
Data-Based Stakeholder Identification in Technical Change Management

Abstract
:1. Introduction
2. Fundamentals
2.1. Stakeholder Identification
2.2. Management of Technical Changes
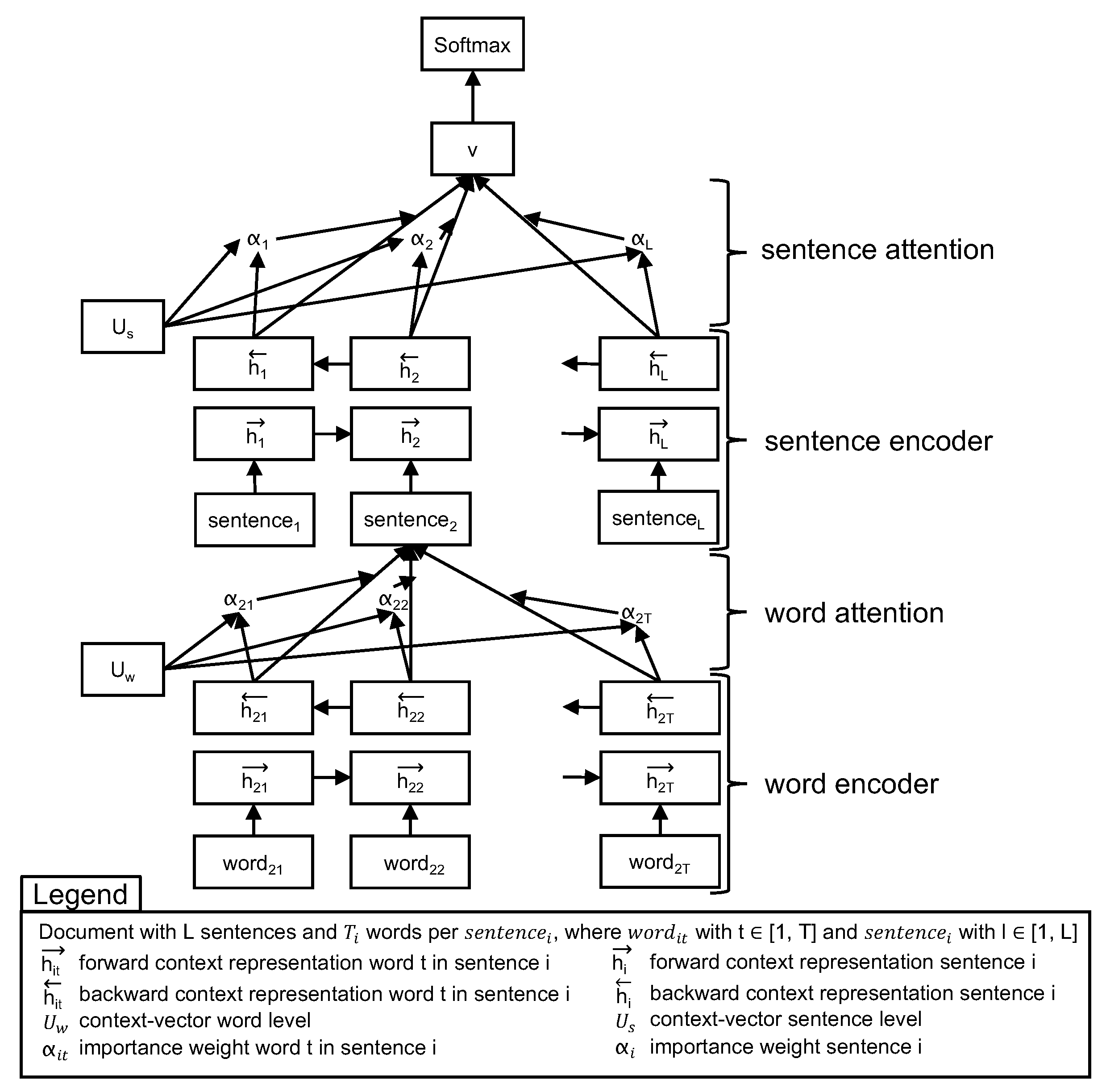
2.3. Text Classification

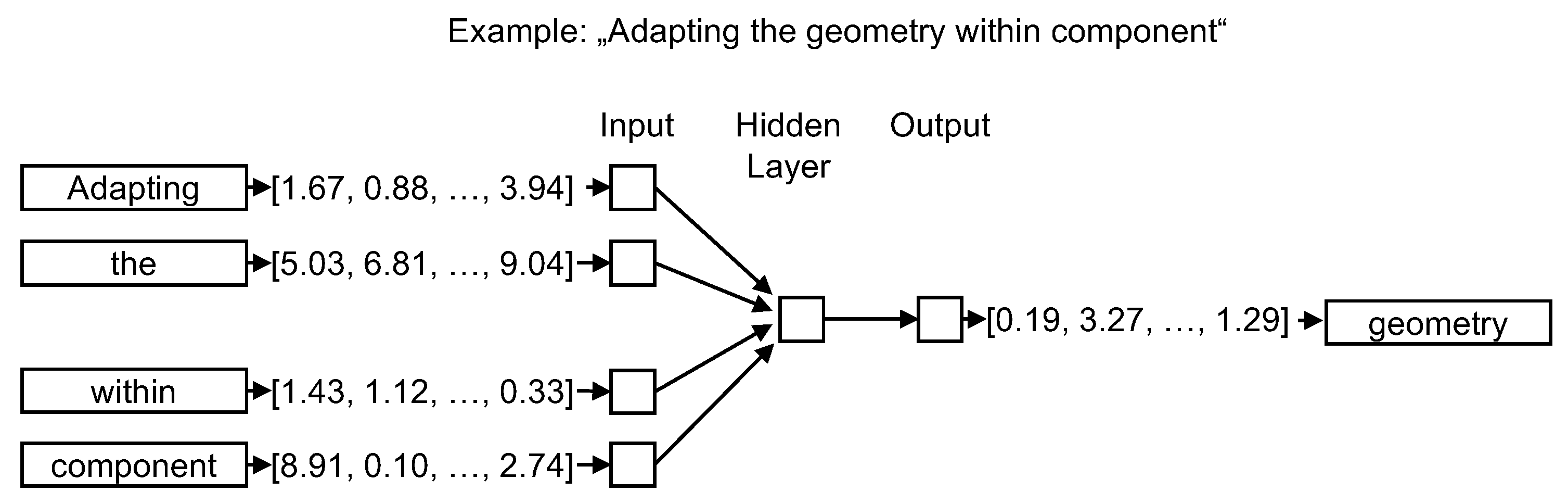
2.4. Word Embeddings
3. State of Research
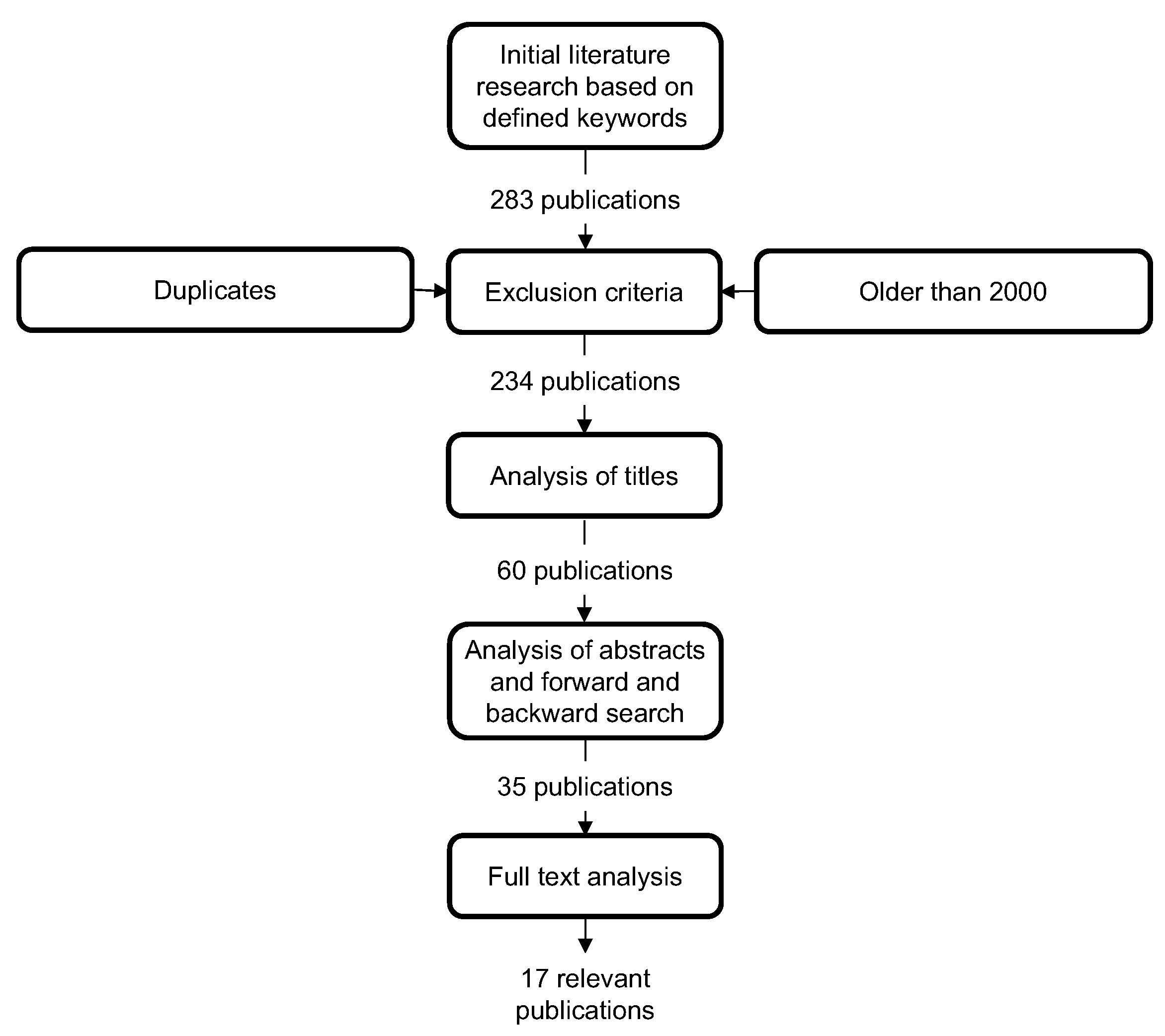
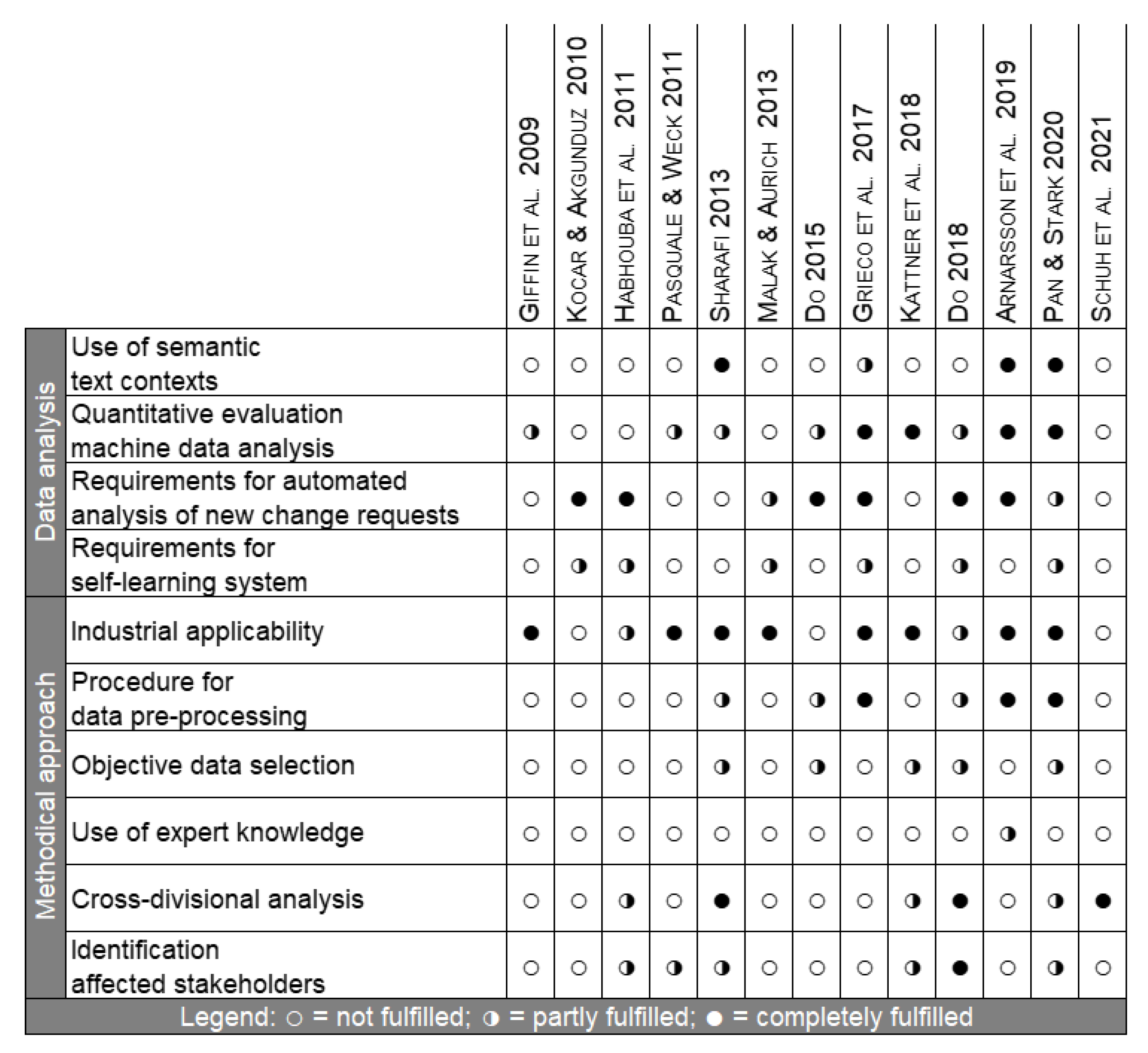
3.1. Relevant Preliminary Work
3.2. Shortcomings
4. Requirements
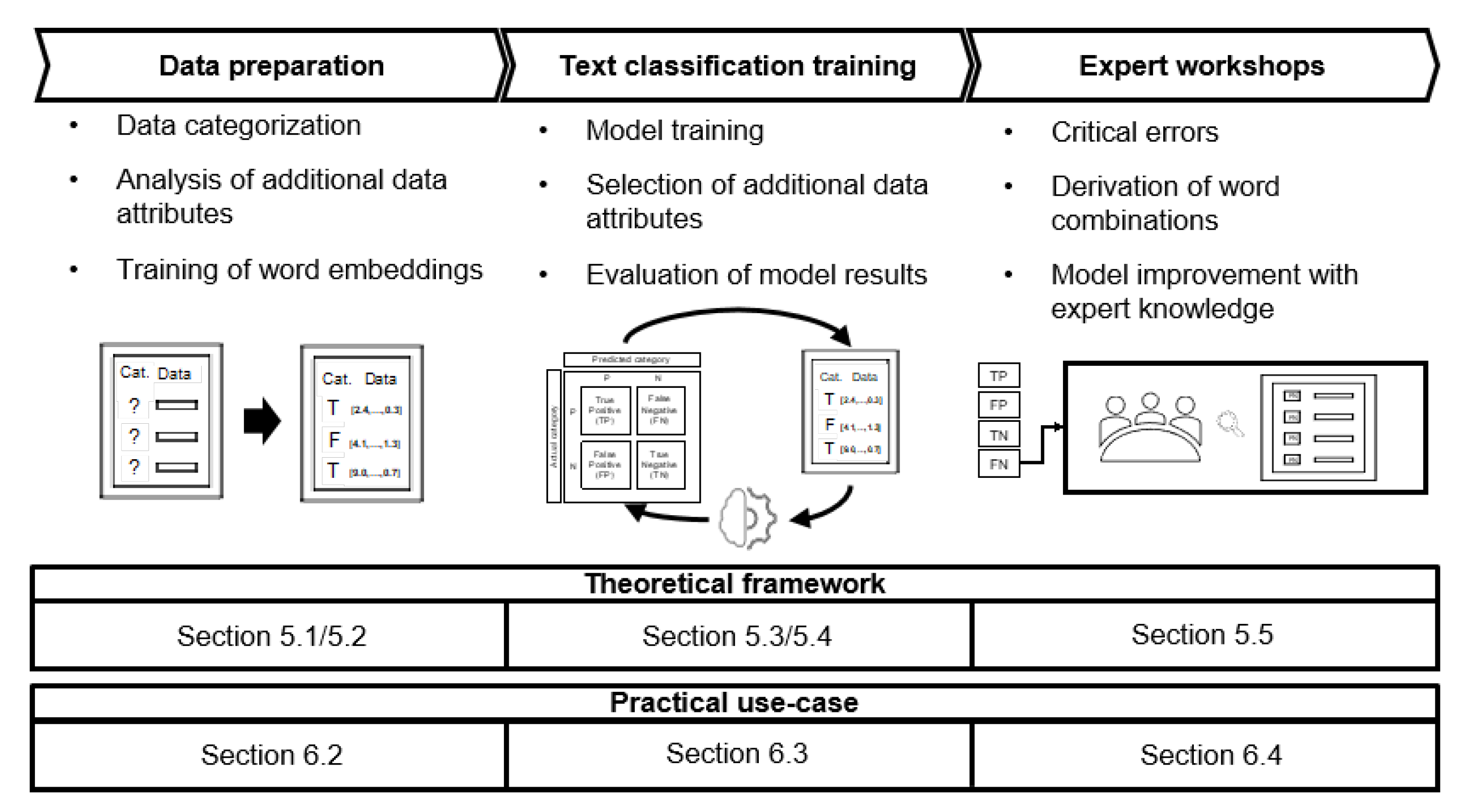
5. Methodology for Data-Based SI
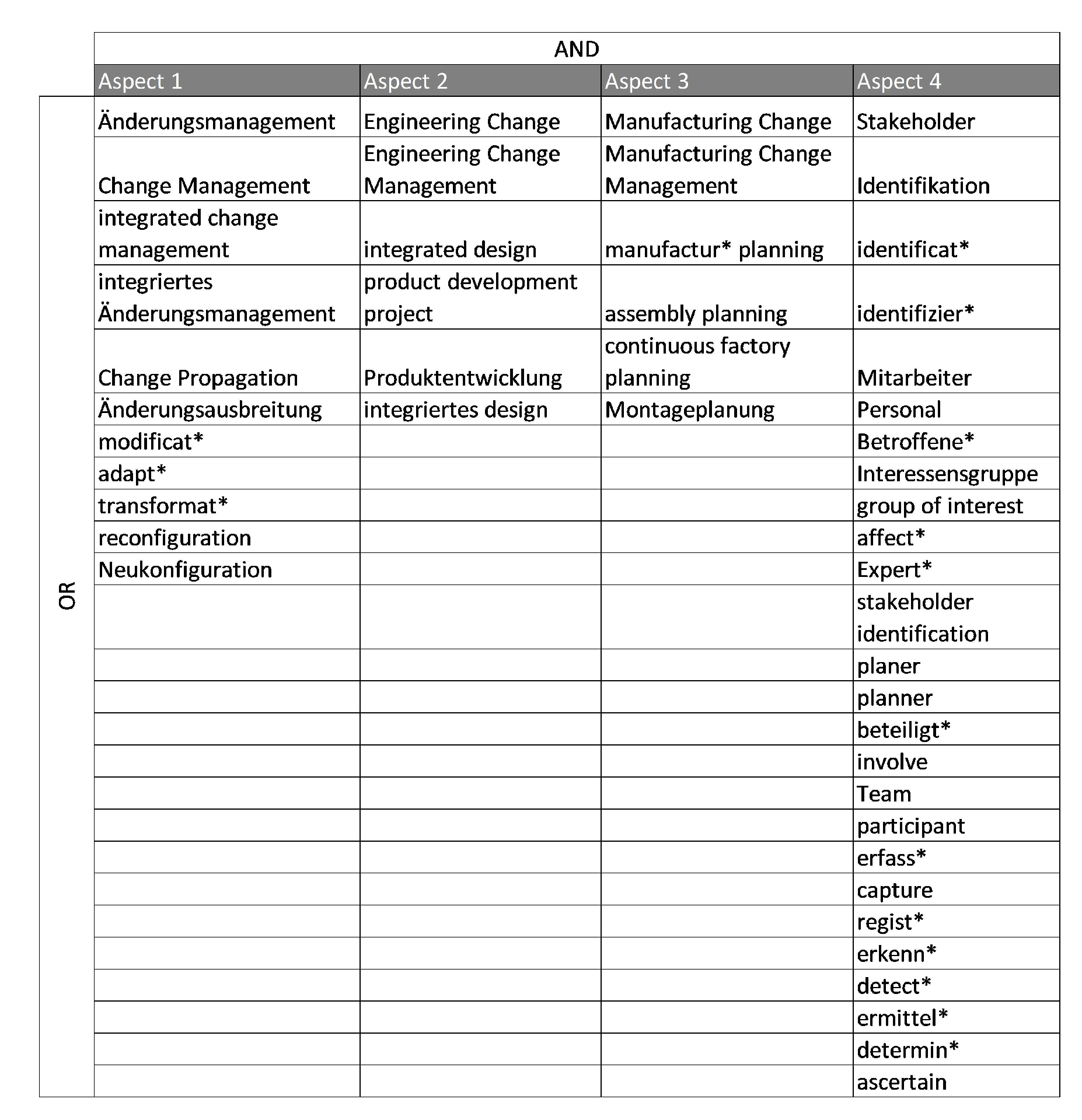
5.1. Data Preparation
5.2. Transformation of Textual Data into Numerical Data
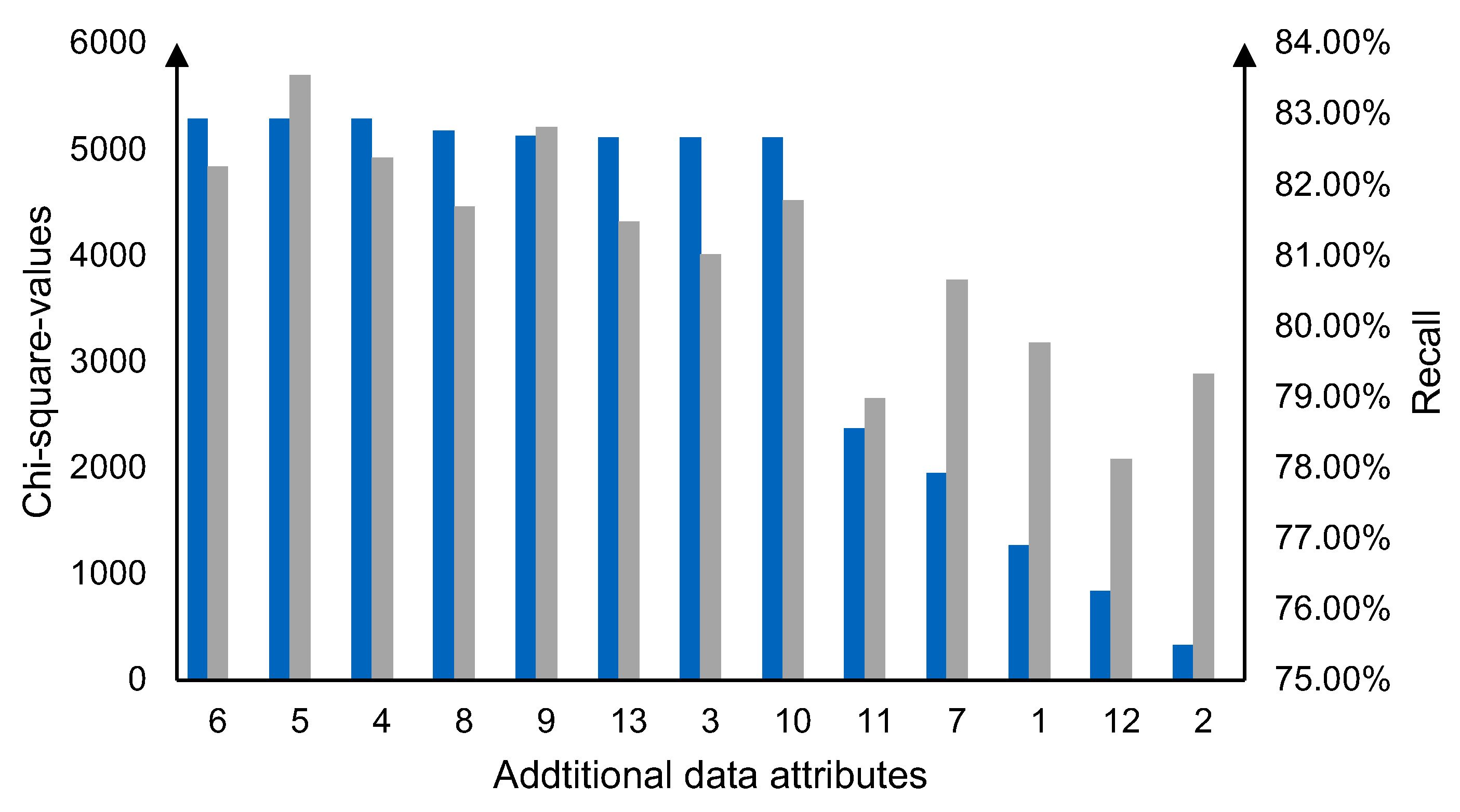
5.3. Feature Selection
5.4. Training of Machine Learning Models
5.5. Integration of Expert Knowledge
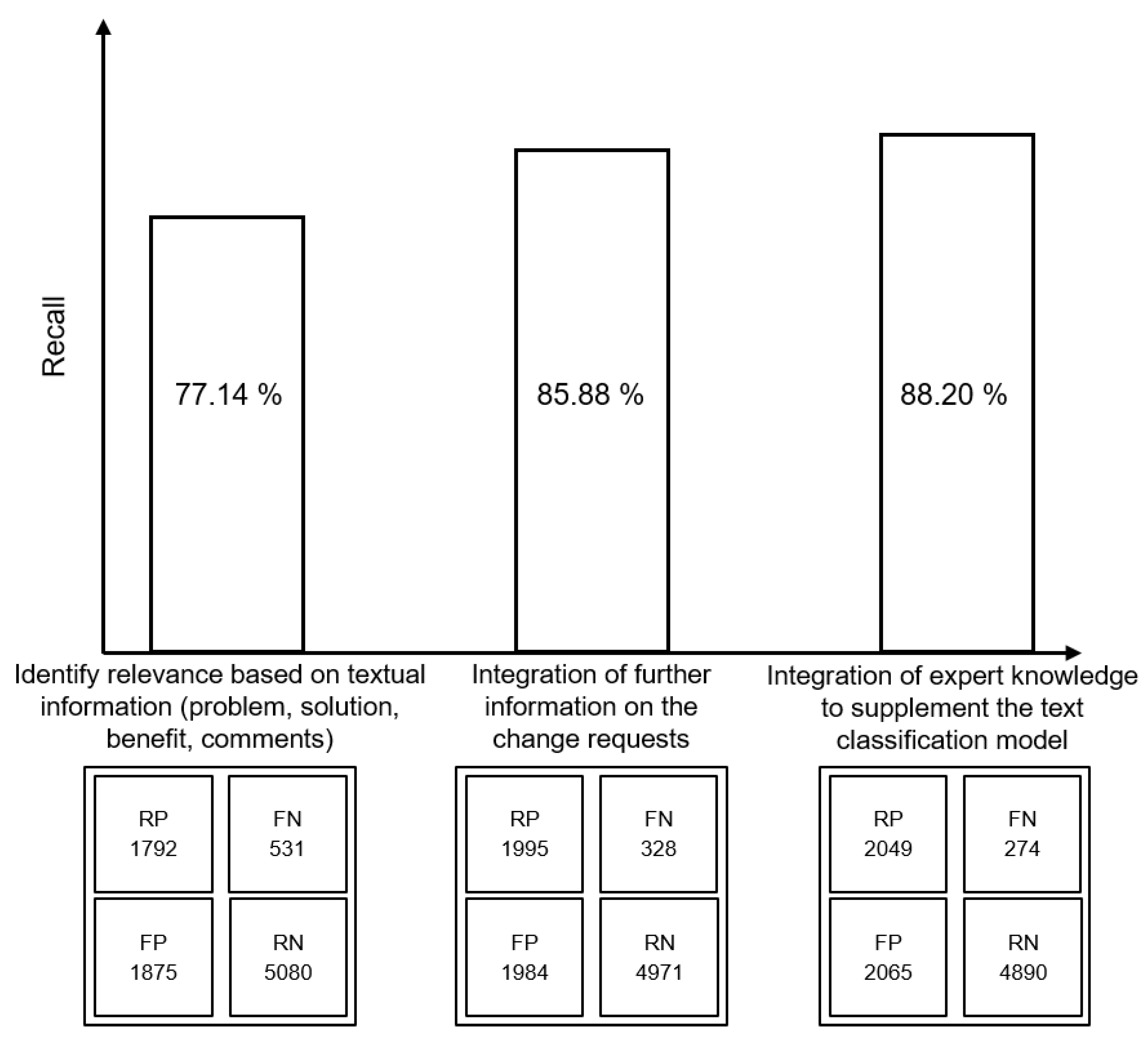
6. Industrial Application and Evaluation
6.1. Use Case ”Assembly”
6.2. Data Preparation
6.3. Model Training
6.4. Expert Knowledge
7. Discussion
7.1. Implications for Industrial Practice
7.2. Fulfillment of Requirements
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A



References
