
Grid-Based Hybrid Genetic Approach to Relaxed Flexible Flow Shop with Sequence-Dependent Setup Times

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. The Relaxed Flexible Flow Shop Problem Model with Sequence-Dependent Setup Times (RFFSP) Methods
2.1. Mathematical Model
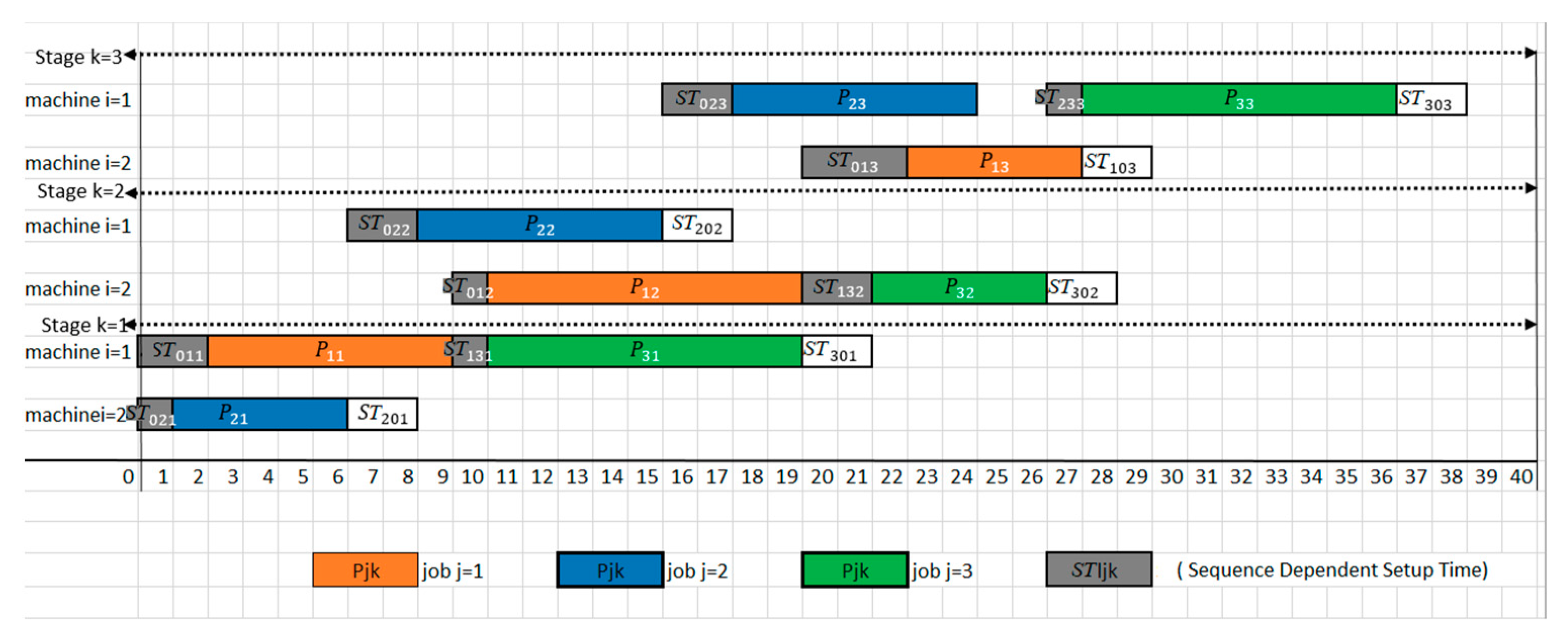
2.2. Disjunctive Graph Model
3. Hybrid Genetic Algorithm in Grid Environment (HGAG) to the Relaxed Flexible Flow Shop with Sequence-Dependent Setup Times
3.1. Hybrid Genetic Algorithm in Grid Environment (HGAG)
| Algorithm 1 Hybrid Genetic Algorithm in Grid Environment (HGAG) | |||
| 1. | Note: blocking routines are used for sending and receiving messages | ||
| 2. | Function HGAG (Processid, idmax) | ||
| 3. | if (Processid == ProcSlave) then | ||
| 4. | |||
| 5. | |||
| 6. | end if | ||
| 7. | Repeat | ||
| 8. | if (Processid == ProcMaster) then | ||
| 9. | ReceiveF(Processi, population[individuali], blocking), | ||
| 10. | population selectionF(rouleteOp, population) | ||
| 11. | populationcrossoverF(crossoverR, circularOp, population) | ||
| 12. | SendF(Processi, population [individuali]), | ||
| 13. | Else | ||
| 14. | |||
| 15. | |||
| 16. | |||
| 17. | |||
| 18. | |||
| 19. | |||
| 20. | |||
| 21. | |||
| 22. | end if | ||
| 23. | until (number of generations) | ||
| 24. | if (Processid == ProcMaster) then | ||
| 25. | ReceiveF (Processi, population [individual i], | ||
| 26. | SBestGlobal min(Cmax(population[individuali])), | ||
| 27. | return (SBestGlobal) | ||
| 28. | Else | ||
| 29. | SendF (ProcMaster, SBestLocal) | ||
| 30. | end if | ||
| 31. | end Function HGAG | ||
- Initialization stage
- Evolutionary stage
- Master process
- Slave process
- t0 is the initial temperature.
- m is the Markov chain length.
- µ is the frozen coefficient.
- tf is the final temperature
- Smetal is the SA initial solution.
- Final stage
- Population Construction
- Selection Operator
- The probability probi to select the individuali is proportional to its relative adaptation, which is calculated as follows:where is the cost inverse for individuali, and is the total fitness of the population.
- Cumulative probabilities are calculated for each individuali, as follows:
- The selection criterion consists of generating a random number r uniformly distributed over an interval [0, 1].
