
The Protection of Data Sharing for Privacy in Financial Vision


Abstract
:1. Introduction
2. Materials
2.1. Candlestick
- Real Body: Real Body represents the price difference between opening and closing.
- Shadow: There are two types of shadow. The upper shadow is the price difference between the highest price and the real body. The lower shadow is the price difference between the lowest price and the real body.
- Color: Color reveals the direction of market movements. The white or green body indicates a price increase; the black or red body shows a price decrease. However, the red body indicates a price increase, and the green body shows a price decrease in Taiwan.
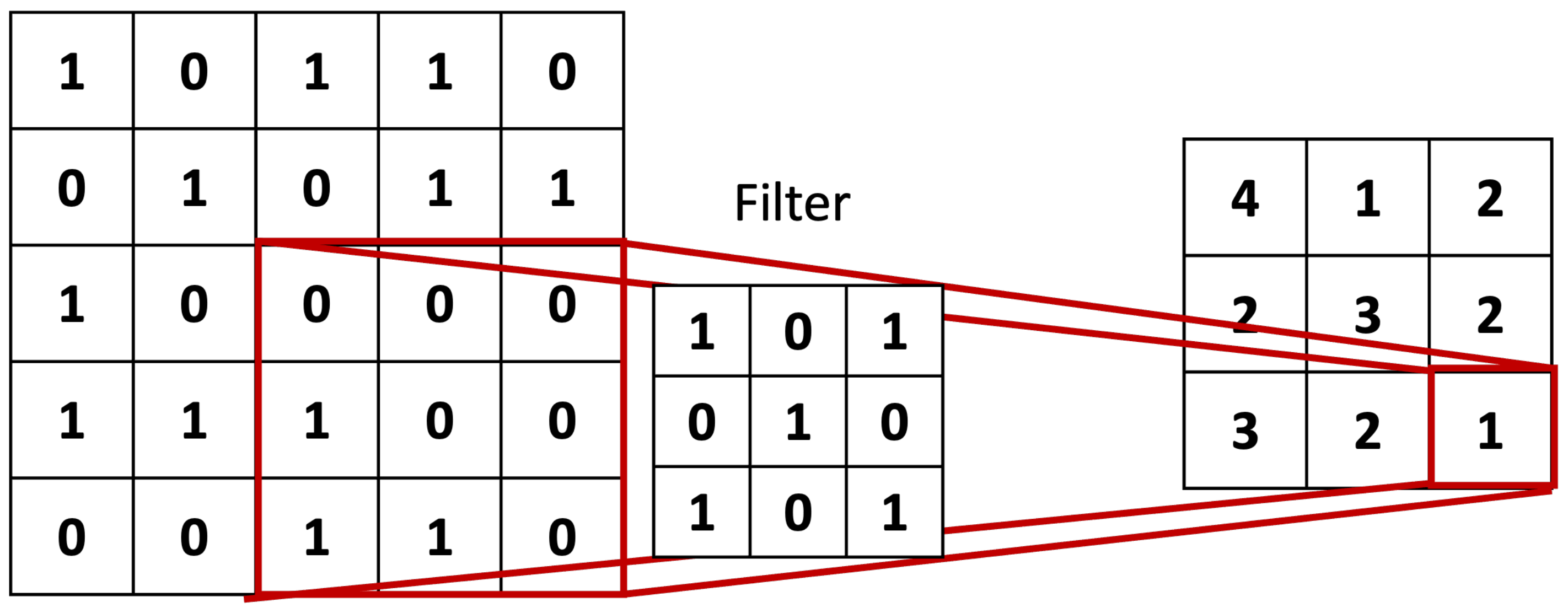
2.2. GAF-CNN Model of Financial Vision
2.3. Differential Privacy
2.4. Model Attack
3. Methods
3.1. Experimental Design
3.2. Build a GAF-CNN Baseline Model
3.3. Build DP Models with Different Noise
- : privacy loss;
- : probability of violating DP mechanism.
