1. Introduction
With the development of society, intelligent devices have gradually become widely used. At the same time, the application field of video images is more extensive. When taking photos, insufficient light will lead to low contrast and overall low brightness, which will not only affect the subjective visual experience brought by appearances but also lead to the loss of image details. This hinders further image processing, such as face recognition and target detection [
1]. However, due to bad weather conditions, poor ambient light, and limited performance of shooting equipment, low-contrast, low-light images are everywhere. Therefore, it is of great significance to study low-light image enhancement [
2].
In recent years, scholars have tried to find an optimal algorithm to improve the quality of low illumination images. First, let us think of the gray-level transform algorithm. The gray level transform algorithm adjusts the image grayscale range. For example, histogram equalization adjusts a gray space originally concentrated in the image to the uniform distribution of all gray areas of the image [
3], to a certain extent, improving the image brightness but did not consider the relationship between the pixels and making the enhanced images lack the sense of reality [
4].
When studying the defogging image algorithm, Dong et al. [
5] found that the pixel value distribution of the inverted image of the low-light image is very similar to that of the foggy notion, so the defogging algorithm can be applied to low-light image enhancement. Although the algorithm has a good enhancement effect, the enhanced image will appear with the artifact phenomenon [
6].
Methods based on the Retinex theory [
7] are relatively popular, and nearly one-third of the methods are designed in combination with Retinex theory. Different subnetworks are used to estimate other components of Retinex theory, which usually have good results. Jobson et al. [
8] proposed a single-scale Retinex algorithm, which uses the constructed Gaussian surrounding function to filter the three color channels of the image, and the filtered image is the estimated illumination component. After logarithmic processing of the original image and illumination image, the output result is obtained by subtracting [
9]. The multi-scale Retinex-enhanced algorithm [
10], compared with the single-scale algorithm, increases the number of Gaussian wrapping functions, which can be regarded as a weighted sum of multiple single-scale Retinex of different scales. Wang et al. [
11] designed a constraint condition formulated by the prior guidance layer of an end-to-end signal for the low-light enhancement of a single image. Feng et al. [
12] proposed a color image enhancement algorithm based on adaptive weighted Retinex and wavelet transform. The low-frequency image is enhanced with adaptive weight Retinex, and the improved threshold is used for high-frequency image denoising. Finally, the inverse wavelet transform is used to reconstruct the luminance component.
In recent years, the popularity of deep learning has been very high. Its powerful feature representation and nonlinear mapping ability has also been widely used in the field of image, and has achieved great success [
13]. Lore et al. [
14] first used the method of deep learning to realize low illumination image enhancement (LLNet). They proposed a method based on a depth self-encoder to recognize signal features from low illumination images. In an image with a high dynamic range, the image is brightened adaptively, without supersaturating the lighter part. Experiments were carried out on real low illumination images, and the effectiveness of the LLNet algorithm is proved.
The Retinex theory is a very effective low-light image enhancement theory. In the case of the unknown reflection component, it is an ill-posed problem to solve the illumination component, so we can only calculate using the approximate estimation method. In this paper, an illumination image estimation method based on YCbCr color space is proposed. By processing the image y-channel component, combining Gamma correction, Retinex theory, noise reduction module, and image fusion procedure, the y-component illumination image is enhanced. Then, the final enhancement effect is obtained using the noise reduction fusion method. This method has been compared with low light image enhancement methods at home and abroad in recent years, and the experimental results have been analyzed objectively and subjectively.
The first section of this paper introduces the background and purpose of relevant research; the second section introduces the relevant work and theoretical knowledge; the third section introduces the design algorithm and details; the fourth section evaluates the experimental results to prove the effectiveness of the proposed algorithm; and finally, we summarize the full text.
3. Proposed Algorithm
In this paper, the effects of color distortion and noise are considered, and a low illumination image enhancement algorithm based on YCbCr color space is proposed, which can avoid color distortion and noise while preserving image details.