- The individual selected is located in the population as follows:
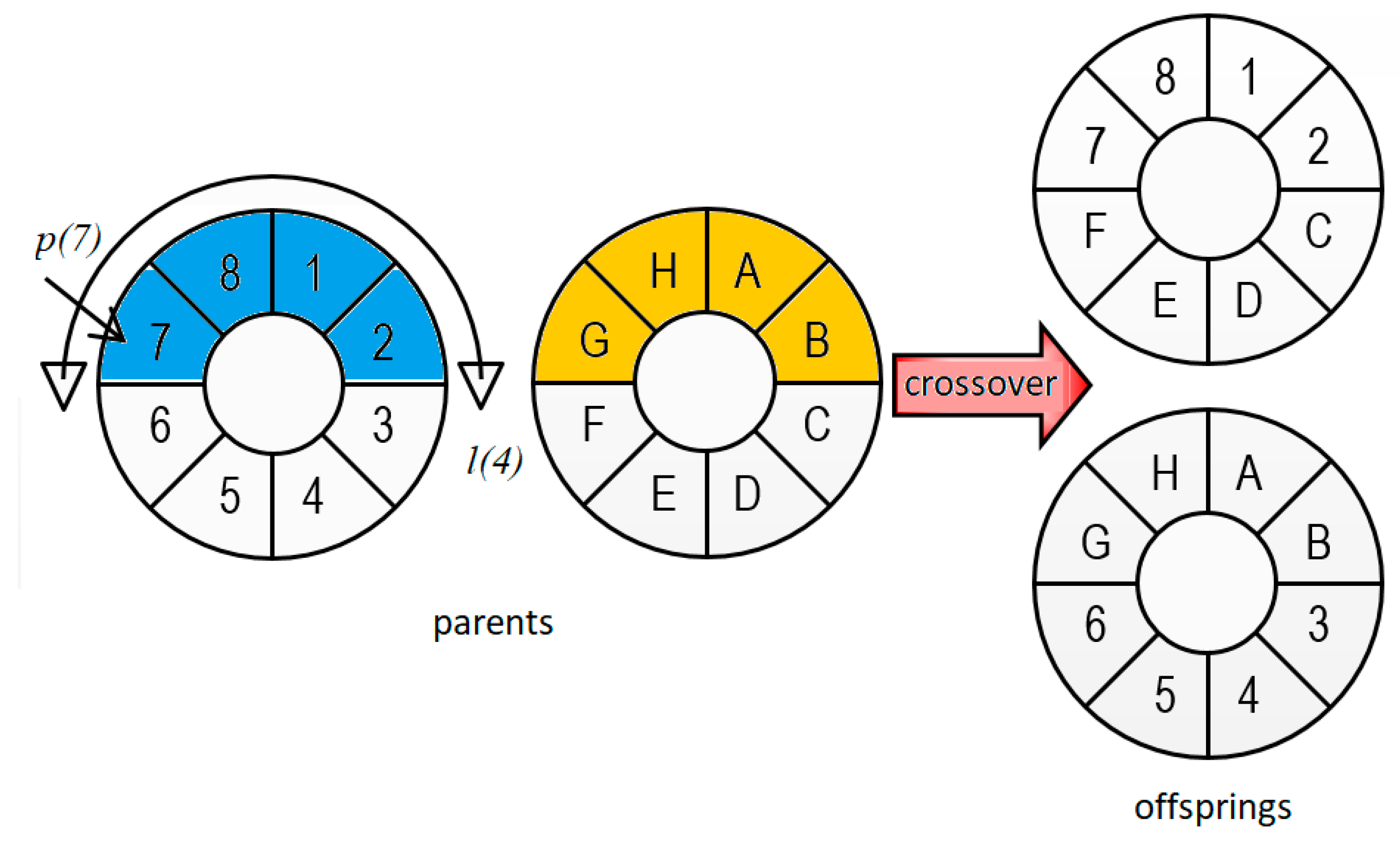
- Crossover operator
- The mechanism has a blocking behavior, i.e., while a process waits to receive messages, it keeps waiting (blocked) until it gets them.
- The slave process sending a message is blocked while depositing it in the master process queue (buffer), continuing its processing once the message has been delivered.
- The master process blocks while reading the messages from its buffer.
- If the receiving process reads a message before it is ready, it blocks until the message is completed.
- When the master process receives messages, it must wait for each slave process in sequential order.
- When the slave processes receive a message, they must wait for the master process to distribute the results in sequential order and then wait their turn.
3.2. Ant Colony System Algorithm
| Algorithm 2 ACS (Ant Colony System) | ||||||
| 1. | Function ACS (h, α, β, γ, δ, p, q, UB, Sant) | |||||
| 2. | τ0 (n.m.k.UB)−1 | |||||
| 3. | τr,s τ0, ∀arc ∈ G(V, A) | |||||
| 4. | τr,s [Cmax(Sant)]−1,∀arc ∈ Sant | |||||
| 5. | Cmax(SBestLocal) 999999 | |||||
| 6. | Repeat | |||||
| 7. | while∀ (antk), con k = 1, 2, …, h | |||||
| 8. | S[antk] =BuildSolution(α, β, γ, q, τr,s,antk) | |||||
| 9. | end while | |||||
| 10. | SBestLocal min(Cmax(SBestLocal), Cmax(S[antk])), k = 1, 2, …, h | |||||
| 11. | for (antk), k = 1, …, h | |||||
| 12. | for (arc(r, s)) ∈ S[antk] | |||||
| 13. | if arcr,s ∈ SBestLocal then | |||||
| 14. | τr,s (1 − δ). τr,s+ δ.Δτr,s | |||||
| 15. | Else | |||||
| 16. | τr,s τr,s | |||||
| 17. | end if | |||||
| 18. | end for | |||||
| 19. | end for | |||||
| 20. | until(p) | |||||
| 21. | return (SBestLocal) | |||||
| 22. | end Function LCS | |||||
- h is the number of ants.
