
Toward an Efficient Automatic Self-Augmentation Labeling Tool for Intrusion Detection Based on a Semi-Supervised Approach


Abstract
:1. Introduction
2. Related Work
2.1. Supervised-Based Techniques
2.2. Unsupervised-Based Techniques
2.3. Semi-Supervised-Based Techniques
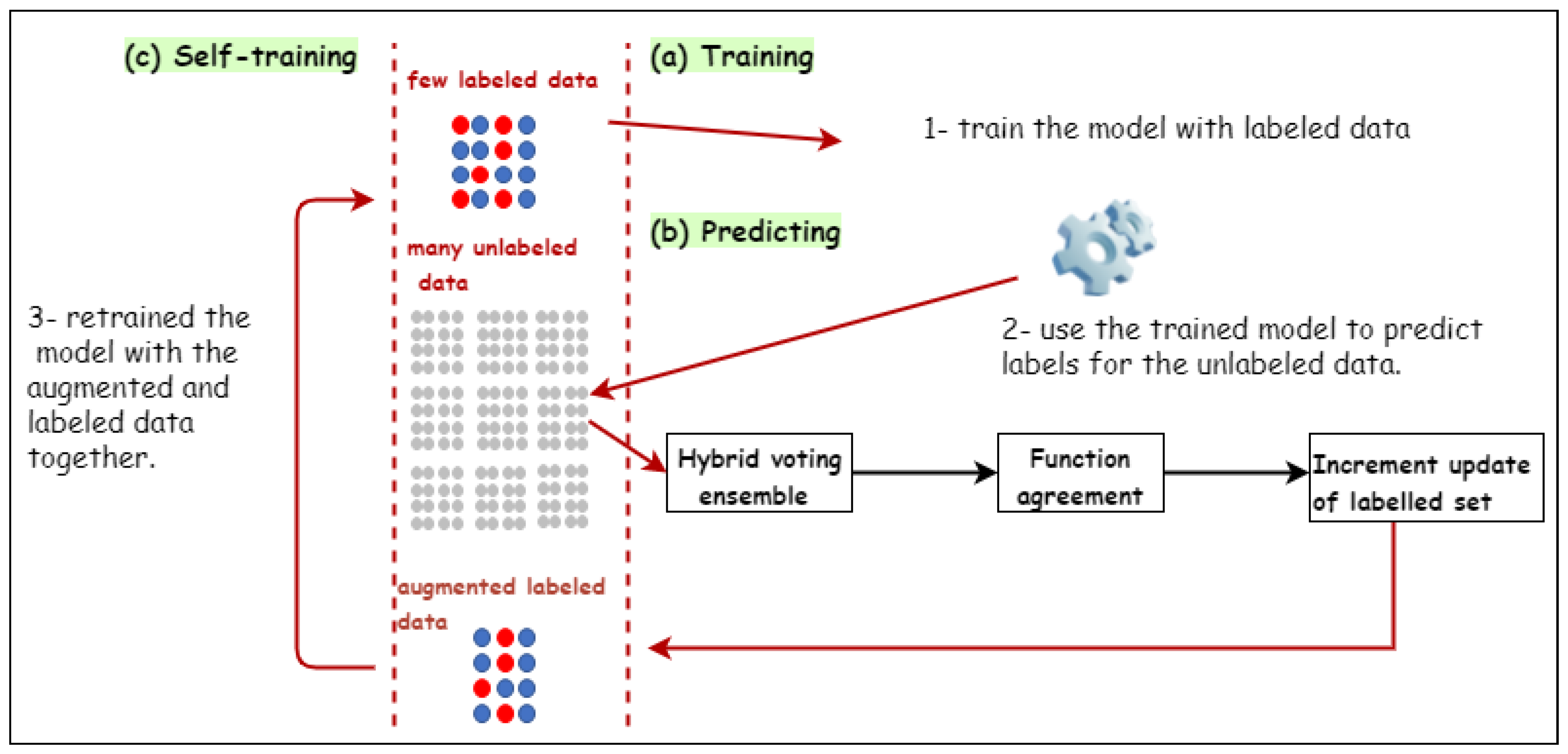
3. SAL: Proposed Self-Augmentation Labeling Approach
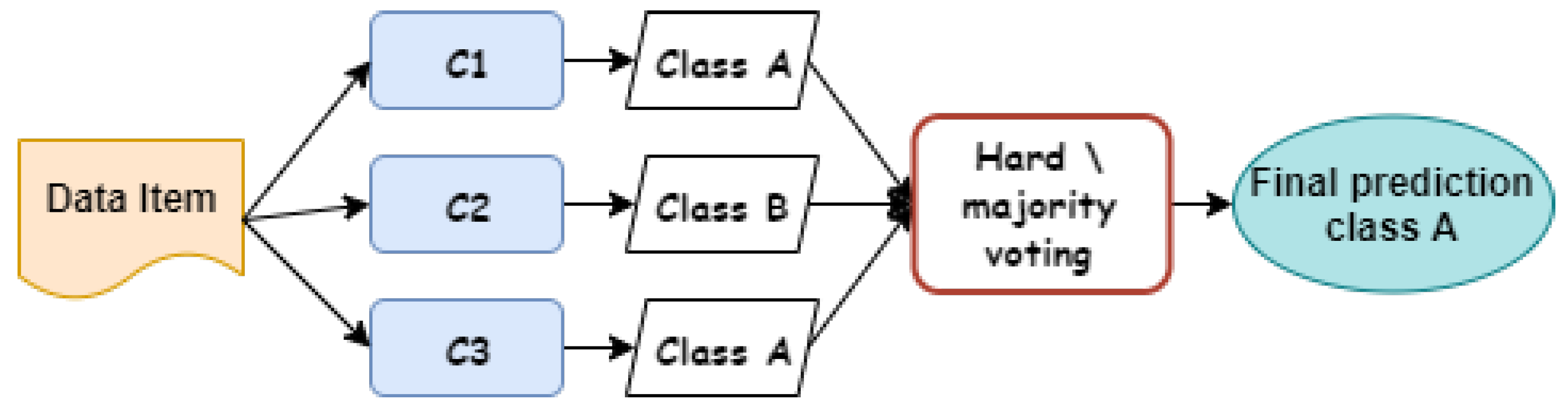
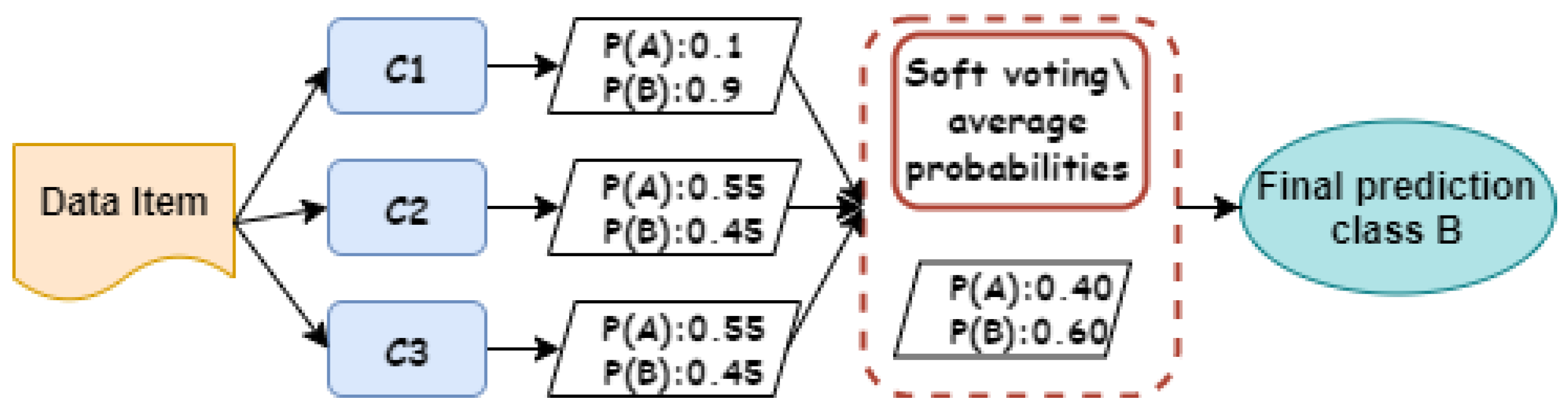
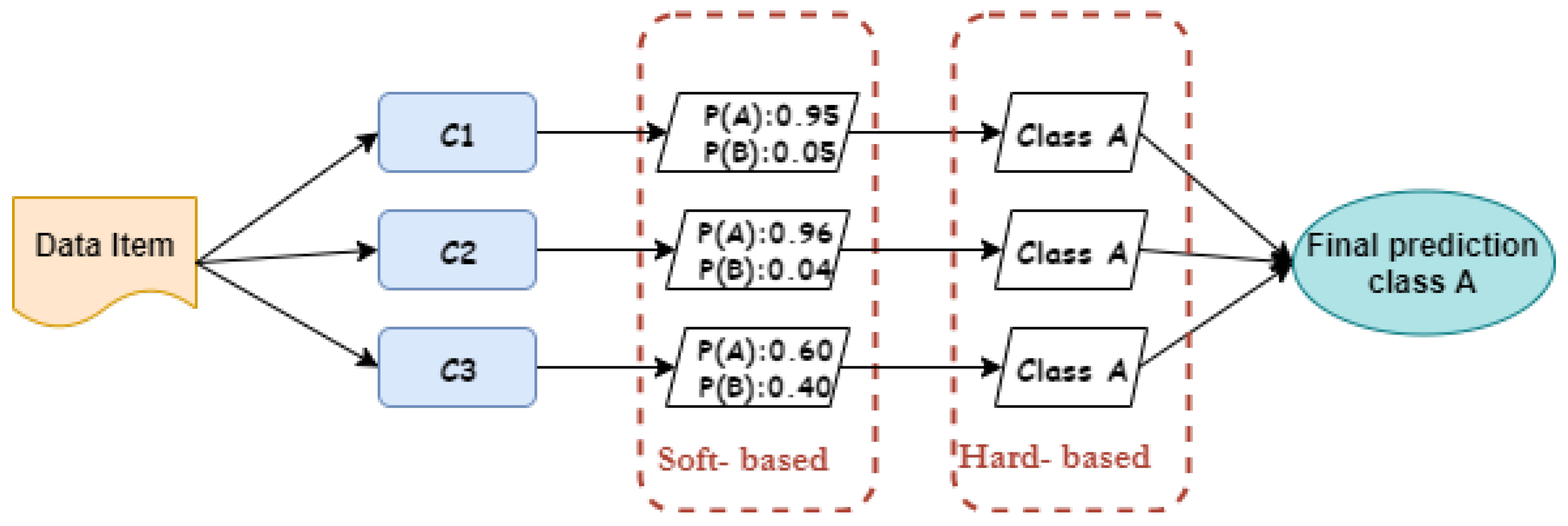
3.1. Hybrid Voting-Based Ensemble Approach
3.2. Function Agreement
- 1
- Labeling threshold. This threshold represents the minimum acceptable probability for labeling the observations. In order to improve the classification accuracy for the results, we will start with a very high value of to ensure that only the most accurately labeled observations are classified. The value of this threshold can be tolerated (decreased) by a fixed value which is denoted as ; this means that the threshold is decreased by when the value of learning rate meets the predefined criterion.
- 2
- Learning Rate. The learning rate (LR) is a hyper-parameter that measures the rate or speed at which the model learns the values of the parameters. It evaluates how quickly the model adapts to the problem. In the proposed algorithm, the labeling threshold value is considered the most effective factor on LR. As a result, a high value leads to a smaller LR, implying that more training is required. On the other hand, as the value of the threshold is decreased, the LR increases, resulting in faster changes and less training. Let denote a variable that represents the number of labeled observations at iteration i, and is a variable that represents the number of unlabeled observations at iteration i.
- 3.
- Illustrative Example. An example is presented below to explain the proposed model’s labeling process. Given three selected supervised classifiers () that are trained on a small labeled dataset to provide decision models (), in this example, each unlabeled observation belongs to one of five possible labels as follows: .
- (1)
- The probabilities of are predicted as shown in Table 1.
- (2)
- The higher probability for each classifier is found and compared with the value.
- (3)
- is assigned to the observation since all classifiers agree on it.
