
Solving a Simple Geduldspiele Cube with a Robotic Gripper via Sim-to-Real Transfer

Abstract
:1. Introduction
- A simulation world guarantees a physics engine with superior fidelity in order to deploy a virtually trained RL agent into the real world directly after training.
- A small discrepancy in sense of physics between the simulation world and the real world is allowed; however, the RL agent is endowed with the ability to overcome/adapt the discrepancy that was not experienced during the simulation-based training.
2. Approach to Solving Geduldspiele Cubes via Sim-to-Real Transfer
2.1. Geduldspiele Cubes in a Robotic Gripper: Flat, Convex, and Concave
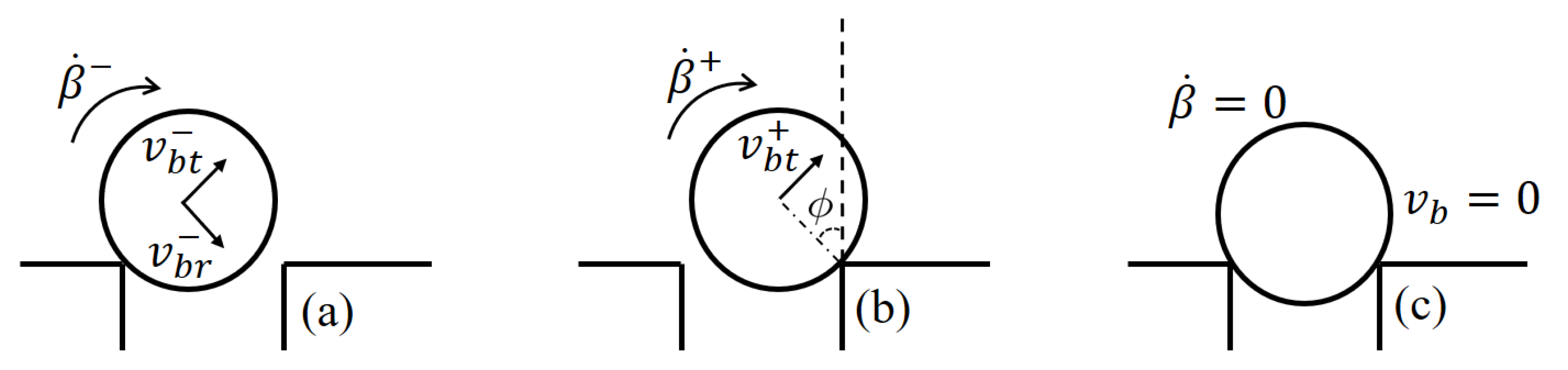
2.2. Dynamic Models: Ball–Plane Model and Ball–Hole Model
- The plane of the geduldspiele is flat.
- The linear velocity of the iron ball always passes through the center of the hole.
2.2.1. Ball–Plane Model
2.2.2. Ball–Hole Model
- (1)
- might be negative, which implies the iron ball will be at the rest position eventually.
- (2)
- might be positive but small, so that it starts to deviate from the hole (this happens when ). If it does not have enough mechanical energy to surely deviate, thenand the iron ball will again be at rest.
- (3)
- might be positive and large enough to deviate from the hole (this happens if ). Afterward, the iron ball will (i) entirely escape from the hole or (ii) hit the boundary of the hole again.
2.3. Derivation of LTI Ball–Plane System Model
2.4. System Architecture for Sim-to-Real Transfer to Solve the Geduldspiele Cubes
2.4.1. Identifying the Friction Coefficient
- Apply the sequence of motor command to a GS cube for 30 s, detect the position of the iron ball, and record those positions at every 200 ms.
- Initialize by arbitrary value. Let ms and run simulations using (21), and generate the trajectory of the ball. Extract every 10th x- and y-position of the ball and store them as (here, a subscript “s” is employed to distinguish the real measurement value from the simulation outputs).
- Define error to be and find that minimizes e.