- α is the importance coefficient alpha.
- β is the importance coefficient beta.
- γ is the evaporation coefficient for the local transition.
- δ is the evaporation coefficient for the global transition.
- q is the coefficient to divide the exploration and exploitation rates.
- p is the stop criterion of the algorithm.
- UB is the best-known quote in the literature.
- Sant is the ACS initial solution.
| Algorithm 3 Local Cooperative Search–BuildSolution() | ||||
| 1. | Function BuildSolution(α, β, γ, q, τr,s, k) | |||
| 2. | r input | |||
| 3. | Sk {r} | |||
| 4. | Repeat | |||
| 5. | r random [0, 1] | |||
| 6. | ifs∈Sk(r) ∧r ≤ q ∧ s ∉ tabuk then | |||
| 7. | Sigkr,s max s ∉ Sk(r)[ (τr,s) α.(nr,s)β ] | |||
| 8. | else ifs∈Sk(r) ∧r > q ∧ s ∉ tabuk then | |||
| 9. | Sigkr,s roulette(((τr,s)α.(nr,s)β)/(∑u ∈ Sk(r)((τr,u)α.(nr,u)β) | |||
| 10. | Otherwise | |||
| 11. | Sigkr,s 0 | |||
| 12. | end if | |||
| 13. | Sk = Sk + sigs | |||
| 14. | τr,s = (1-γ). τr,s + γ.τ0 | |||
| 15. | s r | |||
| 16. | until (r == exitCondition) | |||
| 17. | return (Sk) | |||
| 18. | end Function BuildSolution | |||
- Line 5: A random number r uniformly distributed between 0 and 1 is generated.
- Lines 6–11: A tabu list [29] is first used to build the set arcr,s with the arcs joining the neighborhood of non-visited and reachable nodes of the ant k placed in node r s ∈ Nk(r). Then, another uniformly distributed random number q ∈ [0, 1] is generated and used to determine if exploitation or exploration is conducted. If r ≤ q, the ants apply their knowledge in terms of the pheromone amount (τr,s) and the transition costs (ηr,s). The next best arc with the largest amount of pheromone and a lower transition cost is selected. On the other hand, if r > q, a probability of choosing the next arc arcr,s is obtained using a roulette-based selection.
- Line 13: The selected node s is added to the solution Sk.
- Line 14: As ant k advances from node r to node s, the pheromone is dissipated to make it less attractive to the following ants, allowing it to select other arcs not yet explored.
- Line 15: Ant k advances to the selected node s.
3.3. Simulated Annealing Algorithm
| Algorithm 4 SA (Simulated Annealing) | ||||||||
| 1. | Function SA(to, m, µ, tf, Smetal) | |||||||
| 2. | T To | |||||||
| 3. | Cmax(SBestLocal) 999999 | |||||||
| 4. | Srecent Smetal | |||||||
| 5. | Repeat | |||||||
| 6. | fori, i = 1, 2, …, mdo | |||||||
| 7. | Snew N(Srecent) | |||||||
| 8. | if (CmaxSnew) ≤ Cmax(Srecent)) then | |||||||
| 9. | Srecent Snew | |||||||
| 10. | if (Cmax(Srecent) ≤ Cmax(SBestLocal)) then | |||||||
| 11. | SBestLocal Srecent | |||||||
| 12. | end if | |||||||
| 13. | else if | |||||||
| 14. | Sdif Cmax(Snew) −Cmax(Srecent) | |||||||
| 15. | r random [0, 1] | |||||||
| 16. | if (r ≤ ) then | |||||||
| 17. | SrecentSnew | |||||||
| 18. | end if | |||||||
| 19. | end if | |||||||
| 20. | end for | |||||||
| 21. | T T. µ | |||||||
| 22. | until (T ≤ Tf) | |||||||
| 23. | return (SBestLocal) | |||||||
| 24. | end Function SA | |||||||
- t0 is the initial temperature.
- m is the Markov chain length.
- µ is the frozen coefficient.
- tf is the final temperature
- Smetal is the SA initial solution. This is the solution found by the ACS algorithm.
- Line 7: A new solution Snew is created using a local search in the neighborhood of Srecent N(Srecent).
- Lines 8–12: If the objective function cost, defined in Equation (1), of the solution Snew is not greater than those of the Srecent solution, Snew replaces Srecent. Srecent always takes the best solution found. Furthermore, the SbestLocal solution is updated with Snew.
- Lines 13–19: On the other hand, if the objective function cost of the solution Snew is greater than those of the Srecent solution, the Boltzmann criterion is used to accept the Snew solution as the Srecent solution. This criterion allows escaping from local optimums and the continued exploration of the solution space.
- Solution Representation
4. Experimental Results
4.1. Platform of Experimentation
4.2. Generation of Test Instances
- Five groups of jobs N = {20, 40, 60, 80, 140};
- Three groups of stages K = {2, 4, 8};
- Four groups of machines M = {2, 3, 4, 5};
- Processing times pjk uniformly distributed in the range (1–99);
- Setup times STljk, uniformly distributed in the ranges (1–25), (1–50), (1–00), and (1–125). These values correspond to 25%, 50%, 100% and 125% of ratio, according to the processing times.
4.3. HGAG Sensibility Analysis
- The design, codification, and tuning of the ACS and SA algorithms are carried out.
- An analysis of previous works described in the existing literature to find the values commonly used for the ACS parameters is conducted. It is found that the α and β values fluctuate between 0 and 5. The values for the pheromone evaporation factors, γ, δ, and the importance factor p, are in 0 and 1. The h value has a maximum of 200, and some researchers set it to with the same value as the number of jobs to the problem. The q parameter takes values higher than 2000, depending on the available computing resources. In some works, the α parameter value is generally set as one, and only the importance factor β is varied [35].
