
Target Speaker Extraction by Fusing Voiceprint Features


Abstract
:1. Introduction
- Two types of voiceprint features, i.e., MFCCs and d-vector, are explored and their effectiveness in performance enhancement when integrated into the speaker-independent speech separation models is investigated. Moreover, the d-vector features originally used by VoiceFilter are substituted for MFCC features for a performance comparison.
- Three different feature fusion methods are proposed to fuse the voiceprint features with the magnitude spectrograms: (1) direct concatenation (Tse-FV(DC)); (2) expanded convolution and concatenation (Tse-FV(ECC)); and (3) concatenation and expanded convolution (Tse-FV(CEC)).
- A feature integration method which efficiently integrates the voiceprint features into two speaker-independent speech separation models, i.e., DPCL and PITNet, is proposed.
2. Methodology
2.1. Overview of Tse-FV
2.1.1. Feature Extraction
2.1.2. Feature Fusion
2.1.3. Target Speech Extraction
3. Experiments and Results
3.1. Experiment Settings
3.1.1. Configurations of Speech Separation Models
3.1.2. Evaluation Method
3.2. Results
3.2.1. Comparison of Model Performance
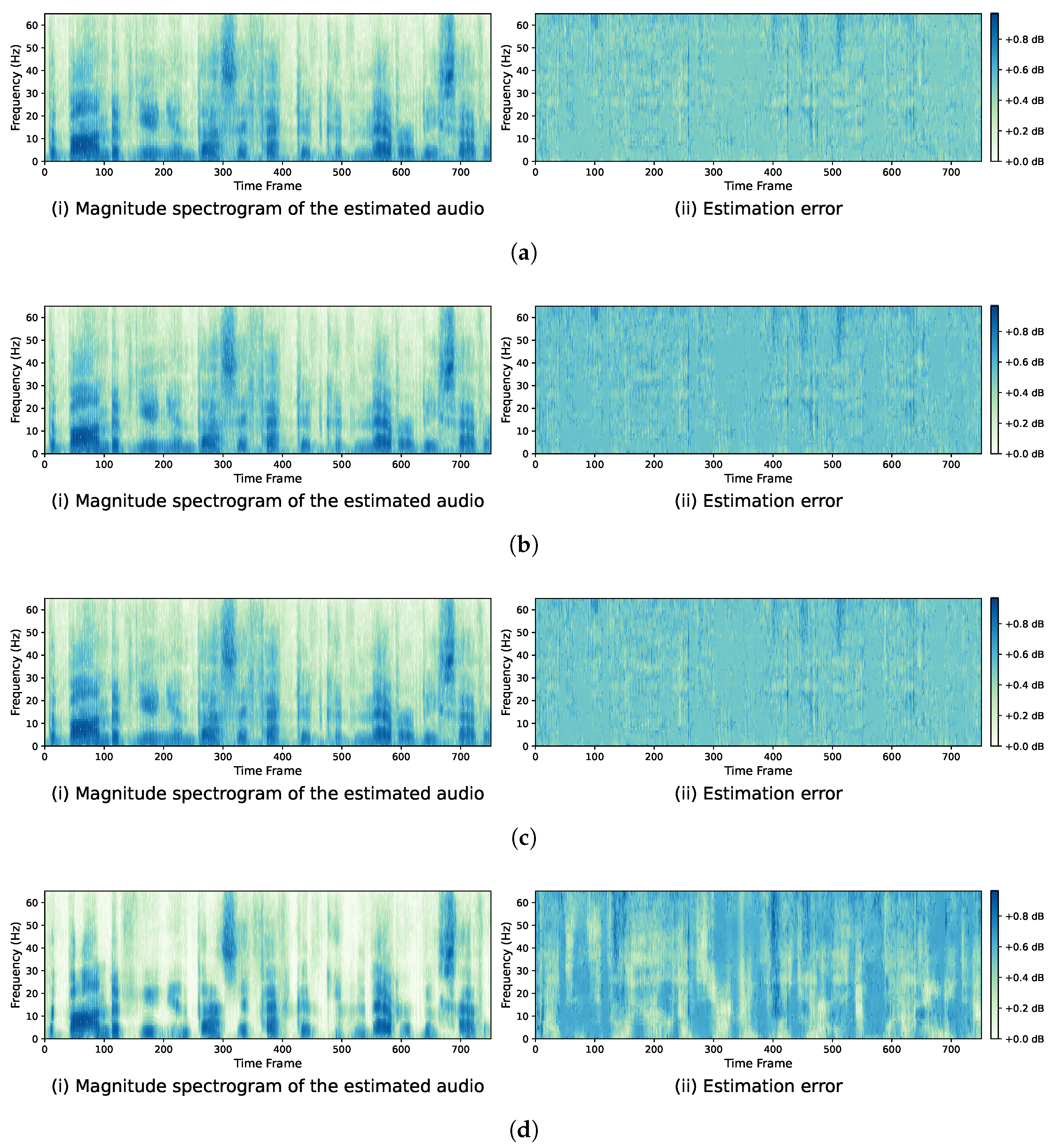
3.2.2. Comparison of Estimated Spectrogram
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, J.; Deng, L.; Haeb-Umbach, R.; Gong, Y. Robust Automatic Speech Recognition: A Bridge to Practical Applications; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Watanabe, S.; Delcroix, M.; Metze, F.; Hershey, J. New Era for Robust Speech Recognition; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 978–983. [Google Scholar]
- Xiao, X.; Xu, C.; Zhang, Z.; Zhao, S.; Sun, S.; Watanabe, S.; Wang, L.; Xie, L.; Jones, D.; Chng, E. A Study of Learning Based Beamforming Methods for Speech Recognition. In CHiME 2016 Workshop; 2016; pp. 26–31. Available online: https://www.semanticscholar.org/paper/A-Study-of-Learning-Based-Beamforming-Methods-for-Xiao-Xu/242cf2e991f0eed4b1309a2a9dff548e8b95900f (accessed on 10 August 2022).
- Rao, W.; Xu, C.; Chng, E.; Li, H. Target speaker extraction for overlapped multi-talker speaker verification. arXiv 2019, arXiv:1902.02546. [Google Scholar]
- Sell, G.; Snyder, D.; McCree, A.; Garcia-Romero, D.; Villalba, J.; Maciejewski, M.; Manohar, V.; Dehak, N.; Povey, D.; Watanabe, S. Diarization is Hard: Some Experiences and Lessons Learned for the JHU Team in the Inaugural DIHARD Challenge. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 2808–2812. [Google Scholar]
