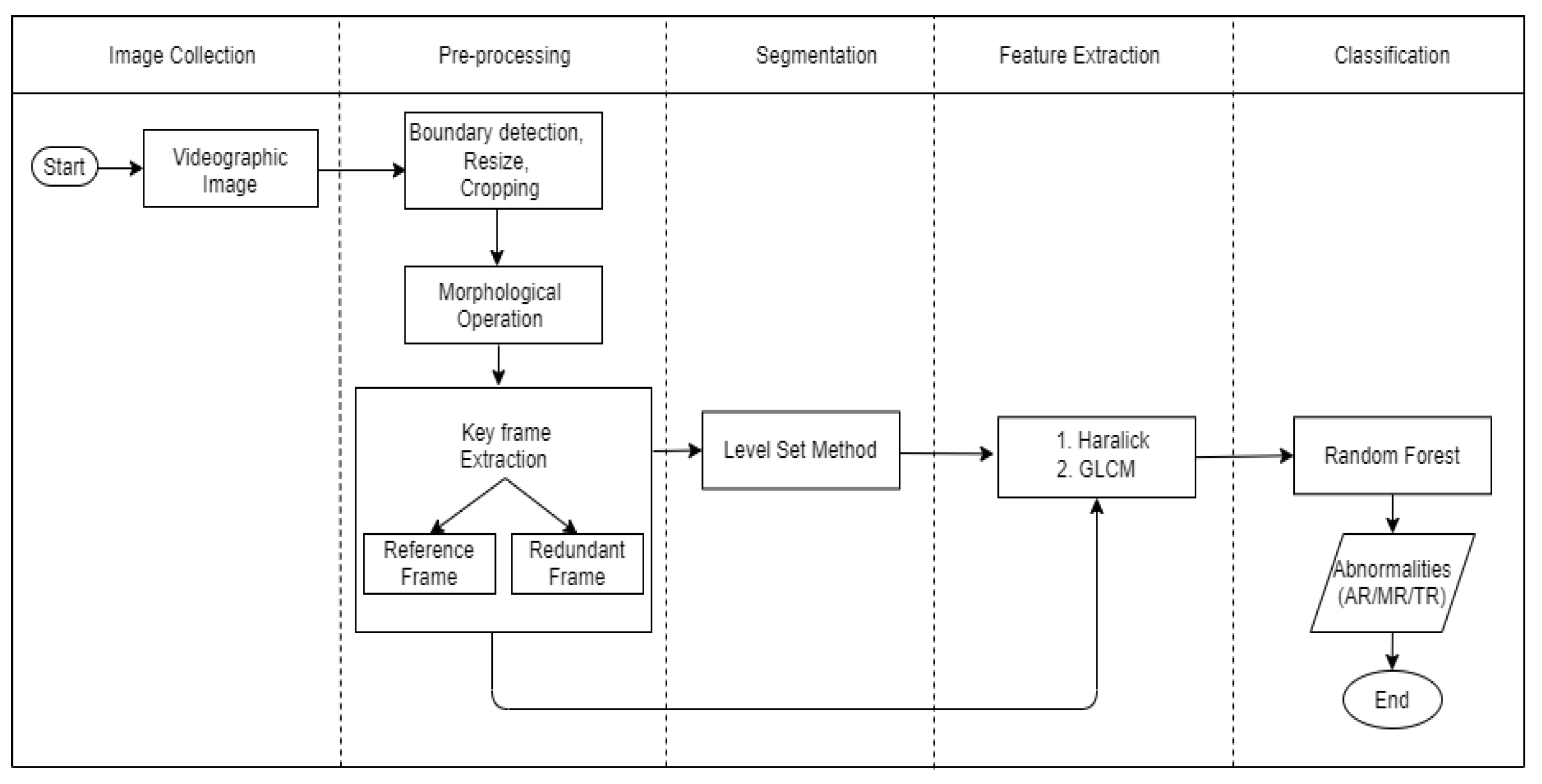
3. Methodology
3.1. Existing Methodologies Used in Proposed Methodology
3.1.1. Gray Level Cooccurrence Matrix (GLCM) and Haralick Texture Features
3.1.2. Random Forest (RF)
3.1.3. Level Set Methodology (LSM)
3.2. Proposed Methodology
3.2.1. Image Preprocessing
- Binarize the image; get the membership of each pixel using label_image.
- Using regionprops, the area of each object in an image is calculated. It measures image quantities and features.
- Sort the area and calculate the centroid of the image.
- Using ismember, the desired image is computed.
- Store the frames into a folder for each video.
3.2.2. Image Keyframe Extraction
3.2.3. Image Segmentation
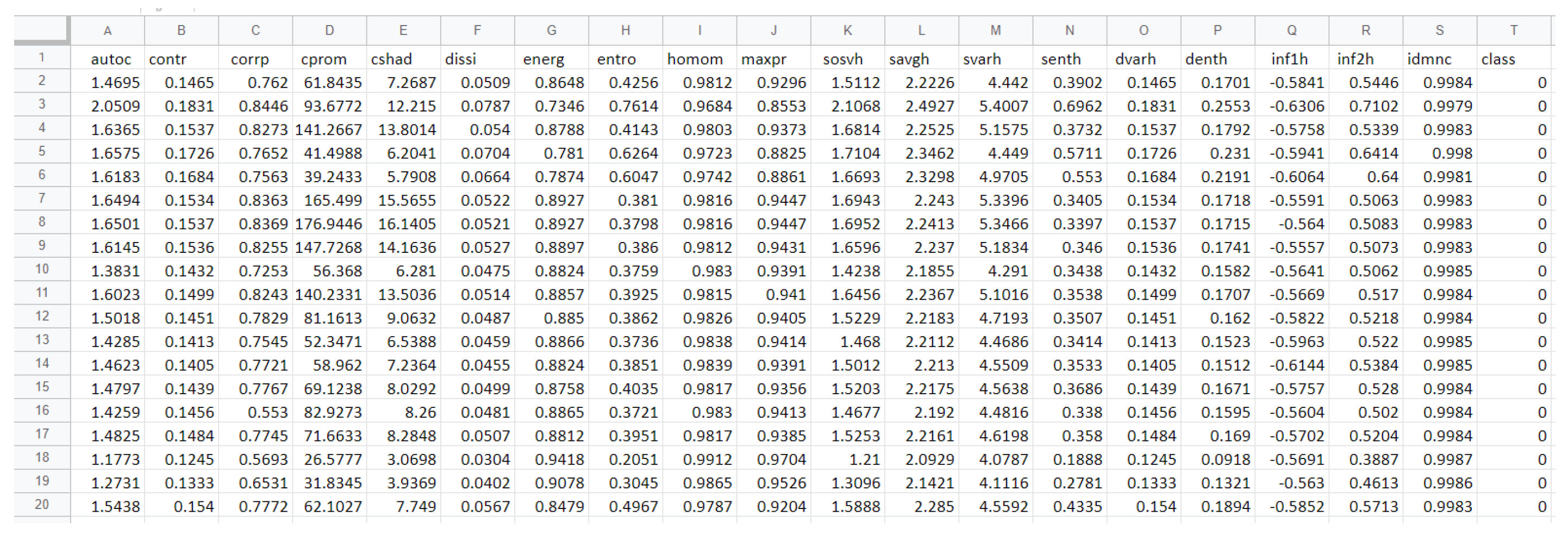
3.2.4. Feature Extraction Using GLCM Texture Features and Haralick Texture Feature
3.2.5. Classification
4. Experimental Results
4.1. Experimental Setup
4.2. Dataset
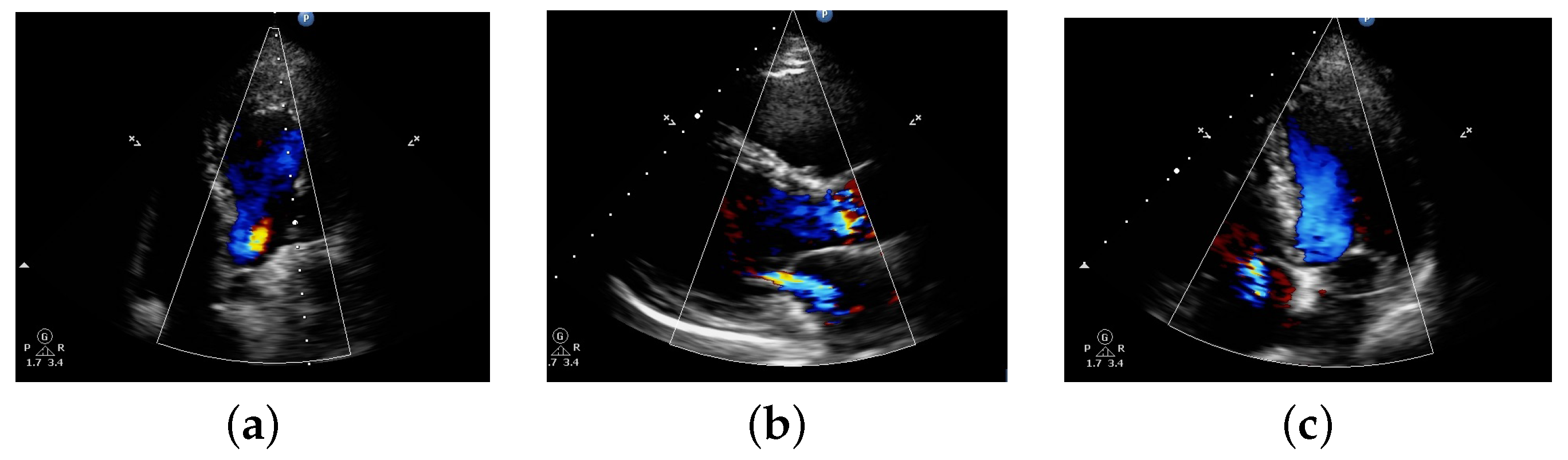
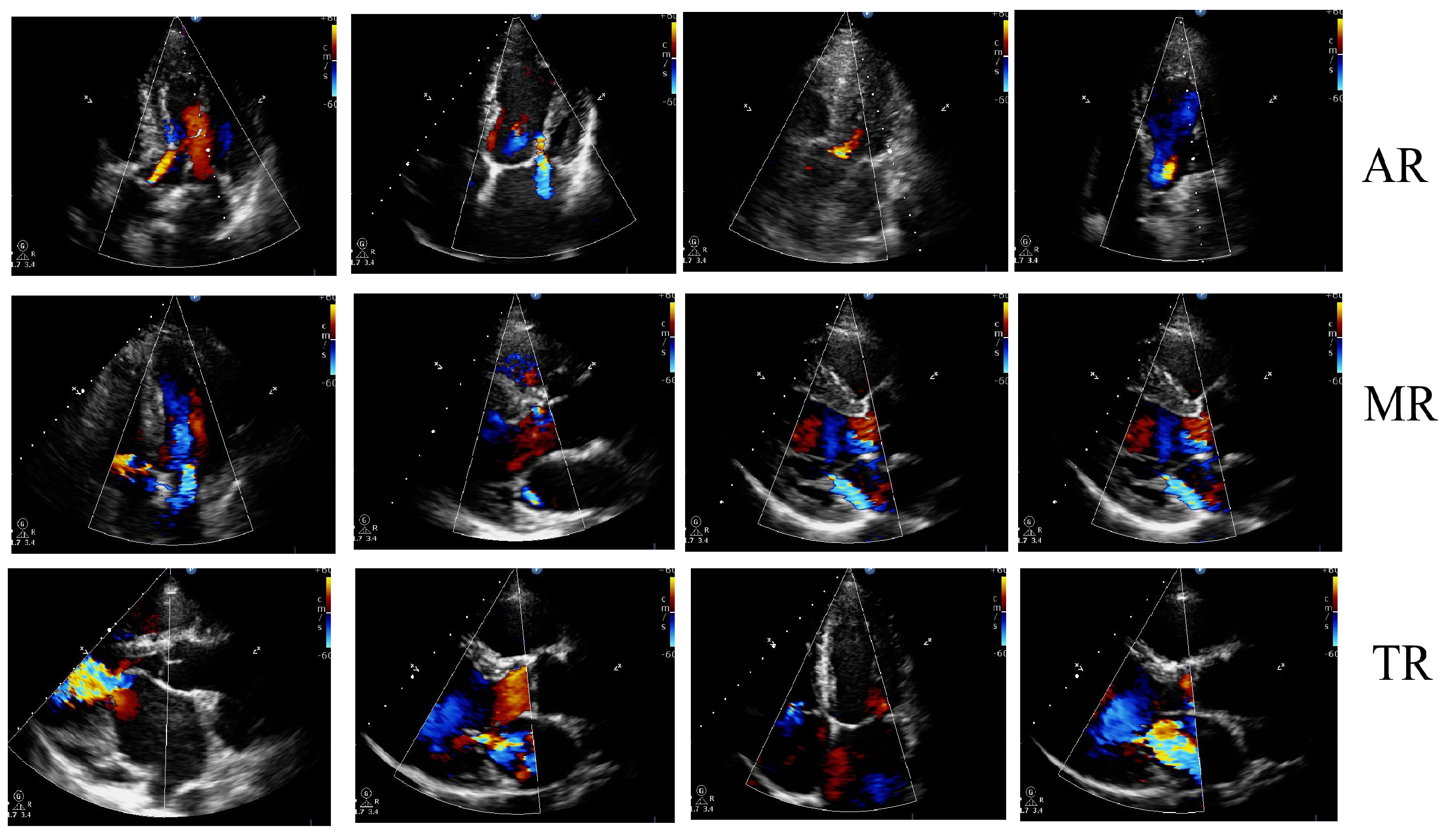
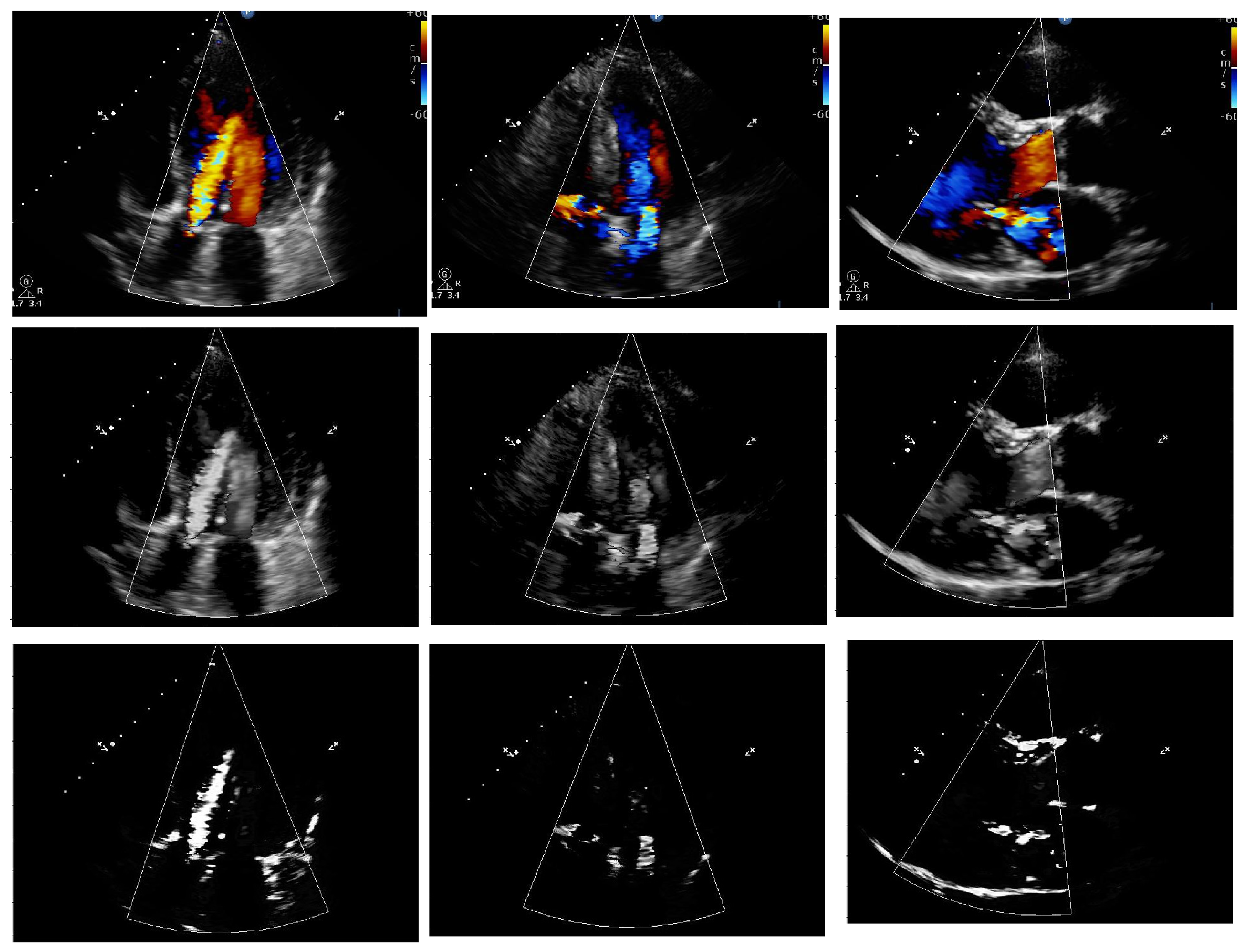
4.3. Output of Proposed Methodology
4.3.1. Preprocessing and Segmentation Output