- An analysis of previous works presented in the existing literature to find the established values for the SA parameters is also carried out. It is found that the values defined for the four parameters of the algorithm, To, m, µ, Tf, are called low, medium, and high.
- Ranges are established for the HGAG parameters. The ranges of values found in the literature [36] consider two selection operators: roulette and tournament. For the crossover operator, the researchers commonly use PMX (Partially Mapped Crossover), OP (One Point order crossover), TP (Two Point order crossover), and OX (Order Crossover), among others. The crossover rate is defined in the range [0.1, 0.5]. The population size is fixed in the range between 20 and 50.
- Sensitivity analysis results
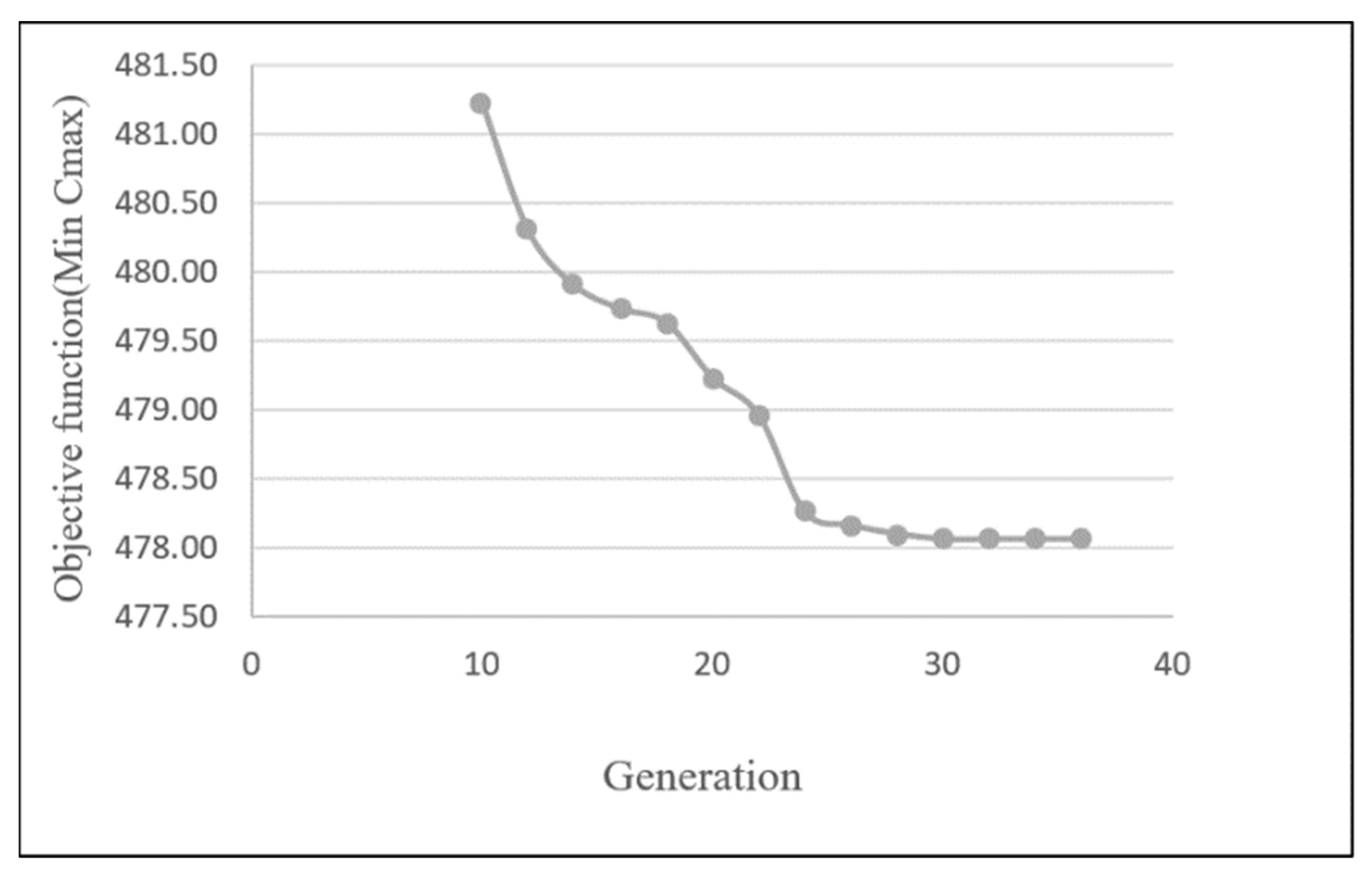
4.4. HGAG Algorithm Convergence
4.5. Grid Efficacy
- Process cooperation in HGAG
- Process cooperation in small instances
- Process cooperation in medium instances
- Process cooperation in large instances
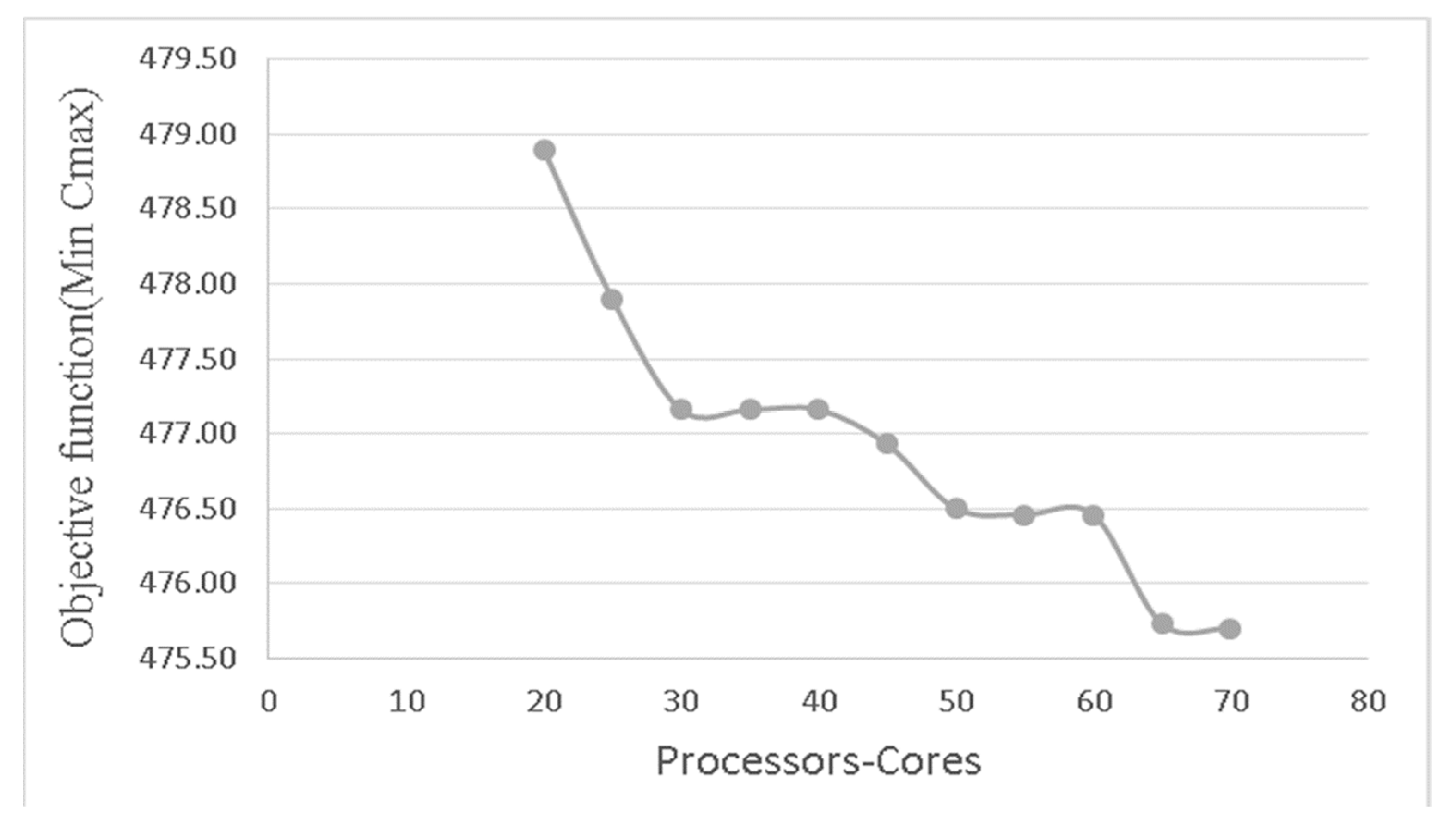
4.6. HGAG Efficiency on the Grid
5. Conclusions
6. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Blazewicz, J.; Ecker, K.H.; Pesch, E.; Schmidt, G.; Sterna, M.; Weglarz, J. Handbook on Scheduling: From Theory to Practice; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Tun, Y.K.; Kim, D.H.; Alsenwi, M.; Tran, N.H.; Han, Z.; Hong, C.S. Energy Efficient Communication and Computation Resource Slicing for eMBB and URLLC Coexistence in 5G and Beyond. IEEE Access 2020, 8, 136024–136035. [Google Scholar] [CrossRef]
- Fu, Y.; Ding, J.; Wang, H.; Wang, J. Two-objective stochastic flow-shop scheduling with deteriorating and learning effect in Industry 4.0-based manufacturing system. Appl. Soft. Comput. 2018, 68, 847–855. [Google Scholar] [CrossRef]
- Lewandowski, R.; Olszewska, J.I. Automated task scheduling for automotive industry. In Proceedings of the 2020 IEEE 24th International Conference on Intelligent Engineering Systems (INES), Reykjavík, Iceland, 8–10 July 2020; pp. 159–164. [Google Scholar]
- Fikar, C.; Hirsch, P. Home health care routing and scheduling: A review. Comput. Oper. Res. 2017, 77, 86–95. [Google Scholar]
- Wang, H.; Gong, J.; Zhuang, Y.; Shen, H.; Lach, J. Healthedge: Task scheduling for edge computing with health mergency and human behavior consideration in smart homes. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1213–1222. [Google Scholar]
- Jamroen, C.; Komkum, P.; Fongkerd, C.; Krongpha, W. An Intelligent Irrigation Scheduling System Using Low-Cost Wireless Sensor Network Toward Sustainable and Precision Agriculture. IEEE Access 2020, 8, 172756–172769. [Google Scholar] [CrossRef]