2.4.2. Defining State, Action, and Algorithm to Virtually Train the Robotic Agent
2.4.3. Our Sim-to-Real Transfer Architecture
- The robotic agent is pretrained with the geduldspiele cube of a flat plane under a reinforcement learning framework adopting PPO in the simulation world and knows .
- In the beginning, the state (measured by camera and mask-RCNN) and reward in/from the real world are sent to the simulator.
- Based on the received state and reward, the robotic agent in the simulation world generates the action to control the robotic manipulator.
- The robotic manipulator takes the action to the geduldspiele cube; as a result, and are sent to the simulator.
- Repeat the above process.
3. Experiments
3.1. Experimental Setup
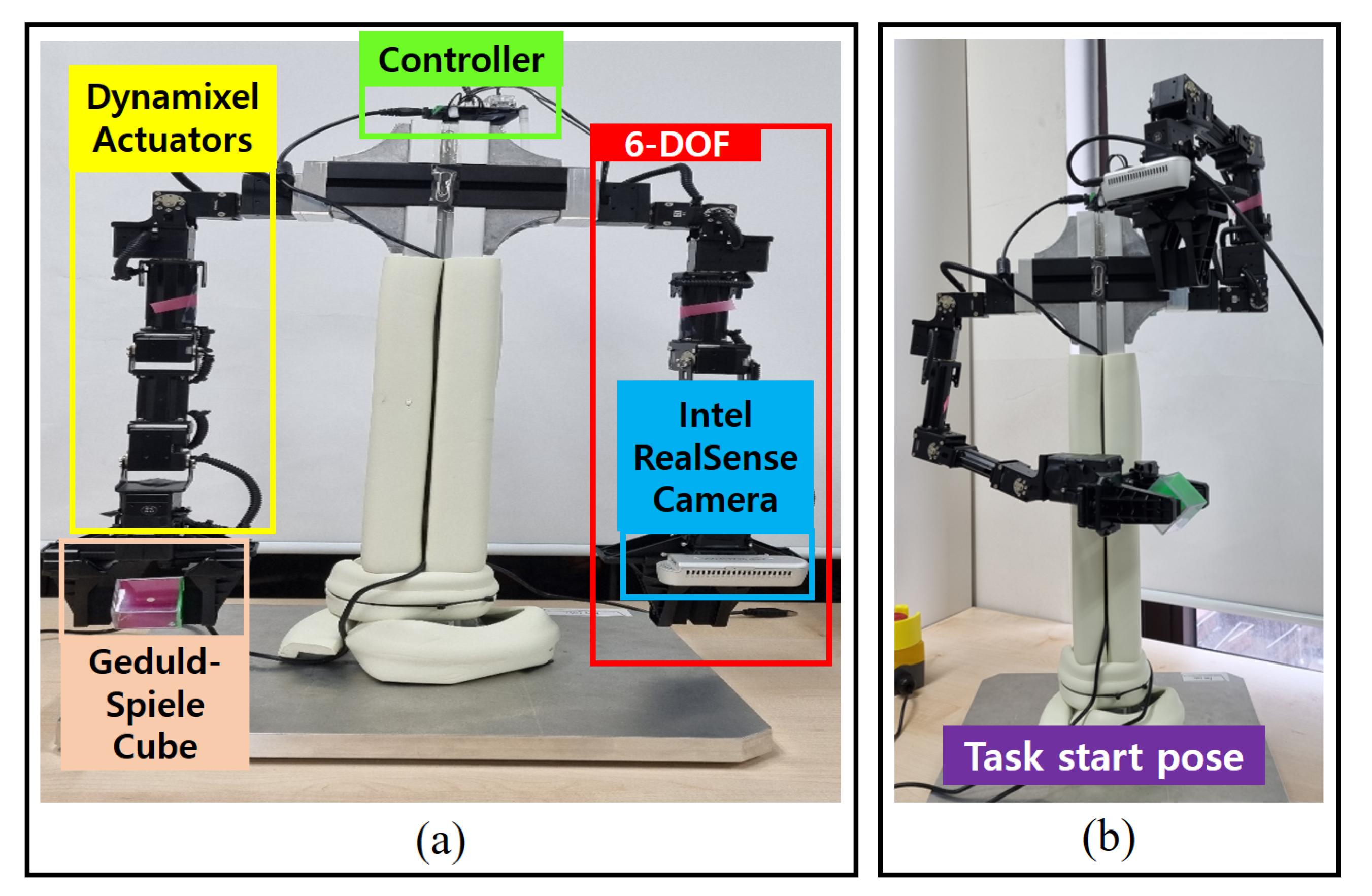
3.1.1. A Dual-Arm Robot, a Geduldspiele Cube, and a Camera in the Real World
3.1.2. A Virtual Wrist–Hand System and a Robotic Agent in the Simulation World
3.1.3. Miscellaneous
- To train YOLO v4, 13,000 iron ball images were used, including light reflections.