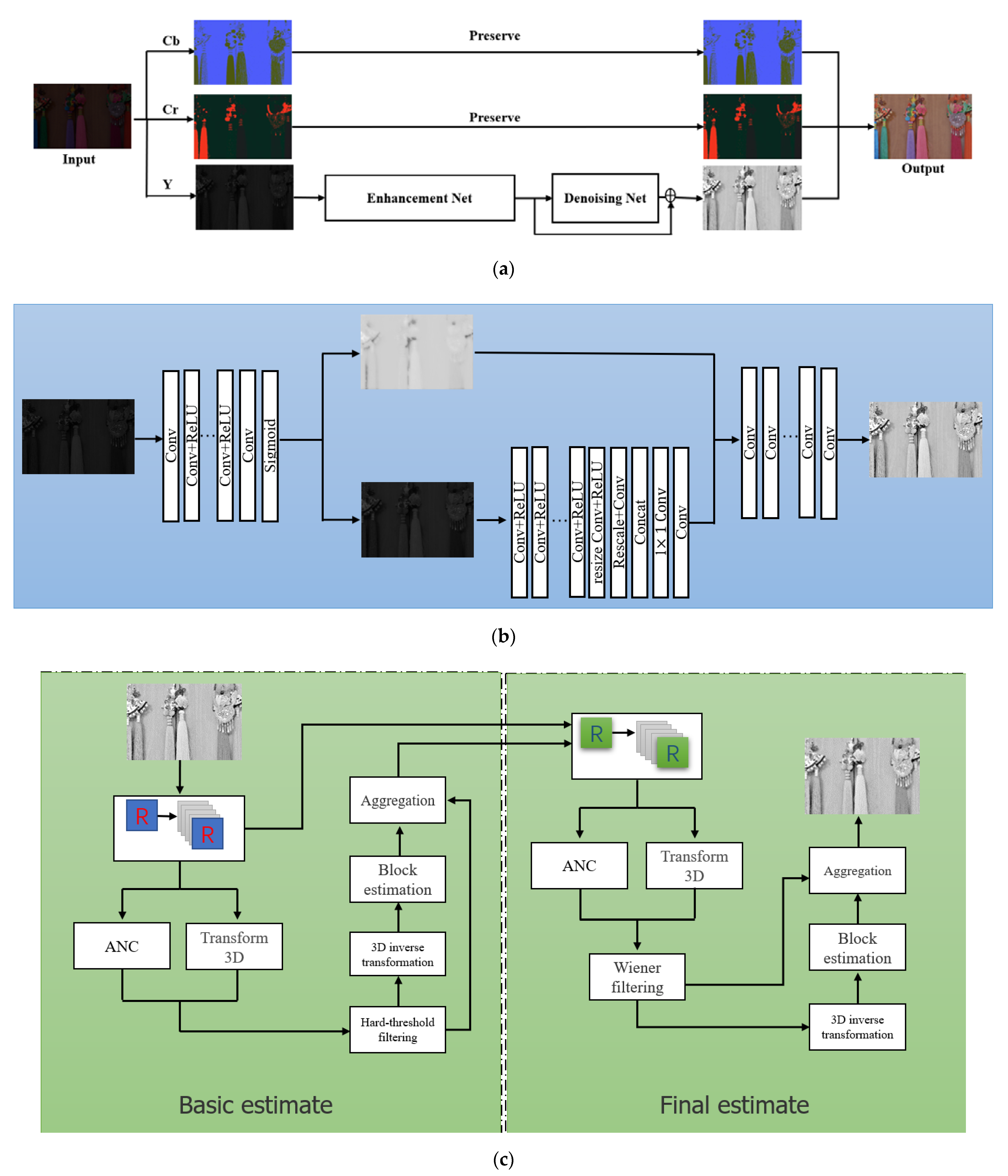
Figure 1 shows the algorithm model used in this paper. The algorithm is divided into two parts: the Enhancement Module and the Denoising Module. First, the image is decomposed into Y, Cb, and Cr channels. The Y channel component is input into RetinexNet to obtain the initial processing image. Then, the Y channel component is copied in two copies, and one is input to the noise reduction module; the other is combined with the output result of noise reduction to obtain the enhanced image. The final enhancement effect is obtained by the method of noise reduction fusion. In the following section, the functions and implementation of each network are described in detail.