| Algorithm 1 Differentially Private Stochastic Gradient Descent (DP-SGD). |
| Load training data |
| Set loss function . |
| Set learning rate , noise scale , group size L, and gradient norm bound C. |
| Initialize randomly. |
| fort in T do |
| Random sample a via sampling probability . |
| Step 1. Compute and clip gradient |
| for i in do |
| compute |
| end for |
| Step 2. Add random noise |
| Step 3. Gradient descent |
| end for |
| Step 4. Compute privacy cost |
| Output and compute the privacy cost with a privacy accounting method. |
3.4. Compare Model Accuracy between Baseline Model and DP Models
3.5. Attack Baseline Model and DP Models
- Privacy loss ():The privacy loss cannot be directly specified when setting parameters, and it has to be calculated by fixing the delta and noise size. Each gradient update will bring some privacy loss during the training process; thus, we must add up these privacy losses. The of DP-SGD makes calculations through the moments’ account using Equation (7), which is shown below.
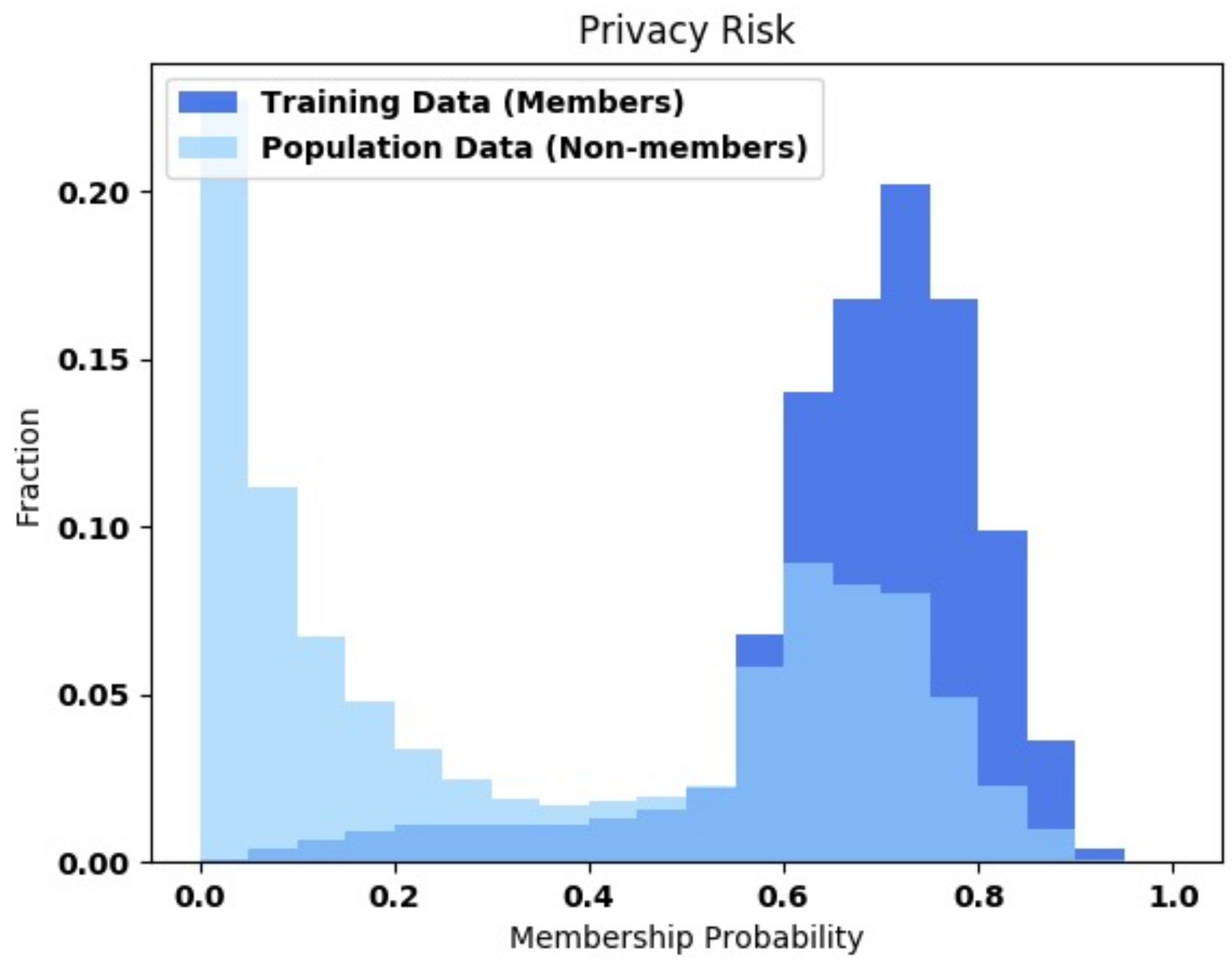
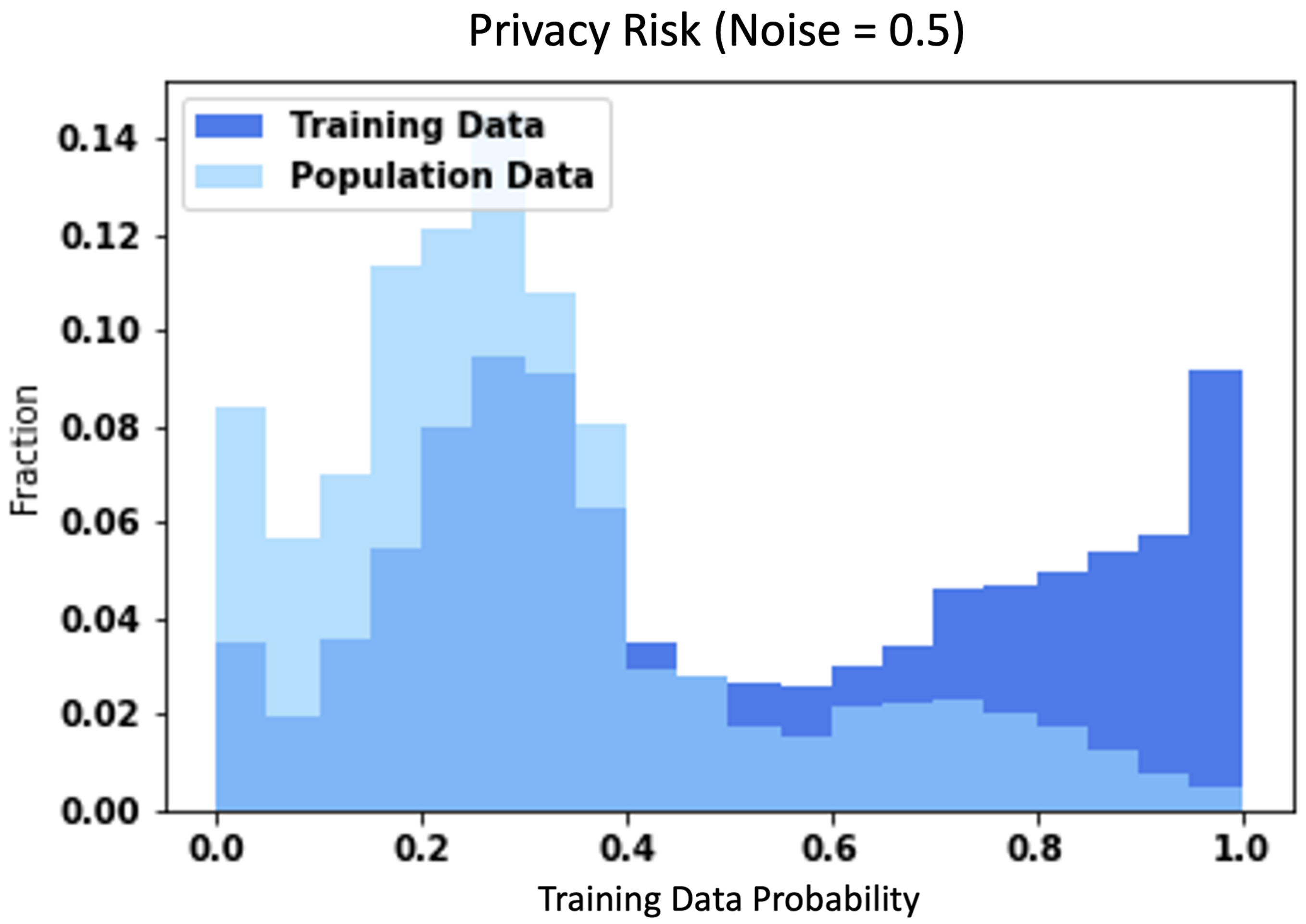
- White-box attack result:Attack the baseline and DP-SGD models using the white-box attack model proposed by Jiayuan Ye et al. [34]. The code source is available from https://github.com/privacytrustlab/ml_privacy_meter, accessed on 1 June 2022. The attack model will show the probability of whether the input data are in training data or not. We will plot the probabilities by referring to Figure 11 from the ml_privacy_meter GitHub. It shows the training data probabilities and non-training data probabilities. The higher training data probabilities show that the model has predicted a higher likelihood and that the data are part of the training data. It can demonstrate the effectiveness of the DP-SGD model in protecting the training data from the attack result.