3.3. An increment Update of Labeled Set
| Algorithm 1 Labeling Process |
| Input: Labeled data set L; Unlabeled data set U; : base learning algorithms. : voting Ensemble Classifier. |
| Output: Fully labeled data set |
Process:
|
4. Experiment Results and Comparison
4.1. Data Sets Used in Experiment
4.1.1. NSL-KDD
4.1.2. ISCX 2012
4.2. The Baseline Algorithms
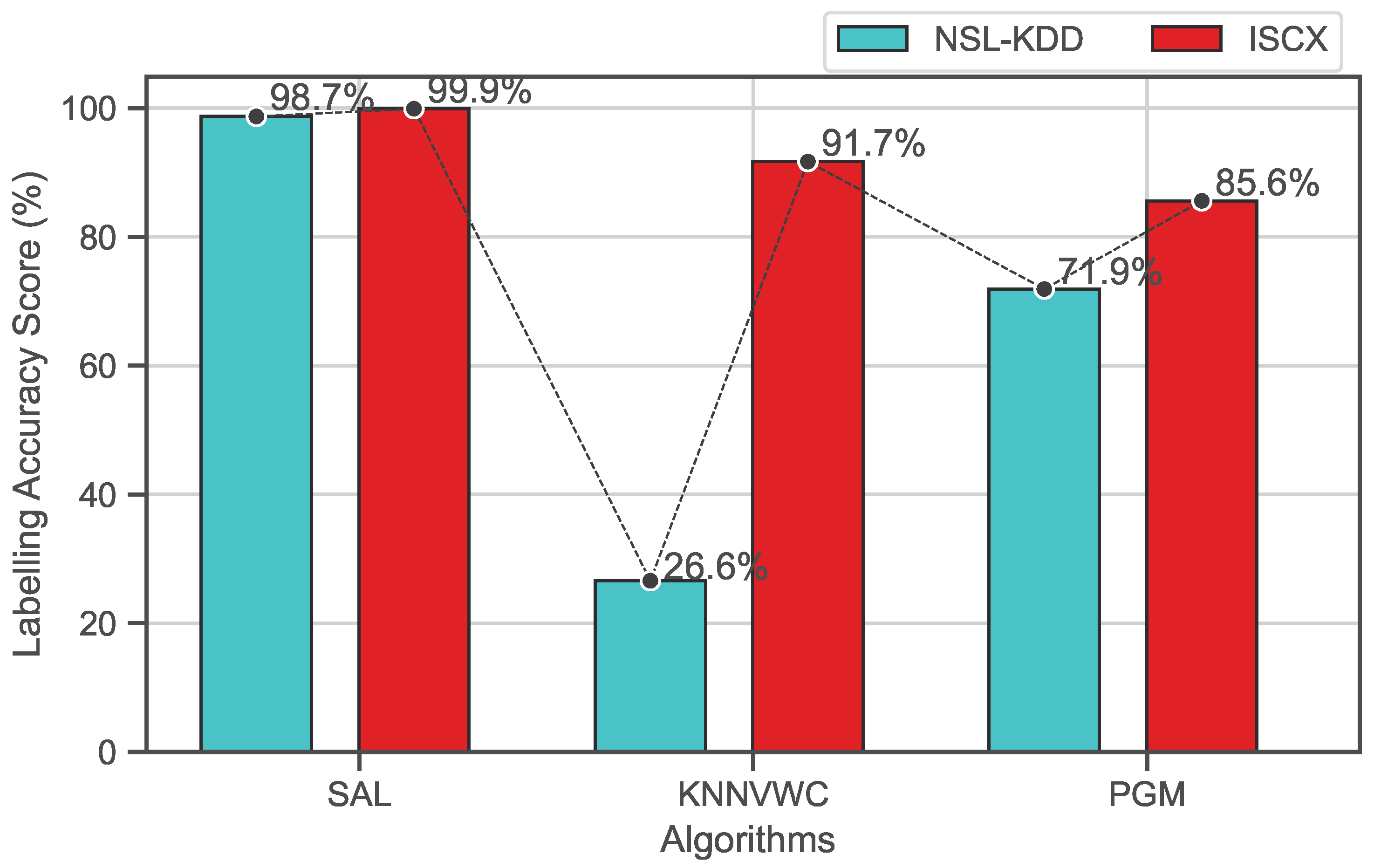
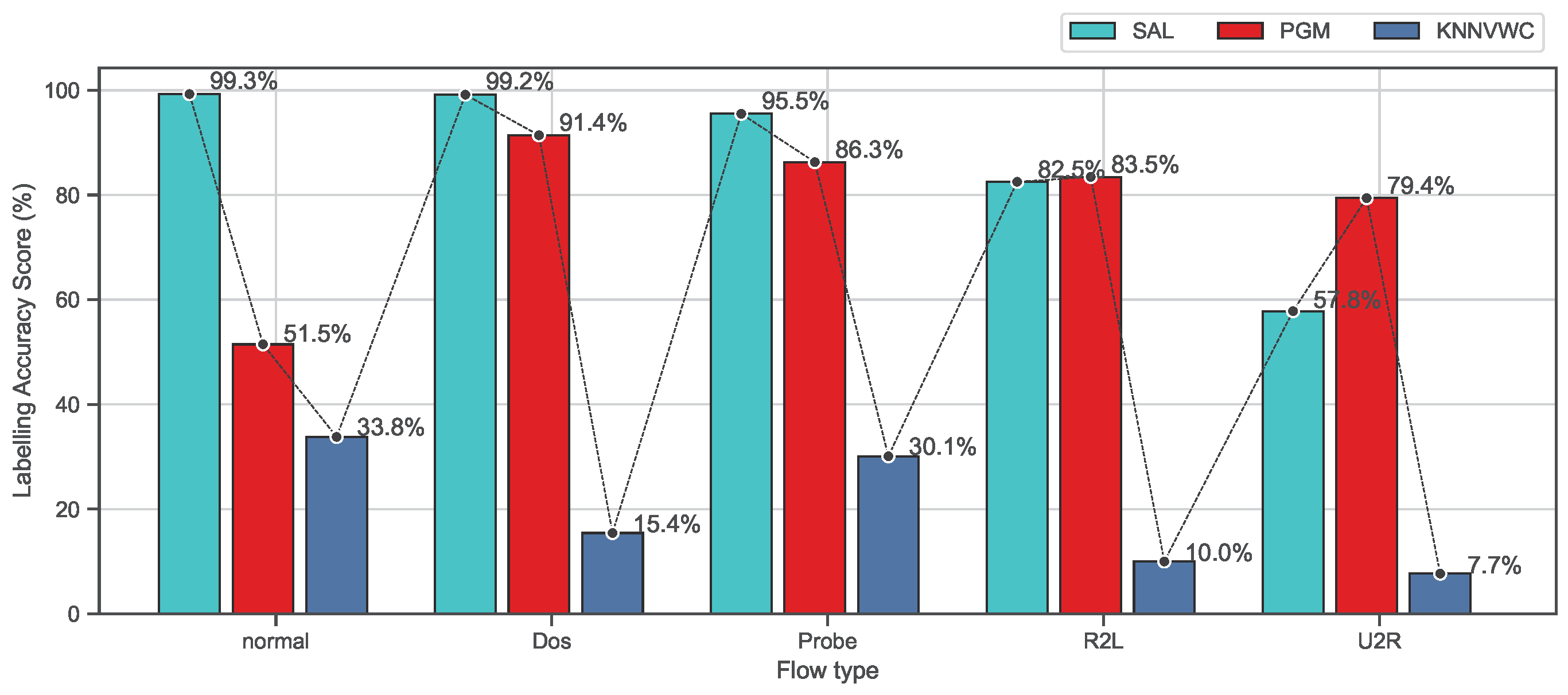
- Probabilistic graphical model (PGM)This algorithm applies a self-training procedure, and probabilistic graphical modules are used to label unlabeled flows. It is a Nave Bayes extension designed to learn from both labeled and unlabeled instances. The first step is used to assign a probability distribution among all known and unknown variables in labeled traffic flow using Naive Bayes. In the second step, this algorithm identifies a rule that describes the relationship between the probability distribution and the decision rule.