- Hershey, J.; Chen, Z.; Roux, J.; Watanabe, S. Deep clustering: Discriminative embeddings for segmentation and separation. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 31–35. [Google Scholar]
- Isik, Y.; Roux, J.; Chen, Z.; Watanabe, S.; Hershey, J. Single-channel multi-speaker separation using deep clustering. arXiv 2016, arXiv:1607.02173. [Google Scholar]
- Chen, Z.; Luo, Y.; Mesgarani, N. Deep attractor network for single-microphone speaker separation. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 246–250. [Google Scholar]
- Yu, D.; Kolbæk, M.; Tan, Z.; Jensen, J. Permutation invariant training of deep models for speaker-independent multi-talker speech separation. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 241–245. [Google Scholar]
- Luo, Y.; Mesgarani, N. Tasnet: Time-domain audio separation network for real-time, single-channel speech separation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 696–700. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-tasnet: Surpassing ideal time-frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Delcroix, M.; Zmolikova, K.; Kinoshita, K.; Ogawa, A.; Nakatani, T. Single channel target speaker extraction and recognition with speaker beam. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5554–5558. [Google Scholar]
- Wang, Q.; Muckenhirn, H.; Wilson, K.; Sridhar, P.; Wu, Z.; Hershey, J.; Saurous, R.; Weiss, R.; Jia, Y.; Moreno, I. Voicefilter: Targeted voice separation by speaker-conditioned spectrogram masking. arXiv 2018, arXiv:1810.04826. [Google Scholar]
- Wang, Q.; Moreno, I.; Saglam, M.; Wilson, K.; Chiao, A.; Liu, R.; He, Y.; Li, W.; Pelecanos, J.; Nika, M.; et al. Voicefilter-lite: Streaming targeted voice separation for on-device speech recognition. arXiv 2020, arXiv:2009.04323. [Google Scholar]
- Li, W.; Zhang, P.; Yan, Y. TEnet: Target speaker extraction network with accumulated speaker embedding for automatic speech recognition. Electron. Lett. 2019, 55, 816–819. [Google Scholar] [CrossRef]
- Ittichaichareon, C.; Suksri, S.; Yingthawornsuk, T. Speech recognition using MFCC. In Proceedings of the International Conference on Computer Graphics, Simulation and Modeling, Pattaya, Thailand, 28–29 July 2012; pp. 135–138. [Google Scholar]
- Tiwari, V. MFCC and its applications in speaker recognition. Int. J. Emerg. Technol. 2010, 1, 12–22. [Google Scholar]
- Shetty, S.; Hegde, S. Automatic Classification of Carnatic Music Instruments Using MFCC and LPC. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelberg, Germany, 2020; pp. 463–474. [Google Scholar]
