
Learned Semantic Index Structure Using Knowledge Graph Embedding and Density-Based Spatial Clustering Techniques


Abstract
:1. Introduction
- We propose a learned index structure of the LOD cloud using KGE models, and algorithms of join query processing based on our index structure are discussed.
- The LOD stored in the form of RDF graphs can be automatically classified using the embedded model and density-based spatial clustering algorithm.
- Embedded vectors can quickly be matched to semantically similar clusters by comparing vector similarity between a given query and cluster centroids, thereby significantly reducing irrelevant traversal for complex semantic search.
- Experiment results verify that this improved representation outperforms the state-of-the-art LOD index structures.
2. Related Works
2.1. Indexing Techniques for RDF Data
2.2. Storage Structure for LOD
2.3. Word Embedding
2.4. KGE
3. Learned Semantic Index Structure
3.1. Architecture of Learned Semantic Index Structure
3.2. SPARQL Join Query Algorithms for Learned Semantic Index
| Algorithm 1. SPARQL join query algorithm for semantic search. | |
| 1: # Example: a complex query type Q = (?s, p1, o1) ⋈ (?s, p2, o2) ⋈ (?s, p3, ?o) ⋈ (s4, p4, ?o) | |
| 2: If Q is a standard SPARQL triple pattern | |
| 3: For each subquery in Q | |
| 4: If distance between subquery and centroids in k-d tree is shortest Then | |
| 5: Search the corresponding R*-tree by mapping list | |
| 6: Adding search results to ResultList | |
| 7: Else break | |
| 8: End For | |
| 9: End If | |
| 10: # Hybrid join search algorithm | |
| 11: While (two or more search results in ResultList) | |
| 12: ResultList is split and combined into multiple result pairs | |
| 13: Initialize ResultList | |
| 14: For each result pair | |
| 15: If result pair is star type Then | |
| 16: ResultList ← Procedure HASH_JOIN(result pair) | |
| 17: Else: | |
| 18: ResultList ← Procedure NESTED_LOOP_JOIN(result pair) | |
| 19: End For | |
| 20: End While | |
4. Experimental Evaluation
4.1. Join Query Performance
4.2. Index Building Time
4.3. Semantic Clustering Performance
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lashkari, F.; Bagheri, E.; Ghorbani, A.A. Neural Embedding-Based Indices for Semantic Search. Inf. Process. Manag. 2019, 56, 733–755. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 26, 465–470. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the EMNLP 2014-2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar]
- Ristoski, P.; Rosati, J.; Di Noia, T.; De Leone, R.; Paulheim, H. RDF2Vec: RDF Graph Embeddings and Their Applications. Semant. Web 2019, 10, 721–752. [Google Scholar] [CrossRef] [Green Version]