- Demirović, E.; Stuckey, P.J. Constraint programming for high school timetabling: A scheduling-based model with hot starts. In Proceedings of the International Conference on the Integration of Constraint Programming, Artificial Intelligence, and Operations Research, Delft, The Netherlands, 26–29 June 2018; Springer: Cham, Switzerland; pp. 135–152. [Google Scholar]
- Ullman, J.D. NP-complete scheduling problems. J. Comput. Syst. Sci. 1975, 10, 384–393. [Google Scholar] [CrossRef] [Green Version]
- Garey, M.R.; Johnson, D.S.; Sethi, R. The complexity of flowshop and job shop scheduling. Math. Oper. Res. 1976, 1, 117–129. [Google Scholar] [CrossRef]
- Brucker, P. Scheduling Algorithms, 2nd ed.; Springer Science & Business Media: Berlin/Germany, Heidelberg, 2004. [Google Scholar]
- Miyata, H.H.; Nagano, M.S. The blocking flow shop scheduling problem: A comprehensive and conceptual review. Expert Syst. Appl. 2019, 137, 130–156. [Google Scholar] [CrossRef]
- Allahverdi, A. A survey of scheduling problems with no-wait in process. Eur. J. Oper. Res. 2016, 255, 665–686. [Google Scholar] [CrossRef]
- Filho, M.G.; de Fátima Morais, M.; Boiko TJ, P.; Miyata, H.H.; Varolo FW, R. Scheduling in flow shop with sequence-dependent setup times: Literature review and analysis. Int. J. Bus. Innov. Res. 2013, 7, 466–486. [Google Scholar] [CrossRef]
- Pinedo, M. Scheduling Theory, Algorithms, and Systems, 3rd ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1995. [Google Scholar]
- Kaighobadi, M.; Venkatesh, K. Flexible Manufacturing Systems: An Overview. Int. J. Oper. Prod. Manag. 1994, 14, 26–49. [Google Scholar] [CrossRef]
- Jungwattanakit, J.; Reodecha, M.; Chaovalitwongse, P.; Werner, F. Algorithms for flexible flow shop problems with unrelated parallel machines, setup times, and dual criteria. Int. J. Adv. Manuf. Technol. 2008, 37, 354–370. [Google Scholar] [CrossRef]
- Ramezanian, R.; Sanami, S.F.; Nikabadi, M.S. A simultaneous planning of production and scheduling operations in flexible flow shops: Case study of tile industry. Int. J. Adv. Manuf. Technol. 2017, 88, 2389–2403. [Google Scholar] [CrossRef]
- Peng, K.; Pan, Q.K.; Wang, L.; Deng, X.; Li, C.; Gao, L. Iterated local search for steelmaking-refining-continuous casting scheduling problem. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 567–572. [Google Scholar]
- Sankaran, V. A Particle Swarm Optimization Using Random Keys for Flexible Flow Shop Scheduling Problems with Sequence Dependent Setup Times. Master’s Thesis, Clemson University, Clemson, SC, USA, 2009. [Google Scholar]
- Amiri, P. Discrete Particle Swarm Optimization for Flexible Flow Line Scheduling. Master’s Thesis, Clemson University, Clemson, SC, USA, 2015. [Google Scholar]