- Mack, O.; Khare, A.; Kramer, A. Managing in a VUCA World, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Wonsak, I.; Bauer, H.; Sippl, F.; Reinhart, G. A scenario-based approach for translating strategic perspectives into input variables for production planning and control. Procedia CIRP 2021, 104, 429–434. [Google Scholar] [CrossRef]
- Wiendahl, H.P.; ElMaraghy, H.A.; Nyhuis, P.; Zäh, M.F.; Wiendahl, H.H.; Duffie, N.; Brieke, M. Changeable Manufacturing-Classification, Design and Operation. CIRP Ann. 2007, 56, 783–809. [Google Scholar] [CrossRef]
- Koch, J. Manufacturing Change Management—A Process-Based Approach for the Management of Manufacturing Changes. Ph.D. Thesis, Technische Universität München, Munchen, Germany, 2017. [Google Scholar]
- Lindemann, U.; Reichwald, R. Integriertes Änderungsmanagement; Springer: Berlin, Germany, 1998. [Google Scholar]
- Jarratt, T.A.W.; Eckert, C.M.; Caldwell, N.H.M.; Clarkson, P.J. Engineering change: An overview and perspective on the literature. Res. Eng. Des. 2011, 22, 103–124. [Google Scholar] [CrossRef]
- Basse, F. Gestaltung Eines Adaptiven Änderungssystems für Einen Beherrschten Serienhochlauf: Design of an Adaptive Engineering Change System for a Stable Series Ramp-Up, 1st ed.; Produktionssystematik; Apprimus Verlag: Aachen, Germany, 2019; Volume 2019, Band 22. [Google Scholar]
- Malak, R.C. Methode zur Softwarebasierten Planung Technischer Änderungen in der Produktion: Zugl.: Kaiserslautern, Techn. Univ. Produktionstechnische Berichte aus dem FBK. Ph.D. Thesis, Lehrstuhl für Fertigungstechnik und Betriebsorganisation Techn. Univ., Kaiserslautern, Germany, 2013. [Google Scholar]
- Wickel, M.C. Änderungen Besser Managen—Eine Datenbasierte Methodik zur Analyse Technischer Änderungen. Ph.D. Thesis, Technische Universität München, Munchen, Germany, 2017. [Google Scholar]
- Sharafi, A. Knowledge Discovery in Databases; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2013. [Google Scholar] [CrossRef]
- Do, N. Identifying experts for engineering changes using product data analytics. Comput. Ind. 2018, 95, 81–92. [Google Scholar] [CrossRef]
- Sippl, F.; Schellhaas, L.; Bauer, H. Umfrage zum Änderungsmanagement in der Produktion Status quo, industrielle Anwendung der Änderungsauswirkungsanalyse und Stand der Digitalisierung. Z. für Wirtsch. Fabr. 2021, 116, 208–212. [Google Scholar] [CrossRef]