4.3.2. Features Extracted
4.3.3. Classification Output
- Accuracy: It is the measure of correctly classified images as a percentage. It can be calculated using Equation (7).
- Precision: It is the fraction of True Positives (TP) and False Positives (FP). Precision can be calculated using Equation (8).
- Recall: It represents the fraction of True Positives (TP) and False Negatives (FN). It can be calculated using Equation (9).
- Using reference frame extraction, two-fold cross-validation highest accuracy obtained is 85.29% and 91.17% for with segmentation and without segmentation, respectively, and three-, five-, and eight-fold cross-validation highest accuracy is 100% in both cases.
- Using redundant frame extraction, the best accuracy for two-fold is 87.73% and 98.76%, three-fold is 85.91% and 94.36%, five-fold is 85.71% and 100%, and eight-fold is 84.61% and 100% for with segmentation and without segmentation, respectively.
- The overall accuracy for two-fold is 76.64% and 83.52%, three-fold is 88.69% and 86.95%, five-fold is 89.22% and 96.46%, and eight-fold is 77.50% and 95% for with segmentation and without segmentation, respectively, in the case of the reference frame, and two-fold is 69.36% and 92.39%, three-fold is 71.26% and 92.71%, five-fold is 63.14% and 96.23%, and eight-fold is 72.30% and 100% for with segmentation and without segmentation respectively in the case of the redundant frame. The overall accuracy of two-, three-, five-, and eight-fold for with and without segmentation for reference frame is 83.56% and 90.48%, respectively. The overall accuracy of two-, three-, five-, and eight-fold for with and without segmentation for reference frame is 69.01% and 95.33%, respectively.
- Using five folds provided the best result when testing data are divided into 10%, 20%, 30%, 40%and 50%.
- Based on the output obtained on the accuracy, precision, recall, and F1-score, it can be seen that in most cases, without segmentation gives a better result compared to with segmentation approach. The result that reflects this can be visualized using eight-fold cross-validation, a smaller data distribution using a reference frame.