- Various-Widths Clustering ( kNNVWC)This approach can produce clusters of various distributions, sizes, and radii from high-dimensional data. The clustering process is divided into three sub-phases: cluster width learning, partitioning, and merging. These phases are repeated and executed until the user-defined criteria are met. In the first stage, we estimate the global width of the data set, which is the average of the widths of a set of observations picked randomly from the data set. Then, the determined width will be used in the partitioning phase to recursively partition a data set into several clusters. The third stage aims to reduce cluster overlap as much as possible in order to explore the most representative observations. The labeling process of unlabeled observations is based on the majority class (or label) of the labeled observations contained in the cluster, whereas the class label that receives the largest number of votes is assigned to this observation.
4.3. Performance Metrics
4.3.1. Overall Accuracy
4.3.2. Recall
4.3.3. F-Measure
4.4. The Experimental Setup
4.4.1. Parameters Setting
- 1
- The procedure for selecting classifiers for the ensemble learning phase.
- 2
- The value of the threshold, which represents the minimum acceptable probability for labeling the observations at each iteration
- 3
- The value of the threshold, which denotes the maximum learning rate that allows threshold to be updated.
- 4
- The threshold value, which indicates threshold decrements step.
4.4.2. The candidate Classifiers
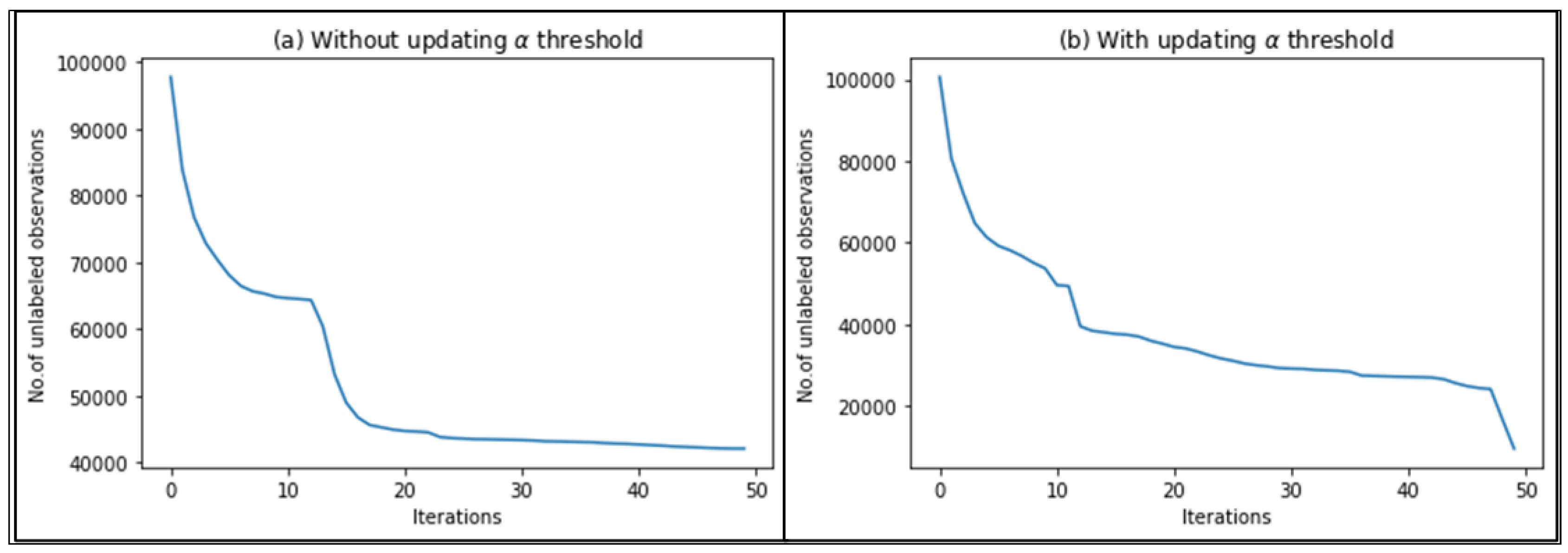
4.4.3. Optimisation of Threshold
4.5. Results and Discussion
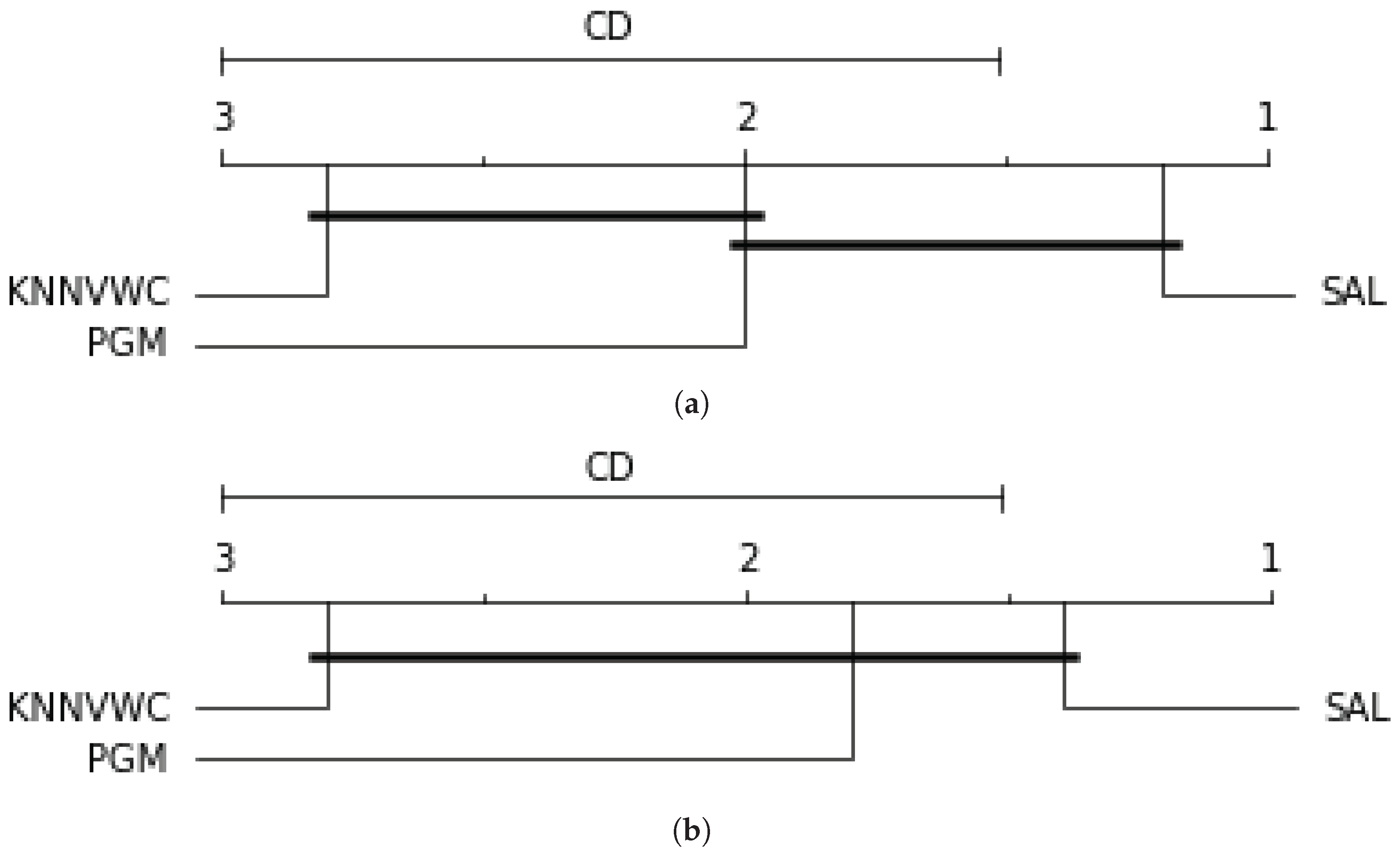
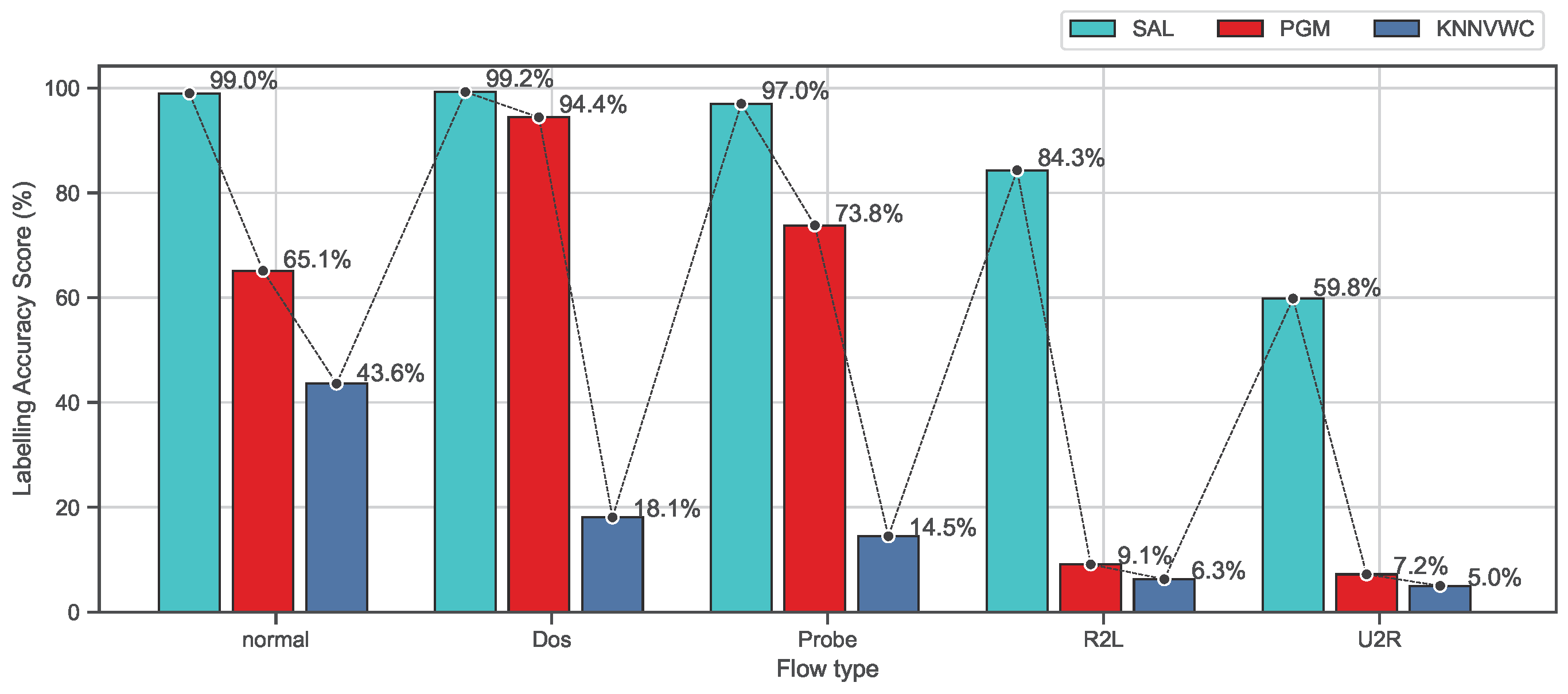
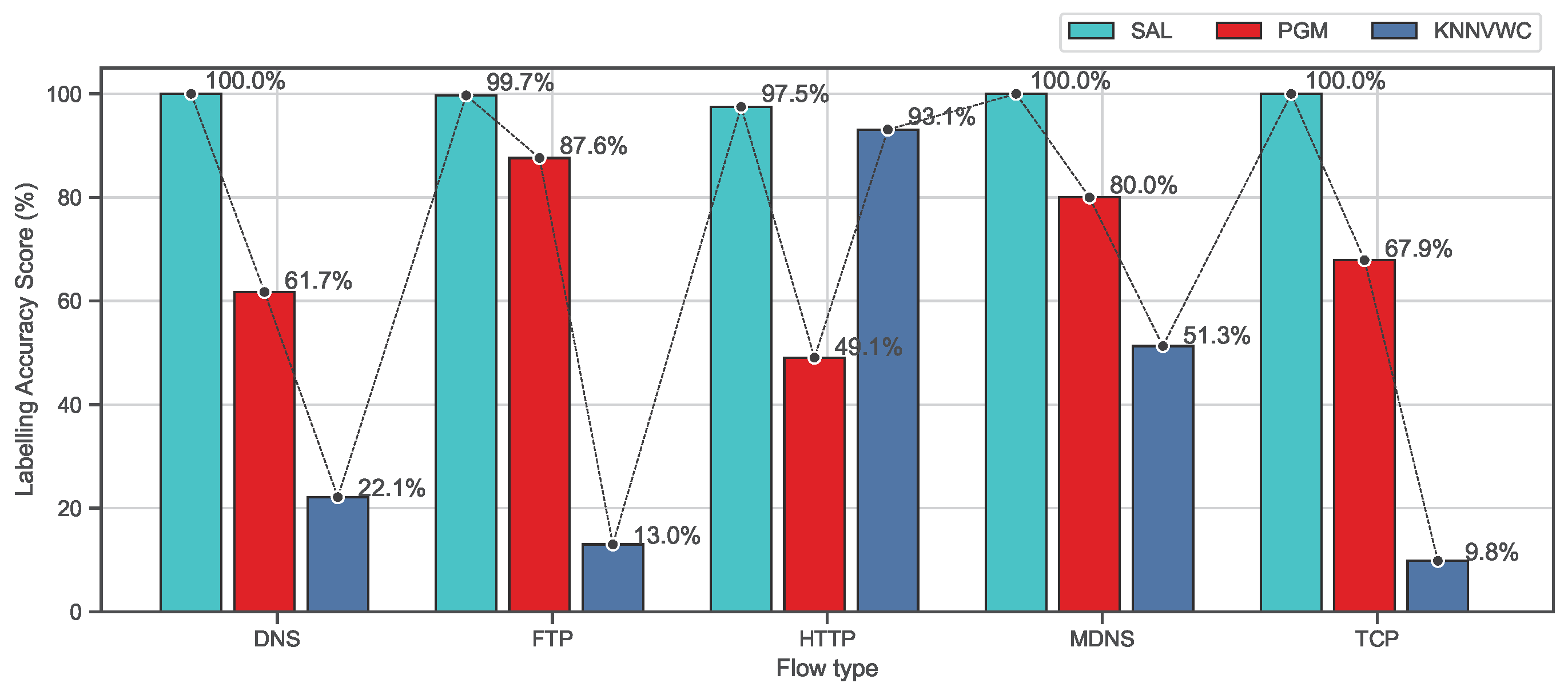
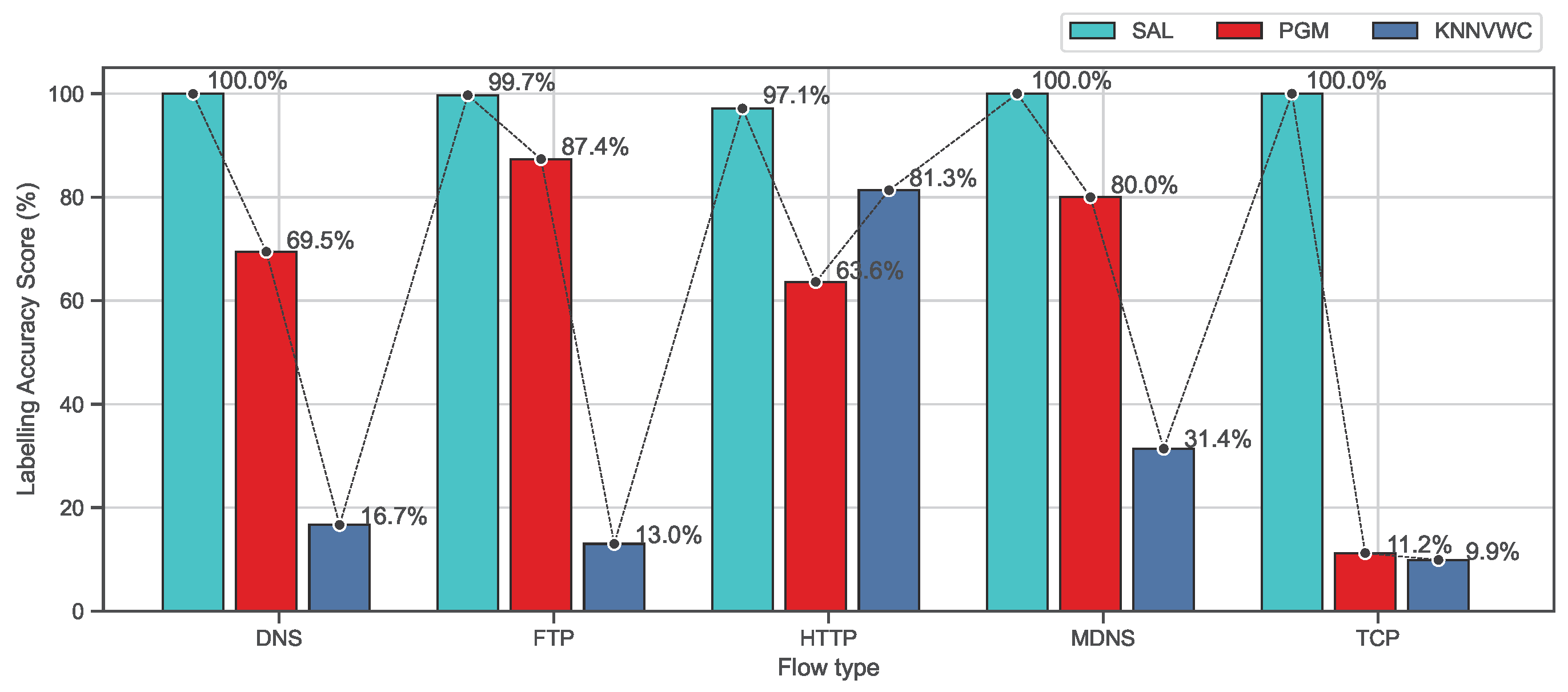
4.5.1. Overall Accuracy Evaluation
4.5.2. Class-Based Evaluation
4.5.3. Runtime performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chio, C.; Freeman, D. Machine Learning and Security: Protecting Systems with Data and Algorithms; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Al-Harthi, A. Designing an Accurate and Efficient Classification Approach for Network Traffic Monitoring. Ph.D. Thesis, RMIT University, Melbourne, Australia, 2015. [Google Scholar]
- Taha, A.; Hadi, A.S. Anomaly Detection Methods for Categorical Data: A Review. ACM Comput. Surv. CSUR 2019, 52, 38. [Google Scholar] [CrossRef]