- Koch, J.; Hofer, A. Änderungsmanagement in der Produktion: Herausforderungen und Anwendungen in der industriellen Praxis. WT Werkstatttechnik 2016, 7/8, 520–526. [Google Scholar] [CrossRef]
- Wickel, M.C.; Lindemann, U. A retrospective analysis of engineering change orders to identify potential for future improvements. In Proceedings of the DS 81: Proceedings of NordDesign 2014, Espoo, Finland, 27–29 August 2014. [Google Scholar]
- Freeman, R.E. Strategic Management: A stakeholder Approach, 1984th ed.; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Beam, C.; Specking, E.; Parnell, G.S.; Pohl, E.; Goerger, M.N.; Buchanan, J.P.; Gallarno, G.E. Best Practices for Stakeholder Engagement for Government R&D Organizations. Eng. Manag. J. 2022, 1–20. [Google Scholar] [CrossRef]
- Hayes, J. The Theory and Practice of Change Management, 4th ed.; Palgrave Macmillan: Basingstoke, UK, 2014. [Google Scholar]
- Jarratt, T.; Eckert, C.; Clarkson, P. Engineering change. In Design Process Improvement; Clarkson, J., Eckert, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 262–285. [Google Scholar]
- Reinhart, G.; Pohl, J.; Schindler, S.; Rimpau, C. Cycle-oriented production structure monitoring. In Proceedings of the 3rd International Conference on Changeable, Agile, Reconfigurable and Virtual Production (CARV 2009), München, Germany, 5–7 October 2009; Zaeh, M.F., ElMaraghy, H.A., Eds.; Utz: München, Germany, 2009; pp. 693–701. [Google Scholar]
- Malak, R.C.; Yang, X.; Aurich, J.C. Analysing and Planning of Engineering Changes in Manufacturing Systems. In Proceedings of the 44th CIRP Conference on Manufacturing Systems, Madison, WI, USA, 31 May–3 June 2011. [Google Scholar]
- Rößing, M. Technische Änderungen in der Produktion—Vorgehensweise zur systematischen Initialisierung, Durchführung und Nachbereitung: Zugl.: Kaiserslautern, Techn. Univ. Ph.D. Thesis, Produktionstechnische Berichte aus dem FBK, Techn. Univ., Kaiserslautern, Germany, 2007. [Google Scholar]
- Stanev, S.; Krappe, H.; Ola, H.A.; Georgoulias, K.; Papakostas, N.; Chryssolouris, G.; Ovtcharova, J. Efficient change management for the flexible production of the future. J. Manuf. Technol. Manag. 2008, 19, 712–726. [Google Scholar] [CrossRef]