4. Results
4.1. Data Illustration
- Evening Star (Figure 12) consists of three candlesticks, the first is a long red candlestick, the second is a very short candlestick, and the third is a long green candlestick. This pattern is bearish.
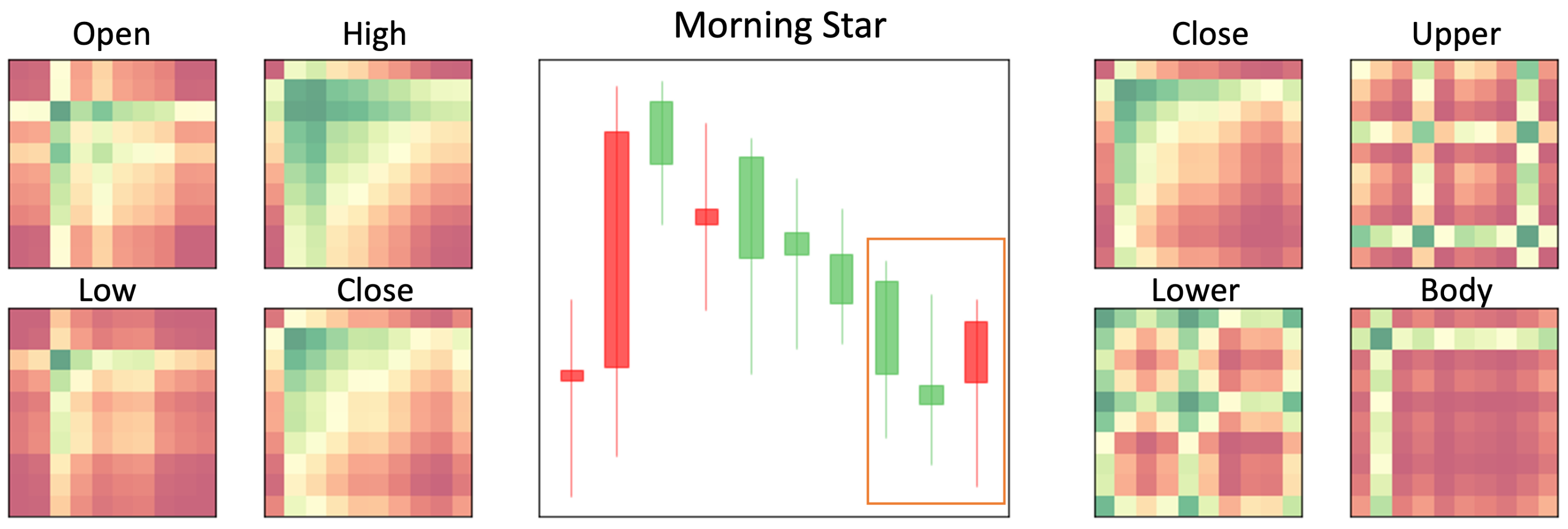
- Morning Star (Figure 13) is composed of three candlesticks. Opposite of Evening Star, the Morning Star represents a bullish pattern. The first candlestick is a long green one. The second is very short, and the third is a long red. The longer the third one is, the greater the upward trend.
- Bearish Engulfing (Figure 14) consists of two candlesticks, usually after an uptrend. The first bar is red, the second bar is green, and the first body will be smaller than the second. Bearish Engulfing represents a bearish pattern.
- Bullish Engulfing (Figure 15) is the opposite of Bearish Engulfing, indicating a bullish pattern. It consists of two candlesticks; the first green candlestick body is smaller than the second red candlestick.
- Shooting Star (Figure 16) consists of two candlesticks, which usually appear behind the uptrend. The first candlestick is red, and the color of the second one is not essential, as long as it is short enough and has a long upper shadow. This pattern indicates a bearish pattern.
