
CSS: Container Resource Manager Using System Call Pattern for Scientific Workflow

Abstract
:1. Introduction
- We developed a technique, SBCC, to classify the types of containers’ resource usage by using the number of futex system calls of tasks executed in the Singularity container runtime.
- We developed a technique, CTBRA, that allocates minimum resources to containers performing IO-intensive tasks and distributes isolated resources equally to containers performing CPU-intensive tasks.
- We developed CSS, a prototype research manager that implements the proposed dynamic resource management technique and demonstrated its effectiveness by performing experiments with NPB (NAS Parallel Benchmark) and CANU framework work.
2. Motivation
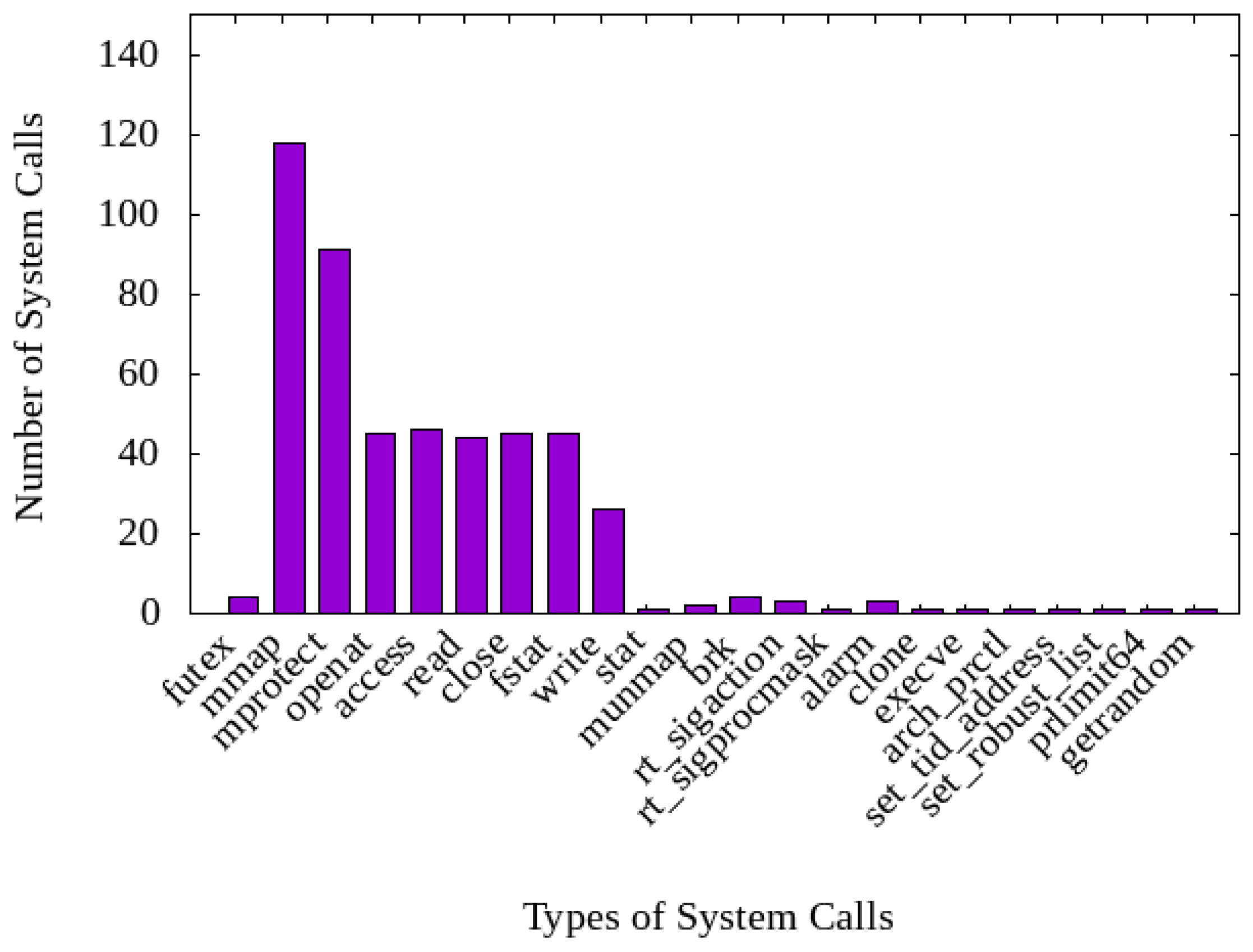
2.1. System Call Pattern
2.2. Resource Management Using Linux Cgroups
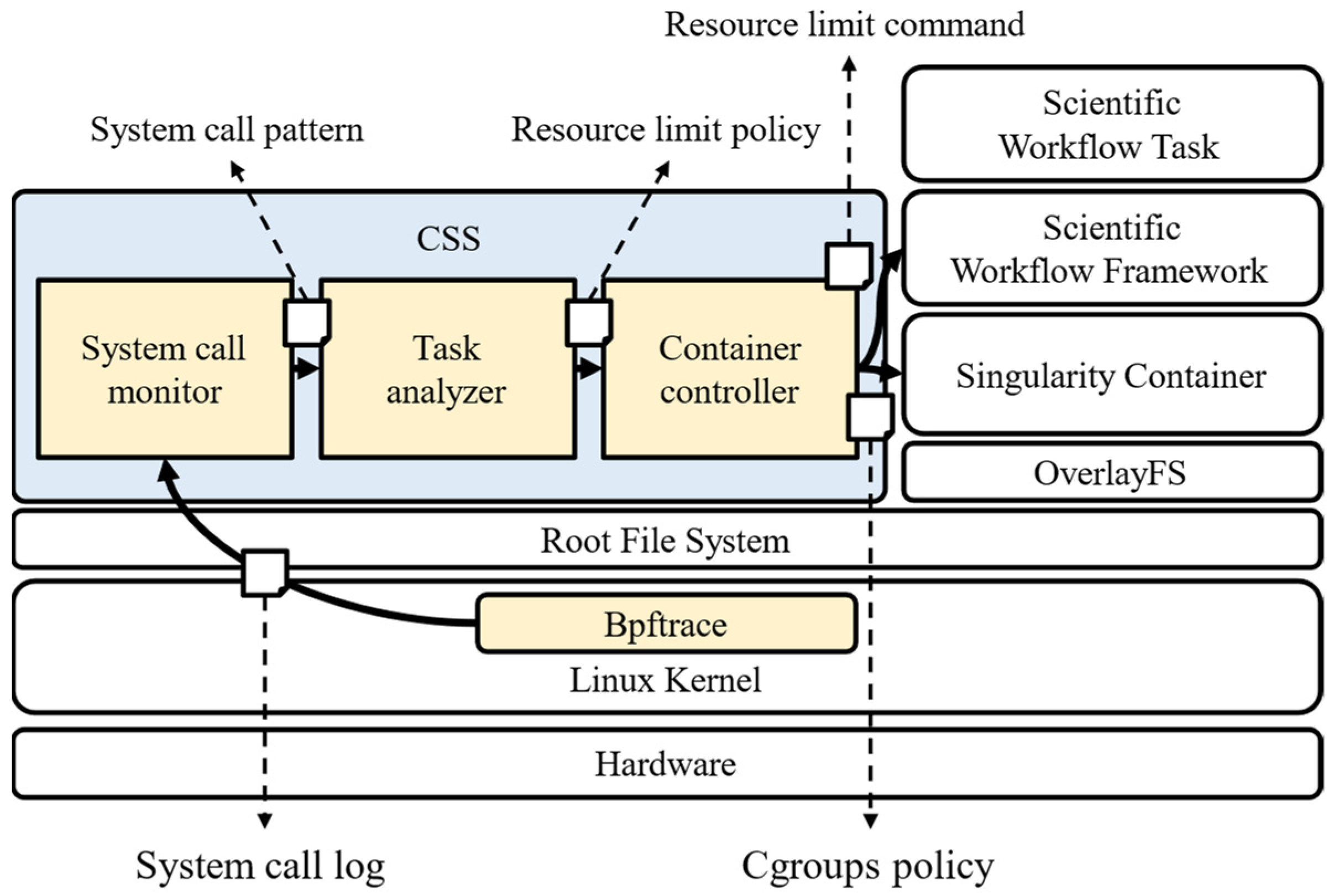
3. Our Solution: CSS
3.1. Design Principle
- Transparent resource management. The resource manager runs as a background service on the host operating system and has a container-independent life cycle. Users can freely use the resource manager without modifying the source code or building a new container. For this purpose, CSS collects the currently running container information based on the namespace information of the host operating system.
- Minimized monitoring overhead. CSS is designed to minimize the overhead of collecting monitoring metrics required for container resource management. When an additional monitoring tool is introduced to measure the resource usage of a container, some overhead is added. In order to eliminate the resource management overhead and have a simple structure, CSS uses the system call log collected for the purpose of strengthening the existing security level.
- Minimized resource coordination overhead. The cgroups technique is used for giving a policy of using computing resources to one process. When resource management is performed for all processes that are hierarchically created inside multiple containers, resource coordination overhead is caused. Therefore, to simplify the management