- The OS for the main desktop computer was Ubuntu 20.04.
- ROS release was ROS-noetic.
- Unity version was 2020.3.
- ROS and Unity send/receive data via TCP/IP.
3.2. Experiment 1: Training and Evaluating the Task Performance of the Robotic Agent for Solving the Virtual Geduldspiele Cubes in the Simulation Environment
- Given: The three “virtual” geduldspiele cubes.
- Train: The robotic agent with the cube of a flat plane in the simulation world.
- Solve: Each virtual geduldspiele cube in the simulation world.
3.3. Experiment 2: Evaluating the Task Performance of the Trained Robotic Agent for Solving the Geduldspiele Cubes by Real Robotic Systems via Sim-to-Real Transfer
- Given: The three “real” geduldspiele cubes.
- Employ: The “virtually trained” robotic agent with the cube of a flat plane in the simulation world.
- Solve: Each real geduldspiele cube in the real world.
4. Results and Discussion
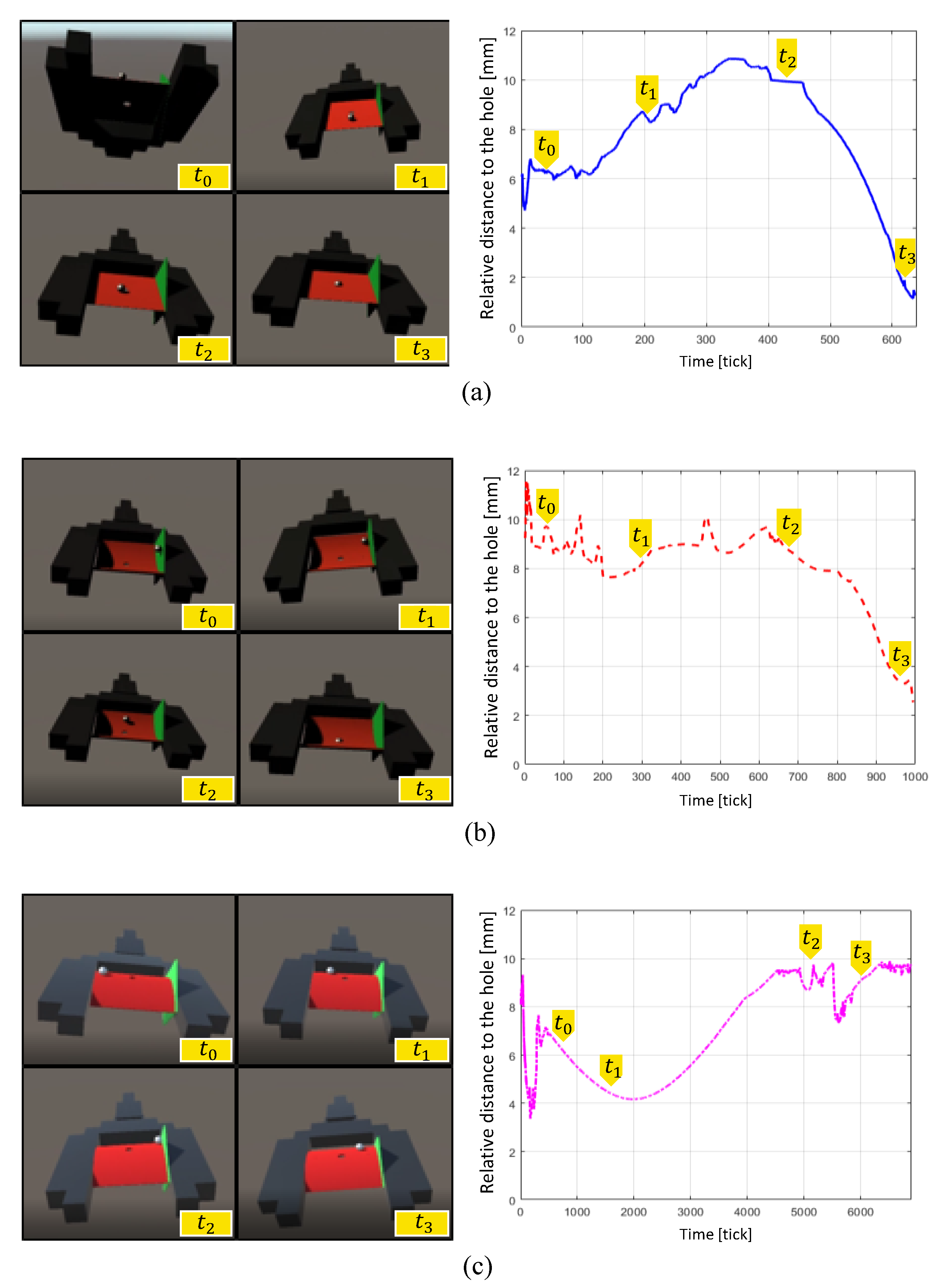
4.1. Result of Experiment 1
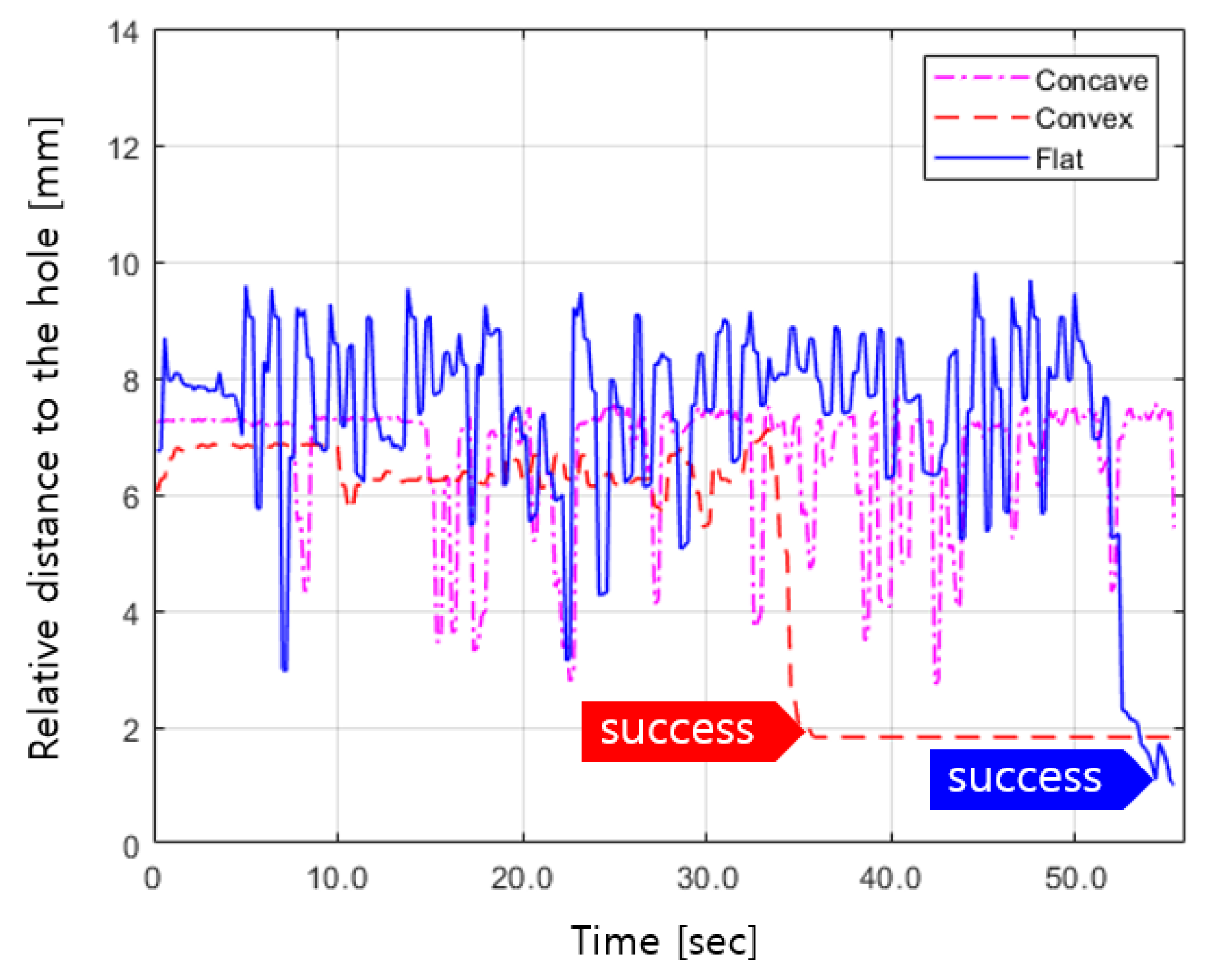
4.2. Result of Experiment 2
4.3. Discussion
- The geduldspiele cubes considered in this study were simpler ones. Generally, the other cubes are much more difficult to solve.
- We set the sampling time for both the sending/receiving and via TCP/IP small enough; however, there might exist a delay which can affect the proposed system performance since it is not indeed real time (or even close to real time).
5. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RL | Reinforcement learning |
| ML | Machine learning |
| GS | Geduldspiele |
| LTI | Linear time invariant |
| PPO | Proximal policy optimization |
| ROS | Robotic Operating System |
References
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-real transfer in deep reinforcement learning for robotics: A survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; pp. 737–744. [Google Scholar]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. Found. Trends® Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef] [Green Version]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Levine, S.; Kumar, A.; Tucker, G.; Fu, J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv 2020, arXiv:2005.01643. [Google Scholar]