- It can be concluded that without using segmentation can also be applied to classify regurgitation in the heart. This might not be the case for all types of diagnosis. It might not be valid for cases of data having ground truth segmentation as well. This can be true for fully unsupervised segmentation techniques and not for supervised or semisupervised segmentation. Using the redundant frame approach provides better accuracy in the case of without segmentation.
4.4. Classification Comparison with Existing Methodologies
- From Table 9, it can be observed that our method provides a better result in most cases compared to PCA-SVM and SVM without segmentation and better accuracy to both the methods in the case when using segmentation.
- In the majority of cases, using 10% testing data provides more promising results than when using 20% or more data. This is mainly due to the data size, which is small in our case.
- The highest accuracy obtained in SVM, PCA-SVM and the proposed approach is 100% which occurs once in SVM and PCA-SVM and eight times using the proposed approach.
- Another observation is made where it can be seen that using the redundant frame extraction method, the result is better when using without any segmentation while using reference frame it is better to use with segmentation. This shows that segmentation is more valid and reliable with a known parameter like ground truth than without any ground truth. Furthermore, this is an important aspect of clinical usage.
4.5. Benefits and Limitations of the Proposed Approach
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Mayoclinic: Heart Disease. Available online: https://www.mayoclinic.org/diseases474conditions/heart-disease/diagnosis-treatment/drc-20353124 (accessed on 7 April 2019).
- Wahlang, I.; Saha, G.; Maji, A.K. A Study on Abnormalities Detection Techniques from Echocardiogram. In Advances in Electrical and Computer Technologies; Springer: Singapore, 2020; pp. 181–188. [Google Scholar]
- Balaji, G.N.; Subashini, T.S.; Chidambaram, N. Automatic classification of cardiac views in echocardiogram using histogram and statistical features. Procedia Comput. Sci. 2015, 46, 1569–1576. [Google Scholar] [CrossRef] [Green Version]
- Transthoracic and Transesophogeal Echocardiography (TEE) and Stress-Echo. Available online: https://www.tcavi.com/services/transthoracic-and-transesophogeal-echocardiography-and-stress-echo/ (accessed on 5 March 2020).
- Wahlang, I.; Maji, A.K.; Saha, G.; Chakrabarti, P.; Jasinski, M.; Leonowicz, Z.; Jasinska, E. Deep Learning Methods for Classification of Certain Abnormalities in Echocardiography. Electronics 2021, 10, 495. [Google Scholar] [CrossRef]
- Lancellotti, P.; Tribouilloy, C.; Hagendorff, A.; Popescu, B.A.; Edvardsen, T.; Pierard, L.A.; Badano, L.; Zamorano, J.L. Recommendations for the echocardiographic assessment of native valvular regurgitation: An executive summary from the European association of cardiovascular imaging. Eur. Heart J. Cardiovasc. Imaging 2013, 14, 611–644. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Varadan, V.K.; Kumar, P.S.; Ramasamy, M. Left lateral decubitus position on patients with atrial fibrillation and congestive heart failure. In Nanosensors, Biosensors, Info-Tech Sensors and 3D Systems 2017; SPIE: London, UK, 2017; Volume 10167, pp. 11–17. [Google Scholar]
- Pinjari, A.K. Image Processing Techniques in Regurgitation Analysis; Jawaharlal Nehru Technological University: Anantapuram, India, 2012. [Google Scholar]
- Healthy Living. Cardiac Catheterization. Available online: https://www.heart.org/en/health501topics/heart-attack/diagnosing-a-heart-attack/cardiac-catheterization (accessed on 20 April 2019).
- Kasthuri, A. Challenges to healthcare in India-The five A’s. Indian J. Community Med. Off. Publ. Indian Assoc. Prev. Soc. Med. 2018, 43, 141. [Google Scholar]
- Kumar, R.; Wang, F.; Beymer, D.; Syeda-Mahmood, T. Cardiac disease detection fromechocardiogram using edge filtered scale-invariant motion features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 162–169. [Google Scholar]
- Allan, G.; Nouranian, S.; Tsang, T.; Seitel, A.; Mirian, M.; Jue, J.; Hawley, D.; Fleming, S.; Gin, K.; Swift, J.; et al. Simultaneous analysis of 2D echo views for left atrial segmentation and diseasedetection. IEEE Trans. Med. Imaging 2017, 36, 40–50. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Tian, L.; Li, C. Key frame extraction based on entropy difference and perceptual hash. In Proceedings of the IEEE International Symposium on Multimedia (ISM), Taichung, Taiwan, 11–13 December 2017; pp. 557–560. [Google Scholar]
- Paul, M.K.A.; Kavitha, J.; Jansi Rani, P.A. Key-frame extraction techniques: A review. Recent Patents Comput. Sci. 2018, 11, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Ali, I.H.; Al-Fatlawi, T. Key Frame Extraction Methods. Int. J. Pure Appl. Math. 2018, 119, 485–490. [Google Scholar]