- Bhattacharyya, D.K.; Kalita, J.K. Network Anomaly Detection: A Machine Learning Perspective; Chapman and Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Love, B.C. Comparing supervised and unsupervised category learning. Psychon. Bull. Rev. 2002, 9, 829–835. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Erman, J.; Mahanti, A.; Arlitt, M.; Cohen, I.; Williamson, C. Offline/realtime traffic classification using semi-supervised learning. Perform. Eval. 2007, 64, 1194–1213. [Google Scholar] [CrossRef]
- Rotsos, C.; Van Gael, J.; Moore, A.W.; Ghahramani, Z. Probabilistic graphical models for semi-supervised traffic classification. In Proceedings of the 6th International Wireless Communications and Mobile Computing Conference, Caen, France, 28 June–2 July 2010; pp. 752–757. [Google Scholar]
- Marsland, S. Machine Learning: An Algorithmic Perspective; Chapman and Hall/CRC: Boca Raton, FL, USA, 2014. [Google Scholar]
- Li, L.; Zhang, H.; Peng, H.; Yang, Y. Nearest neighbors based density peaks approach to intrusion detection. Chaos Solitons Fractals 2018, 110, 33–40. [Google Scholar] [CrossRef]
- Xue, Y.; Jia, W.; Zhao, X.; Pang, W. An evolutionary computation based feature selection method for intrusion detection. Secur. Commun. Netw. 2018, 2018, 2492956. [Google Scholar] [CrossRef]
- Gu, J.; Wang, L.; Wang, H.; Wang, S. A novel approach to intrusion detection using SVM ensemble with feature augmentation. Comput. Secur. 2019, 86, 53–62. [Google Scholar] [CrossRef]
- Kabir, E.; Hu, J.; Wang, H.; Zhuo, G. A novel statistical technique for intrusion detection systems. Future Gener. Comput. Syst. 2018, 79, 303–318. [Google Scholar] [CrossRef] [Green Version]
- Gao, L.; Li, Y.; Zhang, L.; Lin, F.; Ma, M. Research on Detection and Defense Mechanisms of DoS Attacks Based on BP Neural Network and Game Theory. IEEE Access 2019, 7, 43018–43030. [Google Scholar] [CrossRef]
- Salo, F.; Nassif, A.B.; Essex, A. Dimensionality reduction with IG-PCA and ensemble classifier for network intrusion detection. Comput. Netw. 2019, 148, 164–175. [Google Scholar] [CrossRef]
- Tan, H.; Gui, Z.; Chung, I. A Secure and Efficient Certificateless Authentication Scheme With Unsupervised Anomaly Detection in VANETs. IEEE Access 2018, 6, 74260–74276. [Google Scholar] [CrossRef]