- Inverted Hammer (Figure 17) is the opposite of a shooting star, which represents a bullish pattern. It usually appears behind the downtrend. The first candlestick is green, and the color of the second candlestick is not essential. However, the second candlestick should be short enough and the upper shadow should be long enough.
- Bearish Harami (Figure 18) is composed of two candlesticks, with the first candlestick being a longer one and the second candlestick being a shorter green one. The body of the second candlestick must be more concise than the first candlestick. This pattern indicates a signal of price reversal from an uptrend to a downtrend.
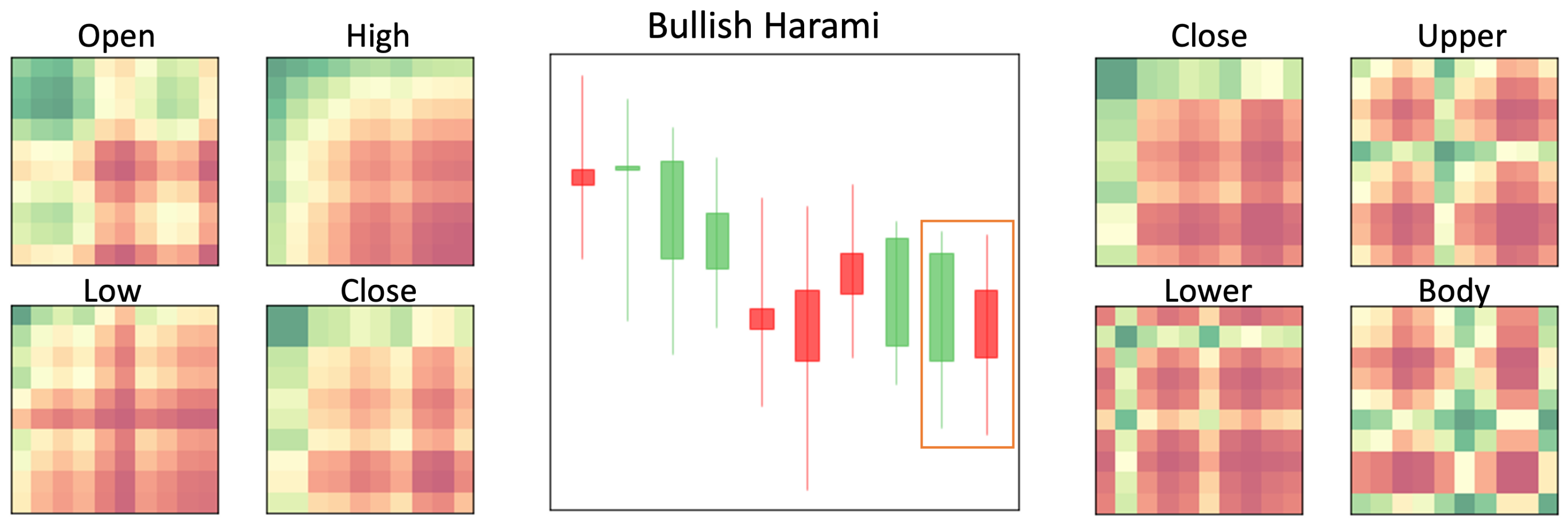
- Bullish Harami (Figure 19) is the opposite of Bearish Harami. It is a sign of price reversal from a downtrend to an uptrend. Bullish Harami consists of a first longer green candlestick and a second shorter red candlestick. The second one is engulfed by the first one.