- ProSTEP iViP, e.V. Manufacturing Change Management (Recommendation): Management of Changes during Production; ProSTEP iViP e.V.: Darmstadt, Germany, 2015. [Google Scholar]
- Chowdhary, K.R. Natural Language Processing for Word Sense Disambiguation and Information Extraction. Ph.D. Thesis, Jai Narain Vyas University, Jodhpur, India, 2004. [Google Scholar]
- Chowdhary, K.R. Natural Language Processing. In Fundamentals of Artificial Intelligence; Chowdhary, K.R., Ed.; Springer: New Delhi, India, 2020; pp. 603–649. [Google Scholar] [CrossRef]
- Vijayarani, S.; Ilamathi, J.; Nithya. Preprocessing Techniques for Text Mining - An Overview. Int. J. Comput. Sci. Commun. Networks 2015, 5, 7–16. [Google Scholar]
- Shah, K.; Patel, H.; Sanghvi, D.; Shah, M. A Comparative Analysis of Logistic Regression, Random Forest and KNN Models for the Text Classification. Augment. Hum. Res. 2020, 5, 1–16. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing. IEEE Comput. Intell. Mag. 2017, 13, 55–75. [Google Scholar] [CrossRef]
- IBM Cloud Education. Natural Language Processing (NLP). Fundam. Artif. Intell. 2020, 603–649. Available online: https://www.ibm.com/cloud/learn/natural-language-processing (accessed on 12 June 2022).