- Verborgh, R.; Vander Sande, M. The Semantic Web Identity Crisis: In Search of the Trivialities That Never Were. Semant. Web 2020, 11, 19–27. [Google Scholar] [CrossRef] [Green Version]
- Bordes, A.; Usunier, N.; Garcia-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 1–9. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the National Conference on Artificial Intelligence, Quebec, QC, Canada, 27–31 July 2014; Volume 2, pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the twenty-ninth AAAI conference on artificial intelligence, Austin, TX, USA, 25-30 January 2015; Volume 29, pp. 2181–2187. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D Knowledge Graph Embeddings. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI 2018), New Orleans, LA, USA, 2–7 February 2018; pp. 1811–1818. [Google Scholar]
- Thiéblin, E.; Haemmerlé, O.; Hernandez, N.; Trojahn, C. Survey on Complex Ontology Matching. Semant. Web 2020, 11, 689–727. [Google Scholar] [CrossRef]
- Bigerl, A.; Behning, C.; Sherif, M.; Saleem, M. Tentris–A Tensor-Based Triple Store. In Proceedings of the International Semantic Web Conference, Athens, Greece, 2–6 November 2020; pp. 56–73. [Google Scholar]
- Jabeen, H.; Haziiev, E.; Sejdiu, G.; Lehmann, J. DISE: A Distributed in-Memory SPARQL Processing Engine over Tensor Data. In Proceedings of the 14th IEEE International Conference on Semantic Computing (ICSC 2020), San Diego, CA, USA, 3–5 February 2020; pp. 400–407. [Google Scholar]
- Fernández, J.D.; Martínez-Prieto, M.A.; Gutiérrez, C.; Polleres, A.; Arias, M. Binary RDF Representation for Publication and Exchange (HDT). J. Web Semant. 2013, 19, 22–41. [Google Scholar] [CrossRef]
- Neumann, T.; Weikum, G. X-RDF3X: Fast Querying, High Update Rates, and Consistency for RDF Databases. Proc. VLDB Endow. 2010, 3, 256–263. [Google Scholar] [CrossRef] [Green Version]
- Hassan, M.; Bansal, S.K. Data Partitioning Scheme for Efficient Distributed RDF Querying Using Apache Spark. In Proceedings of the 13th IEEE International Conference on Semantic Computing, ICSC 2019, Newport Beach, CA, USA, 30 January–1 February 2019; pp. 24–31. [Google Scholar]
- Zou, L.; Özsu, M.T. Graph-Based RDF Data Management. Data Sci. Eng. 2017, 2, 56–70. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Zhang, B.; Rao, G.; Chen, R.; Feng, Z. Hash Tree Indexing for Fast SPARQL Query in Large Scale RDF Data Management Systems. In Proceedings of the CEUR Workshop Proceedings, Cagliari, Italy, 11–12 September 2017; Volume 1963, pp. 1–4. [Google Scholar]
- Wu, D.; Hou, C.; Xiao, E.; Jensen, C.S. Semantic Region Retrieval from Spatial Rdf Data. In Proceedings of the Lecture Notes in Computer Science Database Systems for Advanced Applications, Jeju, Korea, 24–27 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12113, pp. 415–431. [Google Scholar]