4.2. DP Result
4.3. Attack Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning for predicting clinical outcomes in patients with COVID-19. Nat. Med. 2021, 27, 1735–1743. [Google Scholar]
- Cao, L.; Yang, Q.; Yu, P.S. Data science and AI in FinTech: An overview. Int. J. Data Sci. Anal. 2021, 12, 81–99. [Google Scholar] [CrossRef]
- Long, G.; Tan, Y.; Jiang, J.; Zhang, C. Federated learning for open banking. In Federated Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 240–254. [Google Scholar]
- Imteaj, A.; Amini, M.H. Leveraging Asynchronous Federated Learning to Predict Customers Financial Distress. Intell. Syst. Appl. 2022, 14, 200064. [Google Scholar] [CrossRef]
- Ludwig, H.; Baracaldo, N.; Thomas, G.; Zhou, Y.; Anwar, A.; Rajamoni, S.; Ong, Y.; Radhakrishnan, J.; Verma, A.; Sinn, M.; et al. Ibm federated learning: An enterprise framework white paper v0. 1. arXiv 2020, arXiv:2007.10987. [Google Scholar]
- Dimitriadis, D.; Kumatani, K.; Gmyr, R.; Gaur, Y.; Eskimez, S.E. A Federated Approach in Training Acoustic Models. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 981–985. [Google Scholar]
- DeFauw, R.; Cudd, C. Applying Federated Learning for ML at the Edge. 2021. Available online: https://aws.amazon.com/blogs/architecture/applying-federated-learning-for-ml-at-the-edge/ (accessed on 1 July 2022).
- Samarati, P.; Sweeney, L. Protecting privacy when disclosing information: K-anonymity and its enforcement through generalization and suppression. J. Contrib. 1998. Available online: http://dataprivacylab.org/dataprivacy/projects/kanonymity/index3.html (accessed on 1 July 2022).
- Narayanan, A.; Shmatikov, V. How to Break Anonymity of the Netflix Prize Dataset. arXiv 2008, arXiv:610105. [Google Scholar]
- El Emam, K.; Dankar, F.K. Protecting privacy using k-anonymity. J. Am. Med. Inform. Assoc. 2008, 15, 627–637. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Luo, X.; Wu, Y.; Xiao, X.; Ooi, B.C. Feature inference attack on model predictions in vertical federated learning. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 181–192. [Google Scholar]
- Ahmed, M.F.B. Supporting Nonexperts in Choosing Appropriate Privacy-Enhancing Technologies. Available online: https://wwwmatthes.in.tum.de/pages/90yjv1qw6vz8/Master-s-Thesis-Faisal-Ahmed (accessed on 1 July 2022).
- Li, Z.; Sharma, V.; Mohanty, S.P. Preserving data privacy via federated learning: Challenges and solutions. IEEE Consum. Electron. Mag. 2020, 9, 8–16. [Google Scholar] [CrossRef]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our data, ourselves: Privacy via distributed noise generation. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 486–503. [Google Scholar]
- Domingo-Ferrer, J.; Sánchez, D.; Blanco-Justicia, A. The limits of differential privacy (and its misuse in data release and machine learning). Commun. ACM 2021, 64, 33–35. [Google Scholar] [CrossRef]
- Nison, S. Japanese Candlestick Charting Techniques: A Contemporary Guide to the Ancient Investment Techniques of the Far East, 2nd ed.; Penguin Putnam Inc.: New York, NY, USA, 2001. [Google Scholar]
- Bigalow, S.W. Profitable Candlestick Trading: Pinpointing Market Opportunities to Maximize Profits, Second Edition; John Wiley & Sons, Inc: Hoboken, NJ, USA, 2011. [Google Scholar]
- Wang, Z.; Oates, T. Encoding time series as images for visual inspection and classification using tiled convolutional neural networks. In Proceedings of the Workshops at the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ranzato, M.; Boureau, Y.L.; Cun, Y. Sparse feature learning for deep belief networks. In Advances in Neural Information Processing Systems; 2007; Available online: https://proceedings.neurips.cc/paper/2007/file/c60d060b946d6dd6145dcbad5c4ccf6f-Paper.pdf (accessed on 1 July 2022).
- Chen, J.H.; Tsai, Y.C. Encoding candlesticks as images for pattern classification using convolutional neural networks. Financ. Innov. 2020, 6, 1–19. [Google Scholar] [CrossRef]
- Tsai, Y.C.; Szu, F.M.; Chen, J.H.; Chen, S.Y.C. Financial Vision Based Reinforcement Learning Trading Strategy. arXiv 2022, arXiv:2202.04115. [Google Scholar]
- McSherry, F.; Talwar, K. Mechanism design via differential privacy. In Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), Providence, RI, USA, 20–23 October 2007; pp. 94–103. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Differential Privacy Team of Apple Inc. Learning with privacy at scale. Apple Mach. Learn. Res. 2017. Available online: https://machinelearning.apple.com/research/learning-with-privacy-at-scale (accessed on 1 July 2022).