- Garcıa, J.; Fernández, F. A comprehensive survey on safe reinforcement learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Du, Y.; Watkins, O.; Darrell, T.; Abbeel, P.; Pathak, D. Auto-tuned sim-to-real transfer. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 1290–1296. [Google Scholar]
- Jin, S.; Zhu, X.; Wang, C.; Tomizuka, M. Contact pose identification for peg-in-hole assembly under uncertainties. In Proceedings of the 2021 American Control Conference (ACC), Online, 25–28 May 2021; pp. 48–53. [Google Scholar]
- Chebotar, Y.; Handa, A.; Makoviychuk, V.; Macklin, M.; Issac, J.; Ratliff, N.; Fox, D. Closing the sim-to-real loop: Adapting simulation randomization with real world experience. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8973–8979. [Google Scholar]
- Matas, J.; James, S.; Davison, A.J. Sim-to-real reinforcement learning for deformable object manipulation. In Proceedings of the Conference on Robot Learning, PMLR, Zürich, Switzerland, 29–31 October 2018; pp. 734–743. [Google Scholar]
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Vezzani, G.; Schulman, J.; Todorov, E.; Levine, S. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. arXiv 2017, arXiv:1709.10087. [Google Scholar]
- Sadeghi, F.; Levine, S. CAD2RL: Real Single-Image Flight without a Single Real Image. arXiv 2016, arXiv:1611.04201. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Bateux, Q.; Marchand, E.; Leitner, J.; Chaumette, F.; Corke, P. Training deep neural networks for visual servoing. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3307–3314. [Google Scholar]
- Arndt, K.; Hazara, M.; Ghadirzadeh, A.; Kyrki, V. Meta reinforcement learning for sim-to-real domain adaptation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Online, 31 May–31 August 2020; pp. 2725–2731. [Google Scholar]
- Puang, E.Y.; Tee, K.P.; Jing, W. Kovis: Keypoint-based visual servoing with zero-shot sim-to-real transfer for robotics manipulation. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 7527–7533. [Google Scholar]
- Todorov, E.; Erez, T.; Tassa, Y. Mujoco: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 5026–5033. [Google Scholar]