3.1. Enhanced Networks
The enhanced network is a convolutional network model based on the Retinex theory. The network framework is composed of a decomposed network and an improved network.
The RetinexNet algorithm is divided into three steps: (1) the decomposition model uses a low illumination image and standard illumination image to estimate the illumination component and realize the decomposition of the reflection component and illumination component; (2) the adjustment model is used to de-noise the reflection component of the low light image, and encoder-decoder is used to capture an extensive range of light distribution context information for adaptive adjustment of the light component; (3) the reconstructed model restores the enhanced image from the processed reflection component and illumination component. The decomposition model is composed of 5 convolution layers with ReLU activate functions. The parameters of the low-light image and the typical light image are shared, and the reflection component and light component of the low-light image and the reflection component and light component of the normal light image are obtained. The constraint relationship between each component is used to optimize the model. The loss function of this model is composed of reconstruction loss
, reflectivity loss
and light smoothing loss
:
where reconstruction loss
, its objective is to make it possible to reconstruct the corresponding original image from the decomposed reflection component and illumination component. Reflectivity loss
, the purpose is to make the reflection components of the paired low/standard light images as consistent as possible. Illumination component loss
, this loss is to make the area with smooth reflection component as soft as possible on the corresponding illumination component.
3.2. Noise Reduction Module
The central idea of the module is to make full use of the abundant self-similar structures in the image to denoise the image. It is divided into two stages. The first stage is basic estimation filtering. First, a number of reference blocks are placed in the original image at a step size (usually 3 pixels), each reference block searches the appropriate area around it, and all blocks similar to the league are found, stacked into a three-dimensional array, and three-dimensional transformation is applied to the variety. The problematic threshold transformation coefficient was used to reduce the noise, and then 3D inverse transformation was carried out to obtain the estimates of all grouped blocks. Finally, all blocks were returned to their initial positions. The weighted average of all overlapping block estimates was carried out by coalition to obtain the basic calculations of the actual image. The final estimation filtering is performed in the second stage. For each block in the image, block matching is used to find all block positions similar to the current processing block based on the basic estimation. We use these positions to form two three-digit arrays, one from the raw image and one from the base estimate. Applying a 3D transformation to the two groups, wiener filtering is performed on the original image using the energy spectrum estimated as the real energy spectrum. All block estimates of the 3D inverse transform are performed on the filtered 3D coefficients. These block estimators are put back to their original positions. Finally, the weighted average is used to aggregate all the local estimates to obtain the final assessment of the actual image.
Different from bilinear filtering, median filtering, etc., which uses local image information to filter, it uses the whole image for denoising, searches for similar regions in the image-by-image block and averages these regions. It is good enough to remove Gaussian noise from the image.
4. Experiment and Results Analysis
4.1. Experimental Settings
The network performance of deep learning is closely related to datasets. The algorithm in this paper adopts the LOL (low-light) [
21] training set to train and test the network, among which 485 pairs of low-light images are used for the training network and 15 for the test network. Training environment configuration: Intel i7-8700 CPU, 32G memory, and an NVIDIA GeForce RTX2080 Ti GPU. During the training, the batch size was set to 16, the patch size to 48, and Adam’s initial learning rate was set to 0.001. The network framework was built using the TensorFlow 2.6.0 framework, PyCharm software in a 32 GB environment, and an Anaconda Python 3.7 interpreter. Test environment configuration: Inter(R) Core (TM) i5-6300 hq CPU @ 2.3 GHz, Windows10 operating system, PyCharm in 12 GB environment, interpreter Anaconda Python 3.7.