- Nandagopalan, S. Efficient and Automated Echocardiographic Image Analysis Throughdata Mining Techniques; Amrita Vishwa Vidyapeetham University: Tamil Nadu, India, 2012. [Google Scholar]
- Oo, Y.N.; Khaing, A.S. Left ventricle segmentation from heart ECHO images using imageprocessing techniques. Int. J. Sci. Eng. Technol. Res. 2014, 3, 1606–1612. [Google Scholar]
- Mazaheri, S.; Wirza, R.; Sulaiman, P.S.; Dimon, M.Z.; Khalid, F.; Tayebi, R.M. Segmentation methods of echocardiography images for left ventricle boundary detection. J. Comput. Sci. 2015, 11, 957–970. [Google Scholar] [CrossRef] [Green Version]
- Li, B.N.; Qin, J.; Wang, R.; Wang, M.; Li, X. Selective level set segmentation using fuzzy region competition. IEEE Access 2016, 4, 4777–4788. [Google Scholar] [CrossRef]
- Sarica, A.; Cerasa, A.; Quattrone, A. Random forest algorithm for the classification of neuroimaging data in Alzheimer’s disease: A systematic review. Front. Aging Neurosci. 2017, 9, 329. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kulkarni, V.Y. Effective learning and classification using random forest algorithm. Int. J. Eng. Innov. Technol. 2014, 3, 267–273. [Google Scholar]
- Correia, A.H.; Peharz, R.; de Campos, C.P. Joints in Random Forests. Adv. Neural Inf. Process. Syst. 2020, 33, 11404–11415. [Google Scholar]
- Kong, Y.; Yu, T. A deep neural network model using random forest to extract feature representation for gene expression data classification. Sci. Rep. 2018, 8, 16477. [Google Scholar] [CrossRef] [Green Version]
- Varghese, M.; Jayanthi, K. Contour segmentation of echocardiographic images. In Proceedings of the International Conference on Advanced Communication Control and Computing Technologies (ICACCCT), Ramanathapuram, India, 8–10 May 2014; pp. 1493–1496. [Google Scholar]
- Balaji, G.N.; Subashini, T.S.; Suresh, A. An efficient view classification of echocardiogramusing morphological operations. J. Theor. Appl. Inf. Technol. 2014, 67, 732–735. [Google Scholar]
- Supha, L.A. Tracking and Quantification of Left Ventricle Borders in Echocardiographic Images with Improved Segmentation Techniques; Anna University: Chennai, India, 2013. [Google Scholar]
- Baumgartner, H.; Hung, J.; Bermejo, J.; Chambers, J.B.; Edvardsen, T.; Goldstein, S.; Lancellotti, P.; LeFevre, M.; Miller, J.F.; Otto, C.M. Recommendations on the echocardiographic assessment of aortic valve stenosis: A focused update from the European association of Cardiovascular imaging and the American society of echocardiography. Eur. Heart J. Cardiovasc. Imaging 2016, 18, 254–275. [Google Scholar] [CrossRef]
- Aljanabi, M.; Qutqut, H.M.; Hijjawi, W. Machine learning classification techniques for heart disease prediction: A review. Int. J. Eng. Technol. 2018, 7, 373–379. [Google Scholar]
- Alarsan, F.I.; Younes, M. Analysis and classification of heart diseases using heartbeat features and machine learning algorithms. J. Big Data 2019, 6, 81. [Google Scholar] [CrossRef] [Green Version]
- Wahlang, I.; Sharma, P.; Saha, G.; Maji, A.K. Brain Tumor Classification Techniques using MRI: A Study. Res. J. Pharm. Technol. 2018, 11, 4764–4770. [Google Scholar] [CrossRef]
- Suhag, S.; Saini, L.M. Automatic Brain Tumor Detection and Classification using SVM Classifier. Int. J. Adv. Sci. Eng. Technol. 2015, 3, 119–123. [Google Scholar]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Löfstedt, T.; Brynolfsson, P.; Asklund, T.; Nyholm, T.; Garpebring, A. Gray-level invariant Haralick texture features. PLoS ONE 2019, 14, e0212110. [Google Scholar] [CrossRef] [PubMed]
- Haralick Texture Features. Available online: http://murphylab.web.cmu.edu/publications/boland/boland_node26.html (accessed on 27 April 2019).
- Schonlau, M.; Zou, R.Y. The random forest algorithm for statistical learning. Stata J. 2020, 20, 3–29. [Google Scholar] [CrossRef]
- Jiang, X.; Zhang, R.; Nie, S. Image segmentation based on level set method. Phys. Procedia 2012, 33, 840–845. [Google Scholar] [CrossRef] [Green Version]
- Huang, B.; Pan, Z.; Yang, H.; Bai, L. Variational level set method for image segmentation with simplex constraint of landmarks. Signal Process. Image Commun. 2012, 82, 115745. [Google Scholar] [CrossRef]
- Introduction to Level Set. Available online: https://math.berkeley.edu/~sethian/2006/Semiconductors/\protect\discretionary{\char\hyphenchar\font}{}{}ieee_level_set_explain.html (accessed on 27 April 2019).
- Euclidean Distance. Available online: https://en.wikipedia.org/wiki/Euclidean_distance (accessed on 2 May 2019).
- Brynolfsson, P.; Nilsson, D.; Torheim, T.; Asklund, T.; Karlsson, C.T.; Trygg, J.; Nyholm, T.; Garpebring, A. Haralick texture features from apparent diffusion coefficient (ADC) MRI images depend on imaging and pre-processing parameters. Sci. Rep. 2017, 7, 4041. [Google Scholar] [CrossRef] [Green Version]
- Mathworks. Available online: https://www.mathworks.com/matlabcentral/answers/375100-i-want-to-explain-a-detailed-code-glcm-of-my-project-is-detection-on-breast-cancer-and-i-want-to (accessed on 7 April 2019).