- Hwangbo, J.; Lee, J.; Hutter, M. Per-contact iteration method for solving contact dynamics. IEEE Robot. Autom. Lett. 2018, 3, 895–902. [Google Scholar] [CrossRef]
- Ji, G.; Mun, J.; Kim, H.; Hwangbo, J. Concurrent Training of a Control Policy and a State Estimator for Dynamic and Robust Legged Locomotion. IEEE Robot. Autom. Lett. 2022, 7, 4630–4637. [Google Scholar] [CrossRef]
- Berglund, T.; Algoryx Simulation, A.; Mickelsson, K.O.; Servin, L.M. Virtual commissioning of a mobile ore chute. Simulation 2018, 10, 14. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. Airsim: High-fidelity visual and physical simulation for autonomous vehicles. In Field and Service Robotics; Springer: Berlin/Heidelberg, Germany, 2018; pp. 621–635. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Furrer, F.; Burri, M.; Achtelik, M.; Siegwart, R. Rotors—A Modular Gazebo Mav Simulator Framework. In Robot Operating System (ROS); Springer: Berlin/Heidelberg, Germany, 2016; pp. 595–625. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Kaplanis, C.; Shanahan, M.; Clopath, C. Continual reinforcement learning with complex synapses. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2497–2506. [Google Scholar]
- Traoré, R.; Caselles-Dupré, H.; Lesort, T.; Sun, T.; Díaz-Rodríguez, N.; Filliat, D. Continual reinforcement learning deployed in real-life using policy distillation and sim2real transfer. arXiv 2019, arXiv:1906.04452. [Google Scholar]
- Shi, L.; Singh, S.K. Decentralized control for interconnected uncertain systems: Extensions to higher-order uncertainties. Int. J. Control 1993, 57, 1453–1468. [Google Scholar] [CrossRef]
- Amor, R.B.; Elloumi, S. On decentralized control techniques of interconnected systems-application to a double-parallel inverted pendulum. In Proceedings of the 2017 International Conference on Advanced Systems and Electric Technologies (IC_ASET), Hammamet, Tunisia, 14–17 January 2017; pp. 85–90. [Google Scholar]
- Tsividis, P.A.; Pouncy, T.; Xu, J.L.; Tenenbaum, J.B.; Gershman, S.J. Human learning in Atari. In Proceedings of the 2017 AAAI Spring Symposium Series, Stanford, CA, USA, 27–29 March 2017. [Google Scholar]