operation, the resource management policy is copied in each container, and the copied resource management policy is applied to each container’s child processes collectively. In addition, if resource management is performed very frequently, the overhead for resource adjustment is proportionally increased. Since the appropriate resource management interval is determined according to the specifications of the computing system, an interface with which the administrator can set the resource management interval is provided.
3.2. Architecture
- System call monitor. It is a component with the role of collecting futex system calls to derive the resource usage type of the container. It collects the PIDs of running containers through the namespace and manages them in a tree structure. It also monitors system calls that occur in subprocesses created inside the container. The number of collected system calls is stored in the PID tree for the container. The number of occurrences of system calls is accumulated for each resource management interval, and it is initialized for each cleaning interval. The system administrator sets the resource management interval according to the physical system specification and the cleaning interval according to the size of one job.
- Task analyzer. It analyzes monitoring data, creates resource management policies, and performs functions corresponding to the Analysis and Plan stages in the MAPE-K model. It analyzes data stored in the PID tree created by the system call monitor at each resource management interval; based on the analysis, the task analyzer creates a cgroups policy that determines CPU quota. Specific techniques for resource management are described in detail in the next section.
- Container controller. It has the role of applying the resource management policy created by the task analyzer to the container. The cgroups policy, created by the task analyzer, starts the Singularity container runtime process as root and applies to all processes under it. The cgroups policy applied to the container is changed when the container type is changed, or a new container is added.