- Wang, C.; Hsu, H.; Fu, H.; Ky, N.; Nguyen, V.T. Scheduling Flexible Flow Shop in Labeling Companies to Minimize the Makespan. Comput. Syst. Sci. Eng. 2022, 40, 17–36. [Google Scholar] [CrossRef]
- Tavakkoli-Moghaddam, R.; Safari, J. A New Mathematical Model for Flexible Flow Lines with Blocking Processor and Sequence-Dependent Setup Time; Levner, E., Ed.; InTechOpen: London, UK, 2007; ISBN 978-3-902613-02-8. Available online: https://www.intechopen.com/chapters/624 (accessed on 15 September 2021). [CrossRef] [Green Version]
- Cruz-Chávez, M.A. Neighborhood Generation Mechanism Applied in Simulated Annealing to Job Shop Scheduling Problems. Int. J. Syst. Sci. 2015, 46, 2673–2685. [Google Scholar] [CrossRef]
- Araujo, L.; Cervigón, C. Algoritmos Evolutivos; Alfa-Omega: Mexico City, Mexico, 2009. [Google Scholar]
- Pavez-Lazo, B.; Soto-Cartes, J.; Urrutia, C.; Curilem, M. Selección Determinística y Cruce Anular en Algoritmos Genéticos: Aplicación a la Planificación de Unidades Térmicas de Generación. Ingeniare 2009, 17, 175–181. [Google Scholar]
- Richard, P.M.; Amin, M.V.; David, E.C.; Thomas, E.A. Effects of communication latency, overhead, and bandwidth in a cluster architecture. In Proceedings of the 24th Annual International Symposium on Computer Architecture ISCA, Denver, CO, USA, 1–4 June 1997; pp. 85–97. [Google Scholar]
- Dorigo, M. Optimization, Learning and Natural Algorithms. Ph.D. Dissertation, Dipartimento di Elettronica, Politecnico di Milano, Milano, Italy, 1992. (In Italian). [Google Scholar]
- Wardono, B.; Fathi, Y. A tabu search algorithm for the multi-stage parallel machine problem with limited buffer capacities. Eur. J. Oper. Res. 2004, 155, 380–401. [Google Scholar] [CrossRef]
- Kirkpatrick, C. Gelatt, and M. Vecchi. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Cruz-Chávez, M.A.; Juárez-Pérez, F.; Moreno Bernal, P. MiniGrid Morelos, una Sinergia Interinstitucional, Hypatia, Revista de Divulgación Científico-Tecnológica del Consejo de Ciencia y Tecnología del Estado de Morelos; No. 40, Enero/M; Pérez Sabino, S.P., Ed.; CCYTEM: Morelos, México, 2001; pp. 32–33. ISSN 2007-4735. [Google Scholar]
- Ruiz, A.; Stutzle, T. An Iterated Greedy heuristic for the sequence dependent setup times flowshop problem with makespan and weighted tardiness objectives. Eur. J. Oper. Res. 2008, 187, 1143–1159. [Google Scholar] [CrossRef]
- Ruiz, R.; Vázquez-Rodríguez, J.A. The hybrid flow shop scheduling problem. Eur. J. Oper. Res. 2010, 205, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Instances. Available online: http://www.gridmorelos.uaem.mx/~mcruz/instances_RFFSP/. (accessed on 12 December 2021).