- Zhu, H.; Gupta, A.; Rajeswaran, A.; Levine, S.; Kumar, V. Dexterous manipulation with deep reinforcement learning: Efficient, general, and low-cost. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montral, QC, Canada, 20–24 May 2019; pp. 3651–3657. [Google Scholar]
- Finn, C.; Yu, T.; Zhang, T.; Abbeel, P.; Levine, S. One-shot visual imitation learning via meta-learning. In Proceedings of the Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 357–368. [Google Scholar]
- Yu, T.; Abbeel, P.; Levine, S.; Finn, C. One-shot hierarchical imitation learning of compound visuomotor tasks. arXiv 2018, arXiv:1810.11043. [Google Scholar]
- Ng, A.Y.; Russell, S. Algorithms for inverse reinforcement learning. In Proceedings of the Seventeenth International Conference on Machine Learning (ICML 2000), Stanford, CA, USA, 29 June–2 July 2000; Volume 1, p. 2. [Google Scholar]
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 1. [Google Scholar]
- Dehghani, M.; Trojovská, E.; Trojovskỳ, P. A new human-based metaheuristic algorithm for solving optimization problems on the base of simulation of driving training process. Sci. Rep. 2022, 12, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Bonardi, A.; James, S.; Davison, A.J. Learning one-shot imitation from humans without humans. IEEE Robot. Autom. Lett. 2020, 5, 3533–3539. [Google Scholar] [CrossRef] [Green Version]
- Rivera, C.G.; Handelman, D.A.; Ratto, C.R.; Patrone, D.; Paulhamus, B.L. Visual Goal-Directed Meta-Imitation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 3767–3773. [Google Scholar]
- Singh, S.P.; Sutton, R.S. Reinforcement learning with replacing eligibility traces. Mach. Learn. 1996, 22, 123–158. [Google Scholar] [CrossRef] [Green Version]
- Hasp Frank, A.; Tjernström, M. Construction and Theoretical Study of a Ball Balancing Platform: Limitations When Stabilizing Dynamic Systems Through Implementation of Automatic Control Theory; KTH Royal Institute of Technology: Stockholm, Sweden, 2019. [Google Scholar]
- Keshmiri, M.; Jahromi, A.F.; Mohebbi, A.; Hadi Amoozgar, M.; Xie, W.F. Modeling and control of ball and beam system using model based and non-model based control approaches. Int. J. Smart Sens. Intell. Syst. 2012, 5. [Google Scholar] [CrossRef] [Green Version]