3.3. Resource Management
3.3.1. SBCC (System Call-Based Container Classifier)
| Algorithm 1 SBCC |
| Input: , Output: , 01: Collect Singularity container information and assign it to C 02: Collect system calls that occur inside the container 03: for in 04: ← 05: if ≥ then 06: add to 07: else 08: add to 09: end if 10: end for 11: return , |
3.3.2. CTBRA (Container Type-Based Resource Allocator)
| Algorithm 2 CTBRA |
| Input: , , , Output: null 01: forin 02: if != 0 then 03: 04: else 05: 06: end if 07: end for 08: for in 09: 10: end for 11: return null |
| Algorithm 3 Equal Allocation |
| Input: , Output: null 01: if > then 02: 03: * 04: 05: else 06: 07: 08: end if 09: 10: return null |
4. Evaluation
4.1. Experimental Environment
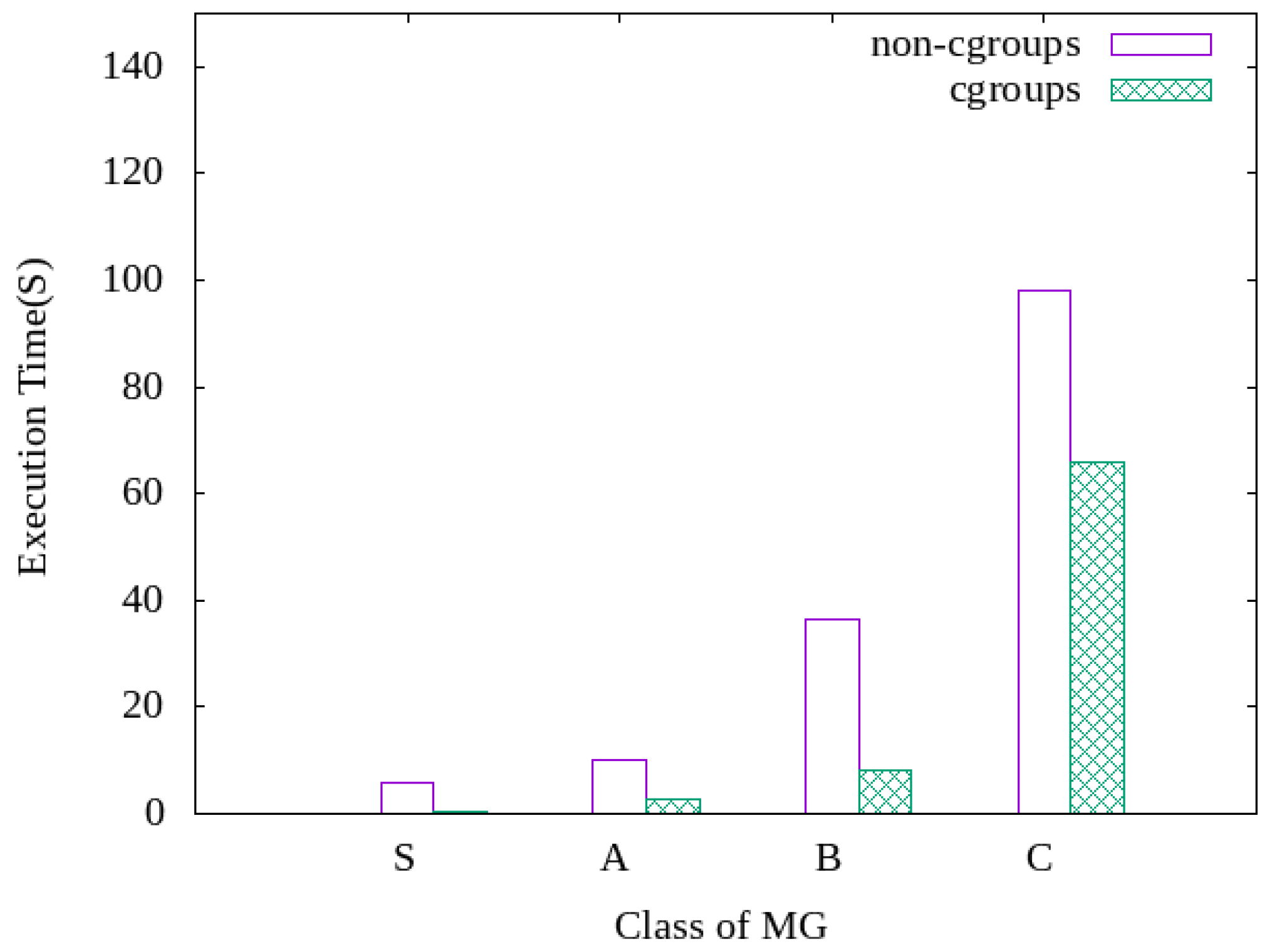
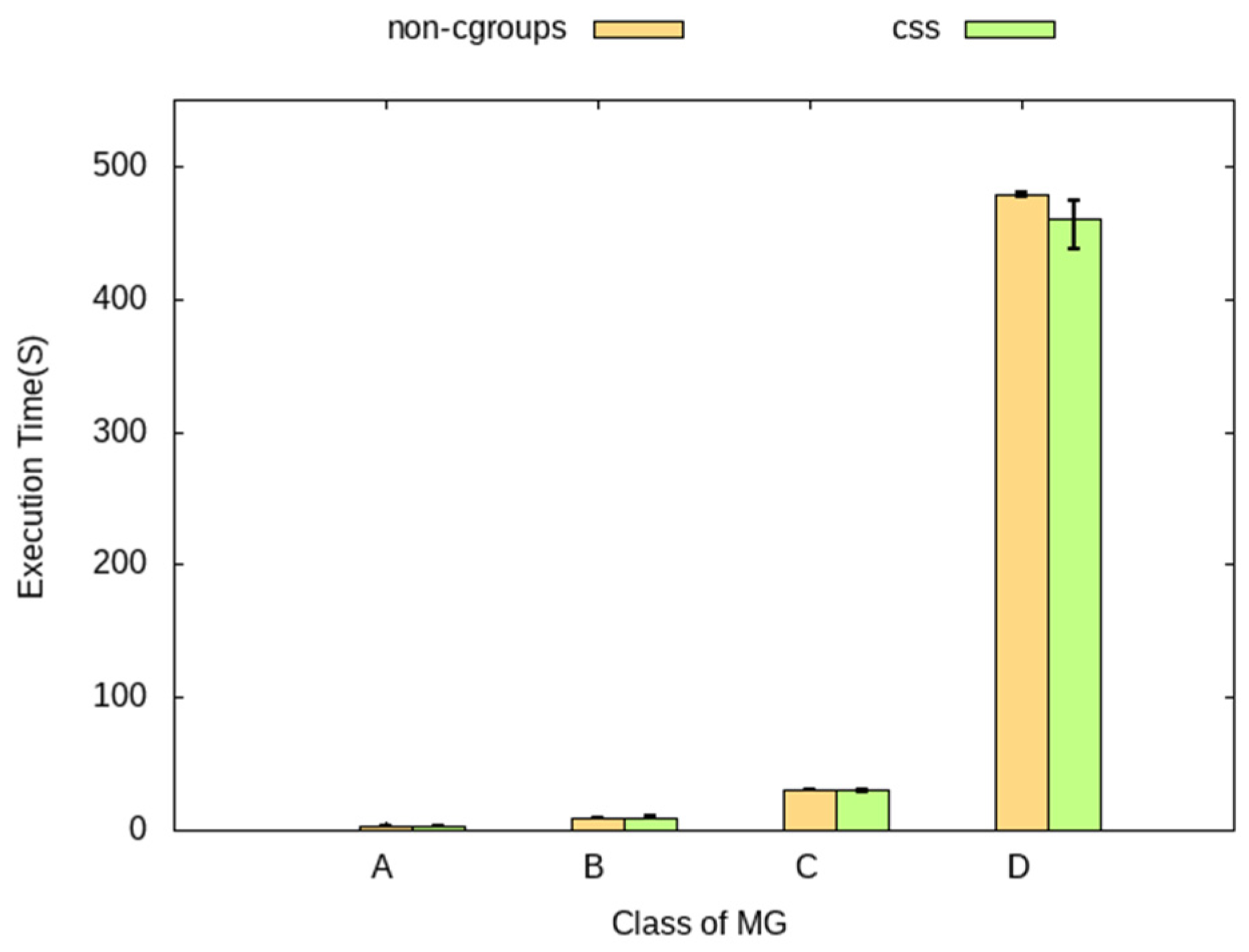
4.2. Performance Analysis for Various Workload Sizes
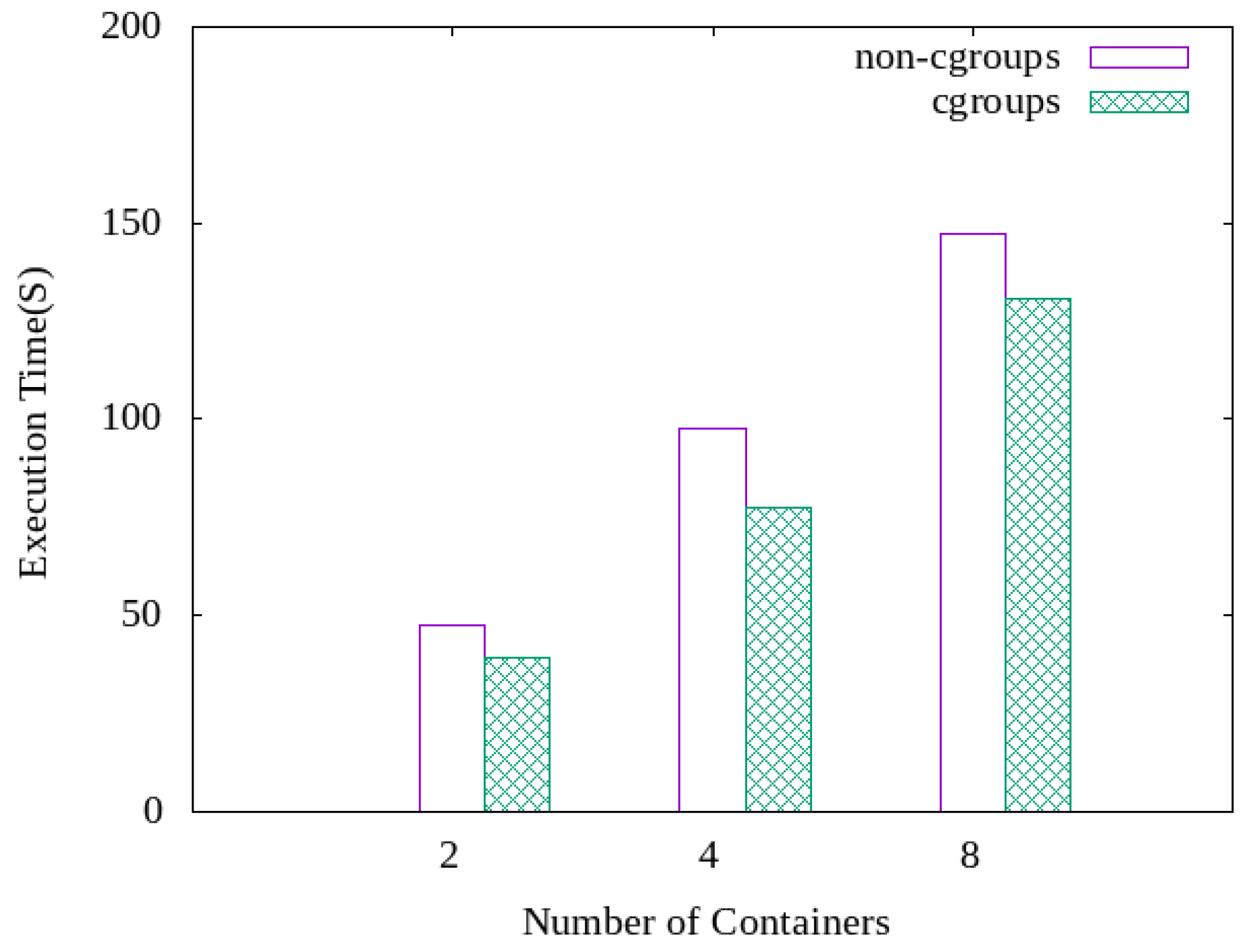
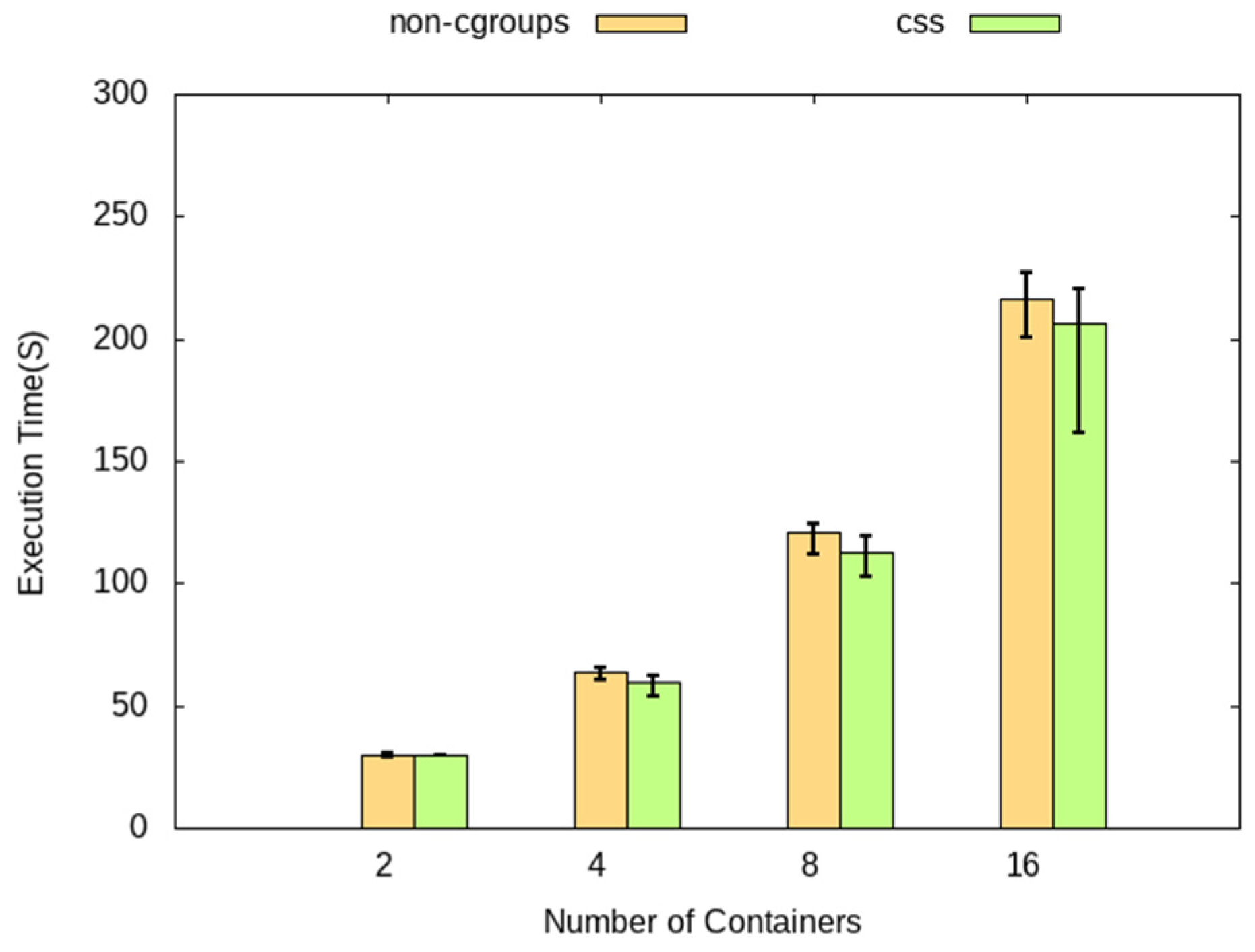
4.3. Performance Analysis for Different Numbers of Containers
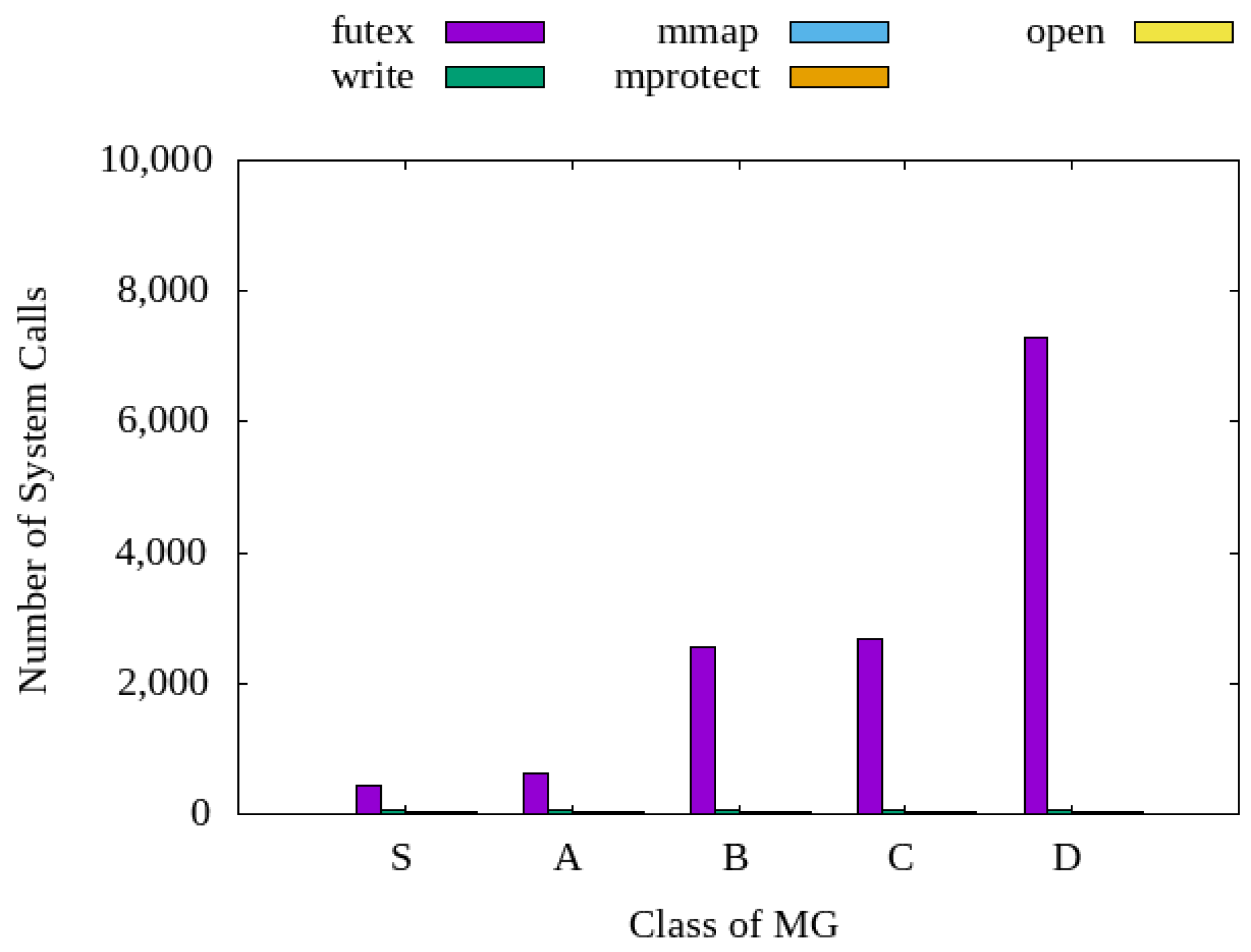
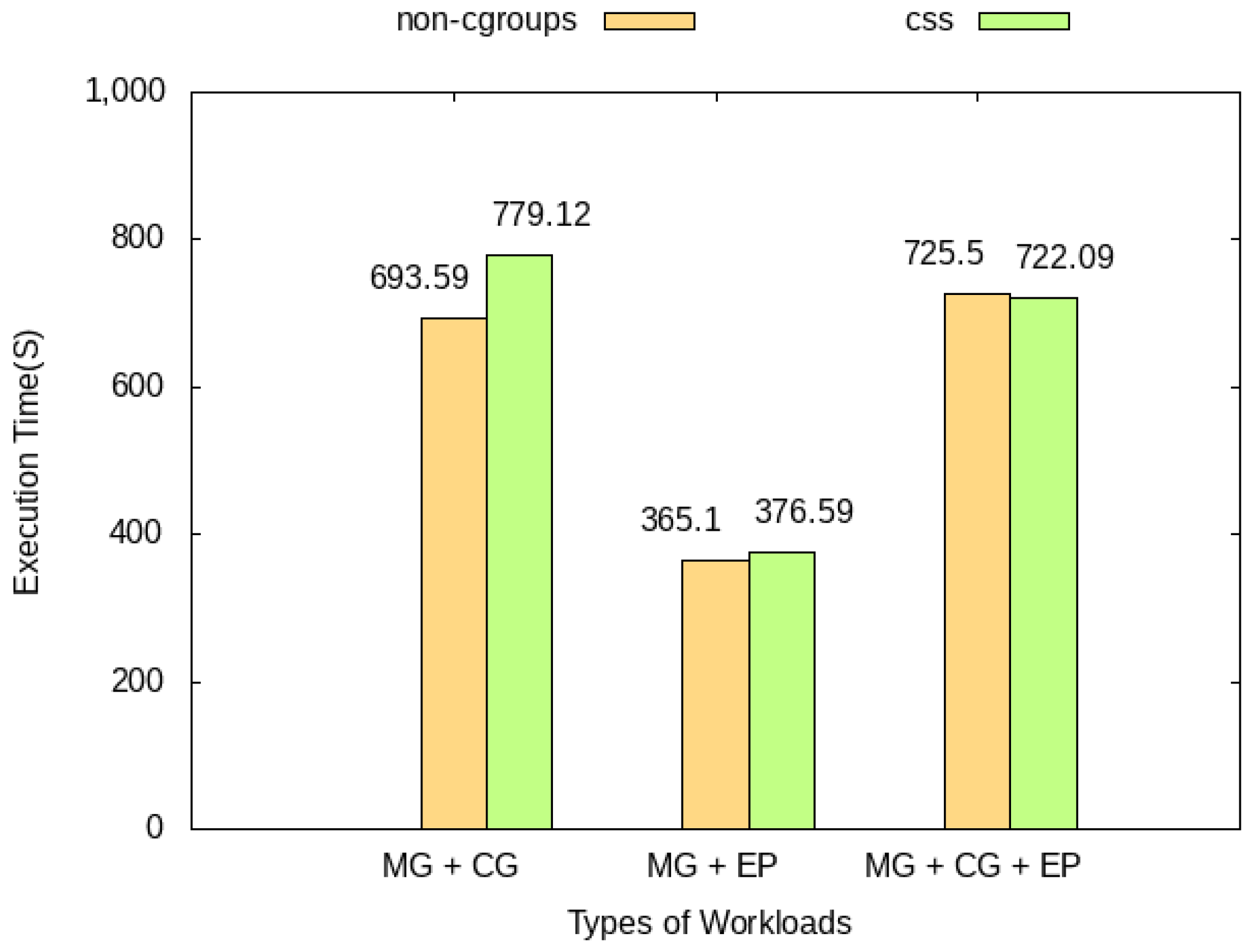
4.4. Performance Analysis for Heterogeneity of Concurrent Tasks
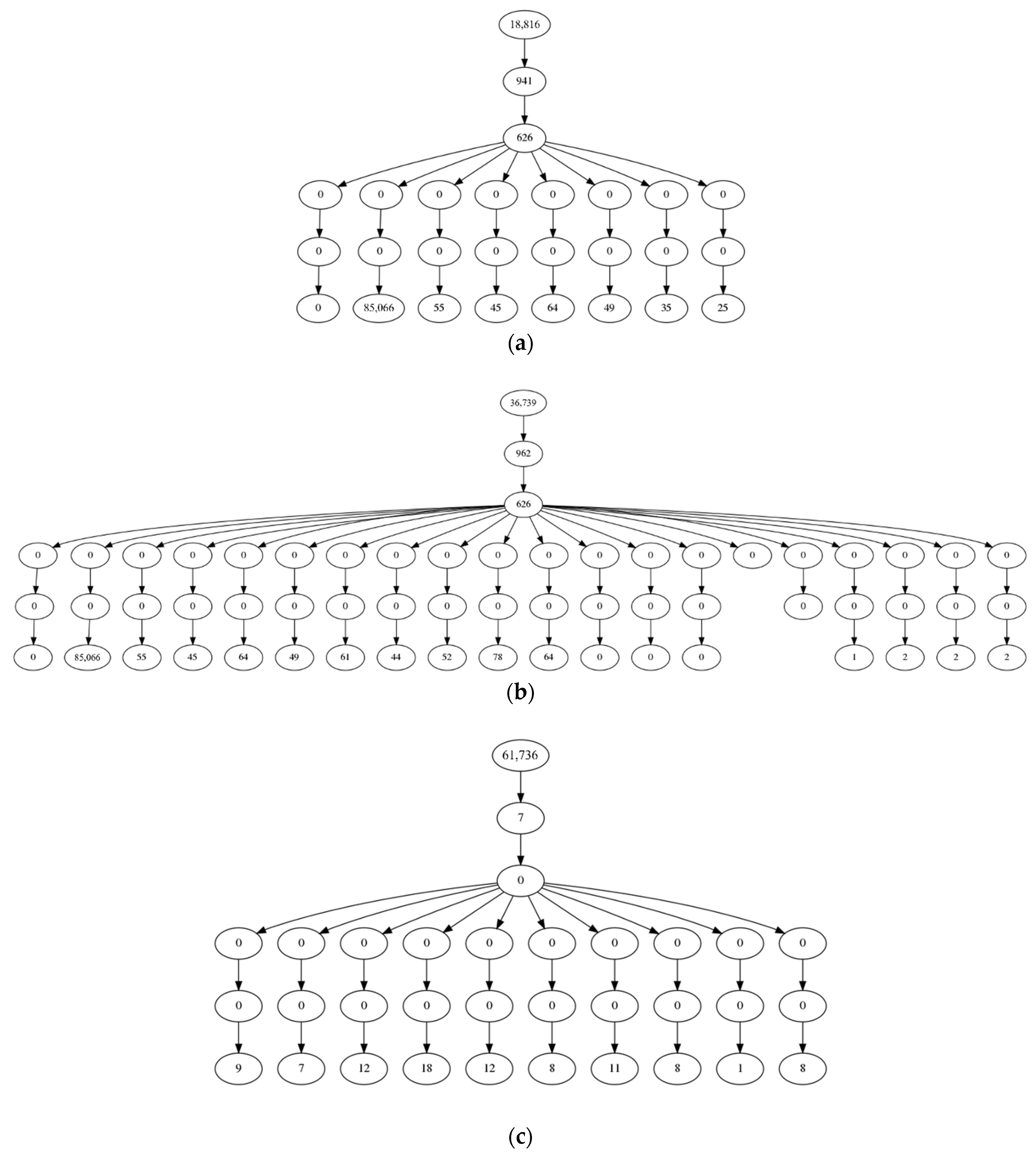
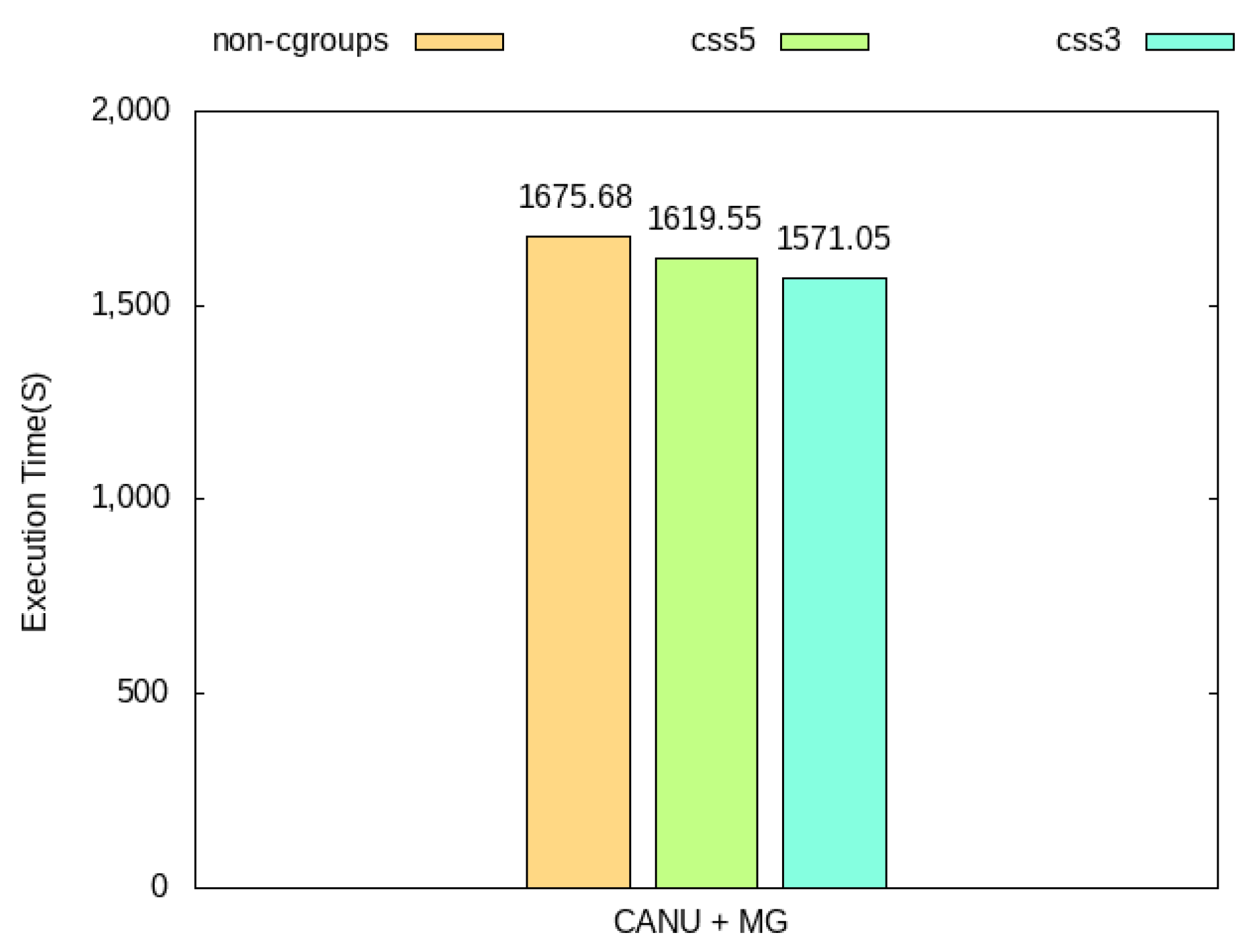
4.5. Validation of Scientific Workflow
5. Related Works
5.1. System Call Monitoring for Container
5.2. Container Resource Management