- Ding, B.; Kulkarni, J.; Yekhanin, S. Collecting telemetry data privately. arXiv 2017, arXiv:1712.01524. [Google Scholar]
- Dwork, C.; Smith, A.; Steinke, T.; Ullman, J. Exposed! a survey of attacks on private data. Annu. Rev. Stat. Its Appl. 2017, 4, 61–84. [Google Scholar] [CrossRef] [Green Version]
- Dinur, I.; Nissim, K. Revealing information while preserving privacy. In Proceedings of the Twenty-Second ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, San Diego, CA, USA, 9–12 June 2003; pp. 202–210. [Google Scholar]
- Wang, R.; Li, Y.F.; Wang, X.; Tang, H.; Zhou, X. Learning your identity and disease from research papers: Information leaks in genome wide association study. In Proceedings of the 16th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 9–13 November 2009; pp. 534–544. [Google Scholar]
- Homer, N.; Szelinger, S.; Redman, M.; Duggan, D.; Tembe, W.; Muehling, J.; Pearson, J.V.; Stephan, D.A.; Nelson, S.F.; Craig, D.W. Resolving individuals contributing trace amounts of DNA to highly complex mixtures using high-density SNP genotyping microarrays. PLoS Genet. 2008, 4, e1000167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dwork, C.; Smith, A.; Steinke, T.; Ullman, J.; Vadhan, S. Robust traceability from trace amounts. In Proceedings of the 2015 IEEE 56th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 17–20 October 2015; pp. 650–669. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Ye, J.; Maddi, A.; Murakonda, S.K.; Shokri, R. Enhanced Membership Inference Attacks against Machine Learning Models. arXiv 2021, arXiv:2111.09679. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 739–753. [Google Scholar]
- Zhu, T.; Li, G.; Zhou, W.; Yu, P.S. Preliminary of differential privacy. In Differential Privacy and Applications; Springer: Berlin/Heidelberg, Germany, 2017; pp. 7–16. [Google Scholar]
- Mironov, I. Rényi differential privacy. In Proceedings of the 2017 IEEE 30th Computer Security Foundations Symposium (CSF), Santa Barbara, CA, USA, 21–25 August 2017; pp. 263–275. [Google Scholar]
- Stephen, W.B. The Major Candlesticks Signals; The Candlestick Forum LLC.: Woodlands, TX, USA, 2014. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Greenberg, A. How one of Apple’s key privacy safeguards falls short. Wired 2017, 13, 2018. [Google Scholar]






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Learning rate | 0.0006 |
| Momentum | 0.9 |
| Batch size | 100 |
| Epoch | 100 |
| Clipping | 1 | 1.5 | Recognition Rate | |
|---|---|---|---|---|
| Noise () | ||||
| 0.1 (90,964.58) | 88.95% | 91.15% | 62.11% | |
| 0.3 (284.62) | 87.48% | 91.25% | 58.21% | |
| 0.5 (39.05) | 87.70% | 90.75% | 51.40% | |
| 0.7 (12.62) | 87.15% | 90.45% | 49.65% | |
| 1 (5.41) | 85.98% | 89.23% | 46.04% | |
| MNIST | CIFAR-10 | Our Data | |||
|---|---|---|---|---|---|
| Accuracy | Accuracy | Accuracy | |||
| Baseline | 98.3% | Baseline | 96.5% | Baseline | 96.13% |
| 2 | 95% | 4 | 70% | 5.41 | 89.23% |
| 8 | 97% | 8 | 73% | 12.62 | 90.45% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.-R.; Tsai, Y.-C. The Protection of Data Sharing for Privacy in Financial Vision. Appl. Sci. 2022, 12, 7408. https://doi.org/10.3390/app12157408
Wang Y-R, Tsai Y-C. The Protection of Data Sharing for Privacy in Financial Vision. Applied Sciences. 2022; 12(15):7408. https://doi.org/10.3390/app12157408
Chicago/Turabian StyleWang, Yi-Ren, and Yun-Cheng Tsai. 2022. "The Protection of Data Sharing for Privacy in Financial Vision" Applied Sciences 12, no. 15: 7408. https://doi.org/10.3390/app12157408