- Chowdhary, K.R. (Ed.) Fundamentals of Artificial Intelligence; Springer: New Delhi, India, 2020. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Nguyen, V. Hierarchical-Attention-Networks-Pytorch. 2019. Available online: https://github.com/uvipen/Hierarchical-attention-networks-pytorch (accessed on 12 June 2022).
- Li, Y.; Yang, T. Word Embedding for Understanding Natural Language: A Survey. In Guide to Big Data Applications; Srinivasan, S., Ed.; Springer International Publishing: Cham, Switzerland, 2018; Volume 26, pp. 83–104. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Webster, J.; Watson, R. Analyzing the Past to Prepare for the Future: Writing a Literature Review. Manag. Inf. Syst. Q. 2002, 26, 13–23. [Google Scholar]
- VDA: ECM Recommendation Part 0 (ECM), VDA 4965—Part 0. Ed. by VDA Verband der Automobilindustrie; SASIG; ProSTEP iViP e.V. 2010-01. Available online: https://www.prostep.org/fileadmin/downloads/VDA_ECM_Recommendation_-_Part_0__ECM__V2.0.3.pdf (accessed on 12 June 2022).
- Sippl, F.; Del Rio, B.; Reinhart, G. Approach for stakeholder identification in Manufacturing Change Management. Procedia CIRP 2022, 106, 191–196. [Google Scholar] [CrossRef]
- Schuh, G.; Guetzlaff, A.; Sauermann, F.; Krug, M. Data-based improvement of engineering change impact analyses in manufacturing. Procedia CIRP 2021, 99, 580–585. [Google Scholar] [CrossRef]
- Giffin, M.; de Weck, O.; Bounova, G.; Keller, R.; Eckert, C.; Clarkson, P.J. Change Propagation Analysis in Complex Technical Systems. J. Mech. Des. 2009, 131, 1–14. [Google Scholar] [CrossRef]
- Pasqual, M.C.; de Weck, O.L. Multilayer network model for analysis and management of change propagation. Res. Eng. Des. 2012, 23, 305–328. [Google Scholar] [CrossRef]
- Kattner, N.; Mehlstaeubl, J.; Becerril, L.; Lindemann, U. Data Analysis in Engineering Change Management Improving Collaboration by Assessing Organizational Dependencies Based on Past Engineering Change Information. In Proceedings of the 2018 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Bangkok, Thailand, 16–19 December 2018; pp. 617–621. [Google Scholar]
- Kocar, V.; Akgunduz, A. ADVICE: A virtual environment for Engineering Change Management. Comput. Ind. 2010, 61, 15–28. [Google Scholar] [CrossRef]
- Malak, R.C.; Aurich, J.C. Software Tool for Planning and Analyzing Engineering Changes in Manufacturing Systems. Procedia CIRP 2013, 12, 348–353. [Google Scholar] [CrossRef]
- Pan, Y.; Stark, R. An Ensemble Learning based Hierarchical Multi-label Classification Approach to Identify Impacts of Engineering Changes. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 1260–1267. [Google Scholar] [CrossRef]
- Do, N. Integration of engineering change objects in product data management databases to support engineering change analysis. Comput. Ind. 2015, 73, 69–81. [Google Scholar] [CrossRef]
- Habhouba, D.; Cherkaoui, S.; Desrochers, A. Decision-making assistance in engineering-change management process. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2011, 41, 344–349. [Google Scholar] [CrossRef]
- Grieco, A.; Pacella, M.; Blaco, M. On the Application of Text Clustering in Engineering Change Process. Procedia CIRP 2017, 62, 187–192. [Google Scholar] [CrossRef]
- Arnarsson, I.Ö.; Frost, O.; Gustavsson, E.; Stenholm, D.; Jirstrand, M.; Malmqvist, J. Supporting Knowledge Re-Use with Effective Searches of Related Engineering Documents-A Comparison of Search Engine and Natural Language Processing-Based Algorithms. Proc. Des. Soc. Int. Conf. Eng. Des. 2019, 1, 2597–2606. [Google Scholar] [CrossRef]
- Hamraz, B.; Caldwell, N.H.; Wynn, D.C.; Clarkson, P.J. Requirements-based development of an improved engineering change management method. J. Eng. Des. 2013, 24, 765–793. [Google Scholar] [CrossRef]
- Heron, M.J.; Hanson, V.L.; Ricketts, I. Open Source and Accessibility: Advantages and Limitations. J. Interact. Sci. 2013, 1, 2. [Google Scholar] [CrossRef]
- Shearer, C. The CRISP-DM Model: The New Blueprint for Data Mining. J. Data Warehous. 2000, 5, 13–22. [Google Scholar]
- Řehůřek, R. Word2Vec Model. 2021. Available online: https://radimrehurek.com/gensim/auto_examples/tutorials/run_word2vec.html (accessed on 12 June 2022).