- Ying, K.-C.; Lin, S.-W. Multi-heuristic desirability ant colony system heuristic for non-permutation flowshop scheduling problems. Int J. Adv. Manuf. Technol. 2007, 33, 793–802. [Google Scholar] [CrossRef]
- Ruiz, R.; Maroto, C. A genetic algorithm for hybrid flowshops with sequence dependent setup times and machine eligibility. Eur. J. Oper. Res. 2006, 169, 781–800. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| STljk | j = 1 | j = 2 | j = 3 | 0 (Cleaning) |
|---|---|---|---|---|
| Stage 1 (STljk) | ||||
| 0 (start) | ST011 = 2 | ST021 = 1 | ST031 = 3 | ST001 = 0 |
| l = 1 | ST111 = 0 | ST121 = 2 | ST131 = 1 | ST101 = 0 |
| l = 2 | ST211 = 1 | ST221 = 0 | ST231 = 1 | ST201 = 0 |
| l = 3 | ST311 = 2 | ST321 = 3 | ST331 = 0 | ST301 = 0 |
| Stage 2 (STljk) | ||||
| 0 (start) | ST012 = 1 | ST022 = 2 | ST032 = 3 | ST002 = 0 |
| l = 1 | ST112 = 0 | ST122 = 3 | ST132 = 2 | ST102 = 0 |
| l = 2 | ST212 = 1 | ST222 = 0 | ST232 = 1 | ST202 = 0 |
| l = 3 | ST312 = 3 | ST322 = 3 | ST332 = 0 | ST302 = 0 |
| Stage 3 (STljk) | ||||
| 0 (start) | ST013 = 3 | ST023 = 3 | ST033 = 1 | ST003 = 0 |
| l = 1 | ST113 = 0 | ST123 = 2 | ST133 = 1 | ST103 = 0 |
| l = 2 | ST213 = 2 | ST223 = 0 | ST233 = 1 | ST203 = 0 |
| l = 3 | ST313 = 3 | ST323 = 2 | ST333 = 0 | ST303 = 0 |
| INSTANCES SET | NAME | Description | SIZE |
|---|---|---|---|
| 1. | RFFS_SDST_20 × 4 × 4 × 25 | n = 20, m = 4, k = 4, STljk = 25% | Small |
| 2. | RFFS_SDST_40 × 4 × 4 × 25 | n = 40, m = 4, k = 4, STljk = 25% | |
| 3. | RFFS_SDST_60 × 4 × 4 × 25 | n = 60, m = 4, k = 4, STljk = 25% | Medium |
| 4. | RFFS_SDST_80 × 4 × 4 × 25 | n = 80, m = 4, k = 4, STljk = 25% | |
| 5. | RFFS_SDST_140 × 4 × 4 × 25 | n = 140, m = 4, k = 4, STljk = 25% | Large |
| Parameter | Values | Increments (Units) |
|---|---|---|
| ACS parameters | ||
| h | 1–20 | 1 |
| α | 1 | - |
| β | 0.1–0.9; 1–10 | 0.1 |
| γ | 0.1–0.9 | 0.1 |
| δ | 0.1–0.9 | 0.1 |
| q | 0.1–0.9 | 0.1 |
| p | 500–2000 | 250 |
| SA parameters | ||
| To | 1–110 | 10 |
| 120–500 | 20 | |
| m | 1–9 | 1 |
| 10–30 | 2 | |
| 30–50 | 4 | |
| 50–75 | 5 | |
| µ | 0.800–0.982 | 0.14 |
| 0.984–0.990 | 0.2 | |
| Tf | 0.8–0.2 | −0.2 |
| 0.08–0.02 | −0.02 | |
| 0.008–0.002 | −0.002 | |
| 0.0001 | - | |
| 1 | - | |
| HGAG parameters | ||
| S | Roulette | - |
| G | 10–30 | 2 |
| C | 0.10–1 | 0.10 |
| P | 20–70 | 5 |
| INSTANCE | T0 | m | µ | Tf |
|---|---|---|---|---|
| RFFS_SDST_20X4X4X25 | 450 | 78 | 0.989 | 0.0015 |
| RFFS_SDST_40X4X4X25 | 425 | 56 | 0.890 | 0.0001 |
| RFFS_SDST_60X4X4X25 | 395 | 71 | 0.989 | 0.0001 |
| RFFS_SDST_80X4X4X25 | 160 | 65 | 0.990 | 0.0001 |
| RFFS_SDST_140X4X4X25 | 40 | 70 | 0.990 | 0.0001 |
| INSTANCE | H | α | β | γ | Δ | p | q |
|---|---|---|---|---|---|---|---|
| RFFS_SDST_20X4X4X25 | 18 | 1 | 0.2 | 0.2 | 0.3 | 0.2 | 1250 |
| RFFS_SDST_40X4X4X25 | 20 | 1 | 0.2 | 0.6 | 0.9 | 0.2 | 2000 |
| RFFS_SDST_60X4X4X25 | 14 | 1 | 0.1 | 0.1 | 0.9 | 0.1 | 2000 |
| RFFS_SDST_80X4X4X25 | 18 | 1 | 0.3 | 0.3 | 0.9 | 0.1 | 1750 |
| RFFS_SDST_140X4X4X25 | 16 | 1 | 0.4 | 0.9 | 0.2 | 0.2 | 1500 |
| INSTANCE | G | C | P | ACS | SA |
|---|---|---|---|---|---|
| RFFS_SDST_60X4X4X25 | 30 | 0.5 | 240 | ACS | SA |
| RFFS_SDST_140X4X4X25 | 5 | 0.5 | 120 | ACS | SA |
| RFFS_SDST_20 × 4 × 4 × 25 | |||||
|---|---|---|---|---|---|
| P | N | Np | Cmax Average | t, s Average | Best |
| 5 | 5 | 24 | 481.43 | 361 | 478 |
| 10 | 10 | 12 | 479.67 | 363 | 472 |
| 15 | 15 | 8 | 479.17 | 364 | 476 |