- Pan, Y.; Sun, F.; Teng, Z.; White, J.; Schmidt, D.C.; Staples, J.; Krause, L. Detecting web attacks with end-to-end deep learning. J. Internet Serv. Appl. 2019, 10, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Yao, H.; Fu, D.; Zhang, P.; Li, M.; Liu, Y. MSML: A Novel Multilevel Semi-Supervised Machine Learning Framework for Intrusion Detection System. IEEE Internet Things J. 2018, 6, 1949–1959. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, S.; Mirvaziri, H.; Ghazizadeh-Ahsaee, M.; Karimipour, H. Cyber intrusion detection by combined feature selection algorithm. J. Inf. Secur. Appl. 2019, 44, 80–88. [Google Scholar] [CrossRef]
- Song, H.; Jiang, Z.; Men, A.; Yang, B. A hybrid semi-supervised anomaly detection model for high-dimensional data. Comput. Intell. Neurosci. 2017, 2017, 8501683. [Google Scholar] [CrossRef] [Green Version]
- Camacho, J.; Maciá-Fernández, G.; Fuentes-García, N.M.; Saccenti, E. Semi-supervised multivariate statistical network monitoring for learning security threats. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2179–2189. [Google Scholar] [CrossRef] [Green Version]
- Vercruyssen, V.; Wannes, M.; Gust, V.; Koen, M.; Ruben, B.; Jesse, D. Semi-supervised anomaly detection with an application to water analytics. In Proceedings of the IEEE International Conference on Data Mining, Singapore, 17–20 November 2018. [Google Scholar]
- Idhammad, M.; Afdel, K.; Belouch, M. Semi-supervised machine learning approach for DDoS detection. Appl. Intell. 2018, 48, 3193–3208. [Google Scholar] [CrossRef]
- Suaboot, J.; Fahad, A.; Tari, Z.; Grundy, J.; Mahmood, A.N.; Almalawi, A.; Zomaya, A.Y.; Drira, K. A Taxonomy of Supervised Learning for IDSs in SCADA Environments. ACM Comput. Surv. CSUR 2020, 53, 1–37. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000; pp. 1–15. [Google Scholar]
- Mahabub, A. A robust technique of fake news detection using Ensemble Voting Classifier and comparison with other classifiers. SN Appl. Sci. 2020, 2, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G. Ensemble learning. Handb. Brain Theory Neural Netw. 2002, 2, 110–125. [Google Scholar]
- Chen, C.O.; Zhuo, Y.Q.; Yeh, C.C.; Lin, C.M.; Liao, S.W. Machine learning-based configuration parameter tuning on hadoop system. In Proceedings of the 2015 IEEE International Congress on Big Data, New York, NY, USA, 27 June–2 July 2015; pp. 386–392. [Google Scholar]
- Almalawi, A.M.; Fahad, A.; Tari, Z.; Cheema, M.A.; Khalil, I. k NNVWC: An Efficient k-Nearest Neighbors Approach Based on Various-Widths Clustering. IEEE Trans. Knowl. Data Eng. 2015, 28, 68–81. [Google Scholar] [CrossRef]