- Xiao, B.; Xu, Y.; Bi, X.; Zhang, J.; Ma, X. Heart sounds classification using a novel 1-D convolutional neural network with extremely low parameter consumption. Neurocomputing 2020, 392, 153–159. [Google Scholar] [CrossRef]
- Dehak, N.; Kenny, P.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 788–798. [Google Scholar] [CrossRef]
- Kanagasundaram, A.; Vogt, R.; Dean, D.; Sridharan, S.; Mason, M. I-vector based speaker recognition on short utterances. In Proceedings of the INTERSPEECH, Florence, Italy, 27–31 August 2011; pp. 2341–2344. [Google Scholar]
- Kanagasundaram, A.; Dean, D.; Sridharan, S.; Gonzalez-Dominguez, J.; Gonzalez-Rodriguez, J.; Ramos, D. Improving short utterance i-vector speaker verification using utterance variance modelling and compensation techniques. Speech Commun. 2014, 59, 69–82. [Google Scholar] [CrossRef]
- Ioffe, S. Probabilistic linear discriminant analysis. In Proceedings of the European Conference on Computer Vision 2006, Graz, Austria, 7–13 May 2006; pp. 531–542. [Google Scholar]
- Variani, E.; Xin, L.; McDermott, E.; Moreno, I.; Gonzalez-Dominguez, J. Deep neural networks for small footprint text-dependent speaker verification. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4052–4056. [Google Scholar]
- Li, W.; Quan, W.; Papir, A.; Moreno, I. Generalized End-to-End Loss for Speaker Verification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4879–4883. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K. Phoneme recognition using time-delay neural networks. IEEE Trans. Audio Speech Lang. Process. 1989, 37, 328–339. [Google Scholar] [CrossRef]
- Fang, F.; Wang, X.; Yamagishi, J.; Echizen, I.; Todisco, M.; Evans, N.; Bonastre, J. Speaker anonymization using x-vector and neural waveform models. arXiv 2019, arXiv:1905.13561. [Google Scholar]
- Garcia-Romero, D.; Sell, G.; McCree, A. MagNetO: X-vector Magnitude Estimation Network plus Offset for Improved Speaker Recognition. In Proceedings of the Speaker and Language Recognition Workshop (Odyssey 2020), Tokyo, Japan, 1–5 November 2020; pp. 1–8. [Google Scholar]
- Snyder, D.; Ghahremani, P.; Povey, D.; Garcia-Romero, D.; Carmiel, Y.; Khudanpur, S. Deep neural network-based speaker embeddings for end-to-end speaker verification. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 165–170. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Povey, D.; Khudanpur, S. Deep neural network embeddings for text-independent speaker verification. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 999–1003. [Google Scholar]