- Holmes, B.W. Putting: How a golf ball and hole interact. Am. J. Phys. 1991, 59, 129–136. [Google Scholar] [CrossRef]
- Hubbard, M.; Smith, T. Dynamics of golf ball-hole interactions: Rolling around the rim. Trans. ASME 1999, 121, 88–95. [Google Scholar] [CrossRef]
- Kuchnicki, S. Interaction of a golf ball with the flagstick and hole. Sport. Eng. 2021, 24, 1–9. [Google Scholar] [CrossRef]
- Coefficient of Friction, Rolling Resistance and Aerodynamics, Coefficient of Friction for a Range of Material Combinations. Available online: https://www.tribology-abc.com/abc/cof.htm (accessed on 23 September 2022).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Unity Technologies. PPO-Specific Configurations. Available online: https://github.com/Unity-Technologies/ml-agents/blob/release_18_docs/docs/Training-Configuration-File.md#ppo-specific-configurations (accessed on 23 September 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Symbol | Value | Unit |
|---|---|---|---|
| Ball mass | kg | ||
| Ball radius | m | ||
| The moment of inertia of the ball | kg · m | ||
| Plate mass | l | kg | |
| Plate length | and | and | m |
| The moment of inertia of the plate | and | and | kg · m |
| Coefficient of friction | 0.3604 Identified (see Section 2.4.1) |
| i | Remark | ||||
|---|---|---|---|---|---|
| 1 | 0 | 77 | 0 | spherical shoulder #1 | |
| 2 | 0 | 0 | spherical shoulder #2 | ||
| 3 | 0 | 164 | upper arm | ||
| 4 | 24 | 0 | 0 | elbow | |
| 5 | 124 | 0 | spherical wrist #1 | ||
| 6 | 0 | 0 | 0 | spherical wrist #2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, J.-H.; Jung, H.-J.; Kim, J.-H.; Sim, D.-H.; Yoon, H.-U. Solving a Simple Geduldspiele Cube with a Robotic Gripper via Sim-to-Real Transfer. Appl. Sci. 2022, 12, 10124. https://doi.org/10.3390/app121910124
Yoo J-H, Jung H-J, Kim J-H, Sim D-H, Yoon H-U. Solving a Simple Geduldspiele Cube with a Robotic Gripper via Sim-to-Real Transfer. Applied Sciences. 2022; 12(19):10124. https://doi.org/10.3390/app121910124
Chicago/Turabian StyleYoo, Ji-Hyeon, Ho-Jin Jung, Jang-Hyeon Kim, Dae-Han Sim, and Han-Ul Yoon. 2022. "Solving a Simple Geduldspiele Cube with a Robotic Gripper via Sim-to-Real Transfer" Applied Sciences 12, no. 19: 10124. https://doi.org/10.3390/app121910124