4.2. Results Analysis
We evaluated the proposed experimental method through a large number of experiments, and compared them quantitatively through PSNR, SSIM, and UQI indicators. The higher the three values, the better the image enhancement effect.
PSNR is used to measure the difference between the two images. These include compressed image and original image, evaluation of the quality of the compressed image, restoration image and real image, evaluation of restoration algorithm performance, etc. The formula is:
where MSE is the mean square error of two images; MaxValue is the maximum value of image pixels.
Structural similarity is the most widely used standard for referenced image quality evaluation; SSIM is used to highlight the brightness, contrast, and structural similarity between two images. The value range is 0–1; the closer the value is to 1, the more similar the two images are. Assuming that
x and
y are two input images, the formula is:
where
is brightness comparison,
is contrast comparison, and
is structural comparison.
are the following formulas, respectively:
In the formula, and respectively represent the average value of the two images, and represent the standard deviations of the two images, represents the covariance of the two images, , and are constants to avoid 0 in the denominator.
The UQI is also called the image universal quality index. It can be easily calculated and applied to a variety of image processing applications, mainly combined with three factors to calculate: correlation loss, brightness distortion, and contrast distortion.
The calculation formula of the UQI index is as follows:
where
, is the original image signal;
, is the test image signal.
4.3. Experimental Comparison
To reflect the effect of this algorithm, we compare the proposed approach with the traditional image enhancement algorithm and the latest image enhancement algorithm.
Table 1 and
Figure 2 show the comparison results between the classical low-illumination image-processing methods and our proposed methods on LOL datasets. The data show that our method is superior to other traditional image enhancement algorithms in terms of quality evaluation.
To better reflect the subjective visual effects, we selected indoor images and outdoor images for enhancement. We enlarge the detailed part of the image to better reflect the image enhancement effect, as shown in
Figure 3 and
Figure 4.
Figure 3 shows the indoor low illumination image and the enhanced effect picture. As you can see from the zoom in detail, indoor images were enhanced by HE, Retinex, and MSR, resulting in white, obvious distortion, and serious loss of image details. After processing with the RetinexNet algorithm, the overall brightness of the image is improved, but the contrast is reduced, the overall image becomes blurred, and the visual effect is reduced. LIME enhancement effect is dark on the whole and not obvious in dark areas.
Figure 4 shows the enhanced effect of outdoor low-illumination images. It can be seen from the detailed amplification effect display that the overall enhancement effect of Retinex and MSR is white, and the car light distortion is obvious; the enhancement effect of HE is relatively natural, but the image is noisy; the enhancement effect is not obvious in dark areas of MSRCP and LIME, and details are lost; RetinexNet Enhances the overall relative blur of the image.
The mean opinion score (MOS) test is a commonly used subjective image quality assessment method; human raters were asked to assign perceptual quality scores to test images. Usually, the score ranges from 1 (poor) to 5 (good). The final MOS is calculated as the arithmetic mean for all grades.
The expression of MOS is as follows:
where
R represents the number of evaluators’ satisfaction scores for the image, and
N represents the total number of evaluators. We selected the results of 100 questionnaires, and the average opinion score is shown in
Table 2.
As can be seen from
Table 2, our method gets the highest score in indoor image enhancement effect. As for outdoor image enhancement, our score is tied in the first place with HE, but the score is still higher when compared with the others.
5. Conclusions
In this paper, a composite model for image enhancement with low illumination is proposed that avoids color distortion, preserves image details as much as possible, considers the effect of image noise, and makes full use of the rich self-similar structure in the image to denoise the image. Experimental results show that compared with HE, Retinex, MSR, MSRCP, LIME, and RetinexNet algorithms, the peak signal-to-noise ratio, structure similarity, and universal quality index of images processed by the proposed algorithm are improved by 2.7%, 23.4%, and 15.7%, on average. Through many experiments, it has been proven that the method in this paper has good improvement in both the objective evaluation index and the subjective visual effect.








{kind=link}
{kind=link}
{kind=link}
{kind=link}