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rao, V.; Singh, V.; Goutham, K.S.; Kempaiah, B.U.; Mampilli, R.J.; Kalambur, S.; Sitaram, D. Scheduling Microservice Containers on Large Core Machines Through Placement and Coalescing. In Proceedings of the Workshop on Job Scheduling Strategies for Parallel Processing (JSSPP), Virtual, 21 May 2021; pp. 80–100. [Google Scholar]
- Al-Dhuraibi, Y.; Paraiso, F.; Djarallah, N.; Merle, P. Autonomic vertical elasticity of docker containers with elasticdocker. In Proceedings of the 10th International Conference on Cloud Computing (CLOUD), Honolulu, HI, USA, 25–30 June 2017; pp. 472–479. [Google Scholar]
- Runsewe, O.; Samaan, N. CRAM: A container resource allocation mechanism for big data streaming applications. In Proceedings of the International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Larnaca, Cyprus, 14–17 May 2019; pp. 312–320. [Google Scholar]
- Hu, Y.; de Laat, C.D.; Zhao, Z. Multi-objective container deployment on heterogeneous clusters. In Proceedings of the International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Larnaca, Cyprus, 14–17 May 2019; pp. 592–599. [Google Scholar]
- Tan, B.; Ma, H.; Mei, Y. A NSGA-II-based Approach for Multi-objective Micro-service Allocation in Container-based Clouds. In Proceedings of the International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, Australia, 11–14 May 2020; pp. 282–289. [Google Scholar]
- Nikkhah, S.T.; Geilen, M.; Goswami, D.; Koedam, M.; Nelson, A.; Goossens, K. A Deployment Framework for Quality-Sensitive Applications in Resource-Constrained Dynamic Environments. In Proceedings of the 24th Euromicro Conference on Digital System Design (DSD), Palermo, Italy, 1–3 September 2021; pp. 212–220. [Google Scholar]
- Skarlatos, D.; Chen, Q.; Chen, J.; Xu, T.; Torrellas, J. Draco: Architectural and operating system support for system call security. In Proceedings of the International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; pp. 42–57. [Google Scholar]
- Cgroups Web Documentation. Available online: https://www.kernel.org/doc/documentation/cgroup-v1/cgroups.txt (accessed on 22 June 2022).