| 30 | 30 | 4 | 477.70 | 364 | 473 |
| 60 | 60 | 2 | 476.23 | 366 | 473 |
| 120 | 120 | 1 | 475.10 | 415 | 471 |
| 240 | 120 | 1 | 473.80 | 1087 | 469 |
| RFFS_SDST_20 × 4 × 4 × 25 | |||||
|---|---|---|---|---|---|
| P | N | Np | Cmax Average | t, s Average | Best |
| 5 | 5 | 24 | 1631 | 1631 | 664 |
| 10 | 10 | 12 | 1696 | 1696 | 659 |
| 15 | 15 | 8 | 1747 | 1747 | 656 |
| 30 | 30 | 4 | 660.87 | 1664 | 655 |
| 60 | 60 | 2 | 659.30 | 1708 | 655 |
| 120 | 120 | 1 | 657.97 | 1996 | 654 |
| 240 | 120 | 1 | 656.73 | 4857 | 649 |
| RFFS_SDST_60 × 4 × 4 × 25 | |||||
|---|---|---|---|---|---|
| P | N | Np | Cmax Average | t, s Average | Best |
| 5 | 5 | 24 | 943.00 | 3889 | 937 |
| 10 | 10 | 12 | 940.27 | 3890 | 932 |
| 15 | 15 | 8 | 941.13 | 3988 | 934 |
| 30 | 30 | 4 | 939.37 | 3968 | 933 |
| 60 | 60 | 2 | 937.53 | 4047 | 932 |
| 120 | 120 | 1 | 935.73 | 4076 | 930 |
| 240 | 120 | 1 | 934.37 | 7953 | 927 |
| RFFS_SDST_80 × 4 × 4 × 25 | |||||
|---|---|---|---|---|---|
| P | N | Np | Cmax Average | t, s Average | Best |
| 5 | 5 | 24 | 1282 | 6521 | 1273 |
| 10 | 10 | 12 | 1279 | 6480 | 1272 |
| 15 | 15 | 8 | 1278 | 6606 | 1270 |
| 30 | 30 | 4 | 1275 | 6618 | 1269 |
| 60 | 60 | 2 | 1274 | 6715 | 1266 |
| 120 | 120 | 1 | 1272 | 6803 | 1264 |
| 240 | 120 | 1 | 1271 | 13,299 | 1263 |
| RFFS_SDST_140 × 4 × 4 × 25 | |||||
|---|---|---|---|---|---|
| P | N | Np | Cmax Average | t, s Average | Best |
| 5 | 5 | 24 | 2033.3 | 18,921 | 2022 |
| 10 | 10 | 12 | 2028.1 | 19,189 | 2015 |
| 15 | 15 | 8 | 2028.0 | 19,621 | 2016 |
| 30 | 30 | 4 | 2024.9 | 19,888 | 2016 |
| 60 | 60 | 2 | 2022.4 | 20,159 | 2013 |
| 120 | 120 | 1 | 2010.9 | 20,382 | 2013 |
| 240 | 120 | 1 | 2018.6 | 38,727 | 2013 |
| [fj@cuexcomate ~]$ mpiexec –ppn 1 –np 2 ./ping I am process 0 of 2 running on :cuexcomate I am process 1 of 2 running on :texcal Smaller posible measurable time ~0.953674 usecs (Microseconds) | ||
| Bits (RTT) | Time usecs | Transfer Rate Mb/sec |
| 64 | 750 | 0.163 |
| 128 | 717 | 0.341 |
| 256 | 768 | 0.636 |
| 512 | 809 | 1.207 |
| 1024 | 912 | 2.142 |
| 2048 | 1128 | 3.463 |
| 4096 | 1574 | 4.963 |
| 8192 | 2471 | 6.323 |
| 16384 | 3564 | 8.769 |
| 32768 | 5917 | 10.563 |
| 65536 | 10230 | 12.219 |
| 131072 | 18921 | 13.213 |
| 262144 | 36294 | 13.776 |
| 524288 | 71130 | 14.059 |
| 1048576 | 140704 | 14.214 |
| 2097152 | 279734 | 14.299 |
| 4194304 | 559525 | 14.298 |
| 8388608 | 1115870 | 14.339 |
| 16777216 | 2354889 | 13.589 |
| 33554432 | 4748298 | 13.479 |
| 67108864 | 9321278 | 13.732 |
Publisher′s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juárez-Pérez, F.; Cruz-Chávez, M.A.; Rivera-López, R.; Ávila-Melgar, E.Y.; Eraña-Díaz, M.L.; Cruz-Rosales, M.H. Grid-Based Hybrid Genetic Approach to Relaxed Flexible Flow Shop with Sequence-Dependent Setup Times. Appl. Sci. 2022, 12, 607. https://doi.org/10.3390/app12020607
Juárez-Pérez F, Cruz-Chávez MA, Rivera-López R, Ávila-Melgar EY, Eraña-Díaz ML, Cruz-Rosales MH. Grid-Based Hybrid Genetic Approach to Relaxed Flexible Flow Shop with Sequence-Dependent Setup Times. Applied Sciences. 2022; 12(2):607. https://doi.org/10.3390/app12020607
Chicago/Turabian StyleJuárez-Pérez, Fredy, Marco Antonio Cruz-Chávez, Rafael Rivera-López, Erika Yesenia Ávila-Melgar, Marta Lilia Eraña-Díaz, and Martín H. Cruz-Rosales. 2022. "Grid-Based Hybrid Genetic Approach to Relaxed Flexible Flow Shop with Sequence-Dependent Setup Times" Applied Sciences 12, no. 2: 607. https://doi.org/10.3390/app12020607