- Tripathi, A.; Goswami, T.; Trivedi, S.K.; Sharma, R.D. A multi class random forest (MCRF) model for classification of small plant peptides. Int. J. Inf. Manag. Data Insights 2021, 1, 100029. [Google Scholar] [CrossRef]
- Rustam, Z.; Sudarsono, E.; Sarwinda, D. Random-forest (RF) and support vector machine (SVM) implementation for analysis of gene expression data in chronic kidney disease (CKD). IOP Conf. Ser. Mater. Sci. Eng. 2019, 546, 052066. [Google Scholar] [CrossRef]
- Sleeman IV, W.C.; Krawczyk, B. Multi-class imbalanced big data classification on spark. Knowl.-Based Syst. 2021, 212, 106598. [Google Scholar] [CrossRef]
- Vakili, M.; Ghamsari, M.; Rezaei, M. Performance analysis and comparison of machine and deep learning algorithms for IoT data classification. arXiv 2020, arXiv:2001.09636. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sl. No. | Name of Features | Mathematical Expression |
|---|---|---|
| 1 | Contrast | |
| 2 | Dissimilarity | |
| 3 | Energy | |
| 4 | Entropy | |
| 5 | Correlation | |
| 6 | Homogeneity | |
| 7 | Variance | |
| 8 | Autocorrelation | |
| 9 | Sum average | |
| 10 | Sum entropy | |
| 11 | Sum variance | |
| 12 | Difference entropy | |
| 13 | Difference variance | |
| 14 | Information measure of correlation 1 | |
| 15 | Information measure of correlation 2 | |
| 16 | Cluster Prominence | |
| 17 | Cluster Shade | |
| 18 | Inverse Difference Normalized | |
| 19 | Inverse Difference Moment Normalization |
| No. of Fold | % | Precision | Recall | F1-Score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P0 | P1 | P2 | R0 | R1 | R2 | F0 | F1 | F2 | ||
| 2-folds | 10 | 100 | 78.57 | 100 | 76.92 | 100 | 100 | 86.95 | 87.99 | 100 |
| 20 | 100 | 84.61 | 77.77 | 100 | 84.61 | 77.77 | 100 | 84.61 | 77.77 | |
| 30 | 72.72 | 81.81 | 58.33 | 80.00 | 75.00 | 58.33 | 76.18 | 78.25 | 58.33 | |
| 40 | 75.00 | 81.81 | 81.61 | 100 | 64.28 | 81.81 | 85.71 | 71.99 | 81.81 | |
| 50 | 84.61 | 100 | 77.77 | 84.61 | 100 | 77.77 | 84.61 | 100 | 77.77 | |
| 3-folds | 10 | 50.00 | 100 | 100 | 100 | 50.00 | 100 | 66.66 | 66.66 | 100 |
| 20 | 100 | 66.66 | 87.5 | 100 | 80.00 | 77.77 | 100 | 72.72 | 82.34 | |
| 30 | 75.00 | 60.00 | 100 | 100 | 100 | 71.42 | 85.71 | 75.00 | 83.32 | |
| 40 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 50 | 100 | 71.42 | 75.00 | 100 | 71.42 | 75.00 | 100 | 71.42 | 75.00 | |
| 5-folds | 10 | 66.66 | 100 | 100 | 100 | 60.00 | 100 | 79.99 | 75.00 | 100 |
| 20 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 30 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 40 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 50 | 100 | 85.71 | 100 | 80.00 | 100 | 100 | 88.88 | 92.30 | 100 | |
| 8-folds | 10 | 100 | 100 | 0 | 100 | 75.00 | 0 | 100 | 85.71 | 0 |
| 20 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 30 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 40 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 50 | 100 | 100 | 50.00 | 100 | 66.66 | 100 | 100 | 79.99 | 66.66 | |
| No. of Fold | % | Precision | Recall | F1-Score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P0 | P1 | P2 | R0 | R1 | R2 | F0 | F1 | F2 | ||
| 2-folds | 10 | 100 | 28.57 | 90.00 | 55.55 | 100 | 75.00 | 71.42 | 44.44 | 81.81 |
| 20 | 83.33 | 69.23 | 77.77 | 83.33 | 100 | 53.84 | 83.33 | 81.81 | 63.62 | |
| 30 | 81.81 | 72.72 | 75.00 | 60.00 | 100 | 81.81 | 69.22 | 84.20 | 73.68 | |
| 40 | 75.00 | 72.72 | 100 | 75.00 | 72.72 | 100 | 75.00 | 72.72 | 100 | |
| 50 | 100 | 58.33 | 100 | 86.66 | 100 | 75.00 | 92.85 | 73.68 | 85.71 | |
| 3-folds | 10 | 100 | 50.00 | 72.72 | 72.72 | 100 | 80.00 | 84.20 | 66.66 | 76.18 |
| 20 | 88.88 | 50.00 | 100 | 72.72 | 100 | 88.88 | 79.99 | 66.66 | 94.11 | |
| 30 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 40 | 100 | 66.66 | 100 | 100 | 100 | 75.00 | 100 | 79.99 | 85.71 | |
| 50 | 100 | 100 | 87.50 | 88.88 | 100 | 100 | 94.11 | 100 | 93.33 | |
| 5-folds | 10 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| 20 | 100 | 66.66 | 0 | 55.55 | 100 | 0 | 71.42 | 79.99 | 0 | |
| 30 | 100 | 100 | 75.00 | 89.71 | 100 | 100 | 94.57 | 100 | 85.71 | |
| 40 | 100 | 100 | 60.00 | 66.66 | 100 | 100 | 79.99 | 100 | 75.00 | |
| 50 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 8-folds | 10 | 100 | 33.33 | 100 | 100 | 100 | 33.33 | 100 | 49.99 | 49.99 |
| 20 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 30 | 33.33 | 100 | 50.00 | 100 | 20.00 | 100 | 49.99 | 33.33 | 66.66 | |
| 40 | 100 | 100 | 75.00 | 66.66 | 100 | 100 | 79.99 | 100 | 85.71 | |
| 50 | 50.00 | 100 | 100 | 100 | 50.00 | 100 | 66.66 | 66.66 | 100 | |
| No. of Fold | % | Precision | Recall | F1-Score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P0 | P1 | P2 | R0 | R1 | R2 | F0 | F1 | F2 | ||
| 2-folds | 10 | 95.23 | 96.77 | 90.90 | 97.56 | 90.90 | 93.75 | 96.38 | 93.74 | 92.30 |