- Bala, R.; Nagpal, R. A review on kdd cup99 and nsl nsl-kdd dataset. Int. J. Adv. Res. Comput. Sci. 2019, 10, 64–67. [Google Scholar] [CrossRef] [Green Version]
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark datasets for intrusion detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Mortaz, E. Imbalance accuracy metric for model selection in multi-class imbalance classification problems. Knowl.-Based Syst. 2020, 210, 106490. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; Volume 14, pp. 1137–1145. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Shekar, B.; Dagnew, G. Grid search-based hyperparameter tuning and classification of microarray cancer data. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019; pp. 1–8. [Google Scholar]
- Parmar, A.; Katariya, R.; Patel, V. A review on random forest: An ensemble classifier. In International Conference on Intelligent Data Communication Technologies and Internet of Things; Springer: Berlin/Heidelberg, Germany, 2018; pp. 758–763. [Google Scholar]
- Mathanker, S.; Weckler, P.; Bowser, T.; Wang, N.; Maness, N. AdaBoost classifiers for pecan defect classification. Comput. Electron. Agric. 2011, 77, 60–68. [Google Scholar] [CrossRef]
- Moon, D.; Im, H.; Kim, I.; Park, J.H. DTB-IDS: An intrusion detection system based on decision tree using behavior analysis for preventing APT attacks. J. Supercomput. 2017, 73, 2881–2895. [Google Scholar] [CrossRef]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Hollander, M.; Wolfe, D.A.; Chicken, E. Nonparametric Statistical Methods; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 751. [Google Scholar]
- Denning, D.E. An intrusion-detection model. IEEE Trans. Softw. Eng. 1987, SE-13, 222–232. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decision Model | M1 | M2 | M3 |
|---|---|---|---|
| Is observation ? | 0.98 | 0.99 | 0.97 |
| Is observation ? | 0.009 | 0 | 0.01 |
| Is observation ? | 0.01 | 0.008 | 0.01 |
| Is observation ? | 0 | 0.002 | 0.005 |
| Is observation ? | 0.001 | 0 | 0.005 |
| Sum | 1 | 1 | 1 |
| Max | 0.98 | 0.99 | 0.97 |
| Self-Augmentation Labeling Processes Algorithm | |
|---|---|
| L | The labeled subset of the training data. |
| U | The unlabeled subset of the training data (the most part). |
| C={C1,C2,C3} | Set of the selected supervised base classifiers used to build the decision model. |
| The model that trains on an ensemble to predict an output (class) based on the class with the highest probability of being the output. | |