- Li, C.; Ma, X.; Jiang, B.; Li, X.; Zhang, X.; Liu, X.; Cao, Y.; Kannan, A.; Zhu, Z. Deep speaker: An end-to-end neural speaker embedding system. arXiv 2017, arXiv:1705.02304. [Google Scholar]
- Nagrani, A.; Chung, J.; Zisserman, A. VoxCeleb: A Large-Scale Speaker Identification Dataset. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 2616–2620. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Luo, Y.; Chen, Z.; Mesgarani, N. Speaker-independent speech separation with deep attractor network. IEEE Trans. Audio Speech Lang. Process. 2018, 26, 787–796. [Google Scholar] [CrossRef]
- Vincent, E.; Gribonval, R.; Févotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef]
- Raffel, C.; Humphrey, B.M.E.; Salamon, J.; Nieto, O.; Liang, D.; Ellis, D.; Raffel, C. mir_eval: A transparent implementation of common MIR metrics. In Proceedings of the 15th International Society for Music Information Retrieval Conference, ISMIR 2014, Taipei, Taiwan, 27–31 October 2014. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DPCL | PITNet | VoiceFilter | ||
|---|---|---|---|---|
| LSTM | num_layers | 4 | 4 | 3 |
| hidden_size | 300 | 896 | 600 | |
| bidirectional | True | True | True | |
| Optimizer | activation | Tanh | Relu | Relu, sigmoid |
| type | Adam | Adam | Adam | |
| learning_rate | 1.0 × 10−4 | 1.0 × 10−3 | 1.0 × 10−4 | |
| weight_decay | 0 | 0 | 0 |
| Model | None | MFCCs | d-Vector | ||
|---|---|---|---|---|---|
| DC | ECC | CEC | ECC | ||
| DPCL | 1.57 | 3.37 | 3.67 | 4.23 | 1.63 |
| PITNet | 1.20 | 3.67 | 4.04 | 3.87 | 1.77 |
| VoiceFilter | - | 3.17 | 3.83 | 4.01 | 1.53 |
| Model | None | MFCCs | d-Vector | ||
|---|---|---|---|---|---|
| DC | ECC | CEC | ECC | ||
| DPCL | 8.279 | 10.530 | 10.660 | 12.430 | 9.483 |
| PITNet | 3.371 | 10.540 | 11.970 | 11.940 | 9.325 |
| VoiceFilter | - | 10.420 | 11.470 | 11.160 | 8.159 |
| Model | None | MFCCs | d-Vector | ||
|---|---|---|---|---|---|
| DC | ECC | CEC | ECC | ||
| DPCL | 121.68 | 122.03 | 153.09 | 156.70 | 159.77 |
| PITNet | 530.89 | 531.96 | 612.29 | 619.75 | 632.22 |
| VoiceFilter | - | 346.99 | 402.84 | 407.85 | 414.48 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, S.; Shen, Y.; Wang, D. Target Speaker Extraction by Fusing Voiceprint Features. Appl. Sci. 2022, 12, 8152. https://doi.org/10.3390/app12168152
Cheng S, Shen Y, Wang D. Target Speaker Extraction by Fusing Voiceprint Features. Applied Sciences. 2022; 12(16):8152. https://doi.org/10.3390/app12168152
Chicago/Turabian StyleCheng, Shidan, Ying Shen, and Dongqing Wang. 2022. "Target Speaker Extraction by Fusing Voiceprint Features" Applied Sciences 12, no. 16: 8152. https://doi.org/10.3390/app12168152