- Kurtzer, G.M.; Sochat, V.; Bauer, M.W. Singularity: Scientific containers for mobility of compute. PLoS ONE 2017, 12, e0177459. [Google Scholar] [CrossRef] [PubMed]
- Npb Website. Available online: https://www.nas.nasa.gov/software/npb.html (accessed on 22 June 2022).
- Song, C.; Gil, J.; Lim, J. A Performance Analysis on HPC Task Using cgroups in Singularity Container Runtime Environment. In Proceedings of the KIPS Annual Spring Conference, Seoul, Korea, 19–21 May 2022; pp. 25–27. [Google Scholar]
- Feeley, M.J.; Chase, J.S.; Lazowska, E.D. User-Level Threads and Interprocess Communication; Technical Report 93-02-03; University of Washington, Department of Computer Science and Engineering: Seattle, WA, USA, 1993. [Google Scholar]
- Kephart, J.O.; Chess, D.M. The vision of autonomic computing. Computer 2003, 36, 41–50. [Google Scholar] [CrossRef]
- Bpftrace Github Repository. Available online: https://github.com/iovisor/bpftrace (accessed on 22 June 2022).
- Containerd Website. Available online: https://containerd.io (accessed on 22 June 2022).
- PacBio DevNet Website. Available online: http://pacbiodevnet.com (accessed on 22 June 2022).
- Ghavamnia, S.; Palit, T.; Benameur, A. Confine: Automated system call policy generation for container attack surface reduction. In Proceedings of the 23rd International Symposium on Research in Attacks, Intrusions and Defenses (RAID), San Sebastian, Spain, 14–15 October 2020; pp. 443–458. [Google Scholar]
- Wang, X.; Shen, Q.; Luo, W.; Wu, P. RSDS: Getting System Call Whitelist for Container Through Dynamic and Static Analysis. In Proceedings of the 13th IEEE International Conference on Cloud Computing (CLOUD), Virtual Event, 18–24 October 2020; pp. 600–608. [Google Scholar]
- Kim, S.; Kim, B.; Lee, D. Prof-gen: Practical Study on System Call Whitelist Generation for Container Attack Surface Reduction. In Proceedings of the 14th IEEE International Conference on Cloud Computing, (CLOUD), Chicago, IL, USA, 5–10 September 2021; pp. 278–287. [Google Scholar]
- Russo, G.R.; Cardellini, V.; Casale, G.; Presti, F.L. MEAD: Model-Based Vertical Auto-Scaling for Data Stream Processing. In Proceedings of the International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, Australia, 10–13 May 2021; pp. 314–323. [Google Scholar]
- Hobson, T.; Yildiz, O.; Nicolae, B.; Huang, J.; Peterka, T. Shared-Memory Communication for Containerized Workflows. In Proceedings of the International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, Australia, 10–13 May 2021; pp. 123–132. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Grid Size | Number of Iterations |
|---|---|---|
| S | 32 × 32 × 32 | 4 |
| A | 256 × 256 × 256 | 4 |
| B | 256 × 256 × 256 | 20 |
| C | 512 × 512 × 512 | 20 |
| D | 1024 × 1024 × 1024 | 50 |
| Task | Non-Cgroup | Cgroup | Ratio |
|---|---|---|---|
| BT | 782 | 245 | 3.13 |
| IS | 919 | 380 | 2.42 |
| MG | 50,513 | 28,878 | 1.75 |
| Symbol | Description |
|---|---|
| } | |
| } | |
| IO-intensive container set | |
| CPU-intensive container set | |
| Threshold of number of system calls | |
| -type containers | |
| container |
| Parameter | Value |
|---|---|
| 30 | |
| 2 | |
| Resource Management Interval | 5 |
| Cleaning Interval | 30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, C.; Yu, H.; Lee, E. CSS: Container Resource Manager Using System Call Pattern for Scientific Workflow. Appl. Sci. 2022, 12, 8228. https://doi.org/10.3390/app12168228
Song C, Yu H, Lee E. CSS: Container Resource Manager Using System Call Pattern for Scientific Workflow. Applied Sciences. 2022; 12(16):8228. https://doi.org/10.3390/app12168228
Chicago/Turabian StyleSong, Chunggeon, Heonchang Yu, and Eunyoung Lee. 2022. "CSS: Container Resource Manager Using System Call Pattern for Scientific Workflow" Applied Sciences 12, no. 16: 8228. https://doi.org/10.3390/app12168228