| 20 | 95.74 | 99.17 | 100 | 97.82 | 99.58 | 94.44 | 96.76 | 99.37 | 97.14 | |
| 30 | 88.88 | 71.42 | 93.93 | 86.95 | 86.95 | 83.78 | 87.90 | 78.42 | 88.56 | |
| 40 | 85.00 | 96.77 | 80.00 | 91.89 | 78.94 | 90.32 | 88.31 | 86.95 | 84.84 | |
| 50 | 94.59 | 96.66 | 97.50 | 100 | 93.54 | 95.12 | 97.21 | 95.07 | 96.29 | |
| 3-folds | 10 | 93.75 | 88.23 | 95.65 | 96.77 | 88.23 | 91.66 | 95.23 | 88.23 | 93.61 |
| 20 | 92.59 | 90.00 | 91.66 | 96.15 | 85.71 | 91.66 | 94.33 | 87.80 | 91.66 | |
| 30 | 91.66 | 90.90 | 88.46 | 84.61 | 90.90 | 95.83 | 87.99 | 90.90 | 91.99 | |
| 40 | 96.55 | 95.23 | 90.47 | 96.55 | 95.23 | 90.47 | 96.55 | 95.23 | 90.47 | |
| 50 | 94.44 | 92.85 | 95.23 | 94.44 | 86.66 | 100 | 94.44 | 89.65 | 97.55 | |
| 5-folds | 10 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| 20 | 94.11 | 83.33 | 92.30 | 88.88 | 90.90 | 92.30 | 91.42 | 86.95 | 92.30 | |
| 30 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 40 | 86.66 | 87.50 | 95.00 | 92.85 | 77.77 | 95.00 | 89.64 | 82.34 | 95.00 | |
| 50 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 8-folds | 10 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| 20 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 30 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 40 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 50 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| No. of Fold | % | Precision | Recall | F1-Score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P0 | P1 | P2 | R0 | R1 | R2 | F0 | F1 | F2 | ||
| 2-folds | 10 | 80.95 | 64.51 | 48.27 | 79.07 | 50.00 | 73.68 | 79.99 | 56.33 | 58.87 |
| 20 | 76.59 | 72.00 | 58.82 | 81.81 | 56.25 | 66.66 | 79.11 | 63.15 | 62.49 | |
| 30 | 88.88 | 71.42 | 100 | 95.23 | 86.95 | 80.48 | 91.94 | 78.42 | 89.18 | |
| 40 | 75.00 | 77.41 | 31.42 | 62.50 | 57.14 | 68.75 | 68.18 | 65.74 | 43.12 | |
| 50 | 81.08 | 55.17 | 42.50 | 62.50 | 59.25 | 61.29 | 70.58 | 57.13 | 50.19 | |
| 3-folds | 10 | 87.50 | 81.25 | 86.95 | 87.50 | 68.42 | 100 | 87.50 | 74.28 | 93.01 |
| 20 | 48.14 | 45.00 | 58.33 | 54.16 | 39.13 | 58.33 | 50.97 | 41.86 | 58.33 | |
| 30 | 78.26 | 63.66 | 84.61 | 69.23 | 73.68 | 84.61 | 73.46 | 68.28 | 84.61 | |
| 40 | 65.51 | 71.42 | 66.66 | 70.37 | 62.50 | 70.00 | 67.85 | 66.66 | 68.28 | |
| 50 | 83.33 | 71.42 | 66.66 | 85.71 | 52.63 | 82.35 | 84.60 | 60.60 | 73.67 | |
| 5-folds | 10 | 77.77 | 66.66 | 66.66 | 77.77 | 61.53 | 72.72 | 77.77 | 63.99 | 69.55 |
| 20 | 82.35 | 58.33 | 75.00 | 77.77 | 63.63 | 75.00 | 79.99 | 60.86 | 75.00 | |
| 30 | 85.71 | 80.00 | 88.88 | 80.00 | 72.72 | 100 | 82.75 | 76.18 | 94.11 | |
| 40 | 60.00 | 62.50 | 36.84 | 52.94 | 35.71 | 63.63 | 56.24 | 71.61 | 46.66 | |
| 50 | 62.50 | 69.23 | 84.61 | 83.83 | 52.94 | 84.61 | 71.61 | 59.99 | 84.61 | |
| 8-folds | 10 | 66.66 | 71.42 | 40.00 | 60.00 | 50.00 | 66.66 | 63.15 | 58.82 | 49.99 |
| 20 | 55.55 | 71.42 | 60.00 | 55.55 | 55.55 | 75.00 | 55.55 | 62.49 | 66.66 | |
| 30 | 77.77 | 62.50 | 77.77 | 87.50 | 62.50 | 70.00 | 82.34 | 62.50 | 73.68 | |
| 40 | 81.81 | 90.00 | 80.00 | 90.00 | 81.81 | 80.00 | 85.70 | 85.70 | 80.00 | |
| 50 | 86.66 | 80.00 | 83.33 | 92.85 | 80.00 | 71.42 | 89.64 | 80.00 | 76.91 | |
| Fold | Performance Metrics | With Segmentation | Without Segmentation | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | 10% | 20% | 30% | 40% | 50% | ||
| 2-folds | Accuracy | 67.64 | 76.47 | 76.47 | 82.35 | 85.29 | 91.17 | 88.23 | 70.58 | 79.41 | 88.23 |
| Precision | 72.85 | 76.77 | 76.51 | 82.57 | 86.11 | 92.85 | 87.46 | 70.95 | 79.54 | 87.46 | |
| Recall | 76.85 | 79.05 | 80.60 | 82.57 | 87.22 | 92.30 | 87.45 | 71.11 | 82.03 | 87.46 | |
| F1-score | 65.89 | 76.25 | 75.70 | 82.57 | 84.08 | 91.64 | 87.46 | 70.92 | 79.83 | 87.46 | |
| 3-folds | Accuracy | 78.26 | 82.60 | 100 | 86.95 | 95.65 | 82.60 | 86.95 | 82.60 | 100 | 82.60 |
| Precision | 74.24 | 79.62 | 100 | 88.88 | 95.83 | 83.33 | 84.72 | 78.33 | 100 | 82.14 | |
| Recall | 84.24 | 87.20 | 100 | 91.66 | 96.29 | 83.33 | 85.92 | 90.47 | 100 | 82.14 | |
| F1-score | 81.65 | 80.25 | 100 | 88.56 | 95.81 | 77.77 | 85.02 | 81.34 | 100 | 82.14 | |
| 5-folds | Accuracy | 100 | 69.23 | 92.30 | 84.61 | 100 | 90.00 | 100 | 100 | 100 | 92.30 |
| Precision | 100 | 55.55 | 91.66 | 86.66 | 100 | 88.88 | 100 | 100 | 100 | 95.23 | |
| Recall | 100 | 51.85 | 96.57 | 88.88 | 100 | 86.66 | 100 | 100 | 100 | 93.33 | |
| F1-score | 100 | 50.47 | 93.42 | 84.99 | 100 | 84.99 | 100 | 100 | 100 | 93.72 | |
| 8-folds | Accuracy | 75.00 | 100 | 50.00 | 87.50 | 75.00 | 87.50 | 100 | 100 | 100 | 87.50 |
| Precision | 77.77 | 100 | 77.77 | 91.66 | 83.33 | 66.66 | 100 | 100 | 100 | 83.33 | |
| Recall | 77.77 | 100 | 73.33 | 88.88 | 83.33 | 58.33 | 100 | 100 | 100 | 88.88 | |
| F1-score | 66.66 | 100 | 49.99 | 88.56 | 77.77 | 61.90 | 100 | 100 | 100 | 82.21 | |
| Fold | Performance Metrics | With Segmentation | Without Segmentation | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | 10% | 20% | 30% | 40% | 50% | ||