- Lee, Y. MDH*: Multidimensional Histograms for Linked Data Queries. Lect. Notes Inf. Theory 2014, 2, 243–248. [Google Scholar] [CrossRef]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–12. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the 28th International Conference on Machine Learning (ICML 2011), Bellevue, WA, USA, 28 June–2 July 2011; pp. 809–816. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Ciaussier, E.; Bouchard, G. Complex Embeddings for Simple Link Prediction. In Proceedings of the 33rd International Conference on Machine Learning (ICML 2016), New York, NY, USA, 19–24 June 2016; Volume 5, pp. 3021–3032. [Google Scholar]
- Sun, Y.; Zhao, T.; Yoon, S.; Lee, Y. A Hybrid Approach Combining R*-Tree and k-d Trees to Improve Linked Open Data Query Performance. Appl. Sci. 2021, 11, 2405. [Google Scholar] [CrossRef]
- Ameen, A.; Khan, K.U.R.; Rani, B.P. Reasoning in Semantic Web Using Jena. Comput. Eng. Intell. Syst. 2014, 5, 39–47. [Google Scholar]
- Han, X.; Cao, S.; Lv, X.; Lin, Y.; Liu, Z.; Sun, M.; Li, J. OpenKE: An Open Toolkit for Knowledge Embedding. In Proceedings of the EMNLP 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 139–144. [Google Scholar]
- Chawla, T.; Singh, G.; Pilli, E.S. JOTR: Join-Optimistic Triple Reordering Approach for SPARQL Query Optimization on Big RDF Data. In Proceedings of the 9th International Conference on Computing, Communication and Networking Technologies, Bengaluru, India, 10–12 July 2018; pp. 1–7. [Google Scholar]
- Daszykowski, M.; Walczak, B. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Ali, W.; Saleem, M.; Yao, B.; Hogan, A.; Ngomo, A.C.N. A Survey of RDF Stores & SPARQL Engines for Querying Knowledge Graphs. VLDB J. 2022, 31, 603–628. [Google Scholar] [CrossRef]
- Ben Mahria, B.; Chaker, I.; Zahi, A. An Empirical Study on the Evaluation of the RDF Storage Systems. J. Big Data 2021, 8, 1–26. [Google Scholar] [CrossRef]
- Harth, A.; Decker, S. Optimized Index Structures for Querying RDF from the Web. In Proceedings of the Proceedings-Third Latin American Web Congress (LA-WEB 2005), Buenos Aires, Argentina, 31 October–2 November 2005; pp. 71–80. [Google Scholar]
- Quilitz, B.; Leser, U. Querying Distributed RDF Data Sources with SPARQL. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5021, pp. 524–538. [Google Scholar]
- Ranichandra, C.; Tripathy, B.K. Architecture for Distributed Query Processing Using the RDF Data in Cloud Environment. Evol. Intell. 2019, 14, 567–575. [Google Scholar] [CrossRef]
- Tsatsanifos, G.; Sacharidis, D.; Sellis, T. On Enhancing Scalability for Distributed RDF/S Stores. In Proceedings of the 14th International Conference on Extending Database Technology (EDBT 2011), Uppsala, Sweden, 21–24 March 2011; pp. 141–152. [Google Scholar] [CrossRef]