- Verleysen, M.; François, D. The Curse of Dimensionality in Data Mining and Time Series Prediction. In Computational Intelligence and Bioinspired Systems, Proceedings of the International Work-Conference on Artificial Neural Networks, Barcelona, Spain, 8–10 June 2005; Cabestany, J., Prieto, A., Sandoval, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 758–770. [Google Scholar]
- Hall, M.A. Correlation Based Feature Selection for Machine Learning. Ph.D. Thesis, University of Waikato, Waikato, New Zeeland, 1999. [Google Scholar]
- Bortz, J.; Schuster, C. Statistik für Human- und Sozialwissenschaftler, 7th ed.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Uysal, A.K.; Gunal, S. The impact of preprocessing on text classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar] [CrossRef]
- Camacho-Collados, J.; Pilehvar, M.T. On the Role of Text Preprocessing in Neural Network Architectures: An Evaluation Study on Text Categorization and Sentiment Analysis. arXiv 2017, arXiv:1707.01780. [Google Scholar]
- Kao, A.; Poteet, S.R. Natural Language Processing and Text Mining; Springer: London, UK, 2007. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| R1 Data Analysis Requirements | |
|---|---|
| R1.1 | Open source software |
| R1.2 | Semantic text contexts |
| R1.3 | Quantitative evaluation of machine data analysis |
| R1.4 | Prerequisite for automated analysis of new change requests |
| R1.5 | Performance of classifier |
| R2 Method-Oriented Requirements | |
| R2.1 | Availability of information for model building |
| R2.2 | Procedure for text preprocessing |
| R2.3 | Expert knowledge |
| R2.4 | Objective data selection |
| R2.5 | Industrial applicability |
| R2.6 | Adaptability |
| Data | Description | Exemplary Data Attributes |
|---|---|---|
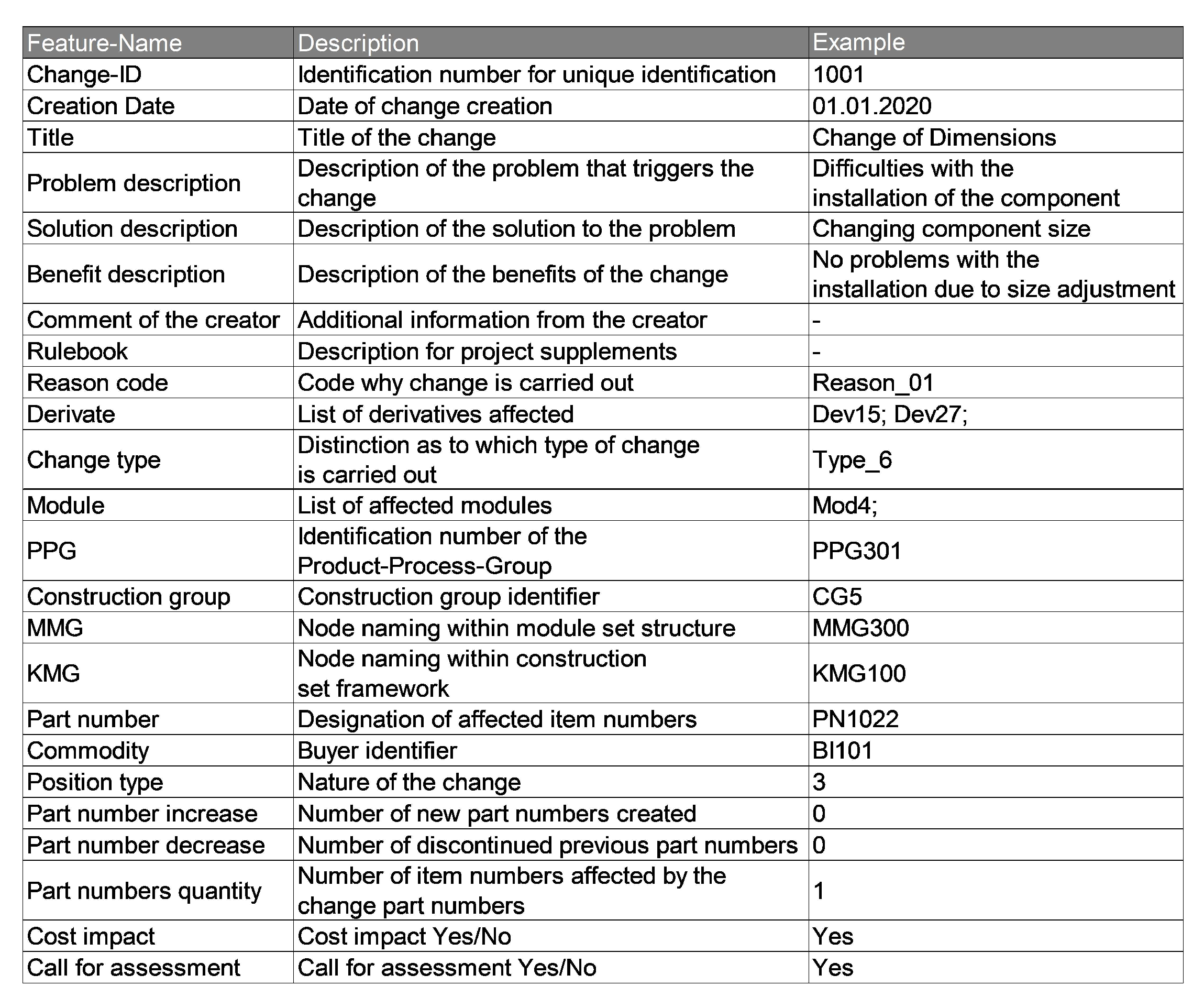
| Mandatory | Textual change data | Title, problem description, solution description, benefit description, comments, … |
| Optional | Additional data attributes | Reasoncode, change type, change trigger, module group, construction group, variants increase, … |
| R1 Data Analysis Requirements | Fulfillment | |
|---|---|---|
| R1.1 | Open source software | fulfilled |
| R1.2 | Semantic text contexts | fulfilled |
| R1.3 | Quantitative evaluation of machine data analysis | partly fulfilled |
| R1.4 | Prerequisite for automated analysis of new change requests | fulfilled |
| R1.5 | Performance of classifier | fulfilled |
| R2 Method-Oriented Requirements | ||
| R2.1 | Availability of information for model building | fulfilled |
| R2.2 | Procedure for text preprocessing | fulfilled |
| R2.3 | Expert knowledge | fulfilled |
| R2.4 | Objective data selection | fulfilled |
| R2.5 | Industrial applicability | fulfilled |
| R2.6 | Adaptability | fulfilled |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sippl, F.; Magg, R.; Gil, C.P.; Düring, S.; Reinhart, G. Data-Based Stakeholder Identification in Technical Change Management. Appl. Sci. 2022, 12, 8205. https://doi.org/10.3390/app12168205
Sippl F, Magg R, Gil CP, Düring S, Reinhart G. Data-Based Stakeholder Identification in Technical Change Management. Applied Sciences. 2022; 12(16):8205. https://doi.org/10.3390/app12168205
Chicago/Turabian StyleSippl, Fabian, Renè Magg, Carla Paulina Gil, Steffen Düring, and Gunther Reinhart. 2022. "Data-Based Stakeholder Identification in Technical Change Management" Applied Sciences 12, no. 16: 8205. https://doi.org/10.3390/app12168205