| 2-folds | Accuracy | 66.66 | 69.81 | 87.73 | 61.32 | 61.32 | 94.34 | 98.76 | 85.84 | 86.79 | 96.26 |
| Precision | 64.57 | 69.13 | 86.76 | 61.27 | 59.58 | 94.30 | 98.30 | 84.74 | 87.25 | 96.25 | |
| Recall | 67.58 | 68.24 | 87.55 | 62.79 | 61.01 | 94.07 | 97.28 | 85.89 | 87.05 | 96.22 | |
| F1-score | 65.06 | 68.25 | 86.51 | 59.01 | 59.30 | 94.14 | 97.75 | 84.96 | 86.70 | 96.19 | |
| 3-folds | Accuracy | 85.91 | 50.70 | 76.05 | 67.60 | 76.05 | 93.05 | 91.54 | 90.27 | 94.36 | 94.36 |
| Precision | 85.23 | 50.49 | 75.51 | 67.86 | 73.80 | 92.54 | 91.41 | 90.34 | 94.08 | 94.17 | |
| Recall | 85.30 | 50.54 | 75.84 | 67.62 | 73.56 | 92.22 | 91.17 | 90.44 | 94.08 | 93.70 | |
| F1-score | 84.93 | 50.38 | 75.45 | 67.59 | 72.92 | 92.35 | 91.26 | 90.29 | 94.08 | 93.88 | |
| 5-folds | Accuracy | 71.42 | 73.17 | 85.71 | 50.00 | 71.42 | 100 | 90.47 | 100 | 90.69 | 100 |
| Precision | 70.36 | 71.89 | 84.86 | 53.11 | 72.11 | 100 | 89.91 | 100 | 89.72 | 100 | |
| Recall | 70.67 | 72.13 | 84.24 | 50.59 | 73.79 | 100 | 90.69 | 100 | 88.54 | 100 | |
| F1-score | 70.43 | 71.95 | 84.34 | 58.17 | 72.07 | 100 | 90.22 | 100 | 90.22 | 100 | |
| 8-folds | Accuracy | 57.69 | 61.53 | 73.07 | 84.61 | 84.61 | 100 | 100 | 100 | 100 | 100 |
| Precision | 66.02 | 62.32 | 72.68 | 83.93 | 83.33 | 100 | 100 | 100 | 100 | 100 | |
| Recall | 58.88 | 62.03 | 73.33 | 83.93 | 81.42 | 100 | 100 | 100 | 100 | 100 | |
| F1-score | 57.32 | 61.56 | 72.84 | 83.80 | 82.18 | 100 | 100 | 100 | 100 | 100 | |
| Author | Methodologies Used | Types of Classification | Type of Images | Accuracy (%) |
|---|---|---|---|---|
| Allan [12] (2017) | JICA, PCA, SVM | Types of regurgitation | Static | 82 |
| Kumar [11] (2010) | Affine transform, Histogram, Pyramid matching, SVM | Normal or abnormal (hypokinesis) | Static | 90.5 |
| Proposed | Binarization, Levelset method, Haralick and GLCM, Random Forest | Types of regurgitation | Videographic | 95.33 (Highest obtained accuracy in case of reference frame without segmentation) |
| Method | Performance Metrics | With Segmentation | Without Segmentation | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | 10% | 20% | 30% | 40% | 50% | ||
| SVM (Ref) | Accuracy | 0.88 | 0.66 | 0.50 | 0.51 | 0.50 | 1 | 0.57 | 0.47 | 0.42 | 0.34 |
| Precision | 0.90 | 0.66 | 0.56 | 0.52 | 0.56 | 1 | 0.55 | 0.46 | 0.44 | 0.34 | |
| Recall | 0.90 | 0.73 | 0.50 | 0.48 | 0.17 | 1 | 0.60 | 0.53 | 0.53 | 0.51 | |
| F1-score | 0.88 | 0.63 | 0.50 | 0.48 | 0.43 | 1 | 0.56 | 0.43 | 0.43 | 0.73 | |
| PCA-SVM (Ref) | Accuracy | 0.70 | 0.71 | 0.71 | 0.64 | 0.57 | 0.85 | 0.57 | 0.52 | 0.50 | 0.51 |
| Precision | 0.66 | 0.69 | 0.75 | 0.66 | 0.58 | 0.89 | 0.72 | 0.51 | 0.52 | 0.51 | |
| Recall | 0.50 | 0.83 | 0.81 | 0.74 | 0.58 | 0.89 | 0.49 | 0.57 | 0.64 | 0.70 | |
| F1-score | 0.89 | 0.63 | 0.50 | 0.48 | 0.43 | 0.86 | 0.64 | 0.52 | 0.50 | 0.46 | |
| SVM (Red) | Accuracy | 0.33 | 0.40 | 0.42 | 0.40 | 0.33 | 0.90 | 0.88 | 0.90 | 0.90 | 0.94 |
| Precision | 0.33 | 0.33 | 0.66 | 0.58 | 0.46 | 0.77 | 0.79 | 0.83 | 0.83 | 0.92 | |
| Recall | 0.16 | 0.16 | 0.27 | 0.26 | 0.25 | 0.91 | 0.90 | 0.92 | 0.92 | 0.94 | |
| F1-score | 0.22 | 0.22 | 0.38 | 0.37 | 0.32 | 0.84 | 0.84 | 0.87 | 0.87 | 0.93 | |
| PCA-SVM (Red) | Accuracy | 0.54 | 0.58 | 0.47 | 0.51 | 0.47 | 1 | 0.93 | 0.95 | 0.93 | 0.69 |
| Precision | 0.51 | 0.56 | 0.47 | 0.40 | 0.48 | 1 | 0.93 | 0.94 | 0.91 | 0.73 | |
| Recall | 0.54 | 0.57 | 0.47 | 0.40 | 0.48 | 1 | 0.93 | 0.96 | 0.94 | 0.80 | |
| F1-score | 0.53 | 0.56 | 0.46 | 0.50 | 0.48 | 1 | 0.93 | 0.95 | 0.92 | 0.77 | |
| Proposed (Ref) | Accuracy | 1 | 0.69 | 0.92 | 0.84 | 1 | 0.90 | 1 | 1 | 1 | 0.92 |
| Precision | 1 | 0.55 | 0.91 | 0.86 | 1 | 0.88 | 1 | 1 | 1 | 0.95 | |
| Recall | 1 | 0.51 | 0.96 | 0.88 | 1 | 0.86 | 1 | 1 | 1 | 0.93 | |
| F1-score | 1 | 0.50 | 0.93 | 0.84 | 1 | 0.84 | 1 | 1 | 1 | 0.93 | |
| Proposed (Red) | Accuracy | 0.71 | 0.73 | 0.85 | 0.50 | 0.71 | 1 | 0.90 | 1 | 0.90 | 1 |
| Precision | 0.70 | 0.71 | 0.84 | 0.53 | 0.72 | 1 | 0.89 | 1 | 0.89 | 1 | |
| Recall | 0.70 | 0.72 | 0.84 | 0.50 | 0.73 | 1 | 0.90 | 1 | 0.88 | 1 | |
| F1-score | 0.70 | 0.71 | 0.84 | 0.58 | 0.72 | 1 | 0.90 | 1 | 0.90 | 1 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wahlang, I.; Hassan, S.M.; Maji, A.K.; Saha, G.; Jasinski, M.; Leonowicz, Z.; Jasinska, E. Classification of Valvular Regurgitation Using Echocardiography. Appl. Sci. 2022, 12, 10461. https://doi.org/10.3390/app122010461
Wahlang I, Hassan SM, Maji AK, Saha G, Jasinski M, Leonowicz Z, Jasinska E. Classification of Valvular Regurgitation Using Echocardiography. Applied Sciences. 2022; 12(20):10461. https://doi.org/10.3390/app122010461
Chicago/Turabian StyleWahlang, Imayanmosha, Sk Mahmudul Hassan, Arnab Kumar Maji, Goutam Saha, Michal Jasinski, Zbigniew Leonowicz, and Elzbieta Jasinska. 2022. "Classification of Valvular Regurgitation Using Echocardiography" Applied Sciences 12, no. 20: 10461. https://doi.org/10.3390/app122010461