- Guo, Y.; Pan, Z.; Heflin, J. LUBM: A Benchmark for OWL Knowledge Base Systems. Web Semant. 2005, 3, 158–182. [Google Scholar] [CrossRef] [Green Version]
- Aberger, C.R.; Tu, S.; Olukotun, K.; Ré, C. Old Techniques for New Join Algorithms: A Case Study in RDF Processing. In Proceedings of the IEEE 32nd International Conference on Data Engineering Workshops (ICDEW 2016), Helsinki, Finland, 16–20 May 2016; pp. 97–102. [Google Scholar]
- LinkedGeoData Dataset. Available online: https://aksw.org/Projects/LinkedGeoData.html (accessed on 18 April 2022).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension Reduction | Multidimensional Index Structure | |||||
|---|---|---|---|---|---|---|
| Ordering | Transforms | Data Partitioning | Space Partitioning | |||
| Feature | Distance | Feature | Distance | |||
| Characteristic | Convert RDF data into lower dimensional space | Build the multidimensional index structure | ||||
| Advantage | Excellent storage performance | Efficient query processing | ||||
| Weakness | Need refresh entire index structure when new data are inserted | High spatial complexity with the increase of data volume | ||||
| Related work | Tentris [12], DISE [13] | DiStRDF [14], TripleID-Q [15] | SPT+VP [16], | axonDB [17], | HTStore [18], | Vp-tree [19] |
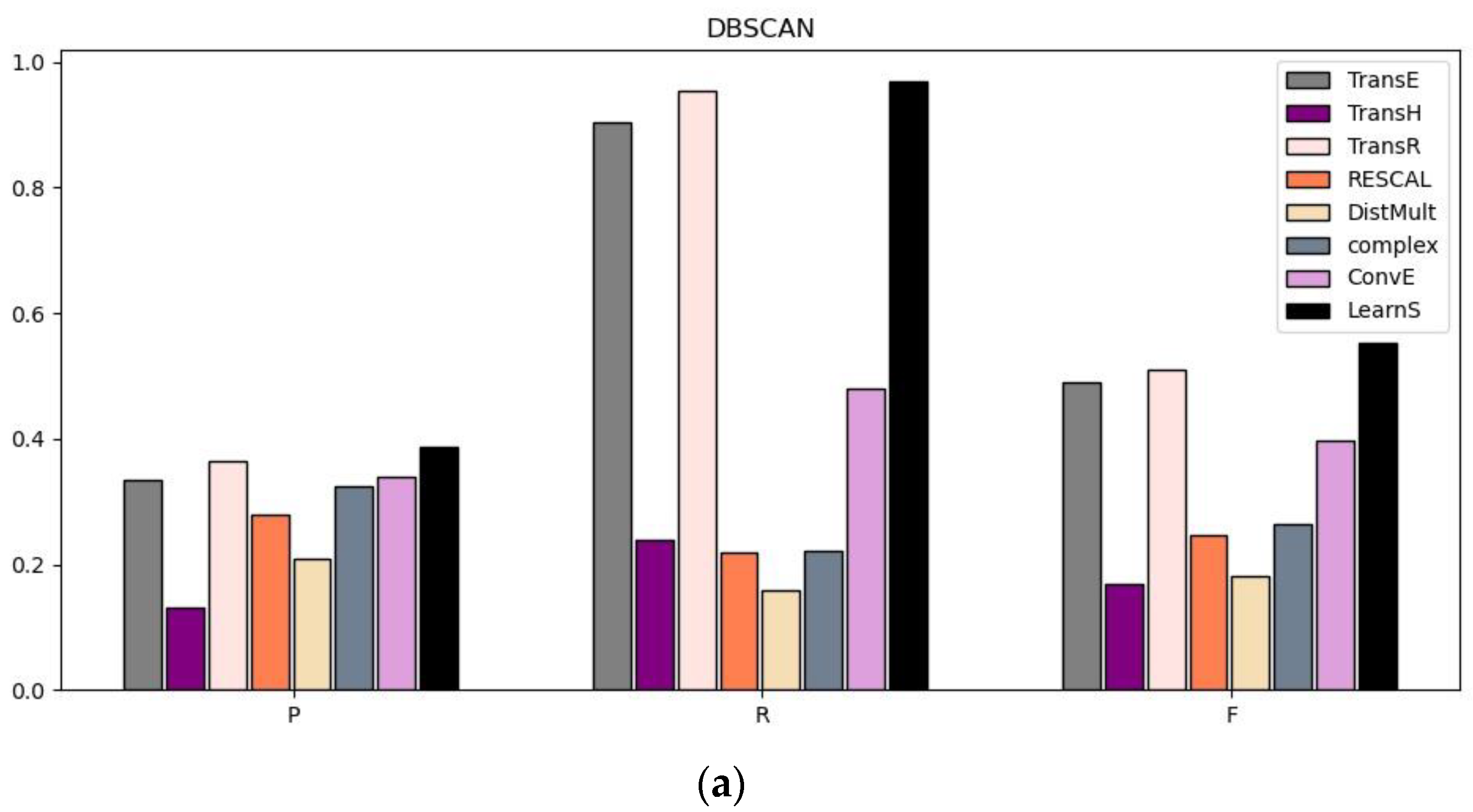
| Models | Precision (P) DBSCAN (K-Means) | Recall (R) DBSCAN (K-Means) | F-Measure (F) DBSCAN (K-Means) |
|---|---|---|---|
| TransE | 0.335 (0.250) | 0.903 (0.865) | 0.489 (0.388) |
| TransH | 0.130 (0.060) | 0.240 (0.080) | 0.168 (0.068) |
| TransR | 0.365 (0.340) | 0.955 (0.901) | 0.511 (0.402) |
| RESCAL | 0.280 (0.250) | 0.220 (0.182) | 0.246 (0.210) |
| DistMult | 0.210 (0.334) | 0.160 (0.287) | 0.182 (0.308) |
| complex | 0.325 (0.310) | 0.221 (0.268) | 0.263 (0.287) |
| ConvE | 0.340 (0.335) | 0.480 (0.425) | 0.398 (0.375) |
| LearnS | 0.386 (0.345) | 0.970 (0.930) | 0.552 (0.503) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Chun, S.-J.; Lee, Y. Learned Semantic Index Structure Using Knowledge Graph Embedding and Density-Based Spatial Clustering Techniques. Appl. Sci. 2022, 12, 6713. https://doi.org/10.3390/app12136713
Sun Y, Chun S-J, Lee Y. Learned Semantic Index Structure Using Knowledge Graph Embedding and Density-Based Spatial Clustering Techniques. Applied Sciences. 2022; 12(13):6713. https://doi.org/10.3390/app12136713
Chicago/Turabian StyleSun, Yuxiang, Seok-Ju Chun, and Yongju Lee. 2022. "Learned Semantic Index Structure Using Knowledge Graph Embedding and Density-Based Spatial Clustering Techniques" Applied Sciences 12, no. 13: 6713. https://doi.org/10.3390/app12136713