| Predefined labeling threshold represents the minimum acceptable probability for labeling the observations at each iteration start initially with a very high value. | |
| Predefined amount from the training data set denotes the maximum value of the learning rate which allows the updating of threshold, so any LR that exceeds this threshold will block the updating at that iteration. | |
| Threshold step (predefined value) to decrement the threshold. | |
| A list represents the number of unlabeled observations in each iteration. | |
| Any single observation belongs to U. | |
| i | Incremental variable starts initially by 0. |
| Class | Normal | Dos | Probe | R2L | U2R | Total |
|---|---|---|---|---|---|---|
| Number of Occurrence | 67,343 | 45,930 | 11,656 | 995 | 49 | 125,973 |
| Percentage | 53.5% | 36.5% | 9.3% | 0.8% | ∼=0% | 100% |
| Protocol | Size(MB) | Pct |
|---|---|---|
| (a) Total traffic composition | ||
| IP | 76,570.67 | 99.99 |
| ARP | 4.39 | 0.01 |
| IPV6 | 1.74 | 0.00 |
| IPX | 0.00 | 0.00 |
| STP | 0.00 | 0.00 |
| Other | 0.00 | 0.00 |
| (b) TCP/UDP traffic composition TCP | ||
| TCP | 75,776.00 | 98.96 |
| UDP | 792.00 | 1.03 |
| ICMP | 2.64 | 0.00 |
| ICMPV6 | 0.00 | 0.00 |
| Other | 0.03 | 0.00 |
| (C) TCP/UDP traffic composition | ||
| FTP | 200.30 | 0.26 |
| HTTP | 72,499.20 | 94.69 |
| DNS | 288.60 | 0.38 |
| Netbios | 36.40 | 0.05 |
| 119.80 | 0.16 | |
| SNMP | 0.01 | 0.00 |
| SSH | 241.40 | 0.32 |
| Messenger | 0.54 | 0.00 |
| Other | 3179.08 | 4.15 |
| Datasets | SAL | KNNVWC | PGM |
|---|---|---|---|
| NSL-KDD | 818.976 s | 46.818 s | 3.486 s |
| ISCX | 6874.436 s | 1052.318 s | 36.96 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsulami, B.; Almalawi, A.; Fahad, A. Toward an Efficient Automatic Self-Augmentation Labeling Tool for Intrusion Detection Based on a Semi-Supervised Approach. Appl. Sci. 2022, 12, 7189. https://doi.org/10.3390/app12147189
Alsulami B, Almalawi A, Fahad A. Toward an Efficient Automatic Self-Augmentation Labeling Tool for Intrusion Detection Based on a Semi-Supervised Approach. Applied Sciences. 2022; 12(14):7189. https://doi.org/10.3390/app12147189
Chicago/Turabian StyleAlsulami, Basmah, Abdulmohsen Almalawi, and Adil Fahad. 2022. "Toward an Efficient Automatic Self-Augmentation Labeling Tool for Intrusion Detection Based on a Semi-Supervised Approach" Applied Sciences 12, no. 14: 7189. https://doi.org